词汇语义表示研究综述
2016-05-04袁书寒
袁书寒,向 阳
(同济大学 电子与信息工程学院,上海 201804)
词汇语义表示研究综述
袁书寒,向 阳
(同济大学 电子与信息工程学院,上海 201804)
构建能够表达语义特征的词语表示形式是自然语言处理的关键问题。该文首先介绍了基于分布假设和基于预测模型的词汇语义表示方法,并给出目前词表示方法的评价指标;进而介绍了基于词汇表示所蕴含的语义信息而产生的新应用;最后,对词汇语义表示研究的方法和目前面临的问题进行了分析和展望。
词汇表示;语义;分布假设;深度学习
1 引言
语义是语言形式所要表达的内在含义,体现了人对语言的反映和认识。让计算机理解自然语言的内容是自然语言处理领域研究的最高目标。由于自然语言具有模糊性、歧义性、复杂性等特点[1],使得计算机理解人类语言、了解其中语义十分困难。词汇作为文本的基本组成单元,是自然语言处理研究的最小对象,建立适当的词汇语义表示方式是实现自然语言理解的基础。
利用计算机实现词汇的语义表示并不是表达抽象的语言语义,而是一种计算模型。但是,由于自然语言本身的复杂性,没有一套完备的理论可用于指导词汇语义的模型化;因此,不同的词汇语义表示方法本质是依据语言的特点构建适合的模型,使得模型可以尽可能保持词语语义的完整性。本文介绍了主要的词汇语义表示方法,给出了词汇语义表示的测评标准,接着介绍了基于词汇语义表示的新应用,最后阐述了词语语义表示的研究趋势并展望了下一步工作。
煤矿机械工作环境较差,加剧了煤矿机械的磨损程度。煤矿企业因为机械磨损造成的损失无法计量。不仅有工作环境导致的机械磨损,还与我国和煤矿机械设计技术水平以及机械后续维修技术较为滞后有关,机械抗磨技术上不完善,导致机械使用寿命较短。如何减少机械磨损,提高机械使用寿命,是煤矿机械设计中应注意的问题,还有研究抗磨措施,提高机械使用效率,实现煤矿产量的提高,减少煤矿企业的经济损失等问题。
2 词汇语义表示研究方法
词汇作为自然语言的基本单位,研究其语义表示形式旨在建立合适的词语表示模型;目前,利用向量空间模型将词语映射为语义空间中的向量,将词语表示成计算机可操作的向量形式是词汇语义表示的主要思路。基于构建向量空间模型所采用的基本假设不同,词汇语义表示方法可分为基于分布的表示方法和基于预测的表示方法。
2.1 基于分布的表示方法
燃油热值与生物燃料中的氧含量具有线性关系,随着含氧量的增加,热值下降。十六烷值(CN值)是燃料自燃能力的无量纲指标,和燃油的着火延迟相关。高 CN值燃油在和空气按比例充分混合前发生燃烧,导致不完全燃烧比例增加和碳烟排放量升高;CN值太低,发动机可能发生失火、温度过高、暖机时间过长、不完全燃烧等现象。生物燃料一般具有较高的CN值,且随着碳链长度的增加而增大,从C10:0增加到C18:0,CN值升高将近一倍,不饱和度的增加会降低燃料的CN值。粘度和表面张力也是燃油的关键参数,对燃油喷射的初次和二次雾化有着重要影响,也影响到燃油颗粒直径和喷射距离[12]。
基于分布的表示方法源自词的分布假设(Distributional Hypothesis),即词的上下文内容相似,则词汇本身的含义也相似[2],利用词—上下文共现次数刻画词汇语义,因此也称作基于计数的方法。由于词的上下文体现了词汇的使用方式,而不同语义的词汇其使用方式是不同的,因此利用分布假设实现的词汇表示间接反映了词的语义。该方法包括三个步骤: 1)选择合适的刻画词汇语义的空间分布矩阵; 2)依据不同的权重计算方法给矩阵赋值; 3)对矩阵进行降维。最终,降维后得到的矩阵即为词汇语义表示矩阵,矩阵的每一行为词的表示向量。
作为教师,可能都有一个体会:凡是在学习上有浓厚的兴趣,求知欲强,积极主动参与教育教学活动的学生,他们的学习效率就高,成绩也优秀。这虽已成为广大教师的共识,但学生学习兴趣不浓的问题依然存在。解决这一老生常谈的问题,作为一名初中语文教师,我是从以下几方面去努力的:
利用反向传播算法更新递归神经网络的参数时,假如输入模型的时间序列过长,则会出现梯度消失问题(vanishing gradient problem)或梯度爆炸问题(exploding gradients problem)[21]。为了避免这些问题,学者提出一种新的递归神经网络(Long Short Term Memory,LSTM)[22-23],与经典的递归神经网络不同,该模型设置记忆单元(Memory cell),该记忆单元在输入、输出和自链接层上增加输入门(Input gate)、输出门(Output gate)和忽略门(Forget gate),用于筛选记忆单元中需要保存或过滤的信息,因此适合训练输入较长时序的词。利用该模型不仅可以得到词汇的语义表示向量,还可以训练语句的表示[24]。

图1 词汇分布表示方式
虽然词-上下文共现矩阵F中C≪W,但当面对大规模语料库时,矩阵F不可避免的面临高维稀疏问题。因而,在得到原始的语义空间矩阵后,需要对矩阵进行降维,以降低计算的复杂度。目前在词语表示研究中主要应用的降维方法包括主成分分析(Principle Component Analysis,PCA)[4]和独立成分分析(Independent Component Analysis,ICA)[5]等。文献[6]则改进传统PCA利用欧式距离判断降维矩阵和原矩阵相似度的方法,基于Hellinger距离对矩阵进行降维,由于Hellinger距离更适合度量离散数值,因此降维后的词表示向量有更好的效果。
基于分布的词汇语义表示方法以海量文本数据为基础,通过上下文分布的共现频率描述词汇的语义,利用该方法得到的词汇语义表示向量在计算词汇相似度上有较好的结果,但是利用上下文分布信息间接刻画词汇语义和词汇的深层语义并不相同。因此,该方法得到的词汇语义表示对类比推理等深层语义关系的发现并不理想。
2.2 基于预测的表示方法
传统的基于多层神经网络计算词表示向量,计算量较大,训练时间往往需要几天甚至数周[14,25],因而在词汇语义表示问题上,研究能够较好表达词汇语义的简单模型成为近两年的研究重点。
近年来,伴随着深度学习技术发展[8-10],表示学习(Representation Learning)或非监督的特征学习(Unsupervised Feature Learning)成为自然语言处理领域重要的研究方向[11]。在词汇语义表示研究中,特征学习的目的是通过非监督的方法从大规模语料库中自动学习出词汇的语义表示向量,进而以词向量为特征应用于自然语言处理的各类监督学习任务中。因此,具有良好语义特征的词汇表示向量是后续任务的重要基础。目前,基于预测的词汇语义表示方法,依据神经网络模型的不同,可以分为基于前向神经网络的方法、基于递归神经网络的方法和基于浅层神经网络的方法等。
我国具备地质条件复杂的特征,不同地区之间的气候环境差异比较突出,也正是因为这一特征导致我国水旱灾害的影响性比较高,对于我国的工业、农业生产以及人民群众的生命财产安全形成了严重的影响。水文情报预报技术属于防汛抗旱的有效技术支撑,但是其需要借助大量且复杂的技术设备,随着各种技术的不断发展近些年水文情况预报技术水平得到了质的飞跃,但是仍然存在一定的改进空间。对此,探讨水文情况预报技术在防汛抗旱工作中的应用与改进措施具备显著现实意义。
2.2.1 基于前向神经网络的方法
基于神经网络训练词表示向量源自神经网络语言模型(Neural Network Language Model)[12]。语言模型的目的是为了训练语料库中词出现的联合概率分布,以达到预测下一个出现的词的目的。图2为神经网络语言模型的结构图[12],其中Cwi为词表示向量。
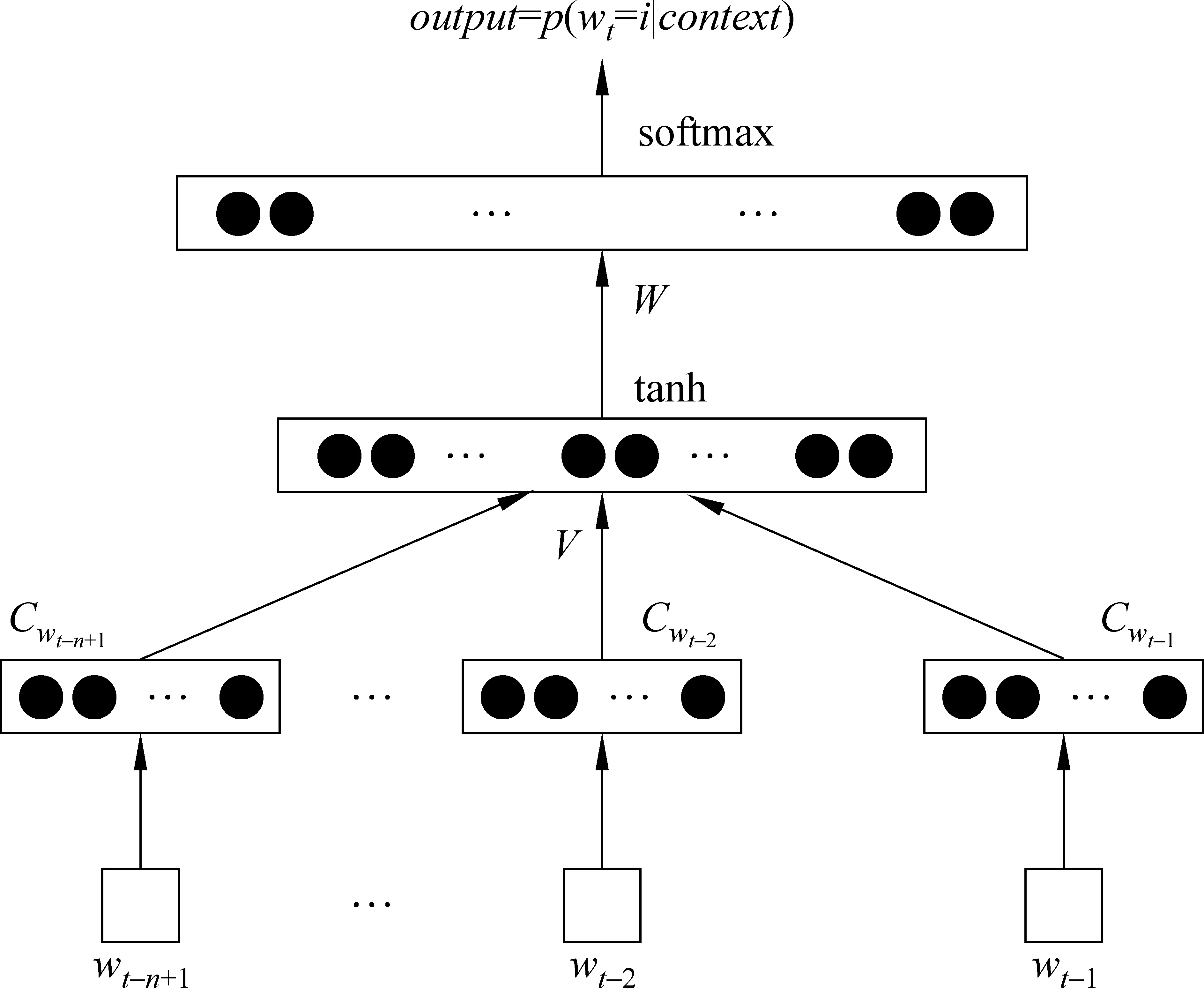
图2 神经网络语言模型
在传统的神经网络语言模型中,训练的目的是为了提高词的联合概率分布,但是由于利用反向传播算法[13]可以更新词汇表示向量。因此,在文献[14]中,作者基于前向神经网络语言模型,先随机初始化训练语料库的词向量表示,构造词典表示矩阵C∈RW*d,其中W为词典中词的个数,d为词向量的维度。模型定义滑动窗口nwin构建模型的输入向量s=(Cwt-n+1,Cwt-n+2,…,Cwt-1)。为了无监督的训练语料库中词表示向量,假设在语料库中套用滑动窗口产生的短句s为正例样本,同时将滑动窗口中的某个词随机替换为词典中的任一词所产生的错误短句为负样本。模型假设正例样本的得分比负例样本的得分高,例如,
fscore(我是中国人)>fscore(我大学中国人)
模型以式(1)所示的Hinge loss为目标函数,该目标函数的目的是在正样本和负样本间构造一个最大的分类边界。
(1)
其中,S为训练语料库中套用滑动窗口后长度为nwin的短句,W为词典的集合,s为训练语料库中的正例样本,sw为负例样本。
2.2.2 基于递归神经网络的方法
在骨盆修复仪中安装有固定的气囊,通过智能系统控制气囊(如图三),有节奏的加压放松牵拉骨盆的挤压,进而改善骨盆宽度。随着气囊加压,将骨盆及大腿部两侧的肌肉向里挤压,这时臀部自然而然的上升。气囊加压作用于人体,通过外力促进作用,模仿人手工的骨盆修复按摩,由外向里轻轻推压,将骨盆修复到产妇生产前的状态。确保修复的质量与效果,满足不同使用者的修复要求。
由于递归神经网络具有一定的时序性和记忆性,利用递归神经网络训练词语的语义表示向量符合语言的形式。如图3所示,不同于前向神经网络,递归神经网络将语料库中的每个词,按顺序逐个输入模型中[15-16]。与前向神经网络类似,利用递归神经网络训练语言模型[15,17-19]通过随时间演化的反向传播算法(Backpropagation Through Time,BPTT)[20]更新模型的参数和输入词向量,得到词汇语义表示向量。
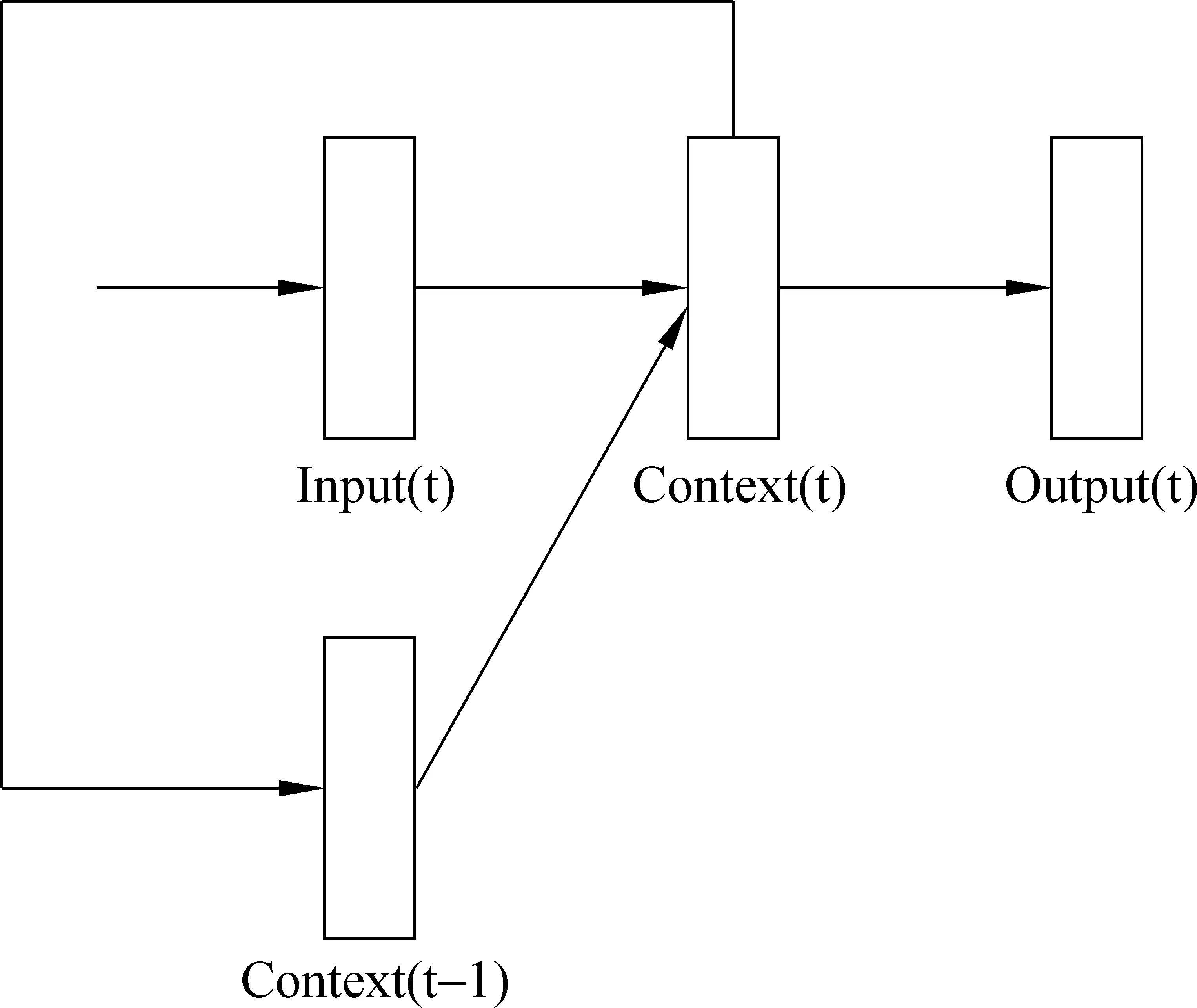
图3 递归神经网络
最基本的语义空间矩阵类型为词—上下文共现矩阵F∈RW×C,其中W为语料库中词库的大小,C为词上下文特征的大小;矩阵的每一行Fw是词w的向量表示,矩阵的每一列Fc表示上下文词语。在确定矩阵F的行、列属性后,需要对F各行各列的fij赋值;其中最简单的方法是给矩阵赋二元数值,即判断词wi的上下文窗口中是否出现词cj,出现为1,不出现为0。另一种方式则如图1所示,计算词wi的上下文窗口中出现词cj的次数作为fij的值[3]。目前,点互信息(Pointwise Mutual Information,PMI)[2]是计算词—上下文共现矩阵值的常用方法,其基本思路是统计词及其上下文词在文本中同时出现的概率,如果概率越大,其相关性就越紧密,点互信息的值也就越大。
由此看来,肥料利用率、有机肥替代、减施增效等政策引导,使高能耗的复合肥产业面临转型,其结果将导致复合肥进入产业调整和行业“洗牌”,使钾肥等上游原料企业经受考验。
2.2.3 基于浅层神经网络的方法
基于预测的表示方法源自神经网络语言模型。语言模型的目的是在给定上文的情况下,预测下一个词出现的概率。该方法基于人工神经网络的神经元分布假设[7],将词汇表示为一个低维实值向量,每一维看作词的一个特征,这种词语表示方法也称作词嵌入(Word Embeddings)。
(1) Word2vec模型
词表示向量的类比推理能力是评价词表示向量的另一个重要指标。在文献[26]给出的测试数据集中,每一个测试数据由(a,b)与(c,d)两组词对组成,表示为a:b→c:d的形式,解释为“a类比于b正如c类比于d”。为了验证词向量的类比能力,在给出a,b,c的情况下,以通过式(7)从训练的词库中准确找出词d*的正确率作为判断词表示向量在类比问题上质量的标准。文献[37]进一步丰富原有测试数据,公开了WordRep测试数据集,该数据集包含一千多万条语义类比词对和五千多万条句法对比词对,利用该数据集可以测试词表示向量在类比推理问题上的泛化能力。
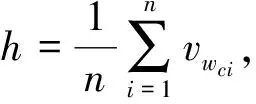
3)附属工程系统庞大。综合管廊内设置通风、燃气、电力、排水等附属工程系统,由控制中心集中控制,实现全智能化运行。另外还有一部分属于开放式走道,作为日常人行通道。
(2)
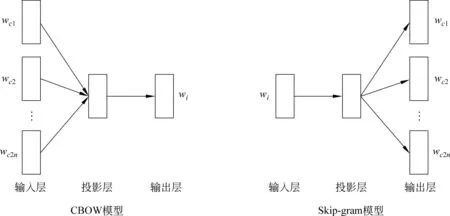
图4 word2vec模型
Skip-gram模型的目标则是给定目标词wi预测上下文的词wc。Skip-gram模型也可分为三层,输入层为目标词的词表示向量vwi,投影层为复制输入层的词表示向量vwi,输出层则是给定目标词预层上下文词的概率。
(3)
文献[28]则进一步证明基于负采样方法训练Skip-gram模型得到的词表示向量等价于利用Shifted PPMI构建词-上下文共现矩阵并对其SVD降维后得到的词表示向量。这一发现说明两类词汇语义表示方法存在一定的联系,也为解释神经网络模型提供了思路。
(2) Log Bilinear模型
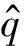
在计算匹配得分之后,模型以最大化式(6)为目标函数,利用Noise-Contrastive Estimation(NCE)[31]算法更新模型的参数θ=(C,vw.qw),得到词的表示向量。
(6)
若将式(6)进一步简化,不设置位置权重矩阵Ci和偏移量b,而是对上下文矩阵求平均,则模型简化为CBOW模型。
4.2 知识库链接预测与关系挖掘
利用浅层神经网络训练词汇表示向量不仅极大提高了模型的训练速度,在语义表示能力上也得到了改进。这说明在词汇表示问题上,深度学习模型并不是越复杂效果越好,直观的想法,简单的模型往往能取得很好的结果。但是,同其他神经网络模型一样,由于模型仅利用局部上下文作为输入,缺乏对全局统计信息的利用,依然有进一步改进的空间。
对词汇语义表示方法的研究近年来涌现大量出色的研究成果,在此不一一列举。本节列举的这些工作体现了词汇表示在语义表达能力上的发展,说明了其重要性和生命力。
3 词汇语义表示质量的测评
因为语言本身具有模糊性和主观性,对词汇的解释可以处于不同的立场和背景中,因而无法简单的判断词汇语义表示好或不好。由于目前没有一个标准数据集或评价指标能够直接判断词汇语义表示的质量,因而,通常从不同的角度间接检验词汇表示向量语义表达的能力。常用的判断词语表示质量的指标包括: 词语相似度计算、词类比推理能力评价以及将词语表示向量应用于具体问题所带来的结果变化。
3.1 词汇相似度计算
词汇表示的质量可以通过计算词之间的相似程度来判断,好的词汇表示方法能够反映词的相似程度。目前,余弦相似度是判断两个词语表示向量相似程度的基本方法,余弦夹角反映两个词的距离远近。在计算训练得到的词表示向量相似度之后,通过与人工标注的词语相似度数据集进行比较,计算斯皮尔曼相关系数(Spearman’s rank correlation)[32],检验词汇相似度计算的准确性。目前,广泛使用的人工标注词语相似度的数据集有: WordSimilarity-353[33]、MEN[34]、SimLex-999[35]和RW(Rare Word)[36]等。其中,WordSimilarity-353和SimLex-999是最常见的测试数据集,其主要标注了名词、动词和形容词间的相似度,而SimLex-999严格依据词汇的词义相似程度标注分数,而不是词间的相关性。例如,(clothes(衣服)—closet(衣橱)),在WordSimilarity-353中标记为8分,在SimLex-999中的评分为1.96。这也说明随着词汇语义表示研究的发展,词汇表示模型逐渐能体现语义特征,对测试数据本身也提出了新的要求。
3.2 词的类比推理
为了切实提高我院学生能力,本文根据我院物联网工程专业教学现状,从学生的实际情况出发,结合CDIO教育理念,对《岗位技能实训》课程深入进行教学改革。《岗位技能实训》课程是我校物联网工程专业的核心课程,在学生学习大部分课程之后的第七学期开设,以提高学生综合运用所学知识完成项目开发、培养学生之间的团队协作能力为主要目的;同时为了使学生能够从学校到工作有一个适应转变的过程,该课程不适宜采用偏重理论教学、以教师为中心的方式,应该以学生为主体、尽可能地为学生创造一个项目开发训练环境,增加实践环节,使其能系统化地分析运用所学知识、与其她成员合作完成课程实训内容。
Mikolov等人[26-27]提出的Word2vec模型由于其训练得到的词向量有很好的语义特性得到广泛的关注。如图4所示,该模型包括连续词袋模型(Continue Bag Of Words,CBOW)和Skip-gram模型两种词向量的训练方法。在Word2vec模型中,存在上下文词表示矩阵MWc∈Rw*d和目标词表示矩阵MWi∈Rw*d。
(7)
3.3 其他应用指标
在前向神经网络语言模型中,模型需要定义一个固定的上下文窗口,该窗口大小确定了模型输入或输出的词汇个数;但是直观上,语言是一种序列模型,语言本身具有一定延续性,因此需要一个能刻画时序特征的模型表示语言的特性。
由于词汇语义表示的目的是为了解决自然语言处理中的实际问题,因而可以将词向量作为输入,考察其对实际任务的影响,并依此评价词汇表示的质量。若通过词向量对任务的结果有提升,则认为词向量本身质量较高,反之亦然。目前,主要考察的自然语言处理任务有[6,14,38-41]: 词义消歧(Word Sense Disambiguation,WSD)、词性标注(Part of Speech, POS)、命名实体识别(Name Entity Recognition,NER)、语义角色标注(Semantic Role Labeling, SRL)、分块(Chunking)和完成语句(Sentence Completion)等。该方式可以看作一种半监督的学习机制,先利用大规模语料库无监督的训练词表示向量,进而将预训练得到的词向量作为其他监督学习问题的输入,考察其对最终结果的影响,从而评价词表示向量的质量。
通过搭建各种测试场景进行牵引供电系统供电能力测试。测试前,对车辆负载特征进行分析,并联合设计单位对牵引供电系统和车辆的负荷特性进行分析,包括对牵引供电系统的各种运行模式所对应的负荷运行进行编排;重点对接触网在不同运行方式(双边供电、单边供电、大双边供电)下的供电能力进行检验,并记录AW0(空载)、AW3(超载)等不同载荷列车的起动电流波形;同时观察牵引供电设备(DC 1 500 V开关柜及保护、钢轨电位限制装置等)是否发生误动作,以确保牵引供电系统的供电能力满足标准及设计要求;复核设计单位关于运营过程中的负载状态,以确保线路安全运营。
4 词汇语义表示应用研究
词语表示向量可以广泛应用于解决各类实际问题,除了可以应用于3.3节中提到各类自然语言处理的任务中,基于词表示向量本身所具有的语义表达能力,近两年产生了新的应用方向。
4.1 语义组合(Semantic Composition)
语义组合的目的是将简单的词语进行组合以表达复杂语句的语义,而整体语义可以看作是部分语义的组合函数。因此,语义组合是实现语义表示从词汇级别向句子级别扩展的重要手段。语义组合函数定义如式(8)所示。[42]
p=f(u,v,R,K)
(8)
其中,u,v表示待组合部分,R表示u,v间的关系,K表示用于语义组合的其他上下文知识。其中最简单的组合方式为线性组合[42],该方法定义基于加法p=u+v或乘法p=u·v的组合函数实现语义组合。但由于其无法体现词语组合的顺序,近年来基于递归自编码(Recursive Auto-encoder)[43-44]和卷积神经网络[45-46]的非线性组合方法得到深入研究,并在同义语句判断、情感分析等评价指标中取得很好的结果,是未来重要的研究方法。
通过竞赛可以提高学生学习数学的信心。在竞赛当中,共同体成员可以互相合作,沟通交流,这有助于共同体的长久发展。对于在竞赛中获奖的教师团队来说,能增强他们的职业幸福感与工作积极性。
知识库(Knowledge Base)中包含大量实体和实体间关系信息,是实现智能问答、知识推理的重要基础,但是现有的知识库远不完整,如何丰富现有知识库一直是学术界研究的热点。由于词向量具有较好的类比推理能力,因而有研究利用词表示向量实现实体间的关系发现或链接预测,从而达到知识库完善的目的[47-54]。利用词汇语义表示实现知识库链接预测与关系挖掘的基本思路是将实体表示为对应的词汇表示向量,将实体间的关系看作词汇间的某种映射关系,并利用现有的知识库训练实体间的关系映射形式,从而实现链接预测与关系抽取。基于词汇语义表示向量的链接预测与关系抽取在自然语言和结构化的知识数据中建立了联系,从而可以不再依赖于人工参与而极大丰富现有的知识库。
从语言学角度分析,语言基础知识由语音、词汇、语法这三大要素构成。这三大要素贯穿于二语学习的整个过程之中。当二语学习者在语言学习过程中受到母语的影响时也往往表现在以下方面:
4.3 机器翻译
词汇语义表示还可以应用于机器翻译中。基于深度学习的机器翻译模型[55-57]的基本思路是认为对于训练语料中的原始语言Ss和目标语言St,若两种语言表达相同的意思则有相同的抽象特征表示,因而将输入的原始语言词序列编码(encode)成其特征表示Rs,进而对Rs解码(decode)为目标语言的词语序列,若在训练过程中出现与目标语言词St中词序列不匹配的情况,则更新模型的参数和词表示向量。以词汇语义表示为基础,利用深度学习模型实现机器翻译不仅提高了翻译的准确性还减少了训练过程中的人工参与。
5 研究趋势
总体而言,针对词汇语义表示的研究主要集中在两方面: 1)提出新的模型,以提高词汇语义表达能力; 2)针对实际应用问题,在解决特定任务时构建适合词汇表示的新模型。除此之外,伴随大数据时代的来临,训练样本呈现出海量多元异构的特点,该领域发展还有一些新的变化趋势。
首先,在利用海量文本数据非监督的训练词汇语义表示向量的基础上,结合外部知识资源以提高词汇语义表示质量得到越来越多的关注[58-60];WordNet、Freebase等知识资源,包含了自然语言上下文中没有的语义信息,因此用该方法训练得到的词表示向量具有更丰富的语义。充分利用现有的知识数据源,将更多的语义信息作为模型的输入,是未来进一步提高词向量语义表达能力的重要手段。
其次,针对词汇语义表示向量的训练不仅局限于文本数据,而是结合图像等数据源实现多模态(multi-modal)学习,得到多模态的联合特征表示,进而实现图像识别、图像的文本描述生成[61-65];虽然词汇表示向量并不是模型的训练目标,但是通过该模型得到的词表示向量因为融合了图像的信息,能同时捕捉文本和图像的语义信息。词汇的语义表示已经不仅局限在自然语言处理领域,它还和图像处理、语音识别等领域结合,推动了其他应用领域的发展。
此外,伴随模型本身复杂度的提高,计算性能成为模型能否应用于实际问题的关键。依赖于新的计算框架的提出和计算机自身的发展,目前在解决计算性能问题上主要有两种思路: 1)利用Map-Reduce[66]框架,构建大规模的分布式神经网络计算集群[67],提高模型的计算速度;2)利用GPU加速计算,由于深度学习属于计算密集型模型,逻辑控制语句较少,利用GPU可以极大提高计算效率,已经成为模型训练重要的技术手段[68-70]。
6 总结与展望
词汇作为语言的基本单元,计算机能够表示词语、理解词语含义是实现自然语言理解的重要基础。词语的表示可以归结为两大类: 基于分布的方法和基于预测的方法。基于分布的方法主要统计词的上下文共现次数,因而具有更好的统计意义和更快的训练速度,但是该方法得到的词表示向量仅捕捉词之间的相关性;而基于预测的方法主要基于神经网络语言模型,该方法适合于大规模语料库,且得到的词向量具有更好的类比、推理等能力;但是该方法训练时间相对较长且没有很好利用词的统计信息。本文介绍了该领域近几年国际上最新的研究成果,综述了词汇语义表示训练的各类模型和方法,常用的评价标准以及最新的应用方向和发展趋势。
(1)满载紧急制动减速:输送机在紧急制动过程中各处的胶带张力均应大于零,严防胶带松弛、撒煤或叠带事故。F1= 484.15 kN,F2= 285.2 kN ,F3=156 kN;
词表示方法虽然是传统的研究领域,但是伴随着新方法的引入又产生了新的活力。目前已经取得了一定的成果,但仍面临着很多的挑战。
组织结构电镜观察结果如图3。新鲜克氏原螯虾的肌肉组织结构紧密,组织间间隙较小。液体冷却介质急冻克氏原螯虾肌肉组织与新鲜克氏原螯虾的肌肉组织结构类似,组织间间隙较小。这表明,在液体冷却介质急冻克氏原螯虾过程中,水在肌肉细胞组织中没有形成具有破坏性的冰晶体。而常规冷冻克氏原螯虾的肌肉组织间隙大,这是由于水在肌肉细胞组织中形成了具有破坏性的冰晶体造成的。
1) 尽管实验显示基于神经网络得到的词表示向量比基于词分布假设得到的词表示向量要好[71],但是利用神经网络模型训练词表示向量的可解释性有待进一步研究,这其中包括神经网络模型本身的可解释性以及训练得到的词表示向量的可解释性。
2) 目前对词汇语义表示质量的评价是通过其在相似、类比等问题上的表现间接的进行评价,缺乏明确直接的检验词表示语义的标准,词表示向量的质量评估是一个重要的研究方向。
3) 由于构建词表示向量的方法大多基于词的上下文,因此词汇语义表示更倾向于表达词的相关性,而不是词义的相似性,与真实的语义更不同,构建能表达语义的词表示模型是词语表示研究的最终目的。
关于什么是语义,如何通过计算机表达语义,目前学术界没有定论。基于向量空间的词汇语义表示方法虽然是目前最有效的表达词语特征的方式,但是依然有其局限性,能够表达词语语义的表示方法还需进一步的探索和研究。
[1] 孙茂松, 刘挺, 姬东鸿, 等. 语言计算的重要国际前沿 [J]. 中文信息学报, 2014, 28(1): 1-8.
[2] Turney P, Pantel P. From Frequency to Meaning?: Vector Space Models of Semantics [J]. Journal of Artificial Intelligence Research, 2010, 37: 141-188.
[3] Sahlgren M. The Word-Space Model: using distributional analysis to represent syntagmatic and paradigmatic relations between words in high-dimensional vector spaces [D]. Stockholm University, 2006.
[4] Bishop C M. Pattern Recognition and Machine Learning [M]. 2006.
[5] Vayrynen J J, Honkela T. Word Category Maps based on Emergent Features Created by ICA [J]. Proceedings of the STeP, 2004, 19: 173-185.
[6] Lebret R, Collobert R. Word Embeddings through Hellinger PCA [C]//Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics. 2014: 482-490.
[7] Hintor G E, Mcclelland J L, Rumelhart D E. Distributed representations [J]. Parallel Distributed Processing: Explorations in the Microstructure of Cognition, 1986, 1: 77-109.
[8] Hinton G E, Salakhutdinov R R. Reducing the Dimensionality of Data with Neural Networks [J]. Science, 2006, 313: 504-507.
[9] Bengio Y. Learning deep architectures for AI [J]. Foundations and Trends in Machine Learning, 2009, 2(1): 1-127.
[10] Bengio Y. Deep Learning of Representations: Looking Forward [C]//Proceedings of the International Conference on Statistical Language and Speech Processing. 2013: 1-37.
[11] Bengio Y, Courville A, Vincent P. Representation learning: A review and new perspectives [J]. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 2013, 35(8): 1798-1828.
[12] Bengio Y, Ducharme R, Vincent P,et al. A Neural Probabilistic Language Model [J]. Journal of Machine Learning Research, 2003, 3: 1137-1155.
[13] Rojas R. The Backpropagation Algorithm [G]. Neural Networks - A Systematic Introduction, 1996.
[14] Collobert R, Weston J, Bottou L,et al. Natural Language Processing (almost) from Scratch [J]. Journal of Machine Learning Research, 2011(12): 2493-2537.
[15] Tomas M, Karafiat M, Burget L et al. Recurrent neural network based language model [C]//Proceedings of INTERSPEECH, 2010: 1045-1048.
[16] Sutskever I, Martens J, Hinton G. Generating Text with Recurrent Neural Networks [C]//Proceedings of the 28th International Conference on Machine Learning, 2011:1017-1024.
[17] Tomas M. Statistical Language Models based on Neural Networks [D]. Brno University of Technology, 2012.
[18] Yao K, Zweig G. Recurrent Neural Networks for Language Understanding [C]//Proceedings of INTERSPEECH, 2013: 2524-2528.
[19] Mikolov T, Kombrink S, Burget L,et al. Extensions of recurrent neural network language model [C]//Proceedings of ICASSP, 2011: 5528-5531.
[20] Boden M. A guide to recurrent neural networks and backpropagation [R]. 2002: 1-10.
[21] Bengio Y, Simard P, Frasconi P. Learning long-term dependencies with gradient descent is difficult [J]. Neural Networks, IEEE Transactions on, 1997, 5(2): 157-166.
[22] Hochreiter S, Schmidhuber J. Long short-term memory [J]. Neural computation, 1997, 9(8): 1735-1780.
[23] Graves Alex. Supervised Sequence Labelling with Recurrent Neural Networks [M]. 2012.
[24] Palangi H, Deng L, Shen Y等. Deep Sentence Embedding Using the Long Short Term Memory Network: Analysis and Application to Information Retrieval [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(4): 694-707.
[25] Turian J, Ratinov L, Bengio Y. Word representations?: A simple and general method for semi-supervised learning [C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, 2010: 384-394.
[26] Mikolov T, Corrado G, Chen K,et al. Efficient Estimation of Word Representations in Vector Space[C]//Proceedings of Workshop at ICLR, 2013.
[27] Mikolov T, Yin W, Zweig G. Linguistic regularities in continuous space word representations [C]//Proceedings of NAACL-HLT, 2013: 746-751.
[28] Omer L, Yoav G. Neural Word Embeddings as Implicit Matrix Factorization [C]//Proceedings of NIPS, 2014:2177-2185.
[29] Mnih A. A fast and simple algorithm for training neural probabilistic language models[C]//Proceedings of the 29th International Conference on Machine Learning. 2012.
[30] Mnih A, Kavukcuoglu K. Learning word embeddings efficiently with noise-contrastive estimation [C]//Proceedings of NIPS, 2013: 2265-2273.
[31] GUTMANN M U, HYV?RINEN A. Noise-contrastive Estimation of Unnormalized Statistical Models, with Applications to Natural Image Statistics[J]. J. Mach. Learn. Res., 2012, 13(1): 307-361.
[32] Spearman’s rank correlation coefficient[J]. Wikipedia, the free encyclopedia, .
[33] Finkelstein L, Gabrilovich E, Matias Y,et al. Placing Search in Context: The Concept Revisited [J]. ACM Trans. Inf. Syst., 2002, 20(1): 116-131.
[34] Bruni E, Boleda G, Baroni M,et al. Distributional Semantics in Technicolor [C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, 2012: 136-145.
[35] Hill F, Reichart R, Korhonen A. SimLex-999: Evaluating Semantic Models with (Genuine) Similarity Estimation [R], 2014.
[36] Luong M, Manning C D. Better Word Representations with Recursive Neural Networks for Morphology [C]//Proceedings of CoNLL, 2013: 104-113.
[37] Gao B, Bian J, Liu T-Y. WordRep: A Benchmark for Research on Learning Word Representations[J]. arXiv:1407.1640 [cs], 2014.
[38] Collobert R, Weston J. A Unified Architecture for Natural Language Processing?: Deep Neural Networks with Multitask Learning[C]//Proceedings of the 25th International Conference on Machine Learning, 2008: 160-167.
[39] Erk K, Mccarthy D, Gaylord N. Measuring Word Meaning in Context [J]. Computational Linguistics, 2013, 39(3): 511-554.
[40] Jacob A, Dan K. How much do word embeddings encode about syntax [C]//Proceedings of ACL, 2014:822-827.
[41] Zweig G, Burges C. The Microsoft Research Sentence Completion Challenge [R]. MSR-TR-2011-129, 2011.
[42] Mitchell J, Lapata M. Composition in Distributional Models of Semantics [J]. Cognitive Science, 2010, 34(8): 1388-1429.
[43] Socher R, Huval B, Manning D,et al. Semantic Compositionality through Recursive Matrix-Vector Spaces[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. 2012: 1201-1211.
[44] Scoher R, Perelygin A, Wu Y,et al. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank [C]//Proceedings of EMNLP, 2013: 1631-1642.
[45] Kalchbrenner N, Grefenstette E, Blunsom P. A Convolutional Neural Network for Modelling Sentences [C]//Proceedings of ACL, 2014: 655-665.
[46] Wenpeng Y, Hinrich S. Convolutional Neural Network for Paraphrase Identification [C]//Proceedings of NAACL, 2015: 901-911.
[47] Bordes A, Weston J, Collobert R,et al. Learning Structured Embeddings of Knowledge Bases[C]//Proceedings of the Twenty-Fifth AAAI Conference on Artificial Intelligence, 2011:301-306.
[48] Bordes A, Usunier N, Garcia A,et al. Translating Embeddings for Modeling Multi-relational Data [C]//Proceedings of NIPS, 2013: 2787-2795.
[49] Weston J, Bordes A, Yakhnenko O,et al. Connecting Language and Knowledge Bases with Embedding Models for Relation Extraction[C]//Proceedings of EMNLP, 2013: 1366-1371.
[50] Jason W. Embeddings for KB and text epresentation, extraction and question answering [R]. 2014.
[51] Ruiji F, Jiang G, Bing Q. Learning Semantic Hierarchies via Word Embeddings [C]//Proceedings of ACL, 2014: 1199-1209.
[52] Bordes A, Globot X, Weston J et al. Joint learning of words and meaning representations for open-text semantic parsing [C]//Proceedings of the International Conference on Artificial Intelligence and Statistics. 2012.
[53] Wang Z, Zhang J, Feng J et al. Knowledge Graph Embedding by Translating on Hyperplanes[C]//Proceedings of the AAAI. 2014.
[54] Garcia A, Bordes A, Usunier N et al. Combining Two and Three-Way Embeddings Models for Link Prediction in Knowledge Bases [J]. Journal of Artificial Intelligence Research. 2016, 55: 715-742
[55] Cho K, Van M, Bahdanau D et al. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches[J]. arXiv:1409.1259 [cs, stat], 2014.
[56] Sutskever I, Vinyals O, Le V. Sequence to Sequence Learning with Neural Networks [C]//Proceedings of NIPS, 2014:310-3112.
[57] Cho K, Van M, Gulcehre C et al. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation [C]//Proceedings of EMNLP, 2014: 1724--1734.
[58] Mo Y, Mark D. Improving Lexical Embeddings with Semantic Knowledge [C]//Proceedings of ACL, 2014: 545-550.
[59] Bain J, Gao B, LIU T-Y. Knowledge-Powered Deep Learning for Word Embedding[C]//Proceedings of ECML, 2014: 132-148.
[60] Omer L, Yoav G. Dependency-Based Word Embeddings [C]//Proceedings of ACL, 2014: 302-308.
[61] Bruni E, Baroni M. Multimodal Distributional Semantics [J]. Journal of Arti?cial Intelligence Research, 2014, 49: 1-47.
[62] Kiros R, Salakhutdinov R, Zemel R. Multimodal Neural Language Models[C]//Proceedings of ICML, 2014: 595-603.
[63] Kiros R, Salakhutdinov R, Zemel S. Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models [J]. TACL, 2015.
[64] Srivastava N, Salakhutdinov R. Multimodal Learning with Deep Boltzmann Machines [C]//Proceedings of NIPS, 2013.
[65] Vinyals O, Toshev A, Bengio S等. Show and Tell: A Neural Image Caption Generator[C]//Proceedings of CVPR, 2014: 3156-3164.
[66] Dean J, Ghemawat S. MapReduce: Simplified Data Processing on Large Clusters [J]. Commun. ACM, 2008, 51(1): 107-113.
[67] Dean J, Corrado G, Monga R,et al. Large Scale Distributed Deep Networks[C]//Proceedings of NIPS. 2012: 1223-1231.
[68] Collobert R, Kavukcuoglu K, Farabet C. Torch7: A Matlab-like Environment for Machine Learning [C]//Proceedings of NIPS Workshop, 2011.
[69] Jia Y, Shelhamer E, Donahue J,et al. Caffe: Convolutional Architecture for Fast Feature Embedding[C]//Proceedings of ACM international conference on Multimedia, 2014.
[70] Bastien F, Lamblin P, Pascanu R,et al. Theano: new features and speed improvements[M]. 2012.
[71] Baroni M, Dinu G, Kruszewski G. Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors [C]//Proceedings of the 52nd ACL. 2014: 238-247.
A Review on Lexical Semantic Representation
YUAN Shuhan, XIANG Yang
(School of Electronics and Information Engineering, Tongji University, Shanghai 201804, China)
Constructing the words representation which could express the semantic features is the key problem of Natural Language Processing. In this paper, we first introduce the lexical semantic representation based on the distributional hypothesis and prediction model, and describe the evaluations methods of words representation. Then we review the new applications based on the semantic information of words representation. Finally, we discuss the development directions and exiting problems of lexical semantic representation.
words representation; semantic; distributional hypothesis; deep learning

袁书寒(1987—),博士研究生,主要研究领域为自然语言处理、深度学习。E⁃mail:4e66@tongji.edu.cn向阳(1962—),博士,教授,博士生导师,主要研究领域为语义计算、云计算、管理信息系统。E⁃mail:shxiangyang@tongji.edu.cn
2015-06-03 定稿日期: 2015-08-31
国家重点基础研究发展计划(973计划)(2014CB340404);上海市科委科研计划项目(14511108002);国家自然科学基金(71171148,71571136);上海市科委基础研究项目(16JC1403000)
1003-0077(2016)05-0001-08
TP391
A
