基于机器学习的电商平台客户投诉精准定位研究
2025-02-13景奕昕




摘要:针对当前电商平台中客户投诉处理效率低下、解决周期长且准确率不高等问题,本文提出一种基于机器学习的客户投诉精准定位方法;针对收集到的客户投诉文本进行预处理,以确保后续分析的有效性;采用BERT等深度学习技术来提取投诉文本中的关键特征,以反映投诉的主要内容和情感倾向;基于此特征集,构建一个卷积神经网络模型,自动识别和分类客户投诉的不同类型及其优先级;最后,通过对比实验验证了所提方法的有效性和优越性。本方法的整体平均F1分数为0.96,预测标签与真实标签之间的差异程度为0.05,紧急投诉响应时间预测误差仅为0.45 h,为电商平台提供了一套高效、可靠的客户投诉管理方案。
关键词:机器学习;电商平台;投诉定位
doi:10.3969/J.ISSN.1672-7274.2025.01.006
中图分类号:F 713.36;TP 393.4" " " " " " " " "文献标志码:A" " " " " " 文章编码:1672-7274(2025)01-00-04
Research on Precise Positioning of Customer Complaints on e-Commerce Platforms Based on Machine Learning
JING Yixin
(Wuhan IPASON Technology Co., Ltd., Wuhan 430000, China)
Abstract: In response to the low efficiency, long resolution cycle, and low accuracy of customer complaint handling in current e-commerce platforms, this article proposes a machine learning based method for accurate customer complaint localization; Preprocess the collected customer complaint texts to ensure the effectiveness of subsequent analysis; Using deep learning techniques such as BERT to extract key features from complaint texts to reflect the main content and emotional tendencies of the complaint; Based on this feature set, construct a convolutional neural network model to automatically identify and classify different types of customer complaints and their priorities. Finally, the article validated the effectiveness and superiority of the proposed method through comparative experiments. The results showed that the overall average F1 score of this design was 0.96, the degree of difference between predicted labels and real labels was 0.05, and the prediction error of emergency complaint response time was only 0.45 hours, providing an efficient and reliable customer complaint management solution for e-commerce platforms.
Keywords: machine learning; E-commerce platform; complaint positioning
随着电子商务的迅速发展,越来越多的消费者选择在线购物作为主要的消费方式。这种趋势不仅推动了电商平台的繁荣,也带来了新的挑战,其中之一就是如何有效地管理和处理大量的客户投诉。客户投诉是电商企业获取客户反馈的重要途径之一,及时而准确地响应这些投诉对于维护品牌形象、提升客户满意度至关重要。然而,传统的客户投诉处理方式通常依赖于人工审核和分类,这种方式不仅耗时费力,而且容易出现错误。而人工智能技术的进步,特别是机器学习的发展,为解决这一难题提供了新的思路。鉴于上述背景,本文开发了一种基于机器学习的客户投诉精准定位方法,以帮助电商平台加速客户投诉问题的解决流程,改善客户服务流程,提升客户满意度和忠诚度。
1" "文本预处理
文本预处理是确保后续分析准确性和效果的基础,它主要包括以下四个步骤:数据清洗、分词、去除停用词、词干提取与词形还原。这一阶段的目标是将原始的、非结构化的文本数据转化为可供机器学习算法使用的格式。
第一步,采用Python中的re模块,对原始文本数据进行清洗。具体而言,通过正则表达式lt;.*?gt;识别并移除所有的HTML标签,确保文本内容的纯净性。接着,通过模式[^\w\s]来过滤掉非字母数字字符以及特殊符号,利用\d+来剔除任何单独出现的数字序列。为了进一步标准化文本,应用.lower()方法将文本中的所有字符统一转换为小写字母形式,以显著减少词汇变体的数量,如“Example”“EXAMPLE”和“example”均将被视为相同的词汇。
第二步,进行分词处理,即将文本切分成单词或短语。对于中文文本,可使用jieba分词库进行分词处理;而对于英文文本,则使用NLTK库中的word_tokenize函数进行处理。例如,对于一条英文投诉:“This product is not good.”,能够得到一个分词列表:['This', 'product', 'is', 'not', 'good']。
第三步,使用NLTK或Scikit-learn提供的停用词列表,过滤文本中频繁出现但不携带太多意义的词汇,如“的”“是”“和”等停用词,以减少特征空间的维度,同时提高后续处理的效率。
2" "特征提取
为了实现基于机器学习的电商平台客户投诉精准定位,利用双向Transformer架构来生成上下文敏感的词语嵌入,以捕捉更深层次的语义关系[1-2]。为了最小化预测被屏蔽单词的概率与实际单词之间的负对数似然,损失函数的计算公式如式(1)所示:
(1)
式中,L表示损失函数;表示被随机屏蔽的单词集合;表示被屏蔽的第个单词,而表示未被屏蔽的其他单词;表示单词出现的概率。
除了文本特征,还需考虑用户的购买历史、浏览行为以及与客服的互动记录等行为特征。利用PCA(Principal Component Analysis)降维技术,通过对原始数据进行线性变换,提取出数据的主要成分,即那些能够最大程度解释数据方差的特征向量。具体而言,从原始行为特征矩阵中计算协方差矩阵,如式(2)所示:
(2)
式中,表示协方差矩阵,用于描述各特征之间的线性关系强度和方向;n表示样本数量;表示原始行为特征矩阵,每一行代表一个样本,每一列代表一个特征;表示原始行为特征矩阵的均值向量,每一维对应一个特征的平均值;T表示转置。接着,找到其特征值和特征向量,进而选取前k个最大的特征值所对应的特征向量作为新的基底,形成一个降维后的空间。通过利用降维后的特征,分析用户在提交投诉前后的购物行为模式,如用户在投诉前后的时间段内购买频率的变化、浏览页面的数量以及与客服交流的次数等,以便于更有效地识别可能导致投诉的因素,并采取相应的措施来改善用户体验。
3" "构建卷积神经网络模型
鉴于文本中预处理和特征提取已作为前期工作完成,将处理好的数据集划分为训练集、验证集和测试集,比例分别为70%、15%和15%。训练集用于模型训练,验证集用于调整超参数和防止过拟合,而测试集则用来评估最终模型的泛化能力[3]。而后,采用包含三个卷积块的网络结构,每个卷积块由一个卷积层和一个最大池化层组成。每个卷积层配置不同大小的滤波器(如3、4、5),以便捕获不同长度的n-gram特征。
考虑到任务的本质是分类问题,选择交叉熵损失(Cross-Entropy Loss)作为损失函数,以有效度量预测概率分布与真实标签之间的差异。假设有个样本,每个样本属于个类中的一个。对于第个样本,设其真实的标签为,并且将这个标签转换为one-hot编码形式,即,其中当且仅当是该样本的真实类别,否则。而模型预测的概率向量为。整个数据集平均交叉熵损失的计算公式,如式(3)所示:
(3)
式中,表示模型预测第个样本属于第类的概率;而是第个样本的真实标签向量中的元素。
确保电商平台在面对不同的客户群体和不断变化的市场环境时,仍然能够准确地识别和定位客户投诉的问题所在。
4" "投诉优先级评估
为了更高效地处理客户投诉,根据预定义的规则对投诉进行优先级排序。基于客户的购买历史、商品类别、问题严重程度等因素,使用Python的pyparsing库设计一系列逻辑规则,解析客户投诉信息中的关键字段,如投诉内容、客户ID、商品ID等。对于高价值客户(如VIP会员),将其投诉优先级设置为10分(满分10分),确保这些客户的投诉能够得到最快响应。针对涉及健康安全问题的商品投诉,在规则引擎中添加一个特殊条件,用于识别包含关键词如“过敏”“伤害”或“安全”等的投诉内容,一旦发现这些关键词,不论客户的等级如何,该投诉的优先级就会被自动设为10分,以确保这类投诉能够立即处理。如表1所示。
通过将所有调整后的分数相加,得出最终优先级分数,确保所有的投诉都能够得到适当的重视,并且最重要和紧急的投诉问题能够得到优先处理,从而提升电商平台的整体客户满意度和服务质量。
5" "测试与评估
5.1 测试准备
为了确保测试过程的准确性和可重复性,需进行软件、硬件资源以及测试数据集的准备。其中,操作系统为Ubuntu 20.04 LTS,ython版本则为Python 3.8.5。测试服务器配备两个Intel Xeon Gold 6248 CPU,总计40个物理核心,以保证足够的并行处理能力。测试数据来源于某大型电商平台的客户服务中心,包括过去两年内近10万条真实客户的投诉记录,涵盖各种类型的投诉,如物流延误、商品质量问题、售后服务不满意等,以全面评估本方法的效果。
5.2 评估指标设计
由于客户投诉涉及到多种类型的问题,为了评估模型对不同类别投诉的识别能力,引入多分类F1分数(Macro-F1 Score),如式(4)所示:
(4)
式中,表示多分类F1分数;是类别总数;是第类别的F1分数。
在一个投诉案例可能包含多个问题的情况下,为了衡量模型在处理复杂多标签投诉时的表现,引入Hamming Loss指标,如式(5)所示:
(5)
式中,表示Hamming Loss指标;表示样本数量;是每个样本可能拥有的标签数量;表示第个样本的真实标签向量中的第个元素;表示第个样本的预测标签向量中的第个元素;是指示函数,当时返回1,否则返回0。
鉴于电商平台的特殊性,还需关注模型在处理紧急投诉时的性能。因此,定义一个新指标——紧急响应时间预测误差(ERTPE),用来评估模型预测紧急投诉响应时间的准确性。紧急响应时间预测误差的计算公式如式(6)所示:
(6)
式中,是紧急投诉的数量;是第个紧急投诉的实际响应时间;是模型预测的第个紧急投诉的响应时间。
通过对上述三个指标的计算和应用,可以全面评估本方法在处理不同客户投诉时的能力和效率,从而确保其在实际电商场景中的有效性和实用性。
5.3 结果分析
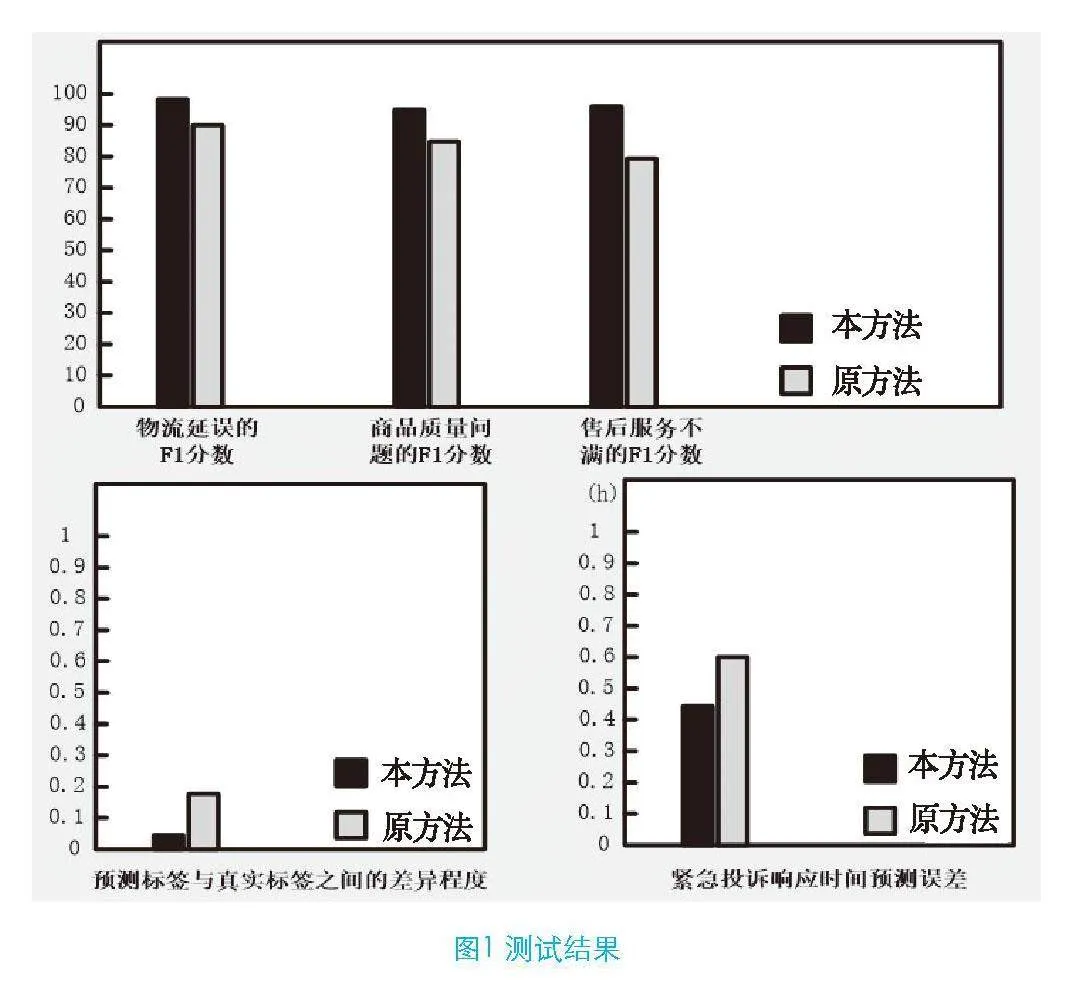
本方法在测试集上的表现如图1所示。
实验结果显示,在测试集上,本方法对于物流延误的识别达到了0.98的F1分数,对于商品质量问题的识别达到了0.95,对售后服务不满类别则达到了0.96。在整体平均F1分数方面,当前方法比之前方法提高了0.12,这表明本方法在识别不同类型的投诉方面表现良好,尤其是在物流延误方面,显示出较高的识别精度。同时,本方法在测试集上的平均Hamming Loss为0.5,即在每条记录上平均只错误预测了5%的标签,相比之前降低了0.13,能够较好地处理多标签投诉问题;相较于原方法,本方法在预测紧急投诉响应时间方面的平均误差仅为0.45 h,能够相对准确地预测紧急投诉的处理速度,具有一定的应用价值。
6" "结束语
综上所述,本文所述方法不仅在识别不同类型的投诉方面表现出色,而且在处理多标签投诉和预测紧急投诉响应时间方面也显示出了高效和准确的特点,将有助于电商平台提高客户满意度和服务效率。未来的研究方向可以从以下几个方面展开:一是进一步优化模型结构,探索更高级的自然语言处理技术,如注意力机制和双向循环神经网络(BiRNN),以提高模型的能力;二是扩展数据集,引入更多样化的投诉案例,使模型具有更强的泛化能力,为企业和社会带来更多的价值。■
参考文献
[1] 黄伟.大数据技术的机器学习算法[J].中国新通信,2024,26(11):47-49.
[2] 周毅勇.基于机器学习和社群互动信息的用户购买意愿分析[J].科技创新与生产力,2024,45(2):28-31.
[3] 李翠萍.基于机器学习的直播电商客户流失风险预测[J].互联网周刊,2023(10):40-42.
作者简介:景奕昕(1978—),男,汉族,湖北武汉人,副高级工程师,博士,研究方向为人工智能、两化融合、信息安全。
