移动云环境下基于预测图的动态协调过程推荐
2017-02-01侯小毛张福泉
侯小毛 张福泉 刘 定
(1.湖南信息学院 电子信息学院,湖南 长沙 410105;2.北京理工大学 软件学院,北京 100081)
0 引言
在互联网高速发展时代,每天都有海量的内容被生产,我们并不缺少优质的内容,也不缺乏生产优质内容的能力,而是优质内容并没有触及其核心用户,无法实现内容与用户的精准匹配.移动云计算作为移动互联网高速发展的新兴服务模式,有着广阔的市场应用前景.云端多样化的服务内容如何高效地传送至云端用户,并给用户提供最需要的数据是当前移动云计算需要解决的关键问题,这归根结底就是一个个性化推荐的问题[1].当前比较大型的互联网公司都在做个性化推荐服务,通过综合并利用用户的兴趣偏好、属性,主题的属性、内容、分类,以及用户之间的社交关系等等,挖掘用户的喜好和需求[2,3],主动向用户推荐其感兴趣或者需要的内容,实现内容的精准化推送.作为移动云计算环境,这种个性化推荐服务的环境和要求更高,服务需要更精准,响应需要更迅速,能耗需要尽可能降低,目的是为了更适合移动端的轻量级低能耗负载访问.
1 预测图
图结构作为数据存储的一种结构方式,常用作于复杂数据的多样分析,云端用户数据种类丰富,数据量庞大,对于单个用户来说,数据属性的多样化及异构性,在分析的时候采用图结构来定义说明更加方便.
图结构的分析核心主要是图的邻接矩阵分析[4],从邻接矩阵中将单个的节点通过网状图连接起来,构成一张有价值的数据网图,下面将对图邻接矩阵进行定义.
假设S(ui)={ui,k|k=1,2,…,Ki}和S(uj)={uj,k|k=1,2,…,Kj}分别为两个云计算用户ui和uj的近邻组集合,若ui和uj有部分邻居关系,则定义:
若(ui≻uj):S(uj)∩S(uj)≠Ø,则表示ui和uj两个集合有对等关系.
若(uiuj):S(ui)⊆S(uj),表示uj和ui是包含与被包含关系.包含等级低.
若(ui|uj):S(ui)⊆S(uj),表示uj和ui是包含与被包含关系.包含等级中.
若(uiuj):S(ui)⊆S(uj)且有Sim(ui,ui,k)≤Sim(uj,uj,k),表示uj和ui是包含与被包含关系.包含等级高.
若(ui≻uj):S(ui)∩S(uj)=Ø,则表示ui和uj两个集合无直接关系.
这样,所有云计算用户都可以用上述关系来描述,这种关系运用图结构来表示,根据对等和包含关系,可生成一个带环有向结构图,这里我们定义为预测图,如此,云计算用户数据就可以基于预测图来分析.
在预测分析中,分别对用户和资源进行相似计算,从而对用户图结构和资源图结构进行整理与分类处理,计算集合相似方法较多,本文采用皮尔逊相关系数法来计算相似度[5],根据用户对某种或者某类资源的感兴趣程度,可将用户进行相似度计算.计算公式如(1)所示.
(1)

下面对资源进行相似度计算,云计算服务种类多,资源丰富,在对资源进行分类时,也可以按照公式(1)的方法进行相似计算,目的是在动态推荐时,可以为用户提供更全面的相似服务.
(2)
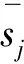
N(si)={sj|σ(Sim(si,sj)(k))>ε,1≤k≤K},
(3)
N(ui)={uj|σ(Sim(ui,uj)(k))>ε,1≤k≤K}.
(4)
因此,资源和用户可以根据公式(3)和(4)组建近邻矩阵.
2 动态协调推荐
平台推荐一般分为静态和动态两种模式[7],静态推荐取一段时间内根据用户喜好和属性进行内容推荐,而动态推荐是则分为实时推荐和非实时推荐,也是根据用户特点进行针对性推荐,相比于静态模式,推荐内容更精准,特别是实时推荐,更是有效地跟踪用户需求,提高推荐内容准确度,但动态推荐服务端成本高,能耗高,综合静态模式和动态模式优缺点,本文选择基于协调过程的动态推荐方法.下面将对动态协调过程推荐模型的建立进行描述.
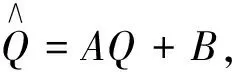
(5)
其中,用户和云计算环境数据资源关系图用矩阵A表示,用户和云计算环境数据资源的矩阵用B表示.
公式(1)描述了预测数据集合计算方法,该方法在计算过程中,矩阵A和B的抽象建模过程会有损失[9],在此定义目标函数F来对此损失进行评价,设用户集合为U,数据资源集合为S,计算方法如.
(6)
其中,aij、bi和qij分别表示用户与资源近似值,资源索引和用户离线损失值.动态推荐的精准正是因为每一次推荐都是将用户跟踪数据和云计算资源匹配的结果.这种匹配随时间变化,而且无规律,在此,将用户、资源和匹配数量三者进行随机变换,方法如公式(7)、(8)、(9)所示.
U|t+r=H1(|U|t|pt),
(7)
S|t+r=H2(|S|t|qt),
(8)
L|t+r=H3(|L|t|ht),
(9)
H1、H2和H3分别为随机变换函数.这个随机变换过程描述了t+r时刻的变换情况.时间间隔为r.在动态推荐过程中,对随机变换函数进行相似模拟[10],方法如
(10)

在相似模拟过程中,为了方便量化,采用σ(x)函数进行归一化处理.引入随机变换之后,公式(6)可以变为基于时间t的函数如
(11)
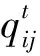
3 实例仿真
为了验证本文推荐算法的性能,本文通过Spring+Mybatis来完成数据模型建立,通过Matlab进行数据统计分析,在实例仿真过程中,将分别从相似度变化指数、近邻动态变化指数和准确度指数三个方面来验证算法性能.前两者验证动态推荐的功能性,是否能够在有限时间内找出与某用户具有一定相似关系的用户和资源,后者验证该模型相较于其他推荐模型的优势.
3.1 实验环境设置及参数配置
在本文仿真中,预测图建立,矩阵计算等操作均在Spring+Mybatis完成,实验仿真数据均来自于文献WS-DREAD,其中,云计算用户个数为339个,云计算资源服务共计5 825项[11].
考虑到动态协调过程的适应性,必须考虑用户和资源在模型构造时的动态变化情况,这也是精准推荐实现的基础,在预测图邻接矩阵变换后,要进行相似度和准确度计算评价,而动态协调建模过程对服务质量QoS的影响是评估该动态协调过程的关键.下面将对QoS中两个关键因素即响应时间(RT)和吞吐量(TP)在建模过程中的变化进行仿真.
3.2 相似度变化指数
考虑到用户和资源在动态协调过程中的变化情况,在邻接矩阵变换及相似计算过程中,相似度变化指数衡量动态协调过程达到稳定状态的效率.其计算方法如
(12)
其中τ为动态协调过程计算变化状态的最小时间间隔,Sim(ui,uj)(t)为t时刻用户或者资源ui和uj的相似度.L为用户或者资源总数.
对此过程进行Matlab仿真,分别对339个用户和5 825条云资源服务项在RT和TP两个服务质量下的ΔSV随时间变化情况.如图1和2所示.
从图1可以看出,随着时间的增加,用户RT和TP的相似度变化指数减小,且用户的RT相对于TP来说,下降速度更快,当仿真时间到达到3 s时,相似度变化指数趋近于0.
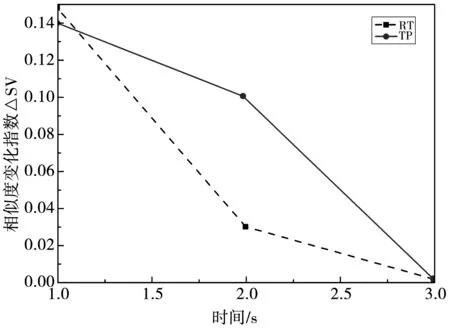
图1 用户的
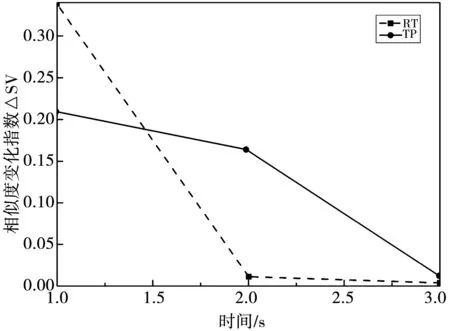
图2 资源的
从图2可以看出,随着时间的增加,资源的RT和TP的相似度变化指数减小,当仿真时间到达到3 s时,RT的相似度变化指数趋近于0,TP的相似度变化指数趋近于0.01.
综合图1和图2可以得到,用户和资源的ΔSV随时间的增加而降低,在3 s内基本达到稳态,这说明在动态协调过程中,在用户和资源的变化不大的情况下,相似度变化不明显,因此根据相似度组建的近邻矩阵也比较稳定.
3.3 近邻动态指数
在对相似变化指数进行仿真后,下面将对动态协调过程中的近邻动态指数变化进行考察.近邻变化指数计算方法为

(13)
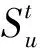

图3 用户的
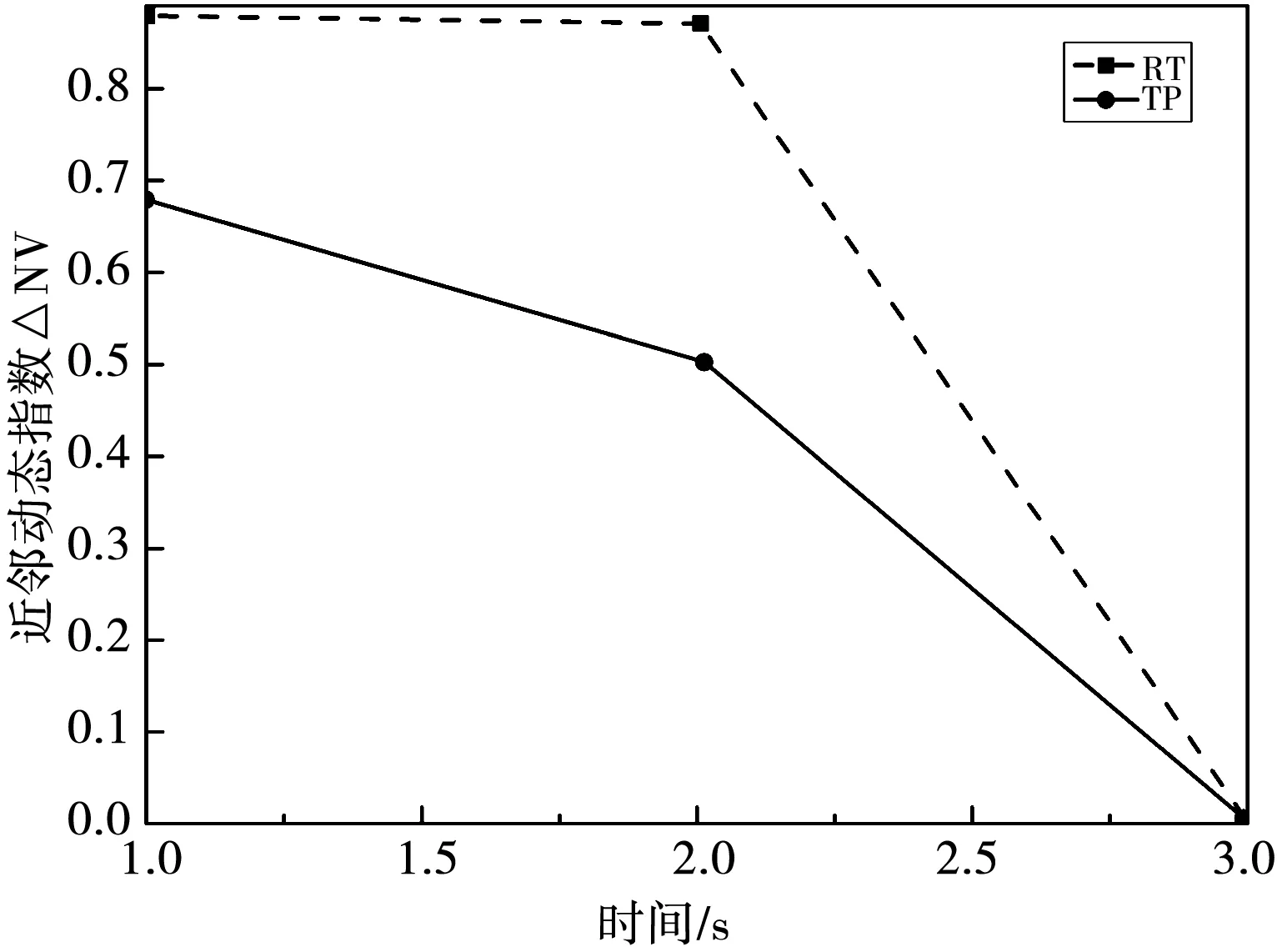
图4 资源的
从图3可以看出,随着时间的增加,用户RT和TP的近邻变化指数减小,在2 s内,两者的近邻变化指数下降速度较慢,2-3 s时间段内,下降速度明显加快,当仿真时间到达到3 s时,近邻变化指数趋近于0.
从图4可以看出,随着时间的增加,资源RT和TP的近邻变化指数减小,当仿真时间到达到3 s时,近邻变化指数趋近于0.
综合图3和图4可得,随着时间的增加,用户和资源的近邻变化指数均在减小,3 s达到稳态,表明经过3 s后,用户和资源在RT和TP服务质量下,近邻趋于稳定状态.
综合图1-4可得,随着时间的增加,动态协调过程推荐模型对于云计算环境中不论是用户属性还是资源属性的某个服务质量均会达到稳定状态,收敛性好.
3.4 准确度
关于准确度的评价标准,主要有绝对误差(MAE)和均方误差(RMSE)两个指标.计算方法
(14)
(15)
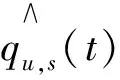
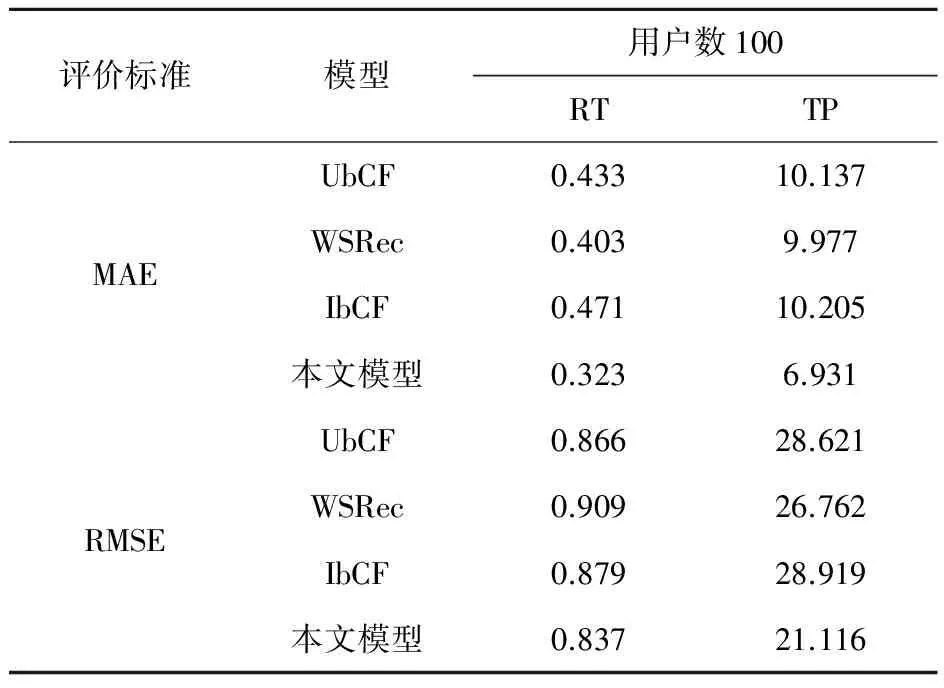
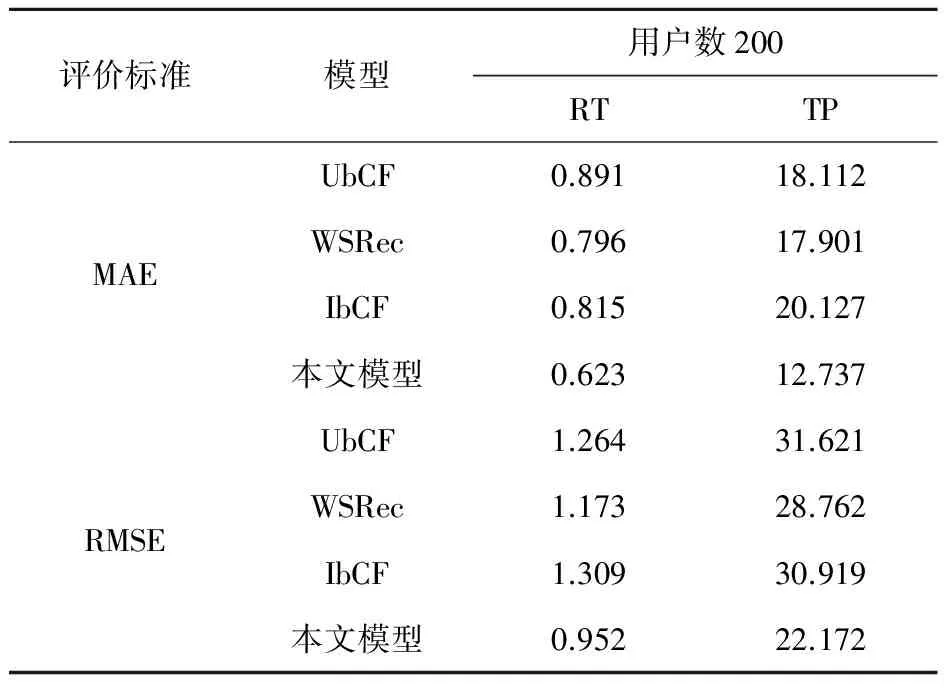
下面将对典型的推荐模型和本文推荐模型在准确度方面进行比较,当前研究中,比较常用的推荐模型主要有:UbCF、WSRec和IbCF[12].下面分别计算这三种模型及本文模型的MAE和RMSE,为了验证系统的稳定性,分别计算了用户数为100和200的准确度,结果如表1所示.
表1不同推荐模型的MAE和RMSE比较(u=100)
评价标准模型用户数100RTTPMAEUbCF0.43310.137WSRec0.4039.977IbCF0.47110.205本文模型0.3236.931RMSEUbCF0.86628.621WSRec0.90926.762IbCF0.87928.919本文模型0.83721.116
表2不同推荐模型的MAE和RMSE比较(u=200)
评价标准模型用户数200RTTPMAEUbCF0.89118.112WSRec0.79617.901IbCF0.81520.127本文模型0.62312.737RMSEUbCF1.26431.621WSRec1.17328.762IbCF1.30930.919本文模型0.95222.172
从计算结果对比可得,本文模型在动态协调过程推荐中的MAE和RMSE明显比UbCF、WSRec和IbCF小,这表明在准确度方面,本文算法有所提高,随着用户数量的增加,动态推荐模型的算法的MAE和RMSE也随之增加,增加幅度方面,UbCF、WSRec和IbCF和本文模型差距较小.
4 结语
本文将预测图融合与动态协调过程推荐,经过近邻矩阵化处理和相似度模拟,找出用户和资源的近邻相似关系,为动态协调过程推荐服务提供理论基础,在庞大的云计算资源库中为不同用户提供差异化的推荐服务.相比于传统推荐模型,在准确度方面提升明显,具有一定的推广价值.
[1] 凌霄娥. 基于社会化标签和历史价格曲线的网络结构个性化推荐方法[J]. 计算机工程, 2017, 43(4):212-216.
The peak e. Network structure of personalized social tag recommendation method and historical price curve based on [J]. Computer Engineering, 2017, 43 (4): 212-216.
[2] Feng X, Sharma A, Srivastava J, et al. Social network regularized Sparse Linear Model for Top-N recommendation[J]. Engineering Applications of Artificial Intelligence, 2016, 51(C):5-15.
[3] 翟鹤, 刘柏嵩. 基于用户信任及推荐反馈机制的社会网络推荐模型[J]. 计算机应用与软件, 2016, 33(11):258-262.
[4] 徐仁和, 卢文博, 王海涛. 基于邻接矩阵变型的K分网络社团算法[J]. 信息安全与技术, 2016, 7(3):31-34.
[5] 柳顺义, 张和平. 定向图的斜邻接矩阵的积和多项式[J]. 兰州大学学报:自然科学版, 2016, 52(5):681-685.
[6] Niusvel AcostaMendoza, Andrés GagoAlonso, Jesús Ariel CarrascoOchoa, et al. Extension of canonical adjacency matrices for frequent approximate subgraph mining on multi-graph collections[J].International Journal of Pattern Recognition & Artificial Intelligence, 2017.
[7] Guo G, Zhang J, Yorke-Smith N. A novel recommendation model regularized with user trust and item ratings[J]. IEEE Transactions on Knowledge & Data Engineering, 2016, 28(7):1 607-1 620.
[8] 陈曦, 成韵姿. 一种优化组合相似度的协同过滤推荐算法[J]. 计算机工程与科学, 2017, 39(1):180-187.
[9] 张萌, 南志红. 基于用户偏好的信任网络随机游走推荐模型[J]. 计算机应用, 2016, 36(12):3 363-3 368.
[10] 徐选华, 王佩, 蔡晨光. 基于云相似度的语言偏好信息多属性大群体决策方法[J]. 控制与决策, 2017, 32(3):459-466.
[11] 万树平. 一种具有区间数信息的多属性大群体决策方法[J]. 模式识别与人工智能, 2011, 24(3):340-345.
[12] 刘先红, 李纲. 科研社交网络的推荐系统对比分析[J]. 图书情报工作, 2016, 60(9):116-122.
