面向计算机的汉语动词“得”邻接特征考察
2014-05-29骆琳
骆 琳
(华中科技大学 中文系,武汉 430074)
“得”作为现代汉语中一个使用频率极高、意义用法相当复杂的汉字,在不同的语境和上下文组合中,代表了几种不同层次、不同类属的语言单位,具有不同的功能,表达不同的意义。从为计算机识别服务的目的出发,立足于面向计算机的自然语言信息处理,将研究范围限定在无论来源、无论读音、无论词性,凡字形相同的“得”字均纳入我们的讨论范围。
以《汉语大词典》、《现代汉语词典》和《现代汉语八百词》的分类为依托,我们将“得”字的用法分为六类:“得1”为普通动词,“得2”为能愿动词,“得3”为构成述补结构的结构助词,“得4”为动态助词,“得5”为构词语素,“得6”为专名、借词用字等其他用法。另外还有一些误为“得”的错别字,因着眼于计算机识别,不妨称之为“得7”。“得7”与其他类型性质根本不同,前六类根据需要或提取或排除,而“得7”是在文本预处理阶段即应予以校正的对象,永不会被提取。
我们的研究思路是在自建真实文本语料库的基础上,完成对封闭性训练语料的核对与标注。使用Visual Basic.Net语言自行研制WordParse软件,完成ACCESS格式的语料分析数据库建设及数据统计分析。在自然语言信息处理的研究中,观察和分析字符串的左右邻接特征至关重要。DataWord软件的研制则为我们建构前后接续观察和统计系统,更直观、更迅捷地观察和统计字符串的前后接续状况提供了便利。
限于篇幅,本文只讨论研究成果中涉及对普通动词“得1”前后接续特征的观察和统计。
一 动词“得”左右邻接特征分布统计
判断自然语言中字符串能否邻接在语言信息处理研究的许多领域广为使用,能否邻接的判断标准应该由大规模的真实文本统计而出,然而由于自然语言中词语分布的稀疏性,对判断标准的准确性和全面性所造成的干扰,使我们在对动词“得”的邻接特征进行判断时,不得不对统计出来的具体词形进行归类,即在对语料库中真实文本统计的基础上通过内省,并结合专家知识库中的相关知识,对词语进行归类,用词语类的接续关系代替词形的接续关系作为判断邻接与限制的依据,并通过数据的统计来说明动词“得”对邻接词语的选择性。
(一)动词“得”左邻接特征分布
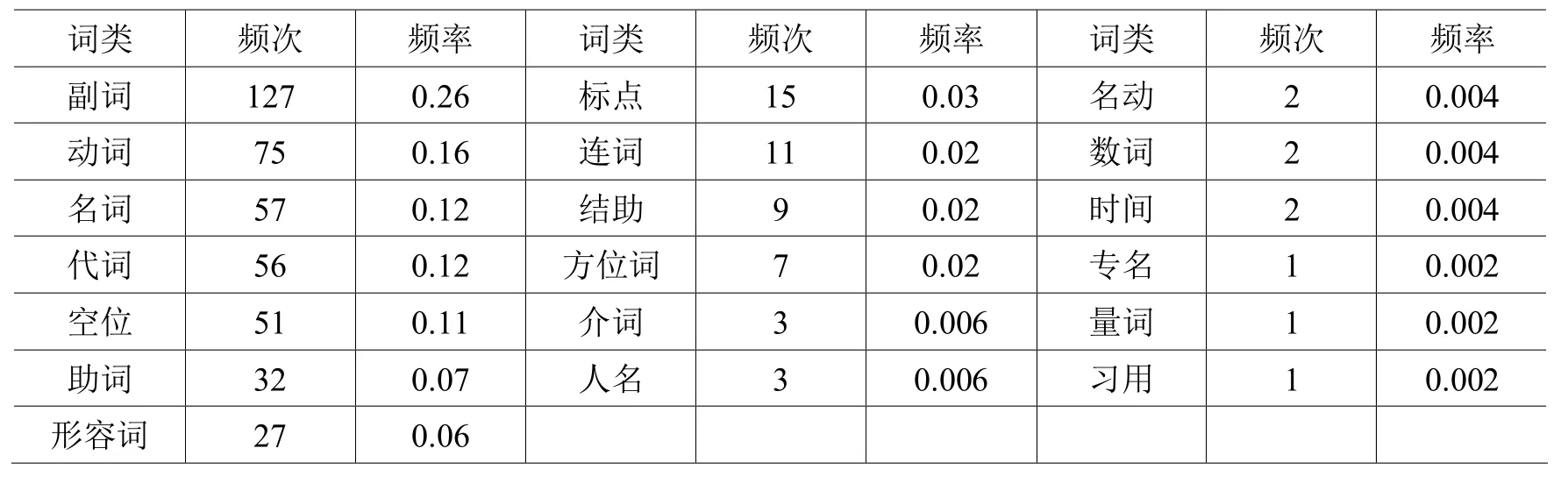
“得”左邻接词类、频次及频率列表 表1
从表1中可以看出,在490例含动词“得”结构中共有210个词语、18种词类(含标点)与“得”左邻接,连接的词语类别相对较多,并且各个词类之间的分布也较为均匀。连接频率最高的是副词,出现127频次,占总频次的26%,这可能与“得”作为一个普通动词,在通常情况下能够为副词所修饰有关。其次是动词,出现 75频次,占总频次的 16%,其中以能愿动词和单音节典型动词为主。然后是名词、代词、助词和形容词,虽然数词、量词、时间词、专有名词和习用语也出现连接,但频次极低。此外,与“得”左邻接还出现了51频次的空位和15频次的标点,分别占了总频次的11%和3%,这与含动词“得”结构主要充当谓语有关。
(二)动词“得”右邻接特征分布
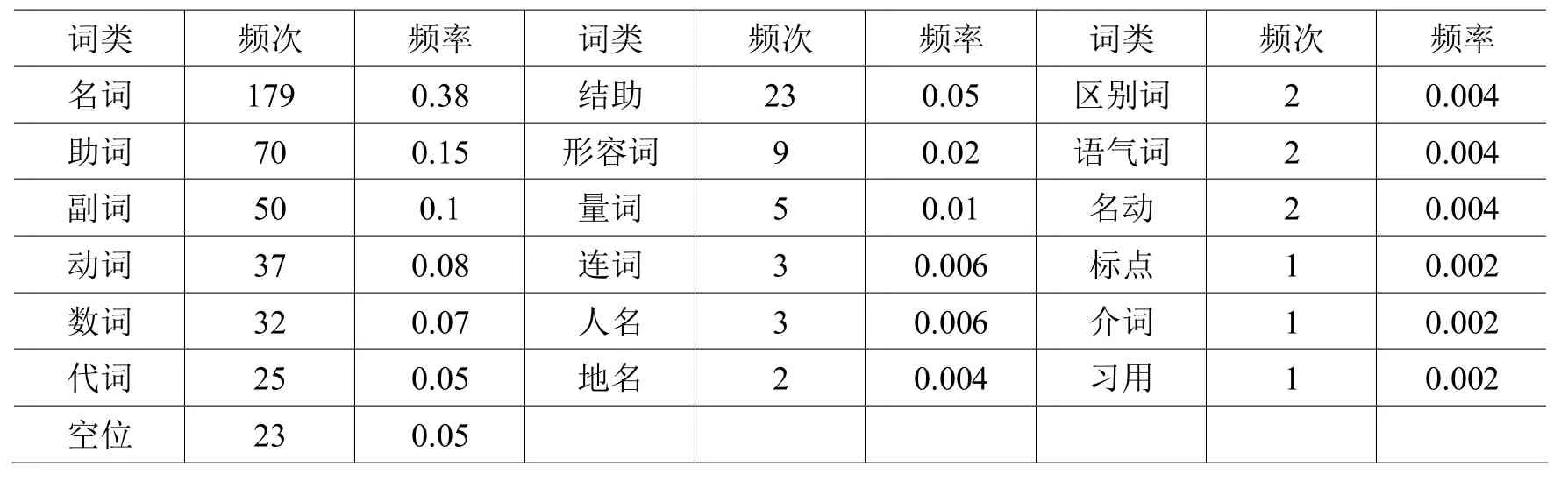
“得”右邻接词类、频次及频率列表 表2
表2中显示,在490例含动词“得”结构中共有172个词语、18种词类(含标点)与“得”右邻接,同样,连接的词语类别相对较多,只是各个词类之间的分布并不均匀,并且连接出现的高频词较为集中,如副词“不”和时态助词“了”均出现48频次,各占连接总频次的 10%。当然,连接频率最高的是名词,出现179频次,占总频次的38%,这是由于作为普通动词,“得”具有一般动词的语法功能,在通常情况下,“得”后面都要带宾语,只有在主谓谓语句中,“得”充当谓语部分的小谓语,而全句的主语正是“得”语义上的关涉对象的情况下,“得”可以不带宾语,再就是在“得”前带有结构助词“所”的格式中,“得”后也可以不带宾语,因此在“得”的右邻接中出现了23频次的空位,占总频次的5%。其次是助词,出现 70频次,占总频次的 15%,这也与一般动词能后接时态助词“着、了、过”的语法功能有关。再就是副词、动词、数词、代词、结构助词、形容词、量词、连词和出现频率极低的区别词、语气词、介词以及习用语。
二 动词“得”的左熵和右熵
为了进一步验证对于动词“得”左右接续能力的考察,我们引入熵的计算,通过数据的演算进一步说明“得”对左右邻接词语所具有的选择性。
熵是一个描述随机变量的不确定性的度量。就熵而言,一个随机变量的熵越大,它的不确定性也越大,信息量也就越大,即正确估计其值的可能性就越小;相反,一个随机变量的熵越小,它的不确定性也越小,信息量也就越小,即正确估计其值的可能性就越大。
熵的计算公式为:
如果X是一个离散随机变量,其概率分布为P(x),x∈X,则X的熵H(X)是:
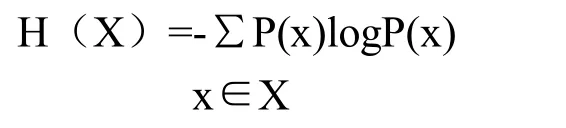
为了表现某个词或某个词类对于左右邻接关系的选择性,我们把这个词或词类记作 T,把与这个词或词类左邻或右邻的词语单位看作随机变量L和R,把L和R的取值记作c,则L和R对于T的条件熵(称作T的左熵和右熵),分别为:

f表示频次。
显然,左熵和右熵越小,T左右邻接词语的不确定性越小,确定性越大,或者说T对左右邻接语言单位的选择性就越强;反之,左熵和右熵越大,T左右邻接词语的不确定性越大,确定性越小,或者说T对左右邻接语言单位的选择性就越弱。
(一)动词“得”左右熵的计算
这里我们把“得”当作 T,通过归并,使与动词“得”邻接的语言单位都以(词)类的形式邻接,然后在自建的真实文本数据库中,计算出“得”的左熵和右熵,计算结果如下:
左熵H(L/T)= 0.979301 右熵H(R/T)=0.882221
从“得”左熵和右熵的计算结果可以看出,动词“得”的左熵和右熵都很高,并且左熵高于右熵,这说明动词“得”的左右邻接词语(类)的不确定性很大,即动词“得”对左右邻接语言单位的选择性强,并且左边的选择性又强于右边。这正说明“得”作为普通动词,其语法功能和句法组合具有较大的灵活性,能与其左右邻接的词语类别和词形数量较多。
(二)动词“得”不同接续关系左右熵的计算
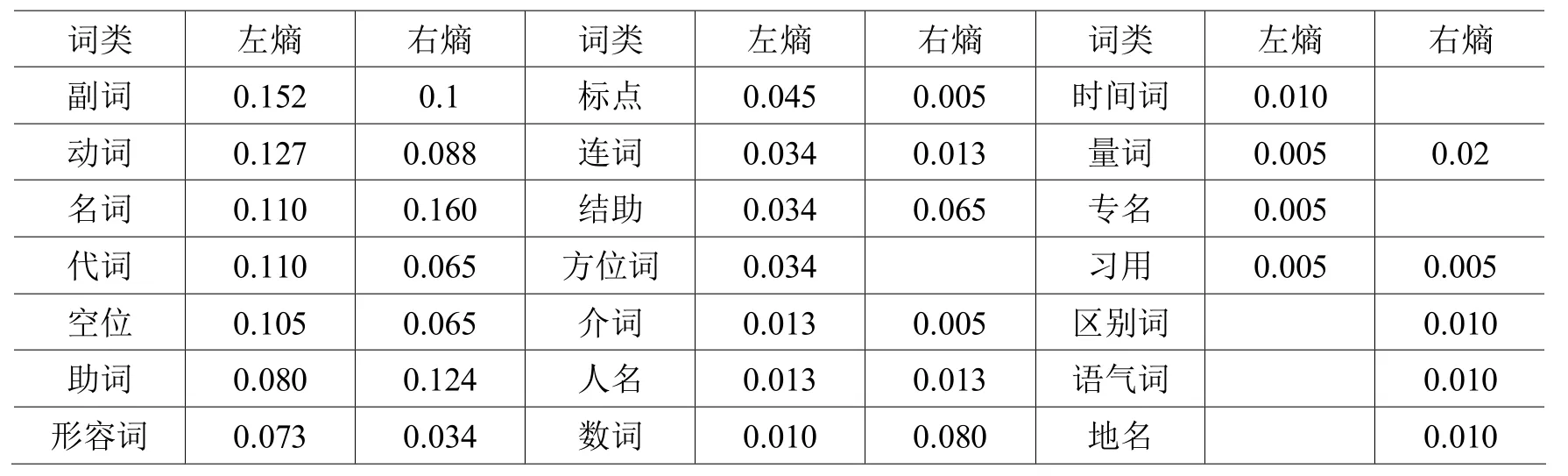
“得”不同接续关系的左熵与右熵 表3
从表3中熵的计算结果可以看出,动词“得”在与不同词类的接续关系中熵值各不相同,甚至相差很远。例如,动词“得”对所有能与之邻接的词类表现出了较强的倾向性,在与副词的邻接中左熵最大,因此,对副词的选择不确定性强,信息量大,正确估计其值的可能性小,这与“得”作为普通动词最易受到副词的修饰相一致,而在与介词的邻接中右熵最小,因此,对介词的选择确定性强,信息量小,正确估计其值的可能性大,这也说明了动词“得”的宾语更多时候为名词性成分,而非谓词性成分,故动词“得”与名词接续,右熵最大。
这一计算结果将为后续搭配概率的统计分析提供有利的数据支持。
在对汉语动词“得”的左右邻接特征的考察中,我们以量化研究为基石,以概率统计为基本手段,以“数据驱动”为基本理念,实现了在大规模的语料库范围内采用基于统计的方法对动词“得”在真实文本中的前后接续情况进行了穷尽性考察。考察结果表明,“得”的左邻接,连接词类相对较多,且各词类之间的分布也较为均匀,以副词邻接频次最高,与动词邻接,则以能愿动词和单音节典型动词为主;“得”的右邻接,虽然连接的词类同样较多,但分布并不均匀,高频词较为集中,以名词邻接频次最高。这与“得”作为一个普通动词,具有一般动词的语法功能,且含动词“得”结构主要充当谓语有关。
为了进一步说明“得”对于左右邻接关系的选择性,我们引入了“熵”的概念,通过对“得”的左右熵及不同接续关系的左右熵的计算,其结果进一步验证了我们在大规模真实文本中对于动词“得”左右邻接特征的考察,也为今后搭配概率的统计分析提供了有利的数据支持。
白硕 1995《语言学知识的计算机辅助发现》,科学出版社。
陈晓明、周渝 2004 汉语部分句法分析的研究和发展趋势,《贵州大学学报(自科版)》第4期。
冯志伟 1992 计算语言学对理论语言学的挑战,《语言文字应用》第1期。
汉语大词典编辑委员会 1991《汉语大词典》,汉语大词典出版社。
黄昌宁 1993 关于处理大规模真实文本的谈话,《语言文字应用》第2期。
李文浩 2013“都”的指向识别及相关“都”字句的表达策略,《汉语学报》第1期。
吕叔湘 1980《现代汉语八百词》,商务印书馆。
马希文 1989 从计算语言学角度看语法研究,《国外语言学》第3期。
吴蔚天、罗建林 1994《汉语计算语言学——汉语形式语法和形式分析》,电子工业出版社。
俞士汶 1999《现代汉语语料库加工——词语切分与词性标注规范与手册》,北京大学计算语言学研究所。
俞士汶等 1998《现代汉语语法信息词典详解》,清华大学出版社。
詹卫东 2000 80年代以来汉语信息处理研究评述,《当代语言学》第2期。
中国社会科学院语言研究所词典编辑室 1996《现代汉语词典》(修订本),商务印书馆。
