前后缀字母作特征在维吾尔语文本情感分类中的应用
2016-07-26阳木合塔尔艾尔肯
高 阳木合塔尔·艾尔肯
(1.昌吉学院计算机工程系 新疆 昌吉 831100;2.乌鲁木齐职业大学信息工程学院 新疆 乌鲁木齐 830008)
前后缀字母作特征在维吾尔语文本情感分类中的应用
高阳1木合塔尔·艾尔肯2
(1.昌吉学院计算机工程系新疆昌吉831100;2.乌鲁木齐职业大学信息工程学院新疆乌鲁木齐830008)
摘要:维吾尔语具有着黏着型语言的共同特点。维吾尔语的主要特点:在构词法上,主要通过词根和词干上加上各种词缀来形成新的词语。在阿尔泰语系突厥语族中,构词词缀十分重要,构词的词缀也十分丰富,有名词词缀、动词词缀、形容词词缀、数词词缀。由于词缀的属性的专有性,决定了其在严格对立的两个属性中在词缀上会有明显的表现。这就决定了,在情感分类中,词缀会带有情感特性,所以可用来做情感分类的特征。本文提出了使用切词缀的方式,研究了词缀在SVM-KNN分类器中的表现。
关键词:情感分类;词缀;SVM-KNN;机器学习;
0 引言
1.1文本情感分类研究的现状
文本情感分类,就是通过对文本的研究确定出文本所表达的情感倾向。此类研究,最早可以溯源到1997年Rosalincl教授提出的“情感计算”[1]。此后随着人们研究的深入,从研究方法到研究对象日益丰富。在研究对象上,出现了基于词、句、篇章级别的情感分类研究;在研究方法上,出现了基于资源的和基于统计的情感分类研究。近些年来,对文本情感分类领域的研究,主要的研究内容集中在以下几个方面:文本的情感极性分类、文本的主观性分析、词语的语义倾向性识别、观点提取等。具体的研究工作在以下几个领域进行:词的极性分类、主客观分类、基于机器学习的文本情感分类方法、基于情感词标注的文本情感分类。
1.2基于机器学习的文本情感分类方法
用机器学习的方法进行文本的情感分类研究是本文的主要研究点。下面将近年来国内外这方面的研究做简要的陈述。
Pang等人最早使用基于统计的机器学习方法来研究文本情感分类问题,使用SVM、最大熵、朴素贝叶斯等分类器,以不同的特征选择、特征降维方法对Internet上的影评文本进行情感分类研究[2]。Pang等人还实现了另外的一项工作,构造了一个基于minimum-cut的分类器,从而把文本的极性分类问题转化成求取句子连接图的最小分割问题。Lin等人把分类问题的方法用于观
木合塔尔·艾尔肯(1986-),男,维吾尔族,新疆喀什人,乌鲁木齐职业大学信息工程学院计算机系助教,研究方向:自然语言处理。点识别问题,通过基于统计的机器学习的分类算法解析词的用法获取文本的观点。Bruce、Wiebe等人使用Bayes对句子进行主客观分类。Whitelaw等人提取文本中带有形容词的词组和词组的修饰语作为特征,用向量空间文档表示,然后以SVM分类器进行分类,从而区分文档的褒贬情感倾向。[3]在句子级别的文本情感分类领域,Yi等人以模式匹配的算法进行了深入的研究。Goldberg和Zhu提出了一种新的基于图的半监督算法来解决电影评论的等级推定问题,与以前的多分类模型相比,性能大幅提高。Mei等人提出了一个新的Topic-Sentiment Mixture(TSM)概率模型,该模型能同时获得文本的情感信息和主题信息,在没有任何先验领域知识的情况下,也可以发现一个Weblog数据集所蕴含的潜在主题。Ni等人以信息增益(Information Gain)和卡方作为特征选择的方法,用Naïve Bayes、SVM和Rocchios算法对原来的情感文本作为二分类问题研究。[4]
2 基于句子级别的情感分类
句子级别的情感分类,是指鉴别情感句的情感倾向后进行归类,也可以说是一种特殊的情感文本分类。文本情感分类根据其所研究的载体的粒度可分为三类:篇章级情感分类、句子级情感分类和词/短语级情感分类。
随着互联网技术的发展,以及Web2.0的出现,人们从早期被动地接受大型的网站信息平台的信息,转变为可以自主参与到信息的发布、产生,并能自主地参与平台进行信息交流,同时各个信息的受众间也可以互相进行信息的交互。人们从被动的网站信息读取者,变成既是读取者又同时是网页内容的作者,网络上有越来越多的带有个人主观性的信息就越来越多了。为了获得民众网络上出现的对诸如人物、事件、产品的评价信息,情感分类就应运而生了。
句子级别的情感分类,属于特殊的文本情感分类,其所做的研究是以句子为载体。在用户交互性、参与性很强的Web2.0时代,网上的许多带有个人主观的信息都是以单句话的形式出现的,如电子商务网站的产品评论、网络论坛对重大事件的态度以及民众对重要的时事政策的态度,尤其是微博的出现,这一特点体现的更为充分。对句子级别的情感分类的研究对于商品经济的发展、政府重大方针政策的制定、舆情监控等都具有重要的意义。
2.1SVM分类器
机理可简单概括为:在线性可分情况下,找到一个分类超平面将二类分开,同时满足二类的距离最大,能将两个类分开的超平面通常被称作最优分类超平面。支持向量机的核心内容是:把超平面的建立问题转化为统计学习理论中的二次优化问题,根据结构风险最小化原则,从而取得最优解。设给定训练集其中xi∈X⊂Rn,y∈Y={-1,1}i=1,2,...,l。l为训练样本的总的个数,n为模式空间的维数,y为区分样本的类标。支持向量机要解决的是如下的一个最优化问题:

解决这个问题,通常依据最优化理论,转为其对偶问题

用下面的判别函数分类

2.2KNN简介
近邻法(简称NN)是一种重要的非参数模式识别方法。NN分类器的基本原理:对于一待分类的文本向量x,以所有的训练样本作为代表点,在代表点中找出K个相似的文本,然后将这K个文本作为候选类别,以文本x与K个样本的相似度的值作为衡量权重,同时设定相似度阀值,可以判定x的类别[5-8]。
KNN算法如下:

其中,x为待分类的文本,di为K个最邻近的样本中的第i个文本,cj表示所属类别;δ(di,cj)∈{0,1},当di属于cj时取1,反之取0;bj为类别cj所预先设定的阀值;sim(x,di)为待分类文本x与训练样本di之间的相似度值。
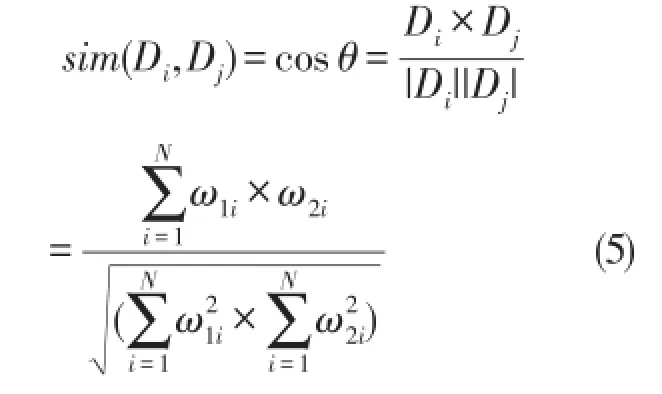
其中,ωij表示特征权重,N为特征向量的维数。
3 SVM-KNN分类器
3.1对SVM分类机理的分析
在中科院的李蓉等研究员,通过对SVM和NN的研究,从数学原理上证明了二者之间的联系,此联系由下面的定理给出。
定理SVM分类器等价于每类只选一个代表点的1-NN分类器。
3.2SVM-KNN分类器简介
将两种分类器相结合是基于上面的定理,SVM可以看成是每类只取一个支持向量作为代表点的NN分类器。该算法的基本机理:先用SVM判断带测试点和超平面的距离,对于离超平面超过某个设定阀值的点,用SVM分类。否则,用KNN来分类[9]。
4 实验结果及分析
本实验采用SVM分类器,采用以切词的后缀为特征,即在前述维吾尔语情感分类流程中,在去停顿词后,以空格为标记,将整篇文本分为一个个单个的词,在对词进行切后缀取代词来做特征,取代传统的以词做特征进行分类的方式。
本实验中多类分类器的构造,是使用“一对一”方法构造n(n-1)/2个二分类器实现的,依卡方为特征选择方法。详见图1、图2、图3

图1 词和5个后缀对比
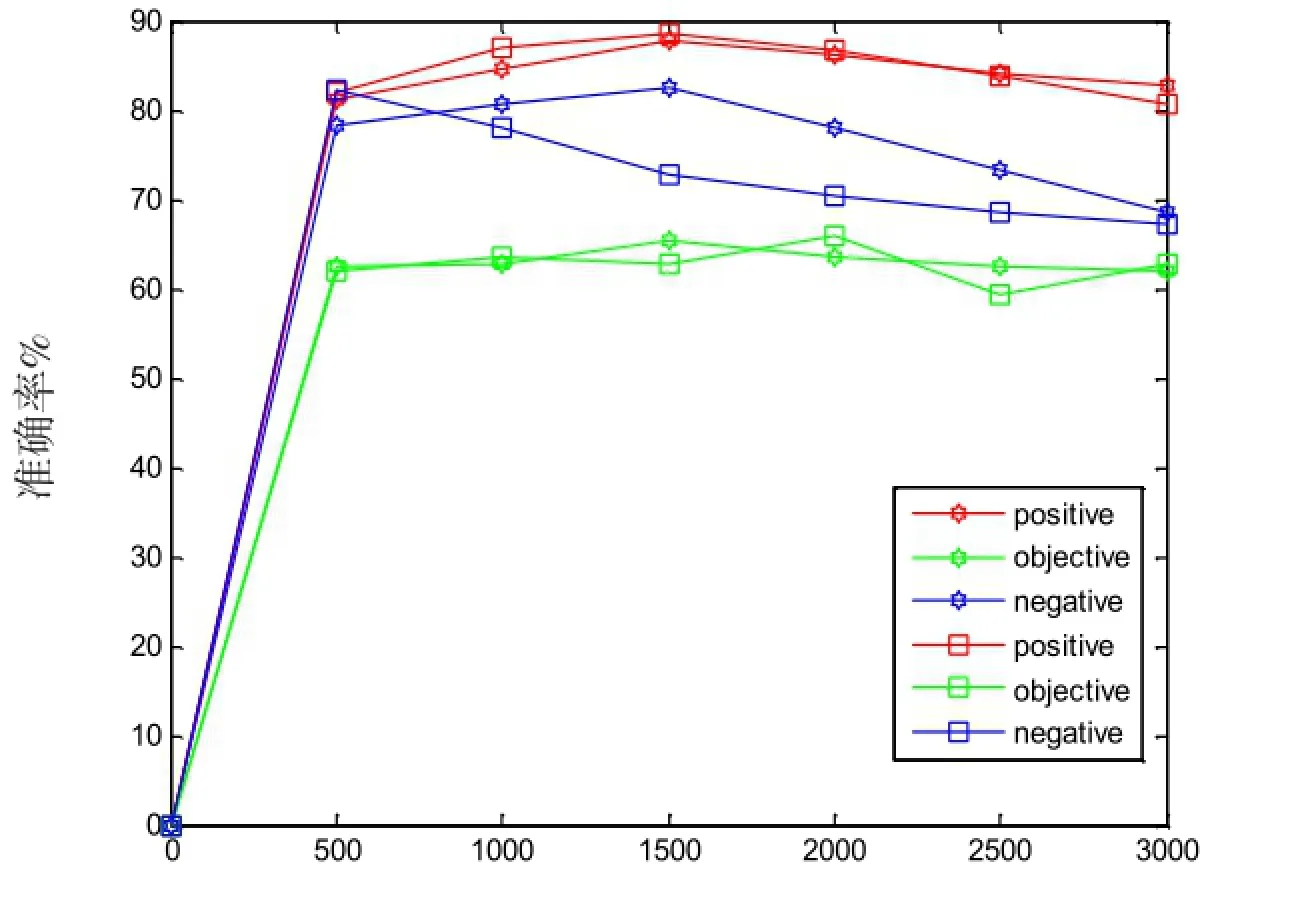
图2 词和6个后缀对比

图3 词和7个后缀对比
本实验中所应用的二分类器所使用的核函数均为多项式核函数,K(x,xi)=[(x*xi)+1]d,核函数参数d(0.5),错误惩罚参数C的值为(4),分类阀值ε的值取(0.5)。
本实验使用的语料为三类情感语料:褒义、贬义、中性。从实验结果,以后缀作特征的方法比以词做特征有着更好的性能。优点是,能一定程度上提高分类的准确率,尤其对于贬义类的情感句子的分类取得了较大的提高,最高可以提高16%。使用词缀作特征的另一个优点是,能够大幅度的降维,这就一定程度的解决维数灾难的问题。在分类中,随着维数的增加所需要的计算量通常是以指数级别增长的,实验证明词缀的方法能够对降维起到了良好的效果。如图4所示,当取5个后缀字母的词缀时,特征维数变为5 599,较之以词做特征的15 372个特征,下降了近50%之多。分别以词、5个字母词缀、6个字母词缀、7个字母词缀作实验对比,总的特征维数分别为:15 372,7 599,9 443,11 370.图4是在取词以及词缀数目不同时的特征维数变化对比图。从三类的实验结果可以看出,一般在特征维数选定在1500—2000时,能获得最优的效果,准确率达到最大值。

图4 总的特征维数
5 总结和展望
本文针提出了一种新的文本情感特征,在SVM-KNN分类器中对非平衡文本数据进行试验,实验结果证明,在一定的维数范围内,能够提高分类的精度。
参考文献:
[1]Picarcl R W.Affective Computing[M].Canbrige:MIT Press,1997.
[2]Pang B,Lee L,Vaithyanathan S.Thumbs up Sentiment Classification Using Machine Learning Techniques.In Proc. Conf.on Empirical Methods in Natural Language Processing,2002:79-86.
[3]肖伟.基于语义的BLOG社区文本倾向性分析[D].上海交通大学软件工程学院,2007.
[4]Yi J,Nasukawa T,Bunescu R,et a1.Sentiment Analyzer:Extracting Sentiments about a Given Ttopic Using Natural Language Processing Techniques.In Proc.of the 3rd IEEE Int.Conf.on Data Mining,2003:427-434.
[5]张宁,贾自艳.使用KNN算法的文本分类[J].计算机工程,2005,3l(8):171-185.
[6]王煜,白石.用于Web文本分类的快速kNN算法[J].情报学报,2007,26(1):60-64.
[7]Metzler D,Croft WB.Combining the Language Model and Interference Network Approaches to Retrieval Information Pro⁃cessing and Management Special Issue on Bayesian Networks and Information retrieval,2004,40(5):735-750.
[8]Pang B,Lee L,Vaithyanathan S.Thumbs up Sentiment Classsific 2007,26(1):60-64.
[9]李蓉,叶世伟,史忠植.SVM-KNN分类器——一种提高SVM分类精度的新方法[J].电子学报,2002,30(5):745-748.
中图分类号:TP391.1
文献标识码:A
文章编号:1671-6469(2016)03-0136-05
收稿日期:2016-03-10
基金项目:新疆科技厅“新疆高校数字图书资源共享体系建设与利用对策研究”(2014731004);昌吉学院研究群体“Web信息抽取与数据挖掘技术及其在网络舆情监测中的应用研究”(2012YJQT03)。
作者简介:高阳(1982-),男,河南周口人,昌吉学院计算机工程系助教,研究方向:自然语言处理、数据挖掘。
