一种垂直结构的高效用项集挖掘算法
2017-09-20黄坤,吴玉佳
黄 坤, 吴 玉 佳
( 1.中国舰船研究设计中心, 湖北 武汉 430064;2.武汉大学 计算机学院, 湖北 武汉 430072 )
一种垂直结构的高效用项集挖掘算法
黄 坤*1, 吴 玉 佳2
( 1.中国舰船研究设计中心, 湖北 武汉 430064;2.武汉大学 计算机学院, 湖北 武汉 430072 )
挖掘高效用项集已成为关联分析中的热点问题之一.多数高效用项集挖掘算法需要产生大量的候选项集,影响了算法性能.HUI-Miner是一个不需要产生候选项集就能发现事务数据库中所有高效用项集的算法.但其需要产生大量效用列表,不仅消耗了过多的存储空间,而且影响了算法的运行性能.针对此问题,提出一个新的数据结构,称为项集列表,用于存储事务和项的效用信息.提出3种剪枝策略,减少项集列表的数量,通过扫描一次事务数据库完成所有项集列表的构建.提出算法MHUI,直接从项集列表中挖掘所有的高效用项集而不产生任何候选项集.在3个不同的稀疏数据集上和最新的算法进行对比实验证明,MHUI算法的运行时间和内存消耗优于其他算法.
数据挖掘;关联分析;频繁项集;高效用项集
0 引 言
数据挖掘中的一个重要任务是关联分析.关联分析的应用非常广泛,它一般分为两个步骤:第一,从数据库中挖掘频繁项集;第二,发现关联规则.第二个步骤通常较为简单,所以,大多数学者都将研究重点放在第一个步骤上面[1-3].在频繁项集挖掘算法中,Agrawal等[1]提出的Apriori算法是此领域的开创性算法,其特点是简单、易实现,不足之处是需要多次扫描数据库,这影响了算法的性能.Han等[2]在随后提出了FP-Growth算法用于挖掘频繁项集,这是一种基于树结构的算法.FP-Growth算法通过扫描数据库将所有的信息存储到一个FP-Tree上,它的性能大大超过了Apriori,因为它寻找频繁项集时不需要产生任何候选项集.Zaki[3]提出一种基于垂直数据结构的频繁项集挖掘算法Eclat,将事务信息存储到列表上,通过对列表的交集运算,能非常快实现对支持度计数以及产生频繁项集.
然而,在这些频繁项集挖掘的框架中,没有考虑项在事务中的数量以及项的重要性(如单位利润、价格、重要性等).在实际应用中,利益最大化对于销售经理来说是一个非常有吸引力的问题.因此,挖掘高效用项集迅速成为数据挖掘领域中的一个研究热点问题.但是,在频繁项集挖掘中,多数算法使用了向下闭性质[1-3],即如果一个项集是非频繁的,则它的超集都是非频繁的.利用此性质能大大减少计算量并降低内存消耗.但是这个性质在高效用项集挖掘中却不能直接使用.因此,这个问题给高效用项集挖掘带来了一个巨大挑战.
鉴于此,一些算法使用估计效用上界的方法来对搜索空间进行剪枝,以提高效用项集挖掘的性能.Liu等[4]提出Two-Phase算法,算法通过两个阶段来确定高效用项集.Yao等[5]提出了UMining算法,使用一种估计方法来减少搜索空间.Li等[6]提出一个孤立项丢弃策略,用于减少候选项集的数量.虽然所有的高效用项集都能够被发现,但这些方法经常会产生大量的候选项集[4-11],并且需要多次扫描数据库.
Ahmed等[7]提出一个基于树结构的算法IHUP用于挖掘高效用项集,获得了比IIDS和Two-Phase更好的性能.Tseng等提出了UP-Growth 算法[8]和UP-Growth+算法[9],减少候选项集的数量,从而提高算法的性能.此外,Wu等[10]和Tseng等[11]也提出了先挖掘闭项集的方式来挖掘完全高效用项集,取得了较好的效果.Liu等[12]提出一种全新的用于挖掘高效用项集的算法HUI-Miner.HUI-Miner不需要产生候选项集,而是直接产生高效用项集.首先产生一系列称为效用列表的数据结构,用于存储项集的事务信息、项的效用信息以及高估效用信息(剩余效用).通过扫描效用列表的方式生成所有的高效用项集,而这一过程不需要产生任何候选项集,HUI-Miner算法在运行时间和内存消耗上都优于上述算法.
HUI-Miner算法产生高效用项集可以分为两个步骤:首先,将数据信息存储到效用列表上;然后再从效用列表上计算得到高效用项集.而HUI-Miner产生的效用列表数量较多,消耗了存储空间并影响算法运行性能.此外,由于该算法在效用列表中不仅存储了项集的事务和效用信息,也存储了用于对搜索空间进行剪枝的额外的剩余效用信息,这也降低了挖掘性能并占用了更多的内存资源.针对上述问题,本文提出一个新的数据结构和一个挖掘算法MHUI,以有效地挖掘高效用项集.
1 问题定义
给定一个有限的一组项I={i1,i2,…,im},其中每个项ip(1≤p≤m)都有一个利润值p(ip).一个项集X由k个项{i1,i2,…,ik}组成,ij∈I,1≤j≤k,k是项集X的长度.长度为k的项集称为k-项集.一个事务数据库D={T1,T2,…,Tn},包含一组事务.其中,每一个事务Td(1≤d≤n)都是I的一个子集,具有一个唯一的标识符Td.每个事务Td中的一个项ip具有一个数量q(ip,Td).
定义1项ip在事务Td中的效用u(ip,Td),定义为u(ip,Td)=p(ip)×q(ip,Td).
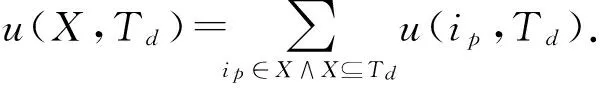

定义4给定项集X及用户指定最小效用阈值minutl,若u(X)≥minutl,则称X为高效用项集.
定义5事务Td的事务效用记为TU(Td),定义为u(Td,Td).

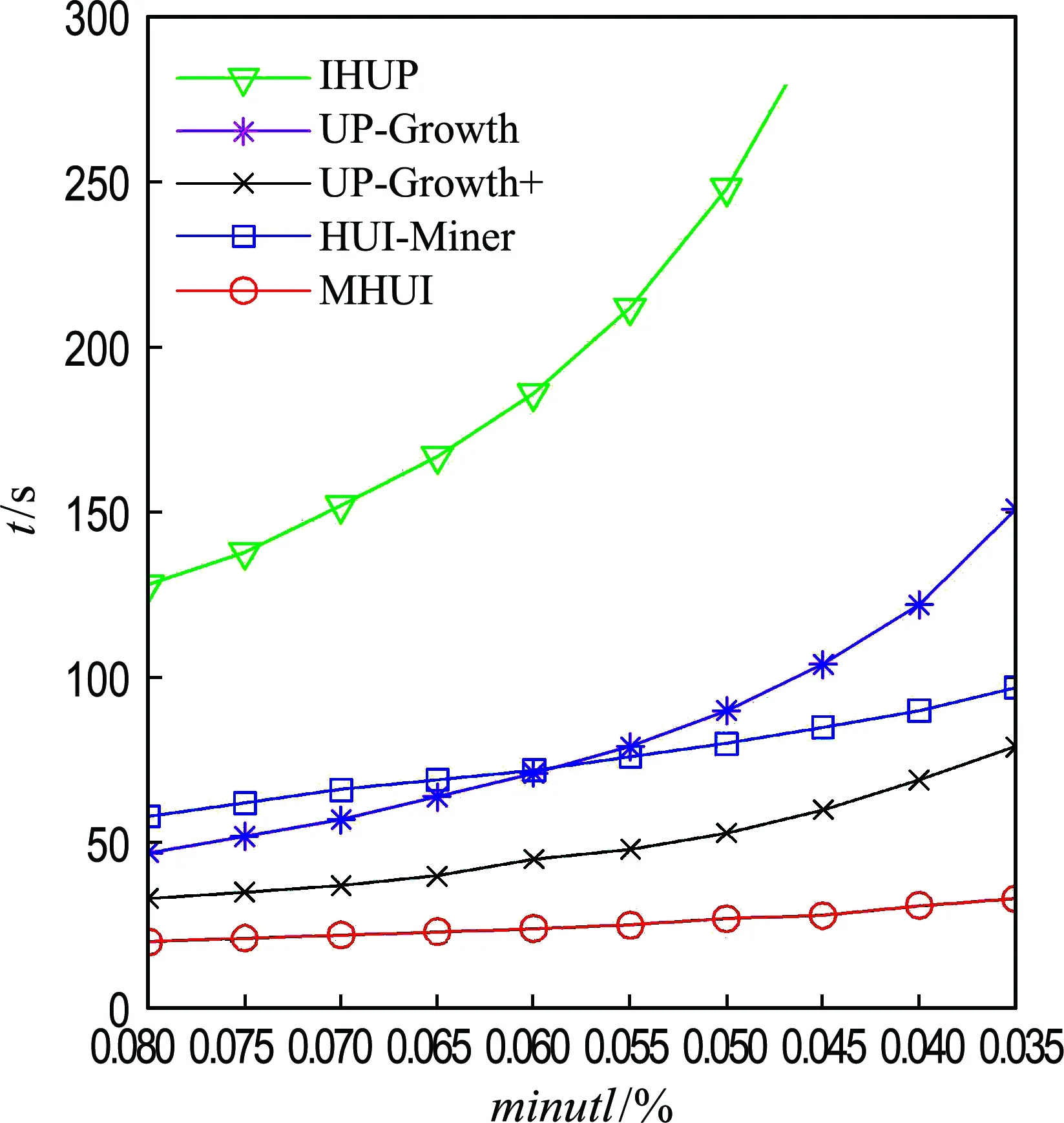
性质1事务加权向下闭性质[4],缩写为TWDC.规定如下:对于任何一个项集X,如果TWU(X) 例如:在表1中,TWU({AB})=TU(T6)=28.设minutl=30,则{AB}和它的超集都不是高效用项集,因为TWU({AB}) 项的单位利润见表2. 表1 事务数据库示例 表2 项的单位利润 在这部分,详细介绍提出的数据结构和算法.扫描一次事务数据库,并应用3种剪枝策略,产生存储所有事务和项的效用信息的项集列表.最后,扫描所有的项集列表,产生高效用项集. 2.1 初始项集列表 首先,扫描如表1所示的事务数据库一次,产生初始项集列表,如图1所示.初始项集列表中存储每个项所在的事务以及对应的效用.例如,项A在事务T1、T2、T6、T8中出现,对应的效用分别为8、16、16、8. 图1 初始项集列表 Fig.1 Initial itemset lists 在图1中,初始项集列表{F}的加权事务效用之和为TWU({F})=TU(T3)+TU(T7)=24.根据性质1,项F和它的超集都不是高效用项集,因为TWU({F}) 定义7(有用项和无用项) 给定一个项ip,如果TWU(ip)≥minutl,则称其为有用项;否则,称其为无用项. 策略1删除初始项集列表中的无用项. 2.2 2-项集列表 在产生初始项集列表之后,通过对初始项集列表进行交集运算,生成2-项集列表.例如项A和项B的共同事务为6,对应的效用分别为16和4,所以项集{AB}的事务为6,效用为20,2-项集列表如图2所示. 性质2项集列表事务加权向下闭性质,缩写为ITWDC.规定如下:对于任何一个项集列表X,如果项集列表X的加权事务效用之和小于minutl,则项集X及其超集都不是高效用项集. 图2 初始2-项集列表 Fig.2 Initial 2-itemset lists 项集列表{AD}的结果为空集,它的超集都为空集,可以直接从2-项集列表中删除.计算每个2-项集列表的加权事务效用.其中,TWU({AB})=24,TWU({BG})=13,TWU({DG})=19.它们可以从2-项集列表中删除,根据性质2,项集{AB}、{BG}和{DG}的超集也不是高效用项集,都称为无用项集. 定义8(有用项集和无用项集) 给定一个项集X,如果TWU(X)≥minutl,则称其为有用项集;否则,称其为无用项集. 策略2删除项集列表中的无用项集. 图3所示为应用策略2之后的2-项集列表,2-项集列表的数量从最初的15个减少到11个. 图3 应用策略2后的2-项集列表 Fig.3 2-Itemset lists by applying Strategy 2 定义9(前缀项集) 给定一个项集X,由k个项{is,is+1,…,is+k-1}组成,所有的项按顺序排列.项is即为项集X的前缀,排在项is前的项集称为项集X的前缀项集. 例如,项集{BC}的前缀项集为A,项集{DE}的前缀项集为ABC. 观察图3中的项集列表{DE},如果直接使用表1中的事务效用TU值来计算项集列表{DE}的TWU值,则TWU({DE})=46.此时项集列表{DE}不能删除,需要保留.如果利用定义9删除前缀项集的效用,则项集{DE}的TWU值的计算方法为TWU({DE}) = 25,它的值小于minutl,根据性质2,项集{DE}及它的超集都不是高效用项集,将项集列表{DE}从2-项集列表中删除,进一步减少项集列表的数量. 策略3删除项集前缀效用. 图4所示为使用策略3之后的2-项集列表,2-项集列表的数量进一步从11个减少到10个. 图4 应用策略3后的2-项集列表 Fig.4 2-Itemset lists by applying Strategy 3 2.3 k-项集列表 为了构建k-项集列表,可以根据k-1项集列表进行事务交集运算构建.例如根据图4所示的2-项集列表,进行事务交集运算,生成3-项集列表,如图5所示.在产生k-项集列表(k>2)时,需要减去重复效用值,文献[12]有详细说明. 图5 初始3-项集列表 Fig.5 Initial 3-itemset lists 图6为使用策略3之后的3-项集列表. 图6 应用策略3后的3-项集列表 Fig.6 3-Itemset lists by applying Strategy 3 至此,文章已介绍如何构建项集列表以及3种剪枝策略的原理.接下来,介绍如何从项集列表中直接生成所有的高效用项集挖掘算法MHUI. 2.4 本文提出的算法 MHUI 本文提出的算法MHUI,仅需扫描一次事务数据库,在不产生候选项集的情况下,直接产生所有的高效用项集.效用项集挖掘算法MHUI表述如下.Algorithm: MHUI Input: DB: the transaction database;minutl: the minimum utility threshold. Output: all the HUIs. Step1: Produce the initialILsthrough scanning the DB. Calculate the initial transaction utilitytu. Output the HUIs of 1-itemset. Step2: Delete the unpromise item from the initialILsand updatetu. 1.flag=0; 2. repeat 3.flag=IL.size(); 4.twu(ip)=TWU(IL,tu); 5. if (twu(ip)) 6. deleteipfromIL; 7. end 8.tu=TU(IL); 9. untilIL.size() 10. Output the HUIs ifu(X)≥minutl Step3:ILsof 2-itemsets are generated by initialILs. Delete the unpromise itemset from theILs. Output the HUIs of 2-itemsets. 11.ILk=List(IL); 12. if (twu(X)) 13. deleteXfromILk; 14. end 15. Output the HUIs ifu(X)≥minutl Step4:ILsofk-itemsets obtained byILsof (k-1)-itemsets 16. repeat 17.k=k+1; 18.ILk=List(ILk-1); 19. Output the HUIs ifu(X)≥minutl 20. untilILk.size()=0 为评估提出的算法的性能,将其同最新的算法进行对比.实验使用的计算机:3.3 GHz Intel i5-4590处理器;8 GB内存,Windows 7操作系统;算法用Java语言实现. 3.1 实验数据集 实验数据集Chain-store[13]是一个真实数据集,采集于一家超市的销售数据.Chain-store数据集提供了项在事务中的数量和单位利润,可直接使用.数据集retail和T10I4D100K来自FIMI网站[14].3个数据集的特点如表3所示. 表3 数据集的特点 3.2 运行时间与内存消耗 为了测试本文提出的算法MHUI的性能,对比实验分别采用了IHUP、HUI-Miner、UP-Growth和UP-Growth+等4个最新的算法. 图7是Chain-store数据集的实验结果,显示在不同的最小阈值的情况下,5种算法的运行时间和内存消耗情况.图7(a)显示的是运行时间,从图中可以看到,MHUI算法比HUI-Miner算法要快1倍左右,主要原因是,本文提出的剪枝策略,使得参与计算的项集列表数量减少.图7(b) 显示的是内存消耗,可以看到,MHUI和HUI-Miner比UP-Growth+消耗的内存要少.主要原因是,Chain-store数据集所包含的项较多,达到46 086个,导致UP-Growth+构建的UP-Tree规则较大,并且产生数量巨大的候选项集,消耗了大量的内存. (a) 运行时间 (b) 内存消耗 图7 数据集Chain-store上的实验结果 Fig.7 The experimental results on database Chain-store 图8显示了在retail数据集上,5种算法在运行时间和内存消耗上的差异.MHUI比HUI-Miner、IHUP、UP-Growth和UP-Growth+等4个算法在内存消耗上优势明显,运行速度一般也要快1倍以上. 图9显示在T10I4D100K数据集上,5种算法在运行时间和内存消耗上的差异.算法MHUI在运行时间上和内存消耗上的表现都比另外4种算法更好.其中,在运行时间上,MHUI比HUI-Miner要快60%以上,比UP-Growth和UP-Growth+要快2倍以上. 实验结果显示,在不同的数据集上,本文提出的算法在性能上好于最新算法.主要的原因如下:第一,提出的算法不产生候选项集;第二,提出的项集列表不存储冗余信息,仅存储事务和项的效用信息,占用空间少;第三,提出3种剪枝策略,减少了项集列表的数量,从而减少了算法的运行时间和内存消耗. (a) 运行时间 (a) 运行时间 本文提出了一个新的数据结构——项集列表.仅需扫描一次数据库,就能完成项集列表的构建.并提出3种用于对项集列表进行剪枝的策略,应用这3种剪枝策略能减少项集列表的数量,减少算法的执行时间,也能降低内存的消耗.最后,提出一个算法MHUI,通过扫描项集列表,直接生成完全高效用项集,在这个过程中,不需要产生候选项集.该算法运行速度快,且减少内存消耗,性能较好. [1] AGRAWAL R, SRIKANT R. Fast algorithms for milling association rules in large databases [C] //Proceedingsofthe20thVLDBConference. Santiago: Morgan Kaufmann Publishers Inc., 1994:487-499. [2] HAN Jiawei, PEI Jian, YIN Yiwen. Mining frequent patterns without candidate generation [C] //ProceedingsoftheACMSIGMODInternationalConferenceonManagementofData. Dallas: ACM, 2000:1-12. [3] ZAKI M J. Scalable algorithms for association mining [J].IEEETransactionsonKnowledgeandDataEngineering, 2000,12(3):372-390. [4] LIU Y, LIAO W, CHOUDHARY A. A two-phase algorithm for fast discovery of high utility itemsets [C] //Proceedingsofthe9thPacific-AsiaConferenceonKnowledgeDiscoveryandDataMining. Vietnam:Springer, 2005:689-695. [5] YAO Hong, HAMILTON H J. Mining itemset utilities from transaction databases [J].Data&KnowledgeEngineering, 2006,59(3, SI):603-626. [6] LI Y C, YEH J S, CHANG C C. Isolated items discarding strategy for discovering high utility itemsets [J].Data&KnowledgeEngineering, 2008,64(1):198-217. [7] AHMED C F, TANBEER S K, JEONG B S,etal. Efficient tree structures for high utility pattern mining in incremental databases [J].IEEETransactionsonKnowledgeandDataEngineering, 2009,21(12):1708-1721. [8] TSENG V S, WU Chengwei, SHIE Baien,etal. UP-Growth: an efficient algorithm for high utility itemset mining [C] //ProceedingsoftheACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining. Washington D C: ACM, 2010:253-262. [9] TSENG V S, SHIE Baien, WU Chengwei,etal. Efficient algorithms for mining high utility itemsets from transactional databases [J].IEEETransactionsonKnowledgeandDataEngineering, 2013,25(8):1772-1786. [10] WU Chengwei, FOURNIER-VIGER P, YU P S,etal. Efficient mining of a concise and lossless representation of high utility itemsets [C] //Proceedings-IEEEInternationalConferenceonDataMining,ICDM. Vancouver: IEEE, 2011:824-833. [11] TSENG V S, WU Chengwei, FOURNIER-VIGER P,etal. Efficient algorithms for mining the concise and lossless representation of high utility itemsets [J].IEEETransactionsonKnowledgeandDataEngineering, 2015,27(3):726-739. [12] LIU Mengchi, QU Junfeng. Mining high utility itemsets without candidate generation [C] //CIKM2012-Proceedingsofthe21stACMInternationalConferenceonInformationandKnowledgeManagement. Maui :ACM, 2012:55-64. [13] PISHARATH J, LIU Y, PARHI J,etal. NU-MineBench Version 3.0.1 [DB/OL]. [2016-06-30]. http://cucis.ece.northwestern.edu/projects/DMS/MineBench.html [14] GOETHALS B, ZAKI M J. Frequent itemset mining implementations repository [DB/OL]. [2016-06-30]. http://fimi.ua.ac.be/ Analgorithmofmininghighutilityitemsetswithverticalstructures HUANG Kun*1, WU Yujia2 ( 1.China Ship Development and Design Center, Wuhan 430064, China; 2.School of Computer, Wuhan University, Wuhan 430072, China ) Mining high utility itemsets (HUIs) is one of popular tasks in field of association analysis. Most of HUIs mining algorithms need to generate a lot of candidate itemsets (CIs) which will affect the performance of algorithm. HUI-Miner can mine all the HUIs from a transaction database without generating CIs. However, this algorithm generates a large number of utility lists (ULs) and so many ULs not only consume too much storage space but also affect the operation performance. To solve this problem, itemsets lists (ILs), new data structures are proposed to maintain information of transaction and item utility. Three pruning strategies are proposed to reduce the number of ILs and can build the ILs just scanning the transaction database only once. A new algorithm namely MHUI is proposed which mines all the HUIs directly from the ILs without generating any CIs. The experimental results show that the proposed method outperforms the state-of-the-art algorithms in terms of runtime and memory consumption on three different sparse datasets. data mining; association analysis; frequent itemsets; high utility itemsets 2016-11-14; 2017-07-23. 国家自然科学基金资助项目(61303046). 黄 坤*(1979-),男,高级工程师,E-mail:hkcfan@163.com;吴玉佳(1986-),男,博士生,E-mail:wuyujia@whu.edu.cn. 1000-8608(2017)05-0524-07 TP312 A 10.7511/dllgxb201705013


2 方法介绍





3 实 验




4 结 语
