改进型MBI防碰撞算法研究*
2016-12-15王玉皞
李 唯,王玉皞,孙 宇,曾 舰
(南昌大学信息工程学院,南昌330031)
改进型MBI防碰撞算法研究*
李 唯,王玉皞*,孙 宇,曾 舰
(南昌大学信息工程学院,南昌330031)
在深入研究多比特识别算法MB(IMulti-Bit Identification Protocol)的基础上,从概率的角度对MBI机制进行分析建模,完善了MBI的理论基础。并且针对MBI算法通信开销较大问题,提出一种改进型多比特识别算法IMBI(Improved Multi-Bit Identification Protocol)。该算法在不增加原算法时间复杂度的前提下,通过引入滑动窗及部分碰撞比特恢复机制,解决了MBI算法中常规时隙标签冗余响应以及反演时隙下空闲分组造成的时延浪费问题,提升了系统识别性能。仿真结果表明,文章建立的模型对MBI算法有良好的逼近性能。此外,所提出的IMBI算法在标签平均消耗和系统时延上性能有大幅提升,进而提升了系统处理海量标签信息的能力。
射频识别;多比特识别;理论分析;滑动窗;部分比特碰撞机制
射频识别技术RFID(Radio Frequency Identifi⁃cation)是一种通过射频信号对带有信息的标签进行无线数据传输,实现非接触通信的自动识别技术,是物联网的重要组成部分。作为一种快速、实时、准确地采集与处理信息技术,RFID已经广泛应用于各个领域和行业,并且深度地影响到社会经济的发展。然而,RFID传感网络中阅读器与标签间的隐私保护、定位和标签碰撞等问题严重制约着RFID的发展,其中核心的就是标签碰撞问题[1-5]。
目前研究的防碰撞算法主要包括ALOHA防碰撞算法及树形防碰撞算法。其ALOHA算法包括纯ALOHA算法PA(Pure ALOHA)、帧时隙ALOHA算法FSA(Framed Slotted ALOHA)、动态帧时隙ALOHA算法DFSA(Dynamic Framed Slotted ALOHA)[6-9]等。这类算法主要特点是,算法结构简单,容易实现,但标签的接入存在不可预见性的问题,且识别效率相对较低。树形防碰撞算法主要包括查询树算法QT(Query Tree)、二进制树算法BT(Binary Tree)、碰撞树算法CT(Collision Tree)[10-14]等。树形防碰撞算法基于数据结构设计,不断将产生碰撞的标签分成多个子集逐个识别。标签数目较多时识别延时较长。文献[15-16]提出了MBI算法,将MQT防碰撞算法与纯碰撞反演理论相结合,去除所有空时隙,实现了多比特识别,提高了系统的识别效率。然而,MBI算法仍然存在以下不足:(1)算法分析仅停留于给定仿真环境下的整体性能仿真,没有针对算法进行完备的理论分析和建模;(2)算法在碰撞比特数大于1时不论标签数量多少均开启反演时隙,标签数量较少时,标签端分组小于阅读器端预留分组,存在延时浪费问题,通信复杂度仍有提升空间;(3)标签响应冗余度较大,即常规时隙中,阅读器发送查询前缀,匹配标签不论碰撞与否都将回复除前缀外的所有ID信息,然而真正有用的信息只存在于第一个包含碰撞的识别段。
本文从概率的角度对MBI进行深入分析,完善其理论基础。此外,针对MBI算法常规时隙标签冗余响应以及反演时隙下空闲分组造成的时延浪费问题,引入滑动窗及部分碰撞比特恢复机制[17],设计了改进多比特识别防碰撞算法(IMBI)。通过滑动窗智能地截取系统有用信息,阻止标签无效数据的发送。对于系统空闲分组问题,通过部分比特恢复机制在标签碰撞比特不大于反演长度M的对数时,直接恢复碰撞位数据信息,反之依照MBI算法开启反演时隙。仿真结果表明,本文提出的理论模型对MBI算法有良好的逼近性能,通过与MBI算法以及传统防碰撞算法的性能对比,不难发现IMBI算法有效的解决了MBI算法遗留的系列问题,系统的识别速度和吞吐率得到了极大的提升,并且能有效的降低系统能耗。
1 MBI算法简介
文献[15]结合标签碰撞信息与集群特点提出MBI防碰撞算法,该算法通过陪集定理[18]对标签进行分组实现多比特识别,去除了算法所有的空时隙,提高了系统的识别效率。并且碰撞越多,算法带来的效益越大,是当前系统性能最高的树形防碰撞算法之一。
1.1 碰撞反演条件
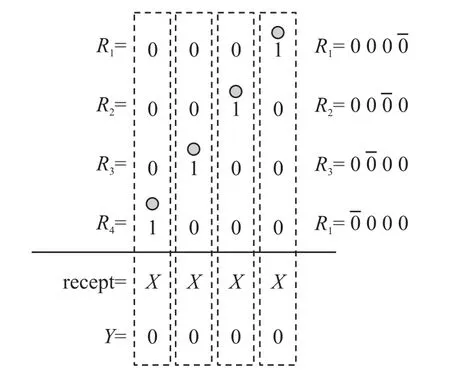
图1 碰撞反演约束条件
1.2 MBI识别机制
MBI算法将纯碰撞反演机制与传统MQT算法结合,阅读器以M比特为单位发送查询前缀,标签接收到查询命令后与自身ID进行比对,匹配则发送标签后面ID信息。阅读器端接收状态包括:空时隙、识别时隙、单比特碰撞时隙和多比特碰撞时隙。
阅读器依照传统QT算法对空时隙和识别时隙进行处理。对于单比特识别时隙,假设标签碰撞为‘X101’,阅读器则根据标签ID的二元性直接在碰撞位分别给定比特‘0’和‘1’识别出‘0101’和‘1101’。MBI算法中包括常规时隙和反演时隙,当阅读器端状态反馈为空时隙、识别时隙、单比特碰撞时隙时,按照常规时隙操作,即上述步骤。当检测到多个比特碰撞时开启反演时隙,满足条件的标签首先遍历事先存储好的分组信息,确定自己分组后选择相应的时隙发送查询码后M位标签数据。阅读器按分组顺序将接收到的比特信息与参考码字异或,即可得到当前反演长度下所有发送标签的M位数据信息。
2 MBI算法理论分析与完善
MBI算法分析仅停留于仿真环境下的整体性能仿真,没有针对算法进行完备的理论分析和建模。本章将从概率的角度分别对算法性能重要评价因子进行深入分析,完善MBI算法的理论基础。模型如图2所示。
2.1 时隙分析
假设系统内有N0个待识别标签,系统初始分配叉树为L0(L0=2M),标签ID长度为1且随机均匀分布。N0个标签随机地从L0个分支中选取一个分支来发送自身ID数据。为考虑普适性,随机抽取任意一个识别深度进行分析。假设当前识别深度为第k层,待识别标签为N。
任意一个分支没有标签响应的概率可表示如下:

某个分支有且仅有一个标签响应(识别时隙)的概率为:
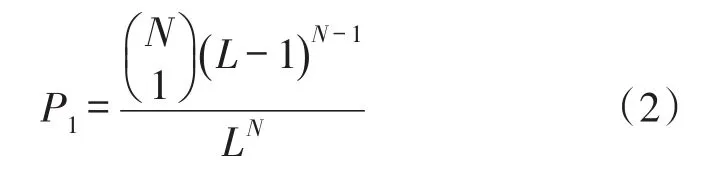
当多个标签同时选择一个分支响应,且响应ID中只有一位比特产生碰撞,则称该时隙为单比特识别时隙,概率可表示为:
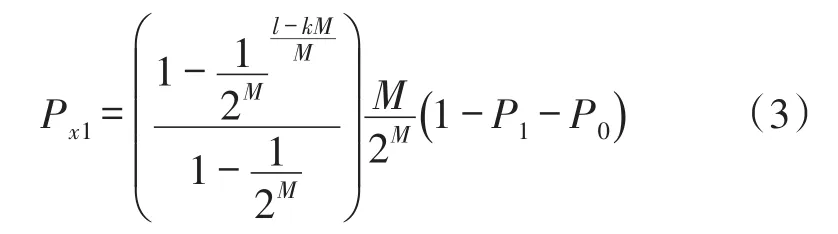
多比特碰撞时隙产生于一个分支下有多个标签回复且碰撞比特数大于1的情况,为以上各时隙集合的补集,故概率应为:
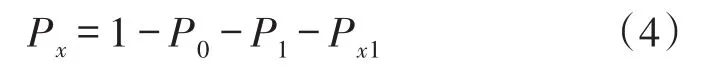
根据式(1)~式(4)易得当前搜索深度下各时隙数:
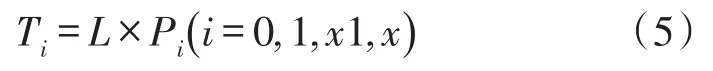
因而在该深度下分段碰撞反演所花总时隙应为:

2.2 平均延时分析
对某识别深度下所需通信延时进行分析,由于每个比特所需传输时间一定。为简化分析,本模型中以传输的比特数代替延时。模型分别从反演时隙和常规时隙两个角度讨论。
常规时隙中,不论标签数量是多少,总的延时可表示为:
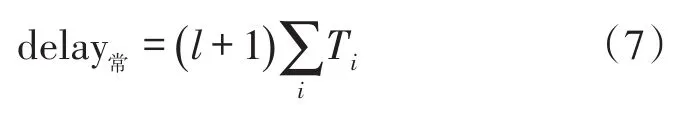
其中,1为阅读器为区分常规时隙和反演时隙增加的一位区分比特。
反演时隙中,延时不仅与标签发送比特数M有关,还与分组数量有关。反演时隙总延时为:
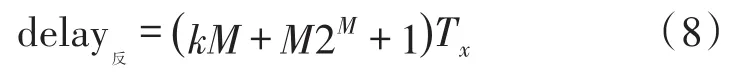
则当前深度下总的识别延时为:
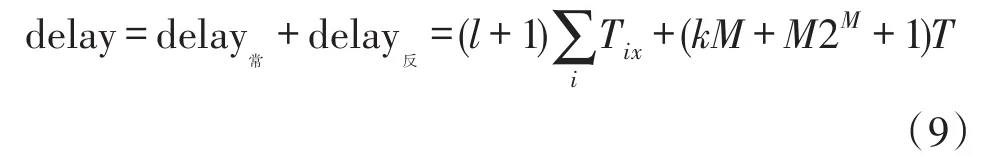
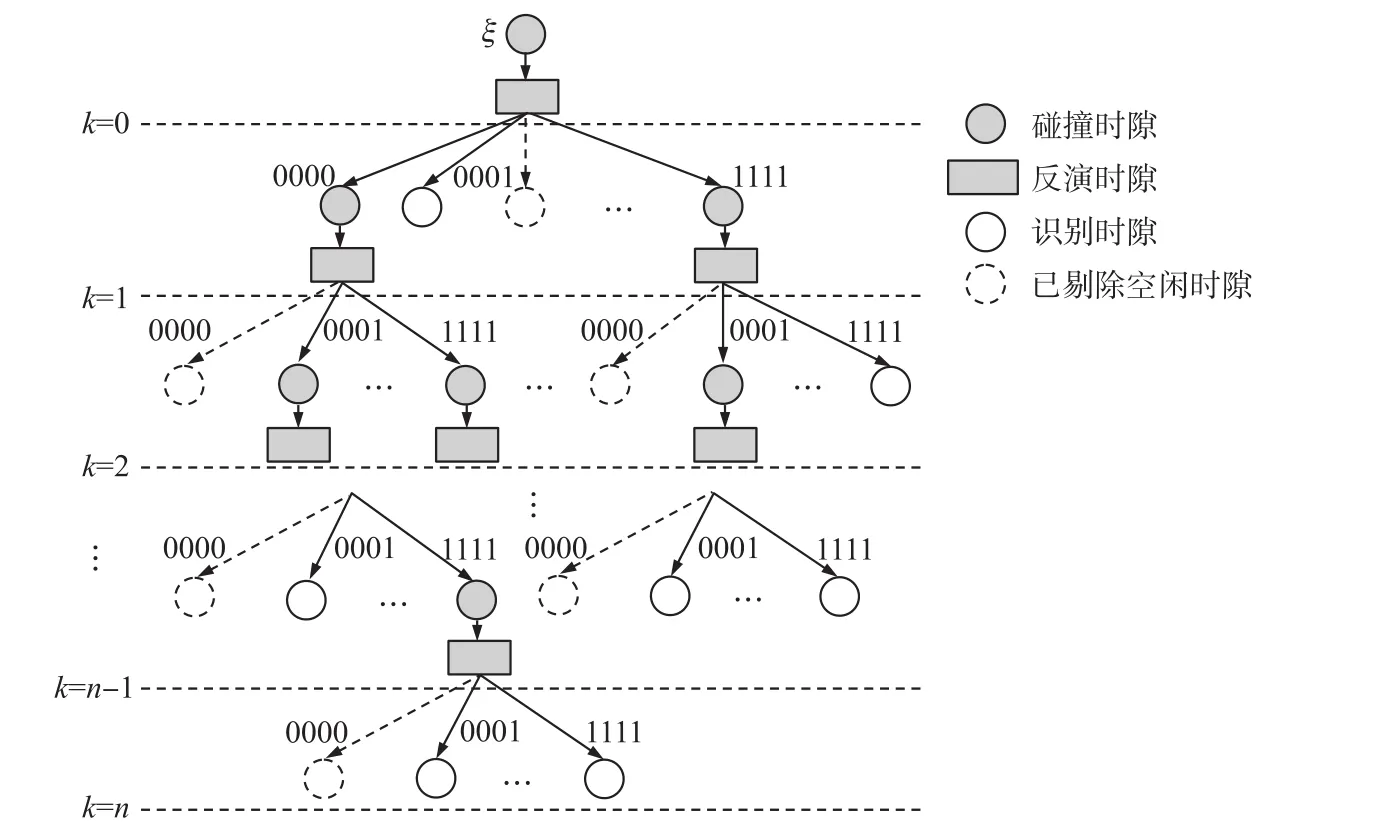
图2 碰撞反演模型
2.3 平均标签消耗分析
平均标签消耗是RFID防碰撞算法性能的另一个重要指标,其表示识别过程中每个标签平均发送的比特数。与延时分析类似,对平均标签消耗的讨论也从常规时隙及反演时隙两方面进行,不同的是平均标签消耗对标签数量的变化更为敏感。同样,针对某个识别深度探讨标签的平均消耗问题。通常情况,树型结构的每个分支节点回复的标签数量不定,难以分别计算。但每个识别深度其包含的标签数量确定,通过对每层整体计算标签消耗能极大的简化分析。第k层识别深度下,常规时隙标签消耗为:
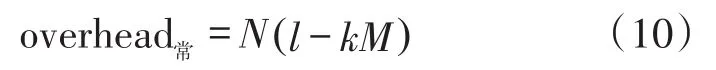
在常规时隙过程中,部分标签被识别而不再参与接下来的反演时隙响应,故反演时隙标签消耗可表示如下:
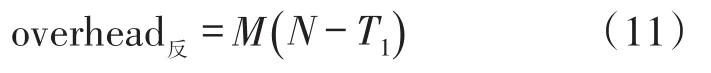
则当前识别深度下总的标签消耗为:
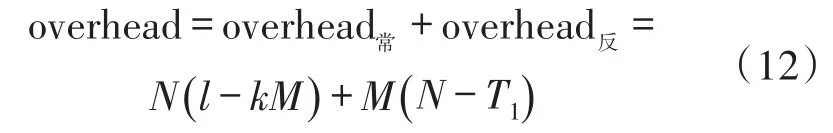
由于每个识别深度下的识别机制一致,只有标签数量和分支节点数量不断变化。故只需在识别过程中不断更新标签数量N及分支叉树L即可得到系统每个识别深度的具体信息。整体建模表示如下:

3 改进型MBI防碰撞算法
本章将对改进型MBI防碰撞算法(IMBI)进行详细介绍,该算法引入滑动窗和部分比特恢复机制,通过滑动窗逐段接收标签响应序列,检测到碰撞则提取出当前识别段并通知标签停止ID数据的发送。系统使用曼切斯特编码定位碰撞。为保证MBI时间复杂度不变,IMBI算法设定在碰撞比特数n满足1<n≤log2(M)时开启部分比特恢复机制,阅读器发送当前前缀及碰撞位的位置信息给标签,匹配标签提取碰撞对应位置ID数据转化为十进制并将M位全0序列对应位置‘1’后发送给阅读器。阅读器通过检测到的碰撞信息解析出当前识别段数据。IMBI算法针对性地解决MBI算法中标签消耗冗余及反演时隙下标签数量较少场景时的延时浪费问题,能有效的减小系统的时间复杂度及系统能耗。
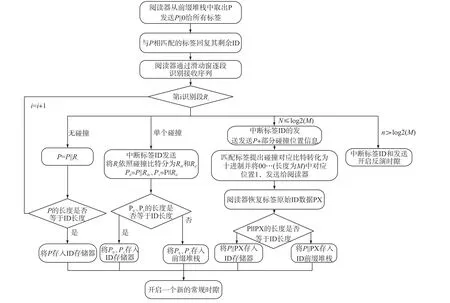
图3 IMBI防碰撞算法流程
IMBI防碰撞算法流程如图3所示,其具体步骤为:
(1)阅读器检查前缀堆栈,不为空则取出前缀发送常规时隙查询命令并等待标签的响应。
(2)标签收到查询命令后首先与自身ID进行比对,前缀匹配的标签回复除前缀外的所有ID。
(3)阅读器以长度为M的滑动窗对接收到的标签响应逐段识别,确定出窗内标签响应碰撞的位置及碰撞比特数量n。
①若没有碰撞,则将该识别段与查询前缀合并作为新的前缀存入前缀堆栈,识别滑动窗往后滑动M位比特的距离,开始识别下一个响应段;②若只有一个比特碰撞,通知标签停止发送后面ID,将碰撞位分别置‘0’和‘1’,与查询前缀合并存入前缀堆栈;③若碰撞比特数n≤log2(M),通知标签停止发送后面ID,阅读器重新发送本轮查询前缀信息及前log2(M)位碰撞比特的位置信息,开启部分比特识别机制,执行步骤(4);④若碰撞比特数n>log2(M),阅读器重新发送本轮查询前缀信息后面加上反演时隙标识码‘1’,开启反演时隙识别模式,执行步骤(6)、步骤(7)。
(4)前缀匹配的标签取出碰撞位所对应比特数据转化为十进制,生成长度为M的全0序列并将其对应位置比特置‘1’后重新响应。
(5)阅读器重新接收标签数据,根据碰撞信息解读出上轮查询时隙响应标签碰撞位传输比特数据,替换掉碰撞比特后与查询前缀合并存入前缀堆栈。
(6)前缀匹配的标签首先遍历事先存储好的分组信息,确定自身分组后选择相应的时隙发送查询前缀后M位标签数据。
(7)阅读器按分组顺序将接收到的比特信息与参考码字异或,得到当前反演长度下所有发送标签的M位数据信息,与查询前缀合并存于前缀堆栈。
下面通过一个实例讲解当反演长度M=4时IMBI防碰撞算法的具体工作流程,假设阅读器通信范围内存在8个ID长度为16的标签tag1~tag8,如表1所示。
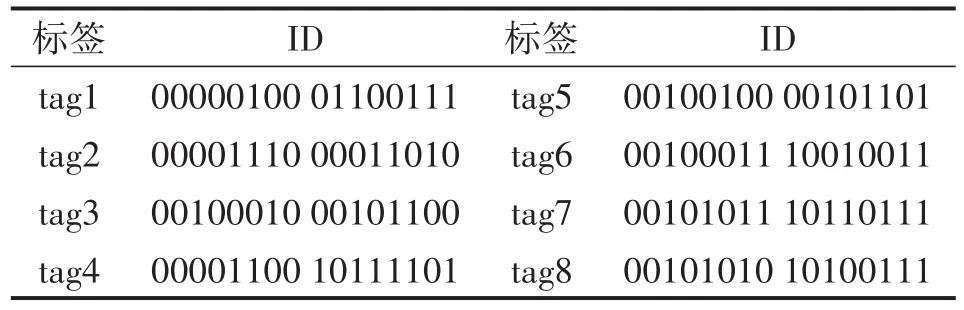
表1 实例标签ID信息
IMBI算法实例步骤如下:
(1)由于初始前缀为空,阅读器发送查询命令(ε,0),tag1~tag8均满足条件回复。阅读器以长度为4的滑动窗对标签响应进行逐段识别,检测到第一个识别段为‘00X0’,有一个比特的碰撞,则立即通知标签停止后面ID的发送,阅读器将碰撞位分别置‘0’和‘1’得‘0000’和‘0010’并将其压入前缀堆栈;
(2)阅读器从前缀堆栈取出前缀发送查询命令(0000,0),tag1、tag2和tag4前缀匹配回复后面12 bit ID信息。阅读器检测到第一个识别段为‘X1X0’,存在碰撞,通知标签停止继续发送后面8 bit ID。因为碰撞比特数为2≤log2(4),开启部分比特恢复机制;
(3)阅读器发送查询命令(0000.X1X0,0)通知标签碰撞位置为bite0和bite3。tag1、tag2和tag4分别提取出对应位置的ID信息组成新的序列‘00’、‘10’和‘11’并转化为十进制‘0001’、‘0100’和‘1000’重新发送。阅读器接收到响应信息‘XX0X’,通过碰撞的位置得到标签在碰撞位的ID序列分别为‘00’、‘10’和‘11’,分别替换0000.X1X0中的碰撞位置比特得到最终恢复序列0000.0100、0000.1100和0000.1110并存于前缀堆栈。
(4)阅读器分别发送(0000.0100,0)、(0000.1100,0)和(0000.1110,0)三个查询码,标签端tag1、tag2和tag4分别对应响应,阅读器未检测到碰撞,为识别时隙,故tag1、tag2和tag4直接识别。
(5)阅读器从前缀堆栈中取出(0010,0)开始发送,tag3、tag5~tag8均满足条件响应,滑动窗截取前4位比特‘XXXX’,由于碰撞数n>log2() 4,阅读器开启反演时隙发送反演前缀(0010,1)进行查询。
(6)tag3、tag5~tag8分别查阅事先存储的分组方案确定自身ID发送时隙并发送‘0010’后4位ID信息,tag3和tag5为第1组,tag6第2组,tag8、tag7分别为第3组和第4组。阅读器端接收到‘0XX0.0011.0101.1011’,第1组中第2位、第3位比特产生碰撞,阅读器分别将参考码字‘0000’的第2位、第3位取反得‘'0100’、‘0010’。其余3组没有碰撞产生,阅读器直接识别。将‘0100’、‘0010’、‘0011’、‘0101’和‘1011’分别与查询前缀‘0010’合并存入前缀堆栈。
(7)阅读器分别查询(0010.0010,0)、(0010.0100,0)、(0010.0011,0)、(0010.1011,0)和(0010.0101,0),tag3、tag5、tag6、tag7和tag8分别回复,无碰撞产生,为识别时隙。
(8)阅读器检测到前缀堆栈为空,识别结束。
具体识别流程如图4所示。
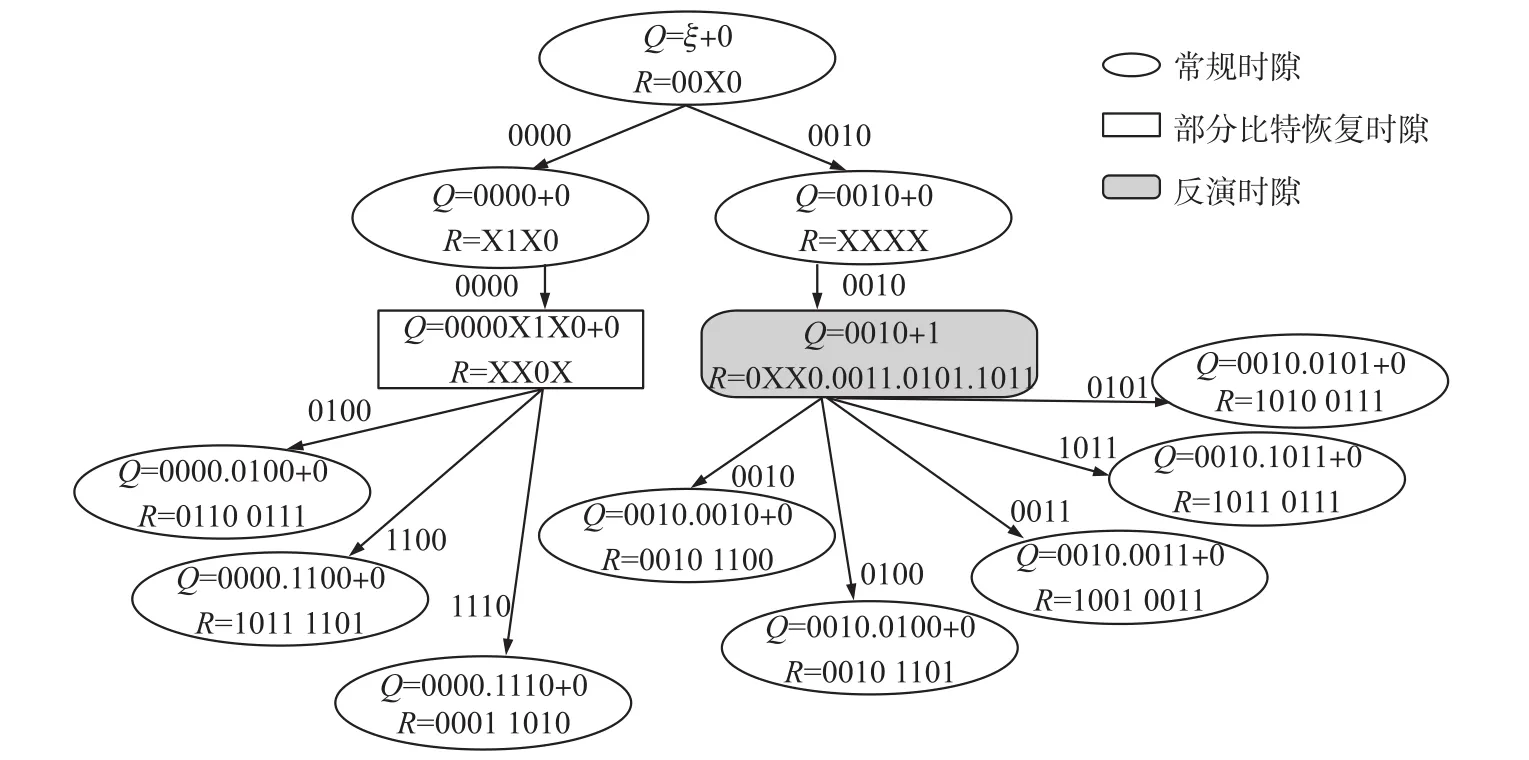
图4 IMBI算法识别实例图
4 模型验证及仿真结果分析
4.1 MBI模型验证分析
为验证该模型的正确性,文中对此算法涉及的三项性能指标进行理论逼近。设定标签ID长度为64 bit,标签分布为均匀分布,标签数量变化范围为1~1 024,每个标签循环次数为50次。图5为系统3项基本性能指标的理论模型分析与实际情况的仿真对比。不难发现,不论是系统总时隙、平均标签消耗还是系统平均时延,该模型都有良好的逼近性能。模型与实际结果存在较小误差的原因在于模型是通过统计理论建立,概率分析与实际情况必然存在一定误差,当仿真次数达到一定数量时误差会随之减小。通过以上对比分析可以证明模型对算法具有较好的逼近能力,同时证明了模型建立的正确性。
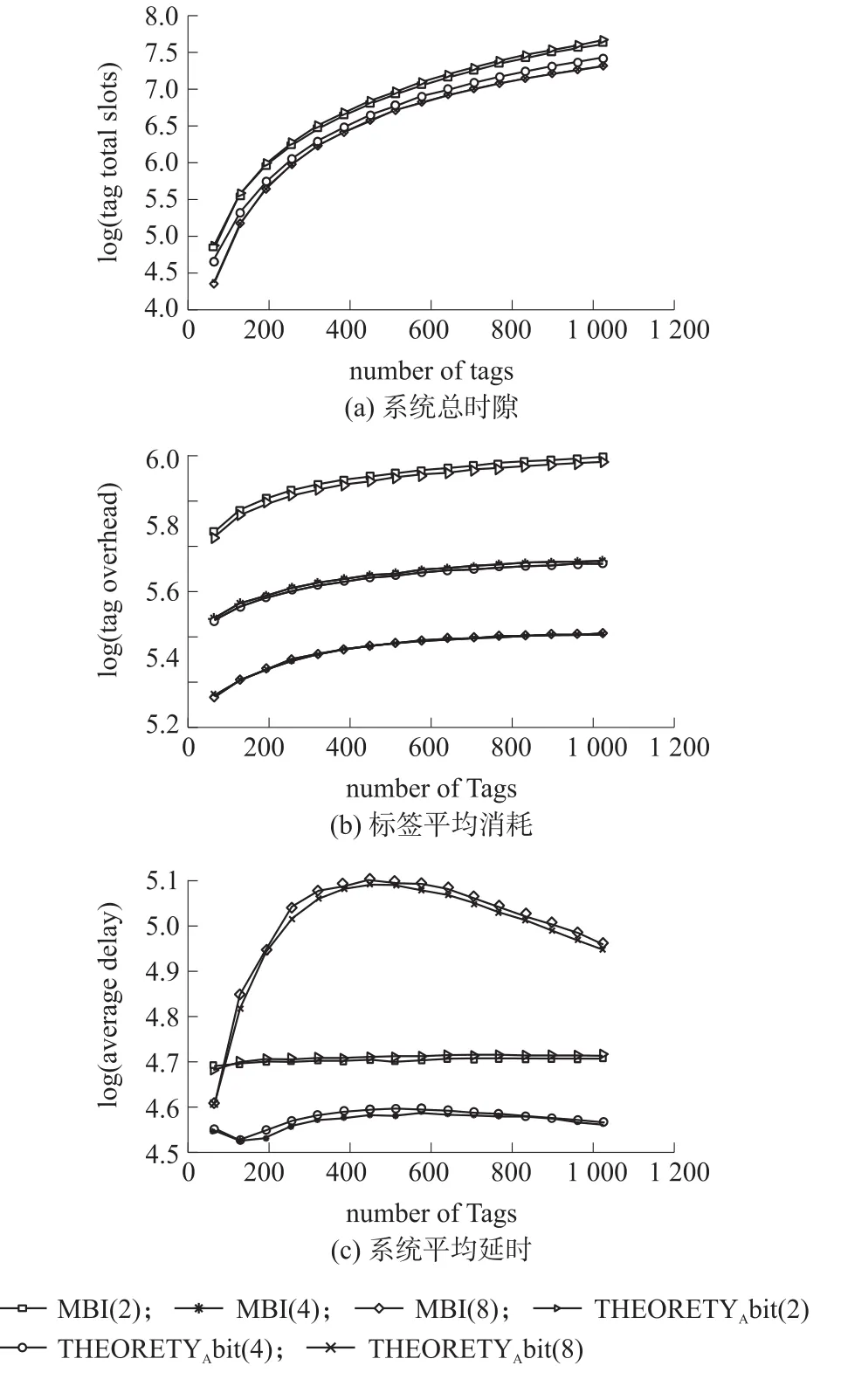
图5 模型验证结果分析
4.2 改进MBI防碰撞算法仿真分析
对提出的改进型MBI防碰撞算法(IMBI)进行仿真,仿真条件与上述模型验证一致。图6(a)~6(c)分别为IMBI算法与MBI,QT,JDS,NEAA算法所需总时隙、标签平均消耗、系统平均延时的比较。
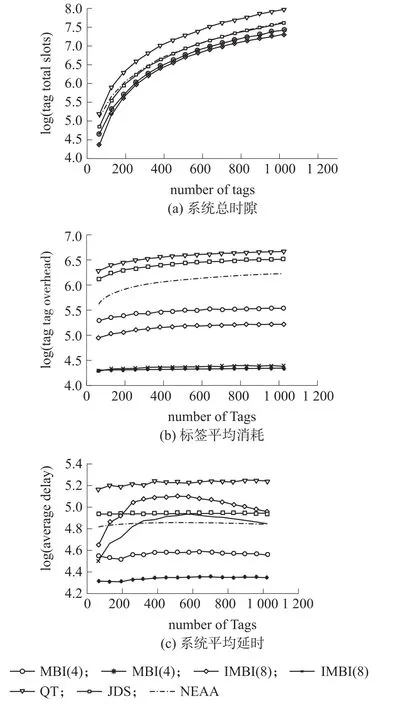
图6 改进MBI算法仿真分析
图6(a)为系统总时隙分析,可以看出,与传统树形算法相比,IMBI算法与MBI算法的系统识别时隙性能最佳,这是因为MBI类型算法采用碰撞反演识别机制,充分利用碰撞信息去除空闲时隙实现了多比特识别。MBI(4)与IMBI(4)、MBI(8)与IMBI(8)曲线重合是由于IMBI算法只针对性地解决系统标签消耗冗余及延时浪费问题,并没有对系统时隙进行改进。
图6(b)是标签平均消耗的仿真对比,由图可知IMBI算法在标签平均消耗上同样具有最佳性能。IMBI引入滑动窗及部分比特识别机制能极大地提升系统性能,M=4时标签消耗相对于MBI算法减少了近19.7%,相对于QT算法减少了32.5%。M=8时标签消耗相对于MBI算法减少了近13.9%,相对于QT算法减少近32.4%。M=8的性能提升优于M=4是由于M=4时的碰撞时隙数多于M=8,M=4的树形结构对比于M=8为纵向扩展,识别深度大于M=8,标签重复响应次数较多,故加入滑动窗后性能提升较大。
图6(c)为系统平均延时分析,与传统的QT,JDS,NEAA算法相比,MBI(4)系统延时最小,为QT的50%。MBI(8)由于存在反演时隙标签空闲分组问题,在标签数量较少时,随着标签数的增加而急剧增长。但当标签数量增大到500左右时,系统延时随标签增长呈下降趋势。IMBI算法在MBI的基础上进行改进,有效地降低了MBI(4)及MBI(8)的系统延时。M=4与M=8性能提升幅度相近在于除了滑动窗带来的系统效益外,部分比特恢复机制有效的消除了空闲分组带来的时延浪费,进一步减小了系统时间复杂度,且该机制给系统带来的效益随着M的增大而增大。
5 结语
本文从概率的角度出发,构建了MBI防碰撞算法的理论分析模型,完善了算法的理论体系。通过该模型,我们只需得知阅读器识别范围内标签数量,即可快速有效地对系统识别性能进行分析。同时,该模型逐层描述了分段碰撞反演算法的识别机制,有助于进一步的对此算法进行深入研究。此外,本文针对MBI防碰撞算法标签响应冗余及反演时隙中空闲分组延时浪费问题,引入滑动窗以及部分比特恢复机制,在不增大系统实现复杂度的基础上,大幅度提升了系统的性能,具有一定的创新性和实用性。
[1]Hugo L,Asier P,Enrique O,et al.An Energy and Identification Time Decreasing Procedure for Memory-Less RFID Tag Anti-Col⁃lision Protocols[J].IEEE Transactions on Wireless Communica⁃tions,2016(99):1.
[2]Zhang D,Wang X,Song X,et al.A Novel Approach to Mapped Correlation of ID for RFID Anti-Collision[J].IEEE Transactions on Services Computing,2014,7(4):741-748.
[3]刘明生,王艳,赵新生.基于Hash函数的RFID安全认证协议的研究[J].传感技术学报2011,24(9):1317-1321.
[4]周治平,张惠根.一种更具实用性的移动RFID认证协议[J].传感技术学报,2016,29(2):271-277.
[5]李勃,毛陆虹,张世林,等.集成于无源UHF RFID标签的宽温测范围CMOS温度传感器[J].传感技术学报,2014,27(5):581-586.
[6]Dheeraj K K,Kwan-Wu C,Raad R.A Survey and Tutorial of RFID Anti-Collision Protocols[J].IEEE Communications Surveys &Tutorials,2010,12(3):400-421.
[7]Zhu L.A Theory of RFID Anti-Collision Mechanisms[M].The Chi⁃nese University of Hong Kong(People’s Republic of China),2010.
[8]Li X.A Study of Anti-Collision Multi-Tag Identification Algorithms for Passive RFID Systems[D].University of North Texas,2010.
[9]Shao Chenglong,Kim Taekyung,Yu Jieun,et al.ProTaR:Probabi⁃listic Tag Retardation for Missing Tag Identification in Large-Scale RFID Systems[J]IEEE Transactions on Industrial Informat⁃ics,2015,11(2):513-522.
[10]Myung J,Lee W,Shih T K.An Adaptive Memoryless Protocol for RFID Tag Collision Arbitration[J].IEEE Transactions on Multi⁃media,2006,8(5):1096-1101.
[11]Chen Y H,Horng S J,Run R S,et al.A Novel Anti-Collision Algo⁃rithm in RFID Systems for Identifying Passive Tags[J].IEEE Transactions on Industrial Informatics,2010,6(1):105-121.
[12]Jihoon Myung,Wonjun Lee,Jaideep Srivastava,et al.Adaptive Bi⁃nary Splitting for Efficient RFID Tag Anti-Collision[J].IEEE Communications Letters,2006,10(3):144-146.
[13]Landaluce H,Perallos A,Bengtsson L,et al.Simplified Computa⁃tion in Memoryless Anti-Collision RFID Identification Protocols[J].Electronics Letters,2014,50(17):1250-1252.
[14]Su J,Sheng Z,Hong D,et al.An Effective Frame Breaking Policy for Dynamic Framed Slotted Aloha in RFID[J].IEEE Communi⁃cations Letters,2016,20(4):692-695.
[15]Wang Y,Liu Y,Leung H,et al.A Multi-Bit Identification Protocol for RFID Tag Reading[J].IEEE Sensors Journal,2013,13(10):3527-3536.
[16]Wang Y,Liu Y,Leung H,et al.A Segment Collision Inversion Protocol for RFID Tag Reading[J].IEEE Communications Let⁃ters,2013,17(10):2008-2011.
[17]Landaluce H,Perallos A,Zuazola I J G,et al.A Fast RFID Identifi cation Protocol With Low Tag Complexity[J].IEEE Communica⁃tions Letters,2013,17(9):1704-1706.
[18]耿素云,屈婉玲,王捍贫.离散数学教程[M].北京:北京大学出版社,2002.
[19]刘祎.基于多比特识别的RFID标签防碰撞算法[D].南昌:南昌大学,2013.

李 唯(1991-),女,南昌大学信息工程学院硕士研究生,主要研究方向为RFID防碰撞协议及无线通信,1522151783@ qq.com;

王玉皞(1977-),男,南昌大学博士生导师,主要研究方向为宽带无线通信,雷达通信一体化,RFID等,wangyuhao@ncu.edu.cn;

孙 宇(1989-),男,南昌大学信息工程学院硕士研究生,主要研究方向为RFID防碰撞协议及无线通信,1043360657@ qq.com。
An Improved MBI Anti-Collision Algorithm for Identification of RFID Tag*
LI Wei,WANG Yuhao*,SUN Yu,ZENG Jian
(College of Information Engineering,Nanchang University,Nanchang 330031,China)
Based on the in-depth study of MBI,a model for perfecting the theory of MBI is established from the view⁃point of probability in this paper.Furthermore,a improved Multi-Bit Identification Protocol(IMBI)is proposed to re⁃duce the communication overhead of the conventional MBI algorithm.By means of introducing sliding window and partial bits recovery mechanism,the proposed algorithm can solve the problems of tag response redundancy in regu⁃lar slot and idle groups in inversion slot simultaneously.In addition,it improves the efficiency of recognition in RFID system without increasing any time complexity.The simulations reveal that the model established has good ap⁃proximation performance.And the proposed algorithm has a better performance on tag average consumption and sys⁃tem delay,thus it improves the ability to deal with massive tag data.
RFID;MBI;Theoretical Analysis;sliding window;partial bits recovery mechanism
TP393
A
1004-1699(2016)11-1711-07
EEACC:6150P;6110;6140 10.3969/j.issn.1004-1699.2016.11.014
项目来源:面向动态本地无线环境的电波传播特征认知方法研究项目(61261010);宽带无线通信与雷达感知融合系统关键技术研究项目(20142BCB23001)
2016-05-10 修改日期:2016-07-04
