基于语义和图的文本聚类算法研究
2016-05-04周文乐
蒋 旦,周文乐,朱 明
(中国科学技术大学 信息科学技术学院,安徽 合肥230027)
基于语义和图的文本聚类算法研究
蒋 旦,周文乐,朱 明
(中国科学技术大学 信息科学技术学院,安徽 合肥230027)
传统的文本聚类往往采用词包模型构建文本向量,忽略了词语间丰富的语义信息。而基于中心划分的聚类算法,容易将概念相关的自然簇强制分开,不能很好地发现人们感兴趣的话题。该文针对传统文本聚类算法的缺点,提出一种基于语义和完全子图的短文本聚类算法,通过对目前主流的三大语义模型进行了实验和对比,选择了一种较为先进的语义模型,基于该语义模型进行了聚类实验,发现新算法能较好地挖掘句子的语义信息且较传统的K-means有更高的聚类纯度。
文本聚类;完全子图;语义相似度;词向量
1 引言
文本聚类,在自然语言处理、人工智能和机器学习领域占有重要地位,它提供了一种从文本数据中自动学习知识的方法,可以从海量数据中挖掘人们感兴趣的话题。而文本(语义)相似度的计算是文本聚类的先决条件。
经典的自然语言处理方法主要有两种: 一种是基于词包(bag-of-words)的统计数学模型,采用one-hot 的表示方法将词转换成一个高维的稀疏向量,维数等于词汇量的大小,进而由词向量的加和表示语句,忽略词语之间语义联系以及词序。这种基于统计模型的方法虽然简单,但是由于没有考虑语言的语义这一重要属性,表达能力有限,在复杂的涉及语义理解的文本聚类、机器翻译等任务中表现不佳;另一种是基于语义词典的方法,基于人工编纂的语义词典,通过两个词在词典树形关系图中的距离以及同义反义词关系来计算两个词之间的语义相似度,然后通过某一种特定的词汇组合方式表达句子之间的相似度。这方面的研究成果有英文的WordNet、中文的《知网》《同义词词林》等。然而这类方法存在很多缺陷[1]: 词典的编纂需要投入大量的人力且严重依赖人的主观判断,更新速度慢,覆盖的词汇范围非常有限。于是一方面人们期望建立好的语言模型和相似度度量,作为文本聚类和机器学习的基础;另一方面,人们也期望不采用人工而是通过机器学习的方法,自动学习词语的语义表示,更好地挖掘文本的深层信息。
我们的研究正是机器学习与自然语言处理的融合。具体来说,我们首先通过机器学习完成语义模型的训练;然后设计实验观察实验效果选择好的语义模型,并且基于选择的语义模型,提出一种基于图的文本聚类算法;最后通过实验证明了算法的可行性和优点。
本文章节安排如下: 第二节介绍了关于语义模型和图聚类算法的相关工作;第三节阐述了本文提出的基于语义和图的文本聚类算法的框架;第四节介绍了关于选择语义模型和算法验证的两组实验设计及结果;第五节对本文工作进行了总结并提出了对未来工作的展望。
2 相关工作
国内关于语义相似度的研究一直比较少,其中较为突出的是文献[2]中刘群等提出的基于《知网》以及另一个同样基于词典的哈工大的《同义词词林》的词汇语义相似度计算,而中文方面也缺少比较权威的语义相似度的测试集。
国外比较早的研究有由Scott Deerwester等于1990年提出的潜在语义分析算法[3](LSA,Latent Semantic Analysis),LSA算法构造单词—文档矩阵,基于单词在文档中TF-IDF(词频—逆文档频率)统计发掘词语之间的潜在语义关系,并通过SVD(奇异值分解)将文档向量映射到LSA语义空间,以达到降维和降噪的目的,此时便可以在低维的LSA语义空间计算文档的相似度。该算法已经在信息检索领域取得巨大成功并得到广泛应用。
之后针对潜在语义分析Gabrilovich于2006年提出另一著名算法显明语义分析[4-5](ESA,Explicit Semantic Analysis),ESA算法同样构造一个单词-文档矩阵,不过此时每一个文档对应于Wikipedia中的一个词条,也即一个概念,单词在该词条文档中的TF-IDF值表明了单词与概念的相关度。于是ESA算法将单词与文档映射到Wikipedia概念空间,得到单词或文档的一个高维向量表示,进而计算单词或文档的相似度。该算法在WordSimilarity-353测试集上取得了0.75的准确率,代表了当时的最高成就。
近年来,基于神经网络(深度学习)的语言模型重新得到重视。Bengio在文献[6]中提出一种神经网络概率语言模型,该模型为由一个线性映射层和一个非线性隐层构成的前向神经网络,其中提到通过训练语言模型可以同时得到词向量(Distributed representations of words in a vector space)。之后Mikolov在研究中简化了Bengio提出的神经网络模型,提出CBOW模型和Skip-gram模型[7-8],这两个模型的最终目的并不是为了训练一个语言模型,而只是为了得到单词的语义向量,简化后的模型提高了训练速度,而得到的词向量则可以被利用在各种不同的自然语言处理任务中。除了Mikolov提出的词向量模型外,文献[9-10]等也提出了类似的词向量模型,文献[11]则将这一模型利用于构建中文分词系统,取得一定成效。
有关图的聚类算法较为经典的有变色龙算法(Chameleon Algorithm)和谱聚类算法(Spectral clustering)。基于图的聚类算法基本思想是将一般的聚类问题通过邻近度矩阵转换成图的划分问题。而谱聚类算法又巧妙地将图的分割问题转换成拉普拉斯矩阵特征向量的聚类问题[12]。Chameleon算法则在图分割后采用层次聚类进一步合并图分割中产生的各个小簇,得到最终的聚类结果[13]。本文提出的基于语义和完全子图的聚类算法,结构上和Chameleon算法非常类似,它们之间的区别将在下文介绍。
3 基于完全子图的聚类算法
3.1 图的基本理论
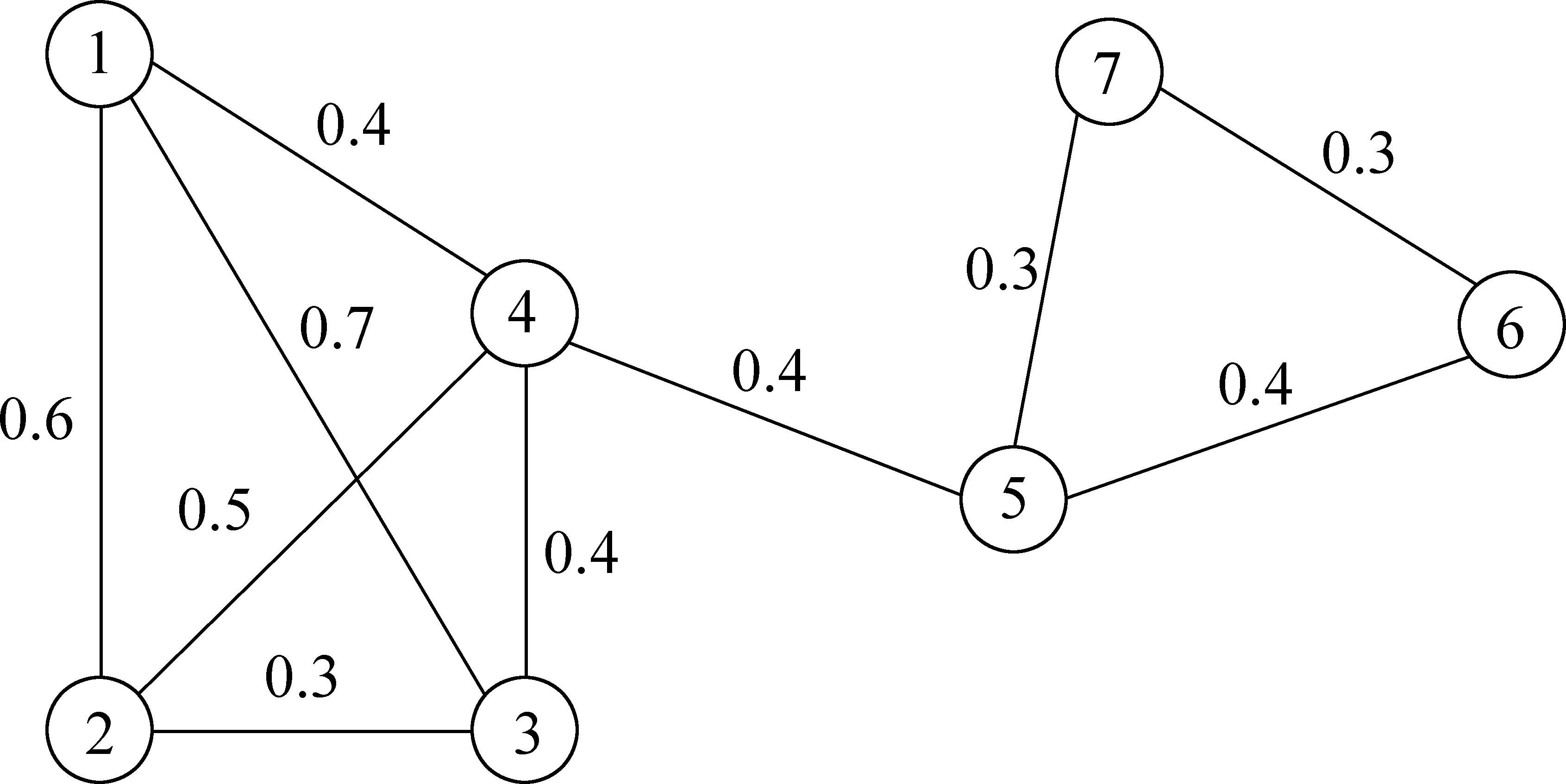
图1 无向图
3.2 算法描述
基于语义和完全子图的聚类算法步骤如下:

算法3.2 基于语义和图的聚类算法1:对于给定的文档集xi{},计算文档对象之间的语义距离矩阵Dij{}2:构建图GV,E(),并选择恰当的距离阈值,进行图的稀疏化3:将图G的所有边对象edgei,j,w()按距离w升序排列得到ES,index=-14:repeat:5: repeat:6: index++7: until:index≥ES或者graph中存在边ESindex[]8: ifindex≥ESthen将剩余孤立点分别作为单独的簇加入CS,break9: endif10: 选取ESindex[]的顶点作为扩展的初始结点np加入到簇C,将所有与np连接的顶点按距离升序排列得到VS11: repeat:12: 依次从VS中选取顶点加入到簇C,并判断是否满足完全子图的要求,满足保留,否则抛弃13: until:VS为空14: 得到一个簇C,加入CS,从G中删除C15:until:G为空16:得到所有的簇CS,计算簇之间的距离矩阵DCij{}17:对簇集合CS重复2~15得到簇的聚类CCS18:综合CS和CCS输出最后聚类结果
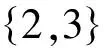
由于基于完全子图的聚类要求结点之间具有全连接,可以保证聚类的结点都有较高的语义相似度,但是此时得到的聚类数目可能较多,我们需要进一步的聚合。算法3.2中的16~17即是对初次聚合的簇进行二次聚类。簇之间的距离度量可以采用层次聚类[15]中三种簇的邻近性度量中的任何一种: 单链: 两个簇中距离最小的两个点的距离;全链: 两个簇中距离最大的两个点的距离;组平均: 两个簇中所有点两两之间距离的均值。本文采用第三种对噪声数据不太敏感的组平均度量。
综合两次聚合结果,即可得到最终的聚合簇。
3.3 算法复杂度分析
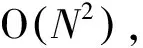
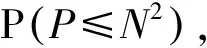
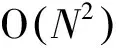
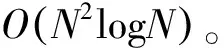
3.4 与传统聚类算法的对比
相比于K-means算法,图聚类算法不受质心的约束,并通过强连接性保证簇的纯度,而且无需指定最终的聚类类别(K-means的K值)就能自动完成聚类。
从结构上来看,本文提出的算法与Chameleon算法非常相似。算法大体分为三个步骤: (1)稀疏化; (2)图划分; (3)聚类。前者采用固定阈值稀疏化,而Chameleon采用k近邻稀疏化;前者通过提取团来对图进行分割,后者则通过多层图划分将图分割到足够小,而两者的目的都是为保证子簇的纯度;对于聚类,前者依旧采取团提取方式,而后者采用层次聚类。基于完全子图的聚类算法和Chameleon算法具有相同的计算复杂度。
4 实验及结果
4.1 语义模型训练及选择
本文采用的训练语料库为截止至2015年3月1号的中文维基百科所有词条文档。维基百科是当前最具影响的互联网百科全书,由来自世界各地的志愿者合作编辑而成,内容覆盖广、更新速度快、词条质量高(这一要求对于基于概念的ESA模型是至关重要的,ESA模型将每一个文档视为语义空间的一个概念,因此要求文档内容是概念相关并且尽量准确的)。经过文本提取、繁化简、分词、过滤短文本和过滤低频词预处理,最后剩下308 345个词条,包含的词汇大小为665 941,文本总大小约1GB。
分别训练了LSA,ESA以及词向量模型,其中LSA和词向量维数均为100维(选取更大维数,得到的词或文档向量将包含更多的语义信息,但训练时间更长,存储更大)。对于词向量模型,正如Mikolov在文献[7]中提到的,向量之间满足一定程度的线性运算关系,我们测试了向量[“中科大”]-向量[“中国”]+向量[“美国”]得到的最相似的结果是向量[“普渡大学”](0.755,相似度),而向量[“哈佛大学”]-向量[“美国”]+向量[“中国”]得到的最相似的结果是向量[“北京大学”](0.761)。
我们设计了一个检索实验来考察三个语义模型的效果,实验数据为从互联网爬取的约48万条各类新闻标题中随机抽取的1 000条,首先分别转换成三个语义模型下的向量,然后通过选取不同类别中具有代表性的条目,计算围绕该样本条目最相似的k=10个样本,通过人工评测比较不同语义模型下的检索结果。经过多组对比实验发现词向量能较好地捕获文本深层次的语义信息。表1中以“文化”类别为例,列举了三个模型前五条检索结果。
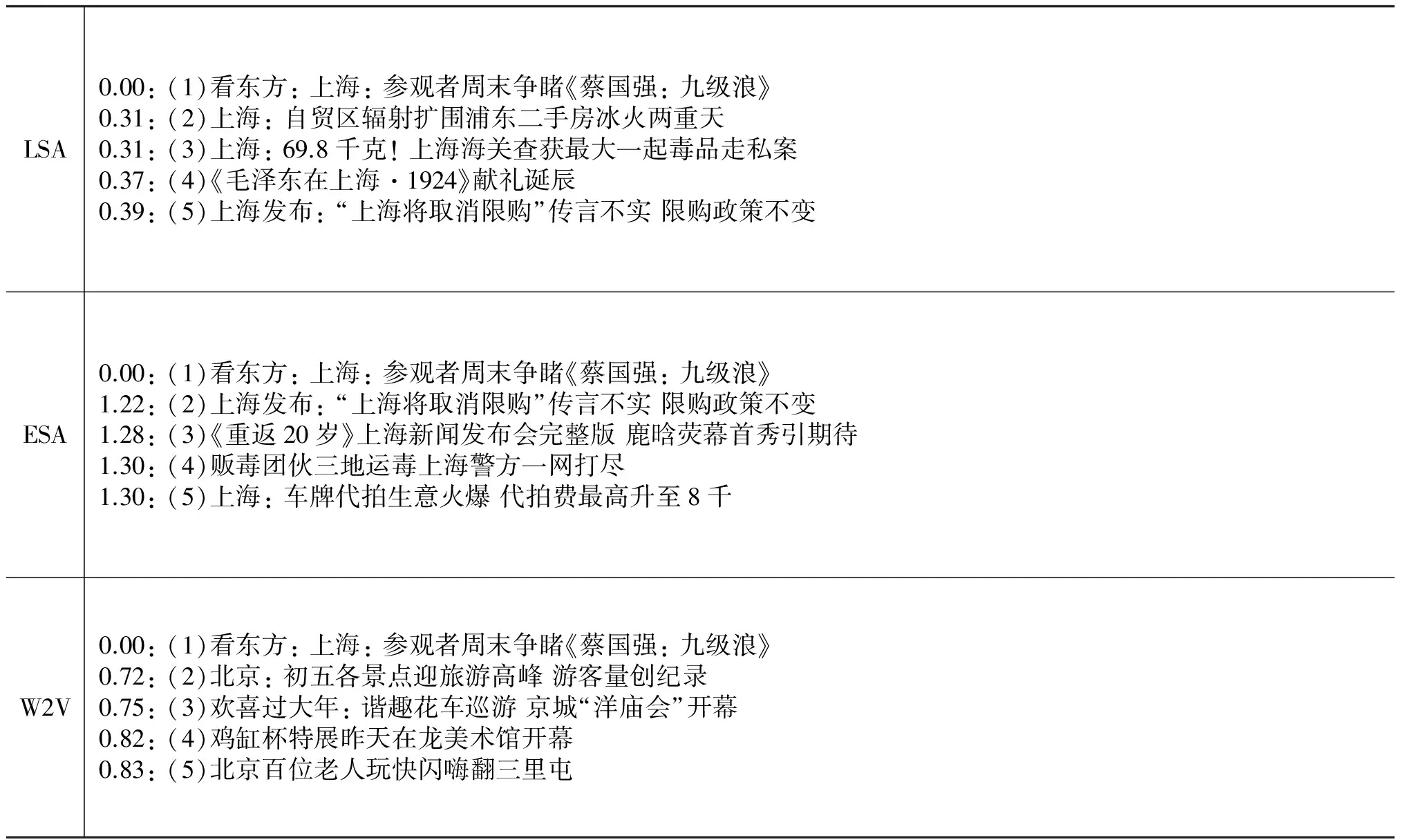
表1 LSA、ESA、W2V模型语义检索实验结果
表1中第(1)条为检索条目,(2~5)为检索的相似结果,分别按语义距离排名,条目前列出了两位小数的距离值,不同语义模型之间的距离不具有可比性。从检索结果看出,LSA和ESA模型侧重于关键字“上海”,结果中均是属于上海的新闻,而W2V模型则侧重于“文化”这一主题。虽然三种模型在不同环境下各有优势,但是对于新闻,人们的兴趣可能更倾向于相似的主题。
另外我们统计了1 000条新闻标题之间的语义距离得到如下语义距离的概率密度曲线。
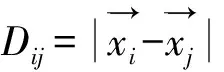
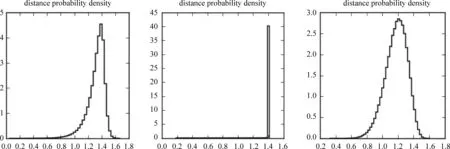
图2 距离概率密度曲线(LSA、ESA、W2V)
综合评估下,我们选用了倾向相似主题并具有较好区分度的W2V(词向量)模型作为比较K-means和完全子图聚类算法的语义模型。
4.2 基于语义和图的文本聚类实验
以W2V语义模型为基础,我们通过实验对比了基于图的聚类算法和传统的K-means算法的聚类效果。实验设计如下: 依然采用前面抽取的1 000条新闻标题作为数据集,转化为W2V空间的语义向量并计算距离矩阵;分别采用基于图的聚类算法和K-means算法聚类;随机选择不同类别中若干具有代表性的样本,计算样本所在类别中与该样本最邻近的n个样本作为聚类代表,最后分析和评价聚类效果。
关于K-means算法中的K值选取,我们参考了K-means方法在上述数据集上的SSE(Sum of the Squared Error)曲线和平均轮廓系数(Silhouette Coefficient)曲线[15],如图3所示。从图中可以看出,SSE曲线随簇数增加而递减但并没有明显的转折点,而轮廓系数曲线存在多个波峰,其中四个明显的波峰分别是8、12、17和21,为了获得较多的感兴趣簇,我们选择了K=21。对于基于图聚类算法中图稀疏化阈值的选取,初始聚类和对簇的二次聚类我们均采取保留1/3连接的策略,即对距离矩阵升序排序后选择排序在1/3处的距离作为阈值,这样选取的是因为一方面保留1/3的边连接可以保证相连结点之间相似度较高;另一方面在该实验中除去少数孤立点后,也可以得到近20个簇,和K-means中的K值相当。
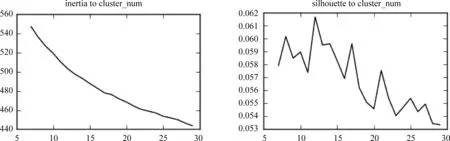
图3 K-means算法SSE曲线(左)、轮廓系数曲线(右)
表2中列举了五个不同标签下的聚类结果,表中第一列标示了所采用的算法,以及聚类后人为标定的标签。第二列和表1中的含义相同。

表2 W2V模型下K-means和完全子图聚类结果
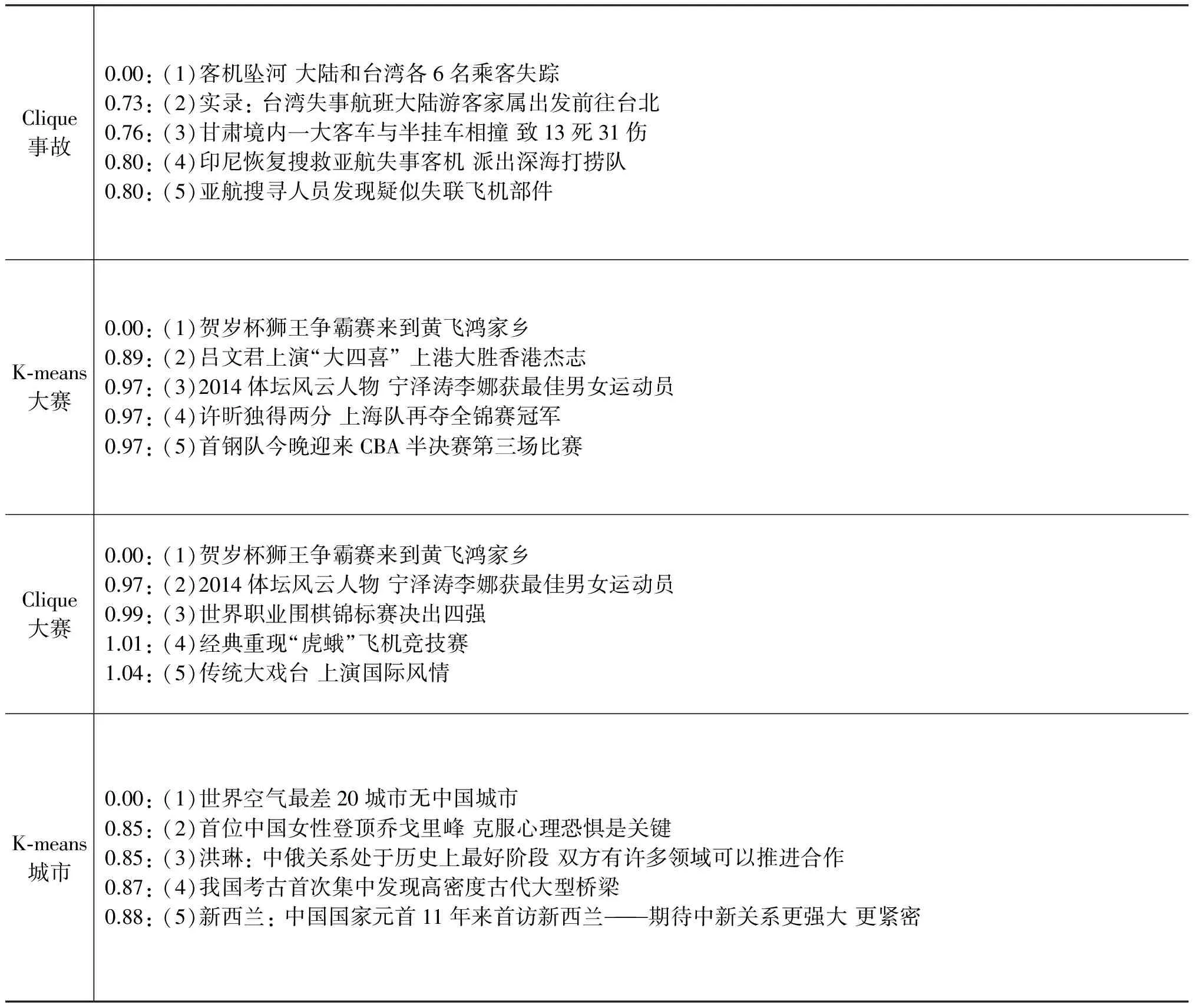
续表

续表
对比于表3中基于W2V语义模型的K-means聚类结果,基于完全子图的聚类表现出一定的优势,“国际”标签中后者聚类的结果更加贴合选择的代表样本(1)中“合作”这一主题;“事故”标签中后者更强调“坠机”事件;“大赛”标签中则注重于“文化”领域;“城市”标签也更贴合“品牌”这一主题。对于“体育”、“财经”、“政治”等特征比较明显的标签,则两种算法的聚类几乎差不多,表中未一一列举。
分析实验数据我们还可以发现尽管一些样本和选择的代表样本本身相似度更高(同一语义模型下的距离更小),按照K-means它们将聚为一类,而基于完全子图的算法却没有把它们聚成一类,例如,“事故”标签K-means聚类中的(2)(以下记作K-2)与(1)的距离为0.72,而完全子图算法中(2)(以下记作G-2)与(1)的距离为0.73,完全子图算法聚合了G-2这一样本却没有包含K-2,K-(3~5)样本的距离也分别小于G-(3~5)的距离。同样的现象也出现在“大赛”、“城市”标签的聚类结果中。
这种现象可以简单地解释如下: 如果已知A和B相似,现在判断C是否与A相似,根据K-means算法,只要C和A足够近似就可以了,而完全子图还需要C和B也足够近似,这个要求体现在满足极大完全子图的条件中。因此完全子图聚类能够得到一个相关度更强的类。
当然基于极大完全子图的聚类算法也有一定的缺陷,即容易产生孤立点(本文对孤立点的处理方式是让其单独成簇),而K-means的聚类则不会出现这样的现象。
5 总结与展望
本文基于中文维基百科训练并比较了三种语义模型,并提出一种基于语义和图的文本聚类算法,该算法能够从语义层次对文本进行聚类,并且相对于传统的K-means算法具有一定的优势。文中详细阐述了算法的原理及特点,并通过实验验证了算法的可行性及优势,在语义聚类方面表现出巨大潜力。
在语义模型方面,本文采用词向量加和构成句子的语义向量。而文献[17]中提出的PV(Paragraph Vector)算法则试图直接训练句子或文档的语义向量。由于词向量的这种简单组合方式并不能很好地表示句法结构,直接训练句子的语义向量在语义挖掘上可能会更具优势。另外,近年来深度学习在图像处理、语音识别领域取得了突破性进展,其强大的特征提取能力也有望在自然语言处理领域做出贡献[18]。
在聚类算法方面,随着机器学习与各学科的融合,聚类算法被应用到各个领域,同时也出现许多从具体领域衍生出的聚类算法。例如,曾应用于计算机视觉领域的谱聚类[12]算法现在作为一种通用机器学习方法表现十分突出。而基于图的聚类算法依然具有很大的挖掘空间,仍将会是机器学习领域研究的热点。
[1] Ping L. 词汇相似度研究进展综述[J]. 现代图书情报技术, 28(7/8): 82-89.
[2] 刘群, 李素建. 基于《知网》 的词汇语义相似度计算[J]. 中文计算语言学, 2002, 7(2): 59-76.
[3] Deerwester S C, Dumais S T, Landauer T K, et al. Indexing by latent semantic analysis[J]. JAsIs, 1990, 41(6): 391-407.
[4] Gabrilovich E, Markovitch S. Computing Semantic Relatedness Using Wikipedia-based Explicit Semantic Analysis[C]//Proceedings of IJCAI.2007, 7: 1606-1611.
[5] Gabrilovich E, Markovitch S. Wikipedia-based semantic interpretation for natural language processing[J]. Journal of Artificial Intelligence Research, 2009: 443-498.
[6] Bengio Y, Ducharme R, Vincent P, et al. A neural probabilistic language model[J]. The Journal of Machine Learning Research, 2003, 3: 1137-1155.
[7] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv.2013: 1301,3781.
[8] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]//Proceedings of the Advances in Neural Information Processing Systems.2013: 3111-3119.
[9] Collobert R, Weston J, Bottou L, et al. Natural language processing (almost) from scratch[J]. The Journal of Machine Learning Research, 2011, 12: 2493-2537.
[10] Pennington J,Socher R, Manning C D. Glove: Global vectors for word representation[J]. Proceedings of the Empiricial Methods in Natural Language Processing (EMNLP 2014), 2014: 12.
[11] 来斯惟, 徐立恒, 陈玉博, 等. 基于表示学习的中文分词算法探索[J]. 中文信息学报, 2013, 27(5): 8-14.
[12] Von Luxburg U. A tutorial on spectral clustering[J]. Statistics and computing, 2007, 17(4): 395-416.
[13] Karypis G, Han E H, Kumar V. Chameleon: Hierarchical clustering using dynamic modeling[J]. Computer, 1999, 32(8): 68-75.
[14] Bron C, Kerbosch J. Algorithm 457: finding all cliques of an undirected graph[J]. Communications of the ACM, 1973, 16(9): 575-577.
[15] Tan P N, Steinbach M, Kumar V. Introduction to data mining[M]. Boston: Pearson Addison Wesley, 2006.
[16] Karp R M. Reducibility among combinatorial problems[M]. springer US, 1972.
[17] Le Q V, Mikolov T. Distributed representations of sentences and documents[J]. arXiv.2014: 1405,4053.
[18] Mnih A, Hinton G. Three new graphical models for statistical language modelling[C]//Proceedings of the 24th international conference on Machine learning. ACM, 2007: 641-648.
Research on Text Clustering Based on Semantics and Graph
JIANG Dan, ZHOU Wenle, ZHU Ming
(School of Information Science and Technology ,University of Science and Technology of China,Hefei,Anhui 230027,China)
Traditional methods for text clustering have generally taken the BOW (bag-of-words) model to construct the vector of document, ignoring semantic information between words. And partitioning clustering method based on centroid tends to split concept closely related clusters stiffly, not suitable for mining interesting topics. To address these issues, , this paper proposes a text clustering method based on semantics and cliques. Compared with three popular semantic models, experiments reveal that our method performs better than K-means on semantic clustering task.
text clustering method;complete sub-graph;semantic similarity;distributed representations of words in a vector space

蒋旦(1992—),硕士,主要研究领域为自然语言处理与数据挖掘。E⁃mail:djiang@mail.ustc.edu.cn周文乐(1989—),硕士,主要研究领域为推荐系统,数据挖掘。E⁃mail:zhouwenle@outlook.com朱明(1963—),博士,教授,博士生导师,主要研究领域为视频大数据分析,智能机器人,未来网络。E⁃mail:mzhu@ustc.edu.cn
1003-0077(2016)05-0121-08
2015-04-07 定稿日期: 2015-06-02
海量网络数据流海云协同实时处理系统(子课题)(XDA06011203);电视商务综合体新业态运营支撑系统开发(2012BAH73F01)
