面向标记分布学习的标记增强
2017-06-23邵瑞枫
耿 新 徐 宁 邵瑞枫
(东南大学计算机科学与工程学院 南京 211189) (计算机网络和信息集成教育部重点实验室(东南大学) 南京 211189) (软件新技术与产业化协同创新中心(南京大学) 南京 210093) (无线通信技术协同创新中心(东南大学) 南京 211189)
面向标记分布学习的标记增强
耿 新 徐 宁 邵瑞枫
(东南大学计算机科学与工程学院 南京 211189) (计算机网络和信息集成教育部重点实验室(东南大学) 南京 211189) (软件新技术与产业化协同创新中心(南京大学) 南京 210093) (无线通信技术协同创新中心(东南大学) 南京 211189)
(xgeng@seu.edu.cn)
(CollaborativeInnovationCenterofWirelessCommunicationsTechnology(SoutheastUniversity),Nanjing211189)
多标记学习(multi-label learning, MLL)任务处理一个示例对应多个标记的情况,其目标是学习一个从示例到相关标记集合的映射.在MLL中,现有方法一般都是采用均匀标记分布假设,也就是各个相关标记(正标记)对于示例的重要程度都被当作是相等的.然而,对于许多真实世界中的学习问题,不同相关标记的重要程度往往是不同的.为此,标记分布学习将不同标记的重要程度用标记分布来刻画,已经取得很好的效果.但是很多数据中却仅包含简单的逻辑标记而非标记分布.为解决这一问题,可以通过挖掘训练样本中蕴含的标记重要性差异信息,将逻辑标记转化为标记分布,进而通过标记分布学习有效地提升预测精度.上述将原始逻辑标记提升为标记分布的过程,定义为面向标记分布学习的标记增强.首次提出了标记增强这一概念,给出了标记增强的形式化定义,总结了现有的可以用于标记增强的算法,并进行了对比实验.实验结果表明:使用标记增强能够挖掘出数据中隐含的标记重要性差异信息,并有效地提升MLL的效果.
多标记学习;标记分布学习;标记增强;逻辑标记;标记分布
多标记学习(multi-label learning, MLL)可以处理一个示例对应多个标记的情况,其目标是学习一个多标记的分类器,将示例映射到与之相关的标记集合上[1-3].在过去的十余年间,MLL技术已经被广泛地应用于许多领域,例如文本[4]、图像[5]、语音[6]、视频[7]等的分类、识别和检索等,这些领域中的数据往往都含有丰富的语义,适合于用MLL来进行建模.
标记分布学习的出现使得从数据中学习比多标记更为丰富的语义成为可能,比如可以更精确地刻画与同一示例相关的多个标记的相对重要性差异等.事实上,Geng[8]曾经指出,单标记学习和MLL都可以看作标记分布学习的特例,这也就意味着标记分布学习是一个更为泛化的机器学习框架,在此框架内研究机器学习方法具有重要的理论和应用价值.然而,标记分布学习应用的基础是假设每个示例由一个涵盖所有标记重要程度的标记分布来标注,这一点在很多实际应用中往往无法满足.这些实际应用中的数据多数情况下由单标记或者多标记(均匀标记分布)标注,缺乏完整的标记分布信息.尽管如此,这些数据中的监督信息本质上却是遵循某种标记分布的.这种标记分布虽然没有显式给出,却常常隐式地蕴含于训练样本中.如果能够通过合适的方法将其恢复出来,则可以真正发挥标记分布学习挖掘更多语义信息的优势.
基于上述考虑,本文提出的面向标记分布学习的标记增强是指将训练样本中的原始逻辑标记转化为标记分布的过程,这一过程依赖于对隐藏在训练样本中的标记相关信息的挖掘.假设Y表示样本的原始逻辑标记空间,D表示经过标记增强后的标记分布空间,那么,标记增强方法将原始的标记空间Y={0,1}c拓展为D=[0,1]c,其中c表示标记的个数.事实上,D构成c维欧氏空间中的一个超立方体,而Y仅位于该超立方体的顶点.标记增强利用隐含于数据中的标记间相关性,可以有效加强示例的监督信息,进而通过标记分布学习获得更好的预测效果.
尽管现有文献中并未明确提出过标记增强的概念,但是许多工作中实际上已经涉及了一些与之相关的方法.例如:在头部姿态估计问题中,文献[9-10]依靠对数据的先验知识,直接假设每个示例的标记分布为高斯分布;文献[11-12]用图模型表示示例间的拓扑结构,通过加入一些模型假设,建立示例间相关性与标记间相关性之间的关系,进而将示例的逻辑标记增强为标记分布;文献[13-16]从训练样本中生成示例对每个标记的模糊隶属度,从而可以将原有的逻辑标记增强为标记分布.上述工作有些是直接为标记分布学习而提出的,有些则是在其他领域提出但可以用来生成标记分布.不管哪种情况,它们都可以统一到同一个概念下,即本文提出的面向标记分布学习的标记增强.
1 符号及形式化定义
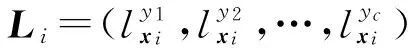
给定训练集S={(xi,Li)|1≤i≤n},标记增强即根据S中蕴含的标记间相关性,将每个示例xi的逻辑标记Li转化为相应的标记分布Di,从而得到标记分布训练集E={(xi,Di)|1≤i≤n}的过程.
2 标记增强方法
在标记分布学习这一概念提出之后,陆续有文献提出了一些面向标记分布学习的标记增强方法.这些研究有的利用了具体应用中的先验知识,如头部姿态和人脸年龄的先验分布[9-10];有的使用了半监督学习[17]中常用的标记传播方法[11];也有的引入了流形学习[12],均取得了不错的结果.而事实上,在标记分布学习概念提出之前,其他领域也已经出现了一些方法,尽管它们的应用背景和具体目标不尽相同,但是放到标记分布学习的框架之中,却可以用于实现标记增强,经典的如模糊聚类[13]、核隶属度[14]等.
本文将现有的标记增强算法分为3种类型,分别是基于先验知识的标记增强、基于模糊方法的标记增强和基于图模型的标记增强.下面分别阐述这3种类型中典型的标记增强算法.
2.1 基于先验知识的标记增强
基于先验知识的标记增强算法建立在对数据本身特点有较为深入理解的基础之上,完全依靠先验知识直接将逻辑标记增强为标记分布,或者部分引入先验知识,在此基础上通过挖掘隐含的标记间相关性将逻辑标记增强为标记分布.本节介绍2种基于先验知识的标记增强算法,分别是基于先验分布的标记增强算法和基于自适应先验分布的标记增强算法.
2.1.1 基于先验分布的标记增强
在某些特定的应用中,人们根据对数据的了解,可以预先知道每个示例应满足的标记分布的参数模型,这种含参标记分布模型就称为先验分布.一旦利用逻辑标记以及一些启发式方法确定了这种模型中的参数,就可以为每个示例生成相应的标记分布.
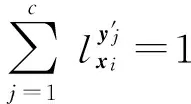
(1)
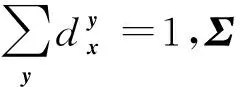
基于先验分布的标记增强算法一般在假设一个先验分布的前提下,利用逻辑标记以及一些启发式方法确定先验分布的参数,直接将示例xi的逻辑标记Li转化为相应的标记分布Di,从而得到标记分布训练集E={(xi,Di)|1≤i≤n}.这类方法依赖于算法设计者对数据本身的深入理解.如果这种理解与事实相符则可能获得不错的效果,并且实现起来方便高效.然而,一旦对数据的理解有所偏差,则标记增强后的结果往往并不理想.
2.1.2 基于自适应先验分布的标记增强
如前所述,2.1.1节中的标记增强算法完全依靠先验知识直接将逻辑标记增强为标记分布.这一做法过于依赖先验知识,在许多对数据的了解不够充分的情况下,其生成的标记分布不一定能够真实反映数据本身的特点.为了解决上述问题,Geng等人[10]以人脸年龄估计为应用背景,在引入先验分布的前提下,通过自适应方法确定先验分布中的参数,从而将每个示例xi的逻辑标记Li转化为相应的标记分布Di.
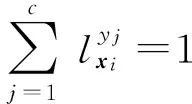
(2)
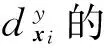
基于自适应先验分布的标记增强算法部分引入先验知识,通过自适应的方法,从训练样本中学习得到先验分布的参数,进而将每个示例xi的逻辑标记Li转化为相应的标记分布Di.这类方法部分依赖先验知识,部分依赖从样例中学习,因此相较2.1.1节中完全依赖先验知识的方法更能有效利用隐藏在训练数据中的标记间相关性.正如文献[10]中的实验所报告的结果,一般情况下,基于自适应先验分布的标记增强算法效果要优于完全依赖先验分布的标记增强算法.
2.2 基于模糊方法的标记增强
基于模糊方法的标记增强[13-16]利用模糊数学的思想,通过模糊聚类、模糊运算和核隶属度等方法,挖掘出标记间相关信息,将逻辑标记转化为标记分布.值得注意的是,这类方法提出的目的一般是为了将模糊性引入原本刚性的逻辑标记,而并未明确其可以将逻辑标记增强为标记分布.但是,很多模糊标记增强方法实际上可以基于模糊隶属度轻松生成标记分布.
本节介绍2种基于模糊方法的标记增强算法,分别是基于模糊聚类的标记增强算法和基于核隶属度的标记增强算法.
2.2.1 基于模糊聚类的标记增强
基于模糊聚类的标记增强[13]通过模糊C-均值聚类(fuzzy c-means algorithm, FCM)[18]和模糊运算,将训练集S中每个示例xi的逻辑标记Li转化为相应的标记分布Di,从而得到标记分布训练集E={(xi,Di)|1≤i≤n}.
模糊C-均值聚类(FCM)是用隶属度确定每个数据点属于某个聚类程度的一种聚类算法.FCM把n个样本分为p个模糊聚类,并求每个聚类的中心,使得所有训练样本到聚类中心的加权(权值由样本点对相应聚类的隶属度决定)距离之和最小.假设FCM将训练集S分成p个聚类,μk表示第k个聚类的中心,则可用:
(3)
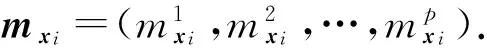
(4)
即Aj为所有属于第j个类的样本的隶属度向量之和.经过行归一化后得到的矩阵A可以被当作一个“模糊关系”矩阵,A中的元素Ajk表示了第j个类别(标记)与第k个聚类的关联强度.

Vi=A∘mxi,
(5)
其中,∘表示模糊数学中的合成算子.最后,对隶属度向量Vi进行归一化,使向量中元素的和为1,即得到标记分布Di.
基于模糊聚类的标记增强算法利用模糊聚类过程中产生的示例对每个聚类的隶属度,通过类别和聚类的关联矩阵,将示例对聚类的隶属度转化为对类别的隶属度,从而生成标记分布.在这一过程中,模糊聚类反映了示例空间的拓扑关系,而通过关联矩阵将这种关系转化到标记空间,从而有可能使得简单的逻辑标记产生更丰富的语义,转变为标记分布.
2.2.2 基于核隶属度的标记增强
该标记增强方法源于一种模糊支持向量机中核隶属度的生成过程[14],通过一个非线性映射函数将示例xi映射到高维空间,利用核函数计算该高维空间中正负类的中心、半径和各示例xi到类别中心的距离,进而通过隶属度函数计算示例xi的标记分布.

φ(xi),
(6)
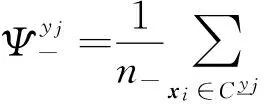
(7)
其中,φ(xi)是一个非线性映射函数,由核函数K(xi,xj)=φ(xi)×φ(xj)确定.正类和负类的半径分别计算为
(8)
(9)
样本xi到正类和负类中心的平方距离分别是:
(10)
(11)
则示例xi对于标记yj的隶属度为
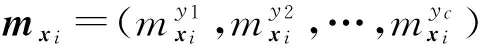
基于核隶属度的标记增强算法利用核技巧在高维空间中计算示例对每个类别的隶属度,从而能够挖掘训练数据中类别标记间较为复杂的非线性系.
2.3 基于图模型的标记增强
基于图模型的标记增强算法用图模型表示示例间的拓扑结构,通过引入一些模型假设,建立示例间相关性与标记间相关性之间的关系,进而将示例的逻辑标记增强为标记分布.本节介绍2种基于图模型的标记增强算法,分别是基于标记传播的标记增强算法和基于流形的标记增强算法.
2.3.1 基于标记传播的标记增强
文献[11]将半监督学习[17]中的标记传播技术应用于标记增强中.该方法首先根据示例间相似度构建一个图,然后根据图中的拓扑关系在示例间传播标记,由于标记的传播会受到路径上权值的影响,会自然形成不同标记的描述度差异,当标记传播收敛时,每个示例的原有逻辑标记即可增强为标记分布.
具体地,假设多标记训练集S={(xi,Li)|1≤i≤n},G=(V,E,W)表示以S中的示例为顶点的全连通图,其中V={xi|1≤i≤n}表示顶点,E表示顶点两两之间的边,xi与xj之间的边上的权值为它们之间的相似度:
(13)
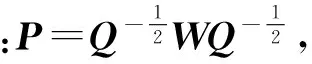
F(t)=αPF(t-1)+(1-α)Φ,
(14)
其中,α是平衡参数,控制了初始的逻辑标记和标记传播对最终描述度的影响程度.经过迭代,最终F收敛到:F*=(1-α)(I-αP)-1Φ,对F*做归一化处理:
(15)
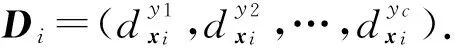
基于标记传播的标记增强算法通过图模型表示示例间的拓扑结构,构造了基于示例间相关性的标记传播矩阵,利用传播过程中路径权值的不同使得不同标记的描述度自然产生差异,从而反映出蕴含在训练数据中的标记间关系.
2.3.2 基于流形的标记增强
基于流形的标记增强算法[12]假设数据在特征空间和标记空间均分布在某种流形上,并利用平滑假设将2个空间的流形联系起来,从而可以利用特征空间流形的拓扑关系指导标记空间流形的构建,在此基础上将示例的逻辑标记增强为标记分布.
具体地,该算法用图G=(V,E,W)表示多标记训练集S的特征空间的拓扑结构,其中V是由示例构成的顶点集合,E是边的集合,W=(wij)n×n是图的边权重矩阵.首先,在特征空间中,假设示例分布的流形满足局部线性,即任意示例xi可以由它的K-近邻的线性组合重构,重构权值矩阵W可通过最小化得到:
s.t.wij=0,xj不是xi的K-近邻,
(16)
其中,Wi表示W的第i行,1T表示全部由1构成的向量.通过平滑假设[19],即特征相似的示例的标记也很可能相似,可将特征空间的拓扑结构迁移到标记空间中,即共享同样的局部线性重构权值矩阵W.这样,标记空间的标记分布可由最小化得到:
(17)
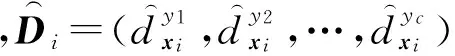
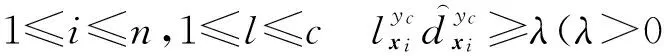
(18)
基于流形的方法通过重构特征空间和标记空间的流形,利用平滑假设将特征空间的拓扑关系迁移到标记空间中,建立示例间相关性与标记间相关性之间的关系,从而将逻辑标记增强为标记分布.
2.4 小结与比较
本节简要介绍了现存的3类可用于实现标记增强的方法,分别是基于先验知识的标记增强、基于模糊方法的标记增强和基于图模型的标记增强,每一类方法分别介绍了几种典型的实现算法.这些算法有些是专门为了将逻辑标记增强为标记分布而提出的,如基于先验知识的标记增强方法和基于图模型的标记增强方法;有些则是源于其他领域的工作,但可以借用到本文语境中实现标记增强,如基于模糊方法的标记增强.这些不同的增强方法,或者通过先验知识,或者通过从样本中学习来获得额外的监督信息,从而将训练样本原有的简单逻辑标记转化为信息量更为丰富的标记分布.综合来看,对于不同类型的标记增强算法,其优点和缺点总结如下:
1) 基于先验知识的标记增强.优点:在对数据有比较深入理解的前提下,可以充分利用先验知识,快速高效地实现标记增强;缺点:过于依赖先验知识,在缺乏关于数据的领域知识的情况下无法应用此类方法.
2) 基于模糊方法的标记增强.优点:利用模糊隶属度,将标记间相关信息与逻辑标记融合,不需要建立精确的数学模型,有较强的鲁棒性,数据和参数等对算法影响较小;缺点:缺乏深度挖掘标记空间和特征空间信息的明确模型,往往难以生成符合特定数据特点的标记分布.
3) 基于图模型的标记增强.优点:充分利用特征空间的拓扑关系来指导标记空间相关性信息挖掘,有良好的数学基础,有利于形成适合数据本身特点的标记增强算法;缺点:模型较为复杂,数据和参数对算法的影响较大.
3 实 验
本节实验在不同数据集上测试了第2节提到的3种代表性的标记增强算法.由于基于先验知识的标记增强方法依赖于对数据本身的深入理解,只有在特定数据集上才能应用,因此这类算法这里不作比较.
实验主要分为2个部分:
1) 在一个人造数据集上测试所有对比算法由逻辑标记增强为标记分布的精度;
2) 在11个多标记数据集上,将基于标记增强的标记分布学习算法与主流的MLL算法进行对比.
3.1 实验设置
3.1.1 数据集
实验中共使用了12个数据集,包括1个人造数据集和11个真实世界的多标记数据集.

(19)
(20)
(21)
(22)
(23)
(24)
这样共生成2 601个分布于三维特征空间流形上的示例,每个示例对应的真实标记分布D由式(19)~(23)产生.

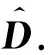
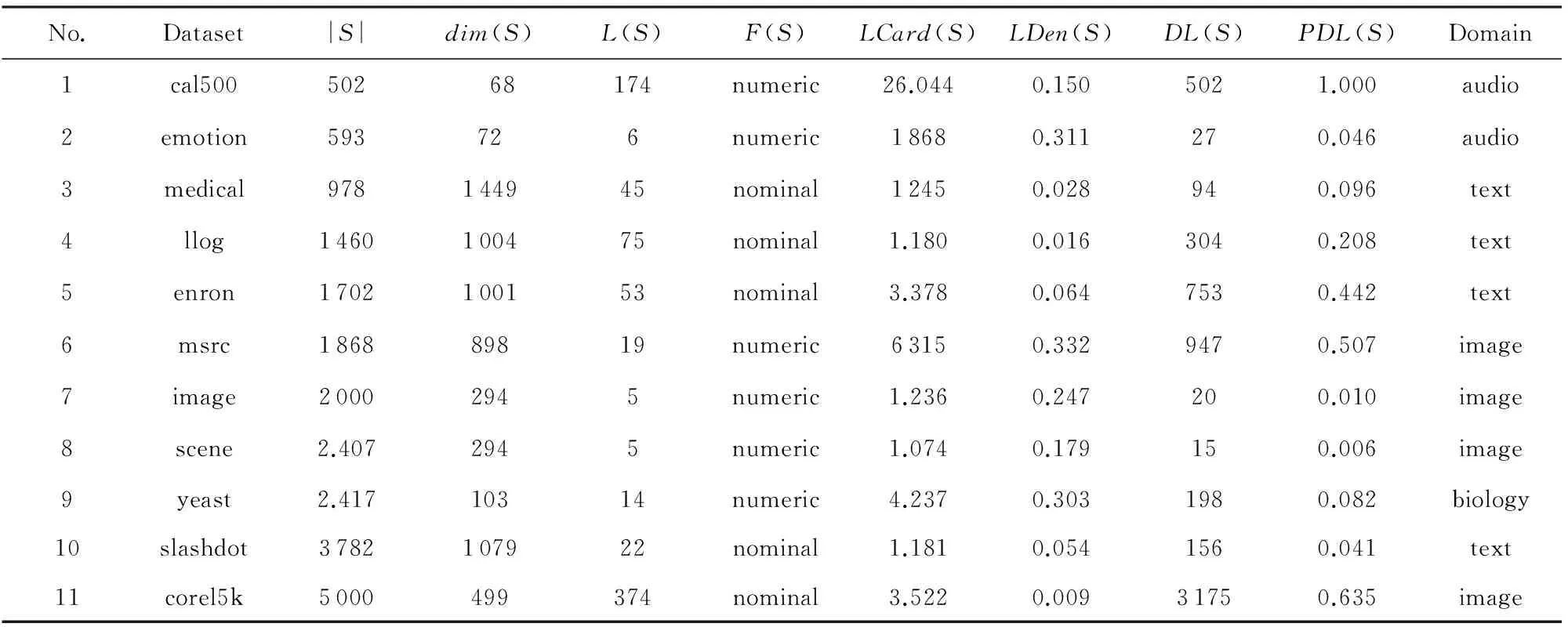
Table 1 Attributes of the Benchmark Multi-label Data Sets表1 基准多标记数据集属性
实验第2部分使用11个基准多标记数据集*http://meka.sourceforge.net/#datasets和http://mulan.sourceforge.net/datasets.html,这些数据集均来自真实应用场景,在本实验中用于比较基于标记增强的MLL与传统MLL算法.表1总结了这些数据集的各种属性.其中,|S|,dim(S),L(S)和F(S)分别表示数据集的样本数目、特征维度、类别标记数目和特征类型.另外还有一些关于多标记数据的统计指标[20],包括标记基数LCard(S)、标记密度LDen(S)、独特标记集合DL(S)和独特标记集合占比PDL(S).
3.1.2 对比算法
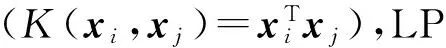
实验的第1部分在人造数据集上直接对比4种标记增强算法生成的标记分布与真实标记分布相比的相似程度.第2部分在11个多标记数据集上对比基于标记增强的MLL和传统的MLL算法.所谓基于标记增强的MLL是指先分别用4种标记增强算法将数据集中原有的逻辑标记增强为标记分布;然后用标记分布学习算法SA-BFGS[8]为从示例到标记分布的映射建模;最后在测试时,用3.1.1节介绍的二值化方法将预测出的标记分布转化为逻辑标记.
用于对比的传统MLL算法包括4种MLL领域的主流算法,分别为binary relevance(BR)[21],calibrated label ranking(CLR)[22],ensemble of classifier chains (ECC)[20]和RAndom K-labELsets (RAKEL)[23].这4种算法都在MULAN MLL包[24]上运行,基分类器为logistic regression模型,ECC全体尺度设置为30,RAKEL的全体尺度设置为2c且K=3.
3.1.3 评价指标

Table 2 Evaluation Measures for Label Enhancement Algorithms
Notes: “↓” indicates the smaller the better, and “↑” indicates the larger the better.
将标记增强算法与传统的MLL方法比较时,我们使用了在MLL中常用的5种评价指标,分别是Hamming-loss,One-error,Coverage,Ranking-loss和Average-precision[25].
3.2 实验结果
3.2.1 标记分布比较实验
为了直观可视化标记增强的效果,假设人造数据集中标记分布的3个分量分别对应RGB颜色空间的3个颜色通道.这样,每个示例的标记分布就可以用示例空间中点的颜色来直观表示.根据3.1.1节描述的人造数据采样方法可知,2 601个样本点分布在三维示例空间的一个流形上.因此,通过比较这个流形上的颜色模式即可直观判断不同算法标记增强的效果.图1显示了人造数据集上的真实标记分布(图1(a))以及4种标记增强算法得到的标记分布(图1(b)~1(e)).为了方便观察,图1中对流形上的颜色应用了去相关拉伸(decorrelation stretch)技术来增强颜色对比度.由图1可以看出,LP算法标记增强后的颜色模式非常接近真实标记分布,KM算法和ML算法记增强后的颜色模式也与真实标记分布相似,FCM算法的颜色模式和真实值差距较大.
进一步,我们对4种标记增强算法在人造数据集上的表现进行了定量分析.表3给出了4种标记增强算法在表2所示的6种评价指标上的比较结果,每个结果后的括号中给出了相应算法的排序,并且统计了每种算法在所有指标上的平均排序.表3中的结果与图1的可视化比较结果一致,即根据平均排序:LP≻KM≻ML≻FCM.LP算法的表现最好,因为该算法在保留了原始的逻辑标记的前提下,使用示例间相关信息对逻辑标记进行了增强;KM算法使用了模糊方法,不会对增强后的标记分布引入过多的误差,因此该算法也能够得到较为不错的结果;ML算法使用了流形模型,将示例间的相关信息与标记相关信息建立了联系,但使用的约束项不能够保留较多的原始逻辑信息,因此标记增强效果与KM算法接近;FCM算法的标记分布生成中使用了简单的模糊合成运算,不能有效地挖掘标记相关信息,因此标记增强的效果较差.

Fig. Visual comparison between the tabel distributions generated by the label anhancement algorithms and the groun-truth label distributions
图1 标记增强算法生成的标记分布与真实标记分布的可视化对比
Table3 Quantitative Comparison Between the Label Distributions Generated by the Label Enhancement Algorithms and the Ground-truth Label Distributions
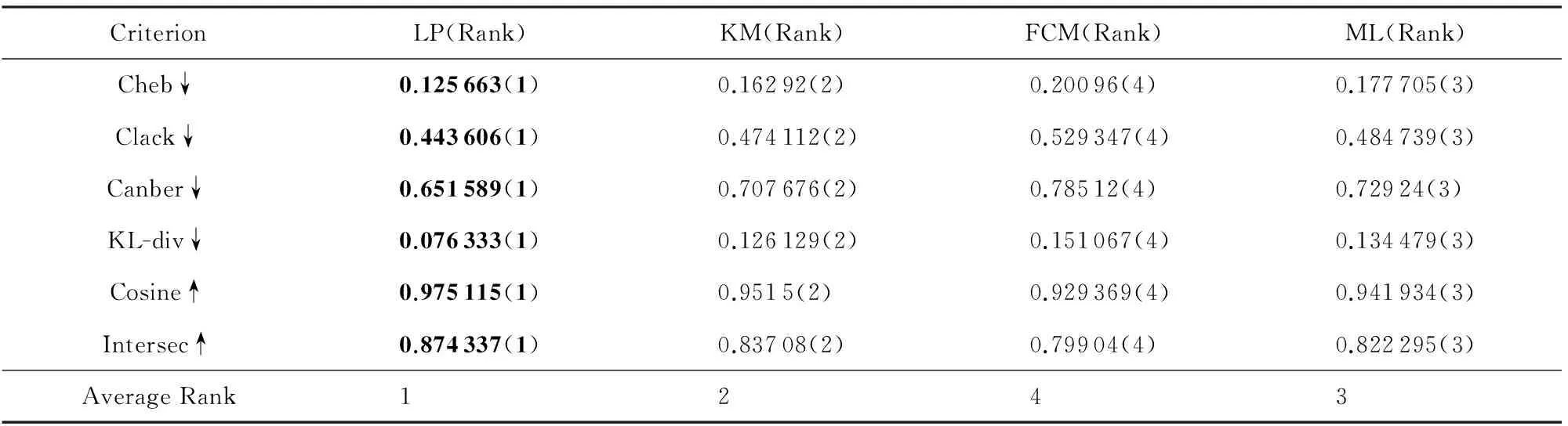
表3 标记增强算法生成的标记分布与真实标记分布的定量对比
Notes:“↓” indicates the smaller the better, and “↑” indicates the larger the better.
3.2.2 MLL比较实验
实验的第2部分在11个真实世界的多标记数据集上比较基于标记增强的MLL与传统MLL算法.在每个数据集上采用10倍交叉验证,记录每个算法分别在5个MLL评价指标上的平均值,结果如表4~8所示.其中,评价指标后的“↓”表示“越低越好”,“↑”表示“越高越好”.在每种指标和每个数据集上表现最好的算法的结果用黑体表示.算法在每种指标和每个数据集上的排序显示在其结果后的括号中,并统计了每种算法在所有数据集上的平均排序.

Table 4 Comparison of Multi-label Learning Algorithms on Ranking-loss↓ (mean±std)表4 MLL算法在Ranking-loss↓指标(均值±标准差)上的比较
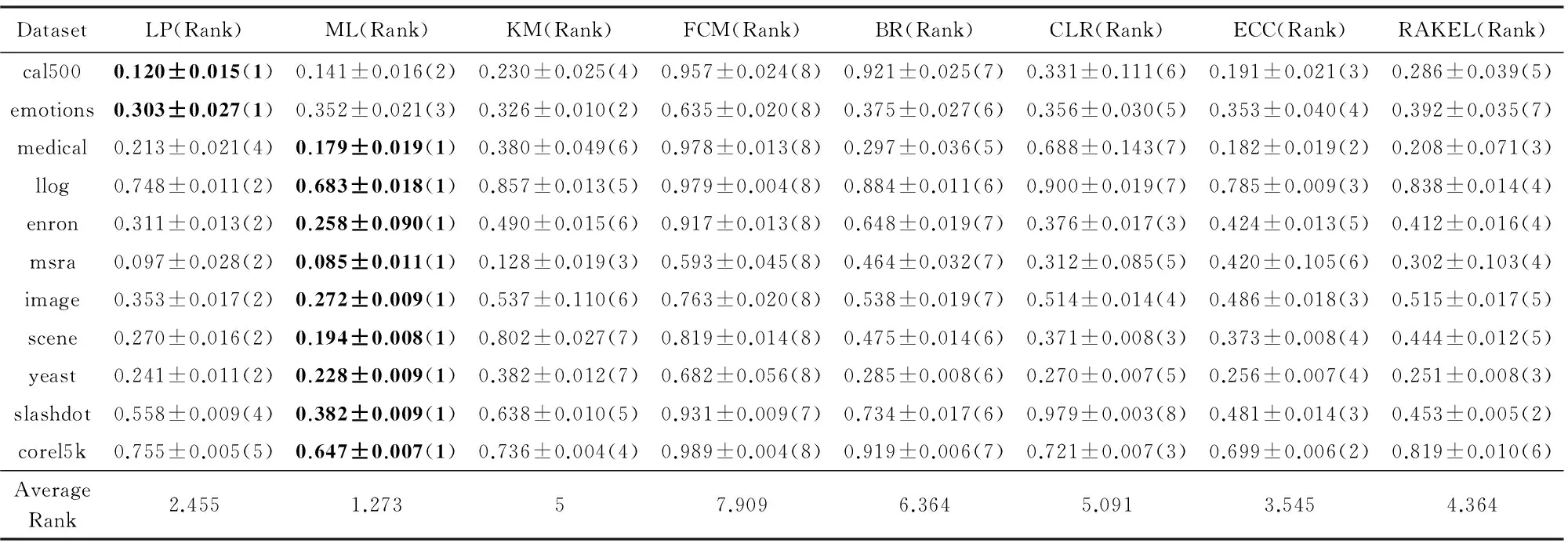
Table 5 Comparison of Multi-label Learning Algorithms on One-error↓ (mean±std)表5 MLL算法在One-error↓指标(均值±标准差)上的比较

Table 6 Comparison of Multi-label Learning Algorithms on Hamming-loss↓ (mean±std)表6 MLL算法在Hamming-loss↓指标(均值±标准差)上的比较
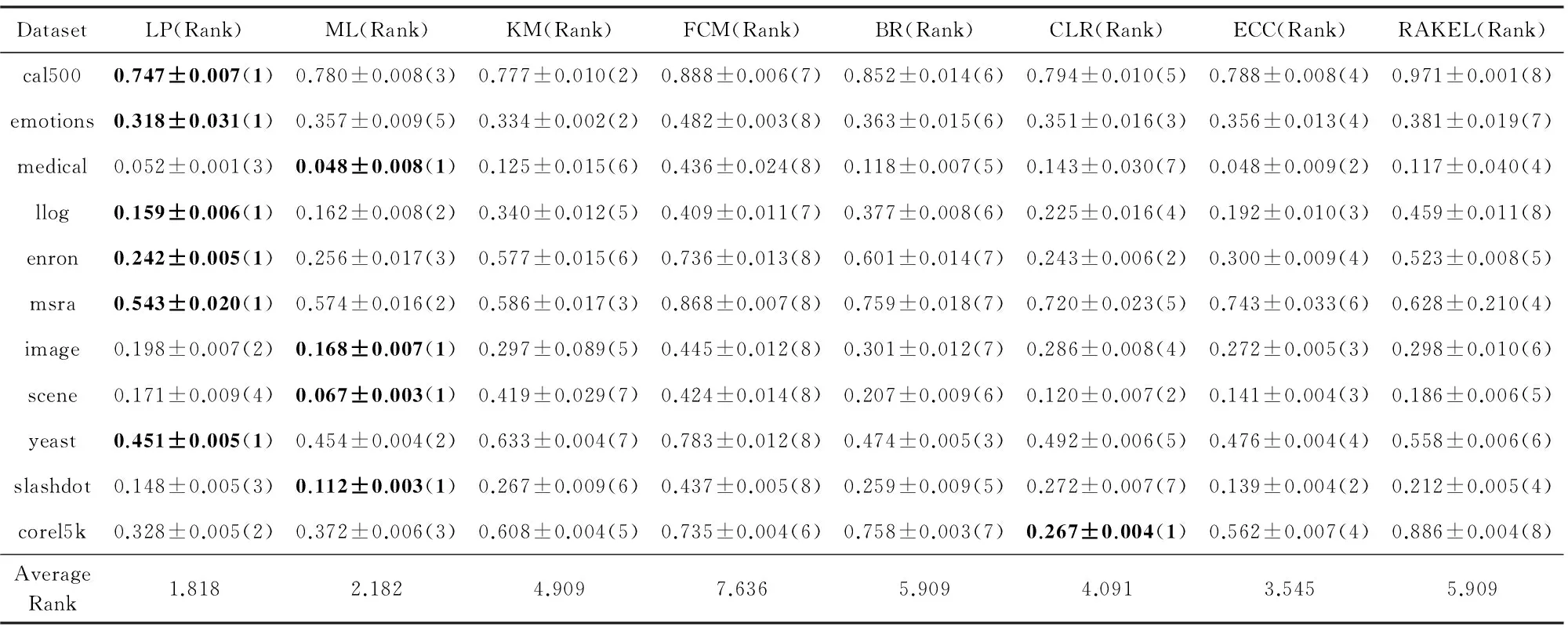
Table 7 Comparison of Multi-label Learning Algorithms on Coverage↓ (mean±std)表7 MLL算法在Coverage↓指标(均值±标准差)上的比较
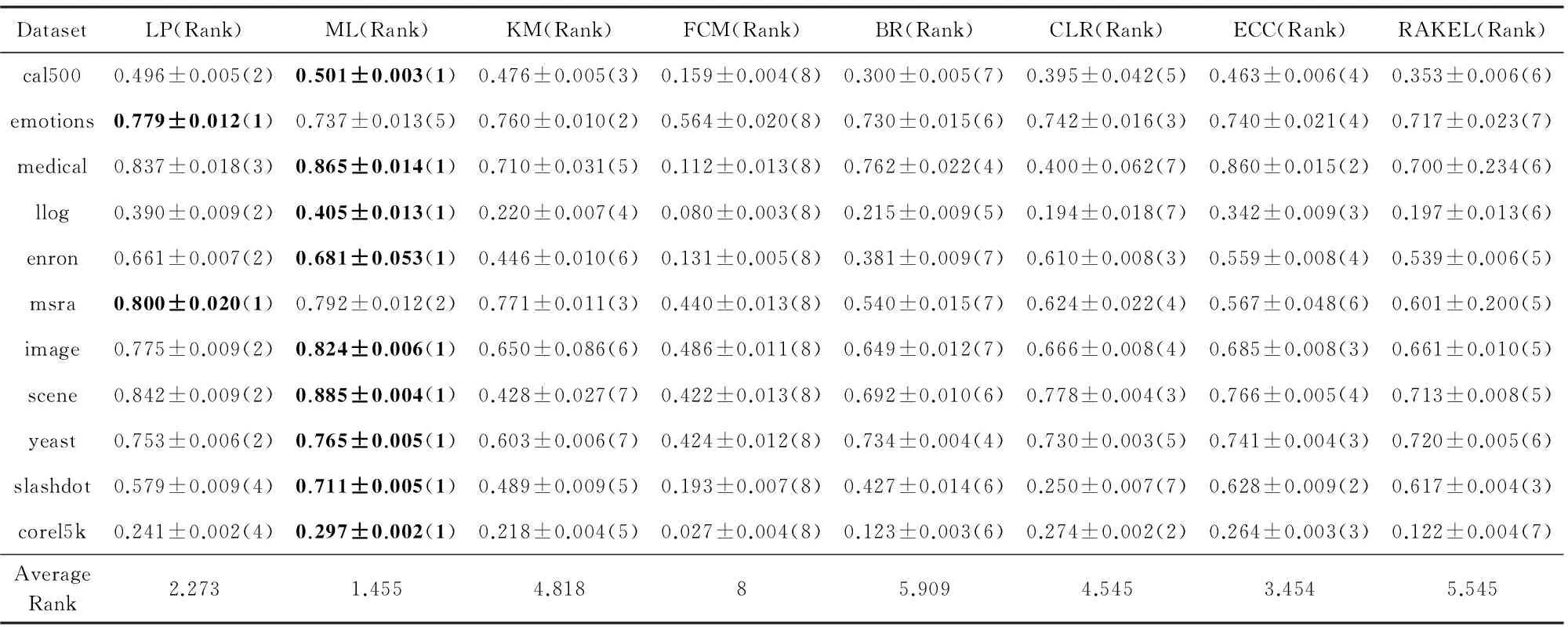
Table 8 Comparison of Multi-label Learning Algorithms on Average-precision↑ (mean±std)表8 MLL算法在Average-precision↑指标(均值±标准差)上的比较
为了从统计意义上比较8种算法在11个数据集上的表现,这里采用一种由Demšar[26]提出的两步统计假设检验法.该方法首先对原假设“所有算法的平均排序是一样的”应用Friedman检验.表9给出了在显著水平为0.05、对比算法数为8、数据集数为11时,各个评价指标上的Friedman统计值FF及关键值(critical value).可以看出,所有指标上的FF值均大于关键值,因此在所有指标上都可以拒绝原假设,即在每个指标上所有算法的平均排序不是都一样的.在此基础上,该方法第2步用Nemenyi检验来检验算法两两之间的平均排序比较,结果可用如图2所示的CD(critical difference)图来表示.Nemenyi检验在显著水平为0.05、对比算法数为8、数据集数为11时,CD=2.809 6.在CD图中,每个算法的平均排序被标注在同一条坐标轴上.如果2个算法的平均排序之差小于CD值,则说明两者没有显著差异,在CD图中即将这2个算法用一条线段连起来.
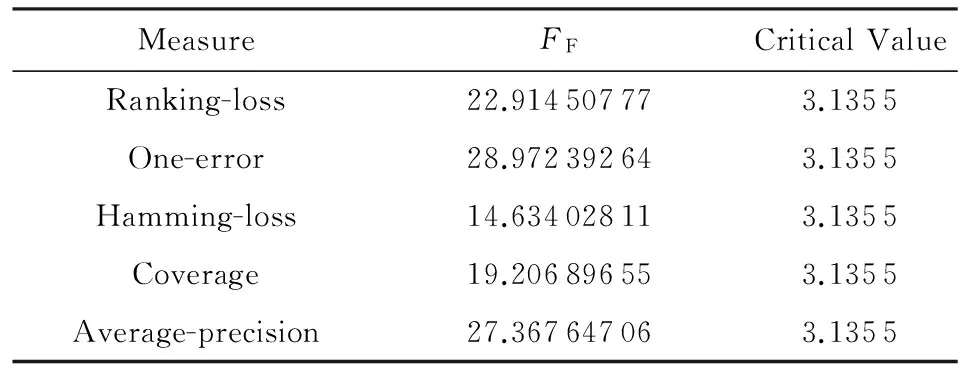
Table 9 Friedman Statistics on Each Evaluation Measure表9 各种评价指标上的Friedman统计值
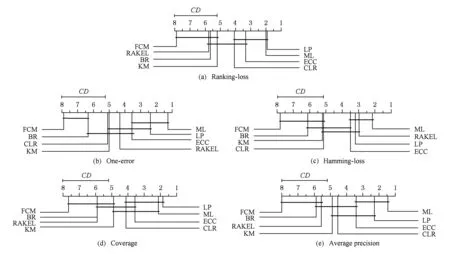
Fig. 2 CD diagrams (CD=2.809 6) of the Nemenyi tests on the eight algorithms for the five evaluation measures图2 在5个不同评价指标上对8种算法对比应用Nemenyi检验的CD图
基于表4~8和图2中的实验结果,我们可以得出以下8条结论:
1) 总体上,4种标记增强算法排名大致为LP≅ML≻KM≻FCM.
2) 在Ranking-loss(图2(a))和Coverage(图2(d))指标上,LP的平均排序是最小的(最优的).
3) 在One-error(图2(b))、Hamming-loss(图2(c))和Average precision(图2(e))指标上,ML的平均排序是最小的(最优的).
4) 在5种评价指标中,ML和LP并没有显著差异,而且这2种标记增强算法都显著地优于MLL算法BR.
5) 在One-error和Average precision指标上,ML显著地优于MLL算法BR,CLR和RAKEL.
6) 在Ranking-loss,Coverage和Average precision指标上,LP显著优于MLL算法BR和RAKEL.
7) 在5种指标上,KM优于BR,且KM与ECC,CLR,RAKEL没有显著的差异.
8) 4种标记增强方法中,FCM平均排序是最差的,但与BR没有显著差异.
对比3.2.1节中的实验结果,ML在第2部分实验的表现好于KM主要是因为这里采用的数据集的标记空间维度(标记个数)明显高于3.2.1节中所采用的人造数据集.这时,KM中对标记逐个处理的手法自然使得其在标记个数较多时表现不佳.另外,总体来看,基于图模型的标记增强(LP和ML)平均性能要优于基于模糊方法的标记增强(KM和FCM),这主要是因为KM和FCM都并非为了面向标记分布的标记增强而专门设计,因此一些非针对性的做法,如模糊操作的简单运用或者对不同标记的逐个处理使得这类方法直接用于标记增强效果并不理想.当然,在一些特殊情况下,如标记个数比较少时,模糊方法也可能取得不错的表现.例如,在人造数据集上KM的表现就要优于ML.
综上,可以认为,一方面,有效的标记增强(如LP和ML算法)能够显著提升传统MLL的效果.这说明标记增强确实有助于挖掘蕴含在训练样本中的标记间相关信息;另一方面,由于KM和FCM算法并非为标记分布专门设计,所以标记增强的效果并不理想,这也说明了针对面向标记分布的标记增强进行专门研究的必要性.
4 结 论
本文提出了面向标记分布的标记增强这一新概念.这类方法可以从训练样本中挖掘隐藏的标记间相关性信息,将样本中原有的简单逻辑标记增强为包含更多监督信息的标记分布,从而为后续的机器学习过程提供了更多可用信息.
本文综述了可用于面向标记分布的标记增强方法.它们有些是专门为标记分布学习提出的增强方法,有些则是在其他领域(如模糊分类)提出,但可以用于实现标记增强.本文进一步通过在1个人造数据集和11个真实世界的多标记数据集上的实验,比较了已有标记增强算法的表现,显示了标记增强方法的优势.实验结果表明,建立在良好标记增强基础上的MLL算法能够取得比建立在逻辑标记基础上的传统MLL算法更好的表现,这也说明了对标记增强方法进一步深入研究的必要性.未来在标记增强方面的研究至少包括3点重要内容:
1) 建立可用于标记增强实验的标准数据集.目前适合于标记增强算法实验的数据集还非常少,本文不得不借助人造数据或者多标记数据集来进行初步实验.而适合于标记增强的专门数据集中应包括真实的标记分布以及对应的逻辑标记.
2) 建立标记增强算法的性能评价体系.该评价体系应能全面反映算法从简单逻辑标记恢复真实标记分布的能力.
3) 提出能够充分利用标记间相关性的标记增强算法.标记间相关性既可以体现在标记空间,也可能从示例空间迁移而来,这方面不论是理论层面还是应用层面都还有很大的研究空间.
[1]Gibaja E, Ventura S. A tutorial on multilabel larning[J]. ACM Computing Surveys, 2015, 47(3): 1-38
[2]Tsoumakas G, Katakis I, Vlahavas I. Mining multi-label data[G]//Data Mining and Knowledge Discovery Handbook. Berlin: Springer, 2009: 667-685
[3]Zhang Minling, Zhou Zhihua. A review on multi-Label learning algorithms[J]. IEEE Trans on Knowledge & Data Engineering, 2014, 26(8): 1819-1837
[4]Rubin N T, Chambers A, Smyth P, et al. Statistical topic models for multi-label document classification[J]. Machine Learning, 2012, 88(1): 157-208
[5]Cabral S R, Torre F D, Costeira P J, et al. Matrix completion for multi-label image classification[C] //Proc of NIPS 2011. Cambridge, MA: MIT Press, 2011: 190-198
[6]Lo H Y, Wang J C, Wang H M, et al. Cost-sensitive multi-Label learning for audio tag annotation and retrieval[J]. IEEE Trans on Multimedia, 2011, 13(3): 518-529
[7]Wang Jingdong, Zhao Yinghai, Wu Xiuqing, et al. A transductive multi-label learning approach for video concept detection[J]. Pattern Recognition, 2011, 44(10/11): 2274-2286
[8]Geng Xin. Label distribution learning[J]. IEEE Trans on Knowledge and Data Engineering, 2016, 28(7): 1734-1748
[9]Geng Xin, Xia Yu. Head pose estimation based on multivariate label distribution[C] //Proc of IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2014: 3742-3747
[10]Geng Xin, Wang Qin, Xia Yu. Facial age estimation by adaptive label distribution learning[C] //Proc of the 22nd Int Conf on Pattern Recognition. Piscataway, NJ: IEEE, 2014: 4465-4470
[11]Li Yukun, Zhang Minling, Geng Xin. Leveraging implicit relative labeling-importance information for effective multi-label learning[C] //Proc of IEEE Int Conf on Data Mining. Piscataway, NJ, IEEE, 2015: 251-260
[12]Hou Peng, Geng Xin, Zhang Minling. Multi-label manifold learning[C] //Proc of the 30th AAAI Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2016: 1680-1686
[13]Gayar N E, Schwenker F, Palm G. A study of the robustness of KNN classifiers trained using soft labels[C] //Proc of the 2nd Conf Artificial Neural Networks in Pattern Recognition. Berlin: Springer, 2006: 67-80
[14]Jiang Xiufeng, Yi Zhang, Lv Jiancheng. Fuzzy SVM with a new fuzzy membership function[J]. Neural Computing & Applications, 2006, 15(3/4): 268-276
[15]Lin Xiaotong, Chen Xuewen. Mr. KNN: Soft relevance for multi-label classification[C] //Proc of the 19th ACM Int Conf on Information and Knowledge Management. New York: ACM, 2010: 349-358
[16]Jiang J Y, Tsai C C, Lee S J. FSKNN: Multi-label text categorization based on fuzzy similarity and k nearest neighbors[J]. Expert Systems with Applications, 2012, 39(3): 2813-2821
[17]Zhu Xiaojin, Goldberg A B. Introduction to Semi-Supervised Learning[M]. Williston, VT: Morgan & Claypool, 2009[18]Klir J G, Yuan B. Fuzzy sets and fuzzy logic[G] //Theory and Applications. Upper Saddle River, NJ: Prentice Hall, 1995
[19]Zhu Xiaojin, Lafferty J, Rosenfeld R. Semi-supervised learning with graphs[D]. Pittsburgh, PA: Language Technologies Institute, School of Computer Science, Carnegie Mellon University, 2005
[20]Read J, Pfahringer B, Holmes G, et al. Classifier chains for multi-label classification[J]. Machine Learning, 2011, 85(3): 333-359
[21]Boutell R M, Luo Jiebo, Shen Xipeng, et al. Learning multi-label scene classification[J]. Pattern Recognition, 2004, 37(9): 1757-1771
[22]Fürnkranz J, Hüllermeier E, Mencía E L, et al. Multi-label classification via calibrated label ranking[J]. Machine Learning, 2008, 73(2): 133-153
[23]Tsoumakas G, Katakis I, Vlahavas I. Randomk-labelsets for multilabel classification[J]. IEEE Trans on Knowledge and Data Engineering, 2011, 23(7): 1079-1089
[24]Tsoumakas G, Eleftherios S, Vilcek J, et al. MULAN: A Java library for multi-label learning[J]. Journal of Machine Learning Research, 2011, 12(7): 2411-2414
[25]Zhang Minling, Zhou Zhihua. A review on multi-label learning algorithms[J]. IEEE Trans on Knowledge and Data Engineering, 2014, 26(8): 1819-1837
[26]Demšar J. Statistical comparisons of classifiers over multiple data sets[J]. Journal of Machine Learning Research, 2006, 7(1): 1-30

Geng Xin, born in 1978. PhD, professor. His main research interests include machine learning, pattern recognition, and computer vision.

Xu Ning, born in 1988. PhD candidate. His main research interests include pattern recognition and machine learning.

Shao Ruifeng, born in 1994. Master candidate. His main research interests include pattern recognition and machine learning.
Label Enhancement for Label Distribution Learning
Geng Xin, Xu Ning, and Shao Ruifeng
(SchoolofComputerScienceandEngineering,SoutheastUniversity,Nanjing211189) (KeyLaboratoryofComputerNetworkandInformationIntegration(SoutheastUniversity),MinistryofEducation,Nanjing211189) (CollaborativeInnovationCenterofNovelSoftwareTechnologyandIndustrialization(NanjingUniversity),Nanjing210093)
Multi-label learning (MLL) deals with the case where each instance is associated with multiple labels. Its target is to learn the mapping from instance to relevant label set. Most existing MLL methods adopt the uniform label distribution assumption, i.e., the importance of all relevant (positive) labels is the same for the instance. However, for many real-world learning problems, the importance of different relevant labels is often different. For this issue, label distribution learning (LDL) has achieved good results by modeling the different importance of labels with a label distribution. Unfortunately, many datasets only contain simple logical labels rather than label distributions. To solve the problem, one way is to transform the logical labels into label distributions by mining the hidden label importance from the training examples, and then promote prediction precision via label distribution learning. Such process of transforming logical labels into label distributions is defined as label enhancement for label distribution learning. This paper first proposes the concept of label enhancement with a formal definition. Then, existing algorithms that can be used for label enhancement have been surveyed, and compared in the experiments. Results of the experiments reveal that label enhancement can effectively discover the difference of the label importance hidden in the data, and improve the performance of multi-label learning.
multi-label learning (MLL); label distribution learning (LDL); label enhancement; logical label; label distribution
2017-01-03;
2017-03-09
国家自然科学基金优秀青年科学基金项目(61622203);江苏省自然科学基金杰出青年基金项目(BK20140022) This work was supported by the National Natural Science Fundation of China for Excellent Young Scientists (61622203) and Jiangsu Natural Science Funds for Distinguished Young Scholar (BK20140022).
TP391
