一种高效的RFID系统冗余阅读器消除算法
2018-09-21郭稳涛何怡刚
郭稳涛,郑 剑,2,李 兵,,何怡刚
(1.湖南机电职业技术学院,湖南 长沙 410151;2.湖南大学电气与信息工程学院,湖南 长沙 410082;3.合肥工业大学电气与自动化工程学院,安徽 合肥 230009)
0 引言
射频识别技术(Radio Frequency Identification,RFID)作为物联网代表性核心技术,已经广泛应用于物流、交通运输、医疗、定位导航等各领域.[1]一个完整的RFID系统通常包含标签、阅读器、中间件[2]和后台应用系统.为保证区域标签能够完全被识别,RFID系统往往会部署过多的阅读器,这可能带来相邻阅读器的射频信号重叠产生相互干扰,同时,同一标签会多次被不同的阅读器读取,产生大量冗余数据.如何消除冗余阅读器是RFID系统领域中数据清洗重大研究问题.冗余阅读器的消除问题已被证明是NP(Non-deterministic Polynomial)问题[3].
冗余阅读器消除问题一直是国内外研究学者关注的热点.具有代表性的研究工作包括RRE(Redundant Reader Elimination)算法[4]、LEO(Layered Elimination Optimization)算法[5]和MRRE (Middleware-Base Redundant Reader Elimination)算法[6].RRE 算法使用阅读器内可读取标签数量为权重,保证权重大的阅读器对标签具有更大地写入锁定优先级,迭代直至所有标签被锁定,未锁定标签的阅读器即为冗余阅读器.LEO算法思想是RRE算法针对某些系统拓扑结构失效而进行的进一步改进,保证标签首次被阅读器读取时即被写入锁定,未锁定标签的阅读器即判为冗余阅读器.这两个算法需要标签具有写锁定存储功能,同时要求阅读器对标签写距离与读距离相等,频繁写操作浪费时间,增加系统的负担,影响系统性能.MRRE算法在RFID中间件建立阅读器和标签二维数组,对该数组进行迭代计算.根据阅读器之间重叠标签的数量判断是否为冗余阅读器,该算法避免了对标签的写锁定操作,从全局上建立阅读器与标签间的对应关系.在系统的冗余检测率、系统标签信息量和覆盖率等方面具有一定的优势,但是该算法需要建立全局的阅读器与标签对应数组和在该数组的迭代操作,尤其迭代终止条件(需要迭代矩阵的元素全为0)极为苛刻,对系统中部署大量的阅读器和标签时,需要较大的存储容量,使算法的复杂性急剧上升,算法的可扩展性差.[7-8]
由于完成消除冗余阅读器是一个NP问题,因此,如何在冗余阅读器的消除率和算法额外开销取得较好的平衡是判断一个冗余阅读器消除算法优劣的重要指标.本文提出了友邻阅读器竞争冗余消除算法NRCEA (Neighbor-Reader Competitive Elimination Algorithm).该算法主要思想是比较相邻阅读器的共同标签数,用来量化阅读器间的信息汇聚度,汇聚度越高的阅读器表明能够识别的标签越多,在网络中发挥作用越大;汇聚度低的阅读器表明可能分布在系统的边缘地带(可读标签数为0的阅读器除外).这两种阅读器在消除算法中最应该保留,这样分别从信息汇聚度低和高的两种情况出发,消除网络中重叠标签,直至最后阅读器可读标签集不再变化为止,可读标签集为空的阅读器即为冗余阅读器.为了验证所提出算法的性能,将NRCEA消除算法与典型的RRE算法和LEO算法进行比较,NRCEA消除算法具有阅读器检测率高和系统部署更合理的优点,同时,与MRRE算法相比具有更低的复杂性.[9-10]
1 冗余阅读器消除算法
冗余阅读器收集标签的功能可以被周围其他阅读器替代,不影响RFID系统的功能,因此,判断系统中标签的归属是去除冗余阅读器的有效途径.阅读器读取标签受信号强弱的限制,具有一定地域性,只能读取周围一定范围的标签,本文提出的冗余阅读器消除算法基于该思想,比较相邻阅读器的可读标签,与其他算法相比,可以极大地降低算法的搜索空间.[11-12]
1.1 阅读器信息汇聚度
RFID系统中部署大量的标签T和阅读器R,且存在大量的冗余阅读器,这些阅读器射频信号强弱相同,读取标签的范围相同,读取的范围记为d.RFID中间件可接受并存储阅读器发送的标签信息,并且可以得到阅读器i在系统部署区域的坐标,记为〈xi,yi〉.
(1)
在中间件中,通过距离判别函数得到系统中每个阅读器的相邻阅读器集,使用一个二元组〈TS,RS〉来表示阅读器的信息,其中TS表示阅读器可读标签集,RS来表示相邻阅读器节点集.根据相邻阅读器节点集RS可以将可读标签集TS中的标签进行分类,共享标签集TS1和孤立标签集TS2,对阅读器i使用的描述公式为:
∀j∈RSi∧∀r∈TSj∧∃r∈TSi→r∈TSi1;
TSi2=TSi-TSi1.
(2)
为了精确刻画相邻阅读器相似程度,对有多个阅读器共享的同一标签,需要重复计算多次,加入到共享标签集TS1中.孤立标签集TS2如果不为空,则表示该阅读器需要独自读取某些标签,标记为非冗余阅读器.使用max来标记系统中的所有标签数,定义相邻阅读器相似度用来刻画阅读器在系统中间可读标签的相似程度.[13-14]
定义1阅读器相邻相似度.阅读器i的相邻相似度可以表示为
α=|TS1|/max.
(3)
|TS1|表示共享标签集的数目,α∈[0,1].
定义2阅读器信息汇聚度.阅读器i的信息汇聚度可以表示为
IAi=w*α(1-w)*|TS|/max.
(4)
其中:w∈[0,1],w取不同值,表示相邻相似度和可读标签数间的比重.阅读器信息汇聚度刻画了当TS2≠∅时,阅读器在系统中承担读取共享标签和总标签的比重,w值越大,表示阅读器承担读取共享标签的功能越大,在阅读器信息汇聚度的量化指标中占据的比重越大.图1为一个简单的RFID冗余阅读器拓扑.
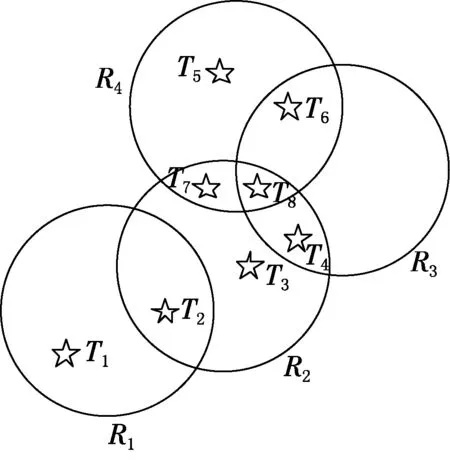
图1 RFID冗余阅读器举例
根据上述概念的定义,可以分别得到可读标签集、共享标签集和孤立标签集:
TSR1={T1,T2},TSR11={T2},TSR12={T1};
TSR2={T2,T3,T4,T7,T8},
TSR21={T2,T4,T7,T8,T8},TSR22={T3};
TSR3={T4,T6,T8},
TSR31={T4,T6,T8,T8},TSR32=∅;
TSR4={T5,T6,T7,T8};
TSR41={T6,T7,T8,T8},TSR41={T5}.
这里,max=9,假设取w=0.7,可以得到信息汇聚度:
首先,TSR32=∅可以看出阅读器R3的可读孤立标签集为空,则该阅读器可能为空,从阅读器的信息汇聚度值相对大小可知,阅读器R2在系统中承担读取标签任务的比重较大,从该阅读器开始进行消减标签,直至阅读器可读标签为零为止.
1.2 算法描述
友邻阅读器竞争冗余消除算法NRCEA的基本思想:首先,RFID系统中各阅读器发送读取标签广播,收集可读范围内所有标签标志,构成可读标签集TS.然后,各阅读器将自身位置坐标〈xi,yi〉和可读标签集TS发送给系统中间件,根据中间件公式(1)计算各阅读器的相邻阅读器集RS,并根据公式(2)将可读标签集TS分成共享标签集TS1和孤立标签集TS2.最后,按照以下步骤判别冗余阅读器[15]:
步骤1中间件根据公式(3)和(4)计算阅读器相邻相似度和信息汇聚度,剔除那些孤立标签集TS2不为空的阅读器,判别为非冗余阅读器,放入非冗余阅读器集NRR.
步骤2从阅读器集中任意选择一个阅读器Ri,与相邻阅读器集TS的阅读器Rj进行比较,如果存在共同标签:
(1) 如果阅读器Ri∈NRR,则从阅读器Rj的可读标签集RS中删除该标签;
(2) 如果阅读器Rj∈NRR,则从阅读器Ri的可读标签集RS中删除该标签;
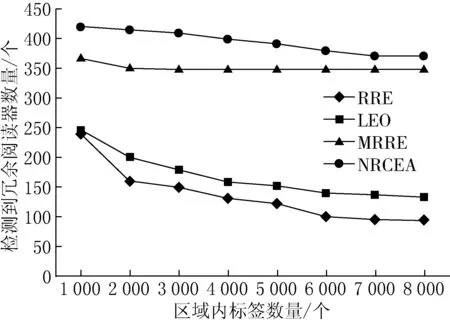
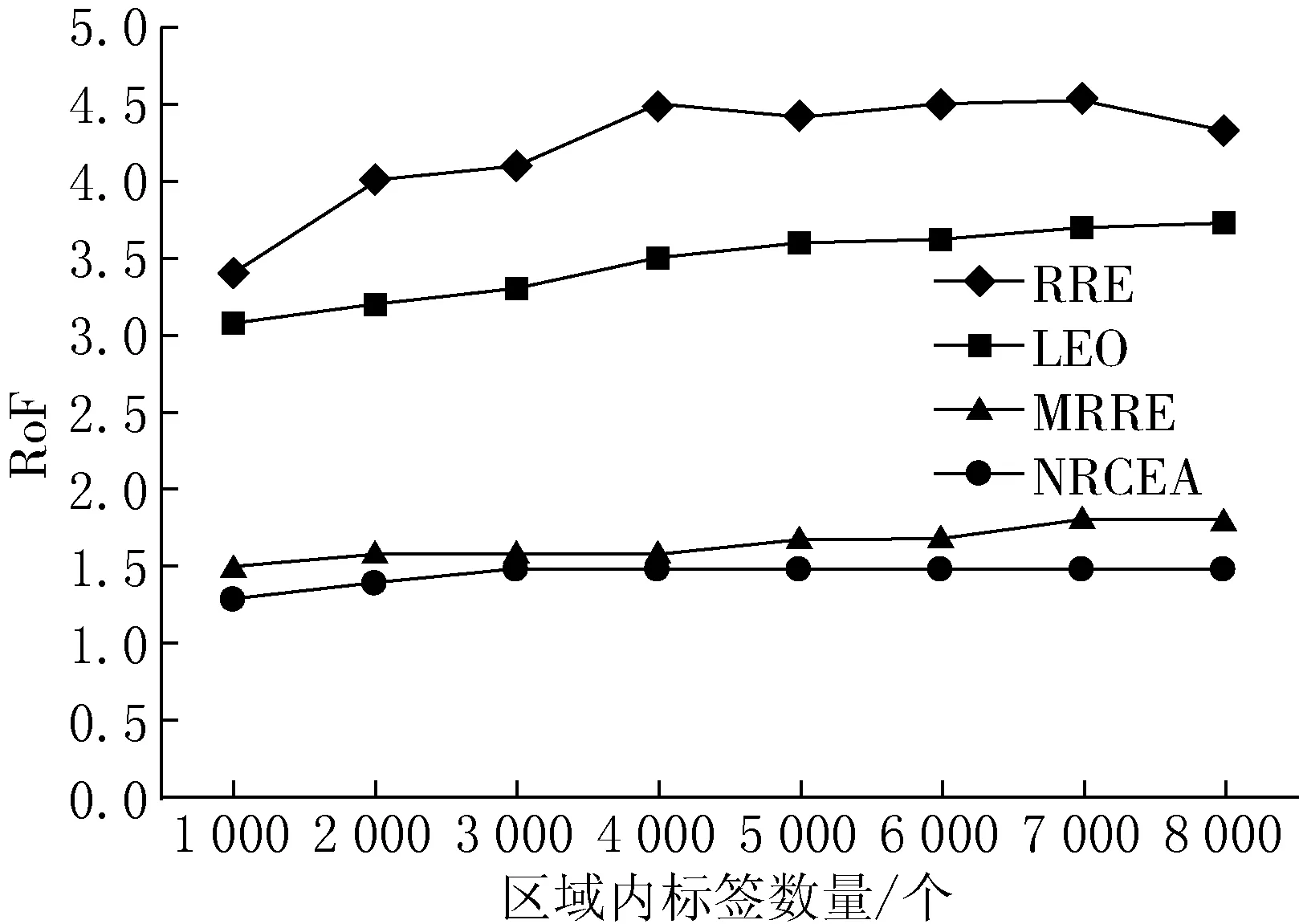
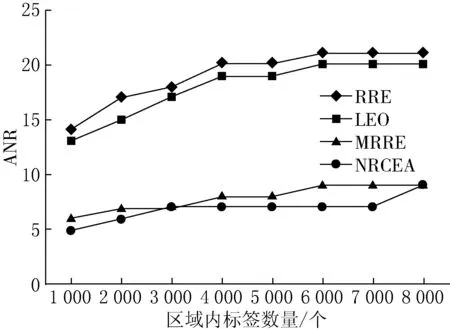
(3) 如果IAi (4) 如果IAi≥IAj,则从阅读器Rj的可读标签集RS中删除该标签. 步骤3不断迭代遍历步骤2,直至阅读器集中所有元素遍历为止. 步骤4计算判别冗余阅读器,如果可读标签集不为空,则为冗余阅读器,放入非冗余阅读器集NRR. 1.2.1 算法伪代码 第1步:初始化,得到所有阅读器可读标签集和相邻阅读器集. Set NRCEA(Set Rds,Set tags,flaot d;float w,float Thresd){ Set NRR=∅,RR=∅; for each(reader rd1 in Rds){ rd1.TS.put(rd.readtargers()); for each(reader rd2 in Rds $$ rd2!=rd1){ if(rd2.RS.contain(rd1)) rd1.RS.put(rd2); elseif(!abs(rd1.x-rd2.x)>2*d&& !abs(rd1.y-rd2.y)>2*d) rd1.RS.put(rd2); } }. 第2步:得到共享标签集TS1和孤立标签集TS2. for each(reader rd1 in Rds){ for each (reader rd2 in rd1.RS) for each (tag t in rd1.RS) if(t in rd2.TS) rd1.TS1.put(t); rd1.TS2=rd1.TS-rd1.TS1; }. 第3步:计算每个阅读器的信息汇聚度. for each(reader rd1 in Rds) rd1.ia=w*rd1.TS1.num()/tags.num()+(1-w)*rd1.TS.num/tags.num(). 第4步:迭代遍历阅读器集,计算非冗余标签集和冗余标签集. for each(reader rd1 in Rds) for each (reader rd2 in rd1.RS) for each (tag t in rd1.RS) if(rd2.TS.contain(t)){ if(NRR.contain(rd1)){ rd2.TS.delete(t); break; } if(NRR.contain(rd2)){ rd1.TS.delete(t); break; } if(!rd1.TS2.empty()){ NRR.put(rd1); rd2.TS.delete(t); break; } if(!rd2.TS2.empty()){ NRR.put(rd2); rd1.TS.delete(t); break; } if (rd1.ia rd1.TS.delete(t); break; } rd2.TS.delete(t); }. 第5步:判断冗余阅读器. for each(reader rd1 in Rds) if(!NRR.contain(rd1)&&!rd1.TS.empty()){ NRR.put(rd1); RR=Rds-NRR; return RR; }. 1.2.2 算法流程 在迭代过程中,相邻阅读器间具有共同标签的阅读器,根据其信息汇聚度值竞争性删除相同的标签,能够保留可读标签数量和相同标签数大的阅读器,该算法流程如图2所示. 图2冗余阅读器消除算法流程 设系统中存在n个阅读器,每个阅读器可读标签平均数量为r,相邻阅读器平均数量为m.系统中标签数为n*r. 首先,RRE算法和LEO+RRE算法在消除冗余阅读器时,需要保存每个标签的锁定的阅读器信息,因此,空间复杂度为系统中标签的数量,即O(n*r);MRRE算法需要保存一个所有阅读器与所有标签一一映射的矩阵,其所有空间复杂度为O(n*n*r).而NRCEA算法消除过程中为每个标签保存一张可读标签集合和相邻阅读器集合,其空间复杂度为O(n*(w+r)).因此,空间代价要比MRRE算法小得多. 其次,RRE算法和LEO+RRE算法需要对每个标签执行写锁定操作,其写操作复杂度为O(n*r),因写操作时间要远远大于读操作时间,因此,该算法的额外写操作时间开销比较大.MRRE算法和NRCEA算法不要写操作,需要遍历所有的阅读器和标签,其最差时间复杂性均为O((n*n*r)2). 因此,NRCEA算法空间复杂度要低于MRRE算法,时间复杂度要优于RRE算法和LEO+RRE算法,能够在时间和空间上均具有明显的优势.同时,NRCEA算法设置2种阅读器保留策略:一种是保留读取孤立标签集的阅读器;另一种是通过计算阅读器信息汇聚度作为相邻阅读器竞争读取标签的权重,保留信息汇聚度大的阅读器,从而使算法在系统标签信息量和覆盖率、系统部署更合理性. 实验环境基于Matlab 7.0,参数同文献[4-6],实验区域为1 000×1 000单位长度,随机分布500个阅读器和若干标签,实验标签的数量范围为[1 000,8 000],设定阅读器读距离d=50,阅读器对标签写距离与读距离比例为0.7[7].各种实验分别进行10次,对实验数据取平均值. 由于LEO算法和RRE算法需要对标签进行写锁定操作,因此代价比较大,性能相对较低.MRRE算法和NRCEA算法在中间件上进行,受RFID工作特性影响较少,其性能较优. 各算法可扩展性性能可以使用系统标签数量变化进行描述.4种算法随标签数量变化的冗余消除结果如图3所示,由图3可以看出,本文提出的NRCEA算法和MRRE算法明显优于LEO和RRE算法,同时,NRCEA算法的冗余阅读器检测率比MRRE算法提高了6%~14%.因为NRCEA算法优先考虑处于边界和孤立阅读器,其他阅读器共享标签消除时依据阅读器信息汇聚度,能够保存读取更多标签的阅读器,将阅读信息量少的阅读器尽可能地消除掉. 图3 各算法去冗余消除结果 系统标签信息量可以使用标签总量溢出率(rate of overflow,RoF)来量化,定义为 (5) 其中:NRR表示系统冗余阅读器消除后非冗余阅读器集合;TS(Ri)表示阅读器Ri可读取的标签集合;NoT表示系统标签总数;Rr表示NRR对标签的平均读取率. 各算法随标签数量变化的RoF性能变化如图4所示.NRCEA算法和MRRE算法的RoF值接近1,远远小于RRE算法和LEO算法,表明冗余阅读器消除后阅读器间共享的标签数量特别少. 图4 各算法RoF性能比较 系统部署合理性是指系统应尽量减少RFID对标签读写冲突发生的概率.通过减少各标签周围覆盖的阅读器的数量,降低阅读器间冲突的发生概率.因此,使用阅读器的平均相邻阅读器数量(average quantity of neighbor readers,ANR)来衡量各算法的系统部署合理性,定义为: RNS(Ri)={Rj|Rj∈RS(Ri)∧Rj∈NRR}; (6) 图5 各算法ANR性能比较 其中:RNS(Ri)表示阅读器Ri在冗余消除后相邻阅读器集;|·|表示对应集合内元素数量. 各算法随标签数量变化的ANR指标曲线如图5所示.由图5可以看出,NRCEA算法明显优于RRE算法和LEO算法,取得与MRRE算法相同的效果,但是算法的复杂度明显低于MRRE算法. 为了解决RFID系统中冗余阅读器的多读问题,本文提出了一种基于阅读器信息汇聚度的高效RFID系统冗余阅读器消除算法NRCEA.与现有的典型RRE算法和LEO算法相比,该算法不需要对标签写锁定操作,不受RFID工作特性的影响.与MRRE算法相比,该算法在存储空间上具有更低的复杂度.仿真实验结果表明,NRCEA算法在算法性能、系统标签信息量和部署更合理性,具有更高的冗余阅读器检测率.
1.3 算法分析
2 算法实验与结果分析
2.1 算法性能分析
2.2 系统标签信息量分析
2.3 系统部署合理性分析
3 结束语
