基于注意力机制和BGRU网络的文本情感分析方法研究
2019-07-29尹良亮孙红光王超贾慧婷索朗卓玛
尹良亮 孙红光 王超 贾慧婷 索朗卓玛

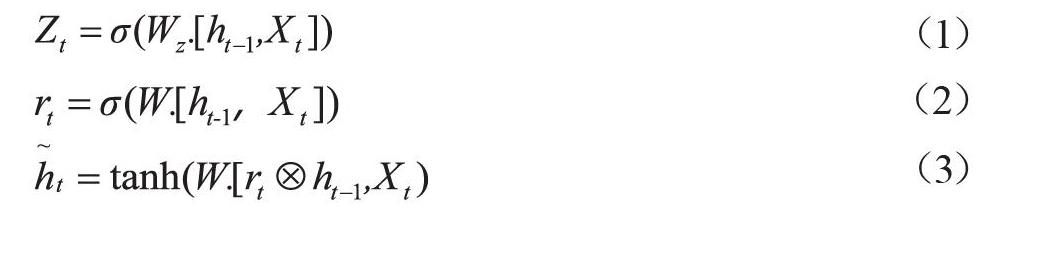

摘 要:文本情感分类只考虑内容中的情感语义,不能有效表示上下文语义信息,忽略词对句子含义的重要程度,基于此,文章提出一种基于注意力机制和双向门循环单元网络的情感分析方法,使用双向门循环单元代替原有的简单网络,有效结合文本中的上下文语义信息。通过在公开数据集IMDB上进行验证,对比MLP网络、BRNN网络和BGRU网络得出,文章提出的方法达到最好分类效果。
关键词:文本情感分析;注意力机制;双向门循环单元;深度学习
随着电子商务的普及和发展,互联网上的产品评论信息呈指数增长。产品评论信息在一定程度上影响消费者的购买意愿,也会影响产品及其企业的形象。这些产品评论包含的信息量巨大,并且呈无结构化特点,通过人工阅读的方式难以实现对它们的处理。本文提出一种基于注意力机制和双向门循环单元(Bi Gated Recurrent Unit,BGRU)网络(Att_BGRU)的文本情感分析方法,利用BGRU代替原有的简单网络,缓解长距离依赖问题和梯度消失问题,并且能够更好地避免过拟合问题的出现。结合注意力机制,能突出目标词的重要性,进而能够获取更多的隐藏信息[1]。
1 基于注意力机制和BGRU网络方法
基于注意力机制和BGRU网络的文本情感分析方法,采用BGRU网络,该网络从正反两个方向捕获上下文语义特征信息,更加有效地结合文本中的上下文语义特征。同时,采用注意力机制,在获取情感特征时,相关度较高的词在句子语义特征中表示占據更大的权重。
该方法的整体流程为:首先,对输入的文本句子利用词向量进行编码,转换为词向量表示后,将用词向量表示的文本特征导入BGRU中,采用注意力机制计算注意力概率,对BGRU的输入和输出的相关性进行重要度分析,根据注意力概率获取BGRU的输出句子级别的语义特征。其次,对引入注意力机制后的BGRU的输出特征进行最大池化处理,获取文本整体特征。最后,将句子级别的特征导入分类器中进行分类,输出分类效果[2]。
2 模型求解
2.1 任务定义
对于长度为n的句子s={w1,w2,…,ai,…,wn},ai为目标词,将句子以词为单位形成一个词序列,将每个词映射为一个多维连续值的词向量,得到词向量矩阵E∈Rk×|V|,k为词向量维度,即把每一个词映射为k维向量xi∈Rk,|V|为词典的大小,即数据集包含的所有词的数量。本文通过句子词向量集合{x1,x2,…,xn}和目标集合{ti}之间的特征信息来判断目标集合{ti}中每一个目标的情感极性。
2.2 门循环单元
为了解决这种长期依赖问题,可以运用Hochreiter等提出的长短期记忆网络(Long Short-Term Memory,LSTM)来替代传统的循环神经网络模型。本文提出方法RNNs采用其中较流行的变体,称作门控循环单元(Gated Recurrent Unit,GRU),结构如图1所示。
图1 门控循环单元网络结构
其中,rt表示重置门,它的值决定了过去的记忆与当前的输入的组合方式;zt表示更新门,它控制着过去的记忆有多少能被保存,重置门单元rt、更新门单元zt和记忆单元st的计算公式如下所示:
其中,表示矩阵对应元素相乘,σ表示sigmoid函数,w表示GRU共享参数。
假设一个句子Si中有T个词,每个词为wit,t∈[0,T],将句子Si看作一个序列,句子中的词为句子序列的组成部分。那么,分别通过前向GRU和后向GRU模型就能得到句子的表达:
通过结合 得到句子Si的语义表示:
2.3 注意力机制的引入
在句子级别的文本语义特征表示中,假设Si表示通过Attention方法得到的句子语义特征,则:
其中,δij表示第j个词的重要程度。定义δij的计算:
假设其中,e是计算词wit的重要性程度的函数:
WH是参数矩阵,V是参数向量,VT是转置向量。
2.4 对输出的特征进行池化
池化处理是对输出结果进行统计,采用最大池化方法对整个句子引入注意力机制以后对对应的输出特征d={s1,s2,s3,…,sm}进行池化:
池化后获得文本特征d,无论句子长度是多少,池化后的特征维度都是固定的,这样就解决了文本句子长度不一的问题。
2.5 对最后得到的特征进行分类
上述得到池化后的特征可以直接作为文本分类器的特征输入。首先,通过一个非线性层(tanh)将d映射到维度为C的空间,C是文本分类器中的类别的数目,计算公式:
采用softmax分类器,得到文本分类,公式如下:
pc是文本情感类别为c的预测概率。
2.6 模型训练
文本情感分析本质上是一个分类问题。为了获取最优的模型,本文通过使用交叉熵损失函数作为模型训练的优化目标,通过随机梯度下降算法来计算损失函数梯度同时更新模型参数,计算公式如下:
其中,D是训练数据集;是文本情感分类为c的0—1分布,即,如果文本情感分类为c,那么的值为1,否则的值为0。
3 实验与分析
采用公共数据集验证本文方法在文本情感分类任务的有效性。英文词向量采用Pennington等[2]提出的Glove词向量,其中,每个词向量为100维,词典大小为331 MB。对于未登录词,采用随机初始化。
3.1 實验数据
本文采用Kaggle提供互联网电影数据库(Internet Movie Database,IMDB)电影评论数据进行训练和验证。数据样本中的情感极性为积极和消极。数据总共有25 000个样本,其中,20 000个样本作为训练集,5 000个样本作为测试集。为了平衡语料,积极和消极情感样本各12 500个。
3.2 实验评价指标
本文采用准确率(accuracy)和平方根误差(Root Mean Square Error,RMSE)两个评价标准来评价分类结果。其中,准确率用来衡量分类器准确性。平方根误差用来衡量预测情感标签和真实情感标签之间的差异。
其中,out_correct表示输出的判断正确的关系个数,out_output_all表示输出的所有关系个数,gold表示当前评论文本的类别,predicted表示当前评价文本的预测类型。
3.3 参数设置
模型的激活函数选用tanh函数,隐含层节点数取100,采用softmax作为分类器。为防止模型计算过程出现的过拟合现象,采用L2正则化方法对网络参数进行约束,训练过程引入丢码策略,其丢码率取0.5。另外,采用批量的rmsprop优化方法用于模型训练,批处理大小取50,训练轮数取100。所有模型参数都根据经验选取。
3.4 实验对比
本文与传统的深度学习方法:多层神经网络(Multilayer Perceptron,MLP),双向循环神经网络(Bi-directional Circulatory Neural Network,BRNN),BGRU的方法在同一个语料库上进行实验对比。为统一比较标准,所有方法的输入词向量均采用Glove词向量,所有网络隐藏节点数均相同,池化和分类均采用2.4,2.5节方法进行处理。4组方法在相同数据集上的情感分类对比实验如表1所示。
从表1结果可以看出,本文提出的方法在数据集上分类效果优于其他方法。Att_BGRU在IMDB数据集中的情感分类准确率达到80.46%。BGRU的分类效果也要比基本的深度学习网络的多层感知机和BRNN要好。分析实验结果可知,在递归神经网络(Recurrent Neural Network,RNN)中,梯度消失导致无法保留前面较远时间的记忆。
At_BGRU方法比BGRU方法分类准确率高,原因是在加上注意力机制后,突出了GRU中关键性输入的影响,同时考虑到文本中句子与结果的相关性,从而更好地识别文本的情感极性,验证了注意力机制在文本情感分类任务的有效性。
4 结语
本文针对传统深度学习方法,如MLP,BRNN,BGRU方法在产品文本情感分析时存在的忽略上下文语义信息等问题,提出了基于注意力机制和BGRU网络的方法进行文本情感分析,在IMDB数据集上进行对比实验,验证了At_BGRU方法能够更好地发现文本信息的情感倾向性。下一步将该方法结合多注意力机制,使方法在不需要外部知识的情况下,例如句法分析等,获取更深层次的情感特征信息,有效地识别不同目标的情感极性。
[参考文献]
[1]HOCHREITER S,SCHMIDHUBER J.Long short-Term memory[J].Neural Computation, 1997(8):1735.
[2]JEFFREY P,RICHARD S.GloVe: global vectors for word representation[C].Doha:Empirical Methods in Natural Language Processing,2014.
Abstract:Text emotion classification only considers the emotional semantics in the content, can not effectively represent the contextual semantic information, and ignores the importance of words to the meaning of the sentence. In this paper, an emotional analysis method based on attention mechanism and bidirectional gate loop unit network is proposed. The bidirectional gate loop unit is used instead of the original simple network, which effectively combines the context semantic information in the text. Compared with MLP network, BRNN network and BGRU network, the method proposed in this paper achieves the best classification effect by validating on the open dataset IMDB.
Key words:text emotion analysis; attention mechanism; two-way door cycling unit; deep learning
