数据挖掘中关联规则衡量方法的改进
2010-06-05赵军民王军豪
赵军民,王军豪,高 蔚
(河南城建学院,河南平顶山467036)
1 关联规则
假设I是一个项集,对于一个特定的事务数据库D,其中每个事务T是I的非空子集,即每一个交易都与一个唯一的标识符TID(Transaction ID)对应。对项集I和事务数据库D,T中所有满足用户指定的最小支持度Minsup(Minsupport)的项集(即大于或者等于Minsup的项集I的非空子集)称为频繁项集(Frequent Itemsets)。在频繁项集中挑选出所有不被其他元素包含的频繁项集称为最大频繁项集(Maximum Frequent Itemsets)。事务数据库D在项集I上满足最小支持度以及最小信任度Minconf(Minconfidence)的关联规则被称为强关联规则,否则就被称为弱关联规则[1]。
2 基于兴趣度约束的关联规则
在数据挖掘的过程中,通常情况下可能会挖掘出上千条的规则,但是并不是所有的规则都对用户有用。为了提高挖掘出的规则的质量,使之对用户来说更新颖、更容易理解,就需要一个更有效的挖掘算法。为了以用户的需求和兴趣为最大目标,尽量减少扫描次数,将无意义的和虚假的规则剔除掉,这里引入了一种约束条件-兴趣度约束。当前最常见、也是最常用的两个兴趣度度量是支持度和信任度,但是仅靠这两个度量标准还存在一定的缺陷[2]:
⑴会产生大量的规则,而其中的大部分是显而易见的或不相关的;
⑵用户没有充分利用领域知识和职业直觉。用户的职业直觉往往对知识发现的过程具有重大的价值;
⑶没有提供好的度量令人感兴趣程度的方法,而从数据中发现令人感兴趣的规则是数据挖掘的一个重要目标。
在实际应用中,挖掘的关联规则可能因为以下原因失去有趣性:①挖掘的规则符合先验知识或期望值;②挖掘的规则可能涉及非有趣属性或属性组合;③规则冗余。本文主要讨论关联规则令人感兴趣程度的度量问题,并给出一种新的综合度量方法。
3 关联规则的综合度量
要看一条规则是不是有趣的,要从确定性、有用性、非预期性和简洁性几个方面进行综合的度量[3]。
3.1 确定性
确定性是规则的有效性以及值得信赖程度的反映。在挖掘过程中,对于像A⇒B这样的关联规则,它的确定性度量就是信任度。信任度是对关联规则的准确度的衡量,表示一个商品的购买暗示着另一个商品的购买。
3.2 有用性
有用性是用来衡量一条规则是否具有有趣性的一个重要因素,它可以用支持度来进行度量。支持度表示用这条规则可以推出百分之几的目标,它也是对关联规则重要性的度量,支持度说明了这条规则在所有事务中占多大的代表性。
3.3 简洁性
简洁性是针对规则的形式而言的,一般指规则的总体简洁性,是用来衡量关联规则的最终可理解程度的指标,并用规则的属性个数或者规则中出现的操作符来进行定义的[4]。它表现在两个方面:一方面表现在规则的项数上,如果规则项数很多,会不利于对这条规则的理解。因此,规则的项数越少,规则的简洁性越好。另一方面表现在规则所包含的抽象层次上,规则包含的抽象层次越高,它对应的解释力越强。
3.4 非预期性
具有非预期性的规则是那些提供新的信息或者跟先验知识相矛盾的规则。非预期的规则出乎客户的意料,与用户的期望相矛盾。传统的关联规则挖掘算法中,用条件概率P(B︱A)=P(A∪B)/P(A)来表示,也就是用信任度作为约束对规则的非预期性进行判断,但它只是给定的A和B的条件概率的估计值,而并没有度量A和B之间蕴涵的实际强度。我们将项集I1和I2之间的影响程度用提升度来进行度量。
定义1:提升度(lift)是利用相关分析来描述规则内在价值的度量,它所描述的是项集I1对I2的影响力的大小。提升度越高,表示I1的出现对I2出现的可能性影响越大,它是对I1和I2之间蕴涵的实际强度的度量。提升度是一个比值:

也可以用P(I2︱I1)/P(I2)来表示。它又分为两种情况:
⑴当lift>1时,表示I1和I2是相关的,代表I1的出现蕴涵了I2的出现,此规则是非预期的、有效的或者有趣的。
⑵当lift<1时,表示 I1和I2是不相关的,规则不是非预期的,是无效的、无趣的,应将其删除。
提升度的值越大,表明两者之间的相关性就越强,规则越有效、越有趣,其利用的价值也就越大[5]。
根据上面规则的度量标准,需要对强关联度重新进行定义,定义如下所示:
定义2:对于事务数据库D,如果I1⇒I2能同时满足以下条件,则称之为强关联规则,否则就称之为弱关联规则,其中Maxlen为最大规划长度。
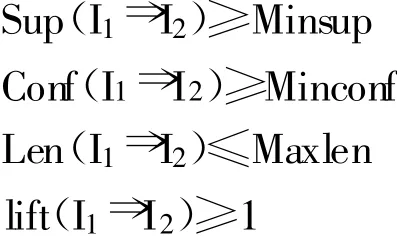
那么,在事务数据库D中挖掘关联规则的问题也就变为:产生所有支持度、信任度分别大于最小支持度和最小信任度,规则长度小于最小规则长度,并且提升度的值大于1的关联规则,也就是找出所有的强关联规则。
4 基于综合度量的关联规则算法设计
以Apriori算法为基础,保留原有的最小支持度、最小信任度这两个衡量指标,并将提升度(lift)以及最大规则长度这两个衡量标准引入到算法中,使之挖掘出更有趣、有效的关联规则。
算法1:产生长度不超过Maxlen的频繁项集
输入:事务数据库D;最小支持度阈值Minsup;最大规则长度的阈值Maxlen
输出:频繁项集L

算法2:产生有趣的关联规则
输入:频繁项集L;最小支持度阈值Minsup;最小信任度阈值Minconf;提升度阈值lift;最大规则长度的阈值Maxlen
输出:强关联规则R

{频繁项集Lk的所有子集
for每一个s都属于SK
If信任度≥Minconf and提升>1 then输出强关联规则R

5 算法实现及性能分析
使用Microsoft Visual Basic实现Apriori算法,并引入支持度、信任度、提升度及规则长度相结合的综合度量标准。此程序可以任意输入支持度、信任度、提升度和规则长度的阈值,并统计运行过程所耗费的时间。
程序界面如图1所示。

图1 关联规则算法运行界面
由于Apriori算法在运行过程中需要多趟扫描数据库,使得算法的运行非常耗时。可以分别利用事务数据量为100、200、500、1000、2000、5000、10000和50000的数据集在相同环境下对程序进行测试,结果如表1和图2所示。

表1 算法运行时间
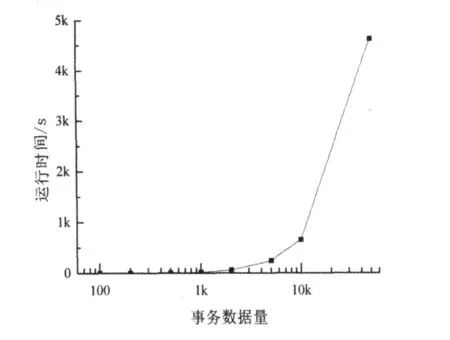
图2 算法运行效率
表1、图2利用综合衡量的方法处理经过整理的数据。这里设最小支持度为0.1,最小信任度为0.25,提升度(lift)应大于或等于1,最大规则长度为3。通过运行后得到了有效的关联规则,与单纯的支持度-信任度相比,减少了无效的关联规则。表2是列出的部分关联规则。

表2 关联规则
6 小结
分析表1和图2可知,随着数据量的变大,算法所需时间呈指数上升趋势。因为需要多次扫描数据库,所以I/O负载太大,对每次K循环,候选项集中的每个元素都必须通过扫描一次数据库来进行验证是否加入频繁项集。另外,算法还有可能产生非常庞大的候选项集,太大的候选项集对时间和主存空间都是一种很大的挑战。所以,该算法虽然有一定改善,仍需要进一步的改进。
[1]陈景民.数据仓库与数据挖掘技术[M].北京:电子工业出版社,2002.
[2]B Padmanab han,A Tu zhilin.Unexpectedness as a measure of interestingnessinknowledge discovery[J].DecisionSupport System,1999:303-318.
[3]Fayyad U,Piantesky-shapiro G.From Data Mining to Knowledge Discovery.Advances in Knowledge Discovery and Data Mining[J].California:AAAI Press,1996:1-363.
[4]Jiawei Han,Micheline Kamber.数据挖掘概念与技术[M].范明,孟小峰,译.北京:机械工业出版社,2001.
[5]吴永梁,陈烁.基于改善度计算的有效关联规则[J].计算机工程,2003,29(13):98-100.
