基于朴素贝叶斯算法的垃圾短信智能识别系统
2016-06-14刘秋阳林泽锋栾青青
刘秋阳+林泽锋+栾青青
摘要:在信息化时代,垃圾短信、诈骗短信越来越成为人们日常生活中的困扰。在对垃圾短信的发展及市面上现有的拦截垃圾短信的软件进行分析后,发现垃圾短信为了躲避拦截在不断变化,拦截软件需要更加智能的去识别这些垃圾短信。为了应对不断变化的垃圾短信,为了解决联网举报、黑白名单等传统垃圾短信拦截模式触及不到的盲区,提出通过机器学习的方式让垃圾短信的拦截更加具智能化。该文就解决垃圾短信智能识别的问题,主要阐述了基于朴素贝叶斯公式的垃圾智能识别算法,分析了其算法效率,介绍了该算法在安卓平台上的设计,并对该系统进行了测试和评估。
关键词:垃圾短信智能识别;机器学习;朴素贝叶斯公式
中图分类号:TP18 文献标识码:A 文章编号:1009-3044(2016)12-0190-03
1 概述
1.1 背景介绍
科技高速发展的今天,智能手机已经越来越成为人们日常生活中必不可缺少的一部分了。骚扰电话和垃圾短信不仅严重干扰了人们的日常生活,甚至对于那些认知能力较差的群体,容易使其上当受骗,造成精神和财产上的损失。国家立法并不完善,无法做到手机号码实名制,预防垃圾短信的任务艰巨困难。现在市面上的垃圾短信拦截软件普遍具有以下缺点:
1)不支持用户个性化的识别功能。每台手机无法根据用户的偏好提供相应的拦截服务;
2)很大程度依赖黑白名单,在白名单联系人手机被盗后无法预防诈骗短信;
3)收集用户信息。需要连接网络,将用户的信息上传至企业,一定程度上侵害了用户的隐私权。
1.2 我们的改进
针对以上情况,为了更好识别、过滤垃圾短信,在本文中,我们设计了一种基于朴素贝叶斯算法的垃圾短信智能识别系统。该系统存储了大量有利于判别垃圾短信的关键词,根据短信内容中出现的关键词进行垃圾短信判断,也可以根据用户的反馈进行智能学习,提供符合用户需求的服务。除此之外,在不连接移动蜂窝网络的情况下也可正常使用,不会将数据上传至服务器,保证不对用户的信息进行收集与窃取。
2 贝叶斯算法
2.1 贝叶斯算法的简介
朴素贝叶斯算法是用于分类的概率算法,在具有大量数据的情况下通过概率分析、判定某物是否能归于某类,具有很高的准确度。对于拦截垃圾短信这一课题,我们也可以用朴素贝叶斯公式对短信进行分类,类别有二:垃圾短信和正常短信,在具备大量关键词出现概率的条件下我们能对短信进行实时分类,实现了对垃圾短信的判定。
2.2 分类器的数学模型
根据测试,MI>2时该特征能起到判别的作用,故此值可作为选择关键词的依据。无论一个关键词是集中出现在垃圾短信中还是集中出现在正常短信中,该关键词对区分垃圾短信与正常短信都产生了贡献,应收纳进关键词数据库中。但事实上,垃圾短信数量与正常短信数量有很悬殊的差距,正常短信的数量要远大于垃圾短信的数量,若选取集中出现在正常短信的关键词,该关键词的MI值很难大于2。故实际运用中多数选取集中出现在垃圾短信的关键词作为特征。
5 算法效率分析
在具备各个关键词的相关条件概率和先验概率的情况下,可以对短信进行判断。先验概率的计算只需一步即可完成,时间效率是线性的。计算关于各个关键词的条件概率是需要进行累乘来实现。假设有N个关键词,其中包含在短信文本中的关键词有N个,累乘的时间效率为O(N)。根据经验,一个短信文本中含有的关键词数量远不及存储的关键词集,N< 6 系统设计与实现 6.1 系统的组成 该智能识别垃圾短信系统主要包含两个功能,判断垃圾短信功能和智能学习功能。判断垃圾短信功能分为下面三个部分:识别短信部分、比较关键词部分和计算概率部分。学习功能由用户反馈的机制实现,具体分为:手动添加垃圾短信,手动删除垃圾短信。 6.2数据库的设计 除了存储各个能作为判别特征的关键词,还应该在数据库中存储该关键词相应的属性,包括:各个关键词在垃圾短信中存在的个数、各个关键词在正常短信中存在的个数,这二者帮助系统计算条件概率。但仅是这些还不够,根据前文所述,该系统所需要存储的数据还包括统计的所有垃圾短信的个数和所有正常短信的个数,这样一来,系统通过总体数目的比值求得先验概率,利于我们进行之后的判断。 6.3 判断垃圾短信的流程 如图1所示, 1)识别短信。当接到一条短信后系统首先识别该条短信,判断其是图片形式的短信还是文字形式的短信。若为图片,系统采用OCR算法将图片转化为文字,若为文字则不进行转化。 2)统一将短信识别成文字后,将该段文字与手机中的关键词数据库中的关键词逐个进行比较。利用KMP算法进行对每个关键词的比较,比较n次(n为数据库中关键词的个数),可以找出既存在于该段文字又存在于关键词数据库的关键词。从数据库中找到并记录有关这些关键词的概率。 3)利用朴素贝叶斯公式整合这些概率进行计算,如2.2所述。若最终算得该短信是垃圾短信的概率较是正常短信的概率大,则判断该短信为垃圾短信。进而,阻止短信接收。 6.4 根据用户标记智能学习功能 用户对垃圾短信的认定一定程度上是个性化的,在系统帮助筛选大部分垃圾短信的同时,还应留给用户一定权限去更改关键词判断时的权重。在用户的角度上,该学习机制分为两个功能,一是将垃圾短信标记为正常短信,二是将正常短信判定为垃圾短信。用户可以获取垃圾短信列表,把自己认定不是垃圾短信的短信进行标记,此时,通过KMP算法扫描出该条短信具有数据库中哪些关键词,把这些关键词在正常短信中存在的个数加上1,在垃圾短信中存在的个数减去1。然后垃圾短信的总个数减去1,正常短信的总个数加上1;同理,用户还可以将正常短信判定为垃圾短信,过程与上述相似,只是在数据库中各个数据的变化情况与之相反。用户获取短信列表后,选择想标记为垃圾短信的短信,事件发生后用KMP做相似处理,数据库中各个相关数据进行相应变化。从系统的角度上,用户的选择改变了判断垃圾短信时的先验概率与条件概率,对最后的结果产生了影响。
6.5 系统效率分析
时间效率的分析:在判断垃圾短信功能部分,将该段文字与数据库中关键词比较所采用的KMP算法效率分析如下:已知两个长度分别为m和n的字符串之间用KMP算法进行匹配,需要O(m+n)[2]。在实际中,文本长度m远大于关键词长度n,故n可以忽略不计,则用一个关键词去匹配文本需要的时间是O(m),假设数据库中含有N个关键词,则通过KMP算法比较得出短信文本中含有的数据库中的关键词这一步骤需要O(m*N)的时间。计算过程的效率分析即是朴素贝叶斯的算法效率分析,已在2.3论述。在智能学习部分,系统同样需要扫描短信文本比较找出既存在文本中又在数据库中的关键词。此时,用KMP算法完成该步骤,效率同样是O(m*N)。相对于识别与计算,整个系统耗时最大的部分在于KMP算法扫描比较文本与数据库中的关键词,是主要的时间消耗部分。
6.6 系统测试与评估
经统计,527条短信中,有500条正常短信,有27条垃圾短信。选取了下列一些关键词,并统计了它们分别在垃圾短信和正常短信中出现的个数。根据2.2特征的选取,以下几个关键词可以作为特征存储到数据库中:楼盘、工行卡号、办号、情色、大盘、未读信息、换号、打钱、收购。且这些关键词都是有助于判断短信为垃圾短信的关键词。
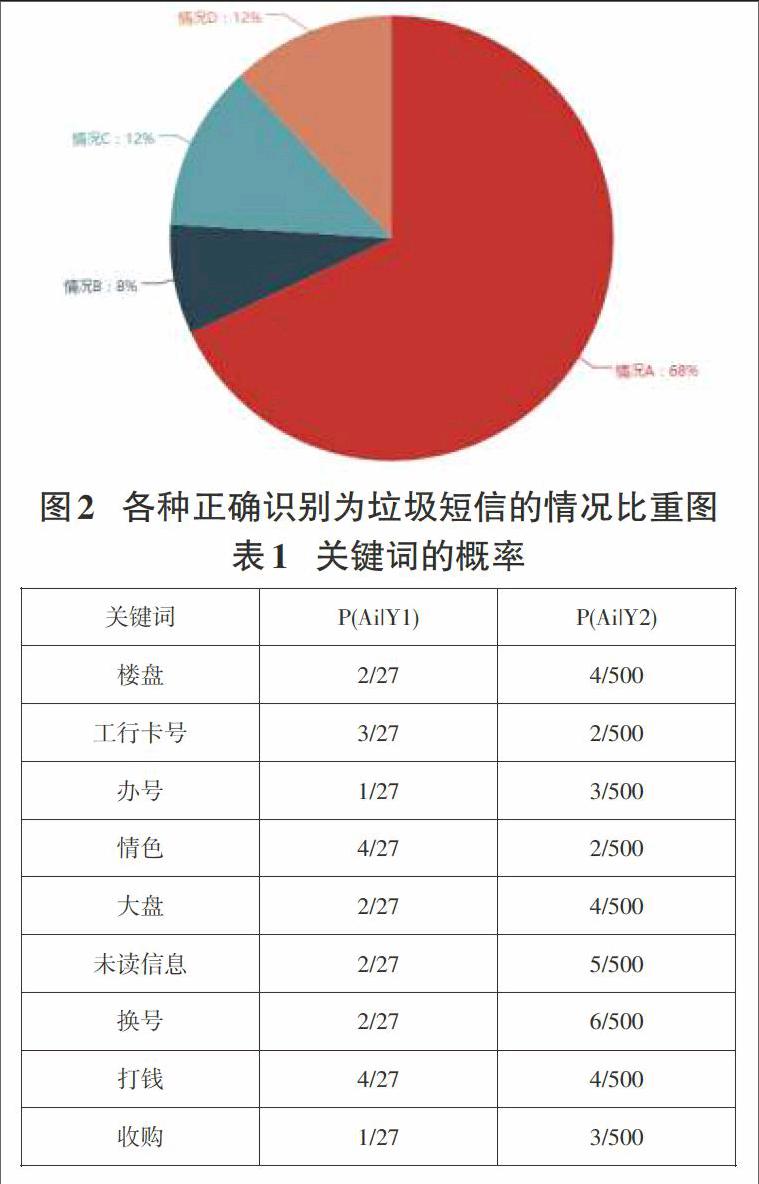
经测试,若一条短信包含以上关键词的个数大于等于2,则系统判定其是垃圾短信(情况A)。在短信只包含其中一个关键词情况中,包含有些特征效果明显的关键词(MI数值大)的短信能被判定为垃圾短信(情况B)。其他的短信尽管包含有助于判断为垃圾短信的关键词,但该关键词的MI值不足以支持该关键词单独存在去直接判断其为垃圾短信,这部分的短信被系统认定为正常短信。
只包含楼盘这一关键词的短信被系统判定是正常短信。此时用户若手动标记其为垃圾短信,第二条只包含楼盘这一关键词的短信接收时就会被系统屏蔽掉(情况C)。
只包含收购这一关键词的短信被系统为正常短信,且用户需要标记两次,下次发送同样短信即可判断为垃圾短信(情况D)。在本次测试的数据中没有出现需要标记三次的情况。
经过统计,27条垃圾短信中,有25条短信可以最终被识别为垃圾短信。识别率为92.6%。
在这25条中,情况A占了17条,情况B占了2条,情况C占了3条,情况D占了3条。
参考文献:
[1] 余芳,姜云飞.一种基于朴素贝叶斯分类的特征选择方法[J].中山大学学报,2004,9(5):119-120.
[2] 杨战海.KMP模式匹配算法的研究分析[J].计算机与数字工程,2010,38(5):38-41.
