基于自然语言处理的易水学派文本挖掘与句法分析图谱构建研究
2024-09-23赵汉青李玥函邹欣妍



特约主持人:李福海
摘要:自然语言处理中,实体与关系抽取是构建知识图谱、设计问答系统、语义分析等任务中不可或缺的环节。中医易水学派的信息多数以非结构化文言文本形式储存,中医文本关键信息抽取对挖掘和研究中医学术流派有重要作用。为了更高效地解决以上问题,研究引入人工智能方法,构建自然语言处理技术架构下基于条件随机场的分词和实体关系抽取模型识别与抽取中医文本实体关系,利用词频逆文档频率算法的常用加权技术提取不同古籍文本中的关键实体信息,并使用基于人工神经网络依存句法分析技术,深入剖析古籍条文,以揭示其中实体之间复杂而精确的语法关系,将其表示为可视化树形结构,为下一步构建易水学派知识图谱及利用人工智能方法开展中医学术流派研究奠定基础。
关键词:自然语言处理;知识图谱;易水学派;句法分析
DOI:10.3969/j.issn.1674490X.2024.04.005
中图分类号:R2""""" 文献标志码:A""""" 文章编号:1674490X(2024)04003008
Construction of a syntactic analysis map for Yishui school through text mining and natural language processing research
ZHAO Hanqing, LI Yuehan, ZOU Xinyan
(College of Traditional Chinese Medicine, Hebei University, Baoding 071000, China)
Abstract: Entity and relationship extraction is a crucial component in natural language processing tasks such as knowledge graph construction, question answering system design, and semantic analysis. The information pertaining to Yishui school of traditional Chinese medicine primarily exists in the form of unstructured classical Chinese text, making key information extraction from TCM texts essential for mining and studying TCM academic schools. To efficiently address these challenges using artificial intelligence methods, this paper presents a word segmentation and entity relationship extraction model based on conditional random field within the framework of natural language processing technology to identify and extract entity relationships from TCM texts. Important key
收稿日期:20240604
基金项目:
国家自然科学基金(82004503);河北省高等学校科学技术研究项目资助(BJK2024108)
第一作者:赵汉青(1990—),男,山东枣庄人,讲师,博士,硕导,主要从事中医药大数据处理与人工智能应用研究。E-mail: zhaohq@hbu.edu.cn
entity information from different ancient books is extracted using commonly employed TF-IDF information retrieval and data mining weighting techniques. Additionally, grammatical relationships between entities in each ancient book article are analyzed using a neural network dependency parsing analyzer, which are then represented as tree structures for visualization purposes. This paper lays the foundation for subsequent steps involving building a knowledge graph for Yishui school and utilizing artificial intelligence methods to conduct research on TCM academic schools.
Key words: natural language processing; knowledge graph; Yishui school; syntactic analysis
0" 引言
人工智能及自然语言处理技术在中医药数据挖掘领域得到了广泛应用,高效挖掘利用中医古籍文献知识已成为推动中医药学传承与创新发展的基石。随着技术的进步,虽然近年来已在相关领域取得了一定成果[1],但仍存在巨大挑战,特别是在中医学派的传承与发展中较少见到自然语言处理技术的应用研究。
中医学派别的学术传承多依赖于读经典,核心是挖掘古籍知识。这些古籍以非结构化的文本形式保存至今。在处理这些古籍数据时,特别是涉及命名实体等信息的提取,需要投入大量的人力与时间。古籍文献主要采用文言文撰写,与现代汉语在词汇和语义层面存在显著差异。这导致针对人工智能分析构建的标准数据集相当匮乏,进而为计算机方法从古籍文献中自动抽取信息设置了重重障碍。使用自然语言处理技术进行古籍文献的内容识别是解决该问题的方法之一,而命名实体识别(named entity recognition, NER)是自然语言文本处理的常用技术。中文命名实体识别方法能够实现从文本数据中自动提取相关中文实体,并能够对实体进行分类[2]。目前,较为准确的命名实体方法是使用手工规则结合人工标注的实体库,对文本数据进行分析判断。这种基于规则的方法最大的优点是具有较高的准确率,主要缺点是过于依赖人工规则,泛化能力差。故基于机器学习方法开展命名实体识别的研究逐渐增多。当前较为成熟的机器学习方法主要为基于有监督学习的隐马尔科夫模型(hidden markovmodel,HMM)、决策树模型(decision tree)、最大熵模型(the maximum entropy principle)、条件随机场(condition random field, CRF)、支持向量机(support vector machine, SVM)等。这些方法仍需依靠人工标注数据,但对规则的依赖较少。[3]随着GPU计算卡性能的大幅提升,基于深度学习的NER方法逐渐占据主导地位,且整体识别效果较基于机器学习方法有较大的提升。目前,基于深度学习的方法主要基于人工神经网络模型,除了常见的图神经网络(graph neural networks,GNN)、递归神经网络(recurrent neural network,RNN)、卷积神经网络(convolutional neural network,CNN)等[4]神经网络模型外,谷歌发布的预训练深度学习模型BERT极大提升了命名实体识别的性能[5],但该模型在中医古籍文本提取中的表现仍然不佳。在中医药文本的知识关系提取方法研究中,除了使用自顶向下的抽取方法外,国内亦开展了多种基于无监督算法的自动抽取研究。广州中医药大学陈莹璇等[6]使用Python Jiayan分词工具对《黄帝内经·灵枢》文本进行自动实体识别,再对提取的实体利用中医药学语言系统开展关系分类以完成整个三元组的提取。张莹莹[7]使用中医专业知识来设计中医知识图谱的模式层,运用CRF++算法对电子病历进行命名实体识别,结合中医规则和Attention-based Bi-directional Long Short-Term Memory机器学习模型来识别和抽取实体之间的关系,初步完成了一个多源异构的中医药知识图谱构建。
本研究通过运用经典的自然语言处理方法,首先对经典古籍文本数据进行分词处理,根据通用PKU方案进行命名实体识别,在此基础上使用词频逆文档频率(term frequency-inverse document frequency,TF-IDF)算法提取关键实体词,随后开展依存句法分析,为后续知识图谱构建提供数据样本。在具体方案实现中,本研究采用条件随机场自然语言处理模型+TF-IDF算法关键实体抽取算法+基于人工神经网络的依存句法分析器对易水学派代表文本数据进行自动分析和可视化展示,为人工智能技术在中医学派研究应用提供参考。
1" 资料与方法
1.1" 实验数据
本研究数据为公开通行版本《医学启源》《脾胃论》《阴证略例》,将全文内容转化为txt文档,去除目录,仅保留全文标题和全部正文部分,去掉空格和空行,不进行数据清理。
1.2" 条件随机场模型
条件随机场是一种判别式无向图模型,一般使用极大似然估计完成文本数据的分词、词性标注等任务[8]。中文分词采用BMES词位法,即词首、词中、词尾、独立词,输入的句子S相当于序列X,输出的标签序列L相当于序列Y,我们要训练一个模型,使得在给定S的前提下,找到其最优对应的L。在模型训练中,特征函数F的选择及其权重W的确定是核心问题。对于每个特征函数,其输入的文本要素主要包括句子S、单词i、单词词性li,特征函数的输出值为0或1,其中0表示观测到的序列标记不符合该特征,而1则表示观测到的序列标记与该特征相符。对于序列L和S,可构建条件概率分布模型公式:
P(L,S)=p(l1)Πip(li|ll-1)p(wi|li)
在分词基础上采用IOB 标注法进行命名实体识别,如图1所示,使用每句话的分词序列生成的gram,利用tri-gram模型抽取特征,最后输入到CRF模型中完成标注。
1.3" TF-IDF算法
TF-IDF算法,是一种在文本数据挖掘领域广泛应用的能够简单快速处理语料的加权技术,尤其适用于从文章中提取关键词[9]。此方法基于统计分析,用于量化一个词在特定文件集或语料库中的重要性。其中TF指的是某个词在文本数据中出现的频率,如果一个词在文档中多次出现,那么它可能是一个较为重要的词汇。该算法的主要计算公式如下:
词频(TF)=某个词在文档中出现的次数/文档的总词数
逆文档频率(IDF)=log(语料库的文档总数/(包含该词的文档数+1))
TF-IDF=TF×IDF
一个词的重要性与其在特定文档中出现的频次呈正相关关系,而与其在整体语料库中出现的频次则呈负相关关系。[10]这种计算方法旨在降低高频通用词对关键词的干扰,从而增强关键词与文章主题之间的关联性和相关性[11]。
1.4" 基于神经网络的依存句法分析器
依存句法分析是一种重要的语言学分析方法,旨在揭示文本中词与词之间的主从关系。这种分析方法将句子中的每个词语与其所依赖的词语之间建立起一种明确的依存关系,从而帮助人们更深入地理解句子的语法结构和含义。通过依存句法分析,可以将复杂的语言结构转化为清晰易懂的树形结构,为自然语言处理和文本数据挖掘研究提供多方位的支持[12]。依存句法分析的应用范围广泛,可用于分析中医药文本的语法构成,探索中医经典古籍条文与现代中医文本的句法差异,对于提高中医药文本自然语言处理技术的准确性和效率具有重要意义。
本研究采用基于神经网络的依存句法分析方法。该方法通过深入分析句子内部的语法关系,将原本线性的词语序列转换为具有层次结构的图表示[13]。在此过程中,主要关注动宾关系、左附加关系、右附加关系、并列关系、定中关系以及主谓关系等常见的语法依赖关系。依存语法作为一种广泛应用的语法分析框架,通过依存弧连接句子中具有特定语法关系的词语,进而构建一棵完整的句法依存树。在构建依存树的过程中,采用栈的数据结构,并以根节点root作为起始点。随后,通过移进、左规约、右规约三种操作状态,逐步将缓存中的词汇压入栈中,从而确保依存关系的正确性和完整性。在本研究中,采用HanLP工具包[14]来实现本研究的依存句法分析,以提供高效且准确的句法分析结果。
1.5" 实验环境
该研究在河北大学中医药信息学实验室小型人工智能平台实施,平台配置Intel Xeon Gold 6248R CPU@3.00Ghz*96,内存256GB,搭载NVIDIA A100 80G*2 GPU计算卡,Ubuntu 18.04.6 LTS,Python 3.9环境运行。
2" 实验结果
2.1" 分词及实体识别结果
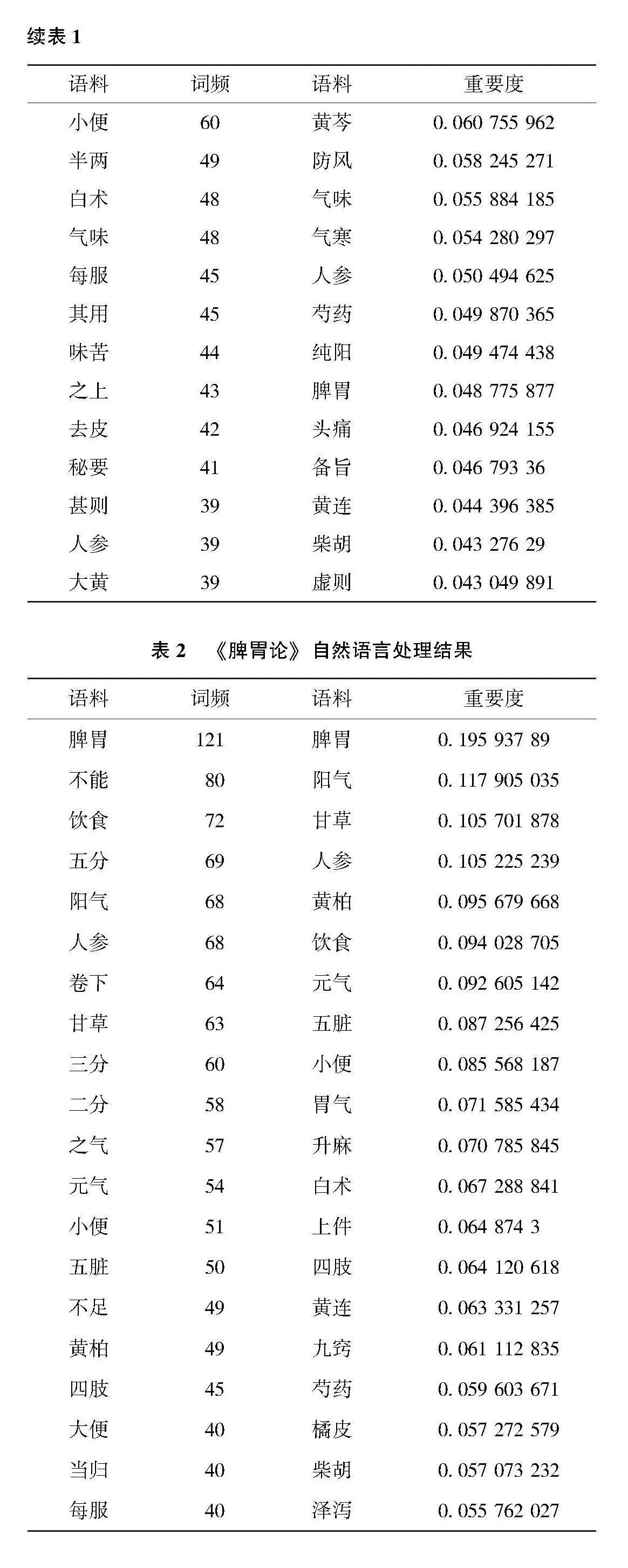
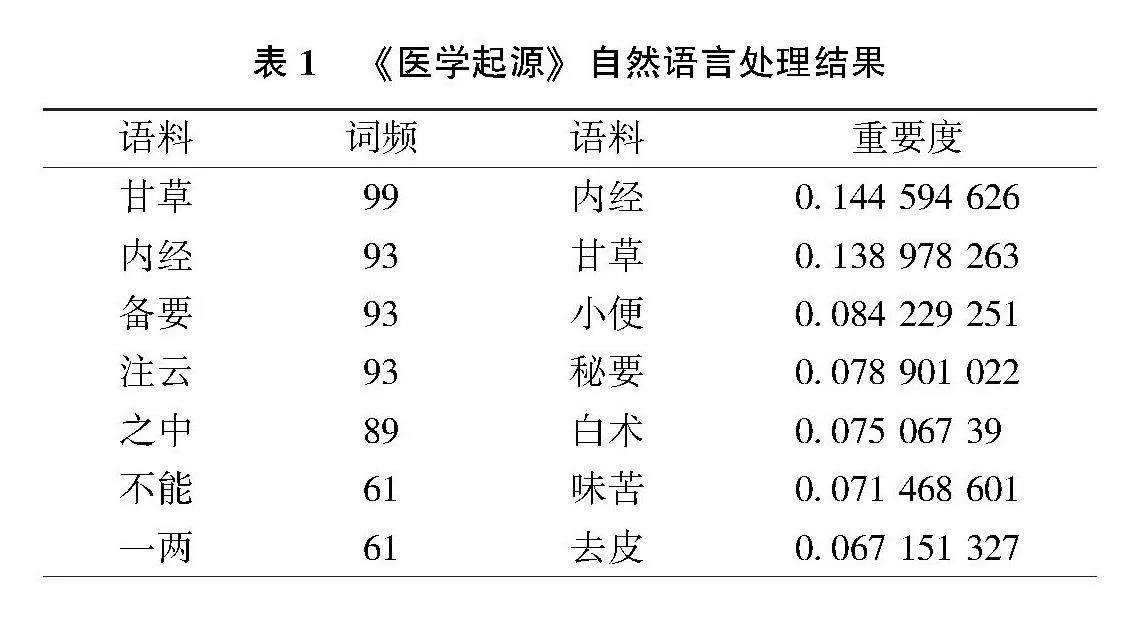
实验完成对《医学启源》《脾胃论》《阴证略例》全文的分词及实体识别,分别获得语料472项、899项、726项。由于中医古籍文本资料实体属性难以定义,本研究暂以名词、动词、形容词、语气词等实体类别进行划分,着重考察研究实体词汇的含义,相关自然语言处理提取的词频及TF-IDF评价重要度如表1至表3所示。
2.2" 相关实体词汇图谱可视化结果
将相关数据整理汇总,按照实体词汇重要度数据绘制词云图,如图2所示。
2.3" 依存句法分析结果
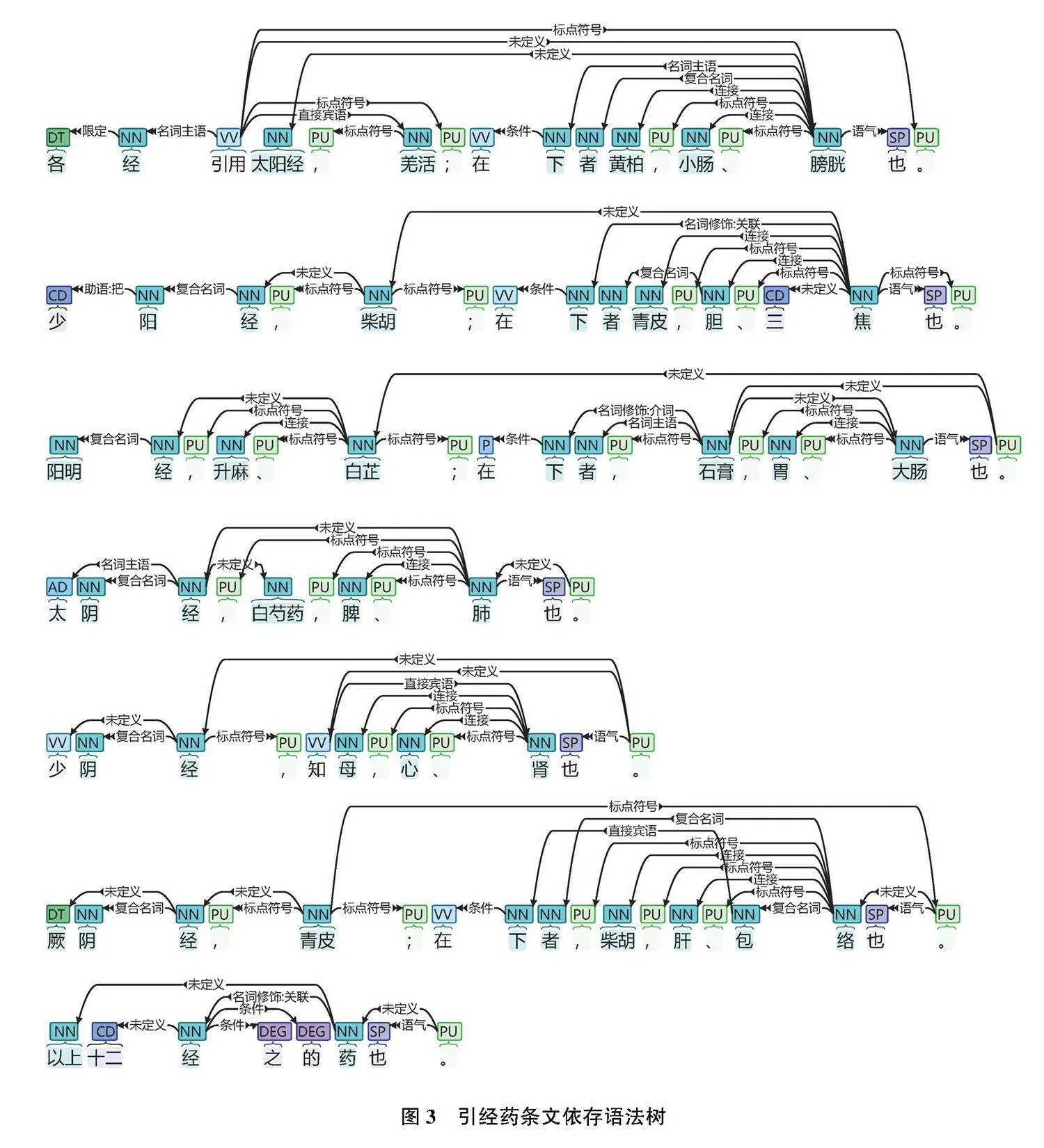
本研究完成三本著作的全部条文部分句法分析,以《医学启源》中有关引经报使理论的文本描述为例,提取样本数据进行关系提取和图像绘制。
样例文本如下:
“各经引用太阳经,羌活;在下者黄柏,小肠、膀胱也。少阳经,柴胡;在下者青皮,胆、三焦也。阳明经,升麻、白芷;在下者,石膏,胃、大肠也。太阴经,白芍药,脾、肺也。少阴经,知母,心、肾也。厥阴经,青皮;在下者,柴胡,肝、包络也。以上十二经之的药也。”
构建依存语法树,如图3所示。该模型可识别此段文言文本,并根据实体识别结果分析其语法结构,从中提炼实体之间的关系,以太阳经为例,能明确区分太阳经与羌活及黄柏与小肠、膀胱之间的关系。
3" 结论
本研究采用基于条件随机场的命名实体识别方法,对中医易水学派经典古籍文本数据的实体词汇、语义特征和句法结构等进行分析,实现了非结构化文本数据中关键命名实体的提取,取得了比较好的效果,对于易水学派不同医家学术观点的总结、学术思想差异的发现以及传承脉络的梳理研究均具有重要的理论和实践指导价值。下一步,将在命名实体识别的基础上,继续研究文言文数据的中医实体关系抽取,进而构建易水学派知识图谱,为人工智能方法在中医学派研究的应用提供参考。
参考文献:
[1]WANG C D,XU J,ZHANG Y. Review of entity relationship extraction[J]. Computer Engineering and Applications, 2022, 56(12): 25-36.
[2]刘浏,王东波.命名实体识别研究综述[J].情报学报, 2018, 37(3): 329-340. DOI: 10.3772/j.issn.1000-0135.2018.03.010.
[3]宫义山,段亚奇.基于不同模型的中文命名实体识别方法研究[J].长江信息通信, 2021, 34(1): 84-86.
[4]赵继贵,钱育蓉,王魁,等.中文命名实体识别研究综述[J].计算机工程与应用, 2024, 60(1): 15-27. DOI: 10.3778/j.issn.1002-8331.2304-0398.
[5]DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[J]. arxiv preprint arxiv:1810.04805, 2018.
[6]陈莹璇,谢炜豪,陈帆,等.中医古籍《灵枢》的知识图谱构建与可视化探讨[J].广州中医药大学学报, 2024, 41(3): 782-790. DOI: 10.13359/j.cnki.gzxbtcm.2024.03.038.
[7]张莹莹.基于知识图谱的舌像诊疗系统研究与构建[D].成都:电子科技大学, 2019.
[8]闫博.基于HanLP关键词抽取与句法分析的图谱构建[J].电子元器件与信息技术, 2022, 6(9): 77-80, 84. DOI: 10.19772/j.cnki.2096-4455.2022.9.019.
[9]孙北宁,吕维新,曾俊,等.一种结合TF-IDF和Simhash的科技项目文本相似性度量方法[J].电子技术应用, 2023, 49(6): 89-93. DOI: 10.16157/j.issn.0258-7998.223379.
[10]高永奇.语料库与SPSS统计分析方法[M].苏州:苏州大学出版社, 2020: 293.
[11]高佳希,黄海燕.基于TF-IDF和多头注意力Transformer模型的文本情感分析[J].华东理工大学学报(自然科学版), 2024, 50(1): 129-136. DOI: 10.14135/j.cnki.1006-3080.20221218002.
[12]杨牧,蔡言胜.依存句法分析的回顾与发展[J].现代语文,2022(1): 89-95.
[13]杨旭华,金鑫,陶进,等.基于图神经网络和依存句法分析的文本分类[J].计算机科学,2022,49(12): 293-300. DOI: 10.11896/jsjkx.220300195.
[14]HE H, CHOI J D. The stem cell hypothesis: dilemma behind multi-task learning with transformer encoders[C]//Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Online and Punta Cana, Dominican Republic. Stroudsburg, PA, USA: Association for Computational Linguistics, 2021: 5555-5577. DOI: 10.18653/v1/2021.emnlp-main.451.
