基于序列到序列模型的文本到信息框生成的研究
2019-07-01鲍军威周明赵铁军
鲍军威 周明 赵铁军


摘 要:本文展示了一种序列到序列的模型(Seq2Seq)来基于文本生成信息框(Infobox),信息框指的是一组“属性-值”对。该模型以端到端的方式工作,可利用一个编码器将一个文本段落表示成一个隐向量序列,然后通过解码器来生成信息框。本文在WIKIBIO数据集上进行实验。研究提出的序列到序列模型取得了58.2的F1值,该结果比流水线式的基准方法显著提升了21.0个百分点。实验结果表明,本模型具有以生成序列的方式来生成“属性-值”对的能力。引入注意力与拷贝机制可以提升模型的准确率。更重要的是,研究观察到该拷贝机制有能力从输入文本中拷贝稀有词来生成目标端信息框中的“值”。
关键词: 文本到信息框生成;序列到序列模型;注意力机制;拷贝机制
文章编号:2095-2163(2019)03-0001-06 中图分类号:TP393.01 文献标志码:A
0 引 言
信息框(Infobox)是一种结构化的知识(https://en.wikipedia.org/wiki/Infobox),其中包含一组关于相应文章主题的“属性-值”对。信息框可以应用在很多需要推理与推断的场景中,例如基于知识图谱的自动问答和语义解析等[1-4]。然而,基于文本通过人工来构建信息框将会耗费大量的资源和成本。而且,更新已经构建好的信息框也需付出大量时间。因此,自动地从文本中抽取信息框受到学界越来越多的关注与重视[5-7]。传统的信息框抽取方法通常包含一个复杂的流程,并主要依赖于专家知识和特征工程。同时,这些系统却常会遭受错误传导的问题。为此,探索端到端的方法来自动学习生成信息框是十分必要的。
最近,序列到序列(Seq2Seq)的模型在很多任务中得到了成功运用,例如机器翻译[8-9],文本摘要[10]等。本文提出一种新的方法将Seq2Seq模型扩展到文本到信息框的生成任务上。总地来说,该模型将输入文本通过编码器表征成一组实值向量,而后通过解码器基于这些实值向量来生成信息框。在本文中,研究将一组“属性-值”对转化成序列,由此使得Seq2Seq模型能够以序列的形式来生成信息框。注意力机制被用于计算各种各样的自然语言表达与“属性”的相似度。同时,研究中还采用拷贝机制从源文本中拷贝稀有词来生成信息框中的“值”。
本次研究在包含了728 321个“人物传记-信息框”对的WikiBio数据集[11]上进行了实验。Seq2Seq模型取得了58.2的平均F1值,该结果比流水线式的方法显著提升了21.0个百分点。经由大量的实验证明可知,Seq2Seq模型有能力以生成序列的方式来生成信息框。注意力与拷贝机制的引入最终将大幅提升模型的准确率。而在研究后却又发现拷贝机制有能力从输入文本拷贝稀有词来生成信息框中的“值”。尤需一提的是,模型分析表明Seq2Seq模型在高频属性上的表现会更好。错误分析则表明Seq2Seq模型在那些需要逻辑推理的“属性”与“值”的生成方面具有一定局限。
1 任务与数据集
1.1 任务
1.2 数据集
WikiBio[11]是来自于Wikipedia的一组包含“人物传记-信息框”对的数据集。人物传记是对应的Wikipedia文章的第一段,同时该段落往往包含了多个句子。WikiBio包含了728 321个实例,且被划分为3个部分,包括582 659条训练数据、72 831条开发数据、以及72 831条测试数据。在本文中,研究使用该数据集来基于人物传记生成信息框。在本文的设定中,如果一个“属性-值”对的“值”中没有一个词出现在输入文本中,那么研究将会过滤掉这个“属性-值”对。如果一个“值”中包含超过5个词,那么相应的“属性-值”对也会被移除。最终,本文获得了WikiBio的一个子集,集合中包含了580 069个实例作为训练数据,72 502个实例作为开发集数据,72 517个实例作为测试数据。在此基础上,研究得出的过滤后的训练数据的统计信息见表1。
2 方法
在本节中,研究展示一个整合了注意力机制与拷贝机制的Seq2Seq模型来进行文本到信息框的生成。继而给出了本方法进行文本到信息框生成的设计展示如图1所示。对此可做探讨分述如下。
2.1 编码器
2.2 解码器
2.3 注意力机制
这里,在分析基础上将观察到输入端的不同的词对生成特定的“属性-值”对的贡献是不同的。因此,解码器在生成每个词时就能够有选择性地使用输入文本中不同的信息。综合以上论述,本次研究就采用注意力机制[13],在解码的每个时刻对输入文本中的每个词都赋予一个概率/权重值,该机制已成功地应用在许多任务中,诸如机器翻译[14]和阅读理解[15]。解码第t时刻的词时,对于输入文本中第i个词的注意力权重可定义为:
2.4 拷贝机制
3 实验
3.1 实验设置
3.1.1 数据集
文中在2.2节描述的过滤后的WikiBio数据集上进行实验。在本次研究的实验设置中,一个“属性”可当作是一个单独的词。如此一来,文中仅使用开发集中的前1 000个数据进行开发。
3.1.2 评测指标
研究中采用准确率(P)、召回率(R)、以及F1值并基于金标准的一组“属性-值”对来推得评价预测的一组“属性-值”对。最终在整个测试数据集上的P,R,F1值是所有实例上相应得分的平均值。
3.1.3 基准线方法
受已有研究[5]的启发,设计实现了一个流水线式的方法作为基准方法。该方法包括了一组分类器和一组抽取器。每个“属性”对应到一个分类器,该分类器用来确定一段文本是否可以生成该“属性”。每个抽取器将用来为某个“属性”进行相应“值”的抽取。被抽取出来的值,例如时间,都进行了正则化。这些分类器是基于Classias(http://www.chokkan.org/software/classias/usage.html.en)工具中的采用L2正則化的L1损失函数的SVM模型实现的。抽取器采用CRF++(https://taku910.github.io/crfpp)模型。研究中,通过使用词汇化的特征,而非诸如词性(part of speech, POS)等句法特征,来训练抽取器。这样做的目的是使其与Seq2Seq模型运用相同的信息以增加可比性。S2S是一个基于GRU-RNN结构的不带有注意力机制与拷贝机制的Seq2Seq模型。研究同时也实现了Seq2Seq模型的其它变种。这里,将在实验结果部分对这些模型变种做出阐释论述如下。
3.2 实验结果
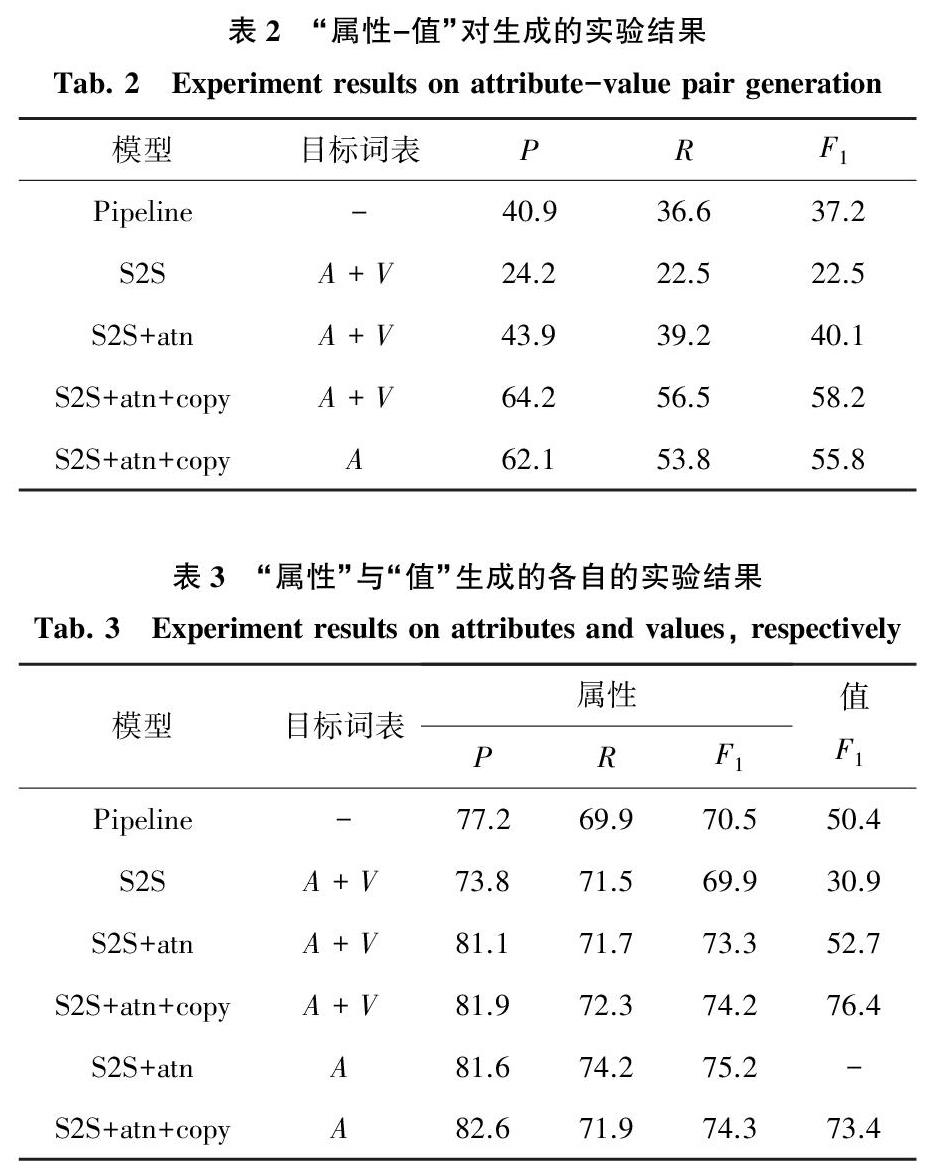
生成“属性-值”对的实验结果见表2。表2中,atn表示注意力机制,copy表示拷贝机制,A表示属性,V表示值。实验结果表明2个带有注意力与拷贝机制的S2S模型要明显好于基于流水线的方法(从37.2到58.2,从37.2到55.8)。引入了注意力机制可以带来17.6个点的提升(从22.5到40.1)。拷贝机制使得模型的结果提升了18.1个百分点(从40.1到58.2)。更重要的是,将“值”加入到目标词表并且使用拷贝开关来权衡可以带来2.4个点的提升(从55.8到58.2)。
研究得到的分别在“属性”与“值”上单独评估的结果见表3。表3中,Attributes表示研究只对生成的“属性”进行评测,values表示只对生成的值进行评测,这些值对应的属性都是预测正确的。atn表示注意力机制,copy表示拷贝机制,A表示属性,V表示值。除了基本的S2S模型外,其它带有注意力机制或者拷贝机制的模型在“属性”与“值”上的结果都要好于基于流水线的方法。经过分析可知,注意力机制在“属性”与“值”的生成上都带来提升,分别是从69.9到73.3以及从30.9到52.7。实验结果表明注意力机制对提升模型的准确率是很有帮助的。拷贝机制在“属性”生成上带来的提升比较有限(从73.3到74.2),在“值”的生成上带来的提升比较显著(从52.7到76.4)。这是由于“属性”与“值”不同,而且常常不会出现在文本表述中。通过观测数据,研究发现不带有拷贝机制的Seq2Seq模型只能生成特殊符号UNK来表示OOV的词,而带有拷贝机制的模型可以从文本中拷贝内容来生成稀有词。此外,目标词表中只包含“属性”的S2S+atn模型在“属性”生成上取得了最好的结果。
3.3 实验分析
3.3.1 模型分析
研究进行实验来探索“属性”的频率对信息框生成的影响。相应地,研究基于训练数据集上“属性”的频率将测试数据集分成7份。图2给出了每个部分的运行结果。图2中,横坐标表示“属性”的不同频率范围。该结果表明“属性”的频率越高,模型取得的结果越好。
3.3.2 错误分析
错误分析的结果即如图3所示。为了分析“属性”生成中产生的错误,研究随机选取了100个实例,其中每个实例有至少一个预测错误的“属性”。由此则发现54%的实例的错误是可以接受的,包括A2类(不恰当的金标准“属性”)、A3(不充足的金标准“属性”)、A5(预测了同义的“属性”)。“属性”生成的主要错误是A1(需要逻辑推理)、A4(预测错的“属性”的频率太低)、A6(其它类型)。此外,随机选取其它100个实例,而且每个实例中都存在某个“属性”预测正确而“值”预测错误的“属性-值”对。这些实例中46%是可以接受的,包括V1(预测了同义的“值”)、V3(错误标注了的金标准的“值”)。主要的错误包括V2(预测了相似的值)、V4(需要逻辑推理)、V5(预测部分“值”)、V6(其它)。
4 相关工作
本工作主要涉及2条研究主线,对此可做探讨分述如下。
4.1 Wikipedia上文本到結构化知识的预测
已有的一些知名的产品都是通过流水线式的方式、并基于Wikipedia进行信息抽取而得到的,例如DBpedia[16]、YAGO[17]、YAGO2[18]、KYLIN[5]、IBminer[6]、iPopulator[19]、以及WOE[20]。Nguyen等人[21]提出使用句法信息与语义信息,就可从Wikipedia中抽取关系。Zhang等人[7]使用连接命名实体(重定向)来将一篇文章总结成信息框。在本文中,研究采用序列到序列(Seq2Seq)的神经网络模型来端到端地进行文本到信息框的生成。
4.2 序列到序列(Seq2Seq)的学习
Seq2Seq模型在很多任务上均可见到效果可观的应用尝试,例如机器翻译、对话回复生成和文本摘要[10,12,22-23]。在本文中,设计展示了一个Seq2Seq模型来进行文本到信息框的生成。文中的Seq2Seq模型采用了带有注意力机制与拷贝机制的“编码器-解码器”框架。不同的注意力机制[13-14, 24]也相继推出,用于将输入序列与输出序列进行对齐。受到这些工作的启发,本文研究采用一种注意力机制来连接自然语言与信息框。拷贝机制的提出受益于近期的关于指向网络(pointing network)与拷贝(copying)方法[10,25-29]的成功。
5 结束语
本文提出了一个序列到序列(Seq2Seq)的模型来进行文本到信息框的生成。实验结果表明Seq2Seq模型有能力以生成序列的方式来生成一个结构化的信息框。研究观察到引入了注意力与拷贝机制可以提升模型的准确率,同时拷贝机制有能力从原文本中拷贝稀有词来生成目标信息框中的“值”。
参考文献
[1] MOONEY R J. Learning for semantic parsing[C] //Computational Linguistics and Intelligent Text Processing(CICLing). Mexico City:dblp,2007:311-324.
[2] BERANT J, CHOU A, FROSTIG R,et al. Semantic parsing on freebase from question-answer pairs[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Seattle,Washington, USA:Association for Computational Linguistics,2013:1533-1544.
[3] YIH W T, CHANG Mingwei, HE Xiaodong,et al. Semantic parsing via staged query graph generation: Question answering with knowledge base[C] // Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Beijing, China:Association for Computational Linguistics, 2015:1321-1331.
[4] BORDES A, USUNIER N, CHOPRA S, et al. Large-scale simple question answering with memory networks[J]. arXiv preprint arXiv:1506.02075,2015 .
[5] WU Fei, WELD D S. Autonomously semantifying wikipedia[C] //Proceedings of the sixteenth ACM conference on Information and Knowledge Management.New York, USA: ACM, 2007:41-50.
[6] MOUSAVI H, GAO Shi,ZANIOLO C. Ibminer: A text mining tool for constructing and populating infobox databases and knowledge bases[J]. Proceedings of the VLDB Endowment, 2013,6(12):1330-1333.
[7] ZHANG Kezun, XIAO Yanghua, TONG Hanghang, et al. The links have it: Infobox generation by summarization over linked entities[J]. arXiv preprint arXiv:1406.6449,2014.
[8] KALCHBRENNER N, BLUNSOM P. Recurrent continuous translation models[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing.Seattle:ACL, 2013:1700-1709.
[9] SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks [C]// Advances in Neural Information Processing Systems. Montreal, Canada: Nips,2014:3104-3112.
[10]NALLAPATI R, ZHOU Bowen, SANTOS C, et al. Abstractive text summarization using sequence-to-sequence RNNs and beyond[J]. arXiv preprint arXiv:1602.06023,2016.
[11]LEBRET R, GRANGIER D, AULI M. Neural text generation from structured data with application to the biography domain[C] // Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing.Austin, Texas: Association for Computational Linguistics, 2016:1203-1213.
[12]CHO K, VAN MERRIENBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[C] //Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar:Association for Computational Linguistics, 2014:1724-1734.
[13]BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473,2014 .
[14]LUONG M H, PHAM H, Manning C D. Effective approaches to attention-based neural machine translation[J]. arXiv preprint arXiv:1508.04025,2015.
[15]KADLEC R,SCHMID M, BAJGAR O, et al. Text understanding with the attention sum reader network[J]. arXiv preprint arXiv:1603.01547,2016.
[16]AUER S, LEHMANN J. What have Innsbruck and leipzig in common? Extracting semantics from wiki content[C]// The Semantic Web: Research and Applications. Innsbruck Austria:Springer,2007:503-517.
[17]SUCHANEK F M ,KASNECI G, WEIKUM G . Yago: A core of semantic knowledge[C]// Proceedings of the 16th International Conference on World Wide Web. Banff, Alberta, Canada:dblp,2007: 697-706.
[18]HOFFART J, SUCHANEK F M, BERBERICH K, et al. Yago2: A spatially and temporally enhanced knowledge base from wikipedia[J]. Artificial Intelligence ,2013,194:28-61.
[19]LANGE D, BHM C, NAUMANN F. Extracting structured information from wikipedia articles to populate infoboxes[C] //Proceedings of the 19th ACM International Conference on Information and Knowledge Management.Toronto,Ontario,Canada: ACM, 2010:1661-1664.
[20]WU Fei, WELD D S. Open information extraction using wikipedia[C] // Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics. Uppsala,Sweden:ACL, 2010:118-127.
[21]NGUYEN D P T, MATSUO Y, ISHIZUKA M. Exploiting syntactic and semantic information for relation extraction from wikipedia[C]//Proceedings of the IJCAI Workshop on Text-Mining Link-Analysis Text Link 2007. Hyderabad, India: [s.n.] ,2007:1414-1420.
[22]AULI M, GALLEYT M, QUIRK C, et al. Joint language and translation modeling with recurrent neural networks[C]// Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Seattle, Washington, USA:ACL,2013:1044-1054.
[23]SORDONI A, GALLEY M, AULI M,et al.A neural network approach to context-sensitive generation of conversational responses[C]// Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Denver, Colorado:ACL, 2015: 196-205.
[24]FENG Shi, LIU Shujie,YANG Nan, et al. Improving attention modeling with implicit distortion and fertility for machine translation[C]//Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers. Osaka, Japan: ACL Press, 2016: 3082-3092.
[25]VINYALS O, FORTUNATO M, JAITLY N. Pointer networks[J]. Advances in Neural Information Processing Systems, 2015:2692-2700.
[26]GULCEHREC, AHN S, NALLAPATI R, et al. Pointing the unknown words[J].arXiv preprint arXiv:1603.08148,2016.
[27]GU Jiatao, LU Zhengdong, LI Hang, et al. Incorporating copying mechanism in sequence-to-sequence learning[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Berlin, Germany:Association for Computational Linguistics, 2016:1631-1640.
[28]YIN Jun, JIANG Xin, LU Zhengdong,et al. Neural generative question answering[J]. arXiv preprint arXiv:1512.01337,2015.
[29]LUONG M T, SUTSKEVER I, LE Q V, et al. Addressing the rare word problem in neural machine translation[C] // Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Beijing, China: Association for Computational Linguistics, 2015: 11-19.
