情感词典构建综述
2016-05-04梅莉莉黄河燕周新宇毛先领
梅莉莉,黄河燕,周新宇,毛先领
(北京理工大学 计算机学院,北京 100081)
情感词典构建综述
梅莉莉,黄河燕,周新宇,毛先领
(北京理工大学 计算机学院,北京 100081)
文本情感分析是近年来迅速兴起的一个研究课题,具有显著的研究价值和应用价值。情感词典的构建在情感分析任务中发挥着越来越重要的影响力。该文对情感词典构建的研究进展进行了总结。首先重点介绍了情感词典构建的研究现状,将其归纳为四种方法,即基于启发式规则的方法、基于图的方法、基于词对齐模型的方法以及基于表示学习的方法,并对每种方法进行介绍和分析;然后对一些常见的语料库、词典资源以及评测组织进行介绍;最后,对情感词典的构建进行了总结,并对发展趋势进行了展望。
情感分析;情感词典;评测;语料;综述
1 引言
近年来,随着Web 2.0的发展,越来越多的用户倾向于在社交网络、帖子论坛、用户评论等网络平台发表带有主观情感色彩的文本数据。这些数据包含大量有用的信息,这些信息反映了人们对于人物、事物、产品等对象的情感倾向性,如喜爱、讨厌、赞扬和批评等。如何利用有效的技术手段去分析这些信息吸引了不少研究学者和商业公司的注意,情感分析便是近年来应运而生的一种信息处理技术。文本情感分析又称意见挖掘,简单而言,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程[1]。情感分析具有广泛的应用价值。例如,基于产品评论的情感分析能够帮助用户了解产品口碑,帮助企业完善产品和提高竞争力;基于新闻评论的情感分析可用于舆情监控任务。此外,情感分析在金融预测、社会学、问答系统等领域也有广泛的应用前景。
通常情况下,文本表达情感主要通过情感词来体现,所以情感词典的好与坏直接影响情感分析的结果。常用的情感分析技术可分为基于词典的方法和机器学习的方法[2]。基于词典的方法通过统计文本中情感词或词组的个数来分析文本的情感倾向。机器学习的方法通常采用监督学习利用已标注数据训练一个分类器,再使用分类器对测试文本进行情感分类。监督学习需要手工标注训练数据,费时费力,而情感词可以作为训练阶段很好的标记[3-4]。另外,情感词在情感分类任务中还可以大大提高准确率[5]。综上,对于大多数情感分析任务,一个有效的情感词典至关重要。
情感词典是带有情感色彩的词(opinion words)或词组的集合,这些词可以是形容词,也可以是副词、名词或者动词。情感词通常会带有某种情感极性,一般可分为正向情感词和负向情感词。正向情感词一般表示带有积极、赞赏、肯定感情的词,也就是通常所说的褒义词,如漂亮、高兴、幸福、兴奋等。负向情感词一般表示带有消极、贬斥、否定感情的词,也就是通常所说的贬义词,如可怕、颓废、丑陋、难过等。
然而,情感词的抽取面临着很大的挑战。首先,社交网络中,用户往往比较喜欢使用口语色彩浓重、隐晦模糊和非规范性的词语表达观点,在这些非正式简短(含有语法错误、错别字、错误标点等)的文本中抽取情感词比较困难。另外,情感词极性会随着不同领域、不同语境发生改变。例如,在图书领域评论中“这部小说的故事太长而且复杂”,其中的情感词“长”带有负向的情感色彩,而在电子领域评论中“这款冰箱的寿命很长”,“长”则带有正向的情感色彩。由于要考虑语料的句子长短、内容规范性、领域性等各个方面,现有的情感词典构建方法会因语料及任务的不同而采用不同的方法。
情感分析是一个具有很大研究价值和应用价值的研究课题,情感词典的构建举足轻重。目前情感词典构建方面的研究越来越多。本文综合已有的研究成果对情感词典的构建进行分析、归纳、总结和展望。
2 情感词典构建的研究现状
在处理网络文本过程中,情感词的抽取及极性判断对于情感分析任务至关重要。大量的研究成果表明,情感词语的抽取和极性判别往往是一体化的工作,极性的分配会根据情感词抽取方法的不同而采取不同的策略。Liu和Zhang[6]将情感词典的构建分为三种: 基于手工的方法、基于词典的方法和基于语料的方法,而本文将从技术角度对情感词典的构建进行综述。大体上,情感词典的构建目前主要有四种方法: 基于启发式规则的方法、基于图的方法、基于词对齐模型的方法和基于表示学习的方法。
2.1 基于启发式规则的方法
基于启发式规则的方法主要是通过观察大量语料的特性,找到一些语法模式、语法规则、语义特征和语言学特性[7-10],然后抽取出情感词并判断其极性。本节将基于启发式规则的方法分为两类: 简单规则的方法和复杂规则的方法,最后进行小结。
2.1.1 简单规则
Hatzivassilogl和McKeown[11]利用一些种子情感词和语言学特性来发现更多的情感词并判断其极性。他们的方法分析文档集中抽取出的由连词连接的形容词对,如连接词and、but、either-or和neither-nor等。由and连接的形容词对往往具有相同的极性,如she is beautiful and clever,而由but连接的形容词对往往具有相反的极性,如she is beautiful but selfish。他们利用语言学里的连词特性抽取出了很多形容词对,但是无法抽取出语料中大量单独的形容词。
Turney和Littman[12]定义了两个词之间的点间互信息(pointwise mutual information,PMI),通过计算目标词与种子情感词之间的PMI判断情感词及其极性。PMI的基本思想是两个词共现的次数越多,二者的关系就会越密切。两个词之间的PMI值,用式(1)计算。
(1)
其中p(w1&w2)表示两个词共同出现的概率,p(w1)和p(w2)表示两个词单独出现的概率。这种方法可以识别各种词性的情感词,缺点是需要辅助的网络资源。
Hu和Liu[13]首先找到频繁出现的产品特征(名词),然后在其附近找到相关的情感词,再利用WordNet中同义词和反义词关系判断候选词的极性。Kanayama和Nasukawa[14]扩展了Hatzivassiloglou的方法,提出了句子内部和句子之间的情感关联性思想。他们认为连续的若干句子往往具有相同的情感倾向,如果其中一个句子含有情感词,那紧连它的句子也会含有情感词并具有相同的情感极性。这种方法在上下文句子中没有种子情感词的情况下召回率会大大降低。
2.1.2 复杂规则
近年来,随着很多技术方法的逐渐兴起,人们将更多的规则应用到情感词典的构建中。许多观察发现,评价词(情感词)和评价对象[15](情感词所修饰的对象)往往是相互联系的,而他们的联系为情感词的抽取提供了很重要的信息。例如,“这个型号的相机非常漂亮”,如果我们知道“相机”是评价对象,那么修饰“相机”的形容词“漂亮”就会被认为是情感词。基于这种思想,Qiu等人[16-17]沿袭了Kanayama和Nasukawa的工作,他们利用评价词和评价对象的关系抽取情感词并判断其极性,提出了双重传播(double propagation)[18]的思想,这种bootstraping的思想联合抽取评价词和评价对象。他们借助依存句法、POS(Part of Speech)标注、parser结果来分析评价词和评价对象之间的关系,再根据定义的八条规则迭代扩展情感词集。这种方法大大增加了召回率,但在词典扩展的过程中由于引入了噪音导致准确率不够高,另外这种方法不适合处理网络上一些非正式的文本。Agathangelou等人[19]在总结研究学者的经典方法后构建了一个多步的方法,同时利用连词和双重传播的方法抽取情感词,并利用一些语言学模式进行词语的极性消歧。
由于手工构建规则的方法耗时耗力且比较有局限性,有研究学者采用自动抽取的方法。Bollegala等人[20]抽取unigram和bigram作为词典元素,利用PMI计算词典元素之间的关联度,构建了一个分布式情感词典,对于每个情感词都有一些与它相关联的情感词列表。他们构建的情感词典在跨领域的情感分类任务上取得了较好的效果。Vishnu等[21]利用多个领域的评论数据构建了特殊领域的情感词典和领域无关的情感词典。文献[22]把情感词的词性不仅局限于形容词和动词,还扩展到带有情感的名词和名词词组上。
2.1.3 小结
基于启发式规则的方法优点是比较简单,针对性强,能够抽取特殊领域的情感词;缺点在于比较耗时,人工定义的规则也相对有局限性,可扩展性差,在处理网络上那些非正式的文本时利用语法信息往往会产生很多错误。
2.2 基于图的方法
在情感词抽取的研究中,越来越多的研究学者倾向于使用基于图传播的方法抽取情感词并判断极性。算法过程通常分两步:
1) 首先建立一个图,图的顶点是由待抽取的目标词或目标词组组成,边的权值为两个顶点之间的相似度;
2) 然后在这个图上用一个图传播的算法迭代计算顶点的情感值。
已有的图传播算法有随机游走(Random Walk)、PageRank、标签传播(Label Propagation)等。在计算边权值的过程中,会用到语法分析结果、句法上下文和词典中的语言学知识等信息。本节将根据情感图顶点的组成特点把基于图的方法分成两类: 单一化情感图顶点的方法和多元化情感图顶点的方法,最后进行小结。
2.2.1 单一化情感图顶点
Kamps等人[23]为了计算形容词的语义指向(semantic orientation)利用WordNet构建了一个同义词网络,通过计算形容词与种子情感词good和bad的最短路径确定该形容词的语义指向。这种方法需要一个同义词词典,而词语之间的反义关系却不能包含在网络中,另外只能局限于形容词。Takamura等[24]改进了该方法,他们利用WordNet上词语的注释信息、同义词、反义词以及上位词信息构建了一个图,然后利用Spin模型计算词语的极性。这种方法需要额外的词典资源。以上的方法都需要使用词典资源,然而,很多语种的情感资源并不像英文一样丰富。对于一些字典资源较稀缺的语种,有研究学者避开了词典资源的使用并取得了较好的抽取效果。由于缺少俄语词典资源,Chetviorkin等[25]为了从Twitter流中抽取情感词提出了一个两步模型的方法,首先利用语言学和统计信息在电影领域训练了一个监督模型,然后在Twitter数据集上抽取特殊领域的情感词并利用Spin模型判断极性。他们的方法优点在于一旦训练就可以运用在不同领域和不同语言。同样没有利用词典资源,文献[26]利用Web文档中的共现统计信息构建了一个情感词典网络图,然后使用一个图传播算法计算候选词的极性。这种方法优点在于未利用词典、POS标注以及语法分析相关的信息。
2.2.2 多元化情感图顶点
很多研究学者发现情感词和评价对象的关系后,只把情感词和评价对象作为图模型的顶点,这样可能会导致准确度不高。鉴于此,一些研究学者在情感图顶点中加入一些辅助元素,例如,表情符号、语义模式等。Xu等人[27-28]提出了一个两级框架结构,首先他们构建了一个情感图游走算法,不仅将情感词和评价对象作为图的顶点,还在情感图中加入语义模式,利用随机游走计算候选词的置信度,置信度越高,被认为是情感词的可能性越大;然后他们使用一个自学习策略过滤掉一些高频噪音并捕获一些长尾词。他们的方法能够提高准确率,过滤掉那些错误的情感关系和评价对象,但情感词的词性只局限于形容词。Feng等[29]把微博上的图形表情符号加入到情感图中,表情符号和候选的情感词共同作为图的顶点,然后随机游走算法抽取排序较前的情感词。这种方法不需要人工标注训练语料,也不用设计语法模式,但对于低频情感词的抽取具有局限性。
2.2.3 小结
基于图的方法优点在于可以将词与词之间的各种联系以特征的形式融入情感图中,另外利用图传播的算法往往能抽取到大量的情感词,缺点在于在图传播算法过程中可能引进很多的噪音。如何优化图传播算法以及选择准确的词语间特征是未来的挑战。
2.3 基于词对齐模型的方法
研究人员发现基于语法的方法在处理非正式的文本时往往会产生很多错误,另外这种方法在处理小或中等大小的语料时能取得较好的结果,但在处理大语料数据时往往会遇到瓶颈。鉴于此,Liu等人[30-33]提出了利用机器翻译中的词对齐模型挖掘情感词和评价对象之间的关系。如图1所示,黑色顶点表示候选情感词,白色顶点表示候选评价对象,具体步骤如下:
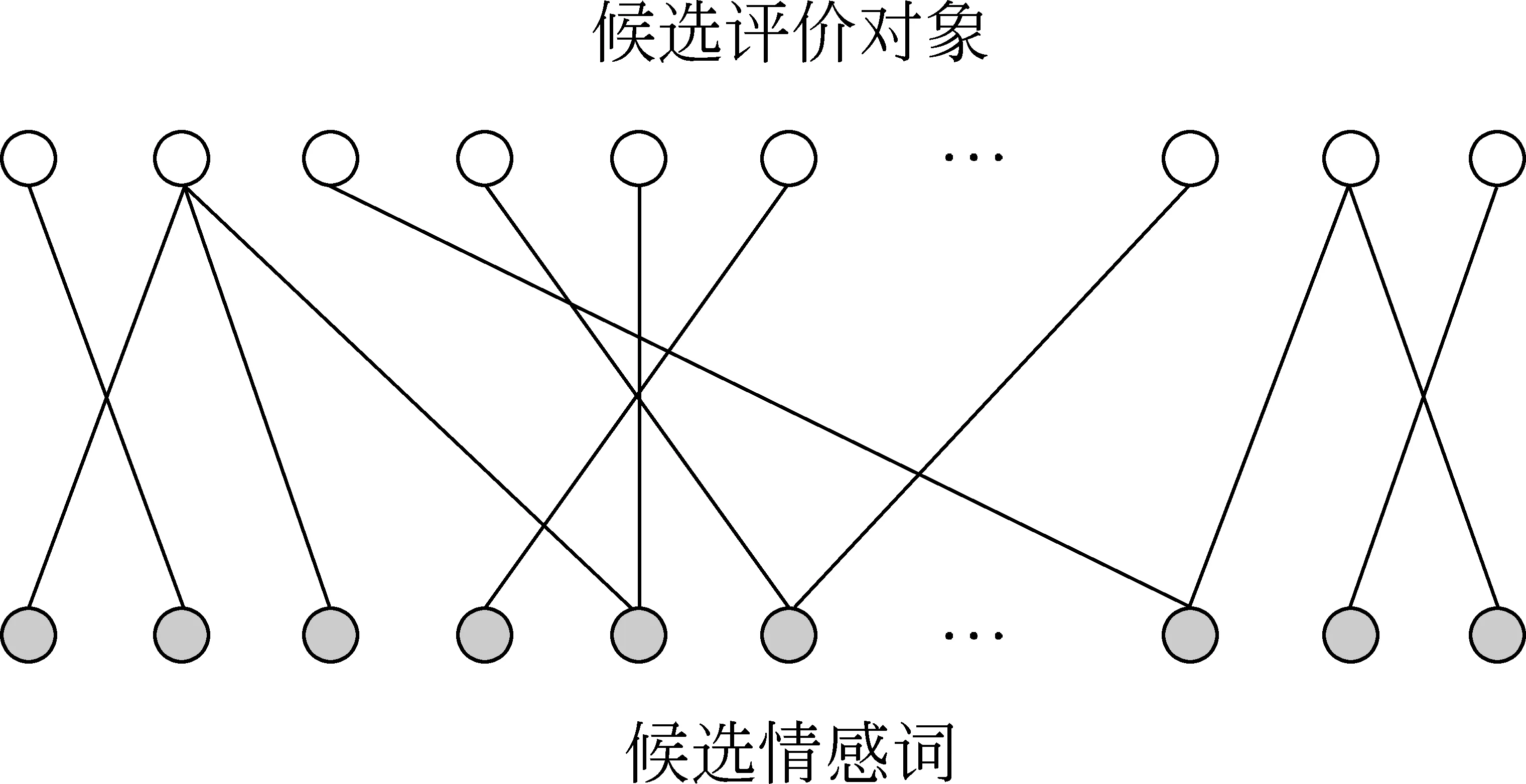
图1 词对齐模型
1) 构建二分图的顶点,选取所有的形容词作为候选情感词顶点,所有的名词或名词词组作为候选评价对象顶点;
2) 利用机器翻译模型IBM挖掘情感词和评价对象之间的关系;
3) 采用基于图的算法计算候选词的置信度,置信度越高,被选择的概率越大。
Liu等[30]首先提出将基于词的翻译模型(WTM)应用在词语的抽取上,他们提出了一个非监督词对齐模型,用该翻译模型挖掘情感词与评价对象之间的关系,在此过程中全局考虑了共现频率信息、词语位置信息等。在计算候选词的置信度时考虑到了情感关系(opinion relevance)和候选词重要性(candidate importance)这两个因素。这种方法在处理网络上的非正式文本和大语料时取得了较好的结果,同时能有效解决那些基于语法和基于近邻规则方法所面临的问题,但是准确度不够高。
文献[31-32]改进了该方法,他们提出了一个部分监督的词对齐模型(PSWAM),采用一些准确率高、召回率低的语法模式约束词对齐模型,这些语法模式的加入能够大大地提高准确率。另外,在计算候选词置信度时,在随机游走算法中对那些度值较高的顶点做出惩罚,这样能够减少噪音,提高准确率。实验表明这种基于PSWAM的方法在处理小和中等大小的数据集上取得了较好的结果。
WTM模型和PSWAM模型只考虑了情感词与评价对象的关系,均未加入语义信息。例如,“漂亮”与“好看”有相似的意思,如果“漂亮”是情感词,那么“好看”也理所当然被认为是情感词。鉴于此,文献[33]构建了一个异构图,同时考虑情感关系(opinion relation)和语义关系(semantic relation)。他利用文献[32]提出的部分监督词对齐模型挖掘情感关系,利用主题模型获取语义关系。另外,在计算候选词的置信度时,考虑了词语的固定搭配。
基于词对齐模型的方法在情感词典构建上比较新颖,它能够有效地避免在网络非正式文本上的语法分析错误,另外比较适合处理中等大小的语料。如何优化词对齐模型以及增加情感词的词性(如名词、动词等)到二分图中是值得深入研究的问题。
2.4 基于表示学习的方法
近年来,词或词组的分布式向量表示(distributed vector representation)在推动自然语言处理[34]中取得了显著的进步,它能够获取大量准确的语法和语义关系[35]。文献[36-38]提出了利用Skip-gram预测词或词组的上下文词并学习到词或词组的向量表示,即词语向量(word embedding),如“漂亮”一词的词语向量是[0.782, -0.177, -0.106, 0.109, -0.542, …]。如图2所示,对于给定的词或词组wi,利用它的词语向量ei预测其上下文词。目标函数如式(2)所示。
(2)
其中T表示每个词在语料中出现的次数,c表示窗口的大小。

图2 skip-gram模型
Tang等人[39]首次提出利用词组的向量表示来构建大规模的情感词典,实验表明这种方法取得了较好的效果。为了将文本的情感信息加入到Skip-gram模型词组的向量表示中,他们构建了一个神经网络架构,定义情感部分目标函数如式(3)所示。
(3)
其中,S表示词组所在的句子在语料中出现的次数,sej表示句子的向量表示。加入情感信息后的神经网络目标函数为f与g的线性组合。这种方法将情感词典的学习看作是词组层次的情感分类任务,取得了较好的效果。
此外,还有一些学者尝试将文本的情感信息加入到词语向量的表示学习中。Mass等人[40]提出了一个同时获取语义和词语间情感信息的词语向量表示方法,语义信息部分基于概率模型获取,情感信息部分基于情感注释获取,最终可以得到一个同时包含语义信息和情感信息的词语向量表示。这种方法取得了较好的效果,但优化函数并非是凸函数且需要较长的学习时间。Labutov和Lipson[41]改进了该方法,他们利用已有的向量表示以及具有情感极性的句子得到了基于任务的新词语向量,由于利用了现有的信息资源,所以大大节省了运行时间。另外,一些学者想到在C&W模型中加入情感信息, Tang等[42]扩展了C&W模型,构建了三个神经网络架构,通过将情感信息加入到损失函数中得到特定情感词的向量表示,经实验证实,这种方法在测量情感词相似度方面优于其他表示学习的方法。
基于表示学习的方法是在近年来逐渐兴起的词语向量研究上发展起来的,具有广阔的研究前景,未来如何优化神经网络模型以及加入有效的情感特征是值得研究的方向。
3 评测标准
公共的评测标准对于推动情感词典的构建起着至关重要的作用。本节将会对现有比较有影响力的语料库[43]、词典资源以及评测组织进行小结。
3.1 语料库
3.1.1 英文语料库
影评数据集(Movie Review Data)*http://www.cs.cornell.edu/people/pabo/movie-review-data/: 该数据集是由Pang和Lee[44]于2002年公布的,由1 000篇正向和1 000篇负向的电影评论组成,另外标注了带有褒义和贬义感情色彩的句子各5 331句。
用户评论数据集(Customer Review Collection)*http://www.cs.uic.edu/~liub/FBS/sentiment-analysis.html: 该数据集起源于Hu和Liu[13]于2004年从亚马逊和Cnet上抓取的,包含了五个电子产品的用户评论数据集,有两种数码相机、DVD播放器、mp3播放器以及手机,平均每个数据集有789个句子,63条评论。他们将每个评论语句标注了评价对象、情感句极性和强度。
MPQA(multiple-perspective QA)语料库*http://mpqa.cs.pitt.edu/: 该数据集最初由Wiebe等人[45-46]构建,包含有692篇新闻评论,每句都标注了评价对象、观点持有者、极性及强度等信息。该语料是一个深度标注的语料库,规模较小。
3.1.2 中文或混合语言语料库
Large数据集[30,47]: 该数据集包含有三个领域: 宾馆、MP3以及餐馆,两种语言英语和汉语。平均每个领域有6 000个句子,因此比较适合训练语料较大的情况。
中文酒店评论语料*http://www.datatang.com/data/11936: 该语料是由谭松波博士[48]整理的一个较大规模的酒店评论语料,从携程网上自动采集,并经过整理而成。语料规模为10 000篇,并标注了正负类。
3.2 词典资源
在构建情感词典的过程中,很多是基于词典的方法,因此高质量的词典资源非常重要,下面列举一些常用的词典资源。
(1) General Inquirer Lexicon*http://www.wjh.harvard.edu/~inquirer/: 该词典是由Philip Stone等人[49]于60年代开始直到现在仍在开发的词典,包含1 915个正向词和2 291个负向词。该词典标注的较详细,每个词语标有极性、强度、领域类别等信息。
(2) Subjective lexicon*http://mpqa.cs.pitt.edu/lexicons/subj_lexicon/: 该词典来自于OpinionFinder系统,含有8 221个主观词[1],每个词语标有词性、情感极性和极性强度等信息。
(3) HowNet情感词典*http://www.keenage.com/html/c_bulletin_2007.htm: 该词典分为中文情感分析用词语集和英文情感分析用词语集。其中,中文情感分析用词语集包含词语和短语共9 193个,英文情感分析用词语集包含词语和短语共9 142个,它们都被分成了正面情感、负面情感、正面评价、负面评价、程度级别和主张词语共六类。
(4) 姚天昉等人构建的汉语情感词词典[50-51]: 该词典包含有3 120个褒义情感词和3 485个贬义情感词。
3.3 评测组织
NTCIR(NACSIS test collection for IR systems)是日本国家科学咨询系统中心主办的多语言处理国际评测会议*http://research.nii.ac.jp/ntcir/index-en.html,主要关注中、日、韩等亚洲语种的相关信息处理[52]。NTCIR的目标是进行多语种、多粒度、多信息源、深层次的主观性信息提取。它的主要任务是从新闻报道中抽取主观性信息,给定各个语种的句子,要求参加评测的系统判断句子是否和篇章的主题相关,并从句子中提取出评价词极性、观点持有者等信息。
COAE(Chinese opinion analysis evaluation)是中国中文信息学会信息检索专委会于2008年推出的中文倾向性分析系列评测。它的主要目的是推动中文倾向性分析词典的建立,促进中文主客观分析技术、倾向性判别技术、评价对象抽取技术以及观点检索技术的发展[53]。COAE主要在词语级、句子级和篇章级进行分析评测,评测任务包括情感词识别、情感词极性判别、评价对象抽取、观点句抽取等。COAE的开展推动和加速了中文倾向性分析研究的发展。
4 总结及展望
本文对情感词典构建方法进行了综述,其中重点介绍了情感词典构建的研究现状,将其归纳为四种方法,并对每种方法进行分析和总结,另外也列举了一些常见的评测标准,包括语料库、词典资源以及评测组织。情感分析的研究目前只有十几年的时间,具有很大的研究价值和应用价值[54-55],而情感词典的构建在情感分析任务中发挥着越来越重要的影响力。虽然情感词典的构建已经取得了巨大进展,但我们认为情感词典的构建研究在以下四个方面值得考虑:
(1) 语料的变化。观察COAE 2014列出的评测任务发现,出现了一项微博情感新词发现与判定的任务,要求从大规模微博句子集中自动发现新的词语以及判定每个词语的情感倾向性。微博、论坛等用户生成内容一般具有一定的数据特点,晦涩模糊、不规范以及常常出现一些带有情感色彩的新词。如“这个选课系统真是坑爹呀”,“坑爹”便是带有负面感情色彩的形容词。因此,探究微博、论坛数据的特点并加以利用将会对情感词典的构建发挥重要的作用。
(2) 一词多义以及语境的影响。同一个词语往往会在不同的语境表现出不同的词义、词性以及情感倾向。如,“cold”一词在形容天气时表示“寒冷”,而在形容人时则有“不友好”的意思。目前,这一问题已经引起了很多研究学者的关注,未来急切需要我们将情感词语的抽取做地更细更深入。
(3) 跨语言的研究。目前,英语的情感资源较为丰富,而其他语种的情感资源则相对较稀缺。由于语言表达方式的差异,很多在英语方面较为成熟的资源和方法无法应用在其他语种。因此,探究英语与其他语种的特点,并将成熟的资源和方法应用在其他语种上将会极大地推进情感词典的构建研究。
(4) 考虑词性及领域相关性。情感词不仅是指形容词带有感情色彩,还包含有动词、名词、副词等词性,另外,情感词还会与领域有着极强的相关性。因此考虑词性以及利用领域知识会对情感词典的构建有很大的帮助。
[1] 赵妍妍,秦兵,刘挺.文本情感分析[J]. 软件学报, 2010, 21(8): 1834-1848.
[2] Maite Taboada, Julian Brooke, Milan Tofiloski, et al. Lexicon-based methods for sentiment analysis[J]. Computational linguistics, 2011, 37(2): 267-307.
[3] Songbo Tan, Yuefen Wang, Xueqi Cheng. Combining learn-based and lexicon-based techniques for sentiment detection without using labeled examples[C]//Proceedings of the 31st annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 2008: 743-744.
[4] Likun Qiu, Weishi Zhang, Changjian Hu, et al. Selc: a self-supervised model for sentiment classification[C]//Proceedings of the 18th ACM conference on Information and knowledge management(CIKM), ACM, 2009: 929-936.
[5] Prem Melville, Wojciech Gryc, Richard D Lawrence. Sentiment analysis of blogs by combining lexical knowledge with text classification[C]//Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2009: 1275-1284.
[6] Bing Liu, Lei Zhang. A survey of opinion mining and sentiment analysis[M]//Mining text data. Springer US, 2012: 415-463.
[7] Soo-Min Kim, Eduard Hovy. Automatic detection of opinion bearing words and sentences[C]//Companion Volume to the Proceedings of the International Joint Conference on Natural Language Processing (IJCNLP).2005: 61-66.
[8] Soo-Min Kim, Eduard Hovy. Determining the sentiment of opinions[C]//Proceedings of the 20th international conference on Computational Linguistics. Association for Computational Linguistics, 2004: 1367.
[9] 朱嫣岚, 闵锦, 周雅倩, 等. 基于 HowNet 的词汇语义倾向计算[J]. 中文信息学报, 2006, 20(1): 14-20.
[10] 王素格, 李德玉, 魏英杰, 等. 基于同义词的词汇情感倾向判别方法[J]. 中文信息学报, 2009, 23(5): 68-74.
[11] Vasileios Hatzivassiloglou, Kathleen R McKeown. Predicting the semantic orientation of adjectives[C]//Proceedings of the 35th annual meeting of the association for computational linguistics and eighth conference of the european chapter of the association for computational linguistics. Association for Computational Linguistics, 1997: 174-181.
[12] Turney, Peter D, Michael L Littman. Measuring praise and criticism: Inference of semantic orientation from association[J]. ACM Transactions on Information Systems (TOIS), 2003, 21(4): 315-346.
[13] Minqing Hu, Bing Liu. Mining and summarizing customer reviews[C]//Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2004: 168-177.
[14] Hiroshi Kanayama, Tetsuya Nasukawa. Fully automatic lexicon expansion for domain-oriented sentiment analysis[C]//Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2006: 355-363.
[15] 刘鸿宇, 赵妍妍, 秦兵, 等. 评价对象抽取及其倾向性分析[J]. 中文信息学报, 2010 (1): 84-88.
[16] Guang Qiu, Bing Liu, Jiajun Bu, et al. Expanding Domain Sentiment Lexicon through Double Propagation[C]//Prolecdings of the IJCAI.2009, 9: 1199-1204.
[17] Guang Qiu, Bing Liu, Jiajun Bu, et al. Opinion word expansion and target extraction through double propagation[J]. Computational linguistics, 2011, 37(1): 9-27.
[18] Lei Zhang, Bing Liu, Suk Hwan Lim, et al. Extracting and ranking product features in opinion documents[C]//Proceedings of the 23rd international conference on computational linguistics: Posters. Association for Computational Linguistics, 2010: 1462-1470.
[19] Pantelis Agathangelou, Ioannis Katakis, Fotios Kokkoras, et al. Mining Domain-Specific Dictionaries of Opinion Words[M]//Web Information Systems Engineering-WISE 2014. Springer International Publishing, 2014: 47-62.
[20] Danushka Bollegala, David Weir, John Carroll. Cross-domain sentiment classification using a sentiment sensitive thesaurus[J]. Knowledge and Data Engineering, IEEE Transactions on, 2013, 25(8): 1719-1731.
[21] K Sai Vishnu, TApoorva, Deepika Gupta. Learning domain-specific and domain-independent opinion oriented lexicons using multiple domain knowledge[C]//Contemporary Computing (IC3), 2014 Seventh International Conference on. IEEE, 2014: 318-323.
[22] Zhe Qi, Mingchu Li. Mining Domain-Dependent Noun Opinion Words for Sentiment Analysis[M].Multimedia and Ubiquitous Engineering. Springer Berlin Heidelberg, 2014: 165-171.
[23] Jaap Kamps, Maarten Marx, Robert J Mokken, et al. Using wordnet to measure semantic orientations of adjectives[C]//Proceedings of the Fourth international Conference on Language Resources and Evaluation.ELRA,2004,1115-1118.
[24] Hiroya Takamura, Takashi Inui, Manabu Okumura. Extracting semantic orientations of words using spin model[C]//Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2005: 133-140.
[25] IliaChetviorkin, Natalia Loukachevitch. Two-Step Model for Sentiment Lexicon Extraction from Twitter Streams[C]//Proceedings of the ACL 2014, 2014: 67.
[26] LeonidVelikovich, Sasha Blair-Goldensohn, Kerry Hannan, et al. The viability of web-derived polarity lexicons[C]//Proceedings of the 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. 2010: 777-785.
[27] Liheng Xu, Kang Liu, Siwei Lai, et al. Mining Opinion Words and Opinion Targets in a Two-Stage Framework[C]//proceedings of the ACL (1).2013: 1764-1773.
[28] Liheng Xu, Kang Liu, Siwei Lai, et al. Walk and learn: a two-stage approach for opinion words and opinion targets co-extraction[C]//Proceedings of the 22nd international conference on World Wide Web companion. 2013: 95-96.
[29] Shi Feng, Kaisong Song, Daling Wang, et al. A word-emoticon mutual reinforcement ranking model for building sentiment lexicon from massive collection of microblogs[J]. World Wide Web, 2014: 1-19.
[30] Kang Liu,Liheng Xu, Jun Zhao. Opinion target extraction using word-based translation model[C]//Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. 2012: 1346-1356.
[31] Kang Liu,Liheng Xu, Yang Liu, et al. Opinion target extraction using partially-supervised word alignment model[C]//Proceedings of the Twenty-Third international joint conference on Artificial Intelligence. AAAI Press, 2013: 2134-2140.
[32] Kang Liu,Liheng Xu, Jun Zhao. Syntactic Patterns versus Word Alignment: Extracting Opinion Targets from Online Reviews[C]//Proceedings of the ACL 2013: 1754-1763.
[33] Kang Liu,Liheng Xu, Jun Zhao. Extracting opinion targets and opinion words from online reviews with graph co-ranking[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics.1: 314-324.
[34] 王灿辉, 张敏, 马少平. 自然语言处理在信息检索中的应用综述[J]. 中文信息学报, 2007, 21(2): 35-45.
[35] Jeffrey Pennington, RichardSocher, Christopher D Manning. Glove: Global vectors for word representation[C]//Proceedings of the Empiricial Methods in Natural Language Processing (EMNLP 2014), 2014, 12.
[36] TomasMikolov, Kai Chen, Greg Corrado, et al. Efficient estimation of word representations in vector space[C]//Proceedings of International Conference on Learning Repesentations(ICLR),2013.
[37] TomasMikolov, Ilya Sutskever, Kai Chen, et al. Distributed representations of words and phrases and their compositionality[C]//Proceedings of the Advances in Neural Information Processing Systems.2013: 3111-3119.
[38] Quoc V Le, Tomas Mikolov. Distributed representations of sentences and documents[C]//Proceedings of the ICML,2014,14,1188-1196.
[39] Duyu Tang, Furu Wei, Bing Qin, et al. Building large-scale twitter-specific sentiment lexicon: A representation learning approach[C]//Proceedings of COLING.2014: 172-182.
[40] Andrew L Maas, Raymond E Daly, Peter T Pham, et al. Learning word vectors for sentiment analysis[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics,2011: 142-150.
[41] IgorLabutov, Hod Lipson. Re-embedding words[C]//Proceedings of the ACL 2013: 489-493.
[42] Duyu Tang, Furu Wei, Nan Yang, et al. Learning sentiment-specific word embedding for twitter sentiment classification[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics.2014: 1555-1565.
[43] 徐琳宏, 林鸿飞, 赵晶. 情感语料库的构建和分析[J]. 中文信息学报, 2008, 22(1): 116-122.
[44] Bo Pang, Lillian Lee,Shivakumar Vaithyanathan. Thumbs up?: sentiment classification using machine learning techniques[C]//Proceedings of the ACL-02 conference on Empirical methods in natural language processing-Volume 10. Association for Computational Linguistics, 2002: 79-86.
[45] Janyce Wiebe. Learning subjective adjectives from corpora[C]//Proceedings of the AAAI/IAAI.2000: 735-740.
[46] Janyce Wiebe, Ellen Riloff. Creating subjective and objective sentence classifiers from unannotated texts[M].Computational Linguistics and Intelligent Text Processing. Springer Berlin Heidelberg, 2005: 486-497.
[47] Hongning Wang, Yue Lu, ChengXiang Zhai. Latent aspect rating analysis without aspect keyword supervision[C]//Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2011: 618-626.
[48] 谭松波. 中文情感挖掘语料-ChnSentiCorp [EB/OL], 2010.
[49] Philip J Stone, Dexter CDunphy, Marshall S Smith. The General Inquirer: A Computer Approach to Content Analysis[J] Journal of Regional Science,1966,8(1): 113-116.
[50] 姚天昉, 娄德成. 汉语情感词语义倾向判别的研究[C].中国计算技术与语言问题研究—第七届中文信息处理国际会议论文集.2007.
[51] 姚天昉, 程希文, 徐飞玉, 等. 文本意见挖掘综述[J]. 中文信息学报, 2008, 22(3): 71-80.
[52] 张俊林, 黄瑞红, 孙乐. 亚洲语言信息检索评测会议 NTCIR 介绍[J]. 数字图书馆论坛, 2006 (9): 20-25.
[53] 赵军, 许洪波, 黄萱菁, 等. 中文倾向性分析评测技术报告[C]. 第 1 届中文倾向性分析评测研讨会论文集. 北京, 2008: 1-20.
[54] 黄萱菁, 赵军. 中文文本情感倾向性分析[J]. 中国计算机学会通讯, 2008, 4(2): 41-46.
[55] 黄萱菁, 张奇, 吴苑斌. 文本情感倾向分析[J]. 中文信息学报, 2012, 25(6): 118-126.
A Survey on Sentiment Lexicon Construction
MEI Lili,HUANG Heyan,ZHOU Xinyu,MAO Xianling
(School of Computer Science and Technology,Beijing Institute of Technology,Beijing 100081,China)
Sentiment analysis is a rapidly developing research topic in recent years, which has great research value and application value. Sentiment lexicon construction plays an increasingly important influence on the task . This paper summarizes the research progress on sentiment lexicon construction. Firstly, four kinds of methods are summarized and analyzed, including the method based on heuristic rules, the method based on graph, the method based on word alignment model and the method based on representation learning. Then, some popular corpus, dictionary resources and evaluation organizations are introduced. Finally, we conclude the topic and provide the development trends of sentiment lexicon construction.
sentiment analysis; sentiment lexicon; evaluation; corpus; survey

梅莉莉(1991—),硕士,主要研究领域为自然语言处理。E⁃mail:lilymay@bit.edu.cn黄河燕(1963—),博士,教授,主要研究领域为机器翻译、自然语言处理、社会计算。E⁃mail:hhy63@bit.edu.cn周新宇(1991—),硕士,主要研究领域为自然语言处理,情感分类及群体情绪预警。E⁃mail:zxykid@qq.com
1003-0077(2016)05-0019-09
2015-05-04 定稿日期: 2016-03-30
国家重点基础研究发展计划(2013CB329303);国家自然科学基金(61402036,61132009)
TP391
A
