基于空洞单流ViT网络的灵活模态人脸呈现攻击检测方法
2024-05-24肖立轩封筠高宇豪贺晶晶
肖立轩 封筠 高宇豪 贺晶晶


摘 要:
灵活模态人脸呈现攻击检测突破传统多模态方法对于模型训练与部署的模态一致性限制,可将统一模型按需灵活部署到多样模态的现实场景,但仍存在模型性能有待提升、计算资源需求高的问题。为此,提出一种以视觉 Transformer(ViT)结构为基础的单流灵活模态人脸呈现攻击检测网络。提出空洞块嵌入模块以减少运算冗余,降低输入向量维度;为区分不同模态特征,设计模态编码标记;采用非补齐策略处理模态缺失问题。在公开多模态数据集上的实验结果表明,该方法在域内和跨域评估中分别获得2.69%和33.81%的最佳平均ACER值,相较于现有的三种方法,具有更优的域内和域外泛化性能,在不同子协议上的性能表现较为均衡,且其模型计算量与参数量均远低于多流方法,更加适合模态缺失场景下的灵活、高效部署。
关键词:人脸呈现攻击检测;灵活模态;多模态;视觉Transformer
中图分类号:TP391.41 文献标志码:A 文章编号:1001-3695(2024)03-041-0916-07doi: 10.19734/j.issn.1001-3695.2023.07.0319
Flexible modal face presentation attack detection based onatrous single stream vision Transformer network
Xiao Lixuan, Feng Jun, Gao Yuhao, He Jingjing
(School of Information Science & Technology, Shijiazhuang Tiedao University, Shijiazhuang 050043, China)
Abstract:
Flexible modal face presentation attack detection can break through the limitations of traditional multi-modal methods on modal consistency in model training and deployment, and it can deploy the unified model flexibly to real scenarios of multiple modals on demand. However, there are still issues with improved model performance and high demand for computing resources. Therefore, this paper proposed a single stream flexible modal face presentation attack detection network based on vision Transformer. Furthermore, this paper proposed the atrous patch embedding module to address the operational redundancy problem and reduce the input vector dimension, designed the modal encoding token to distinguish different modal features, and adopted a non-padding strategy to solve the modal absence problem essentially. The experimental results on publicly available multi-modal datasets show that this method can obtain the best ACER averages of 2.69% and 33.81% in the intra-domain and cross-domain evaluations, respectively, and has excellent in-domain and out-of-domain generalization performance, and ba-lances performance across different sub-protocols compared to the existing three methods. It significantly reduces the quantities of calculations and parameters compared with multi-stream methods, and is more suitable for flexible and efficient deployment in modal absence scenarios.
Key words:face presentation attack detection; flexible modal; multi-modal; vision Transformer
0 引言
近年來,人脸识别系统因其强特异性、易采集、高效低成本等特点被广泛应用于智能安防、公安刑侦、电子商务及金融服务等领域。相较于对抗攻击和合成攻击,人脸识别系统更容易受到呈现攻击的威胁,常见的人脸呈现攻击方式主要有照片、视频回放和人脸面具。人脸呈现攻击检测(face presentation attack detection,fPAD)技术[1]对于保障人脸识别系统稳健运行至关重要,是构建安全可信的人脸身份认证智能化产品的坚实支撑。
目前,fPAD技术的研究重点是从如何提高算法泛化性、鲁棒性和精准度等方面着手,尤其随着深度学习技术在计算机视觉领域的快速发展,深度神经网络模型被应用于fPAD任务。基于元学习的方法[2]和基于对抗迁移学习[3,4]的方法旨在提高算法对未知目标域的泛化性,基于零/小样本的方法[5,6]和基于异常检测的方法[7]旨在提高算法面对未知攻击方式时的鲁棒性。基于辅助监督信号的方法[8]、基于特征融合的方法[9,10]和基于多模态的方法[11]则是以提高算法精准度为目标。多模态方法利用不同模态数据(如可见光、深度图和红外图像)训练模型,融合各模态特征,提取语义更完备的活体强相关特征,以实现真实人脸与假体攻击的精准判别。通常多模态任务需要根据不同部署场景分别设计网络结构并训练模型,这导致所得到的多模态模型效率低,并且受部署场景限制高、灵活性差。为解决该问题,衍生出灵活模态fPAD方法。灵活模态任务是指使用多个模态数据训练出一个统一的模型,可以根据现实需要将模型灵活地部署到模态子集场景上。如图1所示,传统的单模态与多模态任务须在训练数据与测试数据满足独立同分布的条件下,根据现实部署场景所具备的采集设备,设计网络结构并利用相应模态的训练数据获得模型;而灵活模态方法仅需训练得到统一模型,故可以突破部署场景限制,大大提高模型的灵活性,具有重要的实践意义。由于不同部署场景的图像采集设备不尽相同,所以导致统一模型输入存在模态缺失问题。同时,现有灵活模态网络通常采用多流结构,即为每个模态数据分配单独分支以提取特征,从而造成模型复杂冗余、计算资源消耗过高的问题。
为此,本文提出一种单流灵活模态网络(single stream flexi-ble modal network,S2FMN),以视觉 Transformer(vision Transformer,ViT)结构为基础,设计模态编码信息对不同模态数据进行标记,为降低模型输入向量维度,提出空洞块嵌入模块(atrous patch embedding module, APEM)处理输入模态图像,同时采用非补齐策略解决缺失模态问题,可减少模型计算量,提升模型效率。在灵活模态测评协议上,实验对比多流网络与单流网络性能,以验证所提S2FMN方法解决灵活模态任务的有效性与运算高效性。同时,S2FMN方法训练得到的模型解决了多模态与单模态模型无法部署到模态设备缺失场景上的问题,可实现灵活应用。
1 相关工作
1.1 多模态人脸呈现攻击检测
多模态方法可以突破数据源层面的限制,在原有可见光数据上增加深度、红外及近红外数据,通过融合多个模态的特征,进而弥补单模态方法对特定攻击的局限性,可有效应对复杂多变的呈现攻击,提高活体检测的准确率。Zhang等人[12]构建了大规模多模态活体检测CASIA-SURF数据集,并提供了一种多模态数据融合的基准方法。Liu等人[13]针对种族偏见问题,发布了跨种族多模态人脸反欺诈CeFA数据集。George等人[14]提出了包含多通道图片的人脸呈现攻击WMCA数据集,并通过实验验证了仅使用可见光信息进行活体检测,远远逊色于使用多模态数据的结果。随着大型多模态数据集的发布,多模态方法逐渐成为 fPAD领域的研究热点。
Parkin等人[15]提出一种三流融合网络,利用残差模块实现多尺度特征融合。Yu等人[16]将中心差分卷积网络[17]扩展到多模态版本,旨在捕获可见光、深度和红外三种模态间的内在联系。Wang等人[18]提出一个跨模态交互模块,在特征提取阶段实现模态交互。利用关系嵌入模块,通过将全局特征嵌入到细粒度的局部信息,以增强特征描述符的丰富度。George等人[19]提出一种基于可见光与深度信息的跨模态focal损失函数,利用单个信道的置信度函数来调制每个信道的损失贡献。Li等人[20]利用自监督学习网络生成的辅助信息,减少可见光和红外图像间的特征空间距离。朱大力等人[21]将图像的局部区域块作为网络输入,提取可见光、深度和红外三个模态的高层语义特征,并在训练过程中加入多模态特征随机擦除操作,以防止过拟合,提升模型鲁棒性。虽然多模态数据在面对复杂的攻击方式时展现出了不错的性能,但是在推理部署场景缺少某个或某些模态输入数据时,则要被迫放弃已有的多模态模型,需要根据真实场景可获得的模态数据重新构建网络及训练模型,致使多模态 fPAD模型灵活性差、冗余低效。
1.2 灵活模态人脸呈现攻击检测
灵活模态任务旨在解决多模态fPAD训练模型冗余、部署场景受限制的问题,利用多模态数据训练出一个能灵活部署在多样模态场景中的统一模型,目前研究尚处于起步阶段。Yu等人[22]首次提出灵活模态测评协议,并在该协议上采用多流ViT模型,结合不同的特征融合方法开展实验研究。Liu等人[23]提出一种新的模态未知视觉 Transformer(modality-agnostic vision Transformer,MA-ViT)框架,在多模态训练数据的帮助下,消除模态相关信息,补充活体相关特征,改善单模态fPAD方法的性能。值得注意的是,Liu等人[23]所采用的灵活模态测评协议是在可见光、深度图和红外图三个模态进行训练,测试时仅使用其中一个模态数据,与Yu等人[22]采用的协议并不相同。本文研究是按照文献[22]提出的灵活模态测评协议开展实验的,与其工作不同之处在于,文中方法以单流ViT为基础,采用前期融合方式,利用自注意力机制实现多模态特征交互融合。此外,将使用类标记(class token)从模态信息中学习与活体强相关的信息用于分类,并针对缺失模态问题设计非补齐策略。
2 本文方法
2.1 S2FMN网络整体结构
为解决多模态模型灵活性差和多流模型计算资源需求高、模型冗余的问题。本文提出单流灵活模态S2FMN网络模型,如图2所示。针对模态缺失测试场景提出零补齐和非补齐策略,设计模态编码信息用于标记各个模态数据,便于区分模型,保证模型在多种测试场景上平稳运行,提高模型的灵活性。不同于多流网络模型,S2FMN不再为每个模态图像分配单独的分支,而是将多模态图像作为统一输入,经由同一特征提取模块(feature extraction module,FEM)提取融合特征,其核心在于利用自注意力机制捕捉模態间的相关性,更好地提取融合特征,避免模型冗余。所提出的APEM模块采用空洞下采样方法降低输入向量维度,解决模型占用计算资源过高的问题。
S2FMN整体框架主要由图像处理模块(image processing module,IPM)、特征提取模块和分类头(classification head,CH)三部分组成。图2中,rgb为可见光图像,depth为深度图像,ir为红外图像。Xipat表示模态i的图像,i∈{rgb,depth,ir}。Xpos表示位置编码信息,Xmod表示模态编码信息,Xcls表示class token。S2FMN网络借鉴ViT 结构,与ViT[24]网络区别在于,S2FMN网络提出的APEM模块代替原来的图像块嵌入(patch embedding,PE)模块,并引入模态编码来区分多模态特征。利用FEM提取多模态融合特征。经CH将融合特征映射为概率值,对呈现攻击与活体样本进行判别。
3 实验及结果分析
3.1 实验设置
在PyTorch深度学习框架上进行实验,主要硬件配置为Intel Xeon Gold 6133 CPU 和NVIDIA Tesla V100。
3.1.1 数据集
文中在SURF、CeFA和WMCA这三个公开多模态数据集上进行实验。
SURF[12]:包含1 000名受试者的21 000个视频。数据集包含可见光图像、深度图像和红外图像三种模态数据,每名受试者有1个真实人脸视频和6个假脸视频。使用Intel RealSense SR300相机同时捕获可见光、深度和红外数据。
CeFA[13]:包含可见光图像、深度图像以及红外图像。数据集采自美洲、东亚、中亚的1 500名受试者的2D攻击样本。另外包含采集自107名受试者的3D攻击样本共5 538个,其中99名受试者在6种光照条件下的面具攻击样本5 364个,8名受试者在4种光照条件下的胡子或者眼镜攻击样本192个。针对3D攻击的样本全部以视频形式存储。
WMCA[14]:包含72名受试者的1 679个视频。数据集包括4种模态数据,即可见光 、深度图、红外图和热成像,包含多种不同类型的攻击(打印、屏显、眼镜、假头、硬面具、软硅胶面具和纸面具)。
3.1.2 灵活模态测评协议
灵活模态测评协议[22]在表1中列出,包含4个子协议,涵盖数据集内(域内)和跨数据集(跨域)评估,其中R、D和I分别表示可见光、深度和红外图像。各子协议均在SURF&CeFA数据集上使用R&D&I三个模态数据进行模型训练。
域内评估是在SURF&CeFA上开展实验,以测试模型在同一领域内的性能,而跨域评估是在WMCA数据集上进行,以测试模型在不同领域内的泛化能力。
3.1.3 评价指标
评价指标选用平均分类错误率(average classification error rate,ACER),其为假体人脸分类错误率(attack presentation classification error rate,APCER)与活体人脸分类错误率(bonafide presentation classification error rate,BPCER)的平均。APCER表示将攻击的假体人脸错分为真实人脸的比率。BPCER表示将真实人脸错误地判断为假体攻击的比率。显然,ACER指标值越小越好。计算公式为
其中:TP表示正确判定为活体人脸的数量;TN表示正确判定为非活体人脸的数量;FP表示实际的非活体人脸判定为活体人脸的数量;FN表示实际的活体人脸判定为非活体的人脸数量。
3.2 对比实验
为验证S2FMN方法在灵活模态任务上的有效性,依据表1给出的灵活模态测评协议进行域内和跨域实验,并与现有文献方法进行对比。
3.2.1 域内评估
在SURF&CeFA数据集上进行域内评估实验,将S2FMN方法与两种多流结构及一种简单拼接单流进行对比,结果如表2所示。所对比的三种方法均是基于ViT网络构建的,多流结构中的ViT_Concat与ViT_CA方法的特征提取器相同,即均将每个模态数据经由Transformer编码器提取特征,ViT_Concat方法是采用拼接操作实现三个模态数据的融合,ViT_CA方法则是由交叉注意力机制 (cross-attention,CA)模块实现特征级融合,相较于拼接融合方法更为复杂。对比的单流网络结构是将三个模态数据简单拼接后送入Transformer 编码器提取融合特征。
表2的实验结果表明,S2FMN方法在四个子协议上的域内性能均表现最佳,尤其是在子协议2与4上ACER值仅为0.99%、0.64%,其在四个子协议上ACER均值达到2.69%,较取得均值次优结果的对比单流ViT网络要低1.87个百分点,且由ACER标准差可知,S2FMN方法在四个子协议上的性能表现较为均衡。同时可以看出,相较于多流网络,单流网络在灵活模态任务上更加有效,验证了自注意力机制可计算全局相关性的特点,有助于多模态特征交互融合。
3.2.2 跨域评估
为验证模型面对未知域的鲁棒性,文中在WMCA数据集上开展跨域评估,实验结果如表3所示。S2FMN方法在协议1和3上性能最佳,ACER值分别为37.57%和30.20%;而在子协议2和4上,ViT_Concat方法表现最佳,ACER值分别为30.37%和29.51%。S2FMN方法在4个子协议上ACER均值达到33.81%,相较于对比单流ViT网络要低6.40个百分点,取得平均最佳性能。同时,S2FMN方法的ACER标准差仅为3.13%,相较于其他三种对比方法,均衡性表现最佳。值得一提的是,S2FMN方法相較于对比单流ViT网络在四个子协议上的性能均有所提升,ACER值分别下降了3.40、1.21、12.05与8.95个百分点。
3.2.3 跨任务对比
为验证S2FMN方法在子协议上的性能,本文在WMCA数据集上进行统一训练,在四个子协议上进行测试,并与传统单模态和多模态方法进行跨任务对比,实验结果如表4所示。S2FMN在仅有可见光模态时相较于单模态方法表现最佳,ACER值为5.42%。当仅用可见光和红外模态进行测试时,S2FMN方法取得次优结果。虽然其在仅有可见光与深度图模态场景和三个模态齐备场景的性能略逊于MA-ViT[23]和ViT+ConvA+M2A2E[11]方法,但灵活模态任务相较传统单模态与多模态任务难度更大,对模型面对未知场景的泛化性和鲁棒性要求更高。所以,尽管本文方法与传统单模态和多模态方法相比不全面占优,但也是具有较强竞争力的。
3.3 消融实验
从补齐策略与模态编码两个方面在SURF&CeFA数据集上进行消融实验对比,以考察两者对S2FMN方法的影响。
3.3.1 补齐策略的影响
灵活模态任务在测试阶段需要面对模态缺失的问题。ViT_Concat与ViT_CA方法面对模态缺失问题时,均采用零补齐策略,即利用零矩阵作为缺失的模态数据输入网络。本文采用非补齐策略来解决模态缺失问题,即对缺失模态数据不采用已知数据进行补齐。下面探究零补齐与非补齐策略对S2FMN模型性能的影响。在4个子协议上的域内与跨域评估实验结果如表5所示。
其中域内评估结果表明,在子协议1、2和3上非补齐策略的ACER指标值低于零补齐策略,分别下降了2.32、1.91与0.17个百分点,虽然在子协议4上零补齐策略ACER值稍低于非补齐策略0.08个百分点,但非补齐策略的ACER均值要好于零补齐策略1.08个百分点,且非补齐策略的ACER标准差亦更低。同时跨域评估实验结果表明,在四个子协议上非补齐策略的ACER值均低于零补齐策略,分别下降了2.07、4.18、17.52与4.98个百分点,从ACER均值与标准差来看,均是非补齐策略更佳,非补齐策略的ACER均值要好于零补齐策略7.19个百分点。
综合来看,对于S2FMN方法,在解决模态缺失问题时,更适宜采用非补齐策略,其域内与跨域泛化性能均优于零补齐策略,且在不同子协议上的ACER表现更加均衡、波动更小。
3.3.2 模态编码的影响
S2FMN方法采取前期融合策略,若将三种模态数据拼接后直接送入FEM模块中进行多模态特征的交互融合,则模型无法对各模态数据进行区分。为此,设计模态标记(即模态编码信息Xmod)以令模型更好地区分各个模态数据。为探究模态标记的有效性,文中分别在SURF&CeFA和WMCA数据集上开展域内和跨域消融实验,实验结果如图7所示。
在域内评估结果中,有模态编码的实验在子协议1、2和4上的ACER值优于无模态编码,尽管在子协议3上无模态编码的ACER值要优于有模态编码0.41个百分点,但有模态编码的ACER均值为2.78%,整体要优于无模态编码0.24个百分点。在跨域评估中,有模态编码的ACER值在四个子协议上均优于无模态编码,该指标值分别下降了11.61、9.15、16.15与0.84个百分点。
整体而言,在域内测试时,添加模态编码信息更有助于提高模型的准确率,在跨域测试时添加模态编码后的模型泛化性能更好。
3.4 效率分析
在灵活模态任务中,模型的效率对实际应用也是至关重要的。表6展示了多流ViT_Concat网络、简单拼接单流ViT网络和S2FMN的计算量(FLOPs)与参数量(Param)。其中,多流网络模型ViT_Concat的FLOPs高达199.92 G,且Param为96.83 M,这加大了模型的部署难度。而采用零补齐策略的简单拼接单流网络ViT模型的Param相较于ViT_Concat减少11.21 M,FLOPs减少149.5 G。同时发现,S2FMN方法不论采取零补齐或非补齐策略,在四个子协议上的FLOPs均低于对比的两种方法,采用零补齐策略的S2FMN模型FLOPs约为ViT_Concat方法的十分之一。另外,S2FMN方法采取零补齐、非补齐策略时的Param尽管同为85.62 M,但在四个子协议上采取非补齐策略时的FLOPs有所不同,均不超过零补齐策略,尤其是在子协议1上,非补齐策略时的FLOPs仅约为零补齐策略的三分之一。可见,针对缺失模态所采取的策略对模型效率有较大的影响。
值得注意的是,S2FMN方法在采取非补齐策略时,其在四个子协议上的FLOPs仅为ViT_Concat的3.51%、6.98%、6.98%与10.45%,Param为ViT_Concat的88.42%。由此可见,S2FMN方法不仅在评价性能ACER指标上相较于现有方法竞争力较强,而且其低计算复杂度的模型在实际应用部署上也具有一定优势。
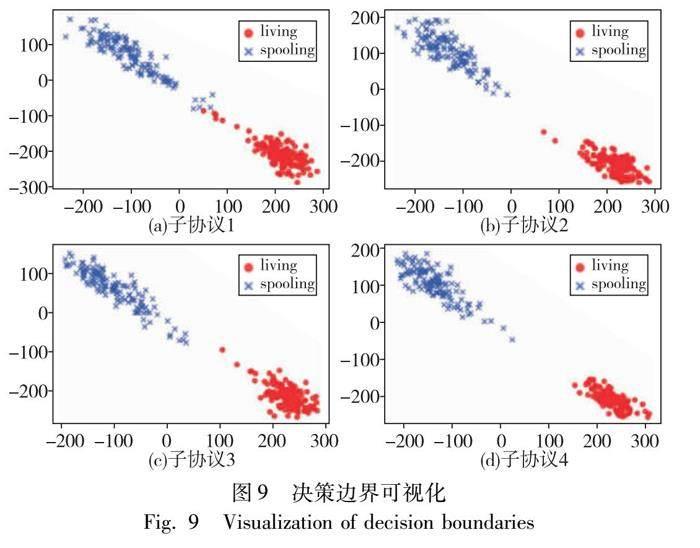
3.5 可视化分析
本文在SURF&CeFA数据集上,从特征融合和模型决策角度出发进行特征可视化分析。
t-分布式隨机邻居嵌入(t-distributed stochastic neighbor embedding,t-SNE)是一种无监督的非线性技术,主要用于数据探索和可视化高维数据。t-SNE尝试保留原始高维数据之间的相对距离关系,并在低维空间中利用概率分布来表示数据之间的相似性关系,可以将高维数据映射到一个低维空间(通常是2D或3D)以便于可视化。本文采用t-SNE将FEM模块的输出特征图降维,分别从2D和3D角度将融合特征和各模态特征分布进行可视化分析,如图8所示,其中RDI表示融合特征分布,R、D和I分别表示可见光、深度图和红外模态特征分布。由图8可见,S2FMN模型能充分聚合各模态特征,融合后的特征RDI对各模态特征均有强表征性。
同时,本文按灵活模态协议将不同测试场景上S2FMN模型的决策边界进行可视化。如图9所示,living和spoofing分别表示活体与假体样本。由图9可见,当子协议1仅有可见光模态时,存在少量样本易混淆;随着子协议2、3分别增加了深度和红外模态后,决策边界逐渐分明,仅有个别离群点;当子协议4同时具备三种模态时,模型可以精准地对活体与假体样本进行区分。
4 结束语
灵活模态任务旨在提高模型性能的同时增加模型的灵活性和高效性,以克服传统多模态任务在部署场景缺失部分模态数据时需要重新训练模型的局限性。文中提出一种基于空洞单流ViT的灵活模态 fPAD方法,在对输入模态数据进行空洞块嵌入处理的基础上,利用自注意力机制实现模态数据的交互融合,在模态缺失时采用非补齐策略。经大量实验表明,S2FMN方法可在保证模型准确性的同时,降低模型的计算量与参数量,确保了模型实际应用的灵活性与高效性。鉴于现有方法在不同子协议上的性能表现存在一定的差异,未来灵活模态任务的研究可探索如何简单高效地解决模态偏向性问题,以进一步提高模型跨域评估性能。
参考文献:
[1]Yu Zitong,Qin Yunxiao,Li Xiaobai,et al. Deep learning for face anti-spoofing: a survey [J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2023,45(5): 5609-5631.
[2]Wang Jingjing,Zhang Jingyi,Bian Ying,et al. Self-domain adaptation for face anti-spoofing [C]// Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2021: 2746-2754.
[3]Hamblin J,Nikhal K,Riggan B S. Understanding cross domain pre-sentation attack detection for visible face recognition [C]// Proc of the 16th IEEE International Conference on Automatic Face and Gesture Recognition. Piscataway,NJ: IEEE Press,2021: 1-8.
[4]孫文赟,金忠,赵海涛,等. 基于深度特征增广的跨域小样本人脸欺诈检测算法 [J]. 计算机科学,2021,48(2): 330-336. (Sun Wenyun,Jin Zhong,Zhao Haitao,et al. Cross-domain few-shot face spoofing detection method based on deep feature augmentation [J]. Computer Science,2021,48(2): 330-336.)
[5]Pérez-Cabo D,Jiménez-Cabello D,Costa-PazoA,et al. Learning to learn face-PAD: a lifelong learning approach [C]// Proc of IEEE International Joint Conference on Biometrics. Piscataway,NJ: IEEE Press,2020: 1-9.
[6]Quan Ruijie,Wu Yu,Yu Xin,et al. Progressive transfer learning for face anti-spoofing [J]. IEEE Trans on Image Processing,2021,30: 3946-3955.
[7]Baweja Y,Oza P,Perera P,et al. Anomaly detection-based unknown face presentation attack detection [C]// Proc of IEEE International Joint Conference on Biometrics. Piscataway,NJ: IEEE Press,2020: 1-9.
[8]Wang Zezheng,Yu Zitong,Zhao Chenxu,et al. Deep spatial gradient and temporal depth learning for face anti-spoofing [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2020: 5042-5051.
[9]孙锐,冯惠东,孙琦景,等. 纹理和深度特征增强的双流人脸呈现攻击检测方法 [J]. 模式识别与人工智能,2023,36(3): 242-251.( Sun Rui,Feng Huidong,Sun Qijing,et al. Texture and depth feature enhancement based two-stream face presentation attack detection method [J]. Pattern Recognition and Artificial Intelligence,2023,36(3): 242-251. )
[10]甘俊英,翟懿奎,项俐,等. 面向活体人脸检测的时空纹理特征级联方法[J]. 模式识别与人工智能,2019,32(2): 117-123.( Gan Junying,Zhao Yikui,Xiang Li,et al. Spatial-temporal texture cascaded feature method for face liveness detection [J]. Pattern Recognition and Artificial Intelligence,2019,32(2): 117-123.
[11]Yu Zitong,Cai Rizhao,Cui Yawen,et al. Rethinking vision Transformer and masked autoencoder in multimodal face anti-spoofing [EB/OL]. (2023-03-11). https://arxiv. org/abs/2302. 05744.
[12]Zhang Shifeng,Wang Xiaobo,Liu Ajian,et al. A dataset and benchmark for large-scale multi-modal face anti-spoofing [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2019: 919-928.
[13]Liu Ajian,Tan Zichang,Wan Jun,et al. CASIA-SURF CeFA: a benchmark for multi-modal cross-ethnicity face anti-spoofing [C]// Proc of IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway,NJ: IEEE Press,2021: 1179-1187.
[14]George A,Mostaani Z,Geissenbuhler D,et al. Biometric face presentation attack detection with multi-channel convolutional neural network [J]. IEEE Trans on Information Forensics and Security,2019,15: 42-55.
[15]Parkin A,Grinchuk O. Recognizing multi-modal face spoofing with face recognition networks [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway,NJ: IEEE Press,2019: 1617-1623.
[16]Yu Zitong,Qin Yunxiao,Li Xiaobai,et al. Multi-modal face anti-spoofing based on central difference networks [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway,NJ: IEEE Press,2020: 650-651.
[17]Yu Zitong,Zhao Chenxu,Wang Zezheng,et al. Searching central difference convolutional networks for face anti-spoofing [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2020: 5295-5305.
[18]Wang Zi,Li Chenglong,Zheng Aihua,et al. Interact,embed,and enlarge: boosting modality-specific representations for multi-modal person re-identification [C]// Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2022: 2633-2641.
[19]George A,Marcel S. Cross modal focal loss for RGBD face anti-spoofing [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2021: 7882-7891.
[20]Li Diangang,Wei Xing,Hong Xiaopeng,et al. Infrared-visible cross-modal person re-identification with an X modality [C]// Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2020: 4610-4617.
[21]朱大力,朱樺,陈志寰. 基于多模态融合的活体检测研究 [J]. 武汉理工大学学报:信息与管理工程版,2021,43(3): 264-286. (Zhu Dali,Zhu Hua,Chen Zhihua. Face anti-spoofing based on multimodal fusion [J]. Journal of Wuhan University of Technology:Information & Management Engineering,2021,43(3): 264-286.
[22]Yu Zitong,Liu Ajian,Zhao Chenxu,et al. Flexible-modal face anti-spoofing: a benchmark [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2023: 6345-6350.
[23]Liu Ajian,Liang Yanyan. MA-ViT:modality-agnostic vision Transformers for face anti-spoofing [C]// Proc of the 31st International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann,2022: 1180-1186.
[24]Dosovitskiy A,Beyer L,Kolesnikov A,et al. An image is worth 16×16 words: Transformers for image recognition at scale [EB/OL]. (2021-06-03). https://arxiv. org/abs/2010. 11929.
[25]Yu F,Koltun V. Multi-scalecontext aggregation by dilated convolutions [EB/OL]. (2015-11-23). https://arxiv. org/abs/1511. 07122.
[26]Liu Ajian,Tan Zichang,Wan Jun,et al. Face anti-spoofing via adversarial cross-modality translation [J]. IEEE Trans on Information Forensics and Security,2021,16: 2759-2772.
[27]George A,Marcel S. Deep pixel-wise binary supervision for face pre-sentation attack detection [C]//Proc of International Conference on Biometrics. Piscataway,NJ: IEEE Press,2019: 1-8.
[28]Liu Ajian,Zhao Chenxu,Yu Zitong,et al. Contrastive context-aware learning for 3D high-fidelity mask face presentation attack detection [J]. IEEE Trans on Information Forensics and Security,2022,17: 2497-2507.
