一种改进的Apriori算法
2010-02-08赵军民张向娟
赵军民,张向娟,高 蔚
(河南城建学院,河南平顶山467036)
1 关联规则简述
项集I={i1,i2,…,im}是m个不同项目的集合,项目ik(k=1,2,…,m)称为数据项,m为数据项集的长度,长度为k的数据项集称为k-项集。一个事务T(Transaction)是数据项集中的一组项目的集合,即I的一个子集T⊆I。每个事务赋予一个唯一的标志符TID,所有事务的全体就构成一个事务数据库D。一个关联规则是形如X⇒Y的蕴涵式,其中各项满足X⊂I,Y⊂I且X∩Y=Φ。
定义1: 规则X⇒Y在事务数据库D中的支持度(support)是指如果D中有s%的事务同时包含X和Y,那么称关联规则X⇒Y的支持度为s%,实际上支持度就是一个概率值,记为support(X⇒Y)=P(X∪Y)。
定义2: 规则X⇒Y在事务数据库D中的信任度(confident)是指同时包含X和Y的事务数与包含X的事务数之比,即若项集X的支持度记为support(X),规则的信任度就为support(X∪Y)/support(X),用概率表示为confident(X⇒Y)=P(Y|X)。挖掘关联规则的问题就是如何产生支持度和信任度分别大于用户给定的最小支持度(minsupp)和最小信任度(minconf)的关联规则。发现关联规则需要经过以下两个步骤:1.找出所有频繁项集;2.由频繁项集生成满足最小信任度的规则[1]。
2 Apriori算法简介
Apriori算法的核心是使用候选频繁项集找频繁项集即通过k-项集搜索(k+1)-项集。为了提高频繁项集逐层产生的效率,Apriori算法定义了两个性质用于压缩空间。
性质1:频繁项集的所有非空子集都必为频繁项集。
性质2:非频繁项集的超集一定是非频繁项集。此性质用于找频繁项集的两个过程:连接和剪枝。(1)连接:通过Lk-1与自己连接产生候选k-项集的集合。该候选项集的集合记作Ck。(2)剪枝:Ck的成员可以是也可以不是频繁项集,但所有的频繁k-项集包含在Ck中,扫描数据库,确定Ck中每个候选项集的计数,计数值不小于最小支持度的所有候选项集是频繁项集,从而确定Ck,为了压缩空间,可以反用Apriori性质,任何非频繁的(k-1)-项集都不可能是频繁k-项集的子集。因此,如果一个候选k-项集的(k-1)-子集不在Ck-1中,则该候选项集也不可能是频繁的。Apriori算法产生候选项集的开销极大,特别是产生的候选2-项集对剪枝操作不但不起任何作用还需要占用大量的存储空间[2]。
3 改进算法的思想及其描述
本文提出的改进算法思想是:根据第一次扫描数据库的结果和以往经验确定候选频繁项集的项数;同时以事务长度|TID|为标准将数据库划分为若干个子数据库,避免对整个数据库的重复扫描和产生大量的候选项集,提高了算法的效率。
定义3:事务长度:每个事务中所含项的个数,记为|TID|,若某个事务中含有K项,称这个事务的长度为:|TID|=K.
性质3:候选k-项集的长度k,满足条件k≤|TID|max最大事务的长度,也就是说,候选项集都包含于某个事务之中。算法描述:
⑴扫描整个事务数据库D,计算给定项集I中各个属性项出现的概率P1,P2,…,Pm;同时计算不同长度|TID|出现的概率P1,P2,…,Pk,并以不同的|TID|为标准将数据库划分为若干个子数据库。
a.定义数组I[m],初值设为0。扫描事务数据库,求出各个属性项i1,i2,…,im的独立出现概率P1,P2,…,Pm与支持度;数组I中的每个数组元素I[1],I[2],…,I[m]记录事务数据库中各个属性项i1,i2,…,im的独立出现概率P1,P2,…,Pm的值。设定一个最小概率s,得到m个频繁项集。
b.定义数组TID[n],初值设为0。扫描事务数据库,求出各个事务长度|TID|(1,2,…,k)的独立出现概率P1,P2,…,Pk。
⑵给定最小支持度,再次扫描整个事务数据库D,将小于最小支持度的各个属性项从事务记录中删除,同时再次计算不同长度的|TID|出现的概率P1,P2,…,Pk,并以不同的|TID|为标准重新将数据库划分为若干个子数据库。比较删除前后|TID|的概率,以概率最大的|TID|结合以往挖掘的经验,确定适合的候选项集的项数k。
⑶生成所有候选项集Ck,扫描|TID|≥k的子数据库,由候选频繁项集的支持度求出频繁项集,如果生成的频繁项集不理想,则重复步骤⑵、⑶,直到生成满意的频繁项集为止[3][4][5]。
4 算法模拟与对比
有一事务数据库D,其中有10个事务记录,预定义最小支持度为20%,生成其最大频繁项集。
用原Apriori算法进行挖掘,首先扫描事务数据库D,计算候选1-项集的支持度,将支持度大于或等于20%的候选1-项项集作为频繁1-项项集,频繁1-项集与自身连接生成候选2-项集。再次扫描事务数据库D计算候选2-项集的支持度,利用剪枝将不满足最小支持度的候选2项集删除,生成频繁2-项集,频繁2-项集再次与自身连接,生成候选3-项集。再一次扫描数据库,使用相同的方法生成频繁3-项集。频繁3-项集再次与自身连接生成候选4-项集,第四次扫描数据库计算候选4-项集的支持度,发现候选4-项集不满足最小支持度的要求,从而得知最大频繁项集为频繁3-项集{abc}、{abd}、{abe}。原Apriori算法生成频繁项集的过程如图1所示。

图1 Apriori算法生成频繁项集过程
用改进算法产生频繁项集的过程如下:扫描事务数据库,计算候选1-项集的支持度,将支持度大于或等于20%的候选1-项集作为频繁1-项集,根据统计的事务长度的数字1、2、3、4出现的概率分别为0%,10%,70%,20%可知事务长度为3的事务占了70%,参考以前的挖掘经验,为了不使某些规则遗漏我们把候选项集的项数暂定为4,生成所有的候选4-项集,根据不同|TID|划分的子数据库计算各个候选项集的支持度,结果都不满足最小支持度的条件,把候选项集的项数定为3重复以上过程,得出满足最小支持度的频繁3-项集{abc},{abd},{abe}。改进算法生成频繁项集的过程如图2所示。
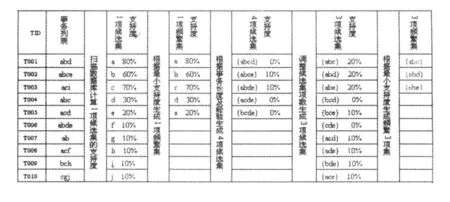
图2 改进算法生成频繁项集过程
从以上的挖掘过程来看,Apriori算法要重复地对事务数据库进行扫描,每生成一个更长的候选项集就需要扫描数据库一次,而且数据库的长度没有任何变化,这对海量数据来说将会造成时间的浪费。在连接步过程中,生成了大量对以后无用的小项频繁项集,造成了存储空间的浪费。特别是在生成小项候选集时,数量是海量的。这些是Apriori算法存在的问题。改进的算法在这些方面作了一些改进:在频繁项集的生成过程中,根据事务长度|TID|出现的概率及以往的经验确定最终频繁集的预计长度,只需要生成频繁1-项集和待生成频繁项集,避免生成海量小项集,节省了存储空间并且减少了扫描数据库的次数。以事务长度|TID|为标准将数据库划分为若干个子数据库,避免了对整个数据库的扫描,只需扫描子数据库。与Apriori算法相比,改进算法在时间和空间上效率都有所提高。
5 结束语
这种算法适合挖掘海量数据集的大项频繁项集的关联规则。但是算法中最终频繁项集的设定是依据|TID|值的概率、以往的挖掘经验及人们的购买习惯,因此有一定的主观性。如果频繁项集项数设定不合适,有可能会遗漏一些用户感兴趣的关联规则,目前的解决方法是:根据人们的购买习惯、|TID|值及以往挖掘的经验共同确定待挖掘频繁项集的项数,为了确保不遗漏一些用户感兴趣的关联规则,可以在首次挖掘时设定较大的频繁项集项数。
[1] 王小虎.关联规则挖掘综述[J].计算机工程与应用,2003(33):190-193.
[2] 李雄飞,李军.数据挖掘与知识发现[M].北京:高等教育出版社,2003.
[3] 徐章艳,刘美玲,张师超,等.Apriori算法的三种优化方法[J].计算机工程与应用,2004(36):190-192.
[4] 黄进,尹治本.关联规则挖掘的Apriori算法的改进[J].电子科技大学学报,2003,32(1):76-79.
[5] 刘巍,蒋华.挖掘关联规则中Apriori算法的改进与优化[J].计算机与现代化,2006(11):113-115.
