基于时/频ICA的PMC模型卷积噪声估计方法研究
2016-09-21张贝贝
吕 钊,张贝贝,张 超
(1. 安徽大学 计算机科学与技术学院,安徽 合肥 230601;2. 安徽大学 信息保障技术协同创新中心,安徽 合肥 230601)
基于时/频ICA的PMC模型卷积噪声估计方法研究
吕钊1,2,张贝贝1,张超1,2
(1. 安徽大学 计算机科学与技术学院,安徽 合肥 230601;2. 安徽大学 信息保障技术协同创新中心,安徽 合肥 230601)
为提高卷积环境下语音识别系统的鲁棒性,提出了一种基于时/频ICA(independent component analysis)的卷积噪声模型估计方法.所提算法首先使用ICA方法从含噪语音信号中提取纯净语音信号的短时功率谱,然后在MEL滤波器组域内将含噪语音的短时谱减去纯净语音的短时谱,并根据去噪后卷积噪声的短时谱估算其HMM(hidden markov model)模型.在仿真和真实环境下进行了语音识别实验,其识别正确率相比较传统的卷积噪声估计方法分别提升了4.70%和4.75%.实验结果表明,论文所提算法能够实现对卷积噪声的精确估计,并有效提升卷积噪声环境下语音识别系统的性能.
语音;独立分量分析;PMC(parallel model combination)模型;卷积噪声
众所周知,对语音识别系统而言,在噪声环境下,使用由纯净语音所训练的语音识别器进行识别时,其性能会显著下降,甚至无法识别,这是因为环境的改变使训练模型与测试模型产生了失配.为了克服这种现象,研究者们最初曾尝试手工录制测试环境中的噪声信号,并将其与训练时所使用的纯净语音进行叠加,然后对这种混合后的信号建立模型.可以看出,这种做法优点是简单、易行,然而,缺点也是显而易见的:1)识别时的噪声环境与事先所录制的噪声环境不可能完全相同,这将限制系统的识别正确率;2)为了获取不同噪声环境下的识别模型,在所有的噪声环境下都需要训练新的模型,其工作量非常大,故该方法不适用于大词汇量的语音识别系统.为了解决上述问题,一种直接采集环境噪声数据并通过失配函数将所采集到的噪声模型与纯净语音模型进行合并的思路被提出.该方法实现了噪声环境下纯净语音模型到含噪语音模型的自动转换,有效提高了语音识别系统的鲁棒性.其中,并行模型合并PMC[1](parallel model combination)、模型组合[2]及模型分解[3]等算法都是该思路的典型应用.
在上述模型补偿方法中,PMC方法由于具有使用相对简单且能够有效描述真实噪声环境下噪声对纯净语音模型的影响等优点,因此应用更为广泛[4-6].然而,到目前为止,人们对加性PMC模型补偿进行了较为深入的研究,但在真实录音场景下,由于语音传感器所采集到的信号不仅包含着说话人的直达波信号,同时还包含着由房间内的墙壁、桌椅等多种不同物体的反射、折射、散射而生成的二次信号,所以接收端所接收到的信号不再是语音与噪声的简单叠加,而用卷积来形容这一混合过程则更为恰当些[7-8].因此,传统的加性PMC补偿方法将不再适用,同时,对卷积噪声的估计是否准确也直接影响到模型补偿的效果.为了解决上述问题,笔者在推导卷积PMC模型的基础上,提出了一种基于时/频ICA(independent component analysis)的卷积噪声估计算法,用以实现卷积环境下对纯净语音模型的补偿.
1 卷积环境下PMC模型补偿方法
PMC方法的基本工作原理是,首先采集背景环境下的噪声数据,对其训练以生成相应的噪声模型,通过失配函数将噪声模型与纯净语音模型进行合并,最终得到含噪语音模型[1].
在卷积噪声环境下,含噪语音信号在第j个Mel滤波器的总输出功率oj(t)可以表示为语音信号功率谱与噪声信号功率谱相乘的形式,即
(1)
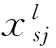
(2)
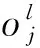
(3)
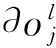
为了求取模型补偿公式,对式(2)两边同时取均值,可得
(4)
如果令
(5)
则将式(5)代入式(4)中可得卷积噪声环境下静态对数谱的Log-Add补偿公式,即
(6)
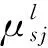
(7)
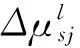
2 基于时/频ICA的噪声模型估计方法
在双入双出条件下,基于时/频ICA的噪声模型估计方法原理框图如图1所示.
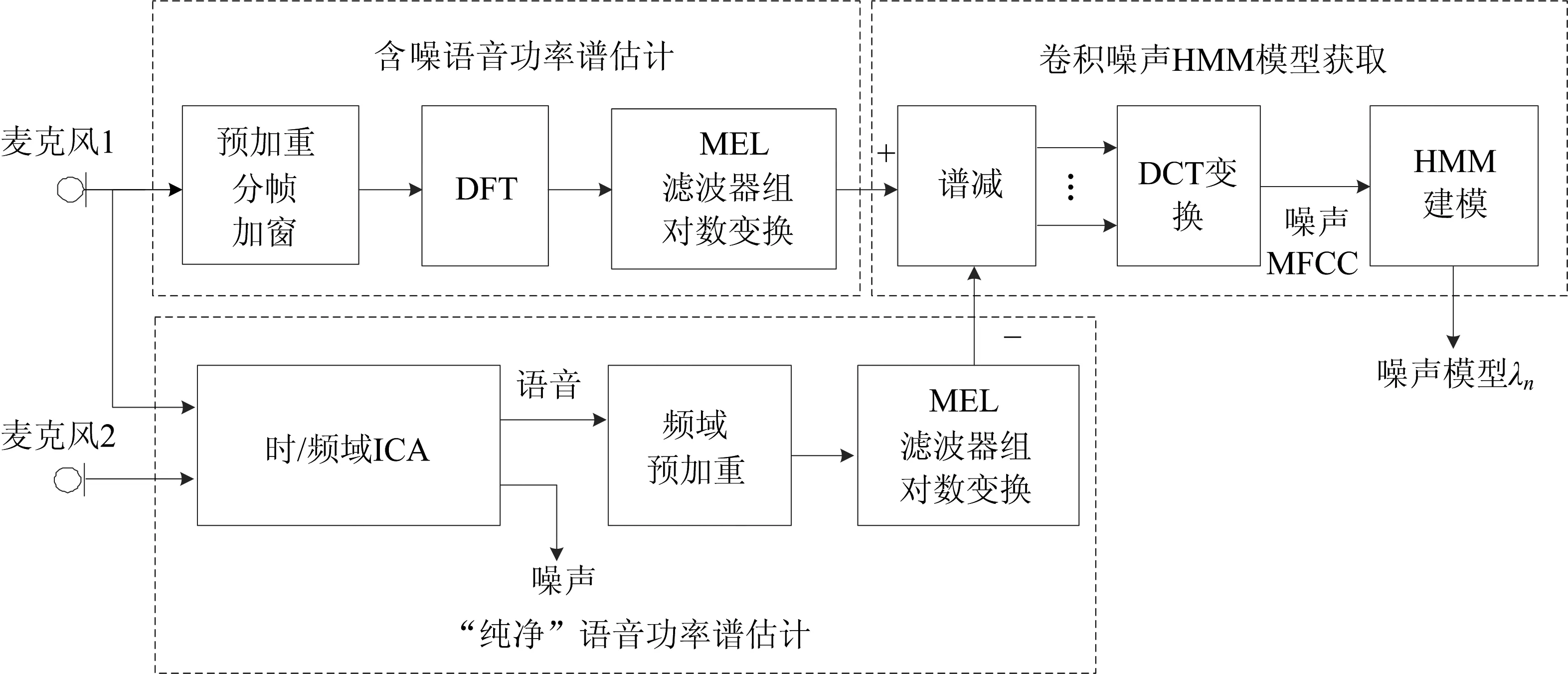
图1 基于时/频ICA的噪声模型估计方法原理框图Fig.1 Block diagram of the convolutive noise estimator based on time/frequency ICA
从图1中可以看出,算法主要由含噪语音功率谱估计单元、纯净语音功率谱估计单元以及卷积噪声HMM模型获取单元3部分组成.为了计算卷积DCT(discrete sine transform)的HMM参数,算法首先由含噪语音功率谱估计单元估算出由麦克风1所采集到的包含着语音与噪声的混合输入信号的功率谱;然后,由纯净语音功率谱估计单元对麦克风1与麦克风2所采集到的两路语音信号通过时/频ICA方法估算纯净语音的功率谱;最后,在卷积噪声HMM模型获取单元内对所获取的含噪语音功率谱与纯净语音功率谱进行基于倒谱域的减法操作,并将所得结果通过DCT变换、HMM建模等步骤获取卷积噪声的HMM参数.
2.1含噪语音功率谱估计
为了估计含噪语音信号的短时功率谱,对麦克风1输入的含噪语音信号x(t)进行短时傅里叶变换,在双入双出条件下,输入信号x(t)可以表示为
(8)
其中:sj(t-k)表示源信号,P代表卷积混合滤波器的阶数,aij则表示第j(j=1,2)个声源到第i(i=1,2)个麦克风的冲激响应.对(9)式进行频点数为L的短时傅里叶变换后其频域表达式为
(9)
其中:l=0,…,L-1;fs为采样率;fl=(l/L)fs表示傅里叶变换后所得到的L个频点;τ=τ0,τ1,…,τM-1,则表示时域上滑动窗的起始位置;win(t)表示窗函数,通常选用汉明窗.
2.2纯净语音功率谱估计
纯净语音功率谱估计是整个算法的核心,其估计的准确性决定了PMC模型补偿效果.为了实现在卷积环境下语音信号的分离,采用了时/频ICA方法,其基本处理流程如图2所示.

图2 时/频域ICA算法流程图Fig.2 Block diagram of time/frequency ICA algorithm
实现过程与含噪语音功率谱估计单元一样,这里不再赘述.需要说明的是,在对含噪语音进行短时功率谱估计时使用的是麦克风1所采集到的信号,而在该步骤中,输入的是麦克风1与麦克风2所采集到的两路观测信号,因此,经过短时傅里叶变换后,将会输出一L*M点的频域观测信号矩阵Yrci(fl,τ),其中M为滑动窗的个数.
在基于峭度极大的ICA算法中,目标函数定义为峭度的绝对值
(10)
在假设w和w*是相互独立的条件下,梯度迭代算法可表示为
(11)
排序模糊与尺度不确定性是时/频ICA算法固有缺点,其处理的好坏直接决定了信号分离的质量.
(1) 尺度不确定性的补偿
时/频ICA是对观测信号各频率点进行操作,因此,在混合与解混过程中不同频点的信号将会获得不同的增益,这就造成了尺度不确定性[9-10].
假设W(fk)为某一频点的分离矩阵,其对应的混合矩阵则可以表示为
(12)
尺度补偿的基本思路就是利用所得混合矩阵A(fk)乘以各频点的独立分量以消除增益误差,即
(13)
其中:Yj(fk,τ)与Vij(fk,τ)分别表示经时/频ICA分离后未进行尺度补偿与尺度补偿后的第j个通道的独立分量.
(2) 排序解模糊
由于ICA算法的输出排序不确定性,使得不同频点的信号在输出通道上存在着较大的随机性,为了保证各频点分离结果对应于同一个信号源,因此必须进行排序解模糊运算.Smaragdis[11]为了解排序模糊提出对相邻频点的分离矩阵进行平滑处理;Nikunen等[12]则提出使用源内包络相关最大化方法解排序解模糊;Kim等[13]还提出使用DOA方法进行排序.
为了平衡运算量与算法精度,笔者采用了K-L散度距离来进行解排序模糊.基本思路是依据相邻频点信号间概率密度函数的相似度(即距离)来进行排序,其值越小表明信号间相似度越高.定义如下
(13)
从式(13)可以看出,在求解K-L散度距离的过程中必须进行较为复杂的概率密度与积分计算,为了降低计算量,使用有限和代替积分,并使用下式估计概率密度
(14)
2.3噪声HMM参数的获取
噪声HMM参数的获取是在倒谱域上将含噪语音功率谱减去纯净语音功率谱来实现的[14],即
(15)
其中:c(l,τ)表示噪声信号的MEL滤波器组输出,Ymc(f,τ)表示含噪语音信号短时功率谱,Yrc(f,τ)表示经卷积ICA分离后的纯净语音信号短时功率谱,τ表示帧数,f为傅里叶变换后的不同频点,Wmel(f;l)表示l维MEL滤波器组.为了动态地调整噪声MEL滤波器组的输出并使之随动于输入语音信号的变化,引入了过减因子β与调节因子α来控制谱减程度,分别定义如下
(16)
其中:SNRi表示分带信噪比,定义为
(17)
其中:si与ti分别对应第i个MEL滤波器组的起始频率与终止频率.
调节因子α获取方法相对简单,即
(18)
其中:Fs为采样率,fi表示第i个MEL滤波器组的上限频率.需要说明的是,经谱减后所得的噪声功率短时谱如果是一个负数,可以通过系数γ来对c(l,τ)实现下整.最后,为了建立噪声的HMM模型,对谱减后的输出结果进行DCT变换并使用Baum-Welch算法进行参数估计.
3 实验及结果分析
实验语音来自40位讲话者共计2 000个语音段,内容为0~9阿拉伯数字,采样率为8 000Hz,量化精度为16bit,训练语音使用28位讲话者1 400个数据,测试语音使用12位讲话者600个数据.实验采用状态数为6,高斯混合数为3,由左至右的连续HMM模型,训练时的最大迭代次数为50,终止迭代概率门限为5×10-6.实验测试噪声均来源于NOISE-92数据库,噪声hmm状态数设置为1,高斯混合状态数设为3,特征参数为12维的静态倒谱系数及一阶动态倒谱系数.实验首先对原始语音信号进行预加重与汉明窗化处理,其中窗长设置为32ms,窗移为16ms,每个窗内提取12维的MFCC及其差分作为特征参数[15].噪声依然使用NOISE-92数据库,分别在白噪声、说话人噪声、飞机噪声及汽车噪声4种噪声环境下进行测试,通过式(19)所示的8阶混合滤波器进行仿真混合.

(19)
在噪声模型获取过程中,γ设为1.6,β与α分别参照式(16)与式(18)进行设定.实验中与以下3种方法进行了对比分析,具体为
(1) 方法1:将含噪语音信号直接送入纯净语音HMM模型进行识别;
(2) 方法2:采用去信号均值偏移估计方法[16]进行卷积噪声功率谱估计;
(3) 方法3:采用基于频谱域及倒谱域的最大期望估计方法[17]进行噪声功率谱估计.
实验结果如图3所示.
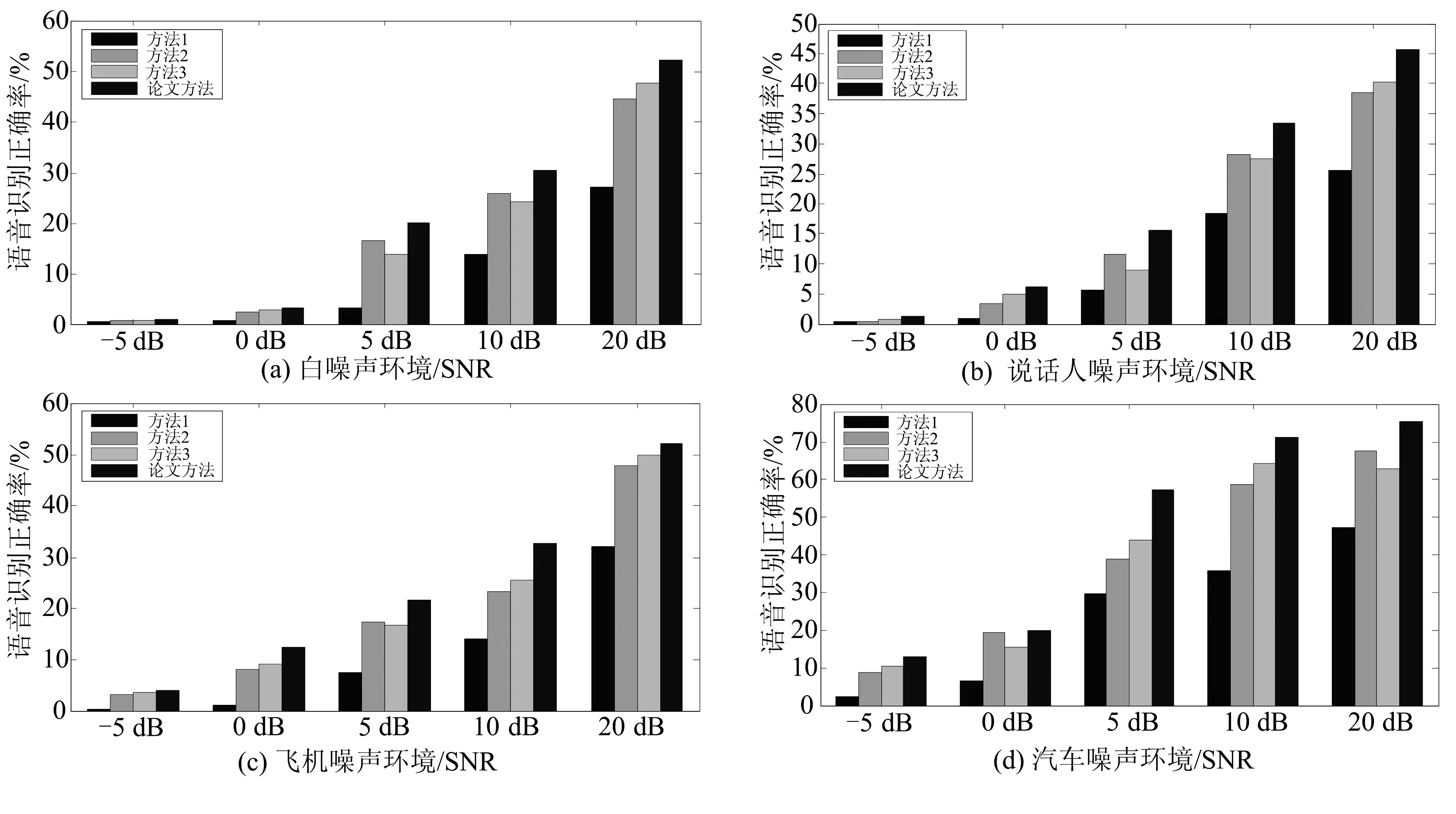
图3 仿真条件下语音识别结果Fig.3 Speech recognition results in simulation environment
从实验结果中可以看出,方法1的语音识别误识率较高,其主要原因是所提特征参数受到卷积噪声的污染而发生畸变,而进行识别的HMM模型则是由纯净语音训练所得,从而训练模型与识别模型不相匹配,最终导致识别结果较差.方法2 与方法3则有效改善这一结果,其中方法2由于直接对观察数据的特征参数迭代求平均,因此可以获得较为精准的噪声参数,其语音识别正确率有所上升,然而由于该方法需要手工标注信息,这在实际中很难做到.方法3是利用观察语料以及干净语音的模型参数对噪声参数进行估计,但是该方法由于是对加性与卷积噪声的迭代估计,在加性噪声较强时,可以获得较为精确的噪声估计,然而当加性噪声较弱时,由于其对卷积噪声的过高估计反而会引起识别率的降低.而论文方法则采用基于倒谱域的谱减方式,即通过将含噪语音短时功率谱减去由时/频域ICA方法所估计的纯净语音短时功率谱来实现对卷积噪声HMM参数估计.通过对比实验结果可以发现,对同一语音识别系统而言, 论文方法所获得的平均识别正确率相比较方法1约提升了16.57%,相比较方法2约提升了4.66%,相比较方法3约提升了4.74%,这说明论文方法在仿真卷积环境下可以准确估计噪声模型,且可用论文所推导补偿方法进行PMC模型补偿.
实验所使用的语音库及各种参数设置与仿真环境下完全相同,录制环境及各要素位置如图4所示,其中:噪声是由扬声器进行播放;语音与噪声声源高度约为1.5m;麦克阵列高度为1.3m,间距为4.1cm;语音源在麦克阵列正前方约60cm处.
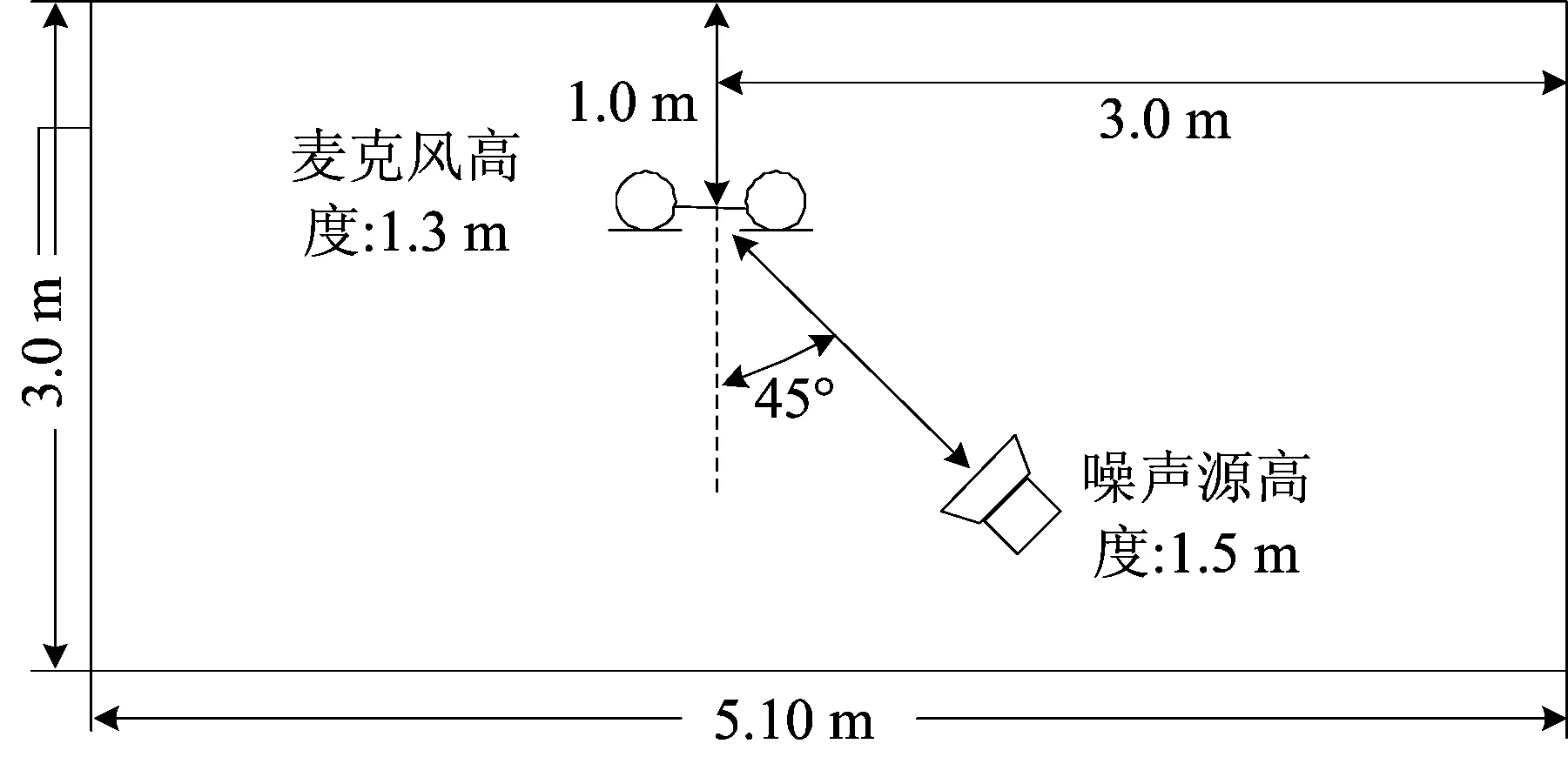
图4 实验环境(噪声源与麦克风相对位置示意图)Fig.4 Experimental environment (relative position between noise speaker and microphones)
不同噪声环境下的语音识别结果见图5.
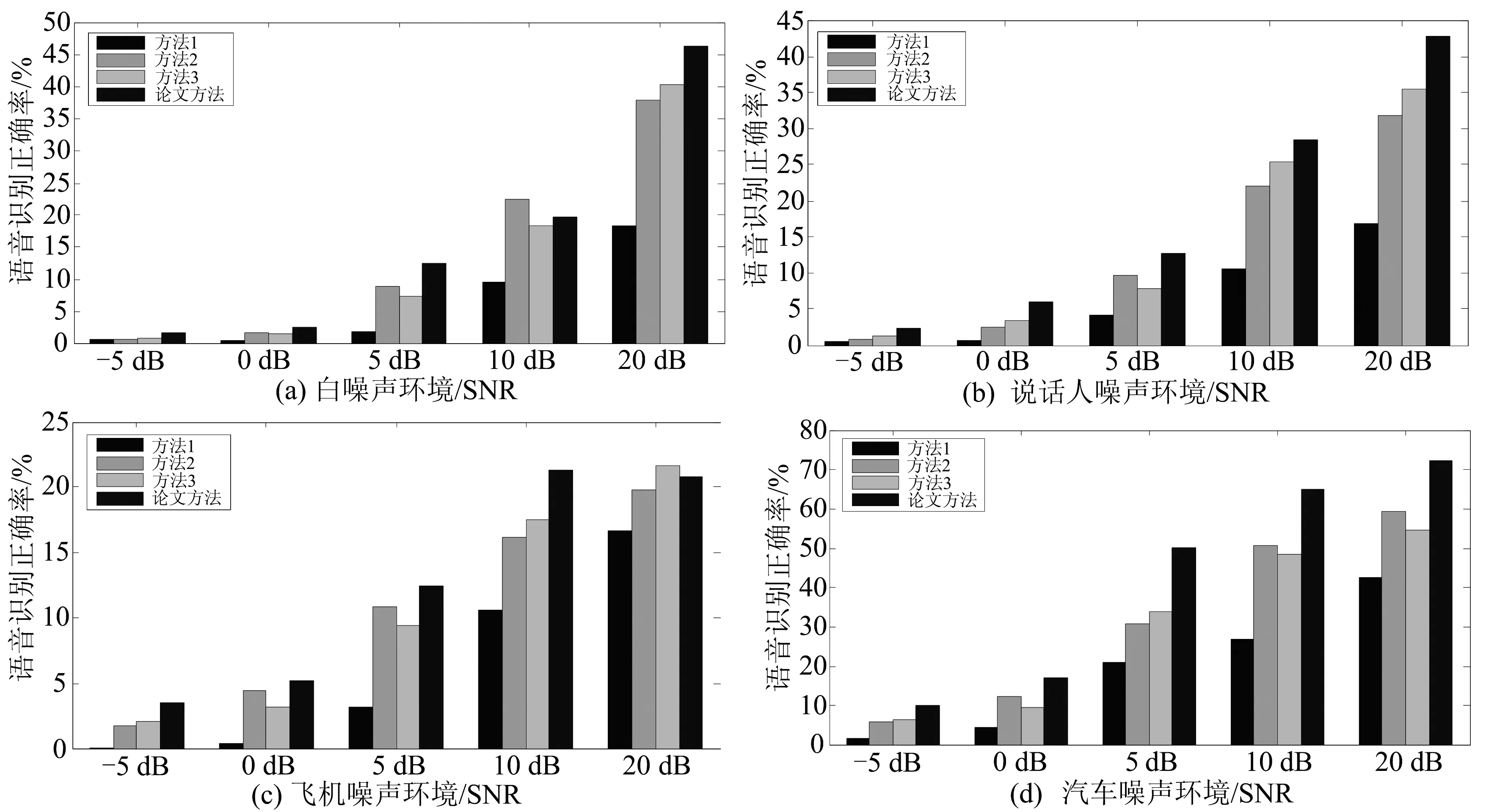
图5 真实环境下语音识别结果Fig.5 Speech recognition results in real environment
从图5中可以看出,相比较仿真环境,在真实录音环境下语音识别正确率均有所下降,其原因主要有两点:1)在真实环境下,麦克阵列所采集到的语音信号不仅包含着说话人的直达波信号,同时还包含着由房间内的墙壁、桌椅等多种不同物体的反射、散射而生成的二次信号;2)由于传输通道的不稳定性、外部电磁干扰以及麦克风自身干扰等诸多因素的存在,使得实验中所使用的滤波器维阶数远小于真实环境下的阶数,因此,在真实环境下时/频ICA的分离效果必然会有所折扣.然而,对几种算法的实验结果进行横向对比时发现,论文方法在不同噪声环境下所获得的语音识别平均正确率相比较方法1约提高了14.51%,相比较方法2约提高了4.75%,相比较方法3约提高了4.76%,结果验证了卷积PMC模型补偿方法及基于ICA的噪声估计方法的有效性.
4 结束语
为解决在卷积噪声环境下使用PMC方法进行HMM模型补偿,推导了卷积PMC模型的补偿公式,并提出了基于独立分量分析的卷积噪声估计方法.该算法使用时/频ICA算法提取纯净语音信号短时功率谱,然后在MEL滤波器组通过谱减实现噪声信号短时功率谱的估计,最后对其进行HMM建模.为了验证PMC卷积模型与噪声估计算法的可行性,在比较HMM模型均值实验的基础上进行了仿真与真实两种环境下的语音识别实验,实验结果验证了所提算法的有效性.然而,论文的实验主要是以双入双出系统为例进行的,当输入通道数大于两路时,时/频ICA算法在排序解模糊问题上将会变得更为复杂,因此,笔者下一步将会结合声源的时/频/空域信息进行多路时/频ICA排序算法的研究.
[1]GALES M J F, YOUNG S J. Robust continuous speech recognition using parallel model combination[J]. Speech and Audio Processing, IEEE Transactions, 1996, 4 (5): 352-359.
[2]MINAMI Y, FRUUI S. A maximum likelihood procedure for a universal adaptation method based on HMM composition[C]//Acoustics, Speech, and Signal Processing, ICASSP-95, International Conference on IEEE, 1995, 1: 129-132.
[3]VARGA A P, MOORE R K. Hidden Markov model decomposition of speech and noise[C]// Acoustics, Speech, and Signal Processing, ICASSP-90, International Conference on IEEE, 1990: 845-848.
[4]SIM K C. Approximated Parallel Model Combination for efficient noise-robust speech recognition[C]//Acoustics, Speech and Signal Processing (ICASSP), IEEE International Conference on IEEE, 2013: 7383-7387.
[5]YU D, DENG L. Hidden markov models and the variants[C]//Automatic Speech Recognition, Springer London, 2015: 23-54.
[6]RAO K S, SARKAR S. Robust speaker verification: a review[C]//Robust Speaker Recognition in Noisy Environments, Springer International Publishing, 2014: 13-27.
[7]ALI U, YAHYA K M, JAN T, et al. Blind separation of convolutive speech mixtures with background interference employing a Hybrid approach With ICA & PCA[J]. Sindh University Research Journal-SURJ (Science Series), 2014, 46 (2):256-280.
[8]ASAEI A, BOURLARD H, TAGHIZADEH M J, et al. Computational methods for underdetermined convolutive speech localization and separation via model-based sparse component analysis[J]. Speech Communication, 2015: 201-217.
[9]HYVARINEN A, KARHUNEN J, OJA E. Independent component analysis[M]. Manhattan: John Wiley & Sons, 2004.
[10]张磊, 张道信, 吴小培. 基于独立分量分析的心理作业诱发脑电特征增强[J]. 安徽大学学报 (自然科学版), 2008, 32 (2): 39-43.
[11]SMARAGDIS P. Blind separation of convolved mixtures in the frequency domain[J]. Neurocomputing, 1998, 22 (1): 21-34.
[12]NIKUNEN J, VIRTANEN T, PERTILA P, et al. Permutation alignment of frequency-domain ICA by the maximization of intra-source envelope correlations[C]// Signal Processing Conference (EUSIPCO), Proceedings of the 20th European, IEEE, 2012: 1489-1493.
[13]KIM M, PARK H M. Efficient online target speech extraction using DOA-constrained independent component analysis of stereo data for robust speech recognition[J]. Signal Processing, 2015, 117: 126-137.
[14]YU T, TOMOYA T, KEIICHI O, et al. Blind spatial subtraction array for speech enhancement in noisy environment[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2009; 17 (4): 650-664.
[15]HUANG X D, ARIKI Y, JACK M A. Hidden Markov models for speech recognition[M]. Edinburgh: Edinburgh University Press, 1990.
[16]BENESTY J, MAKINO S. Speech enhancement[M]. Berlin: Springer Science & Business Media, 2005.
[17]HARRELL J F. Overview of maximum likelihood estimation[M]. Berlin: Springer International Publishing, 2015.
(责任编辑朱夜明)
A study on PMC convolutive noise estimation method based on time/frequency ICA
LYU Zhao1,2, ZHANG Beibei1, ZHANG Chao1,2
(1. College of Computer Science and Technology, Anhui University, Hefei 230601, China;2. Co-Innovation Center for Information Supply and Assurance Technology, Anhui University, Hefei 230601, China)
In order to improve robustness of speech recognition system in convolutive environment, a convolutive noise estimation method based on time/frequency ICA(independent component analysis) (TD-ICA) was proposed in the paper. The algorithm firstly separated the short-time spectrum of speech and noise by TD-ICA algorithm, and then the noise short-time spectrum was acquired by subtracting the estimated clean speech short-time spectrum from the noisy speech in the mel-scale filter bank domain. Finally, an HMM(hidden Markov model) of convolutive noise was established based on the noise short-time spectrum. Experiments have been carried out in simulation and real environment, experiential results revealed that the proposed algorithm obtained the relative increasing of 4.70% and 4.75% compared with conventional noise estimation method, which validated the accuracy of estimated noise signal and proved that the proposed algorithm could effectively improve recognition ratio in convolutive noise environment.
speech; ICA; PMC(parallel model combination) model; convolution noise
10.3969/j.issn.1000-2162.2016.05.005
2016-02-16
国家自然科学基金资助项目(61401002);安徽省自然科学基金资助项目(1408085QF125);安徽省高校省级自然科学研究重点项目(KJ2014A011);光电获取与控制教育部重点实验室开放课题(OEIAM201401)
吕钊(1979-),男,安徽宿州人,安徽大学副教授,硕士生导师,博士.
TN912.34
A
1000-2162(2016)05-0024-08
