面向短文本情感分类的特征拓扑聚合模型
2016-05-04冯旭鹏黄青松付晓东刘利军
胡 杨,冯旭鹏,黄青松,3,付晓东,刘 骊,刘利军
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 昆明理工大学 教育技术与网络中心,云南 昆明 650500;3. 云南省计算机技术应用重点实验室,云南 昆明 650500)
面向短文本情感分类的特征拓扑聚合模型
胡 杨1,冯旭鹏2,黄青松1,3,付晓东1,刘 骊1,刘利军1
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 昆明理工大学 教育技术与网络中心,云南 昆明 650500;3. 云南省计算机技术应用重点实验室,云南 昆明 650500)
由于短文本极稀疏性和特征分散的特点,短文本的情感分类效果总是不及篇章文本的情感分类,针对此问题,该文提出面向短文本情感分类的特征拓扑聚合模型。模型首先从特征点互信息,情感指向相似度,主题归属差异值三个维度整合计算情感特征的关联度,然后根据特征关联度建立拓扑聚合图模型,通过在图上求解强联通分量聚合高关联度情感特征,从大量未标注语料中提取相似特征对训练集特征进行补充,同时降低训练空间维度。实验将模型应用于短文本情感分类,与基准算法对比能提高分类准确率和召回率分别达0.03和0.027。验证了模型在缓解短文本极稀疏性和特征分散问题上的效果。
短文本;情感分类;特征关联度;强联通分量;拓扑聚合
1 引言
随着科学和网络技术的发展以及时代的进步,互联网在人们的生活中扮演着越来越重要的角色。而随着智能手机,平板电脑进入人们的日常生活,在微博、微信、社交网络、电子商务网站和各类服务平台上,以短评论和微博等各种形式存在的短文本信息大量出现且数量还在快速增长。针对这些短文本信息的分析和处理技术已经应用于观点挖掘,用户行为分析,热点话题发现[1]与追踪乃至医疗服务评价等各个领域,从短文本挖掘出有用的信息目前已成为研究界关注的重点。
在针对文本的分析与处理研究工作中,文本情感分类是一个重要的分支,即对主观性文本进行正负极倾向性的分类,从而达到了解用户心理,监督舆论导向等应用目的。Pang等首次将监督学习方法引入文本情感分类问题的解决[2],后续的研究[3-5]说明监督学习的方法已经能够很好的解决文本情感分类的问题。不同于普通文本,短文本由于字数少,用语随意且不规范,使其具有天然的极稀疏性[6],同时,短文本词语特征除了稀疏,还形式多样并且分散。在监督学习中,对已有数据进行人工标记是一项繁重的任务,通常已标记的训练语料是有限的,更多的是大量未标记语料。短文本因篇幅短小,表达随性,其未标注语料中有许多未在训练语料出现的有用特征。例如,在未标注语料中虽然出现了与训练语料中某特征词近义的词条,在训练语料中却从未出现该特征词的情况,例如,训练语料中只有“厉害”或“牛”,未标注语料中却出现“碉堡”,“给力”等词。根据上述论据及前人的总结[7],传统监督学习情感分类方法对短文本情感分类问题并不适用。
目前,研究者主要从两方面对短文本处理问题展开研究: 1)借助外源知识库(主要为Wikipedia,WordNet,HowNet等)对短文本内容进行扩充[6,8-9];2)采用各种特征提取和映射方法,对短文本特征空间进行降维以缓解短文本特征的极稀疏问题[10-13]。其中,第二类方法虽然不需要外源知识库,但因与特定算法或数据的高度耦合性以及短文本训练集蕴含的内容有限,降维后分类和检索的准确率往往偏低[14]。相比之下,第一种基于外源知识扩展的短文本处理方法效果较好,然而,外源知识库大多依赖于人工维护,且针对微博等新兴语料的资源较为稀缺,另一方面,严谨的外源知识库更新速度较慢,很难跟上短文本社交语料极快的更新速度[4],这导致第一类方法有其自身的不足。文献[4]针对此问题提出了基于伪相关反馈的短文本扩展方法,将外部知识源从固定的本体库转为更新速度更快的搜索引擎,从而解决了外源知识库更新速度慢于短文本语料更新速度的问题,但此方法仍然依赖于外部知识源,且搜索引擎的搜索结果排序除了依照文本内容本身的相似度以外,还加入许多商业及个性化因素,排序靠前的结果混杂了较多噪音,从而影响短文本扩展内容的质量。
针对以上问题,提出面向短文本情感倾向性分类的特征拓扑吸收与组合模型,模型定义多维度的特征关联度计算方法,计算有标注训练集和未标注语料集中所有特征的关联度,并建立基于图的特征关联模型。从未标注语料集中提取相似特征对数量有限的训练集特征进行补充,再利用图结构对相似的特征进行聚合处理。模型不需要外部知识源的介入,训练集特征既得到补充又能有效降低维度,且未标注语料越多越丰富,模型越能发挥优势。通过在真实语料上的实验验证,提出的模型在短文本情感分类任务中具有较好的性能。
论文组织结构安排如下: 第二节为相关工作,第三节具体阐述了短文本特征拓扑聚合模型的设计,第四节为实验与分析,第五节对当前工作进行总结和展望。
2 相关工作
文本情感分类是情感识别类问题中的一个重要部分[15]。此领域效果显著的研究成果层出不穷,文献[2]采用朴素贝叶斯、最大熵、支持向量机(Support Vector Machine,SVM)三种分类器对电影评论进行情感分类,能够达到接近80%的准确率,成为监督学习方法解决情感分类问题的典范。Turney提出了无监督的情感分类算法,通过互信息计算词语的语义倾向,进而计算得篇章整体的倾向值[16]。在国内,也有李素科等采用情感特征的谱聚类方法并提出半监督的情感分类方法[17]。
而面对短文本极稀疏,更新快,不规范等特点,在针对短文本进行挖掘与分析工作之前,需要研究者做好特征降维或知识补充的预处理工作。文献[6,8-9]主要采用借助外源知识库的方式对短文本内容进行扩展,Hu根据短文本特征词数量的不同分别采用Wikipedia和WordNet扩展短文本[8],Han利用Wikipedia的结构化信息来补充微博或短文本内容,并结合图上的随机游走算法训练模型[9],肖永磊同样将外源知识库设定为Wikipedia,并采用NMF分解(非负矩阵分解)的方法计算Wikipedia概念之间的语义近邻,为微博扩展与自身相关的语义概念[6]。
另外,还有一些不完全依赖于外源知识库的短文本处理方法。Sriram等分析微博的文本特点,在词袋模型(Bag of Words)的基础上抽取八个额外的应用相关性特征作为辅助特征来补充短文本,提高分类准确率[10],Haesun等使用基于聚类重心数据降维(Centroid method, CM)的方法应用于文本分类[11],Xu等使用潜在语义分析方法解决手机短信分类问题[12],刘全超等利用微博短文本内容及转发、评论关系特征构建情感词典和表情符号库,扩展微博话题以帮助分析微博话题舆情[13]。
目前,国内关于短文本情感分类的研究主要集中在对短文本领域主题的划分与补充以及探究短文本句法规律等方面。杨震等首先对于短文信息进行基于主体相关的上下文领域划分,再根据不同的上下文领域训练单独的短文本分类器,对所属各个领域的短文本分别进行分类[7],陈南昌等从语义分析的角度出发,总结出含显性归总句,含隐性归总句,含特征词和一般文本四种短文本类别,并采取不同策略计算四种短文本的情感值[18]。微博作为短文本的代表文体也受到了学者的关注,文献[15,19]分别基于微博意群间的关系和微博情感单元提出了有效的微博文本情感分类方法。
3 情感特征拓扑图聚合模型
由于面对的是情感分类问题,情感特征是分类学习的基本元素,本文选择常含有主观性的形容词和动词作为情感词,在全体语料集的范围内(包含有标注训练集和未标注语料集)计算情感特征词之间的关联度,后基于强联通分量模型开展训练集特征的补充和多特征的聚合操作。接下来,将从情感特征间关联度的计算和特征补充及聚合两部分阐述情感特征的拓扑聚合模型,模型整体结构如图1所示。
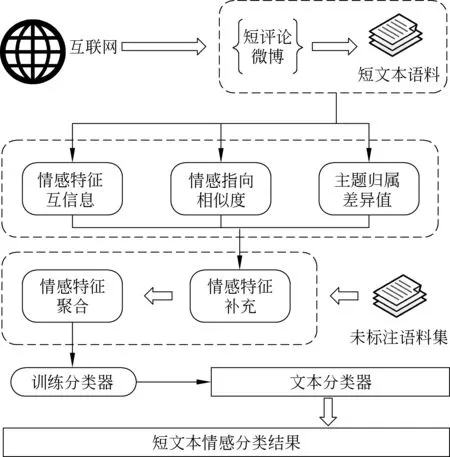
图1 情感特征拓扑聚合模型整体结构
3.1 情感特征关联度计算
设计多维度特征相关性衡量策略,计算改进的点互信息,情感指向相似度,主题归属差异值三个相似维度并整合。
1. 短文本情感特征点互信息
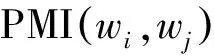
(1)
但由于短文本长度极短(一般不超过140字),如果共现情感词属于被转折性词语分开的情况,则需要对共现值重新定义计算。
转折性词语分为两种:
1) 转折连接词
转折连接词一般出现在短文本中间部分,例如,“这部电影动作精彩 却 剧情恶俗!”,设定: 如果共现的情感词出现在转折连词两端,则认为它们被转折性词语分开。
2) 转折指示词
转折指示词一般出现在短文本句首部分,例如,“尽管 微软精心设计了这一代操作系统,还是不得不说Win8是一款失败的作品!”。设定: 如果短文本中出现转折指示词且共现情感词出现在标点符号的两端,则认为它们被转折性词语分开。
转折连接词和转折指示词具体如表1示例。

表1 转折性词语示例表
考虑情感词是否被转折性词语分开,设置影响权值如式(2)所示。
(2)
于是,计算特征词点互信息时考虑入转折性词语的影响,将式(1)改进如式(3)所示。
(3)
2. 情感指向相似度
情感指向是情感词修饰实体名词的分布情况,这里设定在短文本中,某情感词前最近的实体名词被该情感词修饰,例如,“许教授的敢言固然可敬,但缺乏建设性,忽视了正能量的传播。”其中,“可敬”与“缺乏建设性”修饰“敢言”,“传播”修饰“正能量”。
每个情感词都有自己特有且相对固定的修饰对象,可以认为: 情感指向的相似度是情感词相似度的一种体现。
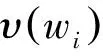
(4)
式(4)中,N为语料集中实体名词的数量,向量元素nij根据实体名词nj是否被情感词wi修饰,设定如式(5)所示。
(5)
如此设定向量元素的意义: 各情感词对于所有实体名词的指向分布是一个0-1分布,若某实体名词被该情感词修饰过,则对应向量元素为1,说明情感词曾被用于修饰该实体名词,否则对应向量元素为0,表示实体名词与情感词之间不存在修饰关系。
情感词wi和wj间的情感指向相似度使用余弦相似度计算,加入平滑因子的计算公式如式(6)所示。
(6)
3. 情感特征主题归属差异值
隐式狄利克雷模型(Latent Dirichlet Allocation,LDA)是一个生成式概率模型,能很好的表示文本的内蕴特征,模型在文本与特征词之间加入了一层抽象的概念——主题[21]。在LDA模型中,主题被定义为文本中特征的概率分布,反过来想,语料中每个特征词也可以表示为归属于各个主题的概率分布,如图2所示。
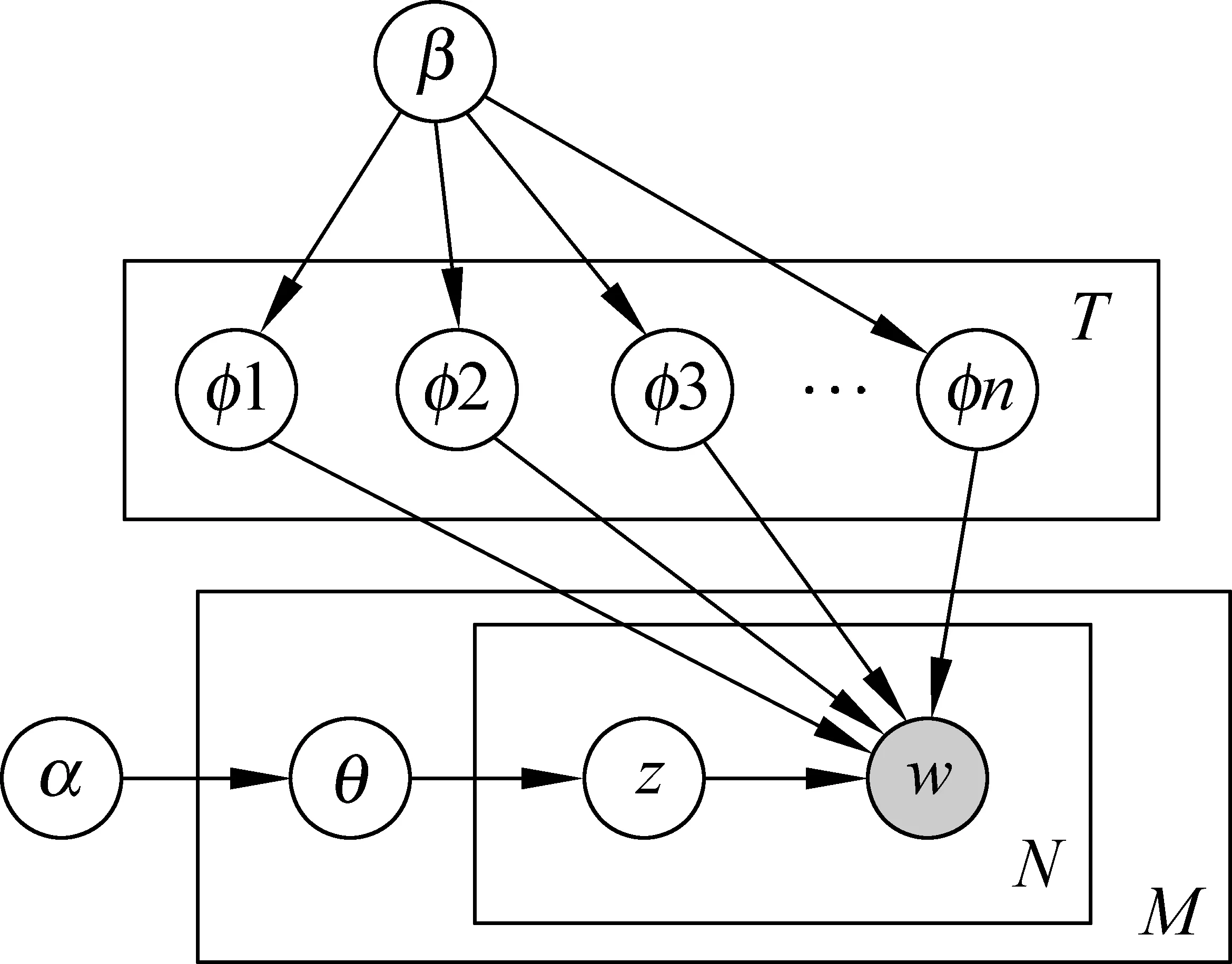
图2 LDA模型特征主题归属
图中,α和β是超参数[21],M,N,T分别为文档数,特征数和主题数,w为特征词,z为特征词的主题分配,θ为“文本—主题”的概率分布,φ1,φ2,…φn是各个主题下“主题—特征”的概率分布。LDA模型中,“主题—特征”的分布概率φkn的计算公式如式(7)所示
(7)
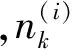
(8)
至此,将每个情感特征表示为所属各个主题的概率分布形式如式(9),其中φnk意义是出现情感词wn时,情感词wn归属于主题k的条件概率,并由式(8)估算。
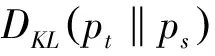
(11)
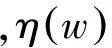
3.2 短文本情感特征吸收与聚合模型
情感特征关联度由上一小节求得的三个维度的情感特征相似性整合而成,通过情感特征之间的关联度可以确定特征聚合图上的边关系。情感特征关联度整合计算公式如式(12)所示。
(12)
关于式(12),由于情感特征的主题归属分布差异与点互信息和情感指向相似度不同,是一种分布差异的描述,故放在分母,ρ是平滑因子,N是语料集中情感特征总数。
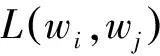
(13)
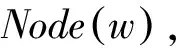
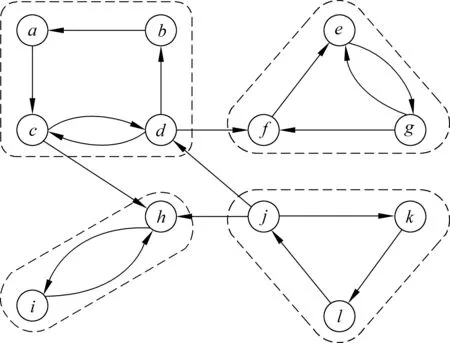
图3 情感特征聚合图模型
通过在建立的有向图模型中求强联通分量,对关联紧密相似度高的情感特征进行聚集,如图3所示。这样,来自未标注语料集的情感特征词被聚集到高相似度的训练集特征周围,对短文本情感特征进行补充,再通过“缩点”操作,即将同属一个强联通分量的节点聚合为一个点,实现短文本情感特征空间的降维。Gabow算法能在线性的时间复杂度解决强联通分量求解问题[22]。
对于未能与训练集特征聚合的未标注语料集特征被将舍弃。对于来自训练集且将被聚合在一起的原情感特征,聚合后特征值的计算有如下两种策略,在实验中将对其进行比较。
4 实验
4.1 实验数据
为评估提出的特征拓扑聚合模型面对短文本情感分类任务时的性能,实验选用的语料集与文献[7]相同: 未去重且平衡的中文情感挖掘语料集ChnSentiCorp*http://www.searchforum.org.cn/tansongbo/corpus-senti.htm,包含针对图书,旅店,电脑三个领域的短评论。除此之外,选用NLPCC 2014所提供的有标注微博情绪分析样例语料集*http://tcci.ccf.org.cn/conference/2014/pages/page04_sam.html作为补充实验数据,根据原来的细粒度类别标注对语料进行重新标记(生气、厌恶、悲伤隶属负面,开心、喜欢隶属正面,正负倾向不明显的害怕、惊讶被屏蔽)。具体各领域实验语料信息如表2所列,可能由于分词器及词库选用不同,前三种与文献[7]所列略有差异。
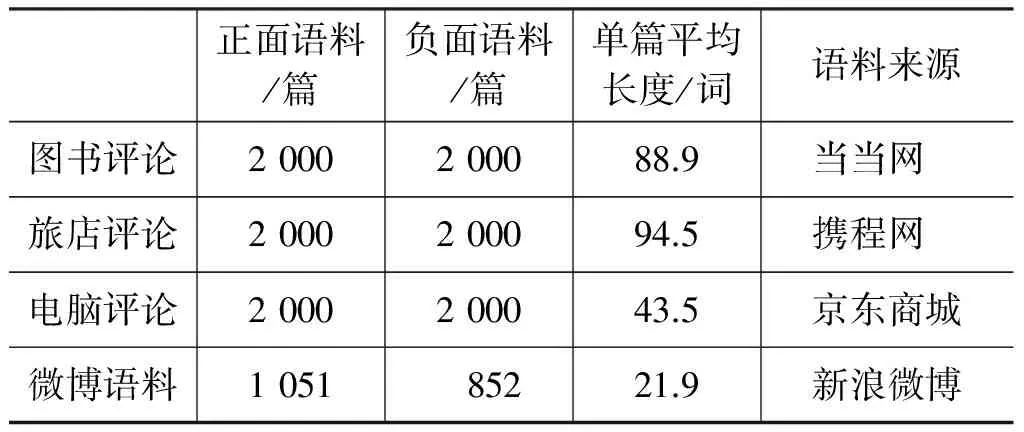
表2 短文本实验语料信息
4.2 实验设计
实验规划为五部分: 1.预处理; 2.阈值α取值影响实验; 3.LDA主题数设置实验; 4.特征聚合特征值计算策略比较实验; 5.提出模型与其他算法对比实验。
实验评价标准: 准确率(P)、召回率(R),采用微平均的方式计算全局准确率、召回率。
实验中使用的工具: 中文分词工具选用ICTCLAS*http://ictclas.nlpir.org/,选用SVM作为基础分类算法,实现工具选用LibSVM*http://www.csie.ntu.edu.tw/~cjlin/,LDA主题建模选用工具Mallet*http://mallet.cs.umass.edu/。以上工具中,LibSVM设置使用径向基核函数(Radial Basis Function,RBF),其余采用缺省值。
实验对比算法: 对实验语料先进行清洗,分词,去停用词。选择朴素贝叶斯(Naïve Bayes,NB),SVM算法直接对短文本进行情感分类以及文献[7]中基于领域归属划分和基于上下文重构的两种短文本情感分类算法作为对比算法,并按照文献[7]描述,实现算法时选用使性能最优的子方法及参数。
实验数据的分配及使用: 为了更客观地验证所提方法的性能,将每个领域的正负实验语料等分为五份,一份作为训练集,一份作为测试集,其余作为辅助训练的未标注语料集。每小份语料轮流充当以上角色进行实验,即每个领域的语料进行20轮实验,实验结果取平均值以尽可能降低随机扰动带来的影响。其他基准方法轮流将每小份语料作为测试集其余为训练集,每个领域进行五轮实验。
4.3 实验结果与分析
实验结果图4、图5展示了关于实验第二部分阈值α的不同取值影响和实验第三、四部分取不同LDA主题数及特征值不同计算策略时的部分实验结果,图4实验结果为固定主题数为150,特征值计算策略为求最大值时的结果,图5实验结果为阈值α固定为0.6时的结果。
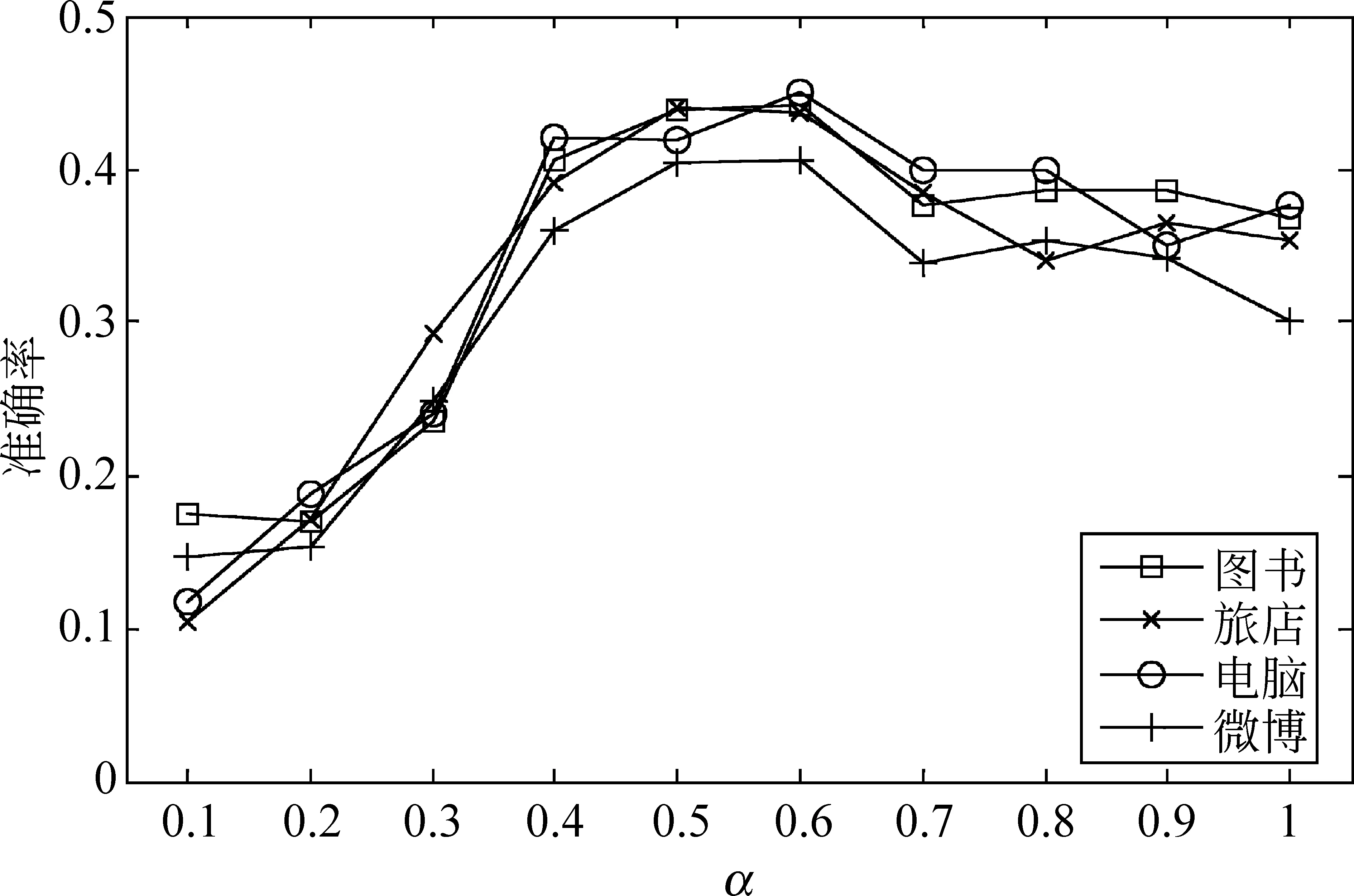
图4 阈值α取值实验结果
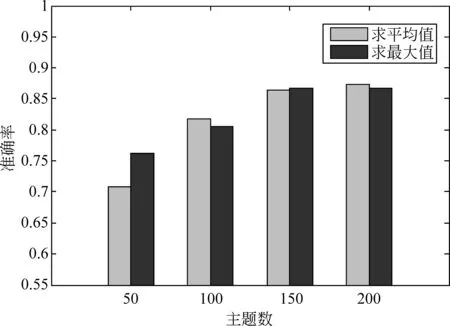
图5 主题数及特征值计算策略实验结果
分析图4结果,可以得出: 1.当阈值α小于等于0.3时,由于特征聚合图建边的门槛太低,导致特征聚合过度,严重影响情感分类效果,分类结果没有参考意义; 2.阈值α从0.4到0.6,情感分类的准确率大致呈上升趋势,到0.6时达到相对峰值; 3.阈值α从0.6到1.0,情感分类准确率开始呈下降趋势,原因是图模型建边标准变高,导致图上节点过于分散,失去了特征聚合的效果,这也从另一个侧面说明特征拓扑聚合模型的有效性。
从图5得出结论: 1.无论特征值计算采用何种方法,情感分类准确率都随着主题数的增多而升高,主题数为150和200时,准确率达到相对峰值,主题数为200时比150时情感分类准确率稍高,但考虑时间效率,认为150是LDA主题数最佳选择;2.使用两种聚合特征值计算方法时,情感分类的准确率差异较小,说明特征值计算方法的选择对情感分类准确率影响不大。因为被聚合于同一点的情感特征本身关联度高,分布差异及原特征值差异较小。
表3、表4分别列出了特征拓扑聚合模型的情感分类与传统分类方法以及基于领域归属划分/上下文重构的情感分类性能对比情况,其中,“NB”和“SVM”分别代表使用朴素贝叶斯和SVM算法直接进行短文本情感分类,“Field”和“Context”分别代表使用基于领域归属划分和上下文重构的方法进行短文本情感分类,“COV”表示基于特征拓扑聚合模型的情感分类,表中加粗数字显示不同算法相同指标的最高者。发现: 1.经过情感特征拓扑聚合模型的处理,情感分类性能明显优于直接使用朴素贝叶斯和SVM算法进行短文本情感分类,分析: 虽然后面两种分类方法使用的训练语料数倍于所提方法,但训练语料较多反而使得短文本特征稀疏且分散带来的影响更加明显,使得传统情感分类方法很难摆脱这两点的困扰。相反,提出模型对特征的吸收与聚合效果得到体现;2.基于特征拓扑聚合模型的情感分类相比基于领域归属划分和上下文重构的方法准确率和召回率分别提高2.59%和2.55%,尤其是在微博领域上,算法的性能提升较明显,准确率和召回率分别提高7.21%和5.84%,分析: 微博语料比一般评论更短,用语更随意,特征更加稀疏且涵盖信息多而杂,导致领域及上下文类别界限较为模糊,不利于完全发挥大类归属重构算法的优势。
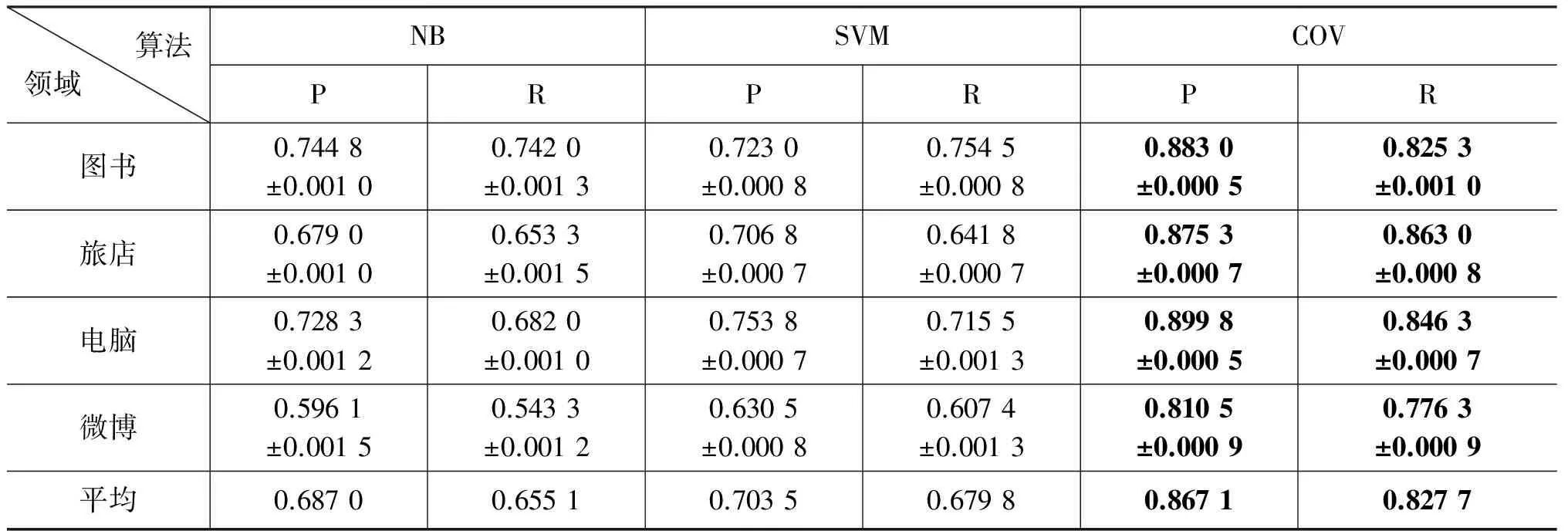
表3 对比传统方法分类实验结果
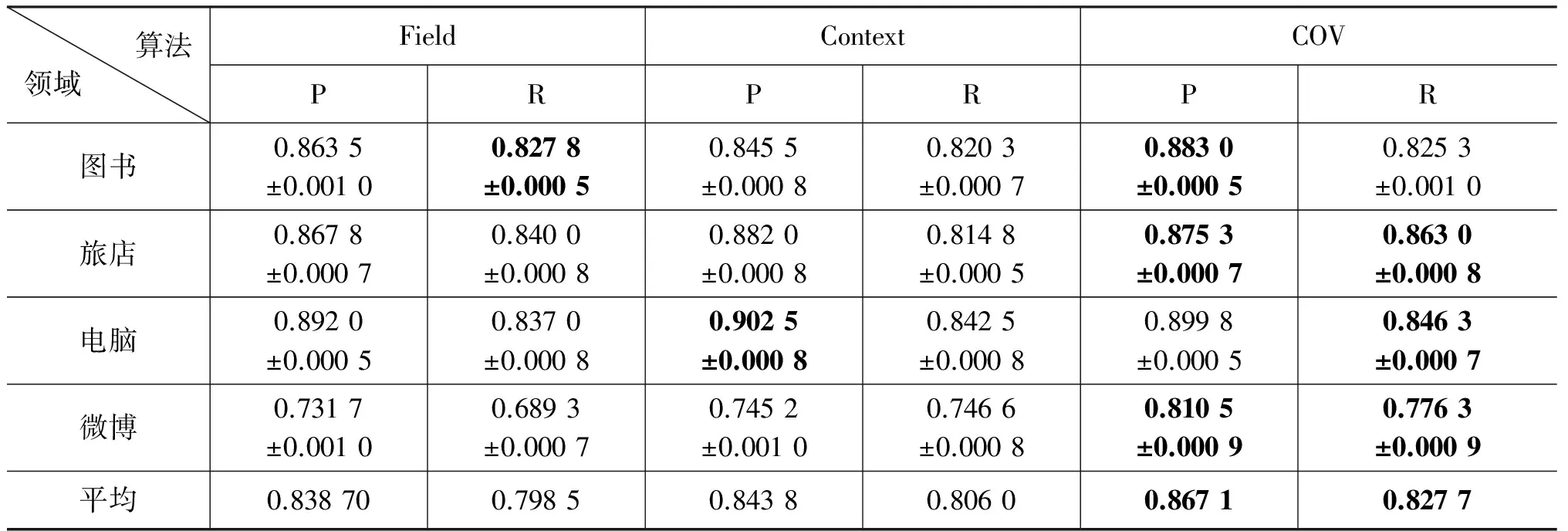
表4 对比领域归属及上下文重构分类实验结果
5 结语
提出一种面向短文本情感分类的情感特征拓扑聚合模型,从三个维度计算情感特征之间的关联度,并建立图模型,利用在图上的强联通分量求解将高相似度情感特征聚合,一方面从未标注语料集向训练集进行了特征补充,另一方面降低了监督学习训练模型的维度。实验将模型应用于包含短评论或微博文本的语料情感分类任务,得到了较好的效果。证明了方法在缓解短文本极稀疏性,特征分散等问题时的有效性。
目前基于深度神经网络的词嵌入学习(如: 词向量模型)及自动编码机等技术从深层的语义关系中挖掘特征间的相关性,未来计划借助此类技术改进模型的特征相关性计算方法,进一步提高特征吸收与聚合的质量,并将模型扩展至跨领域的情形。由于上述技术基于深度神经网络,在面对大规模语料时,还需探索保证算法时空效率的有效方法。
[1] ASitaram, A Huberman. Predicting the Future With Social Media[C]//Proceedings of ACM, 2010.
[2] Pang B, Lee L,Vaithyanathan S. Thumbs up? Sentiment classification using machine learning techniques[C]//Proceedings of EMNLP-02, 2002: 79-86.
[3] Ni XC,Xue GR, Ling X, Yu Y, Yang Q. Exploring in the weblog space by detecting informative and affective articles[C]//Proceedings of the 16th Int’l Conf. on World Wide Web. Banff: ACM Press, 2007: 281-290.
[4] Mullen T, Collier N. Sentiment analysis using support vector machines with diverse information sources[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Barcelona: Association for Computational Linguistics, 2004: 412-418.
[5] Whitelaw C, Garg N,Argamon S. Using appraisal groups for sentiment analysis[C]//Proceedings of the 14th ACM Int’l Conf. on Information and Knowledge Management. Bremen: ACM Press, 2005: 625-631.
[6] 肖永磊, 刘盛华, 刘悦, 等. 社会媒体短文本内容的语义概念关联和扩展[J]. 中文信息学报, 2014, 28(4): 21-28.
[7] 杨震, 赖英旭, 段立娟, 等. 基于上下文重构的短文本情感极性判别研究[J]. 自动化学报, 2012, 38(1): 55-67.
[8] Xia H, Nan S, Chao Z, et al. Exploiting internal and external semantics for the clustering of short texts using world knowledge[C]//Proceedings of the 18th ACM Conference on Information and Knowledge Management. Hong Kong: ACM, 2009: 919-928.
[9] HXianpei, S Le, Z Jun. Collective Entity Linking in Web Text: A Graph-Based Method[C]//Proceedings of the SIGIR, 2011.
[10] BSriram, David Fuhry, Engin Demir, et al. Short Text Classification in Twitter to Improve Information Filtering[C]//Proceedings of SIGIR’10. Geneva, Switzerland, 2010.
[11] Park H, Jeon M, Rosen J B. Lower dimensional representation of text data based on centroids and least squares[J]. Bit Numerical Mathematics, 2003, 43(2): 427-448.
[12] Xu W R, Liu D X,Guo J, et al. Supervised dual-PLSA for personalized SMS filtering[C]//Proceedings of the 5th Asia Information Retrieval Symposium on Information Retrieval Technology. Sapporo, Japan: Springer-Verlag, 2009, 254-264.
[13] 刘全超, 黄河燕, 冯冲. 基于多特征微博话题情感倾向性判定算法研究[J]. 中文信息学报, 2014, 28(4): 123-131.
[14] 王蒙, 林兰芬, 王锋. 基于伪相关反馈的短文本扩展与分类[J]. 浙江大学学报(工学版), 2014, 48(10): 1835-1842.
[15] 桂斌,杨小平,朱建林等.基于意群划分的中文微博情感倾向分析研究[J].中文信息学报,2015,29(3): 100-105.
[16] Turney P D. Thumbs up or thumbs down?: semantic orientation applied to unsupervised classification of reviews[C]//Proceedings of the 40th annual meeting on association for computational linguistics. Association for Computational Linguistics, 2002: 417-424.
[17] 李素科, 蒋严冰, 基于情感特征聚类的半监督情感分类[J]. 计算机研究与发展, 2013, 50(12): 2570-2577.
[18] 程南昌, 侯敏, 滕永林. 基于文本特征的短文本倾向性分析研究[J]. 中文信息学报, 2015, 29(2): 163-169.
[19] 高凯,李思雨,阮冬茹等.基于微博的情感倾向性分析方法研究[J].中文信息学报,2015,29(4): 40-49.
[20] Turney P, Littman M L. Measuring praise and criticism: Inference of semantic orientation from association [J]. ACM Transansaction on Information Systems, 2003, 21(4): 315-346.
[21] Blei D M, Ng A Y, Jordan M I. Latent Dirichlet allocation [J]. Journal of Machine Learning Research, 2003, 3(3): 993-1022.
[22] Gabow H N. Path-based depth-first search for strong and biconnected components[J]. Information Processing Letters, 2000: 107-114.
[23] Kullback S, Leibler R A. On information and sufficiency [J]. Annals of Mathematical Statistics, 1951, 22(1): 79-86.
Feature Polymeric Topology Model for Short-Text Sentiment Classification
HU Yang1,FENG Xupeng2,HUANG Qingsong1,3,FU Xiaodong1,LIU Li1,LIU Lijun1
(1. Faculty of Information Engineering and Automation, Kunming University of Science and Technology, Kunming,Yunnan 650500,China; 2. Educational Technology and Network Center, Kunming University of Science and Technology, Kunming,Yunnan 650500,China;3. Yunnan Key Laboratory of Computer Technology Applications, Kunming,Yunnan 650500,China)
Short-text has some peculiarities: extreme sparsity, disperse features and so on, which leads to inferior sentiment classification on short-text. To solve this problem, we propose the feature polymeric topology model for short-text sentiment classification. The model integrates mutual information among features, similarity of sentiment orientation and topic ascription difference into the sentiment features correlation. Then this correlation is employed to establish topology polymeric graph, in which the strongly connected components are assumed as the most similar sentiment features. Finally, the polymeric topology model supplements the training feature set with similar features from the unlabeled corpora, and reduces dimension of training space at same time. In experiment,the proposed model can improve the presicion and recall by 0.03 and 0.027, respectively.
short-text; sentiment classification; features correlation; strongly connected components; topological polymerization

胡杨(1991—),硕士研究生,主要研究领域为机器学习、文本情感分类。E⁃mail:superhy199148@hotmail.com冯旭鹏(1986—),硕士,实验师,主要研究领域为信息检索、自然语言处理。E⁃mail:fxpflybird@hotmail.com黄青松(1962—),通信作者,硕士,教授,主要研究领域为机器学习、数据挖掘、智能信息系统。E⁃mail:kmustailab@hotmail.com
1003-0077(2016)05-0028-08
2015-08-19 定稿日期: 2016-02-03
国家自然科学基金(81360230, 61462056, 61462051)
TP391
A
