基于改进支持向量机的车牌识别
2014-03-23赵明敏
赵明敏, 田 丽
(安徽工程大学 电气工程学院, 安徽 芜湖 241000)
近年来,由于人类对自然环境的破坏,天气的反常变化越来越多,甚至有些地方是一年有一大半时间被雾笼罩。我们的任务就是在雾霾天气的时候,让监控摄像机可以拍摄到想要的车辆画面,同时可以去除噪声,较好地识别车辆,有效地进行交通车辆管理。
1 车牌自动识别系统
雾霾天气下的车牌识别系统是一种基于图像处理与模式识别技术的图像识别系统,车牌识别系统[1]的实现步骤如图1所示。

图1 车牌自动识别系统实现流程
图像采集通常由摄像装置来完成车牌的图像拍摄,图像处理是对所采集到的图像进行压缩、转换等技术处理,并利用相应的算法提取出车牌的特征,达到我们所需要的清晰度。然而由于车辆运动状态以及雾霾天气的影响,车牌的定位与分割的主要目的是在图像处理后的灰度图像中确定车牌的具体位置,并将包含车牌字符的子图像从整个图像中分割出来,以便进行字符识别。本文使用的方法是基于改进后的支持向量机进行车牌识别[2],能够有效解决当前训练样本数量和特征值较少的车牌字符的精度问题。
2 图像预处理
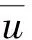
(1)
其中w(q)表示G(x,p)的权值,离p点越近,它的权重越大。图像A和图像B的低频系数矩阵的小区域方差[4]特性可以表示为G(A,p)和G(B,p)。此外,定义M2(p)为图像A和图像B的低频系数矩阵在p点的方差匹配度:
(2)
通常M2(p)的取值在0和1之间变化,它的值越小说明两幅图象的低频融合系数的相关程度越低,反之则越高。
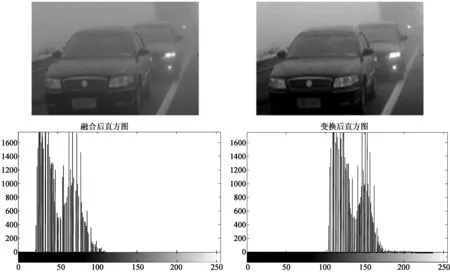
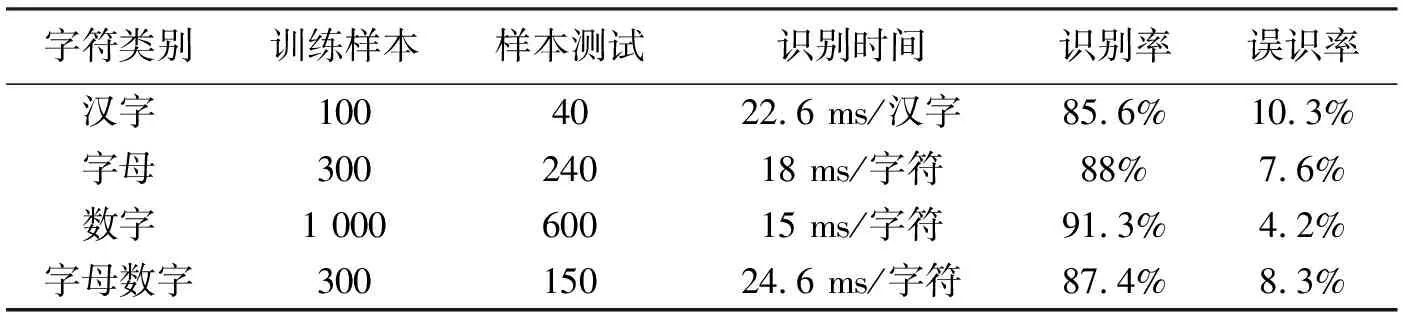
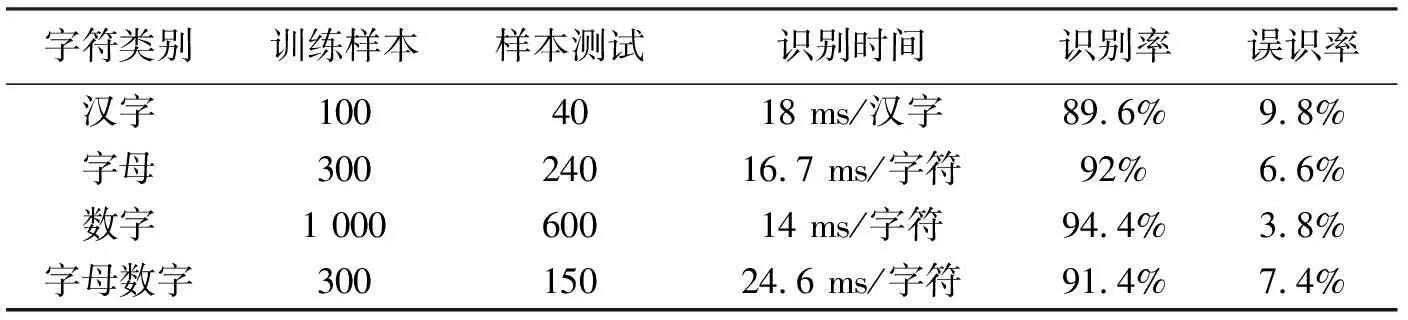
假设T2为匹配阈值,一般取0.5~1。当M2(p) 当M2(p)≥T2时,我们采用的融合策略: 该方法的策略不是基于像素之间的关系,而是基于方差的区域,可以有效保持边缘和细节,因此合成的图像会更清晰,细节较为丰富。 尽管突出了许多图像的细节信息,图像色彩却表现的过于饱和,如图2(a)所示。大量的实验表明,低频融合方法最后经过小波变换[5]、分解,其低频系数的平均值与高频系数的峰值会进行重构,生成的图像既突出了原有图像的细节,又保留了原有图像的逼真度,最终增强了图像效果,如图2(b)所示。 (a)小波低频融合图像 (b)小波变换后图像图2 图像复原 经过小波变换处理后,图像需要车牌定位、图像二值化、边缘检测等处理。一个标准的车牌是由汉字、字母和阿拉伯数字共同组成的,因此我们设计了三个分类器——汉字分类器、数字分类器和字母分类器,提取其特征向量。针对每一个样本文件,设置其中特征向量的分类标号,开始识别某一字符之前,仍需经过预处理和特征提取两步得到代表该字符的特征向量。 支持向量机(Support Vector Machine,SVM)是基于分类问题提出的,但对车牌字符的识别是一个多类别的模式识别问题。本文对去雾后的车牌图像采用改进后的支持向量机算法提取特征值,从而识别出车牌的字符。本文使用的算法与传统SVM算法不同,其基本思路是采用相同阈值的支持向量机多目标输出回归的算法。 SVM的回归问题通常都是单一的目标输出,当前多目标输出一般使用多阈值的方式,相当于用单一目标的特征值重复被提取多次,效果不佳。故我们采用相同的阈值多目标SVM算法。常用的参数优化是网格搜索法,采用2的n次方将区域切割为离散数,导致搜索范围不均匀分布,并且增加了运算量,故提出启发式优先搜索,SVM参数和特征向量的优化过程需要一个评估标准。该标准一般采用k折交叉验证,从而验证均方误差系数。我们预先设定好某个SVM参数,而后进行k折交叉验证:将训练样本集任意分成k个两两不相交的子集,每个k折的大小一致;对随机一组参数建立线性回归模型,用最后一个子集的误差平均值来评价系统参数的性能;反复迭代以上过程k次,所有的子集都有可能进行测试,k-1次迭代后即可得到到最终误差平均值;用该算法的误差平均值来评估SVM的学习能力。 误差平均值的均方误差: (3) 样本的偏差为ε1,ε2,…,εn。 采用的相关系数[6]如下: 其中x是目标值,y是干扰值,0≤r≤1,r的值越靠近1越好。 SVM的参数和参数范围与核函数的选择有关,根据理论分析,我们采用ε-SVR分类,核函数选择sigmoid核。以下提出的方法是采用多目标输出支持向量机[7]使用相同阈值,m表示目标数,n表示训练集数,z表示特征数。 已知训练集: 其中: (4) 约束条件: 得出最优解: 构造决策函数: (5) 求出阈值变量b: 核函数选取: (6) r取经验范围[0,1 000]。Gamma取[0,1],非正定核,其smo运算容易进入无穷循环,最大迭代次数的上限取20 000次。 SVM是将低维空间中的向量投影到高维空间,将低维非线性可分问题转化为线性可分情形。利用Mercer-kernel可以计算两向量在高维空间中的点积,从而计算出各向量在高维空间中的投影。 我们选取200幅图像进行理论分析,使用传统方法与本文提出的图像去雾后字符特征值提取方法相进行对比实验。从中选取汉字样本100个,字母样本300个,数字字符1 000个,字母数字字符300个。对每一类字符,均选取70%的样本字符作为训练样本,30%的字符作为测试样本。传统方法和本文改进后的字符分类识别结果见表1和表2。 表1 传统方法字符分类识别结果表 表2 改进后字符分类识别结果表 通过表1和表2的实验数据表明:改进后的方法在与传统方法相比,字符识别的时间和速度,都有相应的提高,误识率有所降低;但是车牌中不同的字符类别识别的速度和精度不一样,汉字由于本身的复杂性,识别时间较长,识别率相比以前提高3.3%,误识率降低0.5%;字母的识别和以前相比,识别时间降低1.3 ms,识别率提高了4%;字母和数字由于构造相对复杂,识别时间没有减少,但是识别率提高4%,误识率也降低了1.1%。改进后的方法与传统方法相比,工作效率明显提高。车牌图像的不同方法的最终识别效果如图3(a)和图3(b)所示,证明了本文方法的可行性。 (a)传统方法的车牌识别结果 (b)改进后的方法车牌识别结果图3 车牌识别结果 通过仿真对比分析,我们建立的车牌识别模型经过小波低频融合的预处理,然后使用相同阈值的SVM多目标输出回归的算法对车牌图像的特征值提取,对车牌字符有效地识别,与常规方法相比,不仅提高了识别的速度,而且提高了精度。具有一定的优越性,是专门对雾霾天气下行驶车辆有效地进行识别,具有一定的实际意义和应用价值。 本文改进后的支持向量机算法实现车牌字符的识别,是将归一化后的字符像素信息做为特征向量被提取,获得了相对较高的识别速度和识别率,降低了问题的复杂度,提高了工作效率。但是,图像预处理过程中部分字符会发生形变,加上有些字符本身就很复杂,容易与其它字符混淆,导致了较高的误识率。如何能够在保证识别速度的同时提取字符特征向量,以便使字符误识率降低为零,还有待于进一步研究。 [参考文献] [1] 王大印.基于数字图像处理的车牌识别系统[D].北京:北京工业大学,2003. [2] 董燕,朱永胜,刘聪.图像融合技术在车牌识别中的应用[J].计算机测量与控制,2013,21(3):791-793. [3] 晁锐,张科,李言俊.一种基于小波变换的图像融合算法[J].电子学报,2004,32(5):750-753. [4] 刘震,那彦.基于自适应区域方差的图像融合方法[J].电子科技,2013,26(10):67-69. [5] 郭彤颖,吴成东,曲道奎.小波变换理论应用进展[J].信息与控制学报,2004,33(1):67-69. [6] JANMEY P A,BALE M D,FERRY J D.Polymerization of fibrin:analysis of light-scattering data and relation to a peptide release[J].Biopolymers,1983,22(9):2017-2019. [7] 龚乾春.支持向量机在多目标优化中的仿真应用[J].计算机仿真,2010,27(8):205-207.
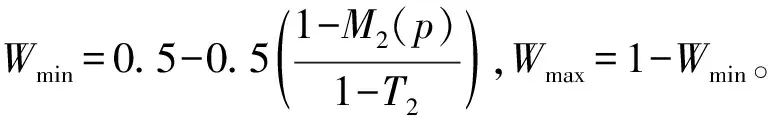
3 字符识别
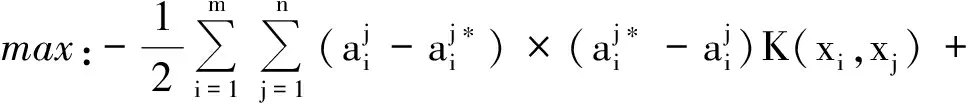
4 实验结果分析

5 结 语
