利用属性集相关性与源误差的多真值发现方法研究
2019-03-13卢菁,胡成,刘丛
卢 菁,胡 成,刘 丛
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
Web正在以前所未有的速度增长.随着电子商务和社会媒体的快速发展,越来越多的用户和应用依赖于在线数据作为信息需求的主要资源.然而Web数据不是完全正确的,来源往往会提供错误的或相互矛盾的信息.如表1所示,在线书商对于《社会计算:社区发现和社会媒体挖掘》一书的作者列表提供了不一致的信息.
表1 各网站提供的作者信息
Table 1 Author information provided by websites

数据源作者列表当当唐磊,文益民,闭应洲京东唐磊华章图书唐磊,刘欢一号店文益民
其中,华章图书提供了正确并且完整的作者列表,京东提供了正确但不完整的作者列表,当当提供的作者列表中一部分是错误的,而一号店则提供了完全错误的作者列表.可以发现,不同网站为同一书籍的作者提供了大量的冲突数据.我们将从不同的、相互冲突的来源获得最完整和准确的合并记录称为多真值发现问题.
当前研究主要集中于单真值发现问题上,文献[1]首次提出并定义了真值发现问题,基于事实和数据源之间相互依赖的关系提出了一种基于迭代机制联合推导数据源质量和真值的可信度算法TruthFinder,并且用相似度度量事实之间的相互影响.文献[2]通过将用户已知的特定事实转化为约束条件,对数据集进行检索提出了Investment等算法.文献[3]提出了一种概率数据模型,考虑事实的难易程度,避免数据源从相对容易的事实获得过高的可信度分值.文献[1-3]考虑影响真值发现的各种因素,但均忽略了数据源间存在相互依赖的关系.文献[4]通过检测数据源提供错误数据的冗余程度来处理数据源间的复制关系,提出的算法能捕获到两两数据源间的一阶复制,但处理相互复制、传递复制时,准确率会降低.文献[5]通过观察数据源联合召回率和联合假真率来处理相互复制和传递复制,但仅考虑了数据复制导致虚假数据间的正相关,无法处理正确数据间的负相关.文献[6]认为基于提取器提取规则的不同,对比在源独立条件和源相关条件下,联合召回率与联合假真率的比值,提出了PrecRec和PrecRecCorr算法.文献[7]提出同一数据源提供的不同类别数据应该具有不同的可信度分值,提出了CTruthFinder算法.文献[8]提出一种图概率模型LTM,利用假阳性和假阴性,对数据源两个方面进行建模,可自动推断真实数据和源质量.缺陷是数据必须符合Beta分布,否则效率将下降.文献[9]认为对象的真值与数据源提供的观察值间相似性加权和达到最大时可直接得到真值列表.文献[4-9]均忽略了数据源质量评估的有效性受到数据源提供事实总数的影响,当数据源仅提供少量事实时,算法对数据源质量评估不准确.数据源提供的事实数量差异很大,少数大规模数据源提供大量的信息,信息分布呈长尾现象.文献[10]提出一种加权聚合框架,将多个数据源提供事实的加权组合建模为真值,通过解决优化问题寻求数据源权重的最佳分配,降低事实数量对数据源评估的影响.然而文献[10]仅能处理数值类型的单真值发现问题,对于非数值类型的多真值发现问题未见探讨.
针对以上问题,本文首先根据信息量对数据源进行分类.对于头部数据源,通过属性集相关性给予相应属性集置信度补偿,易于区别正确和错误数据,发现潜在的真值集合.对于尾部数据源,通过源误差衡量源的可靠程度,误差小的数据源获得更高的权值分配,将真值发现问题转化为一个全局优化问题,找到最佳的权值分配后,得到最接近真实事实的真值集合.本文贡献如下:
1)通过信息量的概念衡量数据源的规模,对数据源进行分类.提出属性集值向量的概念,描述数据源为对象提供的多个属性值分布情况;
2)针对头部数据源提供的属性集,利用属性集值向量间的相关性,给予相互支持以及互补的正确属性集更多置信度补偿,提出了迭代计算数据源可信度以及属性集置信度的多真值发现算法MTDAC(Multi-truth Discovery by Attribute Correlation);
3)对尾部数据源,利用数据源误差来反映数据源的可靠程度,将真值发现问题转化为一个全局优化问题,提出了迭代计算数据源的权重值以及对象真值集合的多真值发现算法MTDSE(Multi-truth Discovery By Source Error);
4)在实际数据集上的实验证明了本文算法的有效性.
2 系统框架
2.1 相关概念
定义1.对象可能值集V*,j:所有数据源对于某个对象的特定属性提供的所有属性值集合.例如,如表1所示,《社会计算社区发现和社会媒体挖掘》的作者列表可能值集是{唐磊,文益民,闭应洲,刘欢}.
定义2.属性集值向量vi,j:二值向量.数据源提供关于某个对象的观察值在对象可能值集上的分布情况.表示数据源si为对象oj提供的值向量.向量长度为该对象可能值集的长度,如果数据源提供了对象可能值集上的第i个属性值,那么该对象向量值的第i个元素设置为1,否则为0.
定义3.数据源信息量P(si):表示数据源提供的属性集个数占数据集中全部属性集的百分比,如公式(1)所示:
(1)
其中,m表示实际数据集中数据源的总个数,|O(si)|表示数据源si提供的属性集个数.对所有数据源的P(si)由大到小排序,根据二八法则,当规模较大数据源组成的集合提供信息量占比超过数据集信息量80%时,该集合中的数据源为头部数据源,其余为尾部数据源.
2.2 系统架构图
本文系统架构图如图1所示,通过以下七个步骤发现真值集合:
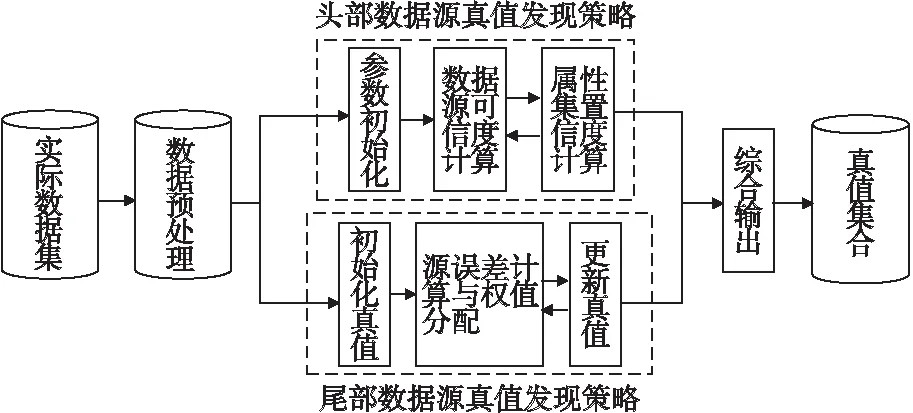
图1 系统总体框架Fig.1 General system frame
1.对数据集进行预处理,根据数据量对数据源进行分类.头部数据源执行步骤(2),尾部数据源执行步骤(5).
2.初始化数据源可信度T(s)及相关参数,计算属性集的置信度A*(v).
3.根据A*(v),重新计算数据源可信度T(s).
3基于属性集相关性的多真值发现方法(MTDAC)
3.1 头部数据源的可信度计算
定义T(si)为头部数据源si的可信度,A(vi,j)为数据源si为对象oi提供属性集的置信度,T(si)可通过计算该头部数据源si提供的所有属性集置信度均值来表示.如公式(2)所示:
(2)
其中,NSi表示由数据源si提供的所有属性集,|NSi|表示数据源si提供属性集的总数量.
3.2 属性集的置信度计算
如图2所示,一个属性集合的置信度应该由提供它的头部数据源以及关于相同对象的其他属性集合来确定.假设s1和s2相互独立,分析没有相关事实的简单情况,V1是关于对象o1的唯一属性集.其置信度A(vi,1)可以计算为:
(3)
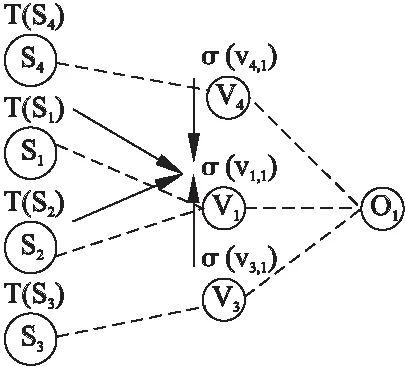
图2 属性间的相互影响Fig.2 Influences among attribute sets
W(V1)表示提供属性集V1的数据源集合.
1-T(si)的值很小,可能会导致下溢.为了方便计算,使用对数重新定义了属性集的置信度:
σ(vi,1)=
-ln(1-A(vi,1))
(4)
3.3 属性集间的相关性
数据源s3提供的属性集V3与V1相似,则说它们是正相关的,如果V3是由许多高可信度数据源提供,V1应该得到置信度评分补偿.本文采用了包含信息缺失的相似性计算方法,即数据源提供的属性集都不包含某特定属性,那么它们之间也是存在相似性的.假设图2中,三个属性集值向量分别为v1,1(1,0,1,0,0),v3,1(1,0,1,0,1),v4,1(1,1,1,1,0),信息检索中采用两向量之间的内积来计算相似性,v1,1,v3,1,v4,1两两之间的内积都为2,但显然v1,1与v3,1之间更相似.
文献[12]定义包含信息缺失的相似性计算方法:
(5)
根据图2,考虑属性集间的正相关性以及对相似性计算方法的优化,定义正相关检测函数,给予置信度评分补偿:
(6)
ρ是正相关因子控制属性集互相影响的参数,ρ的取值越大,正相关的属性集间会获得更多置信度评分补偿.
数据源提供包含错误信息的属性集之间有很大不同,它们之间相似性不会很高.包含错误信息的属性集,它们组成的集合在所有属性集中占比会很低.假设在表1中,京东提供的作者信息为唐磊,当当提供的为刘欢.两数据源都提供了包含部分正确信息的属性集,但它们的属性集值向量是负相关的.提供正确信息的属性集组成的集合在所有属性集中占比不低.设置负相关相似性阈值α,判断属性集是否属于同一集合,当sim(vi,j,vn,j)大于α时,函数f(x)取值为1,否则为0,统计该集合中属性集个数.观察此集合在所有属性集中所占比例,给予相应置信度评分补偿.定义负相关检测函数,如公式(7)所示:
(7)
γ是负相关因子,控制属性集集合数目对置信度评分的影响.|Oj|表示所有数据源为对象Oj提供的属性集总数.
结合φ(vi,j)对属性集的置信度公式(4)进行改进:
σ*(vi,j)=σ(vi,j)+ω(vi,j)+φ(vi,j)
(8)
3.4 基于属性集相关性的多真值发现算法(MTDAC)
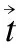
算法1.基于属性集相关性的多真值发现算法(MTDAC).
输入:冲突数据集D、数据源集合S、对象集合O;
输出:真值集合X={n,v*,n|n∈O};
1.相关参数的初始化;
2.FOR EACH Si∈S
3. T(Si)←T0;

5. FOR EACH oj∈O
6.根据数据源si为对象oj属性值提供情况,初始化属性集值向量vi,j;
7. 根据式(8)计算属性集的置信度评分;
8. 根据式(2)重新计算数据源的可信度评分;
12. RETURN真值集合X{n,v*,n|n∈O}.
4基于源误差的多真值发现方法(MTDSE)
4.1 数据源的误差
本文使用文献[10]中源误差的概念融合属性集值向的概念,处理包含数值、字符串类型的多真值发现问题.属性集值向量v*,n表示对象n的真值集合,定义如下:
(9)
当找到TSi权重最优分配时,v*,n为最为可能接近对象的真值集合.我们使用数据源提供的所有信息与初始化真值之间的差异作为数据源的误差,定义如下:
(10)
4.2 数据源权值的最佳分配
误差反映了数据源的可靠程度,误差小的高质量数据源应该获得更高的权重分配[11].权重的最佳分配可转化为全局优化问题,在所有数据源权重值和为1的条件下,寻求目标函数g(TSi)的最小值:
目标函数是凸函数的线性组合,因此目标函数也为凸函数,定能找到最优解使得目标函数取得最小值.在保证全局优化问题取值最小的前提下,可以找到最佳的权重分配:
(11)
算法2.基于源误差的长尾数据多真值发现算法(MTDSE)
输入:冲突数据集D、数据源集合S、对象集合O;
输出:真值集合X={n,v*,n|n∈O};
2.FOR EACH si∈S;
6.REPEAT
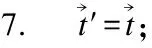
8. 根据等式(9)结合源的权重值TSi重新计算v*,n;
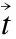
13. RETURN真值集合X{n,v*,n|n∈O}.
5 合并策略与综合输出
6 实验结果与分析
6.1 实验环境
本节所有实验硬件环境为:Intel® CoreTMi7-6700HQ 2.60GHz处理器、8G内存、Windows8操作系统.本文所有算法包括对比算法均使用Java语言实现,JKD版本为JDK6.0,数据库系统采用MySQL5.5.
6.2 数据集
本文采用的数据集是通过爬虫程序获取的图书作者数据集,该数据集包括书名、ISBN、图书销售网站(数据源)、作者列表.利用信息量进行计算,对数据源进行分类.京东图书等47个头部数据源提供的信息量为80.8%,微店等403个尾部数据源提供的信息量为19.2%.我们对原始数据集进行去重处理,并对作者列表的格式进行了统一的修复,避免因格式不一致导致的数据检测问题.经预处理后,数据集包含了2245本图书、450个图书销售网站(数据源)、8829条作者信息、22972条冲突数据记录.我们还随机选择100本图书,搜索该100本图书的封面作者信息,对该100本图书的作者列表进行手工校准,作为标准集.
6.3 评价指标
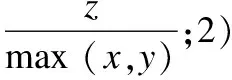
6.4 参数对算法的影响
对MTDAC算法中参数初始化进行讨论,如图3(a)所示,正相关因子ρ>0.1时,对算法的准确率影响很小,算法的F-Score波动范围不超过5%,因为在大多数真实数据集中正确数据的占比要高于错误数据,且数据源提供的正确数据大都是相同或者相似的.正相关因子ρ=0.5时,算法的表现最佳,设置ρ=0.5.在正相关因子ρ不变的情况下,不断调整负相关因子γ的值,观察MTDAC算法的准确率变化,实验结果如图3(b)所示.随着γ不断增加,算法对负相关数据的敏感程度提高,算法的准确率也呈现递增的趋势.γ=0.7时,MTDAC算法在图书作者数据集上得到最佳表现,准确率为0.811.γ在区间(0.7,0.9]时,对负相关数据的敏感程度过高,错误数据的置信度评分也得到一定提高,引入了错误数据,导致算法的准确率降低.
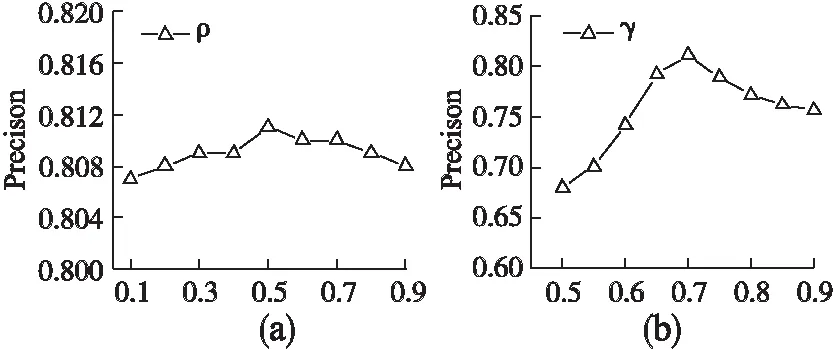
图3 参数对MTDAC算法准确率的影响Fig.3 Influence of parameters on the accuracy of MTDAC
其次,观察不同的参数取值对算法召回率的影响,实验结果如图4(a)所示,在区间(0.1,0.5]上,随着正相关因子ρ不断增加,算法的召回率呈快速上升趋势.因为通过正相关检测函数,提供包含部分正确信息的属性集会得到置信度评分补偿,利于MTDAC算法发现更加完整的真值集合.在正相关因子ρ不变的情况下,调整负相关因子γ的值,观察算法召回率的变化,实验结果如图4(b)所示,在区间(0.5,0.9]上时,算法的召回率波动范围不超过6%,在γ=0.75时,算法的召回率达到峰值.因为存在负相关的属性集集合在所有属性集中占比较低,样本数目少,负相关检测函数给予的置信度补偿相对较低.因此,负相关因子γ对算法的召回率影响很小.结合图3在保证算法准确率的同时,获得相对较高的召回率,初始化ρ=0.5,γ=0.7.

图4 参数对MTDAC算法召回率的影响Fig.4 Influence of parameters on the recall of MTDAC
最后,分别在参数ρ、γ取得最优值的情况下,观察参数对算法F1的影响,实验结果如图5所示,在ρ=0.5,γ=0.7时,算法的综合表现最佳,F1=0.806.
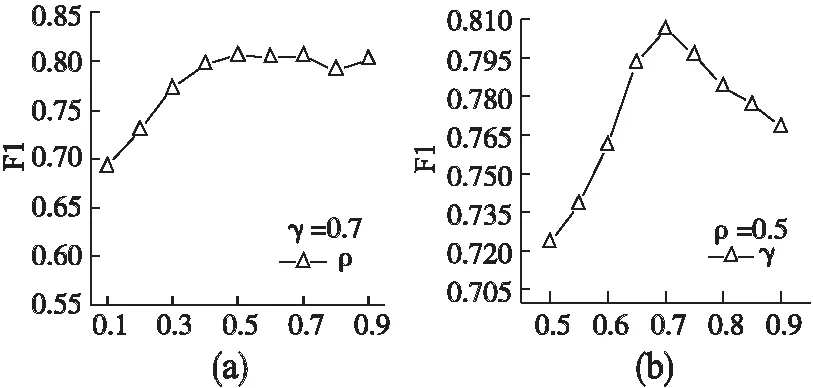
图5 参数对MTDAC算法综合表现的影响Fig.5 Influence of parameters on the F1 of MTDAC
6.5 MTDAC、MTDSE与传统算法的对比
本文设置阈值K=0.5,即属性值为真的概率大于0.5时,该属性值为真值.首先观察各算法对头部数据源提供的事实,各算法的表现如图6(a)所示.基准算法Voting的查全率明显低于其他算法,TruthFinder算法查全率较高,但准确率较低,导致F-Score并不高.MTDAC算法考虑了属性集间更为复杂的相关性,算法的准确率比MTruths算法高出2.5%,算法的综合表现优于其它算法.
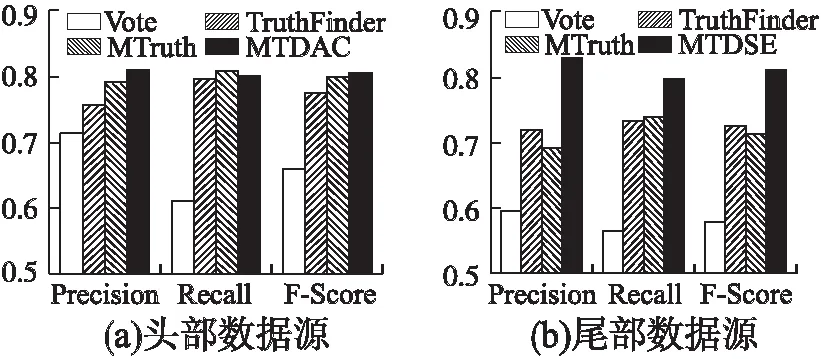
图6 算法在头尾数据源上的综合表现Fig.6 Algorithm performance on head and tail data sources
其次,观察各算法针对尾部数据源提供的事实,各算法的表现如图6(b)所示.由于数据量小,属性集间关系稀疏,各算法的综合表现都有明显下降,Voting算法下降幅度达到12%,其余算法的综合表现降低了7%到9%之间.MTDSE算法在处理尾部数据源提供的信息时,算法的综合表现要优于各对比算法.由此可见,传统算法在处理尾部数据源提供的事实时,得到的真值集合往往不是准确的.
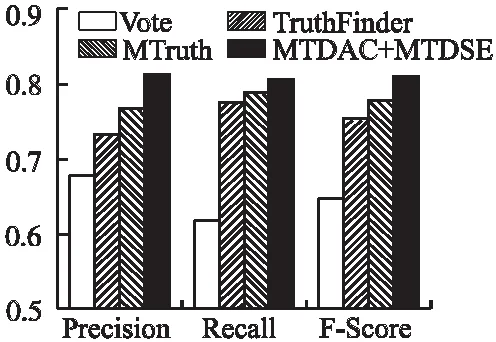
图7 算法在完整数据集上的综合表现Fig.7 Algorithm performance on complete data set
最后,观察各算法以及同时使用MTDAC算法和MTDSE算法在完整的图书作者数据集上的表现,结果如图7所示.两种算法的结合使用获得了最佳表现,传统算法由于没有考虑实际数据集中事实对象在数据源上的分布可能呈现长尾现象,对数据源进行统一处理,导致算法的综合表现不佳.
实验证明了本文提出的基于属性集相关性和源误差的多真值发现方法的有效性,较传统真值发现算法在真实的长尾数据集上的表现有显著提升.
7 结束语
本文首先利用信息量衡量数据源的规模,对数据源进行分类.针对头部数据源提供的属性集,利用相关性给予相应属性集置信度补偿,提高了真值发现的准确率,提出了基于属性集相关性的多真值发现算法MTDAC.针对尾部数据源,利用源误差的概念,将真值发现问题转化为一个全局优化问题,降低事实数量对数据源评估的影响,提出了多真值发现算法MTDSE.通过合并策略对两算法执行后得到的真值集合进行合并,作为综合输出.最后,通过实验验证了本文算法的有效性.在未来的工作中,针对动态变化的数据集,将致力于真值发现的时效性研究,提高算法的综合性能.
