基于强化学习PPO算法的上市公司投资组合管理
2024-05-13代一方
代一方


[摘 要]传统的投资组合管理方法往往依赖于经验规则或数学模型,难以充分利用市场信息和动态调整投资策略。为了解决这一问题,文章提出一种基于强化学习PPO(Proximal Policy Optimization)算法的新方法。使用上市公司的历史数据进行训练和测试,与传统投资策略和其他强化学习算法进行比较,实验结果表明,基于强化学习PPO算法的投资组合管理方法在投资回报率和风险控制方面取得了显著的改进。
[关键词]强化学习;PPO算法;投资组合管理;上市公司
doi:10.3969/j.issn.1673-0194.2024.05.042
[中图分类号]F830.9 [文献标识码]A [文章编号]1673-0194(2024)05-0140-04
1 文献综述
上市公司投资组合管理是金融领域的重要问题之一,它涉及如何有效地分配投资资金以取得最大化回报并控制风险。随着金融市场越来越复杂,传统的投资组合管理方法难以适应快速变化的市场环境。因此,寻求新的投资策略和方法变得至关重要。强化学习作为一种基于智能体与环境交互学习的方法,在解决复杂决策问题方面展现出巨大潜力。近年来,强化学习在金融领域的应用引起了广泛关注,并取得了令人瞩目的成果。
齐岳等(2018)利用深度强化学习中确定性策略梯度DDPG算法构建投资组合管理模型,通过控制每个股票的投资比例,降低整体的风险,此外,还采用Dropout的方法,有效地避免出现过拟合的情况[1]。韩道岐、张钧垚等(2020)提出的ISTG(Intelligent Stock Trader and Gym),将历史行情、技术、宏观经济等众多因素结合起来,通过对比各种参考标准,以及对比优良的控制策略,构建出一个具有可拓展性的深度强化学习股市操盘手模型[2]。傅丰、王康(2020)研究发现,采用强化学习SAC算法进行金融投资组合管理,年收益率可达到17.53%[3]。王舞宇、章宁等(2021)开发出一种新型的智能投资组合优化算法,它可以根據不断发展的市场环境,结合各种风险因素,灵活地改善投资组合的结果,并且可以根据不同的情况,进行相应的调整,从而更好地满足客户的需求[4]。陈浩、时正华(2022)针对投资组合管理问题,设计出一种基于深度强化学习TD3(Twin Delayed Deep Deterministic policy gradient algorithm)双延迟确定性策略梯度算法的投资组合框架,投资者通过观察股票的因子信息做出决策,以达到终期收益最大[5]。
Proximal Policy Optimization(PPO)算法作为一种强化学习算法,具有高稳定性和高效性的特点,为投资组合管理提供了一种有效的解决方案。本文旨在探索基于强化学习PPO算法的上市公司投资组合管理方法,并对其性能进行评估和分析。与传统方法相比,该方法能够更好地利用市场信息、动态调整投资策略,并根据市场的变化及时进行调整。通过将历史指标信息、技术指标等作为状态变量,以投资决策作为行动空间,利用强化学习的优势,提高投资组合的回报率和风险控制能力。
本研究的贡献主要包括以下几个方面:首先,将强化学习方法引入上市公司投资组合管理领域,为投资决策提供了一种新的理论框架。其次,采用PPO算法进行策略优化,旨在提高投资组合管理的稳定性和效率。最后,通过实证研究对所提出的方法进行验证和评估,与传统方法及其他强化学习算法进行比较分析,展示其优越性和应用潜力。
2 投资组合算法设计
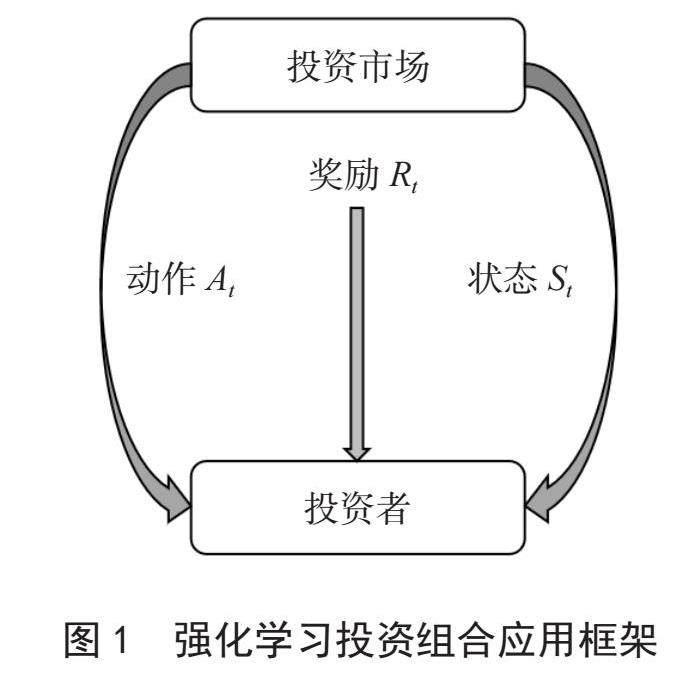
强化学习在投资组合管理中的应用框架是将强化学习方法应用于投资决策的过程。在该框架中,将投资组合管理问题建模为马尔可夫决策过程(MDP),其中投资决策是智能体的行动,市场数据和技术指标是状态变量,回报函数衡量投资决策的效果。基于这个框架,可以利用强化学习的算法和技术来优化投资决策,实现投资组合的最优化。强化学习投资组合应用框架如图1所示。
2.1 动作空间设置
在基于强化学习算法的上市公司投资组合管理中,设置动作空间(Action Space)是关键之一。本文采用组合动作空间(Composite Action Space)方法,组合动作空间是离散和连续动作空间的结合,定义一组离散的操作,设置-1、0、1分别代表卖出、持有和买进一只股票,然后为每个离散动作分配一个连续的数值范围,表示该动作的具体大小。例如,动作可以表示为,表示第t期对第i只股票的操作,为正表示买入该只股票,为负表示卖出该股票。这种设置可以更灵活地表示投资组合的调整。
2.2 环境与状态空间设置
为了应用强化学习,需要定义一个强化学习环境,该环境要模拟投资组合管理的情境。同时,为避免状态空间过于复杂或包含冗余信息,需要考虑状态空间的维度和信息的重要性。在本研究中,收集了上市公司的历史市场数据和技术指标数据,其中,市场数据包括开盘价、收盘价、最高价、最低价、换手率、涨跌幅、成交量、成交金额;技术指标包括平滑异同移动平均线(MACD)、布林线指标(BOLL)上轨线、布林线指标(BOLL)下轨线、相对强度指数(RSI)、30天移动平均价格,然后对数据进行预处理,将处理后的数据作为输入数据。
2.3 奖励函数设置
奖励函数在投资组合管理中起到定义目标、指导行为、控制风险和优化学习的关键作用。通过适当的奖励函数设计,可以提高投资组合管理的效果,并使智能代理能够适应不同市场环境和投资目标。本文根据投资组合的收益来设计奖励函数。奖励函数定义如下:
(1)
其中Xt为资产组合,Pt为股票价格,Ct为现金总额。
2.4 强化学习策略网络建模
在强化学习中,策略网络是智能体的核心组件,用于学习和生成投资决策策略。本文设计一个基于深度神经网络的策略网络,该网络将接收状态作为输入,并输出相应的投资决策。策略网络的目标是通过学习与环境的交互,优化策略参数,以最大化回报函数的累积奖励。在本研究中,选择PPO(Proximal Policy Optimization)算法作为优化算法,通过优化策略参数来最大化期望回报,并保持策略的稳定性,在实现PPO算法时,使用深度神经网络作为策略网络,并根据采样数据进行策略梯度的估计和更新。经过多次采样和优化,逐步提升策略网络的性能。
PPO算法的核心思想是在每个训练迭代中通过近端策略优化来更新策略。相较于一些传统的策略梯度方法,PPO算法采用了裁剪技巧来增强训练的稳定性和收敛性,为了避免策略更新过大,PPO使用了一个重要的技术叫做“Clip Surrogate Objective”。它通过在优化过程中限制新策略和旧策略之间的距离,从而限制了策略更新的幅度。这个限制可以通过引入一个截断函数,将目标函数在一定范围内被截断,限制策略更新的幅度,从而提高算法的稳定性。PPO算法的目标函数定义如下:
(2)
其中为模型更新后的新策略,为更新前的旧策略,为新旧策略的比值。
(3)
为新策略相较于旧策略的优势函数,目标函数包含两部分,一部分为未截断的新旧策略的比值,另一部分为在区间进行截断后的比值,目标函数为两部分的最小值。
3 实 验
3.1 数据样本
在本实证研究中,历史市场数据来源于Tushare 数据接口包,技术指标数据利用Stockstats量化指标库进行计算,数据时间区间为2010年1月4日到2022年12月30日。本文在上证50中将有大量缺失数据的
股票剔除掉,最终挑选出7只股票,即“601318.SH”中国平安,“600519.SH”贵州茅台,“601398.SH”工商银行,“600332.SH”白云山,“600839.SH”四川长虹,“603888.SH”新华网,“600085.SH”同仁堂。
3.2 模型基本设计
本文使用上述数据样本进行模型训练和优化,激活函数选择了RELU函数,并选择Adam作为优化器。策略网络和价值网络的初始学习率均设置为0.000 01,批量大小设置为128。训练步数
100 000,训练时间为2010年1月4日到2020年12月30日,初始资金设置为100万元。训练过程包括观察股票价格的变化,采取行动和奖励的计算,让代理相应地调整其策略,通过与环境互动,交易代理将随着时间的推移获得最大化回报的交易策略。
3.3 实验结果
测试时间为2020年1月4日到2022年12月30日,不同策略评价指标对比如表1所示。
首先,关于年化收益率,我们观察到所有方法的年化收益率都为负值,其中PPO算法的年化收益率为-0.013 5,DDPG算法为-0.123 5,等权重投资组合为-0.083 6,而上证50指数为-0.199 8。
其次,卡玛比率是另一种衡量风险调整收益的指标,PPO算法和等权重的卡玛比率较高,而DDPG算法和上证50指数的卡玛比率较低。夏普比率是衡量收益和风险之间关系的指标,PPO算法和等权重的夏普比率较高,而DDPG算法和上证50指数的夏普比率较低。
最后,我们还观察到所有方法的最大回撤都为负值,等权重投资组合和上证50指数的最大回撤较大,而PPO算法和DDPG算法的最大回撤较小。这意味着它们都经历了一定程度的损失峰值。
在测试时间范围内,整个股票市场受到了COVID-19大流行和全球经济衰退的影响,这是一个极具挑战性的时期,许多国家实施了封锁措施,导致市场大幅波动和不确定性增加。这样的市场环境对投资组合管理产生了显著的影响,由于全球市场的大幅波动和下跌,许多投资组合和指数都遭受了损失,无论是传统的等权重投资组合、上证50指数,还是基于强化学习的PPO算法和DDPG算法,都出现了负收益率和负最大回撤。在这样的市场环境下,传统的经验规则或数学模型往往难以应对市场快速变化和不确定性增加带来的挑战,基于强化学习的方法在一定程度上可以学习和适应市场的动态变化,但仍然受到市场不确定性的影响。综合来看,PPO算法在年化收益率、累计收益率、夏普比率、卡玛比率和最大回撤等方面相对其他方法表现较好,表明PPO算法在上市公司投资组合管理方面具有很大潜力。
4 结 论
本文提出了一种基于强化学习PPO算法的新方法,用于解决上市公司投资组合管理问题。通过使用上市公司的歷史数据进行训练和测试,并与传统投资策略和其他强化学习算法进行比较,本文得出以下结论:
基于强化学习PPO算法的投资组合管理方法在投资回报率方面有显著的改进。在市场不确定性较大时,相对于传统的经验规则或数学模型,该方法能够更好地利用市场信息,动态调整投资策略,投资损失相对较低,这表明PPO算法能够通过学习和优化,适应不断变化的市场环境,并生成更具竞争力的投资决策。
此外,与其他强化学习算法相比,基于PPO算法的投资组合管理方法在实验中取得了较好的绩效。PPO算法的稳定性和鲁棒性使其能够适应高维状态空间和连续动作空间,并且在训练过程中能够避免策略更新过大的问题。
综上所述,基于强化学习PPO算法的上市公司投资组合管理方法在不确定环境下进行投资方面取得了显著的改进,这种方法能够更好地应对复杂的市场环境,并为投资决策提供了一种灵活且有效的策略。未来的研究可以进一步探索PPO算法的参数调优、策略改进和实际应用的可行性,以进一步提升投资组合管理的绩效和可靠性。
主要参考文献
[1]齐岳,黄硕华.基于深度强化学习DDPG算法的投资组合管理[J].计算机与现代化,2018(5):93-99.
[2]韩道岐,张钧垚,周玉航,等.基于深度强化学习的股市操盘手模型研究[J].计算机工程与应用,2020,56(21):145-153.
[3]傅丰,王康.基于深度强化学习SAC算法的投资组合管理[J].现代计算机,2020(9):45-48.
[4]王舞宇,章宁,范丹,等.基于动态交易和风险约束的智能投资组合优化[J].中央财经大学学报,2021(9):32-47.
[5]陈浩,时正华.基于强化学习TD3算法的投资组合管理[J].计算机与数字工程,2022,50(11):2354-2359,2398.
