基于特征自动选择方法的汉语隐喻计算
2016-06-22曾华琳周昌乐陈毅东史晓东
曾华琳,周昌乐,陈毅东,史晓东
(厦门大学 信息科学与技术学院,福建省仿脑智能系统重点实验室,福建厦门361005)
基于特征自动选择方法的汉语隐喻计算
曾华琳,周昌乐*,陈毅东,史晓东
(厦门大学 信息科学与技术学院,福建省仿脑智能系统重点实验室,福建厦门361005)
摘要:汉语隐喻计算是中文信息处理中的棘手难题之一.已有的隐喻识别研究多以人工方式分析和抽取隐喻特征,存在着主观性强、难以扩充的缺点,并且对于专业背景知识要求比较严格.本文基于大规模语料库的机器学习,利用最大熵分类模型,提出了一种最优特征模板自动抽取的隐喻识别算法,讨论了3种不同层次的特征模板,既包含了经典的简单特征,又将跨多个词的远距离上下文信息,以及描述语义信息的词语相似性引入特征模板进行考察.实验结果表明,该算法提高了隐喻识别准确率,是一种对于汉语隐喻计算行之有效的机器学习方法.
关键词:汉语隐喻计算;隐喻识别;机器学习;自动特征选择
隐喻,广泛存在于人类的语言生活中.从先古哲学家亚里士多德的修辞学,到现代莱可夫的认知语言学,无论是在中文语言学,抑或是在西方语言学研究中,隐喻一直是处于前沿探索阶段的项目[1-7].在语言学与计算机科学的交叉学科——中文信息处理中,隐喻则属于语义级别的范畴,至今仍然是亟待解决的棘手难题之一.
汉语隐喻的研究,主要集中在隐喻识别和隐喻理解两大方面,统称为隐喻计算.隐喻识别旨在从上下文环境中判断隐喻现象的存在,而隐喻理解则需要给出对于隐喻意义的推理.从方法论而言,分别有规则、统计和逻辑的方法.长期以来,在隐喻计算研究中,规则和逻辑的方法占据了主流地位.已有的研究[8-15]中,无论是纯规则,或者是规则和统计相结合的方法,规则都是由人工整理和编写的,建立在人工收集和定义描述的基础上.而通过人工进行收集和编写的规则,规模有限,主观性强,不易于扩充,这是规则(rule-based)方法的通病,也是阻碍隐喻计算实用化的症结所在.
近年来,机器学习方法[16-17]运用到计算语言学的各个领域,都获得了很好的效果,特别是在大语料环境下的机器学习方法的成功使用.隐喻计算中也曾有机器学习方法的尝试,王治敏[10,14]利用最大熵模型研究了名词性汉语隐喻短语的识别,贾玉祥[13,18]则提出了基于实例的隐喻理解与生成,而在他们的研究中,特征的选取仍然是人工进行的,对每个单独的隐喻候选词,每个特殊隐喻现象的特征都进行详细考察,这要求特征的选取者对于隐喻计算模型有着深刻的认识,终究避免不了人工方式所带来的困境,无法将隐喻计算做到一般化的过程.
为了避免人工方法所带来的缺陷,消除主观性及隐喻特征选择的不一致性,本文提出了一种基于大规模语料库的汉语隐喻特征自动抽取方法,将机器学习中的特征选择思想引入到汉语隐喻计算中,分析汉语隐喻在词、句法结构以及语义层面上的不同特点,给出3种不同类型的特征模板描述,并利用最大熵模型构建汉语隐喻特征模板库,以有监督学习方式处理汉语隐喻计算.
1汉语隐喻计算的机器学习分类模型
分类是机器学习算法中的典型任务,基本思想是训练分类函数,然后将待分类对象以特征序列表示进行输入,通过计算分类函数得到的数值给出分类结果.隐喻计算属于典型的机器学习分类问题.本文提出一种适用于汉语隐喻计算的机器学习分类模型,用于构建隐喻计算的2个基本任务.
1.1隐喻计算中的分类
隐喻计算的不同阶段都可以建立分类模型,其理论依据在于隐喻的本质——“同从异出”,即在识别出隐喻的存在并确定本体和喻体之后,在概念系统中,把比较具体的喻体(相当于源域)的知识,与比较抽象的本体(相当于目标域)的知识进行比较,通过动态的互动过程描述,用喻体知识来“认识”本体对象.在这个过程中,作为本体和喻体,都有许多不同的意义描述.
隐喻计算分为2个阶段进行:1) 隐喻识别.从表面上看,喻体的概念范畴与本体差别较大,引起强烈的冲突感,即所谓“异出”.正确感知这种冲突感,实现隐喻识别,这是个二值分类问题.2) 隐喻理解.本体的理解是一个依赖于喻体特征的有选择性的部分映射,这种映射过程并不是随意的,而是根据其上下文环境的限制聚焦后而得的映射结果.于是,隐喻理解可以看作是在上下文环境中,本体受喻体概念聚焦后对于意义再次分类而确定相似点的过程,一旦能够正确地选定相似点,隐喻理解就完成了,这所谓找到了“同从”.隐喻的理解,正是一个从“异出”聚焦到“同从”的过程.最后,隐喻计算还有一个任务,即隐喻生成,它完成了从“同从”本质选择“异出”表现的过程.
综上所述,隐喻识别属于二值分类问题,选取隐喻候选词上下文的特征,根据有效分类算法,作出是否存在隐喻现象的判断;而隐喻理解属于多值分类问题,在给定句子的本体和喻体之后,分析两者的各个义项,确定相似点,完成隐喻的理解过程.隐喻识别与理解可以类比于自然语言处理的经典问题——词义消歧[19-20],三者之间的不同点比较如表1所示.

表1 隐喻计算与词义消歧的分类模型
注:多对多指本体与喻体在意义范畴的相似点确定;一对多指多个词义的唯一确定.
在对隐喻计算的分类任务建模之后,本文将经典的机器学习分类算法引入隐喻计算中来,特别地针对隐喻识别进行研究.
1.2隐喻计算的分类特征模板
在常见的机器学习分类任务中,最重要的在于特征模板的构建.隐喻计算的分类模型中包含了2个任务:1) 定义隐喻计算中的特征.隐喻作为意识层面的认知任务,其特征不再仅仅停留于一般的文本分类任务的特征,本文引入了语义层面的知识,将语义相似度作为显著特征进行表述.2) 收集针对每一个隐喻候选词的有效特征模板.隐喻候选词应该包含本体以及喻体,即在隐喻理解过程中本、喻体各自的知识概念有效特征模板表示.
1.3基于最大熵的隐喻计算分类模型
最大熵模型[21]的优势在于忠于大规模真实文本,特别是对于“稀疏事件”问题的处理上,它能使得未知事件的概率分布不做任何假设,尽可能平均,以得到最大熵为目标.
在有约束条件的情况下,使条件熵最大化,即:


(1)
式中:c为约束条件,在本任务中,即隐喻现象的上下文环境;m为是否是隐喻的分类描述.约束条件是用特征函数(简称为特征)进行描述的.
综上所述,本文重点对于隐喻识别的特征模板进行考察.利用语言学知识,定义备选特征模板库,针对隐喻候选词进行最大熵模型训练,通过自动特征选择算法,筛选显著特征模板,完成隐喻识别的特征自动抽取过程.
2隐喻计算的最优特征模板选择算法
2.1最优特征模板选择算法
本文针对语料库中出现频率较高的隐喻候选词进行训练,抽取每个特定候选词的最优特征模板集.这是一个最优子集合问题,属于组合数范畴,也是一个NP完全问题,其算法时间复杂度为2n.为了降低算法计算复杂度,本文选择利用贪心算法构建模板选择过程.最优特征模板选择算法描述如下:
输入:特征模板集合F={Fi};隐喻候选词;隐喻正反例训练库;隐喻句测试库.
输出:针对特定隐喻候选词的最优特征模板子集S.
初始化最优特征模板子集S=NULL,循环迭代次数Istop=0,最优分数BBsstscore=0;
While特征模板集合F不为NULL do;
T=S;Cscore[]=0;
Forj=1 to sizeof(F)遍历特征模板集合F中所有的特征Fj;
T=T+Fj;
以当前特征模板集合T训练最大熵模型MaxHP(T),并对其进行评分Cscore[j];
T=T-Fj;
end for;

图1 系统流程图Fig.1System flowchart
记录取得最高分的特征MaxCscoreF,以及最高分数MaxCscore;
IF本轮最高分数MaxCscore> 迭代最优分数BBsstscore;
将对应的特征MaxCscoreF纳入最优特征模板子集S中,并更新BBsstscore;
else;
循环迭代次数Istop=Istop+1;
end if;
IF 循环迭代次数Istop超过3次;
结束搜索break;
end if;
end while;
ReturnS.
从备选特征模板集合中选择备选特征,考察备选特征项对于整体分类模型的影响,从而决定是否加入特征模板,选择过程依次逐步开展.考察过程分2步:1) 在训练集中训练加入备选特征项后的特征集合的分类模型;2) 在测试集中计算此分类模型的得分,记录分数,选择取得最高分数的特征项.如果此得分比前一代模板得分高,则将此模板项加入特征模板集;否则,迭代次数加1.当分类模型得分下降的次数超过3次,或者备选特征模板集合为空,则停止考察.
系统整体流程如图1所示.
2.2特征模板构造
特征函数通常选择二值函数或者频率.隐喻计算中常用特征,在人工抽取上常见于选择在词义上具有典型特征的词汇,特定的辅助虚词,特殊的语法结构等.本文针对隐喻识别任务,定义了3种层次的隐喻特征:简单特征、依存关系构建的上下文环境特征、异常度特征.
2.2.1简单特征
以词为序列的特征函数构建任务中,常选择词、词性、N元词与词性的组合.这类特征里具有显著效果的是与此相关的特征词、高频共现、惯用搭配以及常见语法搭配格式.例如,王治敏在其研究[10,14]中核心讨论了名词隐喻中常见的“名词+的+名词”结构,该结构会在中心词向左或者向右的跨度为2个词的窗口中,以“名词+的”或“的+名词”的模式被凸显.
以“他沉浸在书籍的海洋里不能自拔.”为例说明.
分词标注以后的结果为“他/rr 沉浸/v 在/p 书籍/n 的/uj 海洋/n 里/f 不能自拔/v./w”.
候选词“海洋”,W-2为“书籍”,W-1为“的”,W+1为“里”,W+2为“不能自拔”,Pos-2为“n”,Pos-1为“uj”,Pos0为“n”,Pos+1为“f”,Pos+2为“v”.
2.2.2上下文环境特征
隐喻的出现与上下文关系是密切联系的, 在某些上下文环境下,有些句子无法识别为隐喻;然而换个上下文环境,隐喻意义则会呈现出来,这里的上下文环境不仅仅是在简单特征中所描述的词的包围,而是包含了在语法结构中的语法环境.文献[12]中提到,除了“辩词”、“断义”之外,“按语法分割意群”和“将意群组合成句”都是隐喻相似点选择所依赖的隐喻语境作用机制.另外,隐喻意义的理解在不同的语境下也会聚焦到不同的意义.简单特征中,窗口大小的选择是有长度限制的,增加窗口长度所带来的计算复杂度的增大与由此带来的系统准确率的提高相比,得不偿失;特别对于复杂长句来说,在目标词附近寻找到显著特征是一件非常困难的事情,但是又不能无条件地扩大窗口.于是,加入语法分析后的语法结构特征将是一个很好的选择.
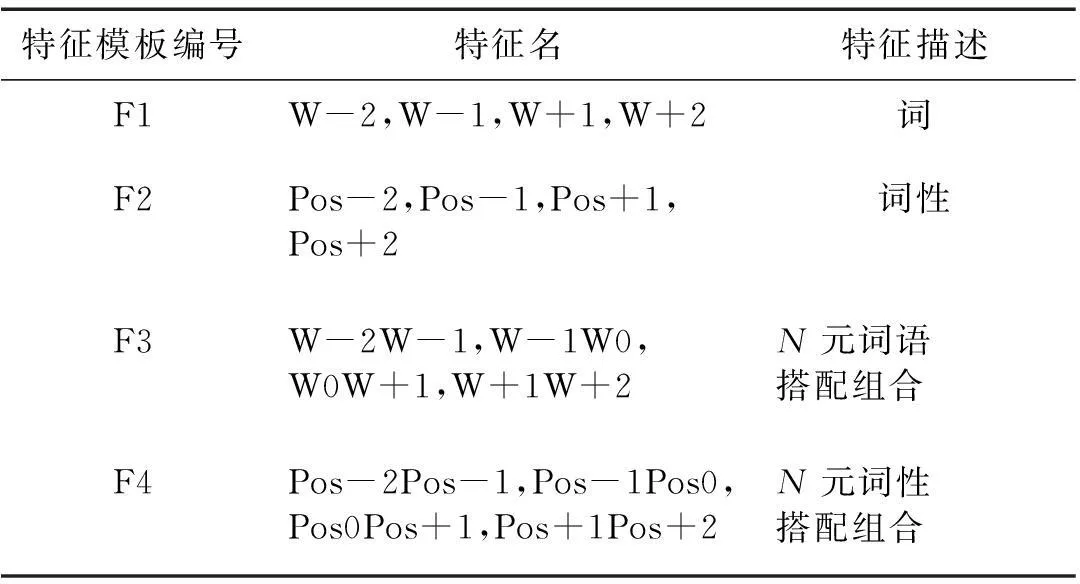
表2 简单特征

HED:核心关系;SBV:主谓关系;VOB:动宾关系(直接宾语);ATT:定中关系;RAD:右附加关系;COO:并列关系;ADV:状中关系;WP:标点符号.图2 依存语法举例Fig.2Example of dependency grammar
以如下句子“草原是这样无边的平展,就像风平浪静的海洋.”分析.本体“草原”和喻体“海洋”分别以主语和宾语的形式出现,中间间隔的词有9个:“的”、“风平浪静”、“像”、“就”、“平展”、“的”、“无边”、“这样”、“是”.
例句的依存语法描述如图2所示.隐喻关系中的本、喻体“草原”和“海洋”之间,在依存语法中以主宾关系共现.抽取经过依存语法分析后而得的语法结构特征作为有效模板,对于隐喻识别准确率的提高是有很大帮助的.在前人做过的隐喻识别算法中,曾经有以依存语法作为分析的依据,然而,对于依存语法的使用是利用模式匹配的方式来进行,并没有针对于某个隐喻候选词的特殊分析,本文将依存语法分析后得到的语法特征以及语法搭配模式加入考察.一方面,加入其语法信息;另一方面,加入依存语法中的上下文搭配,这样也是对于“按语法分割意群”和“将意群组合成句”的语境作用机制的运用.于是,考虑增加表3的上下文环境特征.

表3 上下文环境特征
2.2.3异常度特征
异常度特征是在机器学习下,对于人工规则的一种补充.这里,本文将隐喻的冲突机制作为特定的特征进行引入.所谓冲突机制,阐述的是隐喻“同从异出”机制中本、喻体之间在概念范畴内的同异关系.本文研究的对象集中于名词性的隐喻,考察语料库中关于名词性隐喻的结构,90%以上核心词的依存语法中,存在“名词+名词”结构和“主语+宾语”结构,即本体和喻体都是名词.于是,考察与目标词搭配的名词,考察潜在的本体或者喻体与目标词之间的异常度.
知网,作为知识概念系统及概念属性的描述,可以给出词语之间的语义相似度,这正是在意义的相似性方面给出的潜在本、喻体之间的异常度描述.在此,选取知网的相似度计算作为异常度特征(表4)进行考察,计算公式如下:

(2)
其中S1j,S2j分别为考察目标词W1及目标词搭配名词W2在知网中的义项.

表4 异常度特征
2.2.4窗口大小选择

表5 窗口大小实验结果比较
窗口大小主要在简单特征中进行不同的实验,以隐喻候选词为中心,在规定大小的上下文窗口中选择具有典型意义的特征模板,从训练数据中获取特征数据,形成特征向量,以指导分类的进行.在语言学理论中,词语的上下文环境决定词义,可以通过不涉及词的意义层次,而通过上下文的语法特征来描述其意义.选取不同大小的窗口进行横向比较是有必要的.窗口选择过小,不能很好地体现目标词的上下文环境;而窗口选择过大,虽然上下文信息比较丰富,但是也由此带入了不必要的噪音,并且带来计算量的指数级增加.选择合适大小的窗口,既包含可计算信息,又能在算法效率上找到平衡点,这显得尤为重要.
2.3评价函数
最大熵模型用于对特征模板的训练和隐喻计算过程中.在系统流程中,每轮的模型训练选择一个备选特征加入到候选模板中,利用最大熵模型进行参数的训练,将得到的最大熵模型在测试数据上进行测试,计算识别F-Measure值(后简称F值),F值是准确率P和召回率R的加权调和平均,以此值为衡量该特征模板的标准,计算公式如下:

(3)

(4)
(5)
3实验分析与对比
从《读者》、《围城》中抽取隐喻句库,从汉语比喻词典中抽取经典比喻句,组成隐喻正例库,同时也抽取反例库,并选取新浪微博数据做实验语料.选择在语料中使用较为频繁的10个名词作为研究对象,考察它们在真实语料中的隐喻分布情况,用最大熵方法进行隐喻的识别.
从语料库中总提取1 000个样本,其中每个词语构造约100个实验样本.测试集与训练集比例选取3∶7.开放测试集从搜索引擎收集及《人民日报》1998年上半年语料,针对每个词语构造约50个实验样本.
最大熵模型的使用,选择最大熵工具包(Maximum Entropy Modeling Toolkit for Python and C++,ZHANG Le,2004-12-29),参数估计选用LBFGS,迭代次数为100次.本文实验的计算机硬件配置为Intel i7-4510型CPU,8 G内存,运行64位操作系统.实验程序代码由C++实现,编程环境为Microsoft Visual Studio 2008版.
3.1窗口大小对于简单特征的影响
首先对窗口大小单独进行考察,仅针对简单特征在封闭测试下进行.这里节选“海洋”、“爱情”、“港湾”、“心灵”4个候选词的结果列表展示于表5.
总体来看,(-2,+1)和(-2,+2)窗口的识别准确率大体上要高于(-1,+1)窗口,而(-2,+1)和(-2,+2)效果相当.因为(-1,+1)窗口太小,出现在窗口内的词语较少,很难全面衡量影响名词短语隐喻的各个因素,在隐喻识别上存在较大的偶然性和武断性.而随着窗口的增大、词语数目的增多,特征值数量也随之增多,从而更全面地考察了隐喻识别的各个因素,减少了因窗口太小而造成的误差,使得准确率有所上升.最终,本文选择了(-2,+2)作为实验中简单特征的窗口大小.
3.2自动模板抽取算法结果分析
本文考察的是汉语隐喻特征的自动抽取方法,结果分析从2个方面进行.1) 分析模板自动抽取方式与模板人工抽取方式下的整体隐喻识别准确率变化情况;2) 分析自动抽取的模板与人工抽取的模板的变化情况.
图3和图4中分别描述的是在封闭测试和开放测试环境的不同抽取方式下,10组候选词的F值的变化情况对比.横坐标描述的是10组不同候选词,纵坐标描述的是F值(0≤F≤1).可以看到,无论在封闭测试,还是开放测试,在10组候选词的测试结果中,本文提出的自动抽取算法的整体F值相对于人工方式都有一定的提高.整体上看,在2种方式下,F值的取值走向一致也说明了机器学习的方式抽取模板可以很好地模拟具有相关知识背景的专业人士抽取方式,这从极大程度上解决了由人工抽取模板方法而导致的效率低下、无法扩充、主观性强的缺陷,说明了机器学习方式在隐喻计算领域的可行性.

图3 封闭测试F-Measure值结果Fig.3F-Measure result of closed test sets

图4 开放测试F-Measure值结果Fig.4F-Measure result of open test sets
另外,为了起参照作用,列举本文提出的自动模板抽取算法抽取的特征如表6所示.

表6 自动模板抽取
从以上的模板抽取结果可以看出,常规的简单特征在每个不同候选词的结果中会有不同的选择,并不是所有的简单特征都适用于所有模板.本文提出的另两类模板都有在最后的结果中出现,说明此两类模板确实是有效模板.必须看到的是,本文算法提取的是有效特征模板,而其对应的特征数量相较于人工提取方式而言还是比较多的.人工方式对于特征的提取,具体到每个候选词的每个特征的具体词;而模板方式抽取,只进行到特征模板层次,对于每个特征的具体实际选择包含的内容比较多.因此,在算法复杂度以及计算量上,自动抽取方式相较人工抽取方式会复杂得多;但自动抽取方式更加客观,并且是一般化的处理过程,减少了人工抽取方式的主观性缺陷.
4结论
本文从分析汉语隐喻计算中人工方式所带来的主观性以及规范性问题出发,构建了隐喻计算的2种分类任务,并利用机器学习方法对其进行建模,分别构造了隐喻识别和理解任务的分类模型,提出了一个机器学习方式自动抽取最优特征模板的算法.从实验结果看,相较于人工抽取模板的方式而言,准确率有显著的提高,其更重要的意义在于从大语料库出发,以机器学习方式取代人工规则方式所带来的主观性缺陷,是一种值得推广的学习方式.
本文的研究工作还有提升空间.本文算法的计算量大,对于某个候选词的特征模板选择在数量级上超过人工抽取方式,另外受语料库影响也比较大,这都是机器学习方式无法避免的弊端.进一步的改进任务在于:1) 本文主要是针对以名词为主体的隐喻现象的处理,可以将这种形式推广到动词、形容词性的短语隐喻描述,进一步的从短语级别推广到句子级别等;2) 针对文中提出的隐喻理解和隐喻生成模型提出适用于机器学习的算法进行尝试.
参考文献:
[1]LAKOFF G,JOHNSON M.Metaphors we live by[M].Chicago:University of Chicago Press,1980.
[2]GOALTY A.The language of metaphors[M].New York:Routledge,1997.
[3]RICOEUR P.活的隐喻[M].汪堂家,译.上海:上海译文出版社,2004.
[4]冯广艺.汉语比喻研究史[M].武汉:湖北教育出版社,2002.
[5]冯晓虎.隐喻:思维的基础 篇章的框架[M].北京:对外贸易大学出版社,2004.
[6]胡壮麟.认知隐喻学[M].北京:北京大学出版社,2004.
[7]束定芳.隐喻学研究[M].上海:上海外语教育出版社,2000.
[8]杨芸.汉语隐喻识别与解释计算模型研究[D].厦门:厦门大学,2008.
[9]苏畅.汉语名词性隐喻的计算方法研究[D].厦门:厦门大学,2008.
[10]王治敏.汉语名词短语隐喻识别研究[D].北京:北京大学,2006.
[11]黄孝喜.隐喻机器理解的若干关键问题研究[D].杭州:浙江大学,2009.
[12]周昌乐.意义的转绎:汉语隐喻的计算释义[M].北京:人民出版社,2009.
[13]贾玉祥.基于实例的隐喻理解与生成[J].计算机科学,2009,36(3):138-141.
[14]王治敏.名词隐喻的计算研究及识别实验[J].语言教学与研究,2008(2):68-74.
[15]冯帅,苏畅,陈怡疆.基于百科资源的名词性隐喻识别[J].计算机系统应用,2013,22(10):8-14.
[16]YAO G,ZENG H L,CHAO F,et al.Integration of classifier diversity measures for feature selection-based classifier ensemble reduction[C]∥Soft Computing.Berlin:Springer Berlin Heidelberg,2015:1-11.
[17]DIAO R,CHAO F,PENG T,et al.Feature selection inspired classifier ensemble reduction[J].IEEE Transactions on Cybernetics,2014,44(8):1259-1268.
[18]贾玉祥,俞士汶.基于词典的名词性隐喻识别[J].中文信息学报,2011,25(2):99-104.
[19]何径舟,王厚峰.基于特征选择和最大熵模型的汉语词义消歧[J].软件学报,2010,21(6):1287-1295.
[20]全昌勤,何婷婷,姬东鸿,等.基于多分类器决策的词义消歧方法[J].计算机研究与发展,2006,43(5):933-939.
[21]BERGER A L,PIETRAY S A D,PIETRAY V J D.A maximum entropy approach to natural language processing[J].Computational Linguistics,1996,22(1):1-36.
Chinese Metaphor Computation Based on Automatic Feature Selection
ZENG Hualin,ZHOU Changle*,CHEN Yidong,SHI Xiaodong
(Fujian Key Lab of the Brain-like Intelligent Systems,School of Information Science and Engineering,Xiamen University,Xiamen 361005,China)
Abstract:Chinese metaphor computation is one of difficult problems in the Chinese information processing.It is very subjective and difficult for existing research methods by manually analyzing and extraction of metaphor feature.For the purpose of analyzing the traditional rule-based methods,a new machine learning method based on large scale corpus is proposed for metaphor recognition.The proposed method uses the maximum entropy model,and three different feature patterns,which are common features,large-scale context information,and the similarity of candidate words, to describe semantic information.Experimental results show that the proposed method can improve the accuracy of the metaphor recognition,and also indicate the effectiveness of the proposed machine learning method for metaphor computation.
Key words:Chinses metaphor computation;metaphor recognition;machine learing;automatic feature selection
doi:10.6043/j.issn.0438-0479.2016.03.018
收稿日期:2015-11-17录用日期:2016-04-06
基金项目:国家自然科学基金(61573294);国家科技支撑计划(2012BAH14F03);教育部博士学科点基金博导类项目(20130121110040)
*通信作者:dozero@xmu.edu.cn
中图分类号:TP 391.1
文献标志码:A
文章编号:0438-0479(2016)03-0406-07
引文格式:曾华琳,周昌乐,陈毅东,等.基于特征自动选择方法的汉语隐喻计算.厦门大学学报(自然科学版),2016,55(3):406-412.
Citation:ZENG H L,ZHOU C L,CHEN Y D,et al.Chinese metaphor computation based on automatic feature selection.Journal of Xiamen University(Natural Science),2016,55(3):406-412.(in Chinese)
