分布式RDF数据管理综述
2017-06-23邹磊彭鹏
邹 磊 彭 鹏
1(北京大学计算机科学技术研究所 北京 100080)2(湖南大学信息科学与工程学院 长沙 140082)
分布式RDF数据管理综述
邹 磊1彭 鹏2
1(北京大学计算机科学技术研究所 北京 100080)2(湖南大学信息科学与工程学院 长沙 140082)
(zoulei@pku.edu.cn)
资源描述框架(resource description framework, RDF)作为一个展示、共享和连接网络上的数据的模型,已经被广泛地用在各种应用中.同时,SPARQL(simple protocol and RDF query language)作为一种结构化查询语言则被用来支持对RDF数据进行查询检索.随着RDF数据规模的日益增长,在现有RDF数据库上进行SPARQL查询处理已经超出了单机的处理能力.于是,人们需要设计出高性能的分布式RDF数据库以支持对SPARQL查询进行高效的处理.当前,已经有大量的工作来讨论如何搭建分布式RDF数据管理系统.对这些不同的分布式RDF数据管理方法进行综述,将现有的分布式RDF数据管理方法分成3类:基于云计算平台的分布式RDF数据管理方法、基于数据划分的分布式RDF数据管理方法和联邦式系统.基于云计算平台的分布式RDF数据管理方法利用已有云平台进行RDF数据的管理;基于数据划分的分布式RDF数据管理方法首先将RDF数据图划分成若干子图,然后将这些子图分配到不同计算节点上;联邦式系统的特点是数据已经分布在不同节点上,数据管理系统无法控制数据的分布.在每类分布式RDF数据管理方法的介绍中,将深入讨论以帮助读者了解各种方法的特点.
RDF数据管理;SPARQL查询处理;分布式数据库系统;云计算;关联数据
进入21世纪以来,语义网(semantic Web)逐渐兴起并成为万维网的重要发展方向.在语义网中,人们通过数据库技术将越来越多的知识结构化地组织起来,以便于人们操作与利用.现阶段,人们已提出过各种各样的知识结构化组织方式,其中以万维网联盟(world wide Web consortium, W3C)提出的资源描述框架(resource description framework, RDF)最为有名且已经被广泛地应用在各个领域.
RDF是W3C提出的一组知识表示的模型,以便更为丰富地描述和表达网络资源的内容与结构.RDF利用统一资源标识符(uniform resource identifier, URI)标识网络上的各种事物.这些URI所对应的事物既包括真实世界中的实体(比如一名哲学家)也包括人们在社会实践中形成的概念(比如姓名、出生年月)等.这些URI所对应的事物又被成为资源.RDF的基本数据单元是一个三元组,可以表示为〈主体,属性,客体〉,每个三元组表示某个资源的一个属性值或者某个资源与其他资源的关系.
在实际中,人们还经常将RDF数据视为一个或多个连通图.其中,RDF数据中每个资源被视为一个点,而每个三元组被视为连接2个资源的一条边.Bönström等人[1]提出,相比于将RDF数据视为XML格式数据或三元组的集合,RDF的图模型更能反映RDF数据中涵盖的语义信息.
在定义RDF数据模型的同时,W3C也定义了结构化查询语言SPARQL(simple protocol and RDF query language),以实现针对大规模RDF数据的查询与检索.在SPARQL语法中,用户是用SELECT语句查询满足特定条件的RDF数据片段.具体而言,对于一个SELECT语句中,SELECT子句指定查询应当返回的内容,FROM子句指定将要使用的数据集,WHERE子句包含一组三元模式组成用以指定所返回的RDF数据片段需要满足的模式.SPARQL语言与SQL语言相似的这个特性方便了用户对于SPARQL语言的使用.
与RDF数据的图形式表示类似,一个SPARQL查询可以表示为一个查询图[2-3].查询中每个变量或者常量对应一个查询图上的点,每个WHERE子句中的三元模式对应一条边.当RDF数据和SPARQL查询都转化成图的形式,SPARQL查询语句的查询结果就是其所对应的查询图在RDF数据图上的子图匹配.
由于RDF结构的灵活性,现在RDF数据的应用范围日益广阔.越来越多的知识数据开始表示成RDF格式.比如,德国的莱比锡大学和柏林自由大学合作从维基百科上抽取结构化数据形成的知识库DBpedia[4]已将近有24亿三元组;另外,德国MaxPlanck实验室从Wikipedia上抽取出的信息并结合wordnet中类型信息形成的RDF知识库YAGO[5-7]也已经有将近2亿三元组.
随着RDF数据规模的日益增长,现有RDF数据集的规模已经超出了单机处理能力的限制.于是,为了应对超出单机系统性能限制的RDF数据,利用分布式数据库系统来处理SPARQL查询成为了日益火热的研究课题.
现阶段,在学术界已经有不少在分布式环境下对RDF知识库上SPARQL查询进行处理的方法.我们根据RDF数据存储方式和划分策略,将现有的分布式RDF系统划分为三大类:
1) 基于云计算平台的分布式RDF系统
这种方法依赖于现有的云计算系统,例如Hadoop等,进行RDF数据的管理.通常需要将RDF的三元组数据归结到云平台所支持的存储的文件格式,例如HDFS文件等.数据的物理存储由云平台来负责,不需要RDF系统来设计.
2) 基于数据划分的RDF数据管理方法
这类方法主要讨论数据如何划分,划分以后的数据分别物理地存储到各自的机器上.数据的划分策略和存储方式是这类方法设计的重点.
3) 联邦式分布式RDF数据系统
此类方法假设整体的RDF数据由多个独立节点上的局部数据集成得到,联邦系统不允许重新划分数据,参与系统的本地机器对本地数据拥有管理权,但是联邦系统可以回答针对整体RDF数据集的查询.
1 RDF数据模型与SPARQL查询模型
1.1 RDF数据模型定义
一个RDF数据集可以看做一系列三元组的集合.每一条三元组又可被称为一条声明(statement).一条三元组包括3个元素:主体(subject)、属性(property)及客体(object),通常描述了2个资源间的关系或是1个资源的某种属性.当某条三元组描述了某个资源的属性时,其3个元素也被称为主体、属性及属性值(property value).相关的形式化定义如下.
定义1. 资源(resource).资源是可区别性且独立存在的某种事物.RDF数据中的每一个资源均被分配一个独一无二的标识,称为统一资源标识(URI).
定义2. 三元组(triple).RDF数据中的三元组又称声明(statement),通常被表示为〈主体(subject),属性(property),客体(object)〉.也常简化为〈s,p,o〉的形式.同时三元组也可表示为〈主体(subject),属性(property),属性值(property value)〉,这种方式主要用来描述实体的相关属性.三元组的取值空间可形式化表示为(U∪B)×(U∪B)×(U∪B∪L),其中U代表URI的集合,B代表空值,L代表文本.
图1所示为一个截取自DBpedia[4]的RDF数据集的片段.这个片段中包括7条三元组,描述了欧洲哲学家弗里德里希·尼采(Friedrich Nietzsche)所对应的资源及其相关三元组.
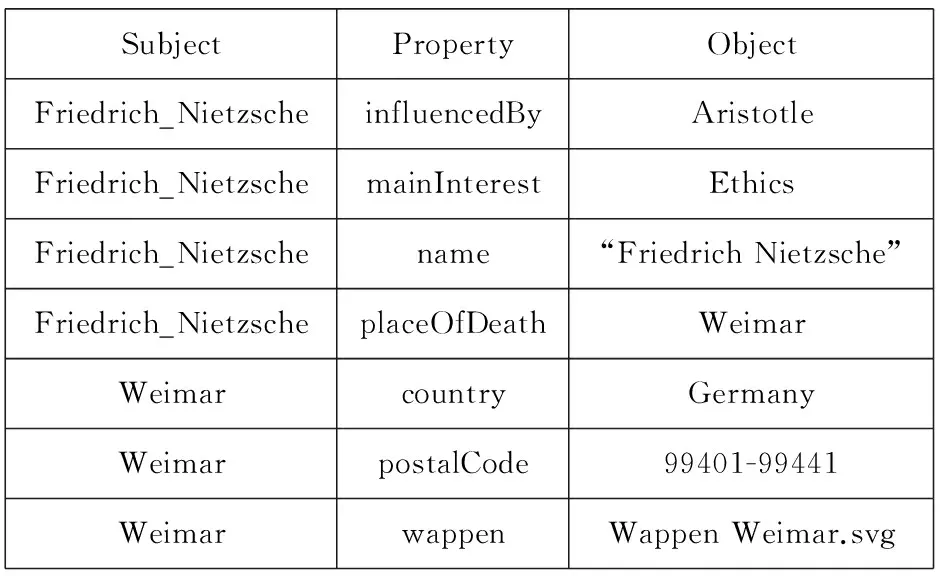
SubjectPropertyObjectFriedrich_NietzscheinfluencedByAristotleFriedrich_NietzschemainInterestEthicsFriedrich_Nietzschename“FriedrichNietzsche”Friedrich_NietzscheplaceOfDeathWeimarWeimarcountryGermanyWeimarpostalCode99401-99441WeimarwappenWappenWeimar.svg

Fig. 1 Example of RDF triples
图1 RDF三元组示例
除了基本的三元组模型,图模型也被广泛地用来描述RDF数据.通过将主体及客体视为顶点且将三元组视为连接顶点与顶点之间的有向边,RDF数据集可以被看作为一张有向图.定义3给出了RDF数据图的定义.
定义3. RDF数据图. RDF数据图被表示为有向图G=〈V,E,L〉,其中:V表示RDF数据图中的点集,V中的每个点对应于所有RDF三元组中的主体或者客体,其可以是资源点、空值点或者文本点;E=V×V是RDF数据图中的有向边集,每条边对应于RDF数据中的一个三元组;L是所有边的标签集合,即属性集合,每条边的标签是其所对应三元组中的属性.
图2展示了一个RDF数据集片段对应的RDF数据图.
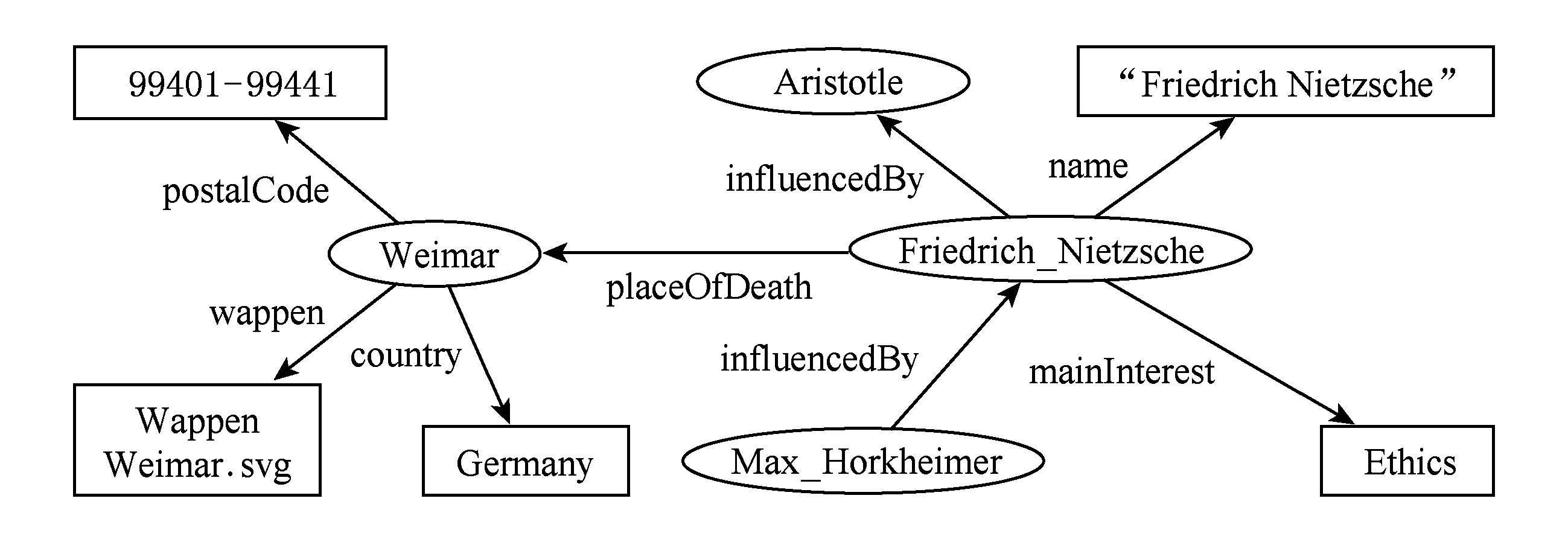
Fig. 2 Example of RDF graph图2 RDF数据图示例
1.2 SPARQL查询模型定义
对于RDF数据,W3C提出SPARQL查询语言作为检索与查询的标准化语言.本文所关注的是以SELECT子句为开头的选择性查询.更进一步来说,由于选择性查询总可以被分解为若干个基本图模式(basic graph pattern),并通过后处理的方式如过滤、聚集查询、查询的合并等满足各种各样的查询需求,因此本文主要关注基本图模式对应的SPARQL查询.
本文基于Pérez等人的工作[8]来定义SPARQL查询及它的匹配.
定义4. 变量. SPARQL查询中的变量是以“?”开头的一串字符,当且仅当2个字符串完全相同时,相对应的变量被视为同一个变量.任何主体、属性或客体均视为变量的一个匹配.
定义5. 三元组模式. 当三元组中的主体、属性或客体被变量取代时,该三元组被称为三元组模式(triple pattern).三元组模式的取值空间为(U∪B∪V)×(U∪B∪V)×(U∪B∪L∪V),其中V为所有可能变量的集合.一个三元组称为是某个三元组模式的匹配当且仅当该三元组与三元组模式的对应元素相匹配,其中变量可以匹配到任何常量,而常量仅能匹配与其标签完全一致的常量.
定义6. SPARQL查询. 一个SPARQL查询是一系列三元组模式以点操作“.”相连接的组合.一个图结构视为某个基本图模式的匹配当且仅当该SPARQL查询中的变量和三元组模式与该图结构中的顶点和三元组的匹配关系形成一一映射.
一个SPARQL查询同样可以被表示为一个图结构.
定义7. SPARQL查询图. 一个SPARQL查询可以被表示为有向图Q=〈VQ,EQ,LQ〉.其中,VQ=V∪Vv,其中Vv是表示变量的顶点的集合,而V的定义与定义3中相同;EQ=VQ×VQ是SPARQL数据图中的有向边集,每条边对应于SPARQL查询中的一个三元组模式;LQ是所有边的标签集合,即属性集合与边上的变量集合.
图3给出了一个示例的基本图模式的SPARQL查询以及其对应的SPARQL查询图,用以查询RDF数据图上所有“受过亚里士多德影响的伦理学相关的哲学家”.
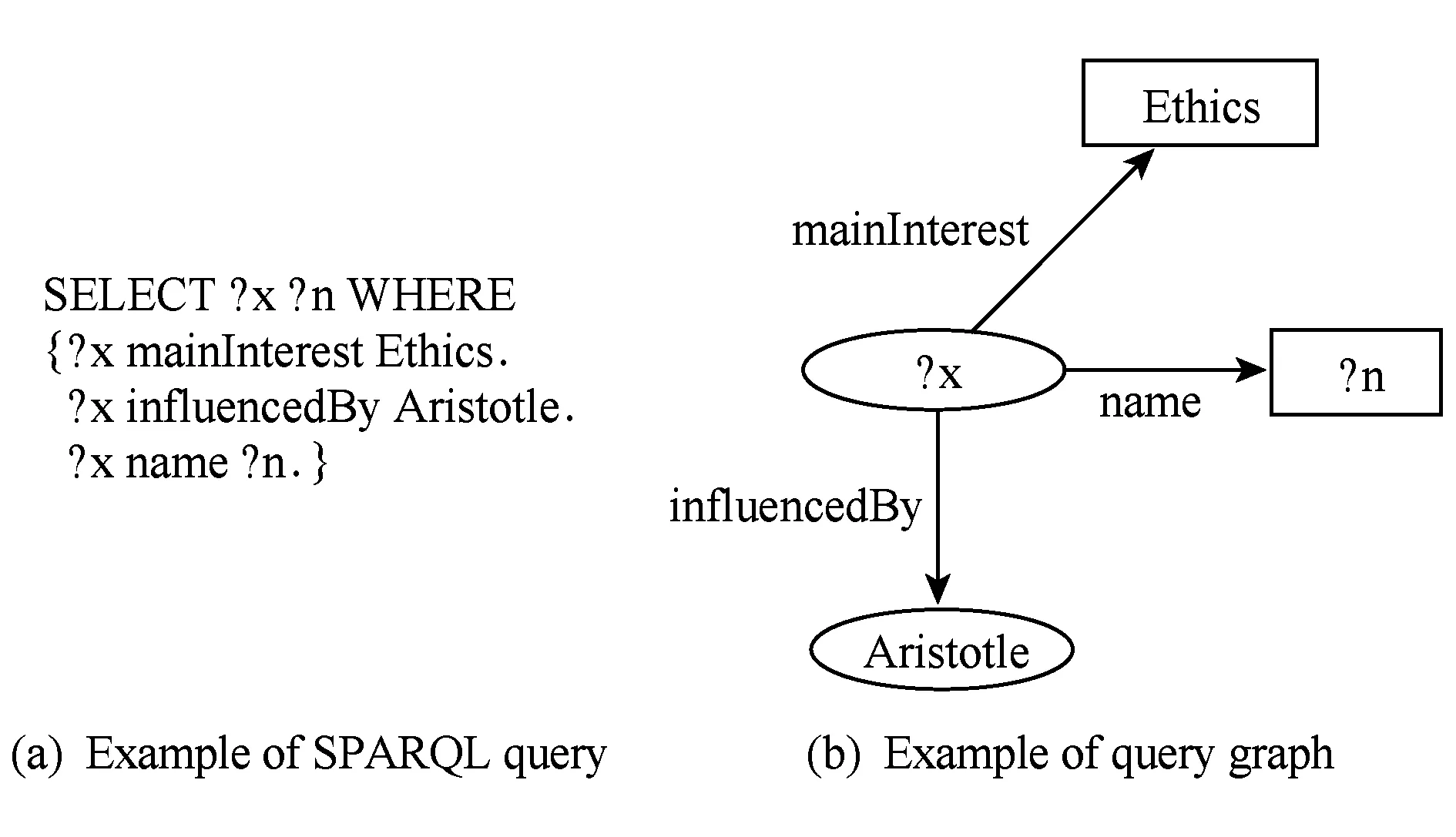
Fig. 3 Example of SPARQL query and its query graph图3 SPARQL查询及其查询图示例
根据上述定义可知,寻找SPARQL查询的结果的过程可以被视为在RDF数据图中寻找子图匹配的过程.于是,一个SPARQL查询的匹配定义如下:
定义8. SPARQL查询匹配. 给定RDF数据图G和基本图模式查询图Q,若Q有n个顶点{v1,v2,…,vn},图G中的n个顶点{u1,u2,…,un}被称为是Q的一个匹配当且仅当存在一个匹配函数f满足下列条件:如果顶点vi不是变量,则f(vi)和vi有相同的URL或者字符值;如果顶点vi是变量,则f(vi)可为任意值;如果存在边〈vi,vj〉是Q中从vi到vj的一条边,那么在G中存在相应的边〈f(vi),f(vj)〉,且如果〈vi,vj〉的标签为p,则〈f(vi),f(vj)〉也必须为p.
在上述语境下,SPARQL查询的处理可以被视为在RDF数据图中寻找相应的子图匹配的过程.针对这个问题,现有很多分布式RDF数据管理方法都是基于图的查询处理算法.对于图3给出的查询示例而言,这个查询图在图2所示的RDF数据图中有一个匹配,为{Friedrich_Nietzsche,“Friedrich Nietzsche”}.
2 基于云计算平台的分布式RDF数据管理方法
所谓基于已有云平台的SPARQL查询处理的方法,它们都是利用已有云平台存储管理系统进行RDF数据的存储,并利用这些已有云平台上成熟的任务处理模式进行SPARQL查询处理.现有被利用来进行SPARQL查询处理的云平台系统包括Hadoop[9],Trinity[10]等.
被最多地利用来进行SPARQL查询处理的云平台系统就是Hadoop[9].作为现阶段被广泛使用的云平台,Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户可以在不了解分布式底层细节的情况下开发分布式程序,并充分利用集群的威力进行高速运算和存储.Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,而MapReduce为海量的数据提供了计算.现有很多分布式RDF数据管理方法[11-14]也是利用HDFS进行RDF数据的存储,同时利用MapReduce进行SPARQL查询处理.
具体而言,这些基于Hadoop的SPARQL查询处理方法首先将RDF数据转化为平面文件存储在HDFS上,不同的方法有不同的RDF数据转化形式.当SPARQL查询输入之后,针对查询图的形式和RDF数据存储的形式,将查询分解成若干子查询.每个子查询通过在HDFS上的扫描得到候选解,然后用MapReduce将候选解连接起来以得到最终解.不同方法之间的主要区别就是不同的RDF数据转化HDFS平面文件的方式.
SHARD[11]以RDF数据中的主体为核心进行数据划分,与一个主体相关的所有三元组被聚集在一起并被存储为HDFS文件中的一行.HadoopRDF[12]和P-Partition[13]都是以RDF数据中的属性为核心进行存储,有相同属性的所有三元组被聚集一起存储于一个HDFS文件中.HadoopRDF[12]在以属性为核心的存储模式之外,还利用客体的类型信息进一步划分RDF数据.
不同于以往方法中以三元组为HDFS上基本存储单元的存储模型,EAGRE[14]提出了一个基于“实体”类型的存储模型.图4展示了EAGRE的系统框架图.具体而言,如图4下半部分所示,EAGRE将RDF三元组数据中所有主体视为一个实体,进而将RDF数据图压缩成一个实体图;然后,将相似的实体聚类成一个实体类,进而形成一个压缩实体图(compressed RDF entity graph).这个压缩实体图存储在内存中,并利用METIS进行图划分,然后根据划分结果将RDF实体以及相应三元组放到不同机器上.同时,每个实体是按照实体类来排序并存在HDFS中的(key,value)存储中.另一方面,如图4上半部分所示,当查询进来之后根据压缩实体图快速确定查询结果可能在哪些entity class中,进而确定候选可能在哪些Hadoop计算节点中;然后,各个计算节点在MapReduce的Map阶段找出候选,并在Reduce阶段将这些候选拼起来.
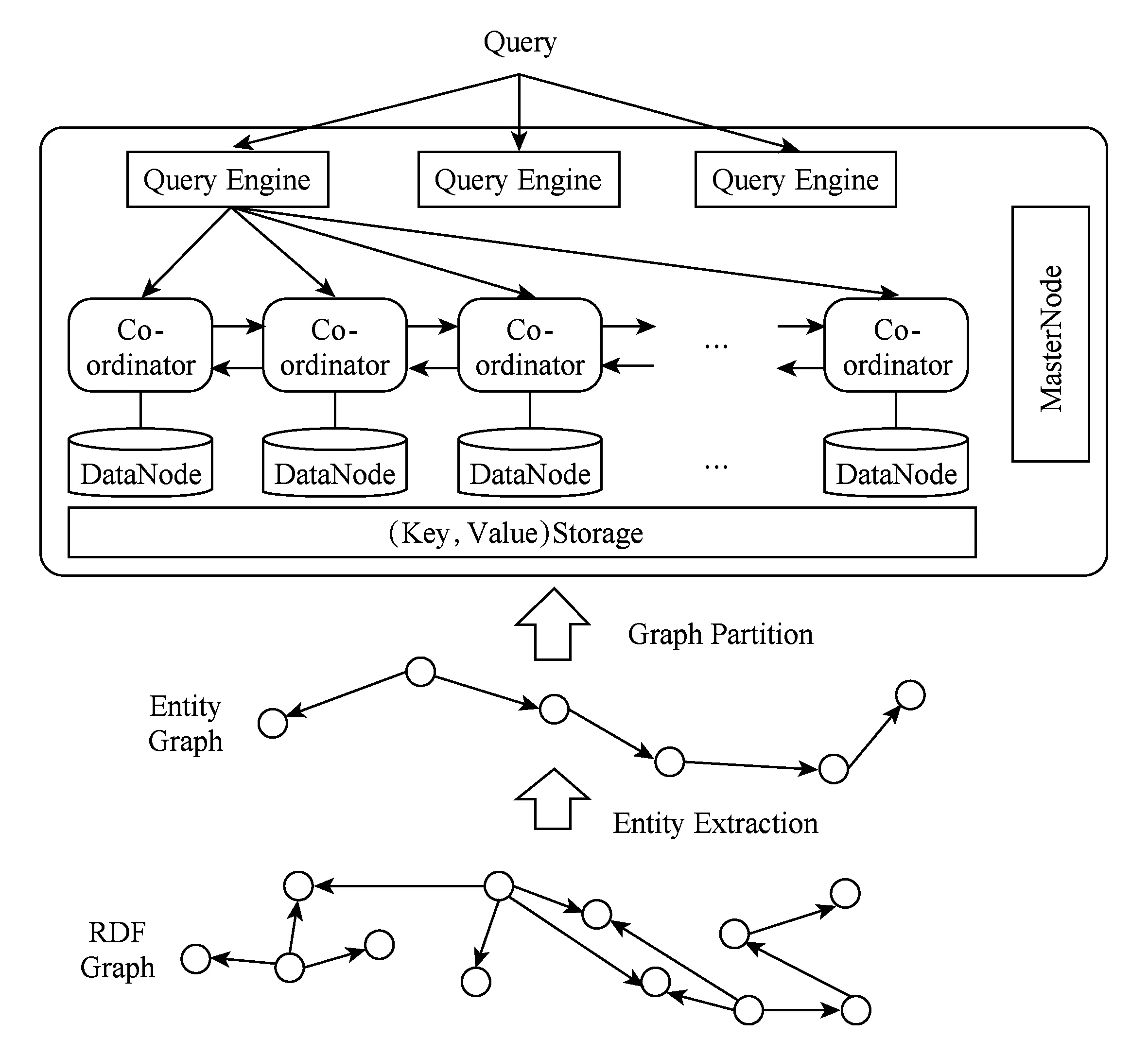
Fig. 4 The Framework of EAGRE[14]图4 EAGRE框架图[14]
除了基于HDFS的方法之外,现阶段还有部分研究工作是基于其他的云平台系统的.比如基于HBase的H2RDF[15-16]、基于Trinity[10]系统的Trinity、RDF[17]、基于Parquet[18]系统的Sempala[19]、基于Spark[20]系统的S2RDF[21].
H2RDF[15-16]构建了(主体、属性、客体)、(属性、客体、主体)和(客体、主体、属性)这3种索引于HBase上.此外,H2RDF只会将一些选择性(selectivity)高的SPARQL查询转化为HBase扫描操作;而对于选择性不高的SPARQL查询,H2RDF会调用MapReduce任务来处理.
Trinity[10]是微软研发的一个基于内存的分布式图数据管理系统.Trinity认为随着时代的发展,一方面内存越来越大且越来越便宜;另一方面图数据上的基本操作非常复杂,将数据在外存会导致操作不便,所以利用内存进行图数据管理才是应有之选.因此,Trinity使用了内存云的技术,也就是将多台机器的内存封装一个起来,使得用户能同时使用多台机器的内存,而且无需知道底层细节.Trinity里面的基本数据结构是键值对,利用这个结构可以以邻接表的形式来存储与管理数据图.
Trinity.RDF[17]提出了利用Trinity进行RDF图数据管理的方法.Trinity.RDF将RDF数据图的邻接表载入Trinity的内存之中.由于RDF数据图一般要视为有向图,所以邻接表可以分出边表和入边表2个.如图5所示,对于RDF数据图上的点n0而言,它的入边和出边分别存入2个不同的邻接表并存储在Trinity的内存云上.
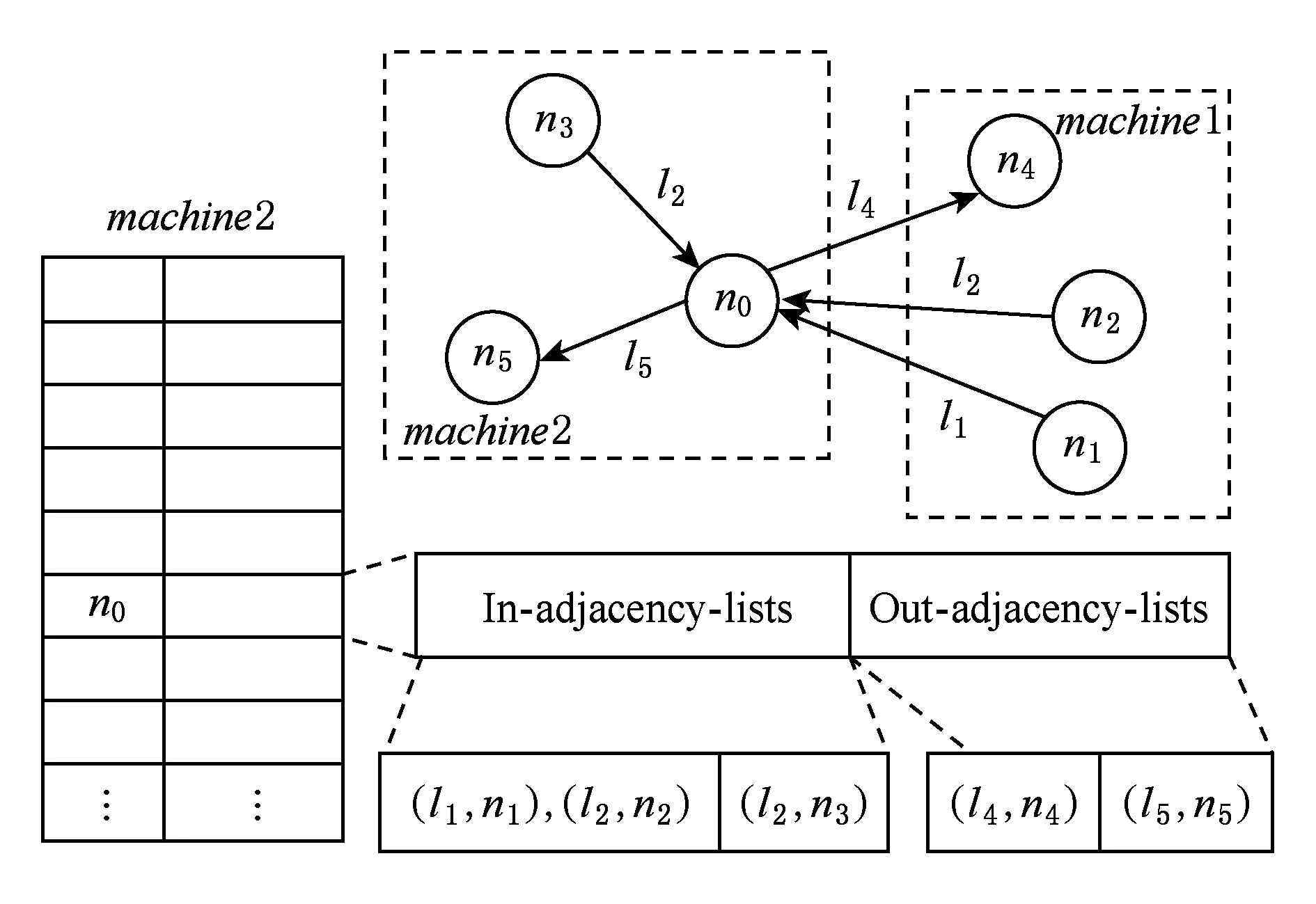
Fig. 5 Example of storage in Trinity.RDF[17]图5 Trinity.RDF存储示例[17]
Sempala[19]是一个基于Parquet[18]分布式RDF数据管理系统.Parquet本质上是一个支持按照列存储的分布式关系数据库管理系统.Sempala将RDF数据按照统一属性表的形式存储在Parquet上.所谓统一属性表就是将每个实体作为关系表中的一行,这个实体的每个属性作为一列.
在查询处理阶段,Sempala首先将查询分解成能转化成Parquet上SQL语言的星状子查询,然后执行这些星状子查询并通过连接操作将这些星状子查询的结果拼接起来以得到最终结果.
S2RDF[21]是基于云平台Spark[20]的关系数据库接口实现的分布式RDF数据管理系统.Spark是加州大学伯克利分校的AMP实验室实现的基于内存的云平台.
因为S2RDF使用了Spark的关系数据库接口,所以S2RDF首先讨论了如何将RDF数据划分成若干关系表并存储在Spark中.S2RDF里基本的划分是垂直划分,即将RDF数据中有相同属性的三元组合在一起存于一张关系数据表中.在基本垂直划分基础上,S2RDF扩展出了ExtVP(extended vertical partitioning),即ExtVP物化了部分垂直划分数据表之间的连接结果并存储在关系数据表,以降低处理连接操作时的代价.
在查询处理阶段,S2RDF将查询中每一个三元组模式都对应上一张垂直划分出来的数据表,然后将这个三元组模式转化成一个相应的SQL语句以去除每个三元组模式的匹配.此处,一个三元组模式如果和其相邻的三元组模式合起来满足ExtVP中的一个物化出的关系数据表,那么这个三元组模式也可能对应上一张ExtVP中的关系数据表.
对于查询中属性为变量的三元组模式,S2RDF维护一张包含所有三元组的大表,所以属性为变量的三元组模式可以直接在这张大表上执行SQL查询.
总的来说,基于云平台的SPARQL查询处理方法因为利用了现有的云计算平台,所以这些方法都有很好的可扩展性与容错性.但是,由于现有云计算框架很多都是面向离线数据分析的,特别是Hadoop的MapReduce框架,所以在利用这些云计算框架进行SPARQL查询处理的效率是一个技术挑战.
3 基于数据划分的分布式RDF数据管理方法
基于数据划分的SPARQL查询处理方法首先将RDF数据图划分成若干子图,然后将这些子图分配到不同计算节点上.各个计算节点安装单机的RDF数据管理系统,以管理被分配来的RDF数据图子图.当SPARQL查询输入这些系统中后,查询首先被划分成若干子查询,然后也被分配到各个计算节点上执行得到部分解,最后所有部分解被收集起来进行连接操作得到最终解.在查询划分时,系统需要考虑数据划分的方法,以保证每个子查询能只在特定的计算节点上进行求解,而不需要不同机器间的通信.不同基于数据划分的SPARQL查询处理方法的主要区别在于数据划分时采用的策略不一样.
在Huang Jiewen等人[22]的工作中,他们提出了根据其图结构信息进行划分的方法.首先对RDF数据图的划分使用现有成熟工具METIS[23]来实现.划分出来的每个RDF数据块对应一个数据分片,进而对应一个系统中的一个工作节点.在每个工作节点内部,使用的是已有的集中式RDF数据管理系统对数据分片内部的RDF数据进行管理.在此过程中,为了提高数据的局部性,每个块除了保存自身所有的点之外,还保存了边界节点n步邻居以内所有点和边的副本(n为系统事先设定的参数).
在查询处理阶段,如果用户输入的SPARQL查询图直径小于n,说明这个SPARQL的匹配一定完全存在于某些数据块之中,而不需要与其他的数据片进行交互;系统直接将SPARQL查询分发给各个工作节点,各个工作节点各自利用已有的集中式RDF数据管理系统找到匹配并直接返回给用户即可.如果用户输入的SPARQL查询图直径大于n,那么说明这个查询的匹配很可能跨越了多个数据块.此时,Huang Jiewen等人[22]的工作就将SPARQL分解成多个查询图直径小于n的子查询;最后需要把子查询结果进行链接操作得到最终的查询结果.
在Huang Jiewen等人[22]工作的基础上,WARP[24]进一步从查询日志挖掘出若干常见的查询模式,然后将满足常见查询模式的结构复制在用Huang Jiewen等人工作进行分块的结果中.
Partout[25]直接应用关系数据库中的“小项谓词”概念[26]在RDF数据上.具体而言,Partout将RDF三元组存储为一张巨大的三元组表并在其上找出“小项谓词”以进行数据划分.
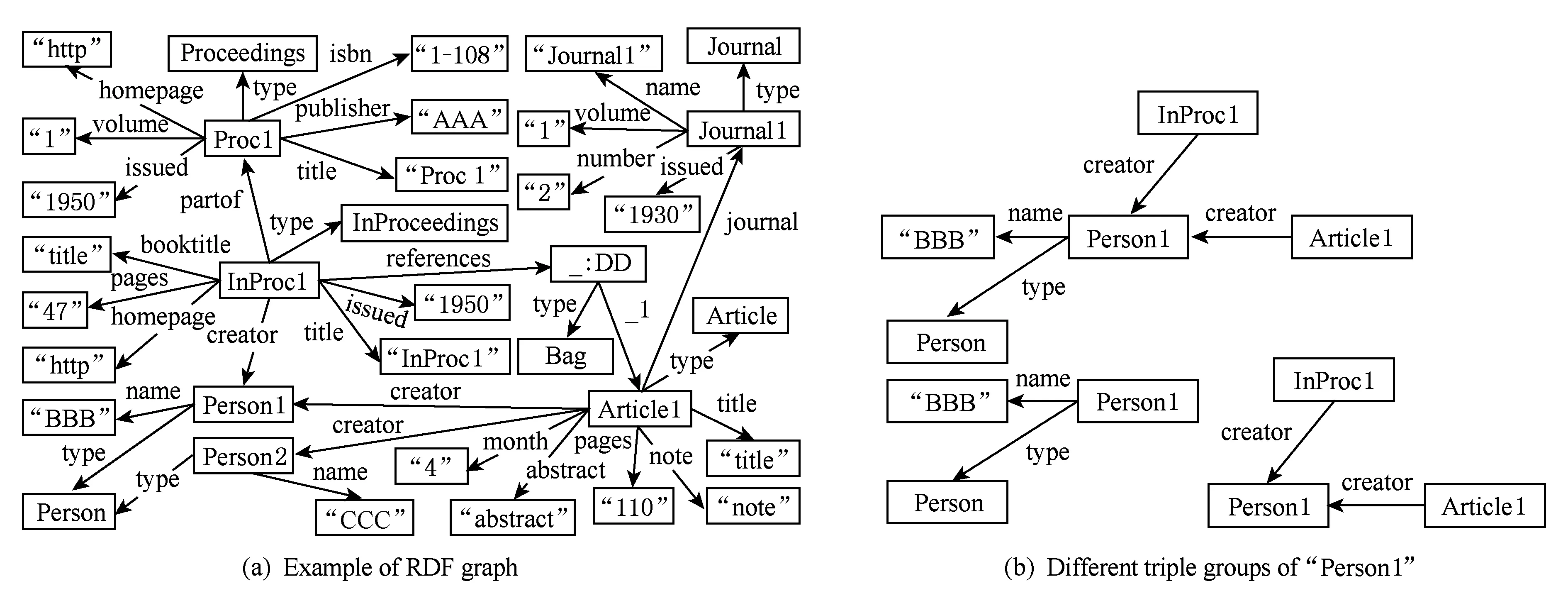
Fig. 6 Example of triple groups of SHAPE[28]图6 SHAPE三元组群示例[28]
中国人民大学陈晋川老师等人[27]也首先找出若干常见查询模式.对于每一个查询模式而言,都将其视为一个查询边序列(e0,e1,…,em),其中任意ei都能和{e0,e1,…,ei-1}中至少一条边连接起来.之后,找到满足e0的三元组,并将这些三元组随机分成n份,其中n为计算节点数量.然后,找到满足e1的三元组.对于每个满足e1的三元组t而言,由于e1能和e0连接,所以存在若干满足e0的三元组{t01,t02,…,t0k}能与t连接起来.因此,该方法[27]将t分别放置于t01所在分块中,t02所在分块中,……,t0k所在分块中.同理,对于满足e2的三元组t′而言,此方法[27]也类似地根据它能与哪些满足e1和e0的三元组连接来判断t′放于哪个分块之中.以此类推,此方法就可以将满足查询边序列(e0,e1,…,em)中任意一条边的三元组放置于某个分块之中.对于任意一个查询模式,陈晋川老师等人所提出的这个方法[27]都会为之生成一个RDF数据的n份划分.
讨论完数据划分之后,就开始讨论如果有多个查询模式,每一个查询模式都对应一个n份分块,怎么将这些分块有效地分配到各个计算节点上使得冗余最少.借鉴LNS(large neighborhood search)算法,提出了一个近似算法,进而将这些分块有效地分配到各个计算节点上.而对于那些没有出现在现有任何查询模式中的三元组而言,陈晋川老师课题组的方法随机将这些三元组放到任意一个机器上.
在SHAPE[28-29]中进行RDF数据划分时,SHAPE划分的基本单元为一个三元组群(triple group).所谓三元组群,其实就是图上的星状结构.SHAPE提出了3种三元组群:只含中心点出边的三元组群、只含中心点入边的三元组群、含中心点出边与入边的三元组群.图6(b)给出了图6(a)中的示例RDF数据图在SHAPE中对应于“Person1”的3种三元组群.在实际应用中,SHAPE支持用户根据实际需求选择上述3种三元组群的一种作为基本划分单元.此外,为了提高查询的局部性,对于每个三元组群,SHAPE支持其向外扩展k步,形成k步的三元组群.
在离线阶段,SHAPE首先利用MapReduce找到RDF数据图上的三元组群;然后,SHAPE将这些三元组群按照Hash分布的方式和基于图分割的分布方式分布到所有机器上.在查询处理阶段,当一个查询Q进来之后,如果Q半径小于k,那么这个查询可以不用不同机器间通信来得到解决;否则,SHAPE将Q分解成若干小于k的子查询,分别得部分解,然后将这些部分解拼起来.
TriAD[30]就是将现有集中式RDF数据管理系统上“六个维度的索引”这个思想扩展到分布式RDF环境下的一个基于内存的分布式SPARQL查询处理引擎.所谓的“六个维度的索引”就是将三元组在主体、属性、客体之间各种排列下能形成各种形态构建都枚举出来,然后为它们构建索引,这样建立的索引恰好是六重索引.这些索引内容正好对应SPARQL查询中带变量三元组的各种可能,于是就能很好地支持SPARQL查询.
在数据预处理阶段,TriAD先建立一个概述图,然后将这个全局概述图(global summary graph)水平划分成若干块分配到不同客户机上.在中心调度机器上,维护一些概述图信息;在客户机上,为每个块建立基于内存的“六个维度的索引”.在查询处理阶段,首先在中心调度机器上对概述图通过Trinity.RDF中提到的图扩展进行匹配来得到查询中每个查询三元组的候选,然后在Slave上通过连接操作获得最终解.在连接操作的过程中,连接操作可能跨机器.
SemStore[31]则是提出了一种称为有根子图(rooted sub-graph)的结构来做为划分基本单元对RDF数据图进行划分.所谓RDF数据图上点v的有根子图就是从v出发做遍历得到的所有点构成的子图.SemStore首先找出能覆盖整个RDF数据图一个有根子图集合,然后利用K-means算法将这些有根子图分成若干类,每一个类里面所有的作为有根子图的一个分块被分配到一个对应的机器.在查询处理阶段,每个查询也被分解成若干有根子图作为子查询并找到部分解,然后通过连接操作将部分解拼成最终解.
华中科技大学袁平鹏等人还提出了一种基于RDF数据图上路径的划分方法[32].这个方法首先在RDF数据图上定义出“源点”和“沉入点”.所谓RDF数据图上的“源点”就是RDF数据图上没有入度的点;而所谓RDF数据图上的“沉入点”就是RDF数据图上没有出度的点.然后,这个方法在“源点”和“沉入点”基础上定义出“末端到末端路径”,即从“源点”或者图上环中没有环外入边的点到“沉入点”或者“末端到末端路径”已经路过点的路径.袁平鹏等人[32]证明了一个RDF数据图能用若干“末端到末端路径”全部覆盖,并且提出了一个有理论保证的近似算法找出了覆盖全图的“末端到末端路径”集合,图给出了一个能覆盖整个数据图的“末端到末端路径”集合的示例.之后,袁平鹏老师研究组[32]提出了算法将覆盖全图的“末端到末端路径”集合分成k份,每份作为一个分块存储到一台机器上.
在查询处理阶段,袁平鹏等人[32]首先将查询分解成一个子查询集合{SQ1,SQ2,…,SQm},其中每个子查询都是查询图中“源点”到所有其可达的点所组成的子图;然后每个子查询被传送到各个计算节点以找到部分解;最后,部分解通过连接操作被拼成最终解.
DiploCloud[33]提出一个同时利用RDF图结构与考虑数据分析需求的混合存储模式.所谓利用RDF数据图结构,就是挖掘出在RDF图中若干存储模式,并以这些存储模式为基本单元进行数据划分;所谓考虑数据分析需求,就是利用列存储技术存储所挖掘出的存储模式中特定位置的数值型数据以高效地支持聚集查询.
此外,北京大学邹磊老师课题组[34]提出了一种基于查询日志的分布式RDF数据库系统设计思路以提高分布式SPARQL查询处理的效率.在这个方法中,我们从查询日志中挖掘并选取出频繁被查询的模式并将它们称为频繁查询模式.选取频繁查询模式的方法能在数据划分时保证RDF数据完整性的同时降低RDF数据存储的冗余度.基于所选取的频繁查询模式,北京大学邹磊老师课题组将RDF数据划分成若干分片,提出了2种数据划分方式:垂直划分和水平划分,这2种数据划分方式是针对于2种不同的查询处理目标.垂直划分是将所有满足相同频繁查询模式的结构划分到相同分片以利用查询局部性提高系统整体吞吐量;而水平划分是通过扩展关系数据库中“小项谓词”的概念来将满足相同频繁查询模式的结构尽可能划分到不同分片以利用系统并行性提高查询处理效率.北京大学邹磊老师课题组[34]还提出了一个数据分配方法将划分出的分片分配到不同机器上.
在查询处理时,上述方法[34]也将用户输入的SPARQL查询基于频繁查询模式分解成若干子查询;然后,每个子查询根据其所对应的频繁查询模式被传输到不同机器上去执行以找出匹配.所有子查询的匹配最终通过连接操作合并成最终匹配.
总的来说,基于数据划分的SPARQL查询处理方法要求按照自身的算法设计进行RDF数据的划分与分配,以减少查询处理阶段的通信代价.但是,在很多实际应用中,RDF数据不能由系统任意划分,而是要基于数据安全性等考量来进行指定的划分.对于这些不能指定数据划分的应用,基于数据划分的SPARQL查询处理方法就无法使用.因此,基于数据划分的SPARQL查询处理方法有一定的局限性.
4 联邦式分布式RDF数据管理方法
某些RDF知识图谱的应用并不允许数据管理系统来指定RDF数据划分.例如,一个RDF数据集是由多个数据拥有方的数据集成得到的,每个拥有方拥有全体RDF数据中的一部分;数据拥有方并不愿意放弃对数据的拥有权和管理权,将数据上传到一个集中的数据中心,由数据中心来对数据进行管理;相反,数据拥有方更希望数据保留在其本地,但是所构建的知识图谱系统可以对全局的知识图谱数据进行查询.这就需要构建一套联邦式分布式RDF数据管理系统,对全局RDF数据进行关联.这种联邦式的RDF数据管理系统并不侵犯数据拥有方对于数据的管理权,数据仍然在每个数据拥有方的本地.这里,每个数据拥有方也被称为RDF数据源.下面,我们简要介绍7种典型的联邦式RDF数据管理系统.
DARQ[35]是最早地讨论如何在联邦式分布式RDF数据管理系统上进行的SPARQL查询处理.图7展示了DARQ的系统框架图.当SPARQL查询输入以后,DARQ根据一个叫服务描述的索引确定出相关的RDF数据源;然后将查询分解成若干子查询并分发到相关的机器上去,之后各个子查询分别求结果;最后将各个子查询的中间结果连接起来得到最终结果.
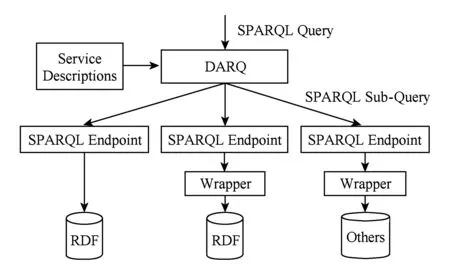
Fig. 7 The framework of DARQ[35]图7 DARQ框架图[35]
所谓服务描述,就是DARQ所构建的一种索引,用以标识出相关数据源.数据描述中包含若干性能,每个性能对应一个数据源.每个性能包含若干元组t=(p,r),其中p表示该数据源有p这个属性,r对应于当属性为p时主体或者客体若干限制.当用户输入查询之后,DARQ首先根据服务描述确定相关数据源;然后,DARQ将查询分解成若干子查询.基本的子查询是单个三元组模式,所以每个子查询都能根据服务描述确定其相关的数据源.如果2个三元组模式都只涉及一个相同的数据源,那么这2个子查询可合并成一个子查询.
与此同时,DARQ就开始讨论查询计划的生成.DARQ所使用的代价生成方法是System-R式动态规划[36]的变种.对于这种查询计划生成方式,最重要的就是如何估计代价.2个子查询连接有2种方式:1)嵌套循环连接,就是一般的自然连接;2)绑定式连接,就是一个子查询先找出解,然后将解传输到另一个子查询那里,最后将解绑定到第2个子查询那里进行过滤.
在DARQ的服务描述之外,还有Q-Tree[37]作为另一种用来确定子查询RDF数据源的索引.在Q-Tree[37]中,每个三元组中的主体、属性和客体都通过Hash函数映射到一个整数.于是,每个三元组都可以视为一个三维向量,进而视为一个三维空间上的点.然后,对这些三维空间上的点,系统构建一种类似于R-Tree的索引——Q-Tree.Q-Tree与R-Tree的不同体现于Q-Tree叶节点所存储的不是一个个项,而是项的数量以及相应RDF数据源.利用Q-Tree索引,系统将SPARQL查询中的每个查询语句都可以视为一个Q-Tree上的一个最小带界矩形框查询(minimum bounding boxes, MBB).于是,SPARQL查询转化为MBB的连接,进而得到每个查询三元组对应的RDF数据源;然后,系统就能将查询分解并分发到各个机器执行得到部分解;最后,系统收集这些部分解并连接成最终解.
Prasser等人[38]认为Q-Tree[37]虽好,但还是存在2个缺点:1)通过Hash函数将主体、属性和客体映射到整数的过程中,没有考虑类型信息;2)通过一般的Hash函数得到的候选三元组不够准确.针对第1个缺陷,Prasser等人发现哪怕不同数据源的RDF数据,相同类的资源会有相似的URI.于是,Prasser等人[38]对多个数据源的URI建立统一前缀树进而统一地编码,使得每个资源都有一个全局的类型信息.在针对第2个缺陷,在Q-Tree中每个叶节点除了记录所有三元组的数量以外,还记录一个LSB集合{(hash(ts) mod 216,hash(to) mod 216)|t=(ts,tp,to)是属于叶节点n的三元组}.利用这个集合,在查询执行过程中能极大地减少中间结果.
在上述方法外,还有SPLENDID[39],HiBISCuS[40]等方法.其中,SPLENDID根据每个数据源的VOID信息建立一个倒排索引.这个索引将每个属性和类型信息映射到一个数据对(d,c),其中d表示属性或类型信息所在的数据源,c表示在d这个数据源上属性或类型信息的数量.HiBISCuS[40]也构建了与DARQ类似的索引.只是,在确定各个子查询的相关RDF数据源阶段,HiBISCuS将查询图建模成一个有向带标签的超图,并利用这个有向带标签的超图进一步减少每个子查询的候选RDF数据源.
不同于上述利用索引来确定相关RDF数据源的方法,FedX[41]则可以在查询处理阶段实时确定相关数据源.当SPARQL查询输入以后,FedX[41]首先将查询中每个三元组模式都传到所有RDF数据源上并通过SPARQL查询语义中的ASK来确定相关数据源;之后,以三元组模式为单位进行查询优化,进而将若干三元组模式聚集在一起并得到连接操作顺序.连接操作顺序的计算方法也是System-R[36]的变种.FedX所使用的连接方式也是和DARQ相似的绑定式连接,但是FedX在传输中间结果时不再是一个一个传,而是若干个中间结果合在一起传.
此外,北京大学邹磊老师课题组[42]提出了一个基于“局部计算-再合并”的分布式RDF数据管理方法.这种方法也是不干预数据图本身已有的划分,即假设数据已经分布在不同的节点上.所谓局部计算(partial evaluation)最早提出并使用在编译优化问题上[43],局部计算将一个计算函数f的参数分成2部分:s和z,其中s是已知的部分,z是未知的部分.局部计算就是仅仅利用所有已知的部分s求出f的局部解.如前所述,我们的方法中假设数据已经划分在不同的计算节点上.每个机器将存储在自身的RDF数据视为已知的部分,而存储在其他机器上的RDF数据视为未知的部分.
系统中每台机器根据自身上所存储的RDF数据计算出整个SPARQL查询的局部匹配,所找出的局部匹配被定义为本地局部匹配;然后,所有被找出的本地局部匹配被归并起来并通过连接操作合并成最终匹配.图8给出了我们提出的分布式RDF数据管理方法的系统架构.

Fig. 8 Framework of the distributed RDF data management system based on partial evaluation[42]图8 基于局部计算的分布式RDF数据管理系统框架[42]
因为这个方法[42]框架是处理整个SPARQL查询而无需进行查询分解,所以这个方法是独立于数据划分的.而且根据这个方法的定义所找出的本地局部匹配能保证计算过程中系统所产生的中间结果涉及的点和边的数量是最少的.
此外,在本地局部匹配归并阶段,这个方法[42]提出了2种不同的归并方式:集中式归并和分布式归并.所谓集中式归并,就是将所有本地局部匹配收集到一台机器上进行连接以得到最终匹配,这种归并方式适用于所找出的本地局部匹配数量不多的情况;而所谓分布式归并,就是将本地局部匹配分配到不同机器上并基于BSP计算模型进行连接操作以得到最终匹配,这种归并方式适用于所找出的本地局部匹配数量很多的情况.
5 总 结
RDF三元组是目前知识图谱普遍采用的数据表示格式.总的来说,它与图数据的表示形式最为接近;但是不同点在于目前的图数据表示模型通常采用的是属性图方式,与RDF的三元组数据之间存在转换的问题.同时,在语义网的框架下,通过RDF Schema和OWL等语言,知识图谱数据具有一定的推理能力,这是目前的图数据模型所不具备的.
本文分类阐述了3类现有分布式RDF数据管理方法,这些方法本身是面向不同的应用场景,满足不同的应用需求而提出的.在分布式RDF数据管理层面,一些新的趋势包括在异构环境下的分布式RDF数据管理问题.例如在一个应用系统当中,存在着关系型数据、XML数据和知识图谱RDF数据,而一个查询可能涉及到这些多个数据库系统.在这样的异构分布式环境下的数据查询优化问题是一个开放性的研究课题,同时在传感器、社交网络等环境下的RDF数据管理问题包括多源且实时更新的特点,面对多源的流式的RDF数据管理也是分布式RDF数据管理的新挑战.
[1]Bönström V, Hinze A, Schweppe H. Storing RDF as a graph[C] //Proc of Latin American Web Congress. Piscataway, NJ: IEEE, 2003: 27-36
[2]Zou Lei, Mo Jinghui, Chen Lei, et al. An SPC-based forward-backward algorithm for arrhythmic beat detection and classification[J]. Proceedings of the VLDB Endowment, 2011, 4(8): 482-493
[3]Zou Lei, Özsu M T, Chen Lei, et al. gStore: A graph-based SPARQL query engine[J]. VLDB Journal, 2014, 23(4): 565-590
[4]Lehmann J, Isele R, Jakob M, et al. DBpedia—A large-scale, multilingual knowledge base extracted from Wikipedia[J]. Semantic Web, 2015, 6(2): 167-195
[5]Suchanek F M, Kasneci G, Weikum G. YAGO: A large ontology from Wikipedia and WordNet[J]. Journal of Web Semantics, 2008, 6(3): 203-217
[6]Hoffart J, Suchanek F M, Berberich K, et al. YAGO2: A spatially and temporally enhanced knowledge base from Wikipedia[J]. Artificial Intelligence, 2013, 194: 28-61
[7]Mahdisoltani F, Biega J, Suchanek F M. YAGO3: A knowledge base from multilingual Wikipedias[C]//Proc of the 7th Biennial Conf on Innovative Data Systems Research. New York: ACM, 2015: 1-11
[8]Pérez J, Arenas M, Gutierrez C. Semantics and complexity of SPARQL[J]. ACM Trans on Database Systems, 2009, 34(3): 16:1-16:45
[9]Apache. Hadoop[OL]. [2016-10-06]. https://hadoop.apache.org/
[10]Shao Bin, Wang Haixun, Li Yatao. Trinity: A distributed graph engine on a memory cloud[C] //Proc of the 2013 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2013: 505-516
[11]Rohloff K, Schantz R E. High-performance, massively scalable distributed systems using the MapReduce software framework: The SHARD triple-store[C] //Proc of SPLASH Workshop on Programming Support Innovations for Emerging Distributed Applications. New York: ACM, 2010: 4
[12]Husain M F, McGlothlin J P, Masud M M, et al. Heuristics-based query processing for large RDF graphs using cloud computing[J]. IEEE Trans on Knowledge and Data Engineering, 2011, 23(9): 1312-1327
[13]Zhang Xiaofei, Chen Lei, Wang Min. Towards efficient join processing over large RDF graph using MapReduce[C] //Proc of the 28th Int Conf on Scientific and Statistical Database Management. New York: ACM, 2012: 250-259
[14]Zhang Xiaofei, Chen Lei, Tong Yongxin, et al. EAGRE: Towards scalable I/O efficient SPARQL query evaluation on the cloud[C] //Proc of the 29th IEEE Int Conf on Data Engineering. Piscataway, NJ: IEEE, 2013: 565-576
[15]Papailiou N, Konstantinou I, Tsoumakos D, et al. H2RDF: Adaptive query processing on RDF data in the cloud[C] //Proc of the 21st Int World Wide Web Conf. New York: ACM, 2012: 397-400
[16]Papailiou N, Tsoumakos D, Konstantinou I, et al. H2RDF+: An efficient data management system for big RDF graphs[C] //Proc of the 2014 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2014: 909-912
[17]Zeng Kai, Yang Jiacheng, Wang Haixun, et al. A distributed graph engine for Web scale RDF data[J]. Proceedings of the VLDB Endowment, 2013, 6(4): 265-276
[18]Apache. Parquet[OL]. [2016-10-06]. http://parquet.apache.org/
[19]Schätzle A, Przyjaciel-Zablocki M, Neu A, et al. Sempala: Interactive SPARQL query processing on Hadoop[C] //Proc of the 13th Int Semantic Web Conf. New York: ACM, 2014: 164-179
[20]Apache. Spark[OL]. [2016-10-06]. http://spark.apache.org/
[21]Schätzle A, Przyjaciel-Zablocki M, Skilevic S, et al. S2RDF: RDF querying with SPARQL on Spark[J]. Proceedings of the VLDB Endowment, 2016, 9(10): 804-815
[22]Huang Jiewen, Abadi D J, Ren Kun. Scalable SPARQL querying of large RDF graphs[J]. Proceedings of the VLDB Endowment, 2011, 4(11): 1123-1134
[23]Karypis G, Kumar V. A fast and high quality multilevel scheme for partitioning irregular graphs[J]. SIAM Journal on Scientific Computing, 1998, 20(1): 359-392
[24]Hose K, Schenkel R. WARP: Workload-aware replication and partitioning for RDF[C] //Proc of the 29th IEEE Int Conf on Data Engineering. Piscataway, NJ: IEEE, 2013: 1-6
[25]Galárraga L, Hose K, Schenkel R. Partout: A distributed engine for efficient RDF processing[C] //Proc of the 23rd Int World Wide Web Conf. New York: ACM, 2014: 267-268
[26]Özsu M T, Valduriez P. Principles of Distributed Database Systems[M]. Berlin: Springer, 2011
[27]Yang Tao, Chen Jinchuan, Wang Xiaoyan, et al. Efficient SPARQL query evaluation via automatic data partitioning[C] //Proc of the 18th Int Conf on Database Systems for Advanced Applications. New York: ACM, 2013: 244-258
[28]Lee K, Liu Ling, Tang Yuzhe, et al. Efficient and customizable data partitioning framework for distributed big RDF data processing in the cloud[C] //Proc of the 6th Int Conf on Cloud Computing. Piscataway, NJ: IEEE, 2013: 327-334
[29]Lee K, Liu Ling. Scaling queries over big RDF graphs with semantic Hash partitioning[J]. Proceedings of the VLDB Endowment, 2013, 6(14): 1894-1905
[30]Gurajada S, Seufert S, Miliaraki I, et al. TriAD: A distributed shared-nothing RDF engine based on asynchronous message passing[C] //Proc of the ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2014: 289-300
[31]Wu Buwen, Zhou Yongluan, Yuan Pingpeng, et al. SemStore: A semantic-preserving distributed RDF triple store[C] //Proc of the 23rd ACM Int Conf on Information and Knowledge Management. New York: ACM, 2014: 509-518
[32]Wu Buwen, Zhou Yongluan, Yuan Pingpeng, et al. Scalable SPARQL querying using path partitioning[C] //Proc of the 31st IEEE Int Conf on Data Engineering. Piscataway, NJ: IEEE, 2015: 795-806
[33]Wylot M, Mauroux P. DiploCloud: Efficient and scalable management of RDF data in the cloud[J]. IEEE Trans on Knowledge and Data Engineering, 2016, 28(3): 659-674
[34]Peng Peng, Zou Lei, Chen Lei, et al. Workload-based RDF graph fragmentation and allocation[C] //Proc of the 19th Int Conf on Extending Database Technology. Konstanz, Germany: OpenProceedings.org, 2016: 377-388
[35]Quilitz B, Leser U. Querying distributed RDF data sources with SPARQL[C] //Proc of the 5th European Semantic Web Conf. New York: ACM, 2008: 524-538
[36]Astrahan M M, Blasgen H W, Chamberlin D D, et al. System R: Relational approach to database management[J]. ACM Trans on Database Systems, 1976, 1: 97-137
[37]Harth A, Hose K, Karnstedt M, et al. Data summaries for on-demand queries over linked data[C] //Proc of the 20th Int Conf on World Wide Web. New York: ACM, 2010: 411-420
[38]Prasser F, Kemper A, Kuhn K A. Efficient distributed query processing for autonomous RDF databases[C] //Proc of the 19th Int Conf on Extending Database Technology. Konstanz, Germany: OpenProceedings.org, 2012: 372-383
[39]Görlitz O, Staab S. SPLENDID: SPARQL endpoint federation exploiting VOID descriptions[C] //Proc of the 2nd Int Workshop on Consuming Linked Data. New York: ACM, 2011
[40]Saleem M, Ngomo A N. HiBISCuS: Hypergraph-based source selection for SPARQL endpoint federation[C] //Proc of the 11th European Semantic Web Conf. New York: ACM, 2014: 176-191
[41]Schwarte A, Haase P, Hose K, et al. FedX: Optimization techniques for federated query processing on linked data[C] //Proc of the 10th Int Semantic Web Conf. New York: ACM, 2011: 601-616
[42]Peng Peng, Zou Lei, Özsu M T, et al. Processing SPARQL queries over distributed RDF graphs[J]. VLDB Journal, 2016, 25(2): 243-268
[43]Jones N D. An introduction to partial evaluation[J]. ACM Computing Surveys, 1996, 28(3): 480-503

Zou Lei, born in 1981. PhD in computer science. Associate professor. His main research interests include graph data management and RDF data management.

Peng Peng, born in 1987. PhD in computer science. Assistant professor. His main research interests include RDF data mana-gement and distributed data management.
A Survey of Distributed RDF Data Management
Zou Lei1and Peng Peng2
1(InstituteofComputerScience&Technology,PekingUniversity,Beijing100080)2(CollegeofComputerScienceandElectronicEngineering,HunanUniversity,Changsha410082)
Recently, RDF (resource description framework) has been widely used to expose, share, and connect pieces of data on the Web, while SPARQL (simple protocol and RDF query language) is a structured query language to access RDF repository. As RDF datasets increase in size, evaluating SPARQL queries over current RDF repositories is beyond the capacity of a single machine. As a result, a high performance distributed RDF database system is needed to efficiently evaluate SPARQL queries. There are a huge number of works for distributed RDF data management following different approaches. In this paper we provide an overview of these works. This survey considers three kinds of distributed data management approaches, including cloud-based distributed data management approaches, partitioning-based distributed data management approaches and federated RDF systems. Simply speaking, cloud-based distributed data management approaches use existing cloud platforms to manage large RDF datasets; partitioning-based distributed data management approaches divide an RDF graph into several fragments and place each fragment at a different site in a distributed system; and federated RDF systems disallow for re-partitioning the data, since the data has been distributed over their own autonomous sites. In each kind of distributed data management approaches, further discussions are also provided to help readers to understand the characteristics of different approaches.
RDF data management; SPARQL query processing; distributed database system; cloud computing; linked data
2016-11-25;
2017-04-01
国家自然科学基金优秀青年科学基金项目(61622201) This work was supported by the National Natural Science Fundation of China for Excellent Young Scientists (61622201).
TP392
