大规模差异化点云数据下的联邦语义分割算法
2024-05-24林佳斌张剑锋邵东恒郭杰龙杨静魏宪
林佳斌 张剑锋 邵东恒 郭杰龙 杨静 魏宪

摘 要:海量點云数据的存储对自动驾驶实时3D协同感知具有重要意义,然而出于数据安全保密性的要求,部分数据拥有者不愿共享其私人的点云数据,限制了模型训练准确性的提升。联邦学习是一种注重数据隐私安全的计算范式,提出了一种基于联邦学习的方法来解决车辆协同感知场景下的大规模点云语义分割问题。融合具有点间角度信息的位置编码方式并对邻近点进行几何衍射处理以增强模型的特征提取能力,最后根据本地模型的生成质量动态调整全局模型的聚合权重,提高数据局部几何结构的保持能力。在SemanticKITTI,SemanticPOSS和Toronto3D三个数据集上进行了实验,结果表明该算法显著优于单一训练数据和基于FedAvg的方法,在充分挖掘点云数据价值的同时兼顾各方数据的隐私敏感性。
关键词:联邦学习;点云语义分割;双层几何衍射;动态权重
中图分类号:TP391.41 文献标志码:A
文章编号:1001-3695(2024)03-010-0706-07
doi:10.19734/j.issn.1001-3695.2023.07.0320
Federated semantic segmentation algorithm under
large scale differential point cloud data
Lin Jiabin1,2,Zhang Jianfeng2,Shao Dongheng2,Guo Jielong2,Yang Jing3,Wei Xian2
(1.College of Mechanical & Electrical Engineering,Fujian Agriculture & Forestry University,Fuzhou 350100,China;2.Fujian Institute of Research on the Structure of Matter,Chinese Academy of Sciences,Fuzhou 350002,China;3.Longhe Intelligent Equipment Manufacturing Co.,Ltd.,Longyan Fujian 364101,China)
Abstract:The storage of massive point cloud data has great significance to the real-time 3D collaborative perception of autonomous driving.However,due to the requirements of data security and confidentiality,some data owners are unwilling to share their private point cloud data,which limits the improvement of model training accuracy.Federated learning is a computing paradigm that focuses on data privacy and security.This paper proposed a novel approach based on federated learning to address the challenge of large-scale point cloud semantic segmentation in collaborative vehicle perception scenarios.It integrated position encoding with inter-point angle information and geometric diffraction of neighboring points to enhance the feature extraction capability of the model.Finally,it dynamically adjusted the aggregation weights of the global model according to the generation quality of the local model to improve the ability to maintain the local geometric structure of the data.This paper applied the proposed method on three datasets,such as SemanticKITTI,SemanticPOSS and Toronto3D.The results show that the proposed approach significantly outperforms the single training data and the FedAvg-based method,and fully exploits the value of the point cloud data while taking into account the privacy sensitivity of each partys data.
Key words:federated learning;point cloud semantic segmentation;double-layer geometric diffraction;dynamic weighting
0 引言
随着激光雷达等高精度传感器的广泛普及和应用,促使许多对3D数据有着实际需求的领域,如自动驾驶、机器人、虚拟与增强现实等,得到快速发展[1]。与2D图像不同的是,3D数据可以更好地理解机器周边环境,更加适用于实际的三维空间场景。点云作为一种常见的三维模型数据,具有非常强的空间表达能力,可以很好地保留原始三维空间的几何结构,而且能够很好地刻画每个类别物体的表面特征以及其他可供深度模型训练的信息,比如坐标、颜色、反射强度等,因此,它是许多场景理解相关应用的首选表示,但是点云的空间分布不均及数据杂乱无序等特点给点云数据处理和应用带来了极大的挑战[2]。当前关于点云感知任务中分割问题的研究往往只专注于在一个完整的集中式数据集上进行模型性能研究,此类方法在真实世界3D应用场景下存在着扩展性差、鲁棒性低等问题。
例如,在自动驾驶领域的多个数据持有方中,由于存在部分群体不愿与他人共享其隐私数据,同时受限于单方数据采集的成本和训练算力要求等问题,形成“数据孤岛”,使得数据的潜在价值不能被充分利用。为此,本文将联邦学习计算范式迁移至此处理该问题,在保证用户数据隐私的前提下,合法合规地利用私域数据进行训练。联邦学习的初衷就是保证“数据不动模型动”,在很大程度上可以促进数据的所有方充分利用分散的数据训练出令各方都满意的机器学习模型[3]。由于分散式的用户数据不能够充分提取点的特征信息,为进一步优化特征编码,对输入点的特征提取采取几何衍射[4]等处理,并基于每轮学习到的特征质量确定最终模型聚合权重。相较于直接采用联邦平均算法[5]构建模型,本文方法能更显著地提升整体性能效果和稳健性。
本文的主要贡献包括:a)将联邦学习方法引入到车辆协同感知场景下的大规模点云语义分割任务中,凭借其安全可信的训练方式,每个数据持有方仅通过私有本地数据生成全局共享知识,从而获取更好的模型性能;b)针对更小范围内随机采样导致的点信息丢失问题,通过优化相对位置编码方式,引入双层几何衍射[4],将每个采样中心点的邻近点作正态分布映射,细化每个邻域内的特征分布,提升局部特征提取能力;c)对室外真实采样的点云分割数据集SemanticKITTI[6]、SemanticPOSS[7]和Toronto-3D[8]进行联邦切片处理,给每个参与方划分不同场景的数据以实现数据隔离,针对本地数据不平衡带来的性能下降问题,在经过相应优化方法后准确度得到有效提升。
1 相关工作
1.1 点云分割
点云语义分割是对海量点数据逐点进行语义分类的一种识别任务。相比于传统方法,深度学习方法能够更好地处理不规则的3D点云数据,通过端到端的方式训练直接从原始点云数据中学习特征表示和语义信息,避免了手工设计特征的复杂过程,克服了传统方法在特征提取和噪声干扰处理方面的局限性,提高了分割效果并减少了计算时间[9]。现阶段基于深度学习的点云分割相关研究大致可以归纳为以下几种:
a)基于投影的分割方法。例如:Lawin等人[10]使用的多视图表示办法,将点云投影到不同的二维平面上,并利用多流的全卷积网络(FCN)融合不同视角的投影分数来预测每个点的最终语义标签;Wu等人[11]提出了一种基于SqueezeNet[12]和条件随机场(CRF)的端到端网络,将3D点云映射到球面上的二维平面(通常是前视图),以保留更多的点云细节。但采用投影的方法会受到遮挡物的影响,因此依旧会造成分割精度的下降。
b)基于体素的方法实质上就是将点云结构化为密集网格的过程。Huang等人[13]利用3D卷积进行体素分割,为体素内所有点指定与体素相同的语义标签。此后,Tchapmi等人[14]创新性地提出了SEGCloud模型,可以实现端到端的细粒度和全局一致性的语义分割。尽管体素化方式可以尽可能地保留点云的域结构,但是不可避免地引入了离散化伪影和信息损失,因此,需要在保留细节和压缩运算成本之间进行权衡。
c)基于点的网络模型是较为直接和普遍的方式,可以将点云直接输入到网络中进行特征提取。然而由于点云的特性是无序、不规则以及非结构化的,所以直接进行卷积操作是不可取的。早期的开创性工作有PointNet[15],提出使用共享MLP层学习逐点特征,并使用对称池化函数学习全局特征;为了捕获来自局部的几何结构,PointNet++[16]通过分层的方式分组聚合邻近点的信息,从而学习更精细的局部特征。为了对不同点之间的相互作用进行建模,Zhao等人[17]提出了PointWeb,通过密集构建局部完全相连接的网络来探索局部区域中所有点对之间的关系,并采取自适应特征调整(AFA)模块实现信息交换和特征细化。除了PointNet系列,还有一些先进的基于点的网络模型采用了注意力机制。例如,Chen等人[18]提出了局部空间感知(LSA)层,根据点云的空间布局和局部结构学习空间感知权重。类似于条件随机场(CRF),Zhao等人[19]提出了基于注意力的分數细化(ASR)模块,通过结合相邻点的分数和学习到的注意力权重来改进初始分割结果。
此外,Engelmann等人[20] 也将递归神经网络(RNN)用于捕获点云的固有上下文特征,提出了一种多尺度块和网格块的转换方法,并通过合并单元(CU)或递归合并单元(RCU)逐层获得输出级上下文。也有工作试图探讨图结构下的点云分割模型,如Ma等人[21]提出的即插即用的点全局上下文推理(PointGCR)模块,使用无向图表示沿信道维度捕获全局上下文信息,可以轻松集成到现有的分割网络中以提高性能。本文采用
一种高效、轻量级的深度网络RandLA-Net[22,23],作为室外大规模点云分割基准,进一步探索了在联邦场景下的模型性能,通过多种优化手段提升在差异化数据分布的边缘客户端下的系统整体鲁棒性。
1.2 联邦学习
人工智能技术的快速发展依赖于深度学习模型的精心设计,而深度学习的大获成功又离不开大量可用、易用数据的互连互通,在全球范围内形成的隐私保护体系大环境下,防范数据泄露和维护数据安全成为了广泛的共识。无论是跨机构还是跨设备的用户群体都倾向于打破数据壁垒,通过多方协作完成数据的合法调控,减小隐私风险和额外成本。联邦学习作为人工智能领域新兴的分布式机器学习范式,天然地适用于缓解“数据孤岛”和“数据隐私”问题,在数据信息高度敏感的金融、医疗健康和边缘物联网等领域都有着广泛的应用。联邦学习通常可依照数据样本和数据特征的重叠程度划分为横向联邦学习、纵向联邦学习和联邦迁移学习[24]。从狭义上来阐述联邦学习:假设进行联邦训练后的模型MF的性能为VF,将其与传统集中式机器学习的模型MS的性能VS进行比较,那么满足以下条件,即存在一个非负实数δ,使得两者的性能损失差距为|VS-VF|<δ ,通常情况下的期望是将数据进行表层安全的联邦训练后所取得的最终效果近似于将数据集中到一起后训练的模型性能。
2 联邦点云语义分割模型
在面对大规模点云数据时,进行精准高效的语义分割是一项极具挑战性的环境感知任务。RandLA-Net[23]是一种轻量化的语义分割网络,其整体架构也是采取语义分割网络中常见的编码器和解码器结构,不同于采集少量的室内点云数据(如1 024个点)进行简单的分类分割任务。本文对输入高达50K的点云数据进行处理,先逐层下采样提取,通过四个编码层将数量压缩至1/256,每个编码层将点云数量减少至原始的1/4,同时通过扩充特征维度保留更多的信息;解码部分选择高效的最近邻差值法放大点的尺度,逐层上采样至原始样本点数,然后通过跳跃连接将网络编码器阶段提取到的底层特征与解码时的高层特征进行融合;最后利用三个全连接层将维度映射到输出类别数。通过大量的前期调研工作后发现,随机采样方法对于大场景下点云分割具备更高的计算效率,相较于最远点采样[16],基于生成器的采样[25]、强化学习下的策略梯度采样[26]等方法,采样速度提升百倍且时间复杂度更低,计算资源和内存开销更小,整体效率更高,更加适用于大场景下的点云分割任务。针对随机采样后可能造成点丢失的情况,进一步提出局部特征聚合模块,通过扩大每个采样点的感受野,更大范围地聚拢局部特征。本文提出局部增强的编码方式并引入双层几何衍射模块,进一步保留了特征细节。
通过联邦学习进行点云语义分割,如图1所示,其中LFEA为局部特征增强聚合模块,DWN为融合模型时第N个本地模型的权值。首先在基准数据上为每个待选择的客户端分配一定数量的点云数据(由车载激光雷达等高精度传感器事先采集而来),每个数据间不存在重叠可共享的部分,且不同端分得的数据在数量上存在显著差异。采取具有中央服务器的横向联邦客户-服务器架构,中心方负责初始化模型参数并下发给数据持有者,每个本地客户仅利用自己私人的点云数据(随机采样数据)进行训练,训练方式等同于常规机器学习模型的训练流程进行边缘端的梯度下降,并逐步更新局部模型参数(期间数据仅作用在每个本地端),达到指定局部迭代次数后上传参数,再由中央服务器采取参数聚合算法融合多个模型,重复联邦训练后达到最大迭代次数,获取最优模型。
2.1 双层几何衍射模块
在局部编码器进行点云的特征提取关乎最终分割性能的优劣,而局部特征聚合模块是对点特征提取的关键步骤。如图2所示,主要体现在对输入点特征不断进行维度扩充,从而学习到更加丰富的上下文信息。
对于每个输入采样点,使用简单的K近邻算法找到关联的邻居点(设定数量为16),进而对原始采样点与若干个近邻点进行相对位置编码,得到rqi。
其中:函数G(·)由一个共享的MLP和softmax层组成;W为可学习的权重。得到的Sqi可视为选择重要特征的软掩模,再与原先的输出特征f^qi进行加权求和,得到聚合特征输出。这样做可以增大每个输入点的感受野,通过汇聚相邻点的特征信息更大程度地保留原始输入点云的局部几何结构。
2.2 局部和全局优化方法
本文针对经典的联邦平均算法进行了两处轻量级的改进。首先重新调整了损失函数,将用于类别不平衡的损失函数FocalLoss(FL)[27],替代传统联邦局部监督学习的交叉熵损失。
FL(pt)=-αt(1-pt)γlog(pt)(10)
其中:αt用于调节正负样本损失之间的比例;pt为预测概率值;γ通过减少易分类权重参数,从而加大对难区分样本的专注度。由此在进行局部目标优化时能朝着所希望的方向进行,可提升整体联邦语义分割任务的准确度。
同时,本文对全局聚合函数重新进行设计,采用的优化方法为DW,如式(11)所示。
其中:k为客户端数量;C为总类别数;pij表示根据每个类别出现频率所赋予的权重。相当于通过混淆矩阵计算出每个类别的真实数目为TP+FN,总数为TP+FP+TN+FN,分母计算由参与方总数确定的总的模型参数权重。旨在根据既定的权重评价指标进行多个模型的参数融合,在每轮次与中心方通信时能动态地调整每个参与方模型参数所占据的比重,相比于直接根据数量来定义权值大小或者直接平均参数,更能反映出单個参与方每轮学习到的局部模型质量。
3 实验结果与分析
3.1 实验配置
本文实验环境采用的深度学习框架为PyTorch 1.8.1,编程语言为Python,在显卡型号为NVIDIA GeForce RTX 3090和版本号为11.1的CUDA上开展实验。进行联邦学习训练阶段的局部epoch设置为5,全局epoch为20/12;在SemanticKITTI和SemanticPOSS上训练的batch size设置为6,测试为20;在Toronto-3D上训练的batch size设置为4,测试时为8。初始学习率为1E-2,采用Adam优化器,每个epoch学习率衰减5%。
3.2 实验数据集
本次实验采用SemanticKITTI、SemanticPOSS和Toronto-3D作为室外点云语义分割评估基准数据集。其中:SemanticKITTI是一个通用的具有丰富逐点点云注释、涵盖驾驶车辆扫描的大型全视野语义分割户外场景数据集,数据集由22个序列组成,前11个序列的23 201个点云用于训练和验证,其中08序列通常用于由真实标签生成的对比测试;SemanticPOSS是由北京大学采集的室外大规模稀疏点云实例,包括人和骑手等常规事物,共分为6个LiDAR数据序列,本文使用序列03作为测试,其余的用于联邦训练;Toronto-3D是由加拿大多伦多MLS系统获取的覆盖了大约1 km由7 830万个点组成的城市道路语义分割的大规模户外点云数据集,该数据集采集场景共4个,其中采用L001、L003、L004作为训练集,L002作为测试集,共拥有8个有效语义标签类。
对上述三个数据集采取联邦多场景下的多点实验数据切分以实现差异化的标签数量分布。如在Toronto-3D上进行联邦数据预处理,为保证数据隔离和划分的有效性,在数量为三个的参与方时由不同采样场景的训练集重新分配本地数据空间。
3.3 实验评估指标
本文实验采用分割中常见的几种指标来评估模型性能,包括整体准确率OA和平均交并比mIoU,詳细定义如下:
其中:pij表示每个类别点的真实标签为i,预测输出值为j;C表示总的语义类别数。
3.4 实验结果与分析
为实现公平的实验对比,所有结果均是在原始点云数据集上评估所得,在进行联邦训练后的三个数据集上的实验可视化结果如图3~5所示。表1~3分别是不同参与方数量在SemanticKITTI、SemanticPOSS和Toronto3D上的实验结果。以基于RandLA-Net为backbone进行联邦基准实验,在数量CN设置为2和3时分别达到了52.5%和52.3%的mIoU,相较于集中式训练平均下降了1.3个百分点,但相对于单一数据进行训练得到42.9%的准确率,性能提升出色。表中FedNRN表示在初始化本地模型中加入双层局部特征增强聚合模块后的实验结果;FedNRNP为融合轻量级的全局和局部优化方法,即采取动态权重聚合和Focal loss为目标函数进行优化。通过FedNRNP将SemanticKITTI的整体分割准确率最高提升了5.6个百分点。在联邦后的SemanticPOSS数据集上进行实验,相较于直接采取RandLA-Net进行实验得到的52.1%和47.0%的语义分割mIoU,优化后的方法FedNRNP实现了57.5%和54.6%的语义分割mIoU,分别提升了5.4%和7.6%。另外,相较于集中式训练所需要的100个epoch才达到的52.8%的mIoU,在进行联邦训练后仅需局部迭代5次,全局迭代20次就能达到52.1%的性能。
在数据分布差异越明显的联邦客户端上,所取得的最终分割结果效果越差。如在SemanticPOSS和Toronto3D三个参与方的基础上,FedNRNP优化方法相较于FedAvg取得的47.0%和72.4%的结果,最后提高至56.1%和78.9%,本文方法针对具有不平衡的本地数据分布特性下的性能损失更加鲁棒,且不同数据集在每个类别的分割交并比均有不同程度的提升。例如在SemanticKITTI上的car、truck、person、trunk、traffic-sign类别,SemanticPOSS上的person,rider,trunk,building,fence类别,Toronto3D上的Road、Rd mrk、Car类别中展现出了同等条件下更有竞争力的分割结果。从图3中可以看出,直接进行多方联邦建模的分割结果,FedRN要明显优于单一数据训练结果SinSK,且经过优化后的方法FedNRNP取得了最接近真实标签所预期的分割结果,进一步验证了优化模型和聚合函数对于捕获点之间信息的有效性。
本文针对所提出的联邦共享模型进行了模块消融实验,结果如表4所示。FedRN为采取RandLA-Net作为骨干网络取得的分割结果;PE为增强的位置编码方式;FGA和BGA分别表示在第一和第二个局部特征聚合模块后嵌入新颖的几何衍射处理模块;DGA为添加的双层特征增强模块。实验结果表明,在融合了PE和DGA方法后的联邦模型取得了更好的效果,达到了56.6%的mIoU,提升了4.5个百分点。
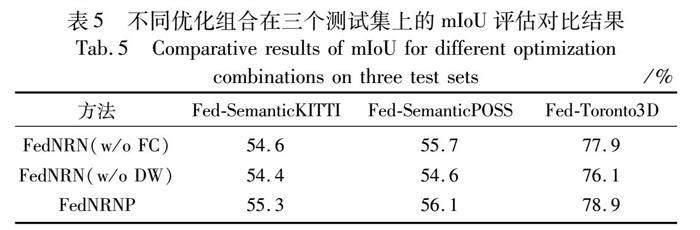
另外,本文还针对提出的全局和局部优化方法进行了消融实验,结果如表5所示。对于进行联邦后的三个数据集上训练得到的模型,在不加入FC(采取FL进行优化)和DW两种方法得到的mIoU均为最差的效果,经融合后得到的FedNRNP方法在不同用户数量上提升显著,均实现了同等条件下的最优,验证了本文方法在应对大场景下异端用户差异化数据分布的鲁棒性。
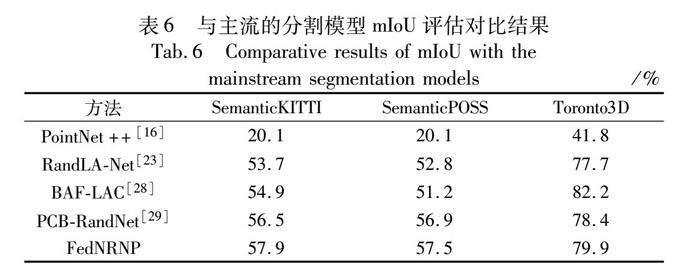
表6将本文方法与主流的大场景点云分割模型进行对比,实验表明,相较于直接将数据暴露给原始服务器的其余四种方法,本文方法在分割性能和数据隐私上仍能取得较好的平衡。
4 结束语
鉴于现实大规模点云场景下的数据隐私敏感特性,本文设计了基于联邦学习的点云语义分割算法,通过增强的局部特征聚合模块提高每个邻域内的几何信息捕捉和学习能力,进一步优化损失和全局聚合函数以提升鲁棒性。由于点云本身具有很强的稀疏性,在经过联邦划分后的数据集无法对多个分散的数据特征进行完整的特征提取,所以进一步优化联邦模型局部特征编码提取器,学习到更多细节和更关键的点间几何信息将是未来优化的重点方向之一。
参考文献:
[1]魏天琪,郑雄胜.基于深度学习的三维点云分类方法研究[J].计算机应用研究,2022,39(5):1289-1296.(Wei Tianqi,Zheng Xiongsheng.Research of deep learning-based classification methods for 3D point cloud[J].Application Research of Computers,2022,39(5):1289-1296.)
[2]张佳颖,赵晓丽,陈正,等.基于深度学习的点云语义分割综述[J].激光与光电子学进展,2020,57(4):20-38.(Zhang Jiaying,Zhao Xiaoli,Chen Zheng,et al.Review of point cloud semantic segmentation based on deep learning[J].Laser & Optoelectronics Progress,2020,57(4):20-38.)
[3]周传鑫,孙奕,汪德刚,等.联邦学习研究综述[J].网络与信息安全学报,2021,7(5):77-92.(Zhou Chuanxin,Sun Yi,Wang Degang,et al.Survey of federated learning research[J].Chinese Journal of Network and Information Security,2021,7(5):77-92.)
[4]Ma Xu,Qin Can,You Haoxuan,et al.Rethinking network design and local geometry in point cloud:a simple residual MLP framework[EB/OL].(2022-11-29)[2023-07-20].https://arxiv.org/pdf/2202.07123.pdf.
[5]McMahan B,Moore E,Ramage D,et al.Communication-efficient learning of deep networks from decentralized data[EB/OL].(2023-01-26).https://arxiv.org/pdf/1602.05629.pdf.
[6]Behley J,Garbade M,Milioto A,et al.SemanticKITTI:a dataset for semantic scene understanding of LiDAR sequences[C]//Proc of IEEE/CVF International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2019:9296-9306.
[7]Pan Yancheng,Gao Biao,Mei Jilin,et al.SemanticPOSS:a point cloud dataset with large quantity of dynamic instances[C]//Proc of IEEE Intelligent Vehicles Symposium.Piscataway,NJ:IEEE Press,2020:687-693.
[8]Tan Weikai,Qin Nannan,Ma Lingfei,et al.Toronto-3D:a large-scale mobile LiDAR dataset for semantic segmentation of urban roadways[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2020:797-806.
[9]朱威,繩荣金,汤如,等.基于动态图卷积和空间金字塔池化的点云深度学习网络[J].计算机科学,2020,47(7):192-198.(Zhu Wei,Sheng Rongjin,Tang Ru,et al.Point cloud deep learning network based on dynamic graph convolution and spatial pyramid pooling[J].Computer Science,2020,47(7):192-198.)
[10]Lawin F J,Danelljan M,Tosteberg P,et al.Deep projective 3D semantic segmentation[C]//Proc of the 17th International Conference on Computer Analysis of Images and Patterns.Cham:Springer,2017:95-107.
[11]Wu Bichen,Wan A,Yue Xiangyu,et al.SqueezeSeg:convolutional neural nets with recurrent CRF for real-time road-object segmentation from 3D LiDAR point cloud[C]//Proc of IEEE International Confe-rence on Robotics and Automation.Piscataway,NJ:IEEE Press,2018:1887-1893.
[12]Iandola F N,Han Song,Moskewicz M W,et al.SqueezeNet:AlexNet-level accuracy with 50x fewer parameters and<0.5 MB model size[C]//Proc of the 5th International Conference on Learning Representations.2017.
[13]Huang Jing,You Suya.Point cloud labeling using 3D convolutional neural network[C]//Proc of the 23rd International Conference on Pattern Recognition.Piscataway,NJ:IEEE Press,2016:2670-2675.
[14]Tchapmi L,Choy C,Armeni I,et al.SEGCloud:semantic segmentation of 3D point clouds[C]//Proc of International Conference on 3D Vision.Piscataway,NJ:IEEE Press,2017:537-547.
[15]Qi C R,Su Hao,Mo K, et al.PointNet:deep learning on point sets for 3D classification and segmentation[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Washington DC:IEEE Computer Society,2017:77-85.
[16]Qi C R,Yi Li,Su Hao,et al.PointNet++:deep hierarchical feature learning on point sets in a metric space[C]//Proc of the 31st International Conference on Neural Information Processing Systems.2017:5105-5114.
[17]Zhao Hengshuang,Jiang Li,Fu C W,et al.PointWeb:enhancing local neighborhood features for point cloud processing[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Pisca-taway,NJ:IEEE Press,2019:5560-5568.
[18]Chen Linzhuo,Li Xuanyi,Fan Dengping,et al.LSANet:feature lear-ning on point sets by local spatial aware layer[EB/OL].(2019-06-20)[2023-07-20].https://arxiv.org/pdf/1905.05442.pdf.
[19]Zhao Chenxi,Zhou Weihao,Lu Li,et al.Pooling scores of neighboring points for improved 3D point cloud segmentation[C]//Proc of IEEE International Conference on Image Processing.Piscataway,NJ:IEEE Press,2019:1475-1479.
[20]Engelmann F,Kontogianni T,Hermans A,et al.Exploring spatial context for 3D semantic segmentation of point clouds[C]//Proc of IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2017:716-724.
[21]Ma Yanni,Guo Yulan,Liu Hao,et al.Global context reasoning for semantic segmentation of 3D point clouds[C]//Proc of IEEE Winter Conference on Applications of Computer Vision.Piscataway,NJ:IEEE Press,2020:2920-2929.
[22]Hu Qingyong,Yang Bo,Xie Linhai,et al.RandLA-Net:efficient semantic segmentation of large-scale point clouds[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Pisca-taway,NJ:IEEE Press,2020:11105-11114.
[23]Hu Qingyong,Yang Bo,Xie Linhai,et al.Learning semantic segmentation of large-scale point clouds with random sampling[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2021,44(11):8338-8354.
[24]Yang Aimin,Ma Zezhong,Zhang Chunying,et al.Review on application progress of federated learning model and security hazard protection[J].Digital Communications and Networks,2023,9(1):146-158.
[25]Dovrat O,Lang I,Avidan S.Learning to sample[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Pisca-taway,NJ:IEEE Press,2019:2760-2769.
[26]Xu K,Ba J,Kiros R,et al.Show,attend and tell:neural image caption generation with visual attention[C]//Proc of the 32nd International Conference on Machine Learning.[S.l.]:JMLR.org,2015:2048-2057.
[27]Lin T Y,Goyal P,Girshick R,et al.Focal loss for dense object detection[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2020,42(2):318-327.
[28]Shuai Hui,Xu Xiang,Liu Qingshan.Backward attentive fusing network with local aggregation classifier for 3D point cloud semantic segmentation[J].IEEE Trans on Image Processing,2021,30:4973-4984.
[29]Cheng Huixian,Han Xianfeng,Jiang Hang,et al.PCB-RandNet:rethinking random sampling for lidar semantic segmentation in autonomous driving scene[EB/OL].(2022-09-28)[2023-07-20].https://arxiv.org/pdf/2209.13797.pdf.
