基于BERT和超图对偶注意力网络的文本情感分析
2024-05-24胥桂仙刘兰寅王家诚陈哲
胥桂仙 刘兰寅 王家诚 陈哲

摘 要:针对网络短文本存在大量的噪声和缺乏上下文信息的问题,提出一种基于BERT和超图对偶注意力机制的文本情感分析模型。首先利用BERT预训练模型强大的表征学习能力,对情感文本进行动态特征提取;同时挖掘文本的上下文顺序信息、主题信息和语义依存信息将其建模成超图,通过对偶图注意力机制来对以上关联信息进行聚合;最终将BERT和超图对偶注意力网络两个模块提取出的特征进行拼接,经过softmax层得到对文本情感倾向的预测结果。该模型在电商评论二分类数据集和微博文本六分类数据集上的准确率分别达到95.49%和79.83%,相较于基准模型分别提高2.27%~3.45%和6.97%~11.69%;同时还设计了消融实验验证模型各部分对分类结果的增益。实验结果表明,该模型能够显著提高针对中文网络短文本情感分析的准确率。
关键词:文本情感分析; 超图; 图分类; 注意力机制
中图分类号:TP311 文献标志码:A
文章编号:1001-3695(2024)03-020-0786-08
doi:10.19734/j.issn.1001-3695.2023.07.0311
Text sentiment analysis based on BERT and hypergraph with dual attention network
Xu Guixiana,b, Liu Lanyina,b, Wang Jiachenga,b, Chen Zhea,b
(a.Key Laboratory of Ethnic Language Intelligent Analysis & Security Governance of MOE, b.School of Information Engineering, Minzu University of China, Beijing 100081, China)
Abstract:To address the problems of large amount of noise and lack of contextual information in short texts on the Web, this paper proposed a text sentiment analysis model based on BERT and hypergraph with dual attention mechanism. This method firstly utilized BERT for dynamic feature extraction of sentiment texts. Meanwhile it mined the contextual, topic and semantic dependency information of the text to model it into a hypergraph, and then aggregated the above information through the dual graph attention mechanism. Finally, it spliced the features extracted by BERT and hypergraph with dual attention network, and obtained the prediction result after softmax layer. The accuracy of this model on the e-commerce review dataset and the Microblog text dataset reaches 95.49% and 79.83% respectively, which is 2.27%~3.45% and 6.97%~11.69% higher than the baselines, respectively. The experimental results show that the model can significantly improve the accuracy of sentiment analysis for Chinese Web short texts.
Key words:text sentiment analysis; hypergraph; graph classification; attention mechanism
0 引言
文本情感分析旨在通過对文本内容进行分析和理解,从中提取出表达者的态度或情感倾向,如积极、消极或中性[1],在众多领域中具有广泛的意义和应用价值。
用户社交媒体分析、产品评论挖掘是情感分析任务中两个重要的应用场景。微博文本是一种典型的社交媒体文本,承载着用户的情感、意见和态度。政府可以通过分析用户言论,了解公众对热点话题的情感反应,及时掌握社会舆论动态,为决策和舆情管理提供有力支持。电商平台上的产品评论包含了消费者的情感倾向和购买体验。深入挖掘消费者对产品的反馈文本,能够帮助商家、企业了解顾客对产品和服务的态度和喜好,从而更有针对性地推出高质量的商品和服务。
然而,此类网络文本大多字数较少,表达方式随意多样,通常存在大量的噪声和缺乏上下文信息,如表情符号、缩写词、网络俚语等,这给情感分析的准确性带来了困难。并且,在处理过程中需要对文本进行有效的全局建模,捕捉上下文信息和单词之间的长距离关联以及相应的语义信息,这对情感分析算法的鲁棒性和泛化能力提出了更高的要求。
针对以上问题,本文面向网络短文本提出了一种基于BERT和超图对偶注意力网络的情感分析模型。BERT已学习到了大量通用语义知识,具有较强的迁移能力,能够在一定程度上克服噪声问题,更加准确和全面地理解文本内容。在超图对偶注意力网络中,挖掘文本的主题、语义依存等多类信息将其建模成超图,并通过对偶注意力机制来聚合这些关联信息,使得模型能够更好地捕捉到全局语义关系。在电商评论和微博文本两个情感分析数据集上,通过多组对比实验和消融实验证明了该模型在情感分析任务上的优越性和各组成模块的有效性。
1 相关工作
随着社交媒体和在线评论等大规模文本数据的不断涌现,准确地分析和理解文本中蕴涵的情感信息变得尤为关键。过去几十年间,文本情感分析的发展经历了从情感词典匹配、基于统计机器学习到基于深度学习模型的过程。当下,社交平台的短文本呈现多样化的语义结构以及需要在更高维度上对数据进行处理,基于情感词典和机器学习等早期方法已不能很好地应对目前研究中存在的问题。深度学习模型在自动学习文本特征的同时又能够实现对高维稀疏的文本表示降维,因此越来越多的研究人员采用深度神经网络对文本进行端到端的情感分析。
基于CNN和RNN的神经网络是情感分析任务中最常见的两类模型,在早期的研究工作中取得了较大的突破[2]。随着注意力机制在计算机视觉领域中取得了惊人的成果,许多研究者将其引入到文本情感分类任务中,证明了其能够加强神经网络对重要特征筛选的能力,降低噪声干扰[3~5]。
谷歌团队基于自注意力机制,先后提出了Transformer[6]和BERT预训练模型[7],在各类自然语言处理任务中都取得了较大突破。RoBERTa[8]、ALBERT[9]等均是研究者们在BERT的基础上针对不同方面进行改进的预训练模型。此类模型的思想是:预先在大规模的语料上采用自监督的方式学习到通用的知识,在完成下游特定任务时,只需要少量相关领域的标注数据进行微调就能够取得较好的性能表现[10~12]。
近年来,图神经网络由于能够有效地处理非欧氏结构数据,在情感分析领域中取得了显著的进展。Yao等人[13]提出的TextGCN首次将图卷积神经网络应用到文本任务中,通过构造文本图的方式对整个语料库中的词共现和文档词关系信息进行建模,在MR电影评论情感数据集中取得了令人满意的效果。Lin等人[14]将大规模预训练模型与图卷积神经网络结合提出了BertGCN,使用BERT系列模型初始化文本图中的节点特征,GCN迭代更新文档表示,实验结果表明图神经网络可以从大规模预训练中显著受益。Jin等人[15]考虑词性和位置关联信息,提出了一种基于句法依赖图的多特征分层注意力情感分析模型,有效地提高了社交短文本的情感分类性能。Yang等人[16]针对文本图中的边构建方法不能很好适应长而复杂的上下文的问题,从多个角度捕获情感特征,还利用依赖性解析器分析每个单词之间的语法关系。Chen等人[17]考虑到现有方法忽略了用户情感取向互动的问题,使用GCN从社交网络中学习用户表示,BERT从用户意见文本中学习情感表示,通过两者融合来判断社交网络中的用户情感倾向。
然而对于含有高阶语义的文本,这些GNN类模型在构建图时,对文本信息并不能充分表达,图中成对的边关系限制了更高质量的文本学习能力。Ding等人[18]第一次尝试将超图运用到情感分类任务中,提出的HyperGAT模型能够捕获词之间的高阶交互关系,并通过超图获取文本语序和语义信息的特征表示,在MR二分类数据集中准确率达到78.32%。Kao等人[19]将HyperGAT用于多标签幽默文本分类任务中,性能远远优于其他基线模型。李全鑫等人[20]提出的IBHC(integration of BERT and hypergraph convolution)模型将BERT、超图卷积网络和注意力机制进行结合,在MR数据集上的实验证明,该模型结构能够增强全局结构依赖和局部语义两种特征的协同表达能力。
以上研究工作表明,将图结构应用在自然语言处理领域已有了非常大的进展和突破,但如何在将文本建模成图的同时保留更多内部信息仍是许多研究者正在探索的内容,而将普通文本图结构扩展为超图更是处于起步阶段,相关研究较少。大规模预训练模型具有强大的表征学习能力,超图结构能够有效地建模文本的语义关联和情感信息。基于此,本文在HyperGAT的基础上改进超图的构建方法,使其包含更多的语义关联和情感信息,并采用图注意力机制来聚合,同时与预训练模型BERT结合,实现针对中文网络短文本的情感分析任务,并选取较为成熟的相关模型进行对比实验,评估本文模型的性能表现。
2 基于BERT和超图对偶注意力网络的文本情感分析模型
本文提出的基于BERT和超圖对偶注意力网络的中文短文本情感模型B_HGDAN(BERT and hyper graph with dual attention network)结构如图1所示。总体分为两大部分,分别是BERT模块、基于超图和对偶注意力机制的HGDAN模块。
2.1 预训练模型BERT提取情感文本动态向量特征
BERT[7]中的自注意力机制允许模型在编码过程中同时考虑输入序列中的所有位置,并分配不同的注意力权重。这使得其能够捕捉文本中的全局依赖关系,可以更好地表达单词、句子和上下文之间的关系。
BERT模型在处理中文时以字为粒度进行,对于给定的由l个字符组成的中文文本序列S={s1,s2,…,sl},首先处理成BERT的输入格式,即S={[CLS],s1,s2,…,sl,[SEP]}。输入序列在经过N个Transformer层后,可得到每个字符对应的BERT向量表示,如式(1)所示。
R=BERT(S)(1)
其中:R={r[CLS],r1,r2,…,rl,r[SEP]},本文将[CLS]字符对应的输出r[CLS],作为该输入情感文本序列的特征向量。
2.2 情感文本超图构建
超图与传统简单图的区别在于,超图的超边可以连接两个或者多个节点。超图被用于描述样本对象之间更为复杂的高阶关系:节点表示对象,超边用来表示对象组之间的高阶交互[21]。
超图可以定义为图G=(V,E),其中集合V={v1,v2,…,vn}表示n个超节点,集合E={e1,e2,…,em}表示超图中的m条超边,使用关联矩阵作为超图的数学表达。超图的关联矩阵A∈Euclid ExtraaBpn×m定义如式(2)所示,若超点vi位于超边ej之上,则Aij为1,否则为0。
Aij=1 vi∈ej0 viej(2)
每条文本都可看作是一个词序列,可以构建出一张文本超图。本文将每个词视作一个超节点,分析文本挖掘超节点之间的关联,并通过超边表示。设每个超节点vi都具有d维的属性向量hi,则所有超节点属性可以表示为H=[h1,h2,…,hn]T∈Euclid ExtraaBpn×d。
为了对情感文本中的异构高阶上下文信息进行建模,本文构建了三种类型的超边,下文将以情感句“房间及服务员的态度让人满意。”为例进行详细说明。
2.2.1 上下文顺序超边
在文本情感分析任务中,准确地捕捉词语之间的上下文顺序关系是至关重要的。情感表达往往受到上下文环境的影响,同样的词语组成在不同的词序下可能表达不同的情感倾向,一些情感词或修饰词可能会影响到其前后的词语情感表达。通过考虑词语的共现关系,尤其是它们在句子中的相对顺序,有助于更准确地理解词语之间的关系。
在超图的构建过程中,本文使用固定大小的滑动窗口来捕捉情感句中的局部词共现信息,一个窗口所覆盖的词超点连接起来构成一条超边。通过这种方式,每个窗口都会生成一条超边,从而形成多条超边,反映情感句的上下文语序信息。图2是滑动窗口尺寸为5时,上下文超边的构建示例。
2.2.2 主题超边
文本的主题信息与情感具有紧密关系。例如“小”一词,当其出现在关于“水果”“酒店”等主题的用户评论里时,该评论可能表达的是负面情感,表示水果不够成熟或房间狭窄等意思;而当其出现在“电子产品”的评论里时,可能表示轻便、便于携带的意思,传达出的是积极情感。因此,本文通过挖掘情感文本中的主题信息,构建主题超边来捕捉单词与主题之间的高阶相关性,提高模型对文本情感倾向判断的精度。
本文使用Dieng等人[22]提出的嵌入式主题模型(embedded topic model,ETM)挖掘潜在主题信息。与传统LDA及其变体等基于词袋建模的主题模型不同,ETM使用word2vec将词向量信息融入到主题向量的训练中,在词向量空间完成主题建模。该模型结合了主题模型能够挖掘潜在语义结构与单词嵌入能够提供低维稠密表示的优势,考虑词语间的相互关系并使拟合出的潜在主题更具可解释性和可区分性。
从所有情感句中挖掘出K个潜在主题构成的集合为T={t1,t2,…,tK},对于每个主题,取前十个概率最大潜在主题词,表示为ti={tw1,tw2,…,tw10}。将每篇情感文本中同属于一个主题的词连接起来构建主题超边,如图3所示。
对于主题数K的最佳取值将通过实验探究,进而完成主题超边的构造,丰富每个情感句中单词的高阶语义上下文信息。
2.2.3 语义依存超边
许多研究将依存句法分析引入到文本情感分析任务中,并取得了令人满意的效果,证明了解析句子的依赖结构对于判断其情感倾向有着重要作用[15,23,24]。但句法分析主要是通过句子结构识别其语法成分并分析成分之间的依存关系,而电商评论、微博等口语化严重、表达通俗随意的网络文本大多不符合现代汉语的语法和语用规定,严重影响句法依存分析结果的准确性。而语义依存分析则是对输入文本中语言单位间的语义关联进行分析,不直接依赖句式语法结构,能够在一定程度上打破这一限制。因此,本文将语义依存分析引入超图构建中,通过语义超边来描述文本中词之间的语义依存信息。对文本进行语义依存分析可以得到如图4所示的依存结构,连接具有依存关系的超点,构建语义超边,从而捕获文本中的语义依赖关系信息。
2.3 对偶注意力机制
在图神经网络中,信息在节点之间传递,生成依赖于图结构的节点表示。而对于一张超图而言,一条超边可能连接了多个超点,一个超点可能存在于多条超边之上,节点间的信息传递问题则更加复杂。
为了支持在超图上的文本特征学习,本文受HyperGAT[18]中图注意力模块的启发,利用超边作为媒介,实现超节点间的特征传递,通过两个聚合函数学习节点表示,从而捕获文本超图上的异构高阶信息。两个聚合函数的定义如式(3)(4)所示。
其中:flj和hli分別表示超边ej和超点vi在第l层中的特征表示;Ei表示连接到超点vi的超边集合;函数AGGRnode 把一条超边上的所有超点特征聚合到该超边;函数AGGRedge为每一个超点聚合与其相连的所有超边特征。由于每个超点对其所在的超边贡献度都不同,每条超边对其连接的各个超点贡献度也不同,所以两个聚合函数的功能采用对偶注意力机制来实现。
2.3.1 超点级注意力
对于一条超边ej,超点级注意力首先计算超边上所有节点对该超边的注意力分数,对每个超点的重要性加以区分,以突出对超边更重要的信息,通过注意力系数加权聚合得到超边表示flj,如式(5)(6)所示。
3 实验与分析
3.1 实验数据集
为验证本文模型的有效性,在两个公开中文文本情感分析数据集上进行实验。online_shopping_10_cats(简称OS10)为二分类数据集(https://github.com/SophonPlus/ChineseN1pCo-rpus),来源于电商平台,包含书籍、酒店、水果等十个类别的产品评论共计6万条,分为积极和消极两种情感。SMP2020-EWECT(https://smp2020ewect.github.io)微博数据集包括开心、愤怒、悲伤等六种情感类别,来源于第九届全国社会媒体处理大会所发布的公开评测任务,包含疫情与通用两大主题,前者中的内容与新冠疫情相关,后者随机收集了平台上的微博数据,涉及范围更广,更能体现微博平台的整体生态,因此本文采用其中的通用微博数据集(简称SMP2020)。数据样例如表1所示。
本文后续实验中以词为粒度抽象成节点构建文本超图,因此首先对文本进行分词处理。分词后两个数据集的句子长度(词数)分布如图5所示。
由图5可以看出,OS10和SMP2020两个数据集的文本长度分别集中分布在[0,125]和[0,100]。经分析发现,OS10数据集中词数过多的评论大多是酒店类和书籍类评论,用户常常在评论中提及自己的出行经过或者摘抄一段书中的内容,这些情况可能会对情感倾向的判断造成干扰。同时,考虑到后续实验中需要构建文本超图,当超节点过少时,超图可能退化为普通图,无法检验该结构的优势。因此,在数据清洗时将两个数据集中句子长度(词数)小于3和大于100的评论舍弃。
经预处理后,OS10数据集中共计5.81万余条用户评论,正负评论分别为2.87万和2.93万余条,分布较为平均;SMP2020数据集中共计微博文本3.4万余条,类别分布如图6所示。
由图6中的统计数据可知,该数据集存在数据不平衡情况,在六个情感类别中,angry类数量最多,占比达30%,fear和surprise两类最少,不足10%。
基于上述情况,为了使各子集中的数据尽可能与原数据集的分布保持一致,以保证实验结果的准确性,本文采用分层重复随机子抽样验证的方法,按8∶1∶1的比例划分出训练集、验证集和测试集,以准确率(accuracy)、精确率(precision)、召回率(recall)以及F1值作为实验的评价标准,将实验重复进行五次后取平均值作为最终结果。
3.2 参数设置
在情感句动态向量获取模块,本文使用了哈工大讯飞联合实验室发布的基于全词掩码技术的中文预训练模型BERT-wwm-ext[25]。该模型在预训练masking阶段采取将一个完整的词全部覆盖的策略,与原始BERT模型以字为粒度随机掩盖相比,该策略使得模型能够更好地学习中文构词规则,对中文文本的上下文理解能力得到了提高。
在HGDAN部分,为每篇情感文本构造出情感超图,以词为粒度视作超节点,提取其上下文信息、语义依存信息和主题信息,构建出上下文顺序超边、语义依存超边和主题超边。对于超节点的初始嵌入,采用腾讯AILab开源的大规模word2vec中文词向量数据[26],该数据包含了超过800万的中文词汇,覆盖了更多的网络用语,对于本文所使用的两个内容均为网络文本的数据集而言,能够在一定程度上减轻未登录词问题。
由于BERT已经在大规模数据上进行了预训练步骤,其理解能力达到了一定的水平,在后续模型训练过程中进行微调即可;而HGDAN模块则是从零开始拟合数据,初始需要较高的学习率来提升收敛速度;所以,为了平衡两者的训练进度,本文设置了分层学习率。模型参数详细设置如表2所示。
在图神经网络中,将实验数据抽象成图是一切工作的基础,图的构建方式极大地影响着后续结果。滑动窗口的大小直接决定顺序超边的数量以及一条超边所能容纳的信息;主题挖掘数目直接决定主题超边的数量以及挖掘出的主题质量。因此,本文对超图模块中构建主题超边的主题数目以及构建顺序超边的滑动窗口的大小进行了探究。
3.2.1 主题挖掘数目
主题个数是主题挖掘算法中一个重要的超参数,会影响主题发現的质量,当主题数过少时,会增大主题内部的歧义,反之当主题数过多时,会出现主题间语义重叠的情况。因此,为确定抽取的主题数量,对数据集进行不同主题数量的实验。
为了客观评价主题挖掘效果,本文采用主题连贯性(topic coherence)对主题模型生成主题的质量进行评估,选择较为常用的标准化点互信息(normalized pointwise mutual information,NPMI)来度量。计算公式如式(14)(15)所示。
其中:K表示挖掘主题数目;T表示与主题k最相关的单词数;p(wi)表示单词wi出现的概率;p(wi,wj)表示词对wi和wj同时出现在一篇文档中的联合概率;本实验中T设置为10。C_NPMI的值越高,说明同一个主题内的词相关性越大,挖掘出的主题可解释性越强。
在实验中,ETM模型的初始词汇嵌入同样采用200维的腾讯词向量,epoch数默认为100,批处理大小设置为128,学习率为0.001。对于OS10数据集,设定主题数目K的取值为[10,20],SMP2020数据集的主题数目K的取值为[5,15],步长均为1进行主题挖掘,计算主题连贯性,确定最优主题数目,实验结果如图7所示。
从图7显示的信息可以看出,两个数据集的主题连贯性曲线呈现了相似的走向。开始随着挖掘主题个数的增多,评分总体呈上升趋势,在主题数过少的情况下,每个主题内部概率最大几个单词之间可能存在较大的歧义。当主题数为K=15和K=11时,分别在OS10和SMP2020数据集上的主题一致性评分达到峰值。随后,主题连贯性随着主题数目的增加而减小,这是由于当抽取的主题数过多时,部分主题之间具有较大的相似度,不易区分。所以,OS10和SMP2020两个数据集的最优主题数目分别设置为15和11。
3.2.2 滑动窗口尺寸
在上下文顺序超边的构建中,本文使用固定大小的滑动窗口来实现。一个窗口构建一条超边,连接所有在窗口内出现的词超点。因此,本文通过实验探究采用不同尺寸滑动窗口时的分类情况。为了避免其他因素的干扰,实验模型仅使用超图和对偶注意力模块,并且超图中仅包含上下文顺序超边。实验结果如图8所示。
从图8中可以观察到,当滑动窗口为3时,模型在两个测试集上的分类准确率达到最高,说明此时构造出的超图能够有效捕捉到文本的语序特征,同时也证明了利用多个词的共现关系构建超边是有意义的。当滑动窗口尺寸大于3时,模型在两个测试集上的分类准确率随着窗口的增大而呈现下降趋势。经分析,两个数据集中情感文本的平均长度(词数)均在30以下,属于短文本,当窗口尺寸过大时,构建出的超边数量减少,同时一条超边内连接了过多的超节点,文本中的上下文语序信息没能更大程度地表达出来。
基于上述结果,在后续实验构建上下文顺序超边时,将滑动窗口大小设置为3。
3.3 对比实验
为验证本文模型在中文网络文本情感分类任务中的性能,分别在两个数据集上对不同神经网络模型进行对比实验。基准模型的选取从四个角度考虑,分别是基于序列的神经网络、基于注意力机制的神经网络、基于序列和注意力结合的神经网络以及基于图结构的神经网络。
a)CNN[27]:卷积神经网络,利用卷积和池化操作获得情感文本表示。
b)BiLSTM[28]:双向长短期记忆网络,把两个方向的最后一个隐藏状态进行拼接作为整个文本的全局特征。
c)Transformer[6]:由编码器和解码器两个部分组成,实验中仅使用编码器模块提取文本特征。
d)BERT[7]:基于BERT预训练模型得到文本的句向量表示,再经过全连接层与softmax进行分类。
e)BERT_CNN:利用BERT模型为情感文本中的每个单元生成动态向量,输入卷积神经网络中进行情感分析。
f)BERT_BiLSTM:利用BERT模型为情感文本中的每个单元生成动态向量,输入双向长短期记忆网络中进行情感分析。
g)TextGCN[13]:图卷积神经网络,基于整个语料库的数据构建文档-单词异构图,转换为节点分类任务。文档-单词边权重为tf-idf值,单词-单词边权重为两者的点互信息值,初始节点特征采用one-hot编码。
h)BertGCN[14]:在TextGCN的基础上,由预训练BERT模型对图节点特征进行初始化,两者联合训练。
i)HyperGAT[18]:超图注意力网络,为每篇文本构建一张超图,利用注意力机制完成超边和超点的信息聚集,转换成图分类任务。在超图的构建中,以句子为单位构建顺序超边,使用LDA主题模型构建主题超边,初始节点特征采用one-hot编码。
j)IBHC[20]:分别使用谱域超图卷积网络和BERT提取文本特征,并通过注意力机制结合。超图中仅含顺序超边,节点特征由GloVe静态词向量进行初始化。
表3展示了B_HGDAN模型和以上基准模型在两个中文文本情感分析数据集上的实验结果。可以发现,本文提出的B_HGDAN模型在两个数据集上都取得了最佳的分类效果,且显著优于其他基准模型,体现了该模型在中文文本情感分类任务上的有效性。同时也可以注意到,由于OS10为二分类数据集,其任务难度比六分类的SMP2020低,所以所有基准模型都取得了比较好的效果,四个评价指标均在92%以上。图9更直观地展示了各模型的性能差异。
根据图9显示的数据,基于序列的两个模型中,BiLSTM都取得了比CNN更好的效果。CNN只能提取到局部关键特征,而BiLSTM可以捕捉到较长距离的依赖关系,同时又从正反两个方向处理输入序列,提供的信息更丰富。该结果也说明了在情感分析任务中,文本的语序信息对于情感倾向的判断十分重要。Transformer和BERT均在自注意力机制的基础上发展而来,后者由多层双向Transformer编码器构成,并拥有更多的自注意力头。同时,BERT在预训练阶段已学习到大量通用知识,具有非常强大的迁移能力。BERT_CNN和BERT_BiSLTM均是基于序列和注意力机制结合的模型。与单独使用CNN和BiLSTM相比,结合后的模型在两个数据集上的分类效果均有所提高,说明BERT能够为单一模型带来增益。然而与单独使用BERT相比,结合后的模型综合效果却更差,并且标准差也更高,说明分类性能更加不稳定。这可能是由于BERT已经能够提取到足够多的文本深层语义信息,而后接一个CNN或是BiLSTM模型无法容纳上游传递来的大量信息,造成了特征的弱化或丢失。
在基于图结构的四个模型中,TextGCN和BertGCN均根据单词共现信息构建数据集级别的普通图,HyperGAT和IBHC则基于单个文档挖掘多方面信息构建文档级超图。其中,TextGCN在两个数据集上的实验效果在所有基准模型中表现并不理想,这可能是因为在图的构建中只通过一个较大尺寸的滑动窗口统计词之间的共现情况,忽略了词序信息,而这类信息在情感分类任务中恰是极其重要的。BERT和GCN的结合在SMP2020数据集上表现出了极大的增益,甚至优于两个基于超图结构的基准模型,但对于OS10数据集的分类效果提高有限。从表3展示的数据可知,HyperGAT在两个数据集上的总体表现次于BERT、BiLSTM以及两者结合的模型。造成这种结果的原因可能是在构建超图中虽然考虑到语序信息的重要性,按照句子为单位构建语序超边,而在本文针对网络短文本进行情感分析的场景下,大部分的文本数据可能只由1~3句话构成,所以,基于此规则构建的语序超边没有真正反映句子内部的语序信息。同时也可以注意到,在基于图的基准模型中,IBHC的表现最优,HyperGAT次于IBHC和BertGCN,说明将BERT与图神经网络结合能够实现优势互补,增强模型的情感特征提取能力。
与以上基线模型相比,本文模型在两个数据集上都取得了最出色的效果。这是由于其结合了BERT,能够充分提取情感文本全局动态特征的优势,同时在HyperGAT的基礎上改进了超图的构建方法,使情感文本建模成超图后仍保留了丰富的上下文语序、主题和语义依存信息。同时本文对以上两个模块采用的是并行结构,能够更好地结合两者的优势,一定程度上避免了串行结构中可能存在的下游模型无法充分使用上游提取到的特征,从而丢失一部分信息的问题。另外也可以注意到,在两个数据集上,五个基于图结构的神经网络模型多次实验的标准差都更小,说明将文本建模成图结构能够刻画单词节点之间的高阶信息,使得分类性能更加稳定。
以上实验结果表明,本文提出的B_HGDAN模型在针对电商评论、微博等网络短文本的情感倾向分析任务中效果显著。
3.4 消融實验
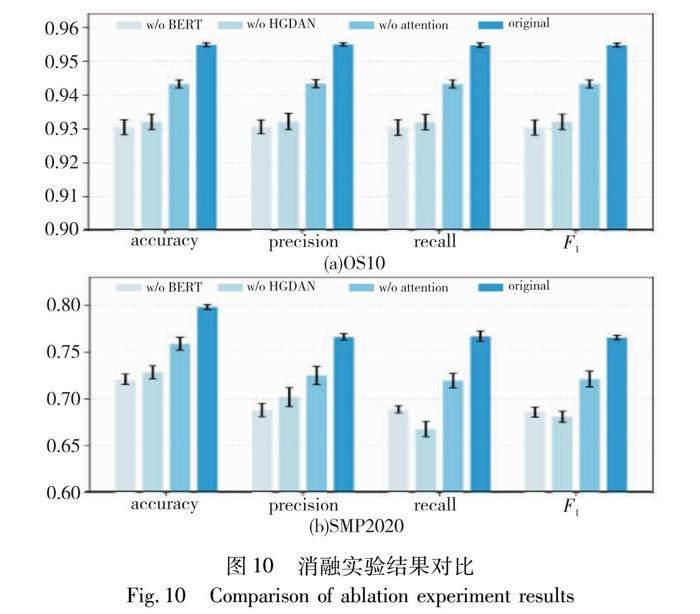
为进一步验证本文模型的有效性,探究模型中各个子模块对情感分析效果的增益,分别单独去除各个子模块进行消融实验。a)w/o BERT:去除原模型中的BERT模块,仅使用HGDAN;b) w/o HGDAN:去除原模型中的超图对偶注意力模块,仅使用BERT;c)w/o attention:去除原模型中的对偶注意力模块。消融实验结果如表4和图10所示。
BERT和HGDAN为本文模型中的两大模块,根据表4展示的数据,分别单独去除一个模块进行情感分析的效果相近,仅使用BERT在OS10数据集上的分类效果平均比仅使用HGDAN高出0.16%,而在SMP2020数据集上,后者的总体效果比前者高0.11%。与预先在大规模的语料上进行了通用知识学习的BERT相比,HGDAN模型在训练过程中仅仅使用了实验数据集中的信息就达到了与前者相当的效果,说明超图结构和对偶注意力机制具有非常强大的学习能力。
在OS10数据集上,本文模型与单独使用BERT和HGDAN相比,平均分类性能分别提高了2.27%和2.24%。在SMP2020数据集上,本文模型与单独使用BERT和HGDAN相比,总体分类性能分别提高了7.95%和7.85%。说明本文模型结合了两者优势,在情感分析任务上的鲁棒性和泛化能力得到了提升。
对比最后两组消融实验结果,在两个数据集上,本文的原始模型比去除注意力模块的变体平均性能分别提高1.16%和4.31%,可看出对偶注意力机制对模型整体情感分析效果具有明显的增益,证明了使用注意力机制来提取超图特征的有效性。
3.5 案例分析
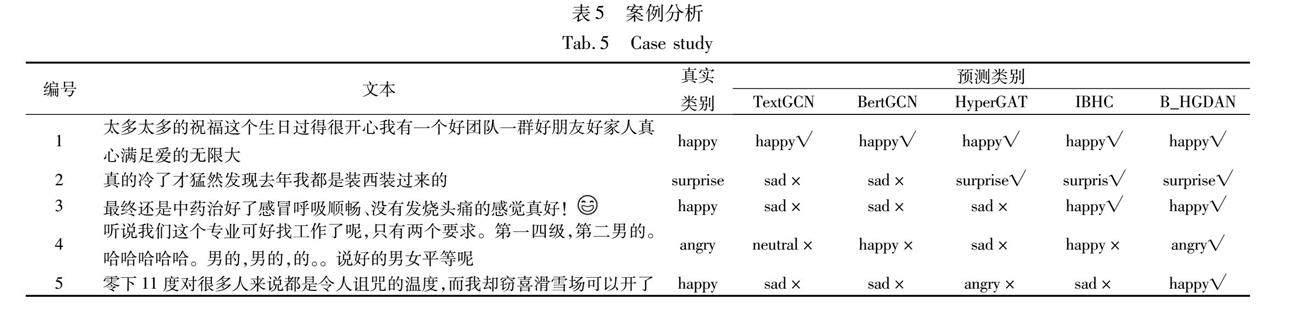
为了进一步验证本文模型在情感分析任务中的有效性,随机选取若干条微博情感文本作为样例,并使用3.3节中TextGCN、HyperGAT等四个基于图结构的神经网络模型对其进行预测,实验结果如表5所示,其中“√”和“×”分别表示判断正确和错误。
案例1的文本含有“祝福”“开心”“满足”等多个倾向明确的情感词,对于这一实例,所有模型都能够正确判断其情感。对于案例2,基于超图结构的模型均正确预测了其情感类别,而基于普通图的两个模型作出了误判,一方面说明了超图能够更加有效地提取情感文本特征,另一方面可能是由于TextGCN和BertGCN两个模型均是通过统计词语在整个数据集范围内的共现信息来构图,对单个文本的上下文关注有限。案例3的文本中出现了多个“感冒”“发烧”等与生病有关的词,大部分模型均判断为“sad”类别,只有IBHC和本文的B_HGDAN模型预测正确。对于案例4和5,除本文模型外,其余模型均作出了错误的判断。案例4中,前半部分更多体现出的是对事实的陈述,还有在通常情况下含积极倾向的语气词“哈哈”,而综合后半部分整体来看,这句话实际带有讽刺的意味。在案例5中,同样也是在句子的最后才体现出了发帖者真实的情感。从结果上看,本文提出的B_HGDAN模型能够抵抗这些因素的干扰,具有较高的准确性和较强的鲁棒性。
4 结束语
本文面向中文网络短文本,提出一种基于预训练模型BERT和超图对偶注意力机制的文本情感分析方法,旨在通过有效结合预训练模型、超图神经网络和注意力机制的优势,提升情感分类任务的性能。该模型首先利用BERT生成具有丰富语义信息的动态文本特征表示,更好地捕捉文本情感表达和上下文信息;其次从多角度挖掘文本信息,将其建模成超图,利用对偶注意力机制对超边和超节点进行信息融合,提高模型对文本结构的理解能力;最后将两个模块各自提取到的文本特征拼接后判断其情感倾向。多组实验结果表明,本文模型在中文网络短文本的情感分类任务中展现了明显的优势。
本文工作的不足之处在于,语义依存分析结果为有向图,并且有向边存在多种类型,在超边构建中本文视为无向图处理,仅在有依存关系的词之间添加边,没有更好地体现超图特质。在未来的工作中,笔者将继续探究如何将语句中的依赖关系更准确地建模成图;同时,对于网络文本存在大量噪声的问题,本文将探究图神经网络与对比学习的结合,进一步提升模型挖掘文本中隐含的复杂映射关系的能力,实现更好的情感分析性能。
参考文献:
[1]Yadav A, Vishwakarma D K. Sentiment analysis using deep learning architectures: a review[J]. Artificial Intelligence Review, 2020,53(6): 4335-4385.
[2]Minaee S, Kalchbrenner N, Cambria E, et al. Deep learning-based text classification: a comprehensive review[J]. ACM Computing Surveys, 2021,54(3): 1-40.
[3]Pan Yaxing, Liang Mingfeng. Chinese text sentiment analysis based on BI-GRU and self-attention[C]//Proc of the 4th IEEE Information Technology, Networking, Electronic and Automation Control Confe-rence. Piscataway, NJ: IEEE Press, 2020: 1983-1988.
[4]Basiri M E, Nemati S, Abdar M, et al. ABCDM: an attention-based bidirectional CNN-RNN deep model for sentiment analysis[J]. Future Generation Computer Systems, 2021,115: 279-294.
[5]周宁, 钟娜, 靳高雅, 等. 基于混合词嵌入的双通道注意力网络中文文本情感分析[J]. 数据分析与知识发现, 2023,7(3): 58-68. (Zhou Ning, Zhong Na, Jin Gaoya, et al. Chinese text sentiment analysis based on dual channel attention network with hybrid word embedding[J]. Data Analysis and Knowledge Discovery, 2023,7(3): 58-68.)
[6]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[EB/OL]. (2017)[2022-07-20]. https://arxiv.org/pdf/1706.03762.pdf.
[7]Devlin J, Chang M, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg,PA:Association for Computational Linguistics, 2019: 4171-4186.
[8]Liu Yinhan, Ott M, Goyal N, et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL]. (2019)[2023-04-16]. https://arxiv.org/pdf/1907.11692.pdf.
[9]Lan Zhendong, Chen Mingda, Goodman S, et al. ALBERT: a lite BERT for self-supervised learning of language representations[C]//Proc of the 8th International Conference on Learning Representations. 2023.
[10]胡任遠, 刘建华, 卜冠南, 等. 融合BERT的多层次语义协同模型情感分析研究[J]. 计算机工程与应用, 2021,57(13): 176-184. (Hu Renyuan, Liu Jianhua, Bu Guannan, et al. Research on sentiment analysis of multi-level semantic collaboration model fused with BERT[J]. Computer Engineering and Applications, 2021,57(13): 176-184.)
[11]Tseng H, Zheng Youzhan, Hsieh C. Sentiment analysis using BERT, LSTM, and cognitive dictionary[C]//Proc of IEEE ICCE-TW. Piscataway, NJ: IEEE Press, 2022: 163-164.
[12]王曙燕, 原柯. 基于RoBERTa-WWM的大学生论坛情感分析模型[J]. 计算机工程, 2022,48(8): 292-298,305. (Wang Shuyan, Yuan Ke. Sentiment analysis model of college student forum based on RoBERTa-WWM[J]. Computer Engineering, 2022,48(8): 292-298,305.)
[13]Yao Liang, Mao Chengsheng, Luo Yuan. Graph convolutional networks for text classification[C]//Proc of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press, 2019: 7370-7377.
[14]Lin Yuxiao, Meng Yuxian, Sun Xiaofei, et al. BertGCN: transductive text classification by combining GNN and BERT[C]//Proc of Findings of the Association for Computational Linguistics. Stroudsburg,PA:Association for Computational Linguistics, 2021:1456-1462.
[15]Jin Zhigang, Tao Manyue, Zhao Xiaofang, et al. Social media sentiment analysis based on dependency graph and co-occurrence graph[J]. Cognitive Computation, 2022,14(3): 1039-1054.
[16]Yang Minqiang, Liu Xinqi, Mao Chengsheng, et al. Graph convolutional networks with dependency parser towards multiview representation learning for sentiment analysis[C]//Proc of IEEE ICDMW. Piscataway, NJ: IEEE Press, 2022: 1-8.
[17]Chen Jie, Song Nan, Su Yansen, et al. Learning user sentiment orientation in social networks for sentiment analysis[J]. Information Sciences, 2022,616: 526-538.
[18]Ding Kaize, Wang Jianling, Li Jundong, et al. Be more with less: hypergraph attention networks for inductive text classification[C]//Proc of Conference on Empirical Methods in Natural Language Processing. 2020: 4927-4936.
[19]Kao Haochuan, Hung M, Lee L, et al. Multi-label classification of Chinese humor texts using hypergraph attention networks[C]//Proc of the 33rd Conference on Computational Linguistics and Speech Processing. 2021: 257-264.
[20]李全鑫, 龐俊, 朱峰冉. 结合BERT与超图卷积网络的文本分类模型[J]. 计算机工程与应用, 2023,59(17):107-115. (Li Quanxin, Pang Jun, Zhu Fengran. Text classification method based on the integration of BERT and hypergraph convolutional network[J]. Computer Engineering and Applications, 2023,59(17):107-115.)
[21]Sun Xiangguo, Yin Hongzhi, Liu Bo, et al. Heterogeneous hyper-graph embedding for graph classification[C]//Proc of the 14th ACM International Conference on Web Search and Data Mining. New York:ACM Press, 2021: 725-733.[22]Dieng A B, Ruiz F J R, Blei D M. Topic modeling in embedding spaces[J]. Trans of the Association for Computational Linguistics, 2020,8: 439-453.
[23]Mu Lingling, Li Yida, Zan Hongying. Sentiment classification with syntactic relationship and attention for teaching evaluation texts[C]//Proc of International Conference on Asian Language Processing. Piscataway, NJ: IEEE Press, 2020: 270-275.
[24]杜启明, 李男, 刘文甫, 等. 结合上下文和依存句法信息的中文短文本情感分析[J]. 计算机科学, 2023, 50(3): 307-314. (Du Qiming, Li Nan, Liu Wenfu, et al. Sentiment analysis of Chinese short text combining context and dependent syntactic information[J]. Computer Science, 2023,50(3): 307-314.)
[25]Cui Yiming, Che Wanxiang, Liu Ting, et al. Pre-training with whole word masking for Chinese BERT[J]. IEEE/ACM Trans on Audio, Speech, and Language Processing, 2021,29: 3504-3514.
[26]Song Yan, Shi Shuming, Li Jing, et al. Directional skip-gram: explicitly distinguishing left and right context for word embeddings[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2018: 175-180.
[27]Kim Y. Convolutional neural networks for sentence classification[C]//Proc of Conference on Empirical Methods in Natural Language Proces-sing. Stroudsburg,PA:Association for Computational Linguistics, 2014:1746-1751.
[28]Xiao Zheng, Liang Pijun. Chinese sentiment analysis using bidirectio-nal LSTM with word embedding[C]//Proc of International Conference on Cloud Computing and Security. Cham: Springer, 2016: 601-610.
