奥巴马竞选视频“抉择”的多模态批评话语分析
2015-07-18孙富强李健雪
○ 孙富强 李健雪
(江南大学 外国语学院,江苏 无锡 214122)
奥巴马竞选视频“抉择”的多模态批评话语分析
○ 孙富强 李健雪
(江南大学 外国语学院,江苏 无锡 214122)
多模态批评话语分析(Multimodal Critical Discourse Analysis,简称MCDA)主张图像、照片、图表等也能像语言文字一样表达内涵,用来揭示隐藏在图像或文字背后的权力关系。文章以多模态批评话语分析为理论依据,结合Kress & van Leeuwen的视觉语法,从语言模态的词频和情态、视觉模态的视觉呈现策略和图文关系三个层面对2012年奥巴马竞选视频“抉择”进行解读。研究表明两种模态共同作用,在视频观看者的潜意识中构建了奥巴马良好的政治形象,实现了对视频观看者意识的操纵和控制。
多模态批评话语分析; 奥巴马; 语言; 意识
批评话语分析(CDA)兴起于20世纪70年代,是一种通过语言学分析,揭示语篇中隐含的意识形态及权力关系的语言学研究范式。CDA 以揭示语篇中隐含着的某种为权力服务的意识形态为己任,旨在探索社会的不平等现象在话语中的反映。[1]57-60随着科学技术的不断发展、多媒体和互联网络的广泛使用,人们的交流发生了巨大的变化,信息已不再是以单一的文本形式呈现,而是与图像、色彩、声音、动画等其它非语言符号共同呈现,单一研究语言已经不能对话语进行深入全面的分析和研究。[2]131-1352012年由David Machin 和Andrea Mayr 提出的MCDA,则可以在很大程度上帮助人们突破这些局限性。MCDA突破了CDA仅关注语言模态的局限性,认为图像、照片、图表等也能表达意义。Machin and Mayr认为,MCDA的任务是借用其理论工具通过详尽的描述过程,识别和揭示其符号的选择。[3]视觉符号和语言一样,塑造社会的同时也被社会所塑造。因此,MCDA不仅对视觉符号的选择感兴趣,而且也关注它们在社会权力关系交际中所起到的作用。
2012年奥巴马竞选视频“抉择”中存在诸如言语、视觉、听觉等多种模态,是一则多模态视频语料,本文以MCDA理论为视角,以竞选视频“抉择”中的视觉和语言模态为研究对象,通过定量和定性的方法,探究竞选视频中存在的语言、权利和意识的关系。
一、研究设计
(一)研究问题
本文接受Halliday 的系统功能语法和Kress & van Leeuwen的视觉语法理论,借用Machin & Mayr (2012) 的多模态批评话语分析方法和分析工具,以2012年奥巴马竞选视频“抉择”为例,探讨视频中的语言模态和视觉模态是如何共同作用实现对视频观看者意识的操纵和控制的?即两种模态是如何构建奥巴马的政治的形象,从而影响民众意识的?
(二)研究步骤
依据研究目的和研究问题,研究步骤可分为三步:
第一步,从视频中提取奥巴马所说的话语,建成小型语料库,用Antconc 3.2.4分析语言模态的词频和情态。
第二步,用视频分析工具ELAN分析视觉模态的视觉呈现策略(gazes, angle, individualization, collectivization and distance)。
第三步,用ELAN分析并标注视频中语言模态和视觉模态(即文字和图像)的关系。
二、结果与讨论
(一)“抉择”中语言模态的分析
1.词频统计。词频统计是语料库检索最基本的统计方法,研究者可以直观地观察到语言的显著特征,通过观察词语出现的频率,得出这一语料(语篇)的主旨或其主要内容。[4]130-133通过Antconc 3.2.4的检索,得出出现频率较高的10个词,分别是the (9次)、to(6次)、a (4次)、and(4次)、can (4次)、choice(3次)、I(3次)、is(3次)、our(3次)和 we (3次)。除can、choice和is是实词外,其他都是功能词。这些功能词由于主要表达语法意义并且数量有限,几乎在任何语料库中频数都很高,与功能词不同,英语中实词指的是具有实际意义,能够独立承担句子成分的词,因此往往在句中传达重要的语义信息。为了更好地观察语料信息,除上述三个出现频率较高的实词外,对其它实词也进行统计,分别是class(2次)、economy(2次)、pay(2次)、politics(2次)、plan(2次)、education(1次)和job(1次)。通过对高频实词的索引分析,该语料所要表达的观点,以及其隐藏的权利和意识关系也清晰地浮现出来。面对2012年总统大选,奥巴马想战胜罗姆尼连任总统。他在这则竞选视频中围绕“抉择(choice)”这一核心词,阐述了民众选择总统,不仅仅是在两个人或政党间进行选择,更重要的是选择两个完全不同的建设国家的政策。奥巴马在此批判了罗姆尼的经济政策,反而主张壮大中层阶级(Middle Class),从而可以加大对教育和基础建设的投入,增加工作岗位。通过对高频实词的分析,我们了解到奥巴马利用有力的话语权,成功地塑造了自己有能力有作为的政治形象,清晰地阐述了自己的政治主张,从而在竞选中使自己处于有利地位。
2.情态分析。研究语篇的情态功能主要目的在于弄清说话者对听话者和情景成分的观点、说话者与听话者之间的社会距离和权力关系;明晰说话者对话语命题真实性所担负的责任和对未来行为做出的承诺和承担的义务。在英语里,表达情态意义的除了情态动词、情态形容词和情态副词外,还有直接引语、间接引语、人称代词、时态。[5]
1)情态动词的使用。系统功能语言学认为,情态是说话人对某个命题或提议的态度、看法,表现说话人的意愿或判断。情态本身也有等级之分。通过对情态的高、中、低量值的区分,可以看出说话者语气的轻重(如表1)。
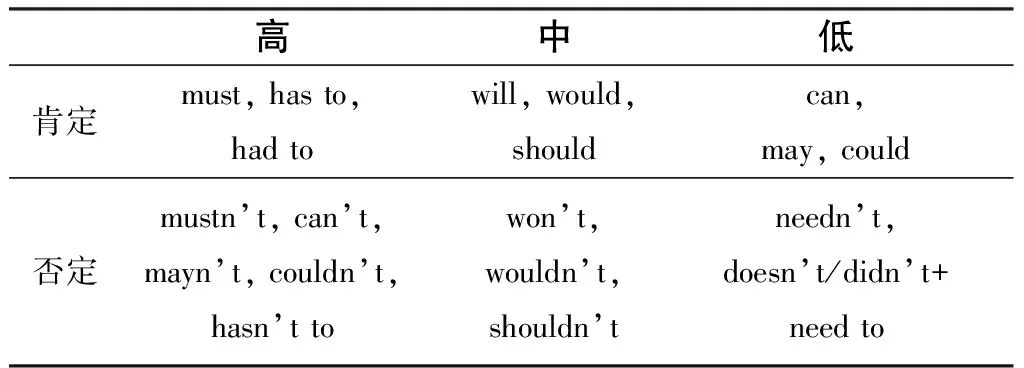
表1 情态词量值分布
通过Antconc 3.2.4的检索,统计出奥巴马使用较多的情态动词是can(3次), would(1次), will(2次)和couldn’t(1次)。其中低情态动词和中情态动词各使用了3次,各占全文情态动词的3/7;高情态动词使用了1次,占全文情态动词的1/7。这是一则竞选视频,主要目的是为了争取更多的民众支持。奥巴马使用较多的中情态动词可以使自己的主张不带有强制的色彩,使信息更容易被听众所接受,从而增加了信息被听众认可的机会,也可以避免遭受听众的批评和挑战。另外,在中情态动词中will(表示预测)使用了2次。这是奥巴马对前途所作出的主观判断,也是对美国民众的一种承诺和担当,以此来影响民众,让他们感觉美国明天的任务很艰巨,支持新总统的工作显得十分必要。高情态动词只使用了1次,但奥巴马强调了这一“抉择”(choice)看似很简单,却关乎国家的未来,需谨慎选择。同时,“couldn’t”也传达出一种强制的态度,这样总统话语权的权威化也表现得更加清楚了。
2)人称代词的使用。这则视频中使用了许多人称代词,如I, our, we等,we和our各使用了3次。以人称代词we为例分析其在视频中的作用。
A. If we do our economy will grow and everyone will benefit.
B. We tried that top-down approach.
C. We can afford to invest in education, manufacturing…
第一句中的we显然是指美国民众,第二句和第三句中we显然是指美国政府及其工作人员。奥巴马在此使用we的效果是使人感觉到奥巴马及新政府和民众是一个整体,不知不觉之间全体美国人民已成为新政府的同盟军、自家人。
奥巴马在竞选视频中使用如此多的人称代词,就是为了塑造自己代表民众利益的政治形象,从而为大选的胜利争取更多民众支持。
(二)“抉择”中视觉模态的分析
随着科技的不断发展,尤其是互联网的广泛应用,人类的交流方式发生了巨大变化,信息已不是仅靠语言模态来呈现,图像和声音等非语言模态也能呈现信息,构建意义。在奥巴马的竞选视频中,图像中包含的各个元素(如gaze, angle, distance等)也发挥着构建意义,建构人物社会关系的重要作用。利用视频分析工具ELAN对竞选视频的视觉呈现策略进行处理,得出数据如表2:
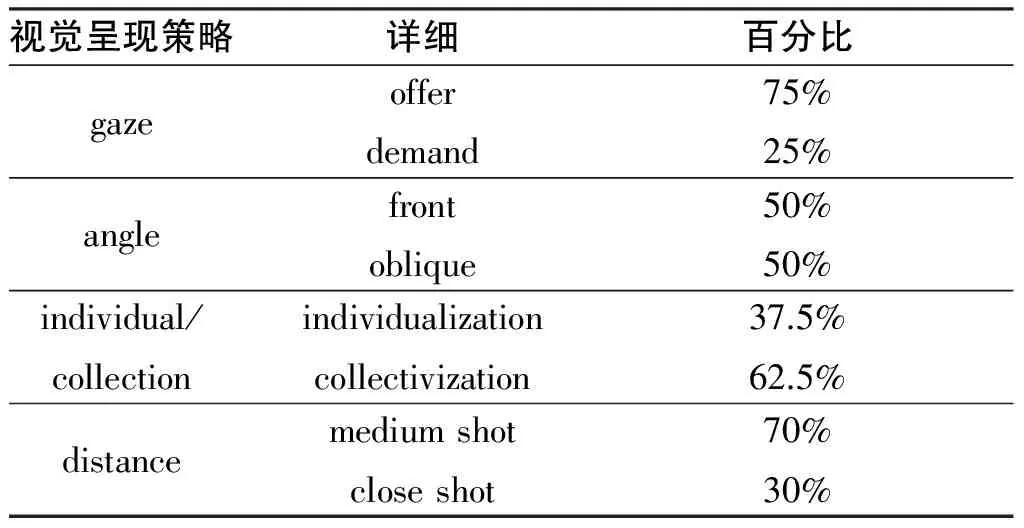
表2 视觉呈现策略
视觉语法认为图像中的参与者(通常是具有生命特征的人或动物)通过目光与图像的观看者可以建立一种想象的人际关系,并将图像的视觉接触依据原则:如果参与者直视观看者,属于“索取”(demand)类图像;反之,则是“提供”(offer)类图像。奥巴马的竞选视频中提供类图像占75%,视频观看者与视频参与者目光并没有直接接触,而是更多的为观看者提供信息,通过三个独立镜头,展现出奥巴马对于教育、生产和能源的关注,传递奥巴马的执政方针,符合竞选视频的宣传功能;而索取类图像则占25%,如图1所示:观看者直接与奥巴马目光接触,形成了奥巴马和视频观看者的一种互动关系,似乎在向观看者发出一种邀请,参与到奥巴马为应对经济危机的所采取的行动中,存在想象中的人际关系。

图1
Kress & van Leeuwen认为可以通过“视角”(angle)来表达达对图像参与者的不同态度,一般采用正面(front)视角和垂直(oblique)视角。奥巴马的竞选视频中采用了等量的两种视角。正面视角(如图1)带给视频观看者一种身临其境的感觉,似乎奥巴马正面与“你”面对面聊天,阐述他的执政方针。这一视角的好处是使得民众更加容易接受奥巴马的改革策略。竞选视频采用的垂直视角中更多的是平视视角,这使得奥巴马与观看者建立了一种平等的人际关系,似乎奥巴马是在与朋友交流,而不是强硬的让人接受他的观点。
Machin & Mayr 认为图像中的参与者可以被描述为独立的“个体”(individualization) 或者是“群体” (collectivization)。当参与者以群体的形象出现在图像中时,他们给人一种感觉即他们似乎一样或者你无法区分他们。这样的图像设计使得参与者融入一个集体中,不分彼此,加重观看者的参与效果。正如奥巴马的竞选视频中,collectivization占
62.5%。这给予视频观看者一种印象即奥巴马与民同甘共苦,他是众多美国公民之一也是广大民众的利益代表,从而增加奥巴马的亲民形象,争取更多的选票。
如同人与人之间的社会关系取决于距离,图像镜头取景的框架尺寸也会体现参与者与观看者之间的亲疏关系,大体分为三种:肩部以上为近距离,即近景;腰部以上为中距离,即中景;整个人并且周围有空间环绕为远距离,即远景。奥巴马的竞选视频中中景占70%,近景占30%。这30%的近景皆为奥巴马一个人的镜头(如图1),从而营造出奥巴马和视频观看者的社会近距离,一种亲近的关系,似乎奥巴马就在“你”眼前,亲切交谈。而70%的中景叙述的是奥巴马与民众、政府工作人员一种即亲近又存在一定距离的效果,符合一位国家领导人应有的权威和亲民形象。
(三)“抉择”中文字与图像的关系
法国符号学家Barthes作为图文关系研究的代表人物,他认为图文之间存在三种关系:固定(anchorage)、说明(illustration)和接递(relay)。[6]“固定”指文字可以克服模糊的图像意义,即文字阐释图像;“说明”指图像支持文字实现语篇,即图像阐释文字;“接递”则指图像文字间的相互补充。利用ELAN对奥巴马竞选视频进行标注,得出图文关系为:接递占50%,说明占37.5%,固定占12.5%。由此可知,竞选视频中以图文互补关系为主,图像和文字(即语言模态和视觉模态)相互补充,共同完成一个目的即利用两种模态的相互合作塑造奥巴马的有作为、有能力和亲民的政治形象,以争取美国民众的支持,在总统大选中取得胜利,实现连任。
三、结 语
研究表明,视频中的语言模态以高频词class、economy和politics等点明语篇的核心内容,结合中情态词的辅助构建了奥巴马有能力,有作为的政治形象;视觉模态则以视觉呈现策略构建了奥巴马亲民又有总统权威的政治形象;语言和视觉两种模态相互作用,在视频观看者的潜意识中构建了奥巴马良好的政治形象,从而争取更多选票,实现连任。本研究有助于加深对竞选类视频广告的解读,同时也有助于提高对人们对于视频广告鉴别能力。
[1]陈云,李洁.王熙凤话语权力的批评话语分析[J].湖南工业职业技术学院学报,2014(3).
[2]仲夏阳,孙志祥.公寓广告中意识形态渗透手段的多模态批评性话语分析[J].西南政法大学学报,2011(5).
[3]Machin, D., A. Mayr. 2012. How to Do Critical Discourse Analysis: A Multimodal Introduction[M].London: Sage.
[4]张淑静.语料库在批评话语分析中的应用[J].郑州大学学报(哲学社会科学版),2014(3).
[5]辛斌.批评语言学: 理论与应用[M].上海外语教育出版社,2005.
[6]Barthes, R. 1977. Image-Music-Text[M].Glasgow: Fontana.
孙富强,男,山东省茌平县人,江南大学外国语学院硕士研究生;
李健雪,男,江苏昆山人,江南大学外国语学院教授,研究方向:应用语言学、功能语言学。
H313
A
1672-8610(2015)06-0021-03
