基于回归模型的云南省非国家级贫困县经济发展状况分析
2015-03-23杨泱
杨 泱
(复旦大学,上海 200433)
全国有592个国家级贫困县,云南省占73个〔1〕,是贫困县最多的省份。云南省129个县(区)中,不属于国家级贫困县的仅有56个〔2〕,贫困地区落后的经济状况严重制约着云南省宏观经济发展。区域经济发展的整体情况很难用少数几个指标全面概括,但生产总值是十分重要的指标之一,研究这56个县(区)生产总值的总体和人均情况无疑可以为云南乃至全国贫困县的宏观经济发展提供参考,并有利于缩小区域发展差距。
一、建立回归模型
多元线性回归模型中因变量Y与自变量X之间的关系为:Y=β0+β1X1+β2X2+ … +βkXk+ε〔3〕,其中β0为y轴截距,β1,…,βk为自变量X1,…,Xk的系数。误差ε表示实际值与估计值的差异,在k=1时,ε代表Yi与直线之间的距离,在k≥2时它代表Yi与响应面(re⁃sponse surface)的距离。由于β0,…,βk是总体系数,所以通常是未知的,需要运用拟合回归方程估计系数的值。估计方程为其中b0,…,bk是β0,…,βk的无偏差估计量。
选取云南56个非国家级贫困县(区)2013年统计数据,设生产总值(亿元)(按2013年价格计算)为因变量Y1;设总人口(万人)、规模以上工业企业主营业务收入(亿元)、人均固定资产投资(不含农户)(元/人)、乡村人口(万人)、公共财政预算支出(亿元)分别为X11,…,X15。再设两个哑变量(dummy variable)概括区位、政策因素,分别为:X16=1,县(区)位于滇中经济圈;X16=0,县(区)位于滇中经济圈之外。X17=1,边境县(区);X17=0,非边境县(区)。滇中经济圈是指昆明、曲靖、玉溪、楚雄四市(州),边境县(区)是指与缅甸、老挝、越南三国接壤的县(区),非国家级贫困县是指云南省129个县(区)中排除73个国家级贫困县后剩下的56个县(区)。设人均生产总值(元/人)(按2013年价格计算)为因变量Y2;设城镇居民可支配收入(元/人)、规模以上工业企业利税总额(亿元)、农村贫困发生率(百分比)、农村居民人均纯收入(元/人)、人均固定资产投资(不含农户)(元/人)分别为X21,…,X25,并设X26、X27两个哑变量,其定义与X16、X17相同。对Y1、Y2分别进行回归分析,结果见表1和表2。
F1=71.48,F2=53.33,F检验的相伴概率P近似于0,回归方程显著。R-Sq(调整)减缓了自变量个数对拟合优度的干扰,其值为90.00%与86.95%,因变量中不能被方程解释的部分较小,R-Sq(预测)衡量模型预测和拟合水平,其值为82.88%与79.89%,拟合效果良好。以两个自变量为一组(哑变量除外),建立样本相关系数r的矩阵(限于篇幅,图略),发现某些自变量之间存在一定的相关关系。另外,在表1中观察到大于10的方差膨胀因子,因此,模型中存在多重共线性问题。
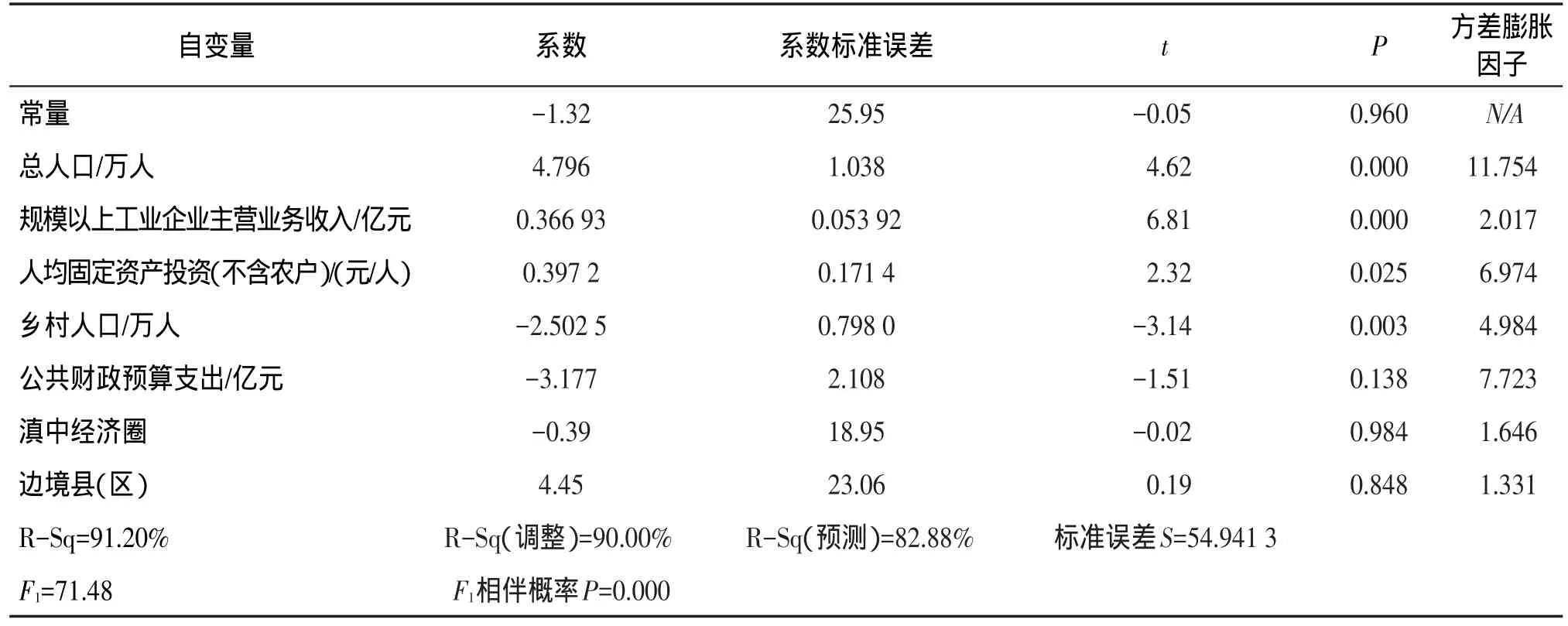
表1 云南省56个非国家级贫困县Y1的回归分析结果
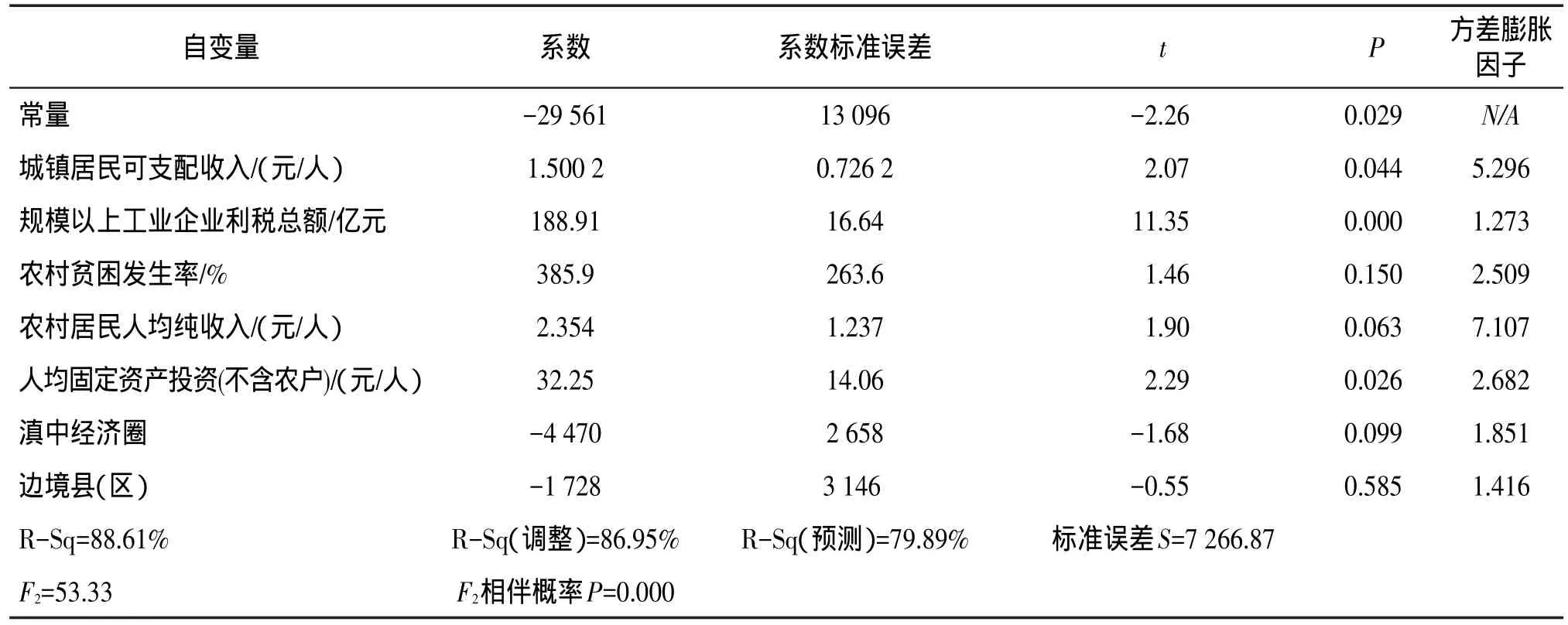
表2 云南省56个非国家级贫困县Y2的回归分析结果
多重共线性常见于涉及经济变量的模型中,可导致方程的系数存在误差。例如表1中公共财政预算支出系数为负,说明在其他条件不变的情况下,提高公共财政预算支出反而降低了生产总值,该结论没有经济学意义。另一方面,多重共线性导致t检验结果参考性降低。综上,当模型包含较多的自变量,尤其当自变量之间存在一定的相关关系时,不仅增加了第一类错误发生的概率,还可能导致多重共线性的发生,需要对模型进行改进。
逐步回归法以统计显著性为基础,是简便有效解决多重共线性问题的方法之一。逐步回归有三种方法,较为常用的是逐步法,其步骤为对自变量逐个进行回归分析,然后比较F检验的P与入选P(P-to-enter),若所有自变量的P均高于预先设定的入选P,则逐步回归不可用,须改用其他方法或调整入选P;若一个自变量的P低于入选P,选择该自变量引入模型;若多个自变量的P低于入选P,则选择其中P最低者引入模型。在引入第一个自变量的条件下,用同样的方法考察是否引入第二个变量。在引入新变量时,对于原来已经引入的变量,其相伴概率P可能会发生变化,须比较变化后的P与删除P(P-to-leave),不符合删除P的自变量被排除。以上步骤重复多次,直到没有变量被引入和删除为止。另外,可以选择入选F与删除F代替对应的P。用所选数据进行逐步回归分析,选择入选P为0.05,删除P为0.1,结果见表3和表4。
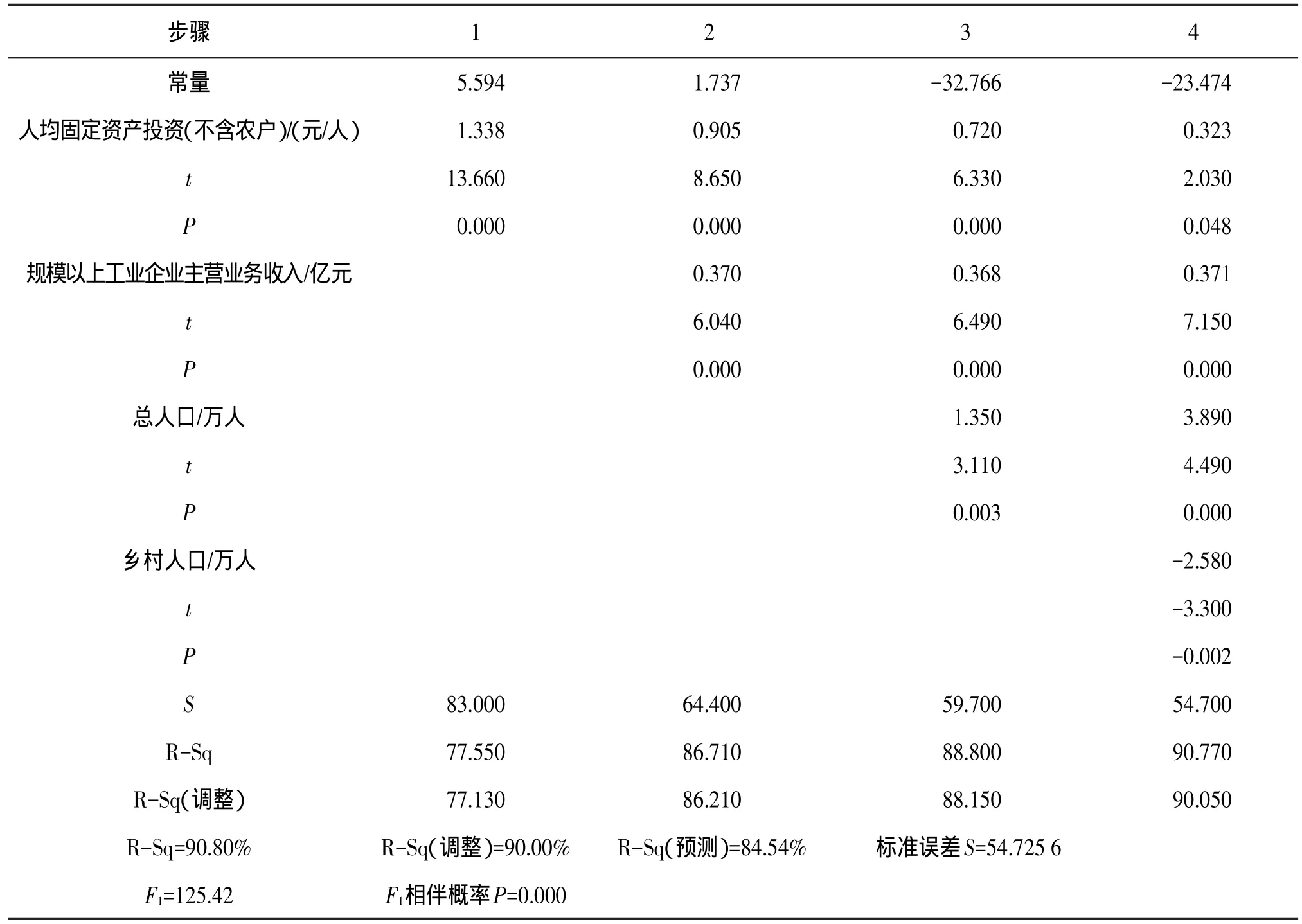
表3 云南省56个非国家级贫困县Y1的逐步回归分析结果
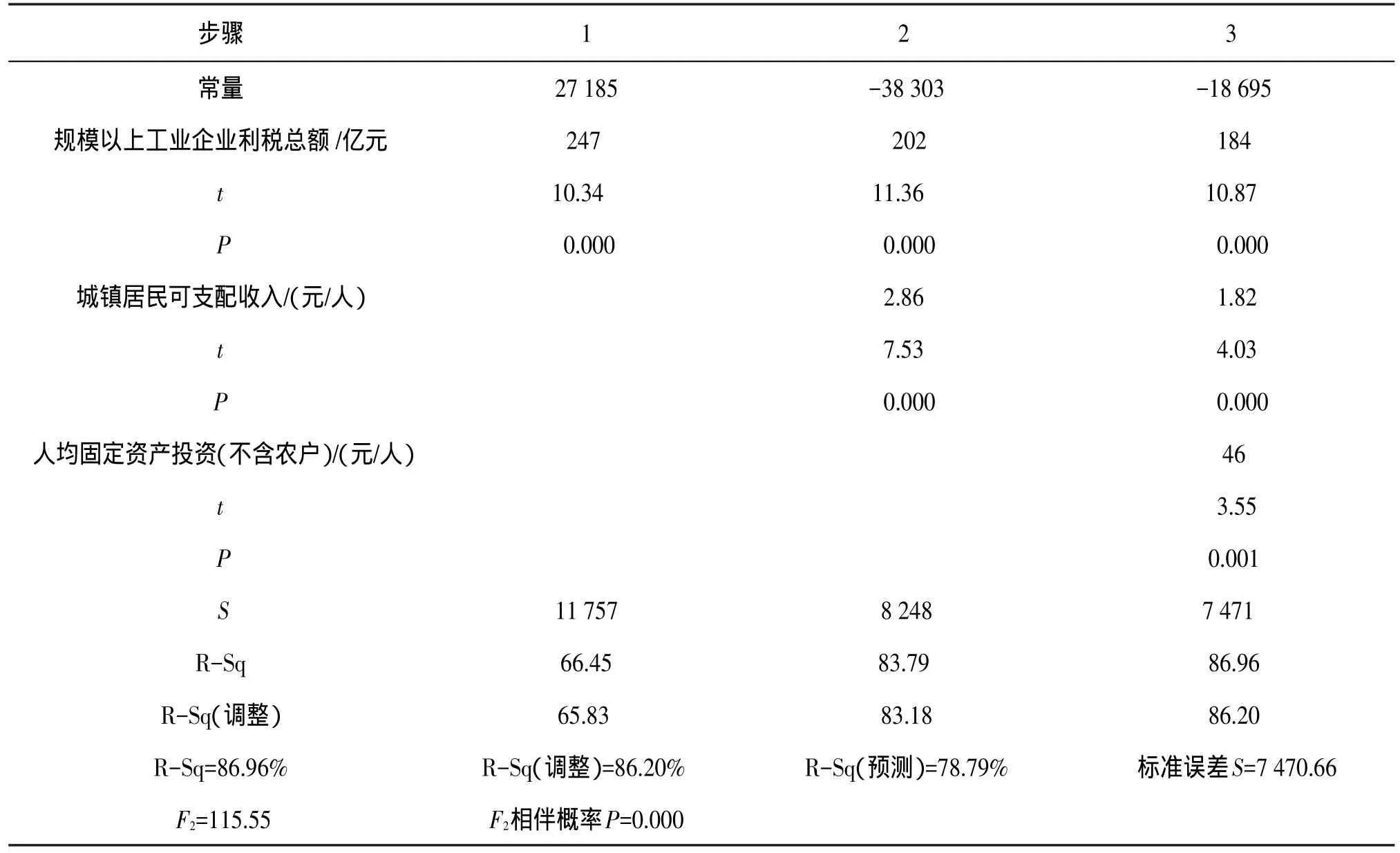
表4 云南省56个非国家级贫困县Y2的逐步回归分析结果
随着逐步回归步骤1~4(第二个模型1~3),两个回归模型的R-Sq(调整)逐步升高,标准误差S逐步降低。再比较之前的回归结果,F值均有提高,方差膨胀因子(图略)均小于10。模型在逐步回归后得到优化,多重共线性问题被解决。
二、残差检验
残差еi是误差ε的估计量,回归分析要求残差满足三个假设:一是服从均值为零的正态分布;二是方差恒定;三是残差之间独立〔4〕。因此,需要做正态检验、异方差检验。因为数据是截面数据,自相关检验不需要。
(一)异方差检验
以Y轴为残差,X为拟合值作出两图(图略),两图形状十分类似,散点大致集中在图的左侧,似乎并未随机分布,怀疑存在异方差。图中存在一些点偏离其他点,经核实原始数据正确,计算过程无误,予以保留。进一步使用White检验(不使用交叉项)和 Glejser检验〔5-7〕,对于 Y1方程分别得到统计量19.76241,相伴概率P为0.0006,统计量22.75764,P为0.0001,对于Y2方程分别得到统计量11.28562,P为0.0103,统计量10.02346,P为0.0184,异方差存在。采用加权最小二乘法解决异方差,如果所取的权数合适,它并不会扭曲模型的经济意义,还能改善模型的各项指标〔8〕,权数W常用自变量或残差的-2 至 2 次方的倒数。取W=1/∣ei∣1.5〔9-10〕,使用加权二乘法后再一次计算White检验和Glejser检验,对于Y1方程分别得到统计量3.914968,P为0.5617和统计量3.531453,P为0.4731,对于Y2方程分别得到统计量3.952946,P为0.4124和统计量4.836801,P为0.1841,模型的R-Sq(调整)等指标也得到优化。但加权二乘法优化模型的代价之一是可能导致多重共线性,尤其是在权数选择失当的情况下,因此,检查模型的方差膨胀因子,发现均小于10(图略),多重共线性问题不存在。
(二)正态检验
Jarque-bera(以下简称JB)统计量基于总体为正态分布时,它近似服从于自由度为2的卡方分布,其计算公式JB=n/6〔S2+1/4(k-3)2〕,原假设H0:数据服从正态分布,备择假设H1:数据不服从正态分布。计算JB统计量,分别得到JB1=2.3171,相伴概率P为0.3139,JB2=0.4197,P为0.8107,得出结论为不拒绝原假设,认为残差服从正态分布。
三、结论
回归模型为:生产总值(亿元)=-23.1629+0.2642人均固定资产投资(不含农户)(元/人)+0.3858规模以上工业企业主营业务收入(亿元)+4.1366总人口(万人)-2.7056乡村人口(万人);人均生产总值(元/人)=-18440.2894+190.0439规模以上工业企业利税总额(亿元)+1.8204城镇居民可支配收入(元/人)+43.1773人均固定资产投资(不含农户)(元/人)。其他条件固定时,1万人口的增长解释了4.1366亿元的生产总值,将单位化简后1的人口增长解释了41366的生产总值,即人均41366元。接近同时期全国人均水准,而全省人均生产总值仅25083元。参照全国,云南省这56个县(区)的生产总值增长虽取得一定成效,但相对发达地区仍然较低。在省内来说,这56个县(区)的生产总值与全省平均水平存在较大差异,一部分地区已经发展起来,但未能带动贫穷落后的地区。因此,云南省各区域的均衡发展是将来值得关注的问题之一。一单位的城镇居民可支配收入解释了1.8204单位的人均生产总值,揭示了提高城镇居民可支配收入是提高人均生产总值的途径之一。乡村人口的系数为负值表明乡村人口越多的地区,生产总值越低,直接的解决方法是提高农民的综合素质,推动农业的商品化、集约化。另一方面,借助户籍制度改革和城市化进程使得一部分富余的乡村劳动力转化为城镇居民,推进城乡之间协调发展。人均固定资产投资(不含农户)、规模以上工业企业主营业务收入、规模以上工业企业利税总额的系数为正,这些县(区)应该进一步扩大投资、建立良好的投资环境、吸纳外部资金并承接部分沿海地区的产业,发挥投资在生产总值增长中的拉动作用。另一方面,扩大工业企业的规模、拓展产品的销路、提高企业的产品竞争力和利润率也能有力地带动生产总值的增长。工业企业缴纳的税收是财政收入的来源之一,起到调节社会经济结构的作用,因此,这56个县(区)应该重视辖区内工业企业的发展。
在56个县(区)中,自变量滇中经济圈和边境县(区)相较于其他自变量显著性不够明显,因此,被逐步回归排除,说明区位因素对这56个县(区)的影响不够显著,滇中经济圈的建设还有待加强,边境的贸易往来还需扩大。
〔1〕国务院扶贫开发领导小组办公室.国家扶贫开发工作重点县名单〔EB/OL〕.(2012-03-19)〔2015-03-15〕.http://www.cpad.gov.cn/publicfiles/business/htmlfiles/FPB/fpyw/201203/175445.html.
〔2〕云南省统计局.云南统计年鉴2014〔M〕.北京:中国统计出版社,2014:481-566.
〔3〕Gerald Keller.Statistics for Management and Economics〔M〕.9th ed.USA:South-Western Cengage Learning,2009:525-735.
〔4〕易丹辉.数据分析与Eviews应用〔M〕.北京:中国人民大学出版社,2008:1-50.
〔5〕金烨.GDP核算的回归估算方法研究〔D〕.上海:上海交通大学,2011.
〔6〕龚秀芳.回归模型中异方差数据的处理〔D〕.上海:华东师范大学,2002.
〔7〕张敏.自相关过程的统计过程控制方法研究〔D〕.天津:天津大学,2006.
〔8〕郑春茂.加权回归及权函数的变换在生物量建模中的应用〔J〕.华东森林经理,2012,26(2):77-79.
〔9〕王军.回归模型异方差性分析〔J〕.科技和产业,2008,8(1):61-63.
〔10〕张晋昕,党容.时间序列分析中的异方差性〔J〕.统计与信息论坛,2002,17(6):62-64.
