基于二分Kmeans的协同过滤推荐算法
2017-03-06吴金李张建明
吴金李+张建明


摘要摘要:针对传统协同过滤推荐算法中存在的数据稀疏性问题,提出了一种基于二分Kmeans的协同过滤推荐算法。该算法在Kmeans算法的基础上,为了降低初始质点选择对聚类结果的影响,在运行中逐个添加质点。首先初始化评分数据并将其作为初始簇,然后选择合适的簇随机产生两个质点将簇分裂为两个簇,重复上述步骤,直到聚类完成。最后为了降低不同用户评分标准差异,将用户评分的平均值和用户同簇内相互间的相似度相结合,计算预测评分矩阵,生成推荐结果。实验结果表明,改进后的算法较好地解决了数据稀疏问题,提高了推荐质量。
关键词关键词:Kmeans算法;二分Kmeans;协同过滤;推荐算法
DOIDOI:10.11907/rjdk.162275
中图分类号:TP312文献标识码:A文章编号文章编号:16727800(2017)001002603
引言
随着网络的发展,互联网上的信息量飞速增长,推荐系统根据这些用户行为信息,挖掘对用户有用的信息对用户进行个性化推荐。随着个性化推荐系统的发展,协同过滤算法成为目前使用最广泛的推荐系统基础算法[12]。其基本思想是找到与目标对象最相似的对象生成推荐结果[34]。
Goldberg等[5]最早提出协同过滤思想,后来明尼苏达大学在实际网站建设时又提出基于用户和基于项目的协同过滤推荐系统,形成传统的协同过滤推荐算法。在实际应用中随着用户数和项目数的增加,系统需要计算的数据量也相应增加,同时用于计算的用户项目评分矩阵数据变得更稀疏,这些都对推荐系统的性能产生影响。因此Sarwar等[6]利用Kmeans算法对用户进行聚类,缩小最近邻的搜索范围,改善可扩展性问題。Herlocker J等[7]对项目进行聚类,缩小了目标项目的最近邻搜索范围,有效减少了运算数据量。Tsai CF等[8]在理论和实验上阐明,基于SOM和Kmeans聚类方法可以作为协同过滤算法的基准,提高了推荐系统的精度。
针对网络数据量大、信息种类复杂等问题,在协同过滤推荐算法的基础上采用大数据处理中的Kmeans算法,可以有效地将数据进行分类,但初始质点的选择对Kmeans算法聚类的结果影响较大。为解决初始质点选择问题,本文提出改进二分Kmeans方法,动态地为数据集添加质点,经迭代计算出所有质点,降低初始质点选择带来的误差,并且添加边界值处理。计算预测评分时针对用户的评分标准不同,采用平均值法降低其所带来的影响,结合对象之间的相似度对预测评分方法加以改进。实验结果表明,本实验方案效果更好。
1基于Kmeans的协同过滤推荐算法
1.1传统协同过滤推荐算法
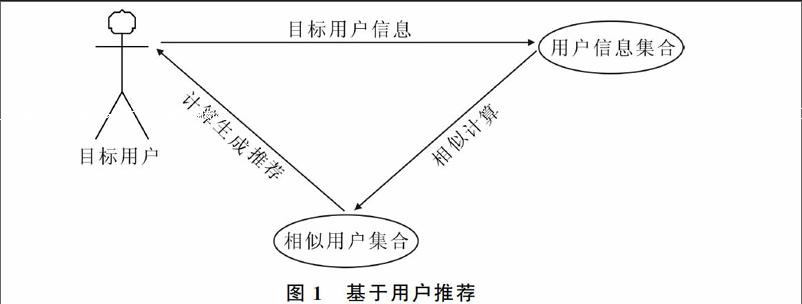
协同过滤算法包括两种思想,基于用户协同过滤和基于项目的推荐算法。基于用户协同过滤算法的基本思想:①找到和目标用户兴趣相似的用户集合;②找到该集合中用户喜欢的,且目标用户没有听说过的物品推荐给目标用户[8],如图1所示。
图1基于用户推荐
首先收集并处理所有用户信息,然后将目标用户的信息与用户信息集合中的信息作相似计算得出相似用户集合。其中关键是计算用户间的相似度,通过第一步数据的处理,用户信息已经转化为空间向量信息,计算空间向量的相似性有效方法,即皮尔森相关系数(PCC)[9]相对于其它方法而言较为准确,例如相对于余弦相似性计算,PCC对向量作去中心和归一化处理,降低了不同用户评分标准不同所产生的影响,皮尔森相关系数如式(1)所示。最后根据用户相似矩阵计算目标用户未接触的商品的预测评分产生推荐结果,对用户进行推荐。
其中Ri、Rj表示用户评分均值,Rik、Rjk表示用户对k项目的评分。
基于物品协同过滤算法基本思想:①计算物品之间的相似度;②根据物品的相似度和用户的历史行为生成推荐列表[10],如图2所示。与基于用户协同过滤类似,基于物品协同过滤算法首先计算出物品之前的相似度,再根据目标用户的历史信息,计算预测与之相似的物品,最后对目标用户形成推荐。
图2基于物品推荐
随着网络用户数目的增加,计算用户相似性的难度加大,运算时间复杂度和空间复杂度的增长和用户数的增长近似于平方关系。因此,著名的电子商务公司亚马逊提出了基于物品的协同过滤算法[11]。由此可以看出,基于用户推荐算法注重找到与用户相似的用户集合中的热点,而基于物品推荐算法则注重用户的历史信息,更倾向于个性化推荐。1.2基于Kmeans的协同过滤推荐算法
在计算对象间的相似度时,传统推荐算法首先计算出每两位用户的相似度,当对象的数据量达到一定程度时,相似度计算量将会非常大。因此,为了降低数据计算量,采用大数据中用于数据分类的Kmeans聚类方法。算法首先根据数据大小确定k个质点做初始质心,计算数据集中所有数据距离最近的质点,将数据指派到该质点所在的簇中。然后根据指派到簇的点,更新每个质心。重复以上步骤,直到质心不再变化,数据被指派到不同的簇[1013]。
为了计算目标用户的相似用户,首先计算目标用户和每个簇内质心的相似性,计算出目标用户所属簇。再计算出目标用户和簇内用户的相似性,得出目标用户相似用户集合。最后对目标用户未接触的物品预测评分后生成推荐。
2基于二分Kmeans的协同过滤推荐算法
Kmeans算法最重要的是质心的选择,质心的选择可以根据数据集中数据的范围,随机生成指定个数的质心。当簇的数量比较大时,比较容易出现质点在簇中分布不均,即可能出现有些簇中质点个数相当少的情况,此时这些初始质心到其它质心的距离较大[12]。当质心相对距离较远时,Kmeans算法不能很好地在簇与簇之间重新计算分布质点,因而聚类结果不佳。为了改善Kmeans聚类方法初始质心选择所带来的影响,采用二分Kmeans算法。二分Kmeans算法思想是为了得到k个簇,将所有点的集合分裂成两个簇,再根据SSE值从这些簇中选取一个最大的继续分裂,直到产生k个簇。其中SSE表示javascript:;用数据集中每个数据和其质心的欧几里得距离计算误差平方,然后求得所有误差和。SSE公式如式(2)所示[13]。
其中,ci表示质心坐标,x表示质心为ci的数据。dist表示空间两个向量的欧几里得距离。每次选定最小的SSE后,重新计算每个簇的质心,采用均值法来计算。第i个簇的质心由式(3)定义。
ci=1mi∑x∈Cix(3)
一般二分Kmeans算法在选取对哪一簇分类有多种方法时,可以选择SSE结果最大簇或者基于一个标准SSE值来选择,并且不考虑边界情况。本文在选取分类簇上按照簇的编号,依次选取。如果在已有的簇中找不到分类后更小的SSE值,并且质心个数小于k,则停止循环,输出现有质心坐标和分类结果。具体流程如图3所示。首先初始化数据,然后判断质心个数是否小于k值,若成立则循环计算分类前SSE1值和分类后SSE2值直到SSE2 对每个簇中所有用户的数据根据皮尔森相关系数[14]计算同一簇内每两个用户间的相似性,然后对用户未评分的部分预测评分。根据相似性,由于每个用户评分标准不同,在计算评分时消除个人评分对目标评分结果的影响。具体实现如式(4)所示。 pu,i=Ru+∑j∈Misim(u,j)×(Rj,i-Rj)∑j∈Mi(|sim(u,j)|)(4) 其中,Pu,i表示用戶u对项目i的评分,Ru表示用户评分均值,Rj,i表示j用户对i项目的评分,Rj表示j用户评分均值。 基于二分Kmeans推荐算法首先对初始数据聚类,然后计算每个簇中用户相似性,最后对用户评分矩阵进行评分预测后,找出预测评分最高的前N个物品形成推荐[15]。具体实现步骤如图4所示。 Step1:将用户评分数据分为训练集和测试集,将两类数据分别存入二维数组中。 Step2:设置分类数量k。 Step3:将训练集数据带入图3流程图进行计算,得到k个质心坐标,并为数组存放每位用户所属的簇。 Step4:根据式(1)计算k个簇内每位用户在其对应的簇内与同簇内每位用户的相似性,求出k个相似矩阵表。 Step5:将相似矩阵表和初始数据表中数据带入式(4)得到预测评分,根据topN得到推荐。 3实验结果及分析 实验数据是MovieLens数据集中小规模的库,包括943位独立用户对1 682部电影的100 000次评分数据。用户对已看过的电影评分,评分范围为1~5。实验采用Java开发平台,根据用户评分生预测评分矩阵从而形成推荐。 评价推荐系统推荐质量的度量标准采用平均绝对误差MAE进行度量。通过计算预测评分和实际评分的MAE值来判断推荐效果。当MAE值越小时,推荐的质量越高,反之推荐的质量越低。MAE公式如式(5)所示,其中pi表示系统对用户的预测评分,qi表示用户的实际评分。 MAE=∑Ni=1|pi-qi|N(5) 本文对Kmeans协同过滤和二分Kmeans协同过滤算法在相同数据集中进行比较,实验结果如图5所示,最近邻个数增加时MAE值减小,表示预测结果越好,基于二分Kmeans的协同过滤推荐效果优于基于Kmeans协同过滤的推荐效果。 4结语 随着互联网科技的发展,网络数据蕴含的信息将逐渐被人挖掘,推荐系统可以有效地处理数据,但由于网络数据存在数据稀疏、数据量大等问题,因而本文采用基于二分Kmeans的协同过滤推荐算法。该算法将相同类别的数据聚集在一起,将不同类别的数据加以分离,降低运算量。对数据动态地添加质点,再更新数据类别,可提高数据分类效果,使得每个类别内的数据结合更紧密,类之间的差距也相应增加。实验结果表明,本文采用基于二分Kmeans的协同过滤推荐算法能够有效提高算法性能。 参考文献: [1]LINDEN G,SMITH B,YORK J.Amazon.com recommendations:itemtoitem collaborative filtering[J].IEEE Internet Computing,2003,7(1):7680. [2]CHUNG K Y,LEE D,KIM K J.Categorization for grouping associative items using data mining in itembased collaborative filtering[J]. Multimedia Tools & Applications,2014,71(2):889904.
