基于C#的Apriori算法的实现及其改进策略
2015-06-15董袁泉
董袁泉
(沙洲职业工学院,江苏 张家港 215600)
数据挖掘是从大量数据中提取或“挖掘”知识.它是根据人们的特定要求,从大量的数据中找出所需的信息.关联规则挖掘就是发现信息存储中的大量数据项之间隐藏的、有趣的规律[1].Apriori算法是最经典的关联规则算法,该算法的主要思想是采用逐层迭代的方法通过低维频繁项集得到高维频繁项集.但是Apri⁃ori算法在实际应用中,还存在不令人满意的地方,可能产生大量的候选集以及需要重复扫描数据库.因此,本文提出了一种基于矩阵的关联规则挖掘算法,通过扫描一次数据库得到所有数据信息,利用布尔矩阵的相关性质对候选项集的支持度进行计数并引入了向量内积的思想,在自然连接以前先进行一个修剪过程,减少参加连接的项集数量,减小生成的候选项集规模,减少了循环迭代次数和运行时间,同时在连接判断步骤中减少多余的判断次数,从而大大提高了算法的性能.
1 关联规则Apriori算法概述
1.1 关联规则定义
假设I是项的集合.给定一个交易数据库D,其中每个事务(Transaction)t是I的非空子集,每一个交易都与一个唯一的标识符TID[2](Transaction ID)对应.关联规则在D中的支持度(support)是D中事务同时包含X、Y的百分比,即概率;置信度(confidence)是包含X的事务中同时又包含Y的百分比,即条件概率.如果满足最小支持度阈值和最小置信度阈值.这些阈值根据挖掘需要人为设定.
1.2 Apriori算法的基本思想
Apriori算法[3]是一种最有影响的挖掘布尔关联规则频繁项集的算法.在该算法中,所有支持度大于最小支持度的项集称为频繁项集,简称频集.该算法的核心思想描述如下:
(1)L1=find_frequent_1-itemsets(D);
(2)for(k=2;Lk-1≠∅;k++){
(3)Ck=apriori-gen(Lk-1,min_sup);
(4)for each transaction t∊D{
(5)Ct=subset(Ck,t);
(6)for each candidate c∊Ct
(7)c.count++;
(8)}
(9)Lk={c∊Ck|c.count≥min_sup}
(10)}
(11)return L=ULk;
1.3 Apriori算法的缺点
Apriori算法利用逐层搜索的迭代方法来寻找频繁项集,用k-项集探索(k+1)-项集.首先产生频繁1-项集L1,然后是频繁2-项集L2,如此下去,直到不能找到频繁k-项集[4].可能产生大量的候选集以及需要重复扫描数据库,是Apriori算法的两大缺点.
2 Apriori算法的C#实现
Apriori算法可以有多种实现方式,比较常见的有C语言和Java实现的方式,本文利用C#语言实现Aprio⁃ri算法.在主程序中主要实现了以下5个步骤,分别完成如下功能:
1、由指定的CommandString从数据库中获得数据
2、从数据库中获得事务集
3、从数据库中得到候选一项集
4、生成候选项集
5、用Apriori算法进行迭代
具体测试时采用SQL Server 2008中的Adventure⁃WorksDW数据库中的视图vAssocSeqOrders和vAssocSe⁃qLineItems来生成事务集,包含2个字段OrderNumber(订单号)和Model(购买产品型号),共有21255条记录;测试时最小支持度sup设定为0.05即最小支持数为21255*0.05=1063,程序运行结果见图1,结果中输出了频繁项集和支持数.其中支持数最小的1083,大于程序中设定的1063,证明了程序的正确性.
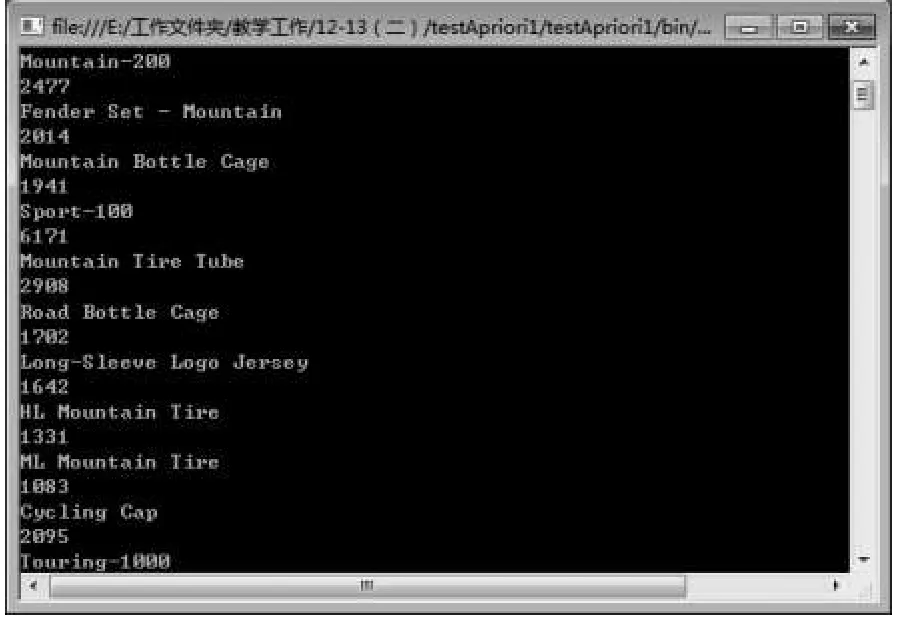
图1 程序运行结果
3 Apriori算法的改进
3.1 相关定义和推论
设I={i1,i2,i3…,in}是项的集合,数据库D是数据库事务的交易集合,每个事务T是相关项的集合,T⊆I,用Tm表示其中的每个事务[5].
定义1一个矩阵中的所有元素均为0或者1.
定义2[5]每个项Ij的向量定义为其中Ti为第i个事务,
定义3D转换为矩阵G的每一个元素{Aij}定义为
其中i=l,2,3…,m,j=l,2,3…,n.具体实例如下:设有项目I={A,B,C,D,E,F},交易数据库为t1={A,B,C},t2={A,C,E},t3={A,C,E,F},t4={A,B,C,D,E},t5={B,C,D,F}. 生成的布尔矩阵为:

并且使用列向量Ri来表示项集I的一个项目,每一个行向量表示一个交易记录.
定义4[6]:布尔矩阵中,每一项Ri的向量定义[7]为=Ri(t1i,t2i…,tni),supp(Ri)表示算法中该向量的支持度:supp(Ri)=t1i+t2+…+tni.例如上例中项目B的支持数为supp(B)=1+0+0+1+1=3.
定义5:向量内积<Ri,Rj,>表示为布尔矩阵中项集{Ri,Rj}的向量内积,<Ri,Rj>=supp(Rij)=t1i×t1j+t2i×t2j+…+tni×tnj.supp(Rij)代表布尔矩阵中项集{Ri,Rj}的支持度,表示所有事务同时出现Ri和Rj的事务记录的个数.
性质1[5]:定义Lk表示为Lk中包含j的频繁项集的个数,如果<k,若k-项集X={i1,i2,…ik}中存在一个项j∊X,则在频繁k-项集产生(k+1)-项候选集时,可以把该数据裁剪掉.
证明设X是(k+1)-项频繁集,则它的k+1个k-子集均在Lk中.则在生成的k+1个k-子集中,每一个项目j∈X共出现k次,∀j∈X,均有>k.因此,如果出现<k,不可能产生(k+1)-项集.
3.2 基于布尔矩阵和向量内积的MV-Apriori算法
由于Apriori算法可能产生大量的候选集以及需要重复扫描数据库,本文提出了一种基于布尔矩阵和向量内积的关联规则挖掘算法MV-Apriori(Association Rule Mining Algorithm Based on Boolean-matrix and Vector-inner-product),该算法步骤如下:
(1)扫描事务数据库生成布尔矩阵,布尔矩阵的各个元素的值按照上述定义1和定义3求得,然后通过统计项目的支持数计算得到频繁1-项集.
(2)利用频繁1-项集连接生成候选2-项集,构造一个2维布尔行向量S2,S2中所有元素均为1,然后将候选2-项集组成的向量集与S2进行内积运算,得到候选项集支持数.
下面以实例说明说明具体的运算方法,首先将一个2-项候选集所代表的2个列向量根据定义2表示为m行2列的向量:,(其中 k<j).
S2与该向量的每一行(记为Hi)与进行内积运算,根据前面的思想选取布尔向量S2=(1 1),Hi=(1 1)表示两个项目均在同一事务i中出现,表示该2-项候选集有一项支持计数,引入一个算式int来得到这次计数,其中int[]表示取整数,<,>表示内积运算.由于Hk,j是m行2列的向量,所以需要它进行m次内积运算,引入公式表示该2-项候选集与2维布尔行向量内积运算得到的2-项集的支持计数.通过与最小支持度比较,得到频繁2-项集.
(3)对项集中出现的其他项目同样进行计数,然后对频繁2-项集进行一次裁剪,根据性质1,如果某个项目在2-项集的支持计数小于2,则裁剪掉包含该项目的所有频繁2-项集,从而得到新的频繁2-项集,这样就可以大大减少3-候选集的数目,因为3-项候选集是由频繁2-项集连接生成的.
(4)构造三维布尔行向量与候选3-项集进行内积,计算得到3-项集的计数,如果某个项目在3-项集的支持计数小于3,则进行裁剪生成频繁3-项集;如果要生成k项候选集,则首先对k-1频繁项集进行裁剪,然后构造k维行向量Sk,k-项候选集的支持计数为:然后裁剪得到k-项频繁集.
3.3 MV-Apriori算法的描述
假设最小支持度记为min_supp,事务交易数据库记为D;那么最小支持数minsupp_count=|D|*min_supp),.根据上面的分析,MV-Apriori算法和Apriori算法相比,增加了如下过程:
(1)把交易数据库D转换为布尔矩阵G.
(2)构造K维布尔向量,与候选K-项集进行内积运算,并求得支持计数.
(3)把支持计数与最小支持度相比进行裁剪,求出K-项频繁集.
具体算法过程及其伪代码描述如下:


3.4 MV-Apriori算法的实例说明
假设有如下事务数据库(见表1),其中包含事务标识T以及项目Item.
该事务数据库 D包含共10个事务(T1,T2,…,T10),6个项目(A,B,C,D,E,F),假设最小支持度为30%,那么最小支持数为0.3*10=3.根据MV-Apriori算法,得到如图2所示的图例说明.最后输出频繁项集为L={B,C,D,E,F,BC,BE,BF,CE,CF,DE,EF,BEF,CEF}.

表1 事务数据库
3.5 MV-Apriori算法分析
MV-Apriori算法的主要优点在于:
1.在生成k-候选项集之前,对Lk-1频繁项集中参与组合的元素进行计数处理,然后进行优化裁剪,这就降低了组合的可能性.如果对大型的数据库而言,这种时间开销的降低对数据挖掘效率来说是显而易见的,MV-Apriori算法只扫描数据库一次,时间复杂度为O(mkn)[8],其中mxn对应于矩阵的行数和列数,k为频集的阶数.而Apriori算法扫描数据库的时间复杂度为O(|D|k+1),|D|>>m.
2.MV-Apriori算法对数据库进行了扫描后的重新生成“删除”一些不支持频繁项集的记录,这里所谓的删除实际上是把不符合再次扫描比较条件的记录与数据库末端的记录进行交换,这会增加一些时间和I/O的开销,但是随着循环次数的增加,本算法对以后通过扫描“新的数据库”中产生频繁项集的优势将体现出来,因为“新的数据库”记录将呈现几何级数的降低.
本文采用SQL Server 2008中的AdventureWorksDW数据库中的视图vAssocSeqOrders和vAssocSeqLin⁃eItems来生成模拟数据,在Windows7(Intel(R)Core(TM)i3-2330M CPU2.2GHZ、内存为2GB)平台、SQL Serv⁃er2008和VS2010的环境下进行仿真.MV-Apriori算法与Apriori算法在不同的支持度下找出所有的频繁项集所用时间的对比如图3所示.其中横坐标表示支持度的阈值(100%),纵坐标表示所用的时间(s).

图2 MV-Apriori算法裁剪生成频繁项集过程
从图3可以看到在支持度不同时两种算法的执行时间差别,优化后的MV-Aprior算法在执行时间上优于Apriori算法,MV-Aprior在对Lk-1连接生成CK之前进行了修剪,通过计数删除掉了包含出现次数小于k-1的项目集,这样排除了不可能成为k项集的元素,减少了下一步CK中侯选项集的数量;在支持度越小的情况下,这种优势更加明显,这表明了MV-Aprior算法比Apriori算法有更好的效率.在支持度变大的情况下,该数据集的项集规模将逐渐变小,但MV-Aprior的效率仍然优于Apriori算法.

图3 两种算法找频繁项集时间对比
4 结束语
Apriori算法是关联规则中的经典算法,文中主要对Apriori算法进行研究分析之后,采用C#语言对算法进行了实现.在分析了Apriori算法的基础上,指出了Apriori算法的局限性,提出了新的MV-Apriori改进算法.改进的算法在每次生成候选项集之后,删除其中没有用的项集,可以大大减少下一步接连生成的项集数量,从而减少数据库扫描次数,节省算法过程所需的存储空间,减少运算时间.仿真结果也表明,采用改进后的Apriori算法可以使扫描次数减少大概一半,当数据库规模非常大时,扫描和比较时间的缩减将更加明显,这将对提高关联规则挖掘的效率起到积极作用.
[1]邵峰晶,于忠清.数据挖掘原理与算法[M].北京:科学出版社,2009:12.
[2]屈世富、万旺根、刘维晓.一种改进的关联规则挖掘算法[J].计算机科学,2010,37(7A):199-202.
[3]AGRWALR,SRIKANR.Fast algorithms for mining association rules in large databases[C].Chile:Santiago,1994:487-499.
[4]徐嘉莉.一种基于矩阵压缩的Apriori优化算法[J].微计算机信息,2009,25(12):213-215.
[5]李唐平.基于矩阵的关联规则算法与Apr1ori算法的研究及改进[D].成都:西南交通大学,2009.
[6]李超,余昭平.基于矩阵的Apriori算法改进[J].计算机工程,2006,32(23):68-69.
[7]王培吉,王培静,白金牛.关联规则挖掘的一种改进算法[J].包头钢铁学院学报,2003,22(1):86-89.
[8]苗苗苗,王玉英.基于矩阵压缩的Apriori算法改进的研究[J].计算机工程与应用,2013,49(1):159-162.
