价格引导双流自注意力序列推荐模型
2024-07-01孙克雷吕自强
孙克雷 吕自强


【摘 要】 针对传统序列推荐算法捕获交互序列中的长期依赖性能力较弱,以及由于数据稀疏性导致推荐结果缺乏个性化的问题,提出了一种价格引导双流自注意力序列推荐模型。通过融合项目价格信息分析用户价格偏好并辅助计算项目相似度,提高推荐结果的个性化程度;将两种信息输入到两个独立的自注意力机制,学习不同位置的重要性、提取其特征,并将输出进行拼接后输入到门控单元学习时间依赖性,提高模型的长期依赖性建模能力。在三个公开数据集上验证了模型的有效性,命中率和归一化折损累积增益最低提升1.11%,最高提升5.34%。
【关键词】 推荐算法;序列推荐;项目价格;自注意力机制;长期依赖性
Price-guided Dual Self-attention Sequential Recommendation Model
Sun Kelei, Lyu Ziqiang*
(Anhui University of Science and Technology, Huainan 232001, China)
【Abstract】 Aiming at the problem that the traditional sequential recommendation algorithm has a weak ability to capture the long-term dependence in the interaction sequence, and the lack of personalization of the recommendation results due to data sparsity, this paper proposes a Price-guided Dual Self-attention Sequential Recommendation (PG-DSASR). By integrating item price information to analyze user price preference and assist in calculating item similarity, the personalized degree of recommendation results is improved. The two kinds of information are input into two independent self-attention mechanisms to learn the importance of different positions and extract their features, and the output is spliced and input into the gated unit to learn the time dependence, so as to improve the long-term dependence modeling ability of the model. The effectiveness of the model is verified on three public datasets. The hit rate and the cumulative gain of normalized loss are increased by 1.11% at the minimum and 5.34% at the maximum.
【Key words】 recommendation algorithm; sequential recommendation; item price; self-attention mechanism; long-term dependence
〔中图分类号〕 TP391 〔文献标识码〕 A 〔文章编号〕 1674 - 3229(2024)02- 0029 - 07
[收稿日期] 2023-10-27
[基金项目] 国家自然科学基金项目(61703005);安徽省高校科研重点项目(2022AH050821)
[作者简介] 孙克雷(1980- ),男,博士,安徽理工大学计算机科学与工程学院副教授,研究方向:推荐系统。
[通讯作者] 吕自强(2000- ),男,安徽理工大学计算机科学与工程学院硕士研究生,研究方向:推荐系统。
0 引言
随着互联网的迅猛发展和广泛应用,数据呈现爆炸性增长,为了有效处理海量信息,个性化推荐系统[1-2]迅速崭露头角。早期的推荐模型主要采用协同过滤[3]的方式来挖掘用户交互序列中的静态变化,然而随着时间推移,用户的兴趣会逐渐演变。为了更准确地捕捉用户在一段时间内的兴趣变化,序列推荐模型[4]应运而生。从最初的马尔可夫链模型[5]到基于循环神经网络、卷积神经网络以及自注意力机制[6]的模型,序列推荐领域百花齐放。目前,基于自注意力机制的序列推荐模型成为该领域的研究热点,但仍然存在一些问题。数据稀疏一直是序列推荐领域难以回避的难题。单一的交互序列嵌入输入的信息受限,难以有效支持网络中大量参数的更新,从而影响推荐精度。在自注意力机制中,直接拼接辅助信息与项目嵌入则可能引入额外噪声。此外,独立的自注意力网络难以很好地捕获交互序列中的长期依赖性。
基于以上分析,考虑到用户在购物时通常关注商品的性价比,而价格与用户期望不符的商品在一定程度上可视为噪声,价格信息作为一种重要的辅助信息能够有效反映用户的兴趣偏好,可以通过引入价格信息来缓解数据稀疏性问题。为了避免直接拼接异构信息引入额外噪声的问题,设计了双流自注意力网络,分别用于学习项目和价格的转换模式。随后,将双流自注意力网络与GRU进行融合,提高模型对用户序列中长期依赖性的捕获能力,提出一种价格引导双流自注意力序列推荐模型(Price-Guided Dual Self-Attention Sequential Recommendation Model,PG-DSASR)。为了证明模型的有效性,在三个公共数据集上进行了对比试验,证明模型在命中率和归一化折损累积增益的4个指标上有一定的提高。
1 相关工作
序列建模的目的是分析用户历史交互数据并从中提取特征和规律,从而实现符合用户偏好的推荐。早期的基于马尔科夫链的模型假设用户的下一次交互受到前一个或者前几个交互的影响,这使得它能够捕获序列中的短期相关性。然而基于这种假设,它在捕获用户-项目交互的复杂的长序列关系时存在较大的局限性。进入深度学习时代,神经网络被引入到序列推荐领域,它们不仅可以挖掘数据中更深层次的信息,而且具有十分灵活的网络结构特征。基于循环神经网络的序列推荐算法[7]能够从全局的角度考虑整个交互序列,在对用户的长期偏好进行建模方面具有较大优势,然而RNN无法很好地长期记忆,它会遗忘之前的信息。受到卷积神经网络的启发,将交互序列的嵌入看成图像并进行卷积操作从而达到提取项目之间局部依赖关系的目的,进而提出了Caser模型[8]。自注意力机制会给那些与下一个交互相关性较大的物品分配较大的注意力权重,反之则分配较小的权重。基于自注意力机制,Kang等[9]提出了SASRec模型。后来Sun等[10]进一步利用双向Transformer和掩码预测任务,提出了BERT4Rec模型用于序列推荐。Li等[11]提出TiSASRec模型,在SASRec的基础上添加了项目的时间间隔信息。除此之外,一些模型针对点击注意力机制的计算局限进行了改良,例如STOSA模型[12]使用沃瑟斯坦距离来衡量两个项目之间的相似度。此外,Gholami等[13]提出可解释性模型PARSRec,它通过融合自注意力机制和循环神经网络,来挖掘物品之间的深层关系以提高推荐质量。
尽管上述序列推荐模型考虑到了引入辅助信息以缓解数据稀疏性的问题,但却忽略了直接拼接异构信息可能带来的额外噪声,同时在捕获交互序列的长期依赖性方面存在一定不足。因此,PG-DSASR通过将双流自注意力网络与GRU进行融合,不仅成功引入价格信息以缓解数据稀疏性问题,还有效解决了直接拼接异构信息可能产生的额外噪声,同时提升了模型对长期依赖性的建模能力。
2 模型框架
PG-DSASR模型框架如图1所示,模型的结构包括四个部分,分别为嵌入层、双流自注意力网络、长期依赖性建模以及预测层。其中嵌入层将模型输入转化为低维嵌入表征;双流自注意力网络通过使用两个多头自注意力模块分别提取交互项目信息以及项目价格信息的嵌入表征,然后进行表征融合;长期依赖性建模则通过GRU的重置门将双流自注意力网络的输出[vj]和上一层的隐藏状态[?j]相结合,并通过更新门进行信息的更新;预测层根据输出计算用户下一项可能感兴趣的项目。模型的外部结构采用串联设计的方法,即每个模块接收一个隐藏状态和一个输入,并产生一个输出和下一个隐藏状态。
2.1 问题定义
序列推荐的任务是利用用户的历史行为来预测未来可能感兴趣的项目。为了便于表述,将I={[iu1,iu2,iu3,…,iu|I|]}定义为项目集,将P={[pi1,pi2],…,[pim]}定义为项目的价格信息合集,将U={[u1],[u2,u3,…,u|U|]}定义为用户集。[|I|]表示数据集中不重复项目的数量,m表示价格信息的数量,[|U|]表示数据集中不重复用户的数量。模型的目标是预测用户在t+1时刻可能交互的项目。
2.2 双流自注意力网络
双流自注意力网络由两个独立的自注意力机制构成,因此可以通过学习两个嵌入表示的相似性来识别对下一个商品产生重大影响的商品,而不用考虑它们之间的位置关系,且从表征的多个子空间学习比从单个表征学习更灵活。双流自注意力网络使用不同的多头注意力机制处理不同类别的输入信息,并将输出的嵌入表征进行拼接,然后输入到线性层以调整维度和压缩语义,如图2所示。
模型在计算键K、值V和查询Q之间的点积的过程中,K和V是相同的,它们的行均是项目的嵌入和项目价格信息嵌入。然而矩阵Q是不同的,它是由用户嵌入和上一个隐藏状态拼接而成的。为了缓解过拟合,提高稳定性,并加快训练过程,网络架构添加了层归一化(LN)和Dropout。
[MultiHead(Q,K,V)=FC(Concat(?eadl1,?eadl2,… ,?eadlh)⊙Concat(?eadp1,?eadp2,… ,?eadph))] (1)
[?eadi=Attention(QWQi,KWKi,VWVi)] (2)
[Attention(Q,K,V)=Softmax(QKTd/?)V] (3)
其中,FC是全连接层,[⊙]表示对多头自注意力机制的输出表征进行拼接,h表示head的数量,[WQi∈Rdq×dq],[WKi∈Rdk×dq],[WVi∈Rdv×dq]是模型学习得到的参数,[dk]是健和值的维度,[dq]是查询的维度。第m行的健、值和查询分别为:
[Q=Concat(EU,?j)] (4)
[m_throw(KI)=m_throw(VI)=EIi(S)m] (5)
[m_throw(Kp)=m_throw(Vp)=EPp(S)m] (6)
在处理多维稠密数据集中的丰富结构和互动关系时,单层的双流注意力网络的模型容量可能会受到限制,导致编码和表示能力不足。通过引入更多的注意层,模型能够逐步学习和捕捉数据中更丰富、更复杂的关系,可以很好地解决上述问题。每一层的注意力机制都可以专注于不同层次的特征和关联,从而提供更全面的编码和表示。具体而言,可以使用相同的查询Q来堆叠多个注意层,并将上一层的输出作为下一层的键K和值V,使模型可以建立起更深入的理解和上下文依赖。
2.3 长期依赖性建模
模型中将双流自注意力网络与门控循环单元相结合,有助于帮助模型更好地捕获交互序列中的长期依赖关系。双流自注意力网络的输出作为GRU模块的输入,并且将查询Q作为隐藏状态输入到GRU内部,计算过程如公式(7)~(10)所示:
[zt=σ(Wz?[?t-1,vt])] (7)
[rt=σ(Wr?[?t-1,vt])] (8)
[?t=tanh (W?[rt⊙?t-1,vt])] (9)
[st=(1-zt)⊙st-1+zt⊙?t] (10)
其中,[σ]表示sigmoid激活函数,用该函数可以将数据映射到0到1之间的范围,从而充当门控信号,[zt]和[rt]分别为更新门和重置门,[vt]是t时刻自注意力层的输出,在此作为门控循环单元的输入,[?t]是当前时刻的候选隐藏状态,[st]代表了用户在t时刻的偏好状态。
隐藏状态携带用户信息和序列的当前状态,为了确保它不会随着数据的更新而消失,模型在每一步都将用户嵌入连接到隐藏状态。初始隐藏状态对交互历史进行编码,这是用户历史操作中嵌入项目的加权平均值。随后,将这些信息提供给GRU可以提高模型的预测精度,其中的更新门负责保存适量的记忆信息,重置门负责将记忆信息与双流自注意力网络的输出信息融合。
2.4 预测层
在每一步使用GRU的输出来预测下一个项目。将GRU的输出乘以[EI],得到一个大小为|V|的相似向量。具有较高值的索引表示接下来更有可能与之交互的项,对这个向量进行排序,并在此基础上进行下一个项目的推荐。模型采用交叉熵函数作为损失函数:
[L=-log(exp (y[target])kexp(y[k]))2] (11)
其中,y是输出,target是要预测的真实项目[V'j+1]。
3 模型验证
3.1 数据集
为了验证模型的推荐效果,选取三个广泛使用的公开数据集Yelp、Amazon Book和MovieLens-1M。Yelp是美国著名商户点评网站,Yelp数据集由来自8大都市区域的约16万商户和800多万条评论等数据构成;Amazon Book是从亚马逊平台收集来的商品评论数据集;MovieLens-1M 是广泛使用在推荐系统中的基准数据集,包含上千用户及其对各类电影的评价。为了方便起见,下文采用“Book”和“Ml-1M”作为简称。数据集详细内容如表 1 所示。
3.2 评价指标
为了评估提出的模型的有效性,使用命中率HR@K(hit ratio)和归一化折损累积增益 NDCG@ K(normalized discounted cumulative gain)作为评价指标,其中K为推荐列表的长度。评价指标的值越大,则表示模型的推荐性能越高。
(1)HR@K表示成功推荐的用户在所有用户中的比例,计算公式如下:
[HR@K=nN] (12)
其中[n]表示推荐正确的项目的数量,[N]代表参与计算的项目数量。
(2)NDCG@K表示成功推荐的结果在推荐列表的排名,分值越高,排名越靠前。计算公式如下:
[NDCG@K=1|Z|U i=1k 2r(i)?1log2(i+1)] (13)
其中r(i)是第i个项目与正样本之间的相关性分数,值为1和0,分别表示正样本和负样本。
3.3 对比模型
为验证PG-DSASR模型的推荐性能,选取GRU4Rec、SASRec、TiSASRec和PARSRec四个模型进行了对比试验,模型介绍如下:
(1)GRU4Rec[7] 基于循环神经网络的深度学习推荐模型;
(2)SASRec[9] 首个使用纯注意力机制进行序列推荐的模型;
(3)TiSASRec[11] 2020年提出的基于自注意力机制的序列推荐模型,引入显性的交互时间间隔到Transformer网络中;
(4)PARSRec[13] 2022年提出的融合自注意力机制和循环神经网络的推荐模型。
3.4 实验结果对比与分析
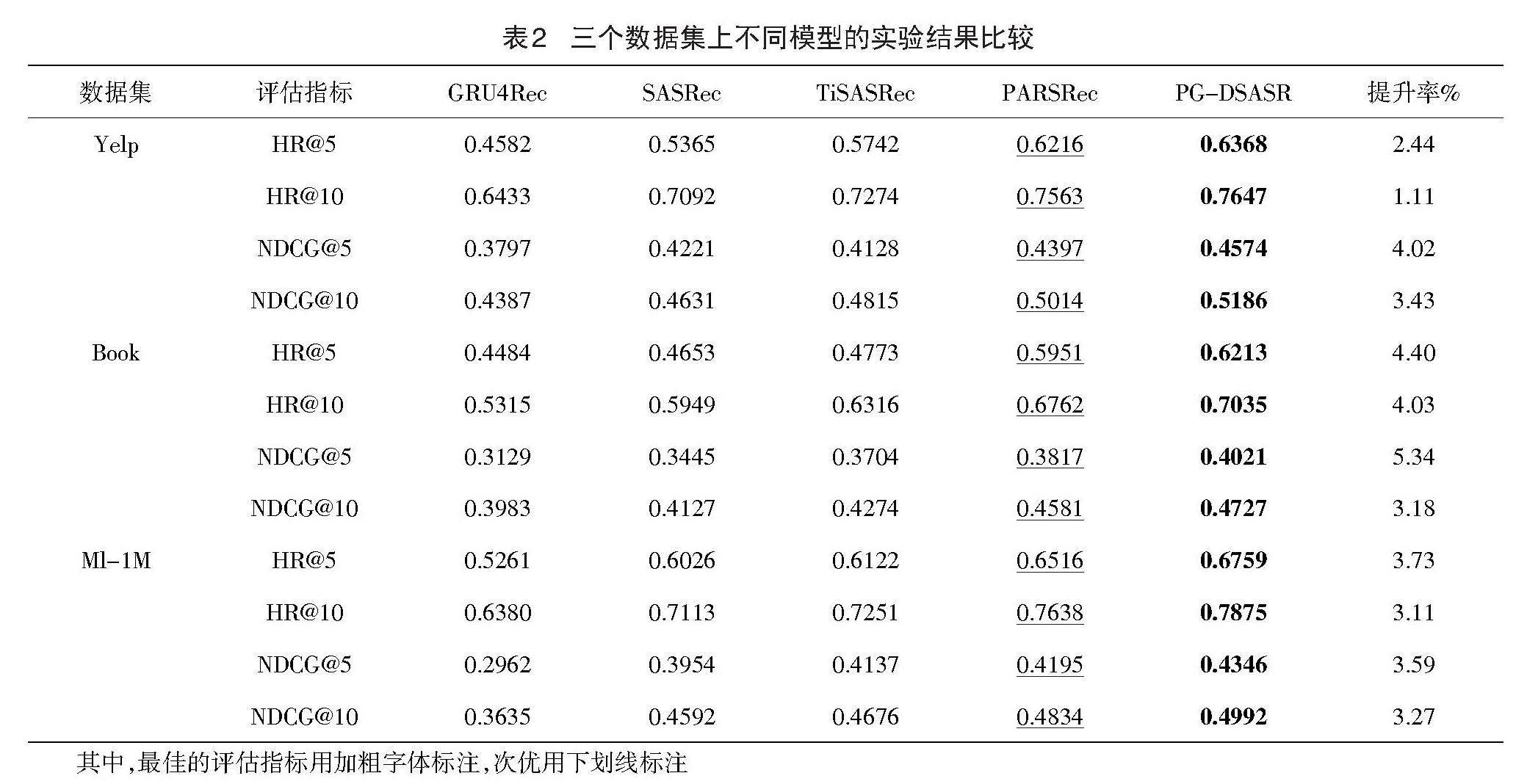
实验中将数据集划分为训练集、验证集和测试集,将样本序列的最后一项用作测试,倒数第二项用于验证,其余则为训练使用。在训练过程中采用学习率为0.001、[β1]=0.9、[β2]=0.999的Adam和Sparse Adam优化器进行优化,各项实验参数采用原论文中的默认值,超参数根据实际情况调整,评估指标的K值分别取5和10。表2显示了所有模型在三个数据集上的模型性能。实验结果分析如下。
PG-DSASR模型在三个数据集上都展示出了最好的性能,在Yelp数据集中与次优模型相比,HR@5和HR@10分别提升了2.44%和1.11%,NDCG@5和NDCG@10分别提升了4.02%和3.43%;在Book数据集中与次优模型相比,HR@5和HR@10分别提升了4.40%和4.03%,NDCG@5和NDCG@10分别提升了5.34%和3.18%;在Ml-1M数据集中与次优模型相比,HR@5和HR@10分别提升了3.73%和3.11%,NDCG@5和NDCG@10分别提升了3.59%和3.27%。评估指标的提升说明:PG-DSASR模型使用双流自注意力网络分别提取交互项目信息和项目价格信息,避免了直接融合异构信息而产生噪声,并且融合了门控循环单元的网络结构,可以同时学习交互项目之间的时间依赖性和不同位置的重要性。GRU4Rec相比于PG-DSASR推荐效果不佳的原因是传统的循环神经网络架构参数较少,无法很好地捕获序列特征,序列建模能力较弱。SASRec相比于PG-DSASR推荐效果不佳的原因是没有解决数据稀疏问题,而且单纯的自注意力网络结构在捕获交互序列中的长期依赖性方面效率较低。TiSASRec相比于PG-DSASR推荐性能不佳的原因是:直接将序列信息与时间间隔信息融合进行注意力计算会产生额外噪声,并且网络结构单一,无法很好地捕获交互序列中的长期依赖性。PARSRec的推荐性能优于SASRec和TiSASRec的原因是:将自注意力机制与RNN融合,提高了模型在挖掘交互数据深层次信息方面的能力,但是它没有考虑缓解数据稀疏问题,且RNN存在遗忘性无法很好地保留信息,最终导致推荐效果不佳。通过表2可以看出PG-DSASR在Book数据集上评估指标的提升最明显,因为Book相比于Yelp和Ml-1M数据更稀疏,验证了模型考虑价格信息对缓解数据稀疏性的有效性。
3.5 消融实验
3.5.1 模型结构分析
为了了解模型的各个组成部分对整体性能的影响,进行了一系列的消融实验。表3总结了最优模型和其变体在三个数据集上的性能,变体如下:
(1)PG-DSASR-P 去除价格信息输入;
(2)PG-DSASR-D 使用单一的自注意力网络;
(3)PG-DSASR-G 使用普通RNN代替门控循环单元。
通过对比结果,可以得知价格信息在反映用户偏好方面起着关键作用。如果将价格信息排除在用户画像之外,可能导致用户画像的不完整,进而影响推荐结果的个性化程度。此外,去除价格信息后数据稀疏性问题变得更加突出,进而影响推荐结果的质量。因此,可以看出引入价格信息有助于提升模型的推荐能力。将价格信息与项目交互嵌入进行线性拼接,并输入自注意力机制,发现最终模型性能下降,原因在于直接融合异构信息进行点积自注意力计算会引入额外的噪声。因此,使用双流自注意力机制分别提取异构信息可以显著提高模型的推荐质量。
另外,采用普通的RNN模块会导致模型性能下降,因为在实际运用中,RNN存在梯度爆炸的问题,导致忘记较远的信息。相比之下,GRU通过其精妙的门结构,合理地遗忘和保留信息,信息能够长期传递下去。因此,选择GRU能够有效解决梯度爆炸的问题,有助于提升模型的长期依赖建模能力。
3.5.2 模型各组件对评估指标的影响
测试模型中各个组件以及网络设计的一些变化对模型性能的影响,结果如表4所示。
根据表4的数据可以得知,Dropout在降低过度拟合的风险、增强模型的泛化能力方面发挥了积极作用。另外,Layer Normalization(LN)的使用有助于减少不同样本之间的浮动,提高模型的稳定性和训练速度。数值表明,移除Dropout和LN都导致模型的总体性能下降,进一步证明它们的存在对提高推荐模型的质量起到关键作用。
此外,从LN中移除Q同样会降低推荐性能。这是因为Q中包含了用户的历史记录信息,而通过残差操作将其添加到GRU输入中有助于提升推荐性能。因此,可以看出Q的存在对于充分利用用户的历史信息、提高推荐性能至关重要。
3.5.3 双流自注意力网络层数对评估指标的影响
图3展示了双流自注意力网络不同层数的设置对模型推荐性能的影响。对网络层数从1到4分别进行了消融实验,评估指标采用NDCG@10。
根据图3的观察结果,可以得知增加双流自注意力网络的层数对模型整体性能的影响并不十分显著。当层数达到2时,评估指标达到峰值,相较于其他层数只有轻微的提升。这表明一层双流自注意力网络已经能够捕获大部分的数据信息,而增加到两层时信息挖掘的能力已经趋于饱和。进一步增加层数反而可能导致性能下降,说明层数的继续增加并不会带来额外的正面效果。
4 结论
本文提出的价格引导双流自注意力序列推荐模型通过引入价格信息成功缓解了数据稀疏问题。该模型采用了两个独立的自注意力机制,分别处理价格信息和序列信息,以避免产生额外的噪声。通过将自注意力机制和门控循环单元融合,分别学习交互序列的时间依赖性和不同位置的重要性,从而对长期依赖关系进行有效的建模,最终提高了模型的个性化推荐能力。在三个真实数据集上的评价指标相较于近期提出的基线模型均取得了显著的提升。未来的工作将着重研究如何更好地捕获用户的短期兴趣,并将其融入模型,以进一步提升推荐性能。这个方向的深入研究将有助于模型更全面、准确地理解用户兴趣动态,从而更好地满足个性化推荐的需求。
[参考文献]
[1] 刘姗姗, 游健强, 史家朋, 等. 网络信息爆炸时代消费行为决策的公众评价效应分析——以大众点评为例[J]. 内蒙古科技与经济, 2022(13):64-66.
[2] 刘君良, 李晓光. 个性化推荐系统技术进展[J]. 计算机科学, 2020, 47(7):47-55.
[3] Linden G, Smith B, York J. Amazon. com recommendations: Item-to-item collaborative filtering[J]. IEEE Internet computing, 2003, 7(1):76-80.
[4] 于蒙, 何文涛, 周绪川, 等. 推荐系统综述[J]. 计算机应用, 2022, 42(6):1898-1913.
[5] Steffen Rendle, Christoph Freudenthaler, Lars Schmidt-
Thieme. Factorizing personalized Markov chains for next-basket recommendation[A]. Proceedings of the 19th International Conference on World Wide Web[C]. New York: Association for Computing Machinery, 2010: 811-820.
[6] Ashish V, Noam S, Niki P, et al. Attention Is All You Need[A]. Proceedings of the 31st International Conference on Neural Information Processing Systems[C]. Red Hook:Curran Associates Inc, 2017:6000-6010.
[7] Hidasi B, Karatzoglou A, Baltrunas L, et al. Session-based recommendations with recurrent neural networks[J]. arXiv preprint arXiv:1511.06939, 2015.
[8] Tang J, Wang K. Personalized top-n sequential recommendation via convolutional sequence embedding[A]. Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining[C]. New York:Association for Computing Machinery, 2018: 565-573.
[9] Kang W C, McAuley J. Self-attentive sequential recommendation[A]. 2018 IEEE International Conference on Data Mining (ICDM)[C]. Singapore:IEEE, 2018:197-206.
[10] Sun F, Liu J, Wu J, et al. BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer[A]. Proceedings of the 28th ACM International Conference on Information and Knowledge Management[C]. New York:Association for Computing Machinery, 2019:1441-1450.
[11] Li J, Wang Y, McAuley J. Time interval aware self-attention for sequential recommendation[A]. Proceedings of the 13th International Conference on Web Search and Data Mining[C]. New York:Association for Computing Machinery, 2020:322-330.
[12] Fan ZW, Liu ZW, Yu W, et al. Sequential Recommendation via Stochastic Self-Attention[A]. Proceedings of the ACM Web Conference 2022[C]. New York:Association for Computing Machinery, 2022:2036-2047.
[13] Ehsan Gholami, Mohammad Motamedi, Ashwin Aravindakshan. PARSRec: Explainable Personalized Attention-fused Recurrent Sequential Recommendation Using Session Partial Actions[A]. Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining[C]. New York:Association for Computing Machinery, 2022: 454-464.
