基于语料库的译者风格动态对比研究
2014-07-31张小林任雪花
张小林,任雪花
(电子科技大学 成都学院,四川 成都611731)
《译学词典》把译者风格解释为“译者的人格倾向,选题倾向,文笔色彩以及译者所遵循的翻译标准,使用的翻译方法和译文语言运用技巧等特点的综合,尤其是语言运用的特点”。[1]传统的翻译风格研究主要关注原作者个性化语言使用是否在译文中得到充分体现以及如何实现译者风格和原作风格的统一。现代翻译学中的译者风格研究主要探究如何描写文学翻译者或译者群体所独有的翻译语言特征。[2]Baker(2000)认为译者风格是译者在翻译过程中留下的“指纹”,是其在译文中所表现出的一些规律性语言模式,这些语言模式并非一次性的,而是为译者偏爱的、反复出现、习惯性的语言行为模式。这是译者下意识的一种语言选择行为,而非完全受源文本或原作者语言风格影响的结果。本文将按照Baker 研究“译者风格”的方法,[3]基于《天府的记忆》英译项目,对译文交叉审阅前后的译者风格进行考察对比,探究Baker 所指的译者风格在译文中的彰显程度及其和源文风格的关系。
一 基于语料库的译者风格研究现状
Baker(2000)是将语料库应用于译者风格研究的首倡者,在其论文《文学作品译者风格考察方法论探索》中提出基于语料库的译者风格研究不同于一般意义上以源文本、原作者文体及风格为关注焦点的翻译文体研究,而是从目标文本的语言形式特征,如标准类/形符比、平均句长、叙述结构(转述动词say)等方面的统计数据入手,关注文学翻译译者或译者群体特有的翻译语言特征。继Baker 之后,后继研究者应用语料库方法主要从三方面开展了译者风格研究。
(一) 借鉴Baker 方法探究译者风格
Bosseaux[4]对Virginia Woolf 的《The Waves》的两个法语译本从形符/类符比和平均句长等角度进行统计对比,发现两者的风格存在明显差异。Yu 从英译汉的视角讨论了海明威小说《老人与海》两个中译本在译者风格方面的差异。[5]伊丽通过对刘士聪散文翻译语料库进行形符/类符比和平均句长以及被动语态和标点符号的考察,[6]发现刘士聪的翻译在传递原作风格之外还体现出其独特的风格和文体特色,如对普通日常词汇的选用以及对简单句的偏爱等。刘泽权对《红楼梦》的四个英译本在词汇和句子层面的基本特征进行数据统计和初步的量化分析,[7]比较和探讨了其在风格上的异同。陈建生、高博对Ezra Pound 和James Legge 的《诗经》英译本从类符形符比、词汇密度、平均词长、平均句长等方面进行了统计和量化分析,[8]揭示了两位译者的风格。这些研究中既有探索某位译者风格的,也有比较译者风格差异的。但大多是对Baker 的方法的简单借用。
(二) 对Baker 方法的拓展
Olohan 从缩略语的角度对比了Peter Bush 和Dorothy S. Blair 的译文,[9]发现Bush 在译文中倾向于使用缩略形式(占67%),而Blair 则恰好相反(缩略形式占24%)。Bosseaux 对Virginia Woolf 另一部作品《To The Lighthouse》的三个法语译本进行比较分析,[10]阐明了法语译本在指示、情态、及物性和间接话语等方面所呈现的具体特征,揭示了三位译者风格的差异。Winters(2004a,2004b,2007,2009)以菲茨杰拉德小说《美女和被诅咒的人》(The Beautiful and Damned)两个德文译本为语料,[11][12][13][14]分别以情态小词、外来词、语码转换和言语行为转述动词为考察对象,讨论了两位德国译者的不同风格。刘泽权、闫继苗(2010)通过考察《红楼梦》中“道”的最频繁报道形式“(某人)道”的翻译,[15]发现报道动词的翻译能够反应译者的风格差异。这些研究并未完全遵循Baker 的方法,而是进行了拓展。但研究中所比较的译者要么来自不同的国家,要么生活在不同的年代,其所处的大环境对其选择的影响不可忽视,统计数据不一定真实反映了Baker 所说的译者下意识选择的结果。
(三) 对Baker 方法的质疑与反思
近年来,也有学者对Baker 的方法提出了质疑和反思。Saldanha(2005)认为Baker 及其他学者的研究本质上仅仅是一些探索性研究,[16]没有提供确凿证据证明一致的风格特征不是依赖于源文本的,且这一特征可以区分不同译者的译文。黄立波、朱志瑜(2012)以Baker 考察译者风格的方法为依据探究了戴乃迭与葛浩文两位译者的风格差异,[2]结果发现利用语料库统计数据如标准类符形符比和平均句长等并不能够有效地将一个译者与另一个译者的翻译风格区分开,并强调译者风格研究不宜将源文本完全排斥在外。这些研究对Baker 的方法进行了反思,遗憾的是他们并未进一步研究源文本对译者风格的影响。王克非(2008)和胡开宝(2012)分别指出基于语料库的译者风格研究不应局限于文学翻译文本的分析。[17][18]
本文将尝试把Baker 的方法应用于非文学类文本的研究,并在排除时代背景和地域差别的前提下动态对比考察译者风格,探究Baker 所指的译者风格在译文中的彰显程度并将其与源文本进行影响力大小的比较。
二 语料收集与研究方法
本文语料全部来自《天府的记忆》英译项目各阶段的译文。《天府的记忆》是一部以成都历史文化为背景、展现中国西部现代化特大中心城市成都魅力的作品。全书共分9 章,分别为九天开出一成都、蜀道难与蜀道通、花重锦官城、海纳百川、道法自然、茶道龙门阵、走出盆地、天地系于人和云帆龙舸。此项目由8 名长期生活在成都的译者承担,除第七章和第九章由一人负责外,其余7 名译者各自负责一章。当各章的译者提交译文初稿后,笔者便建设了译文初稿语料库,并利用Word Smith 5.0 按章节从标准类符/形符比、平均词长以及平均句长等方面进行了译者风格考察。随后,笔者令译者B审阅译者A 的译文,译者C 审阅译者B 的译文,依次类推,根据自己对源文本的理解对译文进行调整和修改。审阅完成后,笔者又建设了译文审稿语料库,并再一次利用Word Smith 5.0 按章节从标准类符/形符比、平均词长以及平均句长等方面进行了译者风格考察。最后将两组数据进行比对,以探究Baker 所指的译者风格在译文中的彰显程度并将其与源文本进行影响力大小比较。
三 译者风格的动态对比及启示
(一) 译者风格的动态对比
利用Word Smith 5.0 对译文初稿语料库按章节从标准类符/形符比、平均词长以及平均句长进行统计,得到如下结果(见表1)。

表1 译文初稿各章的标准类/形比、平均词长和平均句长统计表
统计表明,虽然整个译文各项平均值接近参考语料库Brown 语料库。但不同译者之间却体现出一些差异。其中最为明显的是衡量文本难度的平均句长。最高值为32.28,最低值为16.73,相差将近一倍。Butler(1985)按长度将句子分为三类:[18]短句(1 -9 个词)、中等长度句(10 -25 个词)和长句(25 个词以上),而按照此标准,该项目绝大多数的参与者都倾向于使用中等长度的句子,而译者C、D 和H 却大量地使用长句,这就大大增加了这几章的理解难度。其次是标准类符/形符比,这一数值通常用来衡量一个文本中所使用词汇的多样性,比值越大,词汇多样性就越高。几位译者的标准类/形比最高值为46.0,最低为40.08,相差5.92。在这三组数据中,相差最细微的是平均词长,最高值4.92,最低值为4.67。
语料库统计结果揭示了各章译者之间的风格存在明显的差异,这似乎也印证了Baker 的方法是有效的。但这些差异是否完全是译者下意识的语言选择和使用习惯所致呢?仔细观察可以发现,项目的第七章和第九章都出自译者G,从数据可以看出,三项数据有一定的差异,只是差异不大。这说明同一译者在翻译不同源文本时会体现出较一致风格,但也可能因源文本的差异而出现一些变化。[2]那么,译者本身下意识的语言选择和使用习惯同源文本相比,哪一个对其翻译风格影响更大呢?
为了回答这一问题,在与交叉审阅后的译文进行对比前,笔者提出如下假设:
假设一:如果译者本身下意识的语言选择和使用习惯对翻译风格影响较大的话,那么他在审阅其他译者的译文时会不知不觉地将自己的风格(指纹)留在所审阅的译文中,即所审阅的译文的标准类符/形符比、平均词长以及平均句长会向审阅者本身译文的统计数据靠拢。
假设二:如果源文本对翻译风格影响较大的话,那么即便在交叉审阅之后,其标准类符/形符比、平均词长以及平均句长也不会出现太大变化。
为了检验假设,利用Word Smith 5.0 对交叉审阅后的译文语料库按章节从标准类符/形符比、平均词长以及平均句长几个方面进行统计,得到如下结果(见表2)。

表2 译文交叉审阅后各章的标准类/形比、平均词长和平均句长统计表
表2 显示,交叉审阅以后,整个译文各项统计平均值变化不大。而不同译者之间的差异最为明显的依然是平均句长。最高值为28.29,最低值为17.19,但同审阅前相比,这种差距大大缩小。就标准类符/形符比而言,审阅后最高值为48.52,最低为41.17,较审阅前都有增加。在这三组数据中,相差最细微的仍然是平均词长,最高值4.99,最低值为4.65,不过差距较之审阅前稍微变大了。

表3 预计变化和实际变化对比表
观察表3 可以发现,交叉审阅后,尽管大多数数据按照预计的方向发生了变化,但仍有1/3 的数据出现了逆向的变化,这说明译者本身下意识的语言选择和使用习惯对翻译风格有影响,审阅者在审阅其他译者的译文时会不知不觉地将自己的风格(指纹)留在所审阅的译文中,但这种影响是微弱的,那些出现逆向变化的数据说明,译者在审阅他人译文时,可能更多的是根据自己对源文本的理解做出语言选择,而非下意识的语言习惯占主导地位。且对交叉审阅前后各组统计数据①包括标准类符/形符比、平均词长以及平均句长,其中标准类符/形符比也是一个均值,标准化类符/形符比的计算方法是,计算每个文本每1000 词的类符/形符比,将得到的若干个类符/形符比进行均值处理。如某文本长5000 字,其中第一个1000 词的类符/形符比为50,第二个1000 词的类符/形符比为52,第三个1000 词的类符/形符比为54,那么这三个数字的平均值便是标准类符/形符比。进行T 检验发现其P 值均远远大于0.05 说明两个总体的均值没有显著差异,再一次证明了这种影响是微乎其微的。因此,假设一不成立。
对比初稿和审阅后稿件的各章风格变化趋势图(见图1),可以发现各章语料统计结果的变化趋势虽然有一些偏离,但总体上是重合的,且对交叉审阅前后各组统计数据进行T 检验发现其P 值均远远大于0. 05 说明两个总体的均值没有显著差异,再一次证明了这种影响是微乎其微的。即便在交叉审阅之后,其标准类符/形符比、平均词长以及平均句长也没有出现太大变化,因此假设二成立。
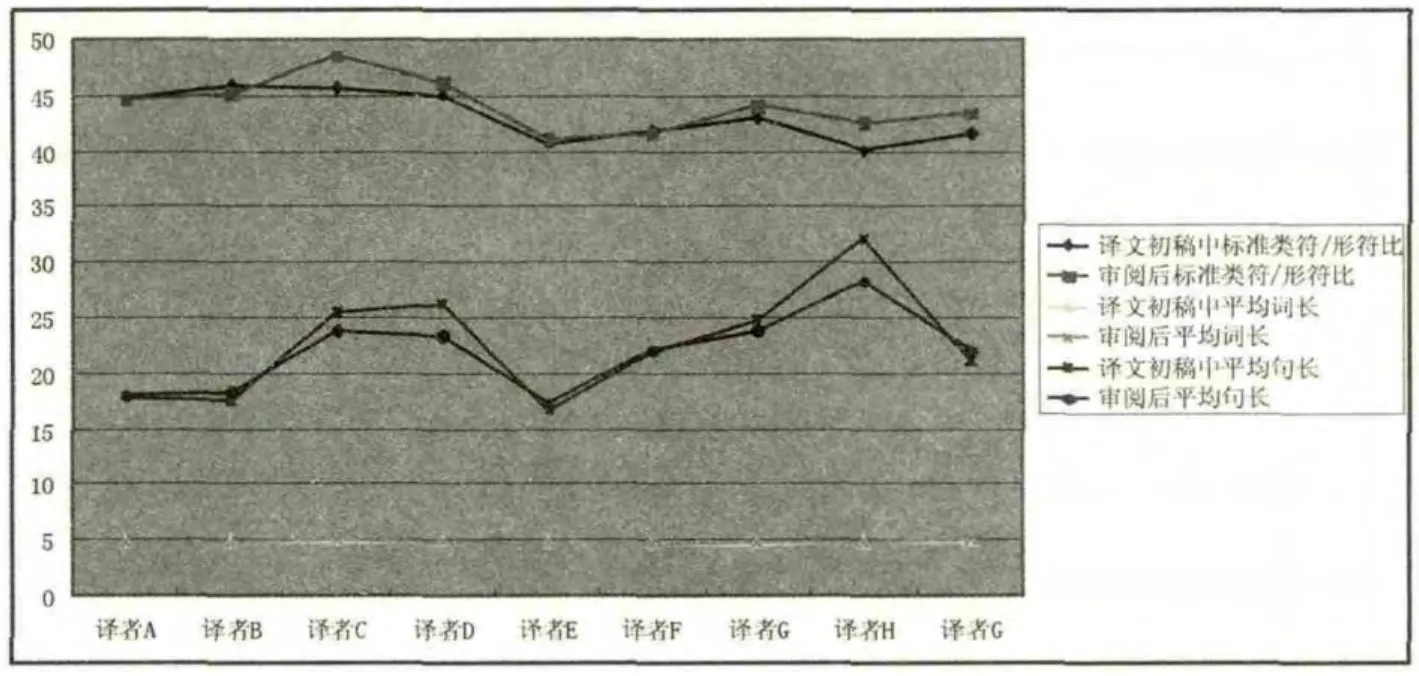
图1 译文交叉审阅前后标准类符/形符比、平均词长以及平均句长比较
(二) 研究的启示
通过对交叉审阅前后译文的语料库统计数据进行动态比较,我们可以得到几方面的启示:第一,Baker 所谓的译者风格是存在的。各章译文的统计数据有明显的差异,且交叉审阅后大多数数据发生了所预计的变化,说明译者在翻译过程中、审阅者在审阅其他译者的译文时都会不知不觉地留下自己的风格(指纹),但这种影响较源文本而言是微弱的。所以,结合源文本来考察译者风格对翻译研究更有意义。第二,基于语料库的译者风格研究方法还不完善。目前基于语料库的研究大多从词汇、句长及叙事结构等角度考察译者风格。但这并不能全面地反映译者语言运用的特点,译者所偏好的句法结构以及语篇衔接方式都应该纳入译者风格考察的范围,才能够得出更令人信服的结论。第三,基于语料库的译者风格考察方法对于翻译实践具有指导意义。事实上,许多翻译项目如今都是依靠团队的力量共同完成,团队中各个译者或多或少都会在译文中烙上自己的不同风格。如果译者之间的风格过于迥异,很难说这样的翻译作品是成功的。那么,在大型翻译项目中,利用语料库方法来考察各译者的风格,通过数据直观地反映出这种风格的差异程度,再将这些数据反馈给译者,有助于其有意识地对其翻译过程中下意识语言选择做出调整,从而实现译文风格的协调统一。
[1]方梦之. 译学词典[Z].上海:上海外语教育出版社,2003.
[2]黄立波,朱志瑜. 译者风格的语料库考察——以葛浩文英译现当代中国小说为例[J]. 外语研究,2012(5) :64 -71.
[3]Baker,M. Towards a Methodology for Investigating the Style of a Literary Translator[J]. Target,2000(2) : 241 -266.
[4]Bosseaux,C. A Study of the Translator’s Voice and Style in the French translations of Virginia Woolf’s The Waves[C]// Maeve Olohan(ed) . CTIS Occasional Papers. Manchester: Centre for Translation and Intercultural Studies,2001.UMIST:55 -75.
[5]Yu,C-h. Similarity and difference in translator’s style: A case study of the two translations of Hemingway’s work. Paper presented at the Conference and Workshop on Corpora and Translation Studies,Shanghai,China. 2007.
[6]伊丽. 基于语料库的刘士聪翻译风格研究[D]. 天津科技大学学士论文,2010.
[7]刘泽权,刘超朋,朱虹.《红楼梦》四个英译本的译者风格初探——基于语料库的统计与分析[J]. 中国翻译,2011(1) :60-64.
[8]陈建生,高博. 基于语料库的《诗经》两个英译本的译者风格考察——以“国风”为例[J]. 天津外国语大学学报,2011(4) :36 -41.
[9]Olohan,M. How frequent are the contractions? A study of contracted forms in the Translational English Corpus[J]. Target,2003(1) : 59 -89.
[10]Bosseaux,C. Point of view in translation: A corpus-based study of French translations of Virginia Woolf’s To The Lighthouse[J]. Across Languages and Cultures.2000,5(1) : 107 -122.
[11]Winters,M. German Translations of F. Scott Fitzgerald’s The Beautiful and Damned: A Corpus-based Study of Modal Particles as Features of Translators’Style[C]// Ian Kemble (ed) . Using Corpora and Databases in Translation. Portsmouth: University of Portsmouth,2004:71 -88.
[12]Winters,M. F. Scott Fitzgerald’s Die Sch? nen und Verdammten. A corpus-based study of loan words and code switches as features of translators’style[J]. Language Matters,Studies in the Languages of Africa 2004.35(1) : 248 -258.
[13]Winters,M. F. Scott Fitzgerald’s Die Sch? nen und Verdammten: A Corpus-based Study of Speech -Act Report Verbs as a Feature of Translators’Style[J]. 2007.52(3) :412 -425.
[14]Winters,M. Modal particles explained How modal particles creep into translations and reveal translators’style[J].2009,21(1) : 74 -97.
[15]刘泽权,闫继苗. 基于语料库的译者风格与翻译策略研究——以《红楼梦》中报道动词及英译为例[J]. 解放军外国语学院学报,2010(4) :87 -92.
[16]Saldanha,G. Style of Translation: An exploration of stylistic patterns in the translations of Margaret Jull Costa and Peter Bush.[D]Dublin City University,2005.
[17]王克非. 语料库翻译学十五年[J]. 中国外语,2008(6) :9 -14.
[18]胡开宝. 国外语料库翻译学研究述评[J]. 当代语言学,2012(4) : 380 -395 .
[19]Butler,Christopher. Statistics in Linguistics[M]. Oxford: Basil Blackwell,1985: 121.
