基于概率交易模型的线下百货推荐
2016-05-04王鹏飞郭嘉丰兰艳艳晏小辉程学旗
王鹏飞,郭嘉丰,兰艳艳,晏小辉,程学旗
(1. 中国科学院 计算技术研究所,网络数据科学与技术重点实验室,北京 100190; 2. 中国科学院大学,北京 100049)
基于概率交易模型的线下百货推荐
王鹏飞1,2,郭嘉丰1,兰艳艳1,晏小辉1,程学旗1
(1. 中国科学院 计算技术研究所,网络数据科学与技术重点实验室,北京 100190; 2. 中国科学院大学,北京 100049)
该文提出了一种新颖的概率交易模型PTM,针对线下百货进行个性化的推荐。传统的推荐模型,如K-近邻算法、矩阵分解等,或者仅利用局部的数据,使得模型面临线下数据极大的稀疏性挑战,或者忽略百货数据中的交易维度,使得模型损失了同一交易中多商品共现的强相关信息,最终导致它们在面对线下百货推荐问题时性能低下。针对以上的问题,本模型从交易的维度出发,建模交易记录中的共现模式,并利用全局的交易数据来学习商品的相关分量,在此基础上推断出用户的兴趣分布,实现个性化的推荐。在真实的线下百货交易数据上的实验结果表明,该模型能够极大地提高线下百货领域个性化推荐的准确性。
PTM;概率交易模型;品牌共现
1 引言
随着电子商务的迅猛发展,传统的线下百货交易面临极大的冲击,商家迫切需要找到新的途径刺激用户的线下消费行为,提高自身的竞争力。由于会员卡、购物卡等机制的普遍应用,线下百货商家积累了大量的用户消费数据,一种重要的方式就是对消费数据进行挖掘和分析,在获取了用户的兴趣后,通过手机短信、移动客户端等实现对用户的精准营销,完成个性化推荐。与电子商务领域相比,线下百货消费数据具有两个主要特点: (1)数据交易记录中“购物篮”特性显著[1],如果将同一个用户在一天内的消费行为看作一个交易记录(Transaction),线下交易数据中多个品牌共现的比例显著高于线上的情况。例如,我们分别随机采样了某实体商场和天猫的2 000笔交易数据做了对比,发现线下交易数据中多商品交易记录占30.88%,而天猫数据中仅占12.66%。(2)单个用户的记录更加稀疏,不同于线上交易的便捷性和及时性,线下百货消费的频度和密集程度显著降低。例如,我们分别对线上线下数据随机采样了400个用户,并分析其三个月的交易记录,发现线上用户平均有2.28笔交易,线下用户仅有1.12笔交易。这些特点给推荐系统带来了全新的挑战。
早期研究人员对线下消费数据进行关联规则挖掘,提出了Apriori、FP-growth等经典的挖掘算法,并发现了“啤酒—尿布”这样的频繁项集使得商品销售量大幅增加。这类算法的优点是从全局的角度对交易记录进行挖掘,建模了交易记录内商品的相关性,有效避免了单个用户消费数据的稀疏性问题。然而,由于仅从全局挖掘,不考虑单个用户的行为特性,这些方法难以实现对用户的个性化推荐。
为了应对用户的个性化需求,近年来人们提出了很多个性化推荐算法,其中一类重要的方法是协同过滤算法,如K-近邻算法,矩阵分解等。上述方法在很多在线应用如Amazon、NetFlix上取得了巨大的成功。此类算法的核心思想基于用户的历史记录来查找相似的用户,并利用相似用户的行为来产生推荐。这些算法在单个用户的历史记录非常稀疏时性能低下,同时这些算法通常都不建模交易信息,仅仅关注用户层面粗粒度的商品相关性,而忽略了交易层面所包含的商品间的强相关性。
针对以上的问题,本文提出了一种新颖的概率交易模型,简称为PTM(ProbabilisticTransactionModel)。该模型从全局的角度对百货交易记录进行建模,学习潜在的相关分量(CorrelationComponent),并基于学得的相关分量推断出用户的兴趣分布,实现个性化的推荐。相对于已有的模型,PTM具有如下的优势: (1)模型直接建模交易中共现信息,充分利用了百货交易记录中所包含的商品间强相关性;(2)PTM从全局的角度学习交易数据中所隐含的相关分量,有效地避免单个用户的数据稀疏性问题;(3)模型基于学得的相关分量推断用户兴趣,可以有效地实现个性化的推荐。我们通过使用一个实际的线下百货消费数据集进行了实验评估,实验结果表明,相对于基准方法,PTM可以更好地学得百货数据中所包含的相关分量,并且显著地提高个性化推荐的准确性。
2 相关工作
在本部分,我们对已有的基于商品消费数据的挖掘与推荐系统进行简要的回顾。
2.1 关联规则挖掘
传统的数据挖掘算法如Apriori、FP-growth等算法,基于关联规则去挖掘数据中的频繁项集,并将数据中频繁共现的商品推荐给用户。Apriori通过迭代的方式构建从低维到高维的频繁项集,获取数据库中有意义的关联。但这种方法在挖掘数据库中的长模式时会产生大量的项集,并且需要重复地扫描数据库。JiaweiHan对算法进行了改进,提出了基于模式增长的FP-growth算法,该算法在内存中构建了FP-tree的数据结构进行数据项集的存储。但这两种方法主要从全局的角度去挖掘交易数据中的频繁项集,缺乏个性化的因素。
2.2 基于内容的推荐模型
基于内容的推荐模型主要借助用户过去购买、点评过的商品的描述来构造用户的兴趣轮廓,并通过计算用户的兴趣轮廓和商品描述之间的相关性,推荐给用户相类似的商品[2-3]。模型的关键在于如何对商品进行描述,以及商品特征如何选取。例如Gemmis[4]将商品的描述,和用户对商品标注的标签信息联合起来去描述用户的兴趣轮廓,并在实验中取得了很好的效果。但通常情况下,此类模型获取到的商品特征是有限的,这使得模型缺乏足够的信息去识别用户对商品的喜好。例如此类模型无法区分两个描述相同,但用户喜好不同的商品。
2.3 协同过滤推荐模型
基于协同过滤的推荐系统是当今较为流行的方式。与基于内容的推荐方式不同,该模型不需要借助商品的描述,仅通过用户对商品的评分即可完成对用户的商品推荐。这种模型可以分成两类[5]:K-近邻算法,矩阵分解。
2.2.1 基于K-近邻算法的推荐模型
K-近邻算法(KNN)是一种非参数的分类算法,该算法认为相似的环境下,同一个群组的人可能兴趣也相似[6]。在对用户U进行推荐时,算法试图找出与该用户距离最接近的K个用户,然后将这K个用户所感兴趣的商品推荐给用户U。但K-近邻算法主要有两个缺点[5]: (1)该算法假设用户共同感兴趣的商品越多,用户的兴趣便越相近。这种假设过于局限,其忽略了那些历史数据较少,但兴趣仍相近的用户。此外,推荐只能选取邻近用户购买过的商品,这使得推荐的范围受到了限制。(2)用户数据的稀疏性问题会给算法的准确性造成很大的影响。比如在电影推荐领域,假如用户仅对有限的电影进行了评分,这会导致用户之间几乎没有共同感兴趣的电影,算法只能借助有限的几个用户进行推荐。
2.2.2 基于矩阵分解的推荐模型
基于矩阵分解的推荐模型应用十分广泛[7-8]。此类模型在Netflix竞赛、Tag推荐上取得了很好的效果。该模型将用户i和物品j分别用一个K维的向量来表示:U.i∈RK代表用户i的偏好,V.j∈RK表示物品j的属性向量[2]。
Rij表示为用户i和物品j的相似程度,也就是用户对该物品的偏好程度。Vi.代表一个潜在相关分量,对应于一组相关的商品。矩阵分解的方式将用户和商品放在同一个低维的空间。但矩阵分解模型有两个缺点: (1)模型的可解释性差,得到的低维空间很难用明确的物理意义去描述[9];(2)传统的矩阵分解模型一般忽略交易的维度,仅仅关注用户层面粗粒度的商品相关性,而忽略了交易层面所包含的商品间的强相关性。
3 本文的方法
针对百货行业数据的特点,本文提出了一种新颖的概率交易模型PTM,来实现个性化的百货推荐。该模型的核心思想如下: 百货卖家关心的是商品间的相关性,通过分析商品之间的相关性来进行推荐,例如用户在购买面包的同时,往往会同时购买牛奶。而用户的交易记录中商品的共现模式则充分体现了这种相关性。因此本文的工作从交易的维度出发,直接建模交易中的商品共现模式。PTM模型利用全局的数据学习得到多个相关分量(每个相关分量对应了一组高度相关的商品),并基于这些相关分量,利用用户历史的交易信息,便可方便地推断出用户的兴趣分布,从而对用户未来感兴趣的商品进行预测,实现个性化推荐。
3.1 概率交易模型
我们首先对PTM模型具体的建模过程进行介绍。PTM模型是一个混合模型(MixtureModel),它建模了一个交易数据集的产生过程。PTM认为一个交易数据集共享了K个潜在的相关分量(CorrelationComponent),每个潜在的相关分量代表了一组相关的商品。如果两个商品越多地出现在相同的交易记录中,则这两种商品的关联性越强,那么在模型中它们就越可能属于同一个相关分量。PTM通过建模数据集中每条交易记录中共现的商品模式,来学得潜在的相关分量。
具体地,给定商品集合I={I1,I2,…IM}和交易集合T={t1,t2,…tN},其中每笔交易tn∈T是一组商品的集合。假定交易集合T共享了K维潜在的相关分量,用z∈{1,2,…K}表示相关分量的指示变量,θ表示一个服从K维多项式分布的向量(∑kθk=1),θk=P(z=k)表示交易数据集中第k个相关分量的比例,φk表示一个服从M维多项式分布的向量(∑mφk,m=1),φk,m表示第k个相关分量下第m个商品出现的概率。模型定义每条交易记录中共现的商品对s=(Ii,Ij)所构成的集合为B:
由于集合S捕捉了交易数据集T中所有在交易层面商品共现的信息,因此PTM对于交易数据集T产生过程的建模,就可以转化为对集合S的产生过程的建模,模型具体的产生过程如下:
1) 采样θ~Dirichlet(α)
2) 对于每一个潜在相关分量k∈{1,…,K}
采样φk~Dirichlet(β)
3) 对于每一个共现商品对s=(Ii,Ij)∈B
采样z~Multinomial(θ)
采样Ii,Ij~Multinomial(φz)
其中狄利克雷分布参数α和β是模型的超参。产生过程对应的概率图模型如图1所示。
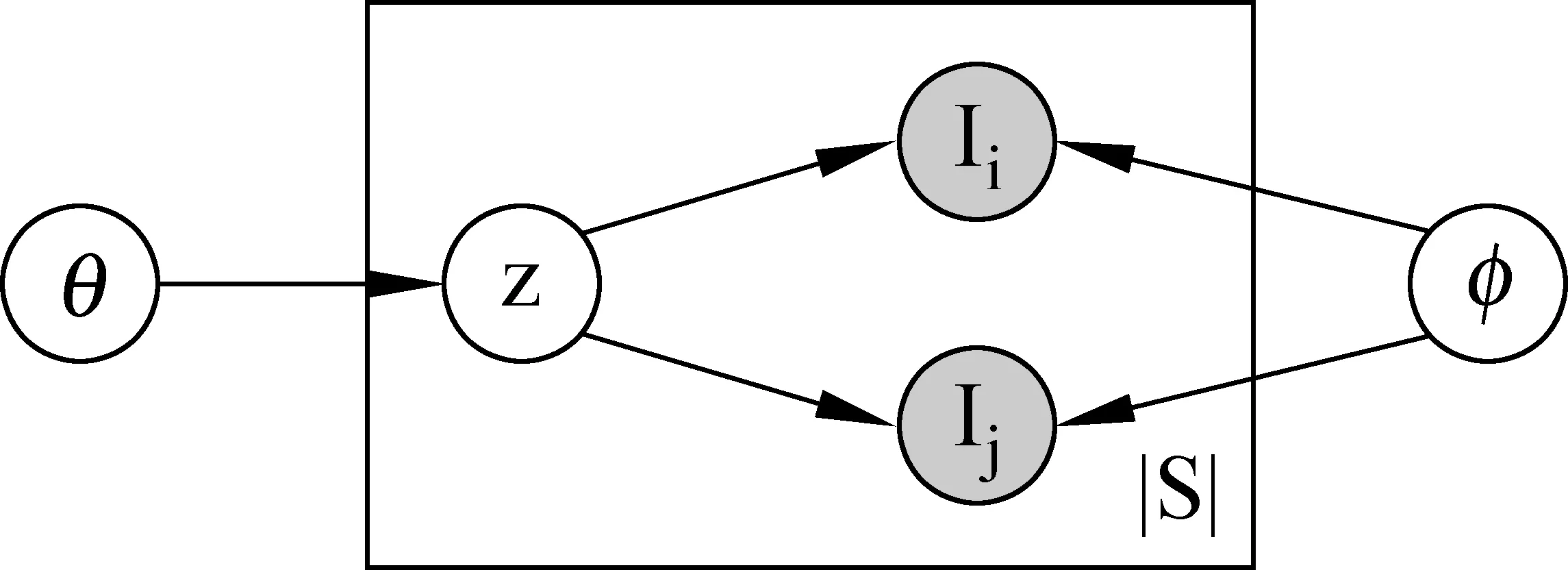
图 1 PTM概率图模型
基于上述的产生过程,可以得到在给定模型参数θ,φ时每一个共现商品对s=(Ii,Ij)出现的概率:
给定模型的超参数α和β,对公式(3)中的模型参数θ,φ进行积分,就可以得到s的边缘分布:
对所有的共现商品对进行累积,就得到了整个数据集的生成似然:
3.2 用户兴趣推断与个性化推荐
通过对上述PTM的学习,可以得到商品的潜在相关分量。模型进一步推断用户的个人兴趣(表达为在潜在相关分量上的一个分布),从而实现对用户感兴趣的商品的预测。
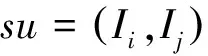
那么用户对第k维潜在相关分量的兴趣概率可以通过式(7)进行计算:
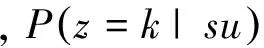
将商品按照上述概率值进行排序,就可以将排序靠前的商品作为推荐提供给用户。
4 模型参数推导
由于PTM模型中目标函数是非凸的,本文采用了Gibbs采样方法来逼近模型的真实解。Gibbs算法是一个简单而又被广泛应用的MCMC算法。和变分推理,最大后验估计等算法相比,Gibbs算法有两个优势:
(1)Gibbs算法通过渐进的方式去逼近最优解,这种方式更加的准确;
(2)Gibbs对内存的需求相对较小,它只要求记住当前迭代的次数以及变量值,从而在处理大规模的数据时更加的有利[10]。
在PTM模型中总共有三个参数需要进行估计: 潜在相关分量的指示变量z,潜在相关分量φ,以及交易数据集在相关份量上的分布θ。由于使用了共轭先验φ和θ可以积掉,因此只需针对每个共现商品对s=(Ii,Ij)采样其分量z,采样依据的条件概率表示如下:
其中z-s代表除去s后的所有的共现商品对的分量分布,nk为s出现在潜在第k维相关分量中的次数,nk,i和nk,j分别表示第i和j个商品出现在第k维潜在相关分量中的次数。这个采样的具体过程如算法1所示。

算法1:PTM的Gibbs采样输入:K维的潜在相关分量,超参数α,β,品牌组合集合S;输出:所有的品牌组合在K维的相关分量上的多项分布;1)随机的初始化所有的品牌组合s的分布;2)对于从1到Niter的每一次迭代 对于品牌组合的集合S中的每一个品牌组合s 从P(z|z-s,S,α,β)中对zs进行采样; 更新参数nz,nIi|z,nIj|z;
在充分的采样步骤之后,可以得到潜在相关分量φ以及全局范围的潜在相关分量概率分布θ的估计如下:
5 实验评价
5.1 实验设置
本文使用了某百货集团旗下2013年的百货消费记录数据集,包含了62 438会员卡用户的139 635笔交易。本文对数据做了预处理,仅保留至少有三笔交易的用户及其交易记录。为了实验评价,实验从中抽取了四个季度均有数据的3 454个用户,共有12 762笔交易数据。本文进一步把数据集分成两部分: 将用户前三个季度的数据作为训练数据,第四个季度的数据作为测试数据。由于我们获得的数据类型为百货品牌,因此我们针对百货品牌进行推荐。对每种方法产生的前n个品牌(n=5、10、15),通过计算其F-measure来进行推荐效果的比较。
其中L_truth代表用户真实购买的品牌集合,L_predict表示模型预测的推荐结果。在实验中,共采用了三种基准方法进行对比实验:
1. 基于流行度的方法(Top): 以购买数量对品牌进行排序,取前n个结果;
2. 基于K-近邻的协同过滤算法(KNN): 本文取K=10的近邻,对用户进行品牌推荐;
3. 基于矩阵分解的协同过滤算法(MF)。
对于本文提出的方法和基于矩阵分解的协同过滤算法,需要设定潜在相关分量的维度K,在实验中,选取了K分别为100、150、200、250、300进行比较。
5.2 实验结果
实验首先对PTM学习得到的潜在相关分量的质量进行评价。以K=150为例,在表1中列出了其中三个相关分量。可以看到第一个分量主要包含了婴幼儿品牌,第二个分量则主要是女性服饰,第三个分量则体现了男士服饰用品,语义非常的清晰。
为了进一步量化评估相关分量的质量,本文采用了自动的方法来评价分量内部的一致性,计算了分量中前n个结果的平均互信息得分PMI(n),PMI被广泛的应用在主题建模的评测中,是一种计算相关分量语义一致性的方法[11]。PMI值越大,则分量内部语义的一致性越好。其计算公式如下:
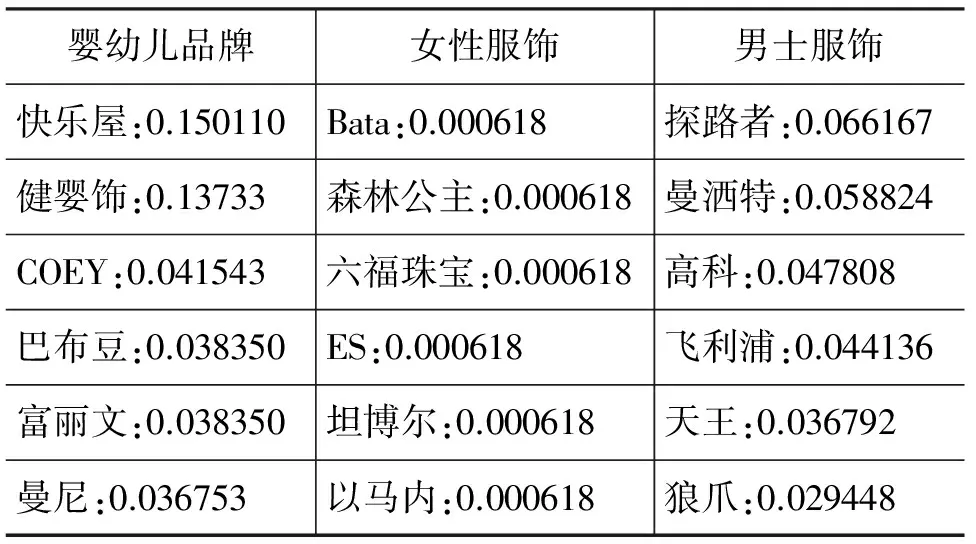
表1 从交易的角度PTM对于品牌的聚类
其中Pk(Ii,Ij)和Pk(Ii)分别表示在第k个分量中商品对(Ii,Ij)共现在同一笔交易中的概率和商品Ii出现的概率。为了比较的公平性,这些值都通过2012年度的数据集进行估计。由于只有PTM模型和MF方法具有对潜在相关分量的学习,因此在这里本文对比了这两个方法产生结果的平均PMI得分,如表2所示。
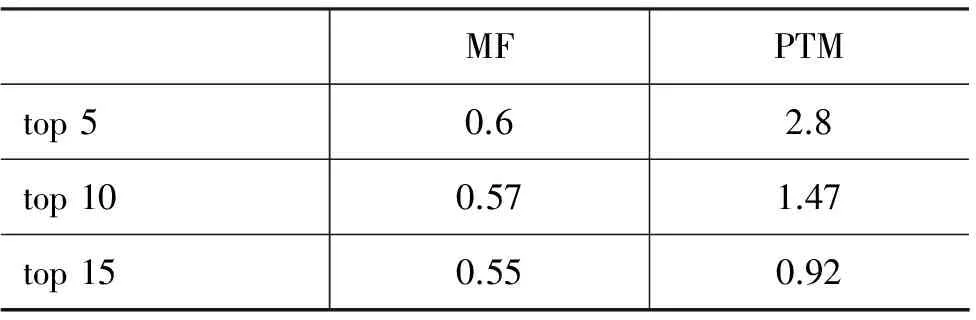
表2 模型的PMI比较
从实验结果可以发现,PTM模型得到的每个分量前n个结果的平均PMI得分要显著的高于MF方法,这说明本文的方法可以产生内部关联性强、更加一致的相关分量,这意味着通过从交易的维度出发,对共现模式直接建模,PTM模型可以更好地建模品牌间的相关性。
实验进一步对不同算法的推荐性能进行了对比,结果显示在图2 中。从结果中可以发现,基于K-近邻的协同过滤算法性能最差,这是由于在线下百货交易数据中,单个用户的购买行为及其稀疏,这对K-近邻的寻找带来了极大的困难,导致性能低下。通过矩阵分解获得用户兴趣降维的表达,可以较好的解决稀疏性带来的问题,从而使得推荐性能得到提升。本文发现一个有趣的现象是基于流行度的简单方法获得了良好的效果,这可能的原因是用户对一些好品牌具有较高的品牌忠诚度,用户过去购买的品牌将来有很大的可能还会购买,导致线下百货交易中热门品牌的分布在不同的季度比较相似,因此向用户推荐热门的品牌会有不错的效果。最终,本文提出的PTM模型一致的优于其他基准方法。通过从全局交易的角度去建模线下百货交易数据,既能有效地避免数据稀疏性,学得较好的相关分量,又能兼顾用户的个性需求,在推荐结果上取得了很好的效果。
图 2 算法性能的比较
6 未来展望
本文针对线下百货交易数据的特点,给出了一个新颖的概率交易模型PTM来实现个性化的百货推荐。该模型通过对百货交易记录中商品的共现行为进行建模,从全局的角度基于百货数据学习得到潜在的相关分量,并基于学得的相关分量推断出用户的兴趣分布,实现个性化的推荐。通过在真实的线下百货交易数据上的实验对比,我们发现PTM模型不但能够学得语义更明、更一直的潜在相关分量,同时在推荐的性能上能显著优于已有的主流推荐算法。
由于用户的线下百货交易行为具有一定的时间特性,未来我们会考虑加入时间的维度,去建模用户兴趣随时间的变化,从而更加精确地完成个性化的推荐。
[1] Igor V Cades,Padhraic Smyth,Heikki Mannila.Probabilistic modeling of transaction data with applications to profiling visualization and prediction [C]// Proceedings of the 7th ACM SIGKDD international conference on knowledge discovery and data mining,2001:37-46.
[2] Michael J Pazzani, Daniel Billsus:Content-Based Recommendation Systems. The Adaptive Web[M],2007:325-341.
[3] Alexandrin Popescul, LyleH Ungar, David M Pennock, et al. Probabilistic Models for Unified Collaborative and Content-Based Recommendation in Sparse-Data Environments[C]//Proceedings of the 17th Conference on Uncertainty in Artificial Intelligence,2001:437-444.
[4] Marco de Gemmis Pasquale Lops Giovanni Semeraro PierpaoloBasile.Integrating tags in a semantic content-based recommender[C]// Proceedings of the 2008 ACM conference on Recommender systems, 2008: 163-170.
[5] Gediminas Adomavicius, Alexander Tuzhilin.Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible Extensions [J]. Journal IEEE Transactions on Knowledge and Data Engineering,2005:734-749.
[6] Rong Pan,Peter Dolog,Guandong Xu.KNN-Based Clustering for Improving Social Recommender Systems[J]. Lecture Notes in Computer Science, 2013: 115-125.
[7] Hao Ma,Haixuan Yang,Michael R.lyu,IrwinKing.SoRec: SoRec: social recommendation using probabilistic matrix factorization[C]// Proceedings of the 17th ACM conference on information and knowledge management ,2008: 931-940.
[8] Steffen Renlde, Christoph Freudenthaler, Zeno Gantner,et al. Bayesian Personalized Ranking from Implicit Feedback[C]// Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence,2009:452-461.
[9] Chong Wang,David M Blei.Collaborative topic modeling for recommending scientific articles[C]// Proceedings of the 17th ACM SIGKDD international conference on knowledge discovery and data mining ,2011:448-456.
[10] Xiaohuia Yan,Jiafeng Guo,Yanyan Lan,et al. A Biterm Topic Model for Short Texts[C]// Proceedings of the 22nd international conference on World Wide Web,2013: 1445-1456.
[11] Osama Khalifa, David W Corne, Mike J Chantler, Fraser Halley: Multi-objective Topic Modeling[C]// Evolutionary Multi-Criterion Optimization,2013: 51-65.
[12] Steffen Rendle,Christoph Freudenthaler,Lars Schmidt-Thieme.Factorizing personalized Markov chains for next-basket recommendation[C]// Proceedings of the 19th International Conference on World Wide Web,2010:811-820.
Probabilistic Transaction Model for Recommendation Offline Shopping Mall
WANG Pengfei1, 2, GUO Jiafeng1, LAN Yanyan1, YAN Xiaohui1, CHENG Xueqi1
(1. Key Lab of Network Data Science and Technology in ICT, Institute of Computing Technology,Chinese Academy of Sciences,Beijing 100190,China; 2. University of Chinese Academy of Sciences, Beijing 100049,China)
In this paper, we propose a novel probabilistic transaction model (PTM) for brand recommendation in the traditional shopping mall. Some existing algorithms, such as KNN based recommendation, take only local information into consideration and suffer from the sparse problem in offline transaction data. Some algorithms, such as matrix factorization based recommendation, take all transactions for each user as a whole and fail to discriminatethe co-concurrence between inter- and intra-transactions. To address these two issues, the PTM is designed to learn the latent representation of brands and transactions from all the brand co-occurrences in each transaction, and then the latent representation for each user could be derived for personalized recommendation. Experiment on real transaction data sets shows that PTM based recommendation outperforms the baselines.
PTM; probabilistic transaction model; co-concurrence

王鹏飞(1987—),博士,主要研究领域为数据挖掘,机器学习,以及个性化推荐。E⁃mail:wangpengfei@software.ict.ac.cn郭嘉丰(1980—),博士,副研究员,主要研究领域为信息检索与数据挖掘。E⁃mail:guojiafeng@ict.ac.cn兰艳艳(1982—),博士,副研究员,主要研究领域为统计机器学习、排序学习和信息检索。E⁃mail:lanyanyan@ict.ac.cn
1003-0077(2016)05-0073-07
2014-09-07 定稿日期: 2015-03-25
973课题(2012CB316303,2014CB340401);863课题(2014AA015204,2012AA011003)
TP
A
