基于Web数据挖掘的多因素科技专家信息提取方法
2013-08-22朱全银尹永华刘金岭
朱全银,周 培,尹永华,陈 浮,刘金岭
(淮阴工学院计算机工程学院,江苏 淮安 223003)
0 引言
近年来,随着Web技术迅猛发展,网络上积累了大量的信息,由于网页信息的半结构化,无法像传统数据库系统那样直接使用。如何更好地利用这些信息成为人们关注的热点[1]。但是在纷繁复杂的Web信息库中准确地获取信息的难度也进一步加大。Web文档可以表示成非结构化文档、半结构化文档和结构化文档,目前大部分页面都以半结构化文档即HTML形式给出[2]。国内外针对正确提取Web文档有效信息做了大量的研究工作。Lin S.H.提出信息块的概念 ,以页面中Table标签作为处理元素,将页面分割成块[3]。对于使用同一个模板生成的网页集,找出在该网页集中多次出现的内容,作为冗余内容,而共同出现较少的内容块作为信息块。但该方法必须局限于同一模板的网页集,因此不够通用。孙承杰等提出一种基于统计的方法来实现对新闻类网页主题信息的抽取,实现简单,对新闻类网页处理效果不错,但该方法只适合于网页的所有主题信息位于同一个Table标记中的情况[4]。王琦等基于DOM(Document Object Model)规范,扩展了STU(Semantic Textual Unit)模型,提出STU-DOM树模型,在删除无关节点的同时有效保留了与主题相关的文字和链接[5]。但该文并没有区分Table标签的两种不同作用,对于结构复杂、噪音较多的网页会留下较多的噪音信息[6]。
本文在以往基于Web信息提取的基础上[7-13],在江苏省各高校网站上选取科技专家介绍页面,研究基于Web数据挖掘的多因素科技专家信息提取方法。
1 科技专家网页正文信息提取算法
1.1 科技专家网页段落介绍样式
通过对江苏省大多数高等院校网页的观察统计,目前对于科技专家的简介分为以下两种样式:
(1)以图表格式呈现。由 特征词“姓名”、“性别”、“出生年月”、“职称”、“联系方式”等特征词组成的图表。如江苏省南京理工大学A教授的简介页面(http://cs.njust.edu.cn/szdw/ShowArticle.asp ArticleID=27),如图1所示。
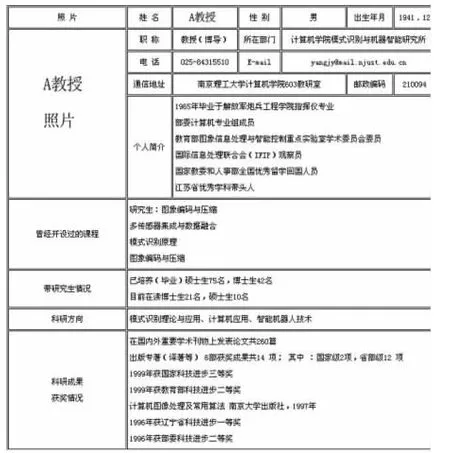
图1 特征词组成的图表呈现形式
(2)以段落文本描述性文字呈现。段落文本包含“姓名”、“性别”、“出生年月”、“职称”等特征词。如江苏省东南大学中国科学院院士B教授的介绍页面(http://rsc.seu.edu.cn/s/98/t/81/a/7068/info.htm),如图 2 所示。

图2 特征词组成的段落文本呈现形式
1.2 专家信息提取算法
定义1:设M为网页源文本,S为网页提取正文。则:

定义2:设K为特征词序列,则:
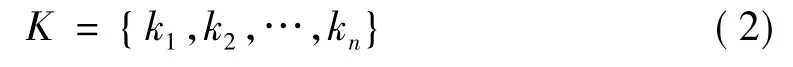
定义3:设特征词kn在S中的位置为P,则:
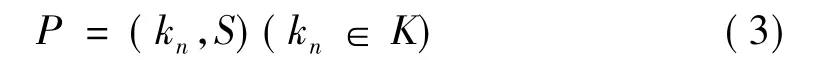
定义4:设特征词之间的距离(特征词在正文文本中的位置的差值)为D,则有:
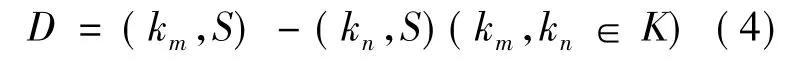
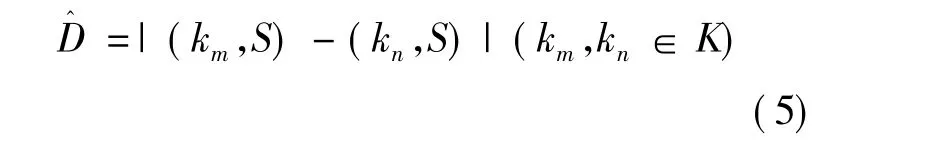
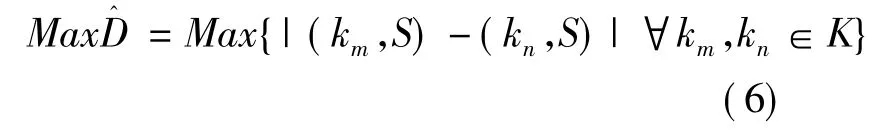

1.3 专家信息提取步骤
本文着重讨论特征词组成的段落文本形式的科技专家信息的提取方法。
通常在同一文本中的词汇、字串之间一般都存在着很强的依赖关系,如上下位关系、同义关系等,因此,对词汇、字串之间的这些关系进行分析将有助于提高文本分析的准确性。本文着重比较特征词之间的位置关系。计算已匹配特征词与潜在特征词之间的绝对距离,最小绝对距离即为专家信息关键词。
具体地说,本文提出的科技专家信息提取方法通过如下各步骤实现科技专家信息的提取:
第1步,通过给定的URL,获取目标网页源代码,即M,过滤网页脚本、网页样式、HTML标签等,获得正文文本S;
第2步,在已有特征词语料库的基础上匹配专家性别、职称、出生年月、籍贯等专家信息文本,得到特征词序列 K1={k1,k2,…,kn};
第3步,通过公式(3)计算特征词序列K1中各特征词在正文文本S中的位置,得到特征词位置序列 P1={p1,p2,…,pn};
第4步,调用中国科学院计算所的ICTCLAS分词系统,对正文文本S进行分词,得到潜在姓名特征词序列 K2={k1,k2,…,kn};
第5步,通过公式(3)计算特征词序列K2中各特征词在正文文本 S中的位置,得到特征词序列P2={p1,p2,…,pn};
第6步,通过公式(5)、(6)、(7)计算序列P1和P2的绝对距离,并得出 Max和 Min,取Min的特征词作为专家信息关键词,并在潜在特征词序列中删除该潜在特征词;
第7步,通过公式(5)计算匹配得到的专家信息关键字段之间的绝对距离,若过大(通常与20~30相比较),则舍弃该专家信息关键词;
第8步,输出科技专家信息。
2 实验分析
为了验证本文提出的专家信息提取方法的有效性,从江苏省内的南京大学、东南大学、南京理工大学、南京邮电大学、南京师范大学等高校网站选取100个科技专家介绍页面作为实验对象。经过本文提出的基于数据挖掘的多因素科技专家信息提取方法对这100个页面进行信息提取后,有如下几种情况:
(1)网页文档中的专家信息提取无缺失无错误,源网页截图如图3所示。

图3 C教授信息源网页
由本文提出的科技专家信息提取方法实现的系统中提取的C教授的专家信息为:姓名:“某某”、性别:女、职称:教授 、职位:博士生导师、出生年月:1940年2月出生、出生地:源网页未提及。
(2)网页文档中的专家姓名信息提取错误,错误原因:经过中科院分词系统分词后,选取潜在人名时错误,源网页截图如图4所示。
由本文提出的科技专家信息提取方法实现的系统中提取的D教授专家信息为:姓名:“某某”、性别:女、职称:教授、职位:硕士生导师、出生年月:1963年5月出生、出生地:江苏扬州人,其中正确姓名为“某某某”,系统提取的姓名为“某某”。

图4 D教授信息源网页
(3)网页文档中专家出生年月信息提取出错,错误原因:特征词匹配出错,源网页截图如图5所示。

图5 E教授信息源网页
由本文提出的科技专家信息提取方法实现的系统中提取的E教授专家信息为:姓名:“某某某”、性别:女、职称:教授、出生年月:1969年3月江苏生、出生地:江苏睢宁人,其中正确出生年月为“1953年3月生”,系统提取的错误出生年月为“1969年3月江苏生”。
(4)网页文档中专家出生地信息提取出错。错误原因为特征词匹配出错,源网页截图如图6所示。

图6 F教授信息源网页
由本文提出的科技专家信息提取方法实现的系统中提取的 F教授专家信息为:姓名:“某某某”、性别:男、职称:教授、出生年月:1960年8月生、出生地:江苏省“六大人”,其中正确的出生地为“河北昌黎人”,系统提取的错误出生地为“江苏省“六大人”。
(5)网页文档中专家信息提取不完整,错误原因为特征词匹配不成功,源网页截图见图7。

图7 G教授信息源网页
由本文提出的科技专家信息提取方法实现的系统中提取的G教授专家信息为:姓名:“某某某”、职称:教授 、出生年月:无,出生地:无,其中文档信息中包含出生年月为“1943年12月出生”,出生地为“江苏无锡”。系统提取信息中未包含出生年月和出生地。
以上是在本文提出的基于Web数据挖掘的多因素科技专家信息提取方法下提取网页文档中科技专家信息出现的几种情况。经过系统对100个科技专家页面的信息提取以及结果统计,得到专家信息提取中的各专家信息字段提取错误率与缺失率如表1所示。

表1 科技专家信息各字段提取错误率
经过统计,在选取的100个科技专家介绍页面当中,共出现431个科技专家信息字段,其中33个科技专家信息出现偏差,根据以上实验统计得出,科技专家信息提取正确率为92.34%,科技专家信息提取查全率为94.43%。
3 结束语
本文提出了基于Web数据挖掘的多因素的科技专家信息提取方法,选取江苏省10多所高校的100个科技专家介绍页面作为实验对象,获得了较好的效果,其中对于中文人名的信息提取错误率仅为2%,中文人名信息提取缺失率为0;性别和职称的信息提取错误率和信息提取缺失率都为0;出生地的信息提取错误率为6.02%,出生地的信息提取缺失率为15.66%;出生年月的提取错误率和提取缺失率分别为2.22%与12.22%。综合100个科技专家介绍页面的所有信息字段,得出科技专家信息提取正确率为92.34%,科技专家信息提取查全率为94.43%,解决了从网页信息中难以准确获取科技专家信息的问题,满足了建设科技专家基础信息数据库的应用系统需求。
[1]Lai Jianbing,Liu Qiang,Liu Yi.Web information extraction based on Hidden Markov Model[C].Proceedings of the 14th International Conference on Computer Supported Cooperative Work in Design,2010:234 -238.
[2]Peng Chen,Yue Zhang.Web information extraction and its application[C].Proceedings of the IEEE International Conference on Cloud Computing and Intelligence Systems,2011:448 - 451.
[3]Lin S H,Ho J M.Discovering Informative Content Blocks from Web Documents[C].Proceedings of the 8th ACM SIGKDD International Conference,2002:588-593.
[4]孙承杰,关毅.基于统计的网页正文信息抽取方法的研究[J].中文信息学报,2004,18(5):17 - 22.
[5]王琦,唐世渭,杨冬青,等.基于DOM的网页主题信息自动提取[J].计算机研究与发展,2004,41(10):182-188.
[6]吕聚旺,都云程,王弘蔚,等.基于新型主题信息量化方法的Web主题信息提取研究[J].现代图书情报技术,2008(12):50-53.
[7]刘金岭,谈芸,李健普,等.基于多因素的中文文本主题自动抽取方法[J].计算机技术与发展,2010,20(7):72-79.
[8]王红艳,朱全银,严云洋,等.商品价格数据的两种WEB挖掘算法比较[J].微电子学与计算机,2011,28(19):168-172.
[9]Quanyin Zhu,Yunyang Yan,Jin Ding,et al.The Commodities Price Extracting for Shop Online[C].Proceedings of the International Conference on Future Information Technology and Management Engineering,2010,(2):317 -320.
[10]Quanyin Zhu,Jin Ding,Yonghua Yin,et al.A Hybrid Approach for New Products Discovery of Cell Phone Based on Web Mining[J].Journal of Information and Computational Science.2012,9(16):5039 -5046.
[11]Quanyin Zhu,Pei Zhou,Sunqun Cao,et al.A novel RDB-SW approach for commodities price dynamic trend analysis based on Web extracting[J].Journal of Digital Information Management,2012,10(4):230 -235.
[12]Quanyin Zhu,Pei Zhou.The System Architecture for the Basic Information of Science and Technology Experts Based on Distributed Storage and Web Mining[C].Proceedings of the International Conference on Computer Science and Service System,2012:661 -664.
[13]Kangjing Hu,Jin Ding,Chengjie Xu,et al.The Development of Software Testing Platform of Huaian City[C].Applied Mechanics and Materials,2013:411 -414.
