基于改进RFM模型和K-means算法的淘宝用户行为分析
2024-12-05陈海燕张经纬


摘 要:大数据时代下,我国电子商务发展迅速,用户行为数据日益增多,利用海量数据对用户行为进行剖析,为精准营销提供决策依据,进而提高用户忠诚度、满意度和活跃度,成为电商平台关注的焦点。基于淘宝用户真实数据集,提出基于改进RFM模型和K-means算法的用户行为分析方法,为了更好地描述用户行为特征,创建“活跃度转化率”指标进行分析,实验结果表明,该方法能够有效地进行用户类别划分,划分结果符合“二八定律”,能够协助电商平台完成精确化的客户关系管理。
关键词:改进的RFM模型;K-means算法;用户行为分析
中图分类号:TP311.13"" 文献标识码:A"" 文章编号:1673-1794(2024)05-0001-04
作者简介:陈海燕,滁州学院经济与管理学院教师,硕士,研究方向:管理科学与工程;通信作者:张经纬,滁州学院科研处教师(安徽 滁州 239000)。
当前,我国电子商务发展迅速,各类电商平台收集并存储了大量用户行为数据,如何利用这些数据准确地进行用户类别划分,并分析每一类用户的行为特点,制定个性化的营销策略,提高用户的忠诚度、满意度和活跃度,利用大数据创造出更高的价值,已经成为电商平台关注的重点[1]。受到数据量的影响,早期的用户行为分析主要是利用统计分析方法建立用户分析模型。当前的用户行为分析更加依赖于机器学习算法,例如利用收集到的真实数据,提取反映用户行为的特征,进而训练聚类模型用于用户划分,将用户分成不同的簇,分析不同簇的特征即可获取当前簇的用户行为信息。因此能否获得反映用户行为的精确特征对用户行为分析的准确性高低影响较大。RFM模型是Hughes为了衡量客户价值和客户创利能力提出的[2],目前已成为用户行为分析中应用最为广泛的模型[3],该模型基于时间间隔、消费频率、消费总额三个维度对用户的行为价值进行评估。
文章利用淘宝用户真实数据集,基于改进RFM模型和K-means聚类算法对用户行为进行分析。考虑到用户除了购买行为,还存在点击浏览、加入购物车、收藏商品等关键行为,同样能从一定程度上反映该用户的价值,所以提出“活跃度转化率”特征用于分析用户行为。“活跃度转化率”一方面能够反映该用户是否活跃,另一方面通过计算购买行为与活跃行为的比值可以在一定程度上体现该用户能否产生与其活跃度对等的价值。此外传统RFM模型中的“消费总额”特征存在泄露个人隐私的风险,因此实际情况下的获取难度较大,一定程度上阻碍了用户分析的效果,本研究提出的“活跃度转化率”特征相比于“消费总额”特征更容易获取。最终,文章基于提出的改进RFM模型和K-means聚类算法对淘宝用户真实数据集进行用户行为分析,划分出不同类别的用户消费群体,从而提出个性化的营销建议,实现基于用户行为分析的客户关系管理与精准营销。
1 理论基础
1.1 RFM理论
RFM模型基于三个维度对用户的价值进行有效评估,对企业寻找高价值用户、有效利用企业资源有着重要作用。该模型首先对用户最近一次的消费时间距离当前分析时间节点的时间间隔(Recency, R)进行分析,一般认为时间间隔R越小分值越大[4],表明用户近期还存在消费行为,这类用户再次购买的意愿会更强烈,相比于R值很大的用户而言,更值得投入时间和精力进行推销和服务。其次,RFM模型考虑了用户的消费频率(Frequency, F),即一段时间内用户的消费总次数[5]。研究表明,消费频率F较大的用户,即经常性产生消费行为的用户,其满意度与忠诚度较高,因而具有较高的用户价值。最后,RFM模型计算了用户一段时间内的消费总额(Monetary, M),研究表明消费总额高的用户在购买更加高级别产品或者新产品上的概率更高,此时可以建立合适的用户回馈机制,例如构建VIP服务,提高这类用户的购物体验。需要指出的是,单一考虑上述某一个指标,是不具备科学性和有效性的,例如仅仅考虑消费频率F的话,某些消费频率F很小的用户,会被直接判定成满意度或者忠诚度低,但是如果结合时间间隔去看,有可能该类用户的时间间隔也很小,说明这类用户很有可能是新用户。所以RFM模型是在综合考虑用户R值、F值、M值的基础上,对用户进行划分,根据每一个指标的高低,可以将用户分成八种类型[6],分别是重要价值客户、重要发展客户、重要保持客户、重要挽留客户、一般价值客户、一般发展客户、一般保持客户、一般挽留客户。企业需要正确地识别出用户属于哪一类别,才能有针对性地进行营销服务,达到利用最少的资源收获最大化利益的目的。
1.2 K-means算法
K-means算法是聚类算法的典型代表,其基本原理是通过计算样本距离聚类中心的距离大小判断样本类别,是一种迭代求解的聚类分析算法[7]。K-means算法求解步骤为:首先,确定样本的类别数K,选择K个样本作为初始聚类中心;然后,针对数据集中每个样本,计算它到K个聚类中心的距离,并将其归属到距离最小的聚类中心所对应的类中;最后,根据划分出的K类结果,重新计算聚类中心,重复进行样本类别划分和聚类中心计算,直至达到设定的迭代次数或者聚类中心位置保持不变即可停止迭代。
2 改进RFM和K-means的淘宝用户行为分析方法
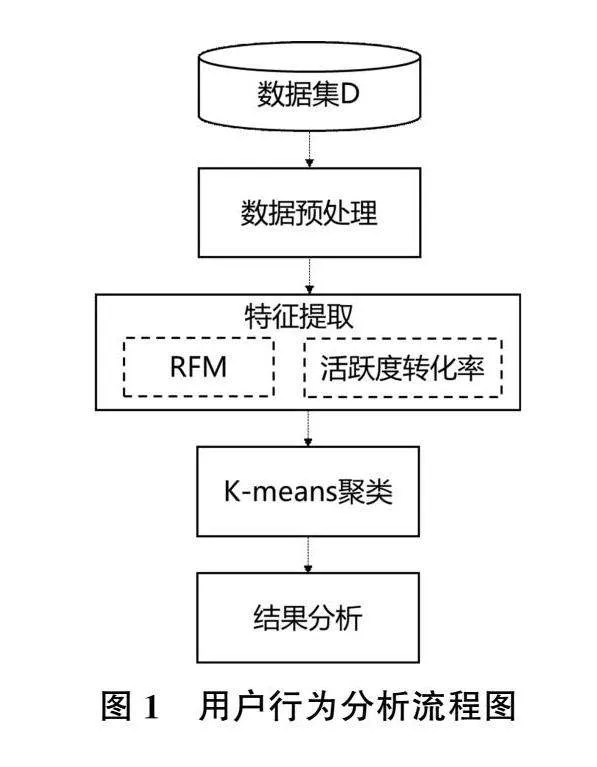
利用淘宝用户购物行为数据集,对该平台用户进行行为分析,具体流程如图1所示。首先,对海量数据进行预处理,消除数据冗余、缺失、异常等常见问题。然后,提取相关特征以备聚类分析使用,根据RFM理论,提取用户的消费时间间隔R、消费频率F、消费总额M三个重要特征,此外,考虑到用户行为中除了购买,还存在点击浏览、加入购物车、收藏商品等关键行为,同样能从一定程度上反映该用户的价值,所以创建“活跃度转化率”这一特征,希望能够获得更好的实验效果。
假设用户在一段时间内的点击浏览次数为X,加入购物车次数为Y,收藏商品次数为Z,这段时间内的购买次数等于消费频率F,根据以下计算公式为可以得出该用户的活跃度转化率A:
A=FX+Y+Z
根据以上公式,活跃度转化率能够反映该用户是否活跃,而且,通过计算购买行为与活跃行为的比值可以在一定程度上体现该用户能否产生与其活跃度对等的价值。随后,利用提取的特征进行聚类分析,基于K-means算法,通过实验选取合适的K值,对已有数据集进行聚类分析,得到聚类结果。最后,通过对比分析每一类别的数据特征,进行用户行为分析,提出个性化的营销建议,实现基于用户行为分析的客户关系管理与精准营销。
3 实验过程
3.1 数据集描述
利用天池实验室提供的淘宝用户购物行为数据集进行用户行为分析,数据集下载链接为:https://tianchi.aliyun.com/dataset/145889?t=1681370074914。该数据集一共包含2859331个不重复的样本,记录了10000个用户在一段时间内的若干操作行为。该数据集一共包含5列,分别记录了用户ID、产品ID、行为类别、产品类别、操作时间,其中行为类别包含四类,分别是浏览、收藏、加购物车和购买,对应标记分别是“1”“2”“3”“4”。
3.2 实验设计
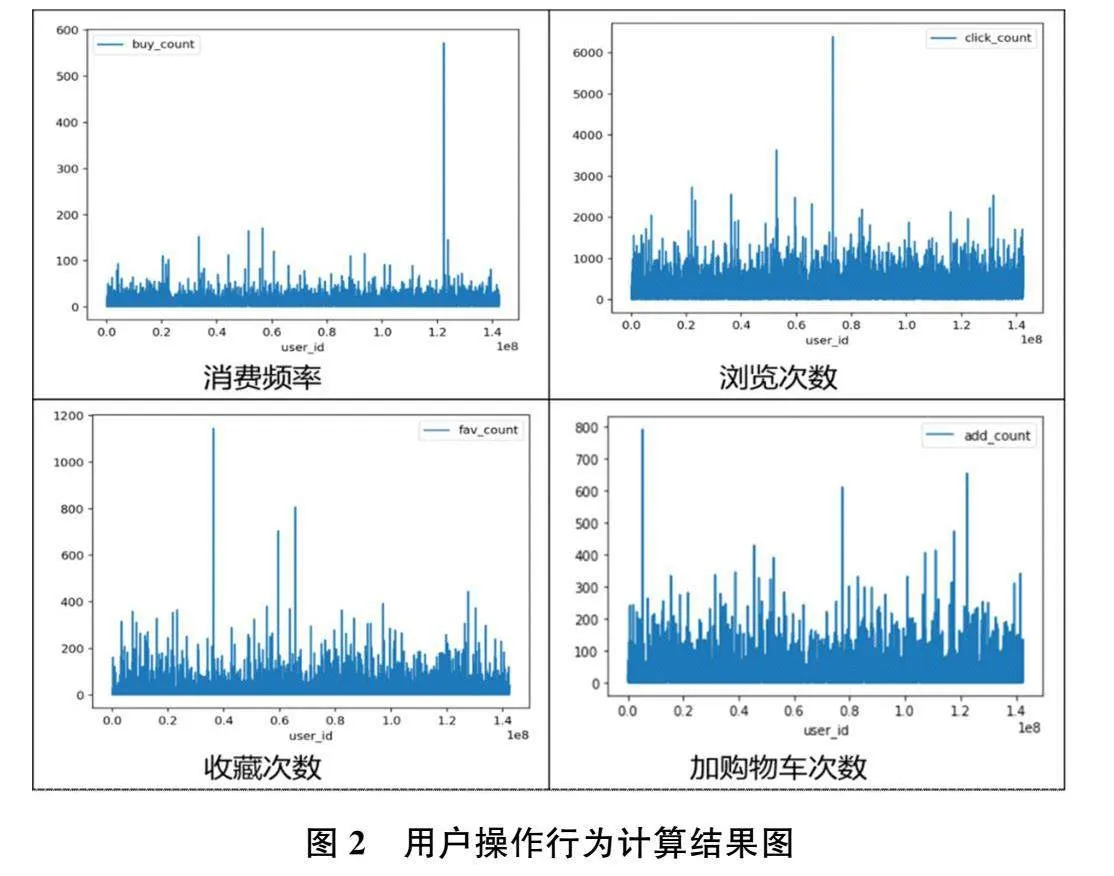
首先,对海量数据进行预处理,经检查发现该数据集不存在数据缺失问题,故不需要进行缺失值填充。用户的操作时间记录精确到了小时,为了方便计算用户的消费时间间隔R,将操作时间中的日期和小时分开,提取出每一位用户进行相应操作的日期信息,格式为“年-月-日”。利用8886个有购物行为的用户进行行为分析,提取需要的特征用于后续聚类模型构建,由于要遵守保护用户隐私协议,该数据集并未给出每位用户的支付金额数据,因此无法提取用户的消费总额M特征。计算用户的消费时间间隔R,利用用户数据记录的最后一天作为分析截止日期,每位用户的消费时间间隔R等于截止日期减去最近一次有购买行为的日期,最终结果以天为单位。计算这段时间内用户的消费频率F,即购买的总次数。此外计算这段时间内用户点击浏览次数、收藏次数、加购物车次数,计算结果如图2所示。随后,根据活跃度转化率的公式计算提取活跃度转化率特征。
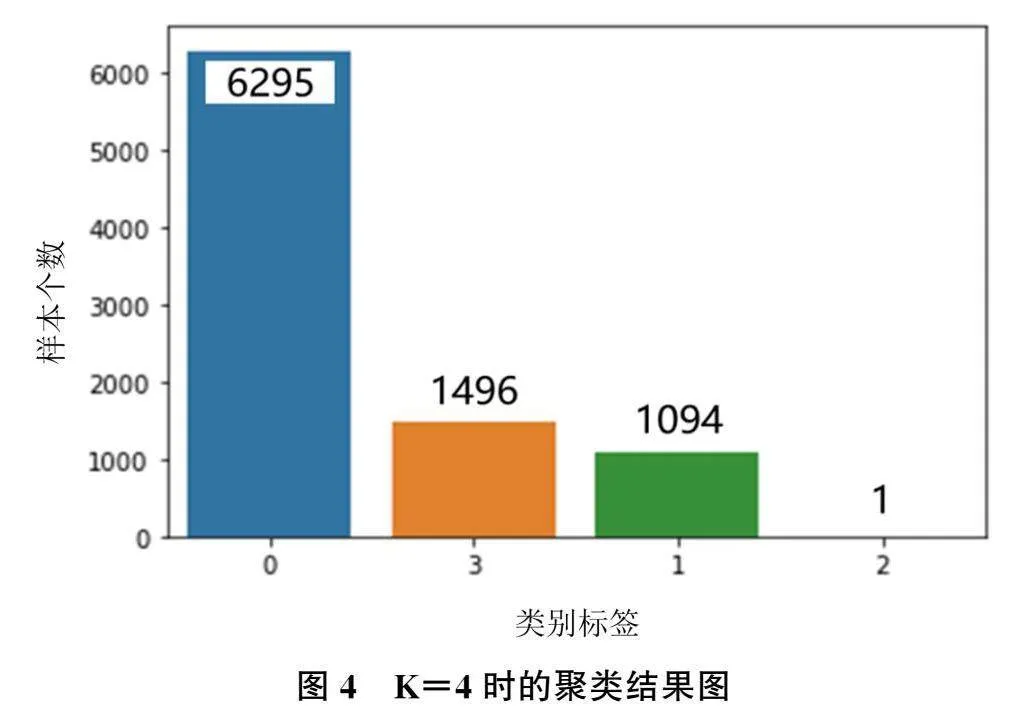
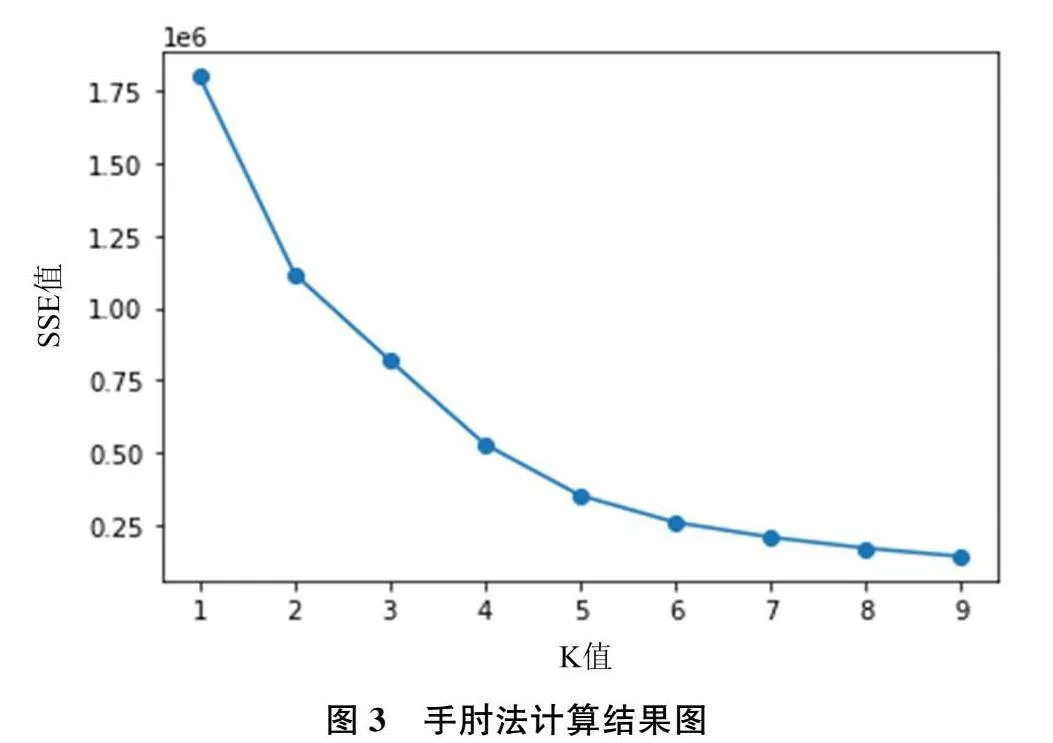
然后,运用K-means聚类算法进行用户类别划分。第一步,利用手肘法和轮廓系数确定最优的K值,避免主观选择K值对聚类效果的影响。手肘法通过每个样本点与其所在簇内质心的误差平方和SSE来评估样本聚类效果的好坏。研究表明,SSE 随着K值的增加呈现递减的趋势,但是在K增大的过程中,其下降幅度逐渐减弱,某一时刻会出现SSE的下降幅度骤减的现象,然后下降幅度逐渐趋于平缓。整个过程中,K值与SSE形成的曲线类似于手肘,最优的K值位于手肘位置,即下降幅度骤减时的K值。基于上述提取的三类特征,手肘法确定K值的结果如图3所示,结果显示最优K值为4或5。进一步根据轮廓系数确定最优K值,轮廓系数是描述簇内外差异的关键指标,其值越接近1说明聚类效果越好。分别计算K取4和5时的轮廓系数,结果显示K取4时的轮廓系数为0.514, K取5时的轮廓系数为0.501,因此最终确定最优K值为4。利用K-means进行类别划分后的结果如图4所示,其中横轴表示类别标签,纵轴表示该类样本的个数。由图4可知,类别标签2的样本个数只有1个,明显该点属于异常点,因此将该样本删除后,对剩下的8885个样本重新进行分析。
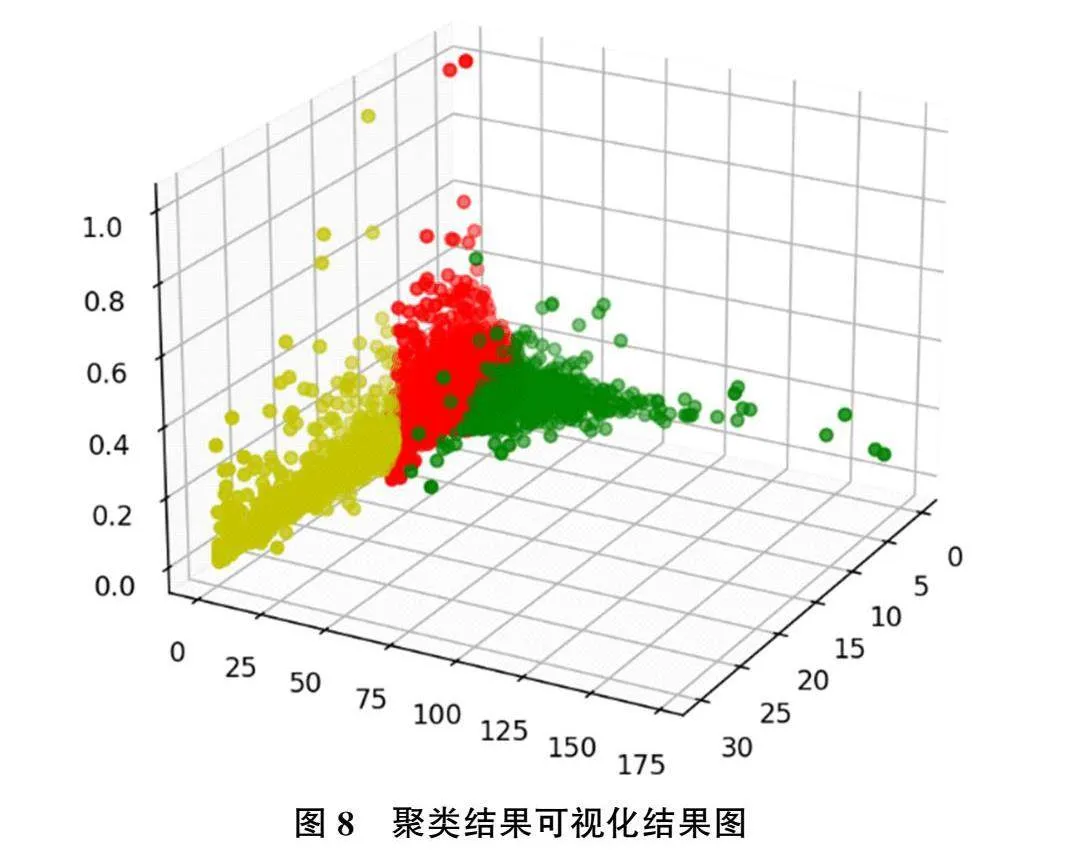
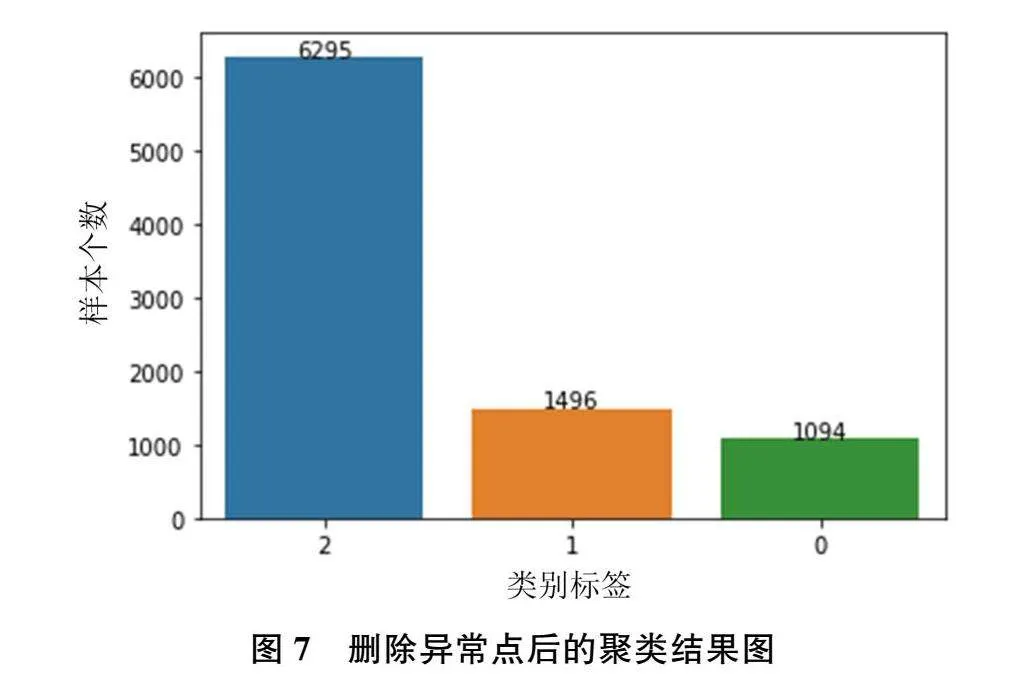
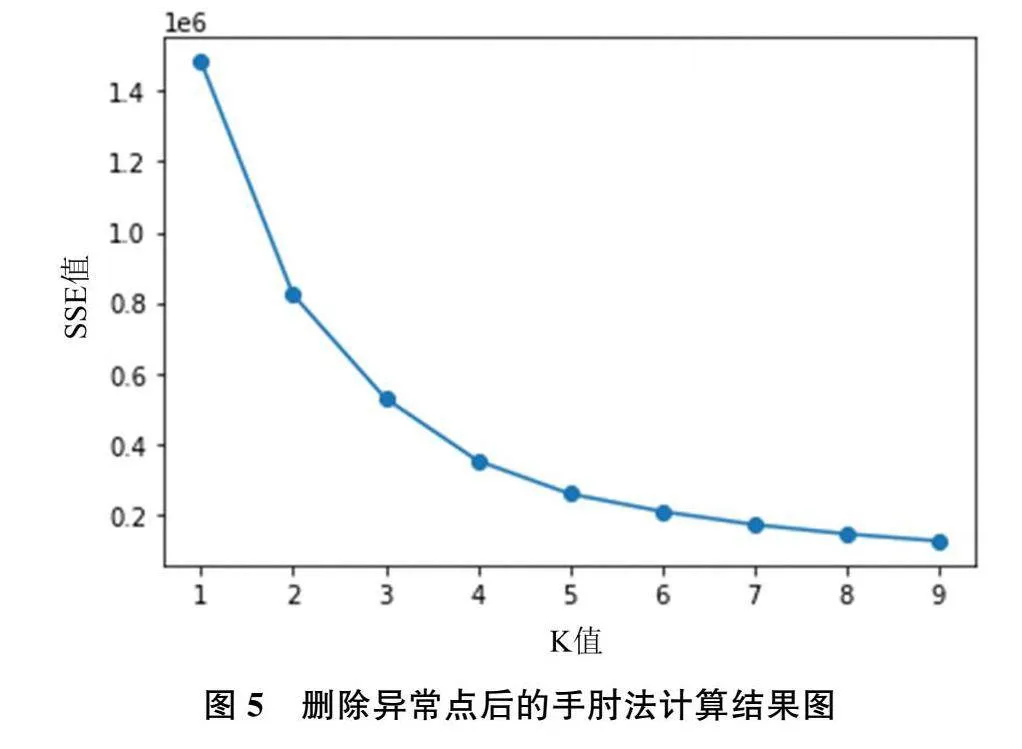
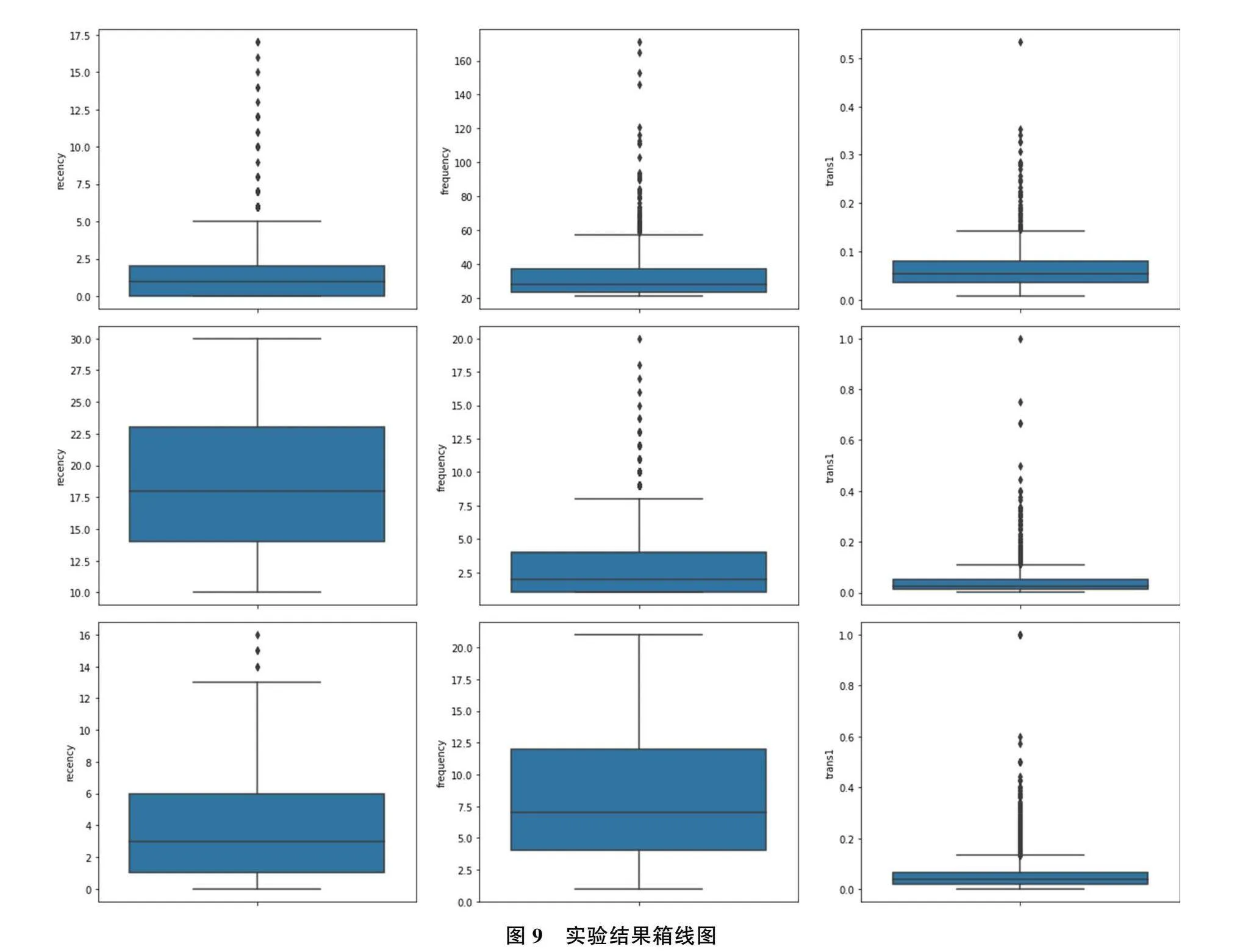
首先利用手肘法和轮廓系数确定K值,利用手肘法重新计算的结果如图5所示。结果显示最优K值为3或4,分别计算其轮廓系数,K取3时的轮廓系数为0.514,K取4时的轮廓系数为0.504,因此最终确定的最优K值为3。通过K-means聚类算法,将用户划分为3类,实验算法的伪代码如图6所示,划分结果如图7所示,其中横轴表示类别标签,纵轴表示样本个数。此外将聚类结果进行可视化分析,根据提取的三类特征绘制散点图,结果如图8所示,图中每种颜色各代表一个分类。最后对每一类别的样本进行统计分析,绘制箱线图。通过该箱线图,可以清晰地发现各组数据的分布差异,其用一组数据中的最小值、下四分位数、中位数、上四分位数和最大值来反映数据分布的中心位置和散布范围。箱线图如图9所示,其中第一行为标签为类0用户的分析结果,第二行为标签为类1用户的分析结果,第三行为标签为类2用户的分析结果。第一列表示消费间隔R特征值,第二列表示消费频率F特征值,第三列表示活跃度转化率特征值。
3.3 结果分析
根据图7和图8所示,8885位淘宝用户被划分成三类,其中类别标签为2的用户个数最多,为6295个;类别标签为1的用户个数次之,为1496个;类别标签为0的用户个数最少,为1094个。由图8可得,每个类别的用户拥有清晰的界限,特征相近的用户被划分为同一类别,聚类效果明显。对每一类别用户进行统计分析并绘制箱线图,如图9所示。图形结果显示标签为0的用户消费时间间隔R较低,说明近期还存在购物行为,其消费频率F较高,但是活跃度转化率较低,一方面说明该类用户忠诚度和满意度较高,另一方面也说明其活跃度较高,能产生更高的价值。标签为1的用户消费时间间隔R较高,说明已经有较长时间没有在淘宝平台产生购物行为,其消费频率F较低且活跃度转化率也较低,一方面说明该用户忠诚度和满意度较低,另一方面也说明其还保持着一定的活跃度。标签为2的用户消费时间间隔R较低,说明近期还存在购物行为,其消费频率F较低且活跃度转化率也较低,一方面说明该用户忠诚度和满意度较低,另一方面也说明其还保持着一定的活跃度。
综上所述,标签为0的用户属于重要价值客户,该类用户共有1094位,符合“二八定律”,即80%的利润往往是由20%的消费者创造的[8],进一步证实了聚类结果的有效性和可靠性。重要价值客户是淘宝的忠实用户,也是淘宝营销宣传的重点目标,其活跃度较高且能产生与活跃度匹配的高价值,淘宝应该向这类用户实施资源倾斜,对于这类用户,无需进行大量的产品推广宣传,而是应该考虑将更多的资源投入在提升服务水平上,可以提供个性化的VIP服务,吸引该类客户开通特殊的身份,提供有别于普通用户的服务。标签为1的用户属于一般挽留客户,其忠诚度和满意度不高,但是还存在部分活跃度,可以花费少部分资源尝试挽留该类客户,向其推荐产品或者传递优惠信息,例如通过邮件、电话、短信等方式推送最新的优惠活动,发放一定数量的优惠券等,若效果不明显,可以考虑放弃该客户群体。标签为2的用户属于重要发展客户,其消费频率不高,但是活跃度较高,且消费间隔较低,近期还存在消费现象,这类用户的黏性较高,对企业来说需要采取措施重点发展,争取让该类用户产生更高的价值。例如,深入了解这类用户的需求,投入相当的资源进行产品推广,实现精准营销;有针对性地发放中等额度的消费券,吸引其购买价格更高的商品,从而提高其消费额度,产生更高的价值。
4 结语
基于淘宝用户真实数据集,提出基于改进RFM模型和K-means聚类算法的用户行为分析方法。考虑到用户除了购买行为,还存在点击、加购物车、收藏等相关行为,这些行为同样对于用户行为分析至关重要,也能从一定程度上反映用户价值,因此创建“活跃度转化率”特征用于用户行为分析。实验结果表明,该数据集中的用户一共分为三类,包含1094位重要价值客户,1496位一般挽留客户,6285位重要发展客户,用户价值分布符合“二八定律”,说明改进的模型取得了较好的聚类效果。针对不同类别的用户,提出针对性的营销建议,以期协助企业更好地开展客户关系管理,提高用户忠诚度和满意度,防止用户流失。
[参 考 文 献]
[1]
刘瑞琪,宋子琨.基于RFM模型的天猫用户价值分析[J].经济师,2022(12):243-244.
[2] HUGHES A M.Strategic database marketing:the masterplan for starting and managing a profitable,customer-based marketing program[M].Chicago: Probus Publishing Company,1994:77-79.
[3] 师奥翔,张洁.基于改进RFM模型的电商用户价值分类的研究[J].计算机技术与发展,2022,32(12):123-128.
[4] 陈丹红,彭张林,万德全,等.众包平台用户价值识别与细分:基于改进的RFM模型[J].计算机科学,2022,49(4):37-42.
[5] 宗毅,李莹,田容,等.基于改进RFM模型的航空公司顾客分级研究[J].民航学报,2023,7(1):8-14.
[6] SUN G,XIE X F,ZENG J,et al.Using improved RFM model to classify consumer in big data environment[J].International Journal of Embedded Systems,2021,14(1):54.
[7] 周志华.机器学习[M].北京:清华大学出版社,2016:202.
[8] 王明艳.基于Power BI的RFM客户价值分类模型[J].科技创新与生产力,2021(9):30-33.
Analysis of Taobao User Behavior Based on Improved RFM Model and K-means Algorithm
Chen Haiyan, Zhang Jingwei
Abstract:
In the era of big data, China's e-commerce is developing rapidly, with an increasing amount of user behavior data. Utilizing massive amounts of data to analyze user behavior and provide decision-making basis for precision marketing, thereby improving user loyalty, satisfaction, and activity, has become the focus of attention for e-commerce platforms. Based on the real data set of Taobao users, a user behavior analysis method based on the improved RFM model and K-means algorithm is proposed. In order to better describe the characteristics of user behavior, the \"activity conversion rate\" indicator is created for analysis. The experimental results show that this method can effectively divide user categories, and the division results comply with the \"Pareto principle\", which can help e-commerce platforms complete accurate customer relationship management.
Key words:improved RFM model; K-means algorithm; user behavior analysis
责任编辑:陈星宇
