基于字典学习与稀疏表达分类的低质量字符识别*
2016-07-19郝宁波廖海斌杨杰
郝宁波 廖海斌 杨杰
(1.武汉理工大学 信息工程学院, 湖北 武汉 430070; 2.黄淮学院 国际学院, 河南 驻马店 463000;3.湖北科技学院 计算机科学与技术学院, 湖北 咸宁 437100)
基于字典学习与稀疏表达分类的低质量字符识别*
郝宁波1,2廖海斌3†杨杰1
(1.武汉理工大学 信息工程学院, 湖北 武汉 430070; 2.黄淮学院 国际学院, 河南 驻马店 463000;3.湖北科技学院 计算机科学与技术学院, 湖北 咸宁 437100)
摘要:为解决低质量字符中的断笔、噪声和模糊问题,以及不同字体与字号的字符识别问题,提出了基于字典学习与稀疏表达分类的低质量字符识别方法.首先,收集不同字体和字号的字符样本构建字符超完备字典;然后,对测试字符进行稀疏表达建模,并根据求解的稀疏系数进行字符分类.为了使字典更具鉴别性,文中提出了基于因子分析的字典学习方法.实验结果表明,文中所提方法不仅可以同时识别不同字体和字号的字符,还具有对断笔、噪声和模糊的鲁棒性.
关键词:字符识别;字典学习;稀疏表达;因子分析
汉字识别研究始于21世纪60年代,到70年代取得了初步的成果[1].目前,比较成熟的文字识别软件有清华紫光OCR、国家职能计算机研究开发中心研制的NC-OCR、汉王科技、北京信息工程学院研制的Bl-OCR等.这些系统能够识别4 000多个常用汉字,而且识别率在95%~99%之间.但这些软件大多是通过电子扫描仪输入图像,对纸张的光洁度、薄厚度、洁白度和印刷或者书写质量的要求较高,极易受到低质量印刷品产生的污点、断笔粘连等干扰[2].
在低质量传真字符中极易出现字符断笔、噪声模糊等现象,如图1所示.对于常规的印刷体字符识别,目前基本上已经取得了满意的识别结果,但对低质量传真图像中出现的断笔、噪声、部分信息缺失和模糊等问题的字符识别,仍然是一个具有挑战性的难题.同时,在传真字符图像中,存在大量不同字体和字号的字符,如图1(a)所示.而现有的字符识别算法往往是针对某几种字体和一定范围字号变化的字符进行识别,因此研究字体和字号不变字符识别具有重要的意义.
近年来,利用压缩感知(CS)[3]和变量选择[4]的理论与方法进行图像的“稀疏表达”,已成为计算机视觉和机器学习领域的研究热点之一.鉴于压缩感知和变量选择在数据处理方面的优势,Wright等[5]将其引入人脸识别,提出了通过l1-范数约束进行特征选择进而识别人脸的新思路.由于从图像中可提取的特征众多,因此,从高维图像特征中寻找到的有效稀疏表达,已被陆续应用在图像分类[6]、视觉单词选择[7]和图像超分辨率[8]等.
在稀疏表达分类(SRC)应用中,字典的构造是一个非常重要的工作.在信号重建中要保证其完备性,在分类中要保证其可鉴别性,在实际应用中还要保证其可计算性与低复杂度.在稀疏表达应用初期,都是通过人工挑选样本来构造字典,但人工挑选方法要么数据过大造成后期稀疏表示求解困难,要么很难挑选到最佳的样本.目前出现的大量鉴别字典学习方法(DDL)[9- 13],通过对字典实施结构约束或是对稀疏系数向量进行鉴别项限定来学习字典的鉴别性,在人脸识别[10]、场景分类[11]、对象识别[12]方面取得了显著的效果.

图1 低质量传真字符实例
为解决低质量字符中的断笔、噪声和模糊问题,以及不同字体与字号的字符识别问题,文中提出了基于字典学习与稀疏表达的低质量字符识别方法.首先收集不同字体和字号的字符样本用于构建字符超完备字典,为了使字典更具鉴别性,文中提出了基于因子分析的字典学习方法;然后对测试字符进行稀疏表达建模,并根据求解的稀疏系数进行字符分类;最后通过实验来验证所提方法的有效性.
1低质量字符识别框架
文中提出的低质量字符识别方法的流程如图2所示,主要包括字符特征提取、鉴别字典训练、模型求解和字符分类.其中,字符图像输入、字符特征提取、稀疏表示模型求解可在线完成,多样化字符图像训练、字符特征提取、基于因子分析的字典优化训练可离线完成.由于文中提出的字符识别方法并不依赖于字符特征提取算法,故采用5尺度和8方向的Gabor变换提取的灰度字符图像特征作为字符的最终特征向量.
稀疏表示分类主要基于线性组合思想:假设每类对象有足够多的样本,待测样本可由所有对象完备字典线性组合表示.如果待测样本属于第i类,则只能由第i类样本线性组合表示,即线性组合系数非0项全部集中在第i类,其他类全为0.因此,可通过适当的稀疏约束求解线性组合方程组,利用求解系数的非0项分布进行分类.因此,字符字典的优化学习和稀疏表达模型求解是基于SRC的字符识别的关键.

图2 文中识别方法的流程图
1.1字符字典的优化学习
收集汉字编码字符集一级字库3 755个,然后在Word中对所有字符变换不同字体和字号,其中每个字符包括6种常见字体(仿宋、黑体、楷体、楷体GB2312、隶书和宋体)、3种不同字号(大号、中号和小号)共18幅字符图像.据此,将字符分为3 755类,每类包括18个训练样本,部分示例如图3所示.
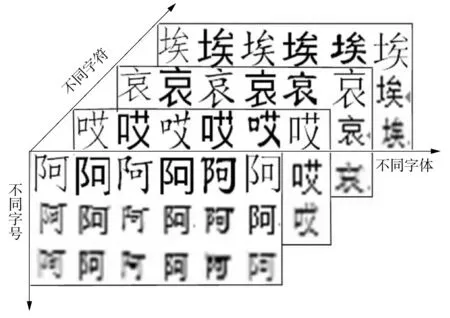
图3 字符训练集示例
一般可以直接使用上述训练集作为字符字典.但这种方式构建的字典并非最优,同时可能导致字典矩阵过大.如上述训练集字符图像个数为18×3 775=67 950,假设每幅图像归一化大小为64×64,通过Gabor特征提取得到2 240维,通过主成分分析(PCA)降维后变为100维,则最后的字典将是100×6 795的矩阵,如此大的矩阵为后期的稀疏求解带来巨大的压力.为了对字典进行优化,同时使字典具有鉴别性能,文中提出了基于因子分析的字典优化学习方法.
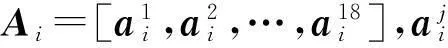
(1)
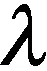

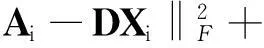
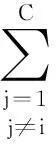
(2)
式中第1项确保Ai可以很好地被D表示.由于Ri可能偏离Ai过大,导致Di不能很好地表示Ai,因此,可以通过第2项最小化使学习得到的D更具有鉴别性.有时Ai可能被其他类子字典Dj(j≠i)很好地表示,从而降低了鉴别性,因此,可以通过最小化第3项来避免此问题.
(2)因子分析鉴别约束项.为了使学习得到的字典D更有鉴别性,可以采用约束规范系数X的方式.把内容和风格看作影响一个事物的两个相互独立的因素,它们决定了事物的观测[14].如在语音信号中,语音文本是内容,说话人的说话语气和声调是风格.在低质量字符识别中,高质量规范字符的信息是内容,而字符的字体、噪声和遮挡等变化是风格.字符识别的任务就是根据字符内容信息识别出不同字体的字符,如果能将影响字符特征的风格因素(不利因素)分离出来,那将非常有利于字符识别.根据以上分析定义因子分析准则:通过字典D求取的稀疏系数矩阵X尽可能地代表样本集A的内容信息,去除风格因子的干扰,使求取的稀疏系统具有很强的鉴别性.根据因子分析准则,可以定义如下的因子分析鉴别约束项:
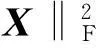
(3)

内容因子定义为
(4)
式中:C为类别数;pi、pj分别为第i、第j类的先验概率,一般取1/C;μi为第i类系数Xi的均值向量,w(i,j)为第i类和第j类的权值,其目的是降低本来已经分得很好的类别对的权值,而让相近的类别对得到更多的关注.文中采用邓氏关联度[15]来计算两类均值之间的权值:
(5)
式中,n为向量的维数,μi(k)、 μj(k)分别为第i、第 j类均值向量的第k个特征,R(μi(k),μj(k))为第i类与第j类均值向量中第k个特征的关联系数,
(6)
灰色关联度主要用来描述系统因素间关系密切程度的量,它是一种有参考系的、有测度的整体比较,且还具有许多优良的特点.
风格因子定义为
(7)
(8)
t为经验常数.引入权值项的目的是降低同类中本来就很相近的样本对的权值,而让那些离得很远的奇异样本对得到更多的关注.
有了鉴别保真项(2)和因子分析鉴别约束项(3),最终的字典学习模型可表示为
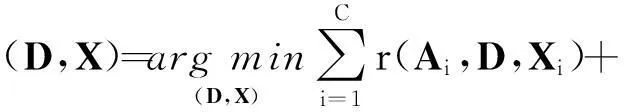

(9)
最终字典学习模型的目标函数求解可以通过交替迭代的方法分成两个子问题进行求解:①固定字典D(由K-SVD方法求得),更新系数矩阵X;②固定系数矩阵X,更新字典D.如此交替迭代直到收敛为止.1.2字符稀疏表示与分类模型
通过1.1节的字典学习可以训练出具有鉴别性与重构性的超完备字典D.然后利用D对测试字符y进行稀疏表示,求取稀疏表示系数x:
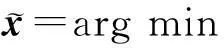
(10)
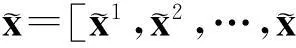

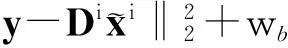
(11)
对ei进行排序,选取最小的ei所对应的类别作为最终识别结果.1.3字符噪声、断笔处理
低质量文本图像中的字符可能存在噪声、断笔情况(统称为遮挡情况),当测试字符y具有遮挡变化时,其可表示为
(12)
式中,B=[DDe]∈Rm×(n+ne),无遮挡图像y0与遮挡误差图像e0分别可由字典D和遮挡字典De∈Rm×ne稀疏表示.在SRC中,De通常为正交单位矩阵.单位矩阵对图像误差和噪声的描述不够准确与直观,且维数过高.因此,文中对其进行改进.
首先收集不同噪声和断笔情况下的字符图像集(遮挡训练集),用遮挡训练样本减去其对应类的均值图像得到误差图像,然后以误差图像样本构建、训练学习遮挡字典De.通过文中方法构建的误差图像比较直观且切合实际.同时,对误差图像样本进行K-SVD训练优化,使遮挡字典De的维数更低,性能更优.
因此,遮挡字符识别的稀疏表示模型为

(13)

2实验结果与分析
实验分两部分进行:①对高质量汉字字符进行识别实验,以验证文中所提方法的有效性;②对低质量汉字字符进行识别实验,以验证文中方法对字符断笔、噪声的优越性.在配置为Inter® CoreTMi5-4440 3.10 GHz、内存4 GB,操作系统为Windows 7,仿真软件为Matlab R2010b的计算机上进行实验.系统的主要技术指标如下:①识别字数,一级汉字共3 755个(简体);②识别字体,包括宋体、仿宋、楷体、楷体GB2312、黑体、隶书;③识别字号,包括1、2、3号.2.1高质量字符识别
文中选取6种字体,每种字体选用3种不同字号,共3 775×6×3=67 950个样本进行测试实验.字符图像归一化大小为64×64,采用Gabor变换提取字符特征,并采用主成份分析(PCA)进行降维.在字典训练集中,每个字符包括6种不同字体和3种不同字号共18幅图像,通过文中提出的字典学习方法进行优化学习后,每类字符(子字典)保留10个字符(原子).
6种不同字体的识别率和识别时间如表2所示.从表中可以看出,黑体的识别率最高,其次是隶书,最差的是华文楷体.文中基于稀疏表示的字符识别方法在没有进行字符二值化、细化等预处理和没有采用多特征、多分类器融合的策略下取得了目前商用字符识别系统的效果,甚至在某些字体上超过目前最好的系统.每字的识别时间在0.1 s左右,即每秒可以识别8个字,基本上可以达到实际应用中的实时性要求.因此,文中提出的基于字典学习和稀疏表示的字符识别方法具有较好的识别性能.

表1 参数取不同值时的识别结果

表2 高质量印刷体字符的识别结果
2.2低质量字符识别
为了验证文中方法对低质量字符中断笔、噪声和部分信息缺失的鲁棒性.文中从真实的低质量传真文本图像为一级字库中每个字符挑选出两个对应的低质量字符图像样本作为遮挡字典训练样本,然后用低质量样本减去其对应字符的均值图像得到误差图像,最后以误差图像构建、训练学习遮挡字典.另外,从其他低质量传真字符图像中挑选出500个具有断笔、噪声和模糊的字符作为测试集(与遮挡训练样本不同),部分字符如图4所示.从图中可以看出,低质量传真字符图像中的字符存在严重的噪声和断笔干扰,人眼免强能够辨认,但对计算机来说面临着巨大的阻碍.
为验证文中识别方法(增加遮挡字典)对字符断笔和噪声的鲁棒性,选取了基于线性核函数的支持向量机(LSVM)、基于四阶多项式核函数(PSVM)的支持向量机和基于高斯径向基核函数的非线性支持向量机(RBF-SVM)作为字符分类器进行实验比较.同时,为验证文中方法增加遮挡字典的有效性,还与直接SRC(不使用遮挡字典的SRC)方法进行了比较.为验证文中基于因子分析的鉴别字典学习方法的有效性,还与传统的K-SVD字典学习方法(K-SVD+SRC)进行了比较.结果如表3所示.

图4 含有断笔、噪声和模糊的字符示例
Fig.4Examples of the characters with broken pen,noise,and ambiguity
表3低质量字符的识别率与耗时
Table 3Recognition accuracy and time of the low-quality characters

方法识别率/%训练时间/s测试时间/s文中方法75.421200(字典训练)0.318直接SRC54.00540(字典训练)0.132K-SVD+SRC71.241050(字典训练)0.318LSVM54.23217 0.002商用系统51.750.006PSVM56.845714 0.020RBF-SVM56.907855 0.023
从实验结果可以看出,非线性支持向量机比线性支持向量机的分类性能要好,但计算复杂度要高得多.在字符分类器的训练过程中,常会遇到一些超参数(如基于最小化交叉熵准则的目标函数的正则化系数,非线性支持向量机的高斯径向基核函数的方差等),文中利用K-Fold交叉验证策略对这些超参数进行优化.针对图4所示的字符,直接使用SRC的识别率为54.00%,使用增加遮挡字典处理后的SRC的识别率为75.42%,说明增加遮挡字典的方法对字符噪声和断笔均具有很好的鲁棒性.文中提出的基于因子分析的鉴别字典学习方法的识别率比K-SVD方法提高了4%左右,说明了鉴别字典学习的有效性.目前识别效果较好的线性和非线性支持向量机的识别结果分别为54.23%和56.90%,说明目前的字符识别方法无法处理字符噪声和断笔识别问题,而文中提出的方法对断笔、噪声和模糊的字符识别具有明显的优势.
3结论
文中将字典学习和稀疏表示引入到传真字符识别中,以解决传真字符的断笔、噪声问题.实验结果表明,文中提出的基于字典学习与稀疏表示的汉字字符识别方法解决了不同字体和字号的字符识别问题,利用稀疏表示可大幅提高对低质量字符(有断笔、噪声等)的识别率,文中识别方法不需要前期的字符二值化和细化等预处理操作,只需要一种特征、一个分类器,与目前的多特征多级联分类器融合识别方法相比具有复杂度低的特点.
参考文献:
[1]刘聚宁.印刷体汉字识别系统研究与实现 [D].大连:大连理工大学,2011.
[2]聂玖星.印刷体汉字识别系统的特征提取和匹配识别研究 [D].大连:大连理工大学,2008.
[3]YANG S Y,WANG M,LI P.Compressive hyperspectral imaging via sparse tensor and nonlinear compressed sen-sing [J].IEEE Transactions on Geoscience and Remote Sensing,2015,53(11):5943- 5957.
[4]THOMSON T,HOSSAIN S,GHAHRAMANI M.Application of shrinkage estimation in linear regression models with autoregressive errors [J].Journal of Statistical Computation and Simulation,2015,85(16):3335- 3351.
[5]WRIGHT J,YANG A,GANESH A,et al.Robust face recognition via sparse representation [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(2):210- 227.
[6]ZHU X F,XIE Q,ZHU Y H.Multi-view multi-sparsity kernel reconstruction for multi-class image classification [J].Neurocomputing,2015,169:43- 49.[7]DORNAIKA F,ALDINE I Kamal.Decremental sparse modeling representative selection for prototype selection [J].Pattern Recognition,2015,48(11):3714- 3727.[8]LIAO Haibin,DAI Wenhua,ZHOU Qianjing,et al.Non-local similarity dictionary learning based on face super-resolution [C]∥Proceedings of IEEE International Conference on Signal Processing.Hangzhou:IEEE,2014:88- 93.[9]ZHANG Q,LI B.Discriminative K-SVD for dictionary learning in face recognition [C]∥Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition.San Francisco:IEEE,2010:2691- 2698.[10]YANG M,ZHANG D,FENG X.Fisher discrimination dictionary learning for sparse representation [C]∥Proceedings of IEEE International Conference on Computer Vision.Barcelona:IEEE,2011:543- 550.
[11]JIANG Z,LIN Z,DAVIS L.Label consistent K-SVD:learning a discriminative dictionary for recognition [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(11):2651- 2644.
[12]CAI Sijia,ZUO Wangmeng,ZHANG Lei,et al.Support vector guided dictionary learning [C]∥Proceedings of the 13th European Conference on Computer Vision.Zu-rich:Springer,2014:624- 639.
[13]陈思宝,赵令,罗斌.局部保持的稀疏表示字典学习 [J].华南理工大学学报(自然科学版),2014,42(1):142- 146.
CHEN Si-bao,ZHAO Ling,LUO Bin.Dictionary learning via locality preserving for sparse representation [J].Journal of South China University of Technology(Natural Science Edition),2014,42(1):142- 146.
[14]廖海斌,陈庆虎,鄢煜尘.基于因子分析的实用人脸识别研究 [J].电子与信息学报,2011,12(7):1611- 1617.
LIAO Hai-bin,CHEN Qing-hu,YAN Yu-chen.Practical face recognition via factor analysis [J].Journal of Electronics & Information Technology,2011,12(7):1611- 1617.[15]DENG J L.Grey information space [J].Journal of Grey Systems,1989,1(2):103- 117.
收稿日期:2015- 10- 08
*基金项目:中国博士后科学基金面上项目(2015M582355);公安部科技攻关项目(SN20110001)
Foundation item:Supported by the General Program of the National Science Foundation for Post-Doctoral Scientists of China(2015M582355)
作者简介:郝宁波(1977-),男,博士生,副教授,主要从事软件开发、图像处理与模式识别研究.E-mail:hnb79@163.com †通信作者: 廖海斌(1982-),男,博士,讲师,主要从事图像处理与模式识别研究.E-mail:liao_haibing@163.com
文章编号:1000- 565X(2016)05- 0123- 07
中图分类号:TP 391
doi:10.3969/j.issn.1000-565X.2016.05.019
Low-Quality Characters Recognition Based on Dictionary Learning and Sparse Representation
HAONing-bo1,2LIAOHai-bin3YANGJie1
(1.School of Information Engineering,Wuhan University of Technology,Wuhan 430070,Hubei,China;2.International College,Huanghuai University,Zhumadian 463000,Henan,China;3.School of Computer Science and Technology,Hubei University of Science and Technology,Xianning 437100,Hubei,China)
Abstract:In order to recognize low-quality characters with interrupted strokes, noise and fuzziness, and to recognize characters with different fonts and sizes, a method to recognize low-quality characters on the basis of dictionary learning and sparse representation is proposed. Firstly, character samples with different fonts and sizes are collected to construct a super-complete dictionary of characters. Then, a sparse representation model is established by using test characters, and a character classification is made according to the solved sparse representation coefficient. Additionally, in order to make the dictionary more discriminating, a dictionary learning method on the basis of factor analysis is proposed. Experimental results show that the proposed method not only can identify characters with different fonts and sizes but also possesses robustness to interrupted strokes, noise and fuzziness.
Key words:character recognition;dictionary learning;sparse representation;factors analysis
