基于对抗学习的指针仪表自适应读数识别算法
2024-05-03刘林马云飞王荷生李宁
刘林 马云飞 王荷生 李宁
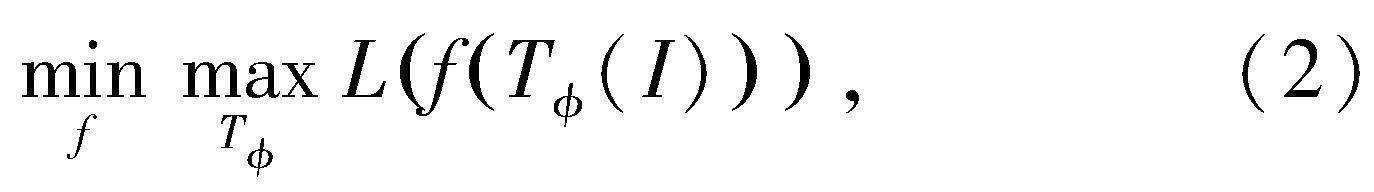
摘要:针对指针仪表采用人工读数方式存在的成本较高、读数不准确、时效性较差的问题,提出一种基于对抗学习的指针仪表位姿自适应读数识别算法。该算法通过目标检测模型识别图像中的指针仪表的位置和姿态,将指针仪表进行校准后并利用数字图像处理技术进行读数识别。为了提升目标检测模型对位姿不同的指针仪表图像的识别效果,本文提出了基于对抗学习的数据增强技术,通过优化搜索模型识别不准的图像旋转角度、平移距离以及缩放比例构造训练数据,提高目标检测模型在指针仪表位姿发生变化时的准确率。以工矿企业中常用的SF6壓力仪表为实验对象,实验结果表明读数识别的误差在1%以内,证明了所提算法的有效性。
关键词:指针仪表;读数识别;目标检测;位姿不变;对抗学习
中图分类号: TP391.41文献标识码: ADOI:10.3969/j.issn.1007-791X.2024.02.007
0引言
随着工业化的快速发展和生产规模的不断扩大,以指针仪表为代表的精密仪器在诸如变电站等与工业生产密切相关的领域中发挥着重要作用。指针仪表具有结构简单、使用寿命长、抗干扰能力强等优点。然而,目前大部分变电站采用人工读数的方式,存在成本较高、读数不准确、时效性较差等问题,因此如何自动、准确识别指针仪表的读数成为工业生产中亟待解决的难题[1-4]。
近年来,随着图像处理与计算机视觉技术的快速发展,利用这些技术解决指针仪表的读数识别问题成为了重要的研究方向。目前国内外已有研究大致可以分为基于传统图像处理技术和基于深度学习方法两大类。传统图像处理方法通常采用边缘检测、霍夫变换、刻度识别、角度法等方式读取指针仪表的读数。文献[1]利用改进的自适应中值滤波方法预处理指针仪表图像,并利用刻度盘转角与刻度之间的线性关系提出基于霍夫变换的指针仪表读数方法。文献[5]提出一种在HSV空间进行指针仪表读数识别的方案,通过对比指针位置不同的两幅图像获取参考仪表盘图像,进而利用角度法进行读数识别。这些基于传统图像处理的方法仍然需要手工设计图像特征,并基于这些特征进行指针仪表的读数识别,因此,这些方法的好坏很大程度上取决于特征设计的好坏,对于不同的应用场景较难适用。另一方面,基于深度学习的方法通过深度神经网络自动检测图像中的指针仪表位置和读数,可以在很大程度上缓解手动设计特征的困难。文献[6]利用典型的目标检测模型RCNN检测图像中指针仪表的位置,进而使用霍夫变换识别指针仪表中指针的位置,得到读数。文献[7]首先针对指针仪表图像进行去噪处理,然后利用目标检测模型Mask-RCNN对指针仪表进行定位和实例分割,最后采用角度法读取指针读数。文献[8]提出基于YOLOv5的指针仪表检测方法截取图像中指针仪表,基于数字图像处理技术进行读数识别。然而,目前基于深度学习的方法泛化能力较差,对于训练过程中没有见到的姿态不同的物体无法准确识别[9-12]。
为了解决上述问题,本文提出基于对抗学习的指针仪表位姿自适应读数识别算法,利用目标检测模型预测图像中指针仪表中心点的位置、大小和另外两个关键点的位置,通过两个关键点的相对位置可以计算出指针仪表的位姿,进而从图像中截取指针仪表区域并对其进行旋转校正,得到水平状态下的指针仪表区域图像,实现对图像中的指针仪表进行自动检测与读数识别。为了提升目标检测模型对位姿不同的指针仪表图像的识别能力,本文进一步提出基于对抗学习的训练方式,将目标检测模型的训练过程建模为最小最大化优化问题,其中内层最大化问题旨在搜索当前模型难以识别正确的指针仪表旋转角度、平移距离与放缩比例,而外层最小化问题在搜索到的“最坏情况”下训练模型,以提升模型在指针仪表位姿发生变化时的准确性。在得到校准后水平状态下的指针仪表图像后,通过数字图像处理技术,从图中提取指针仪表的边缘信息,采用圆环检测与线段检测算法找到指针仪表的指针和刻度线位置,进而准确识别出指针仪表的读数。
本文以变电站中常用的SF6压力仪表为实验对象,通过数据采集与标注训练所提出的位姿不变目标检测模型,在测试阶段可以准确预测图像中指针仪表的位置和姿态,进而得到指针仪表的读数。实验表明,本文所提算法的读数识别误差在1%以内,证明了算法的有效性。
1位姿自适应读数识别算法设计方案
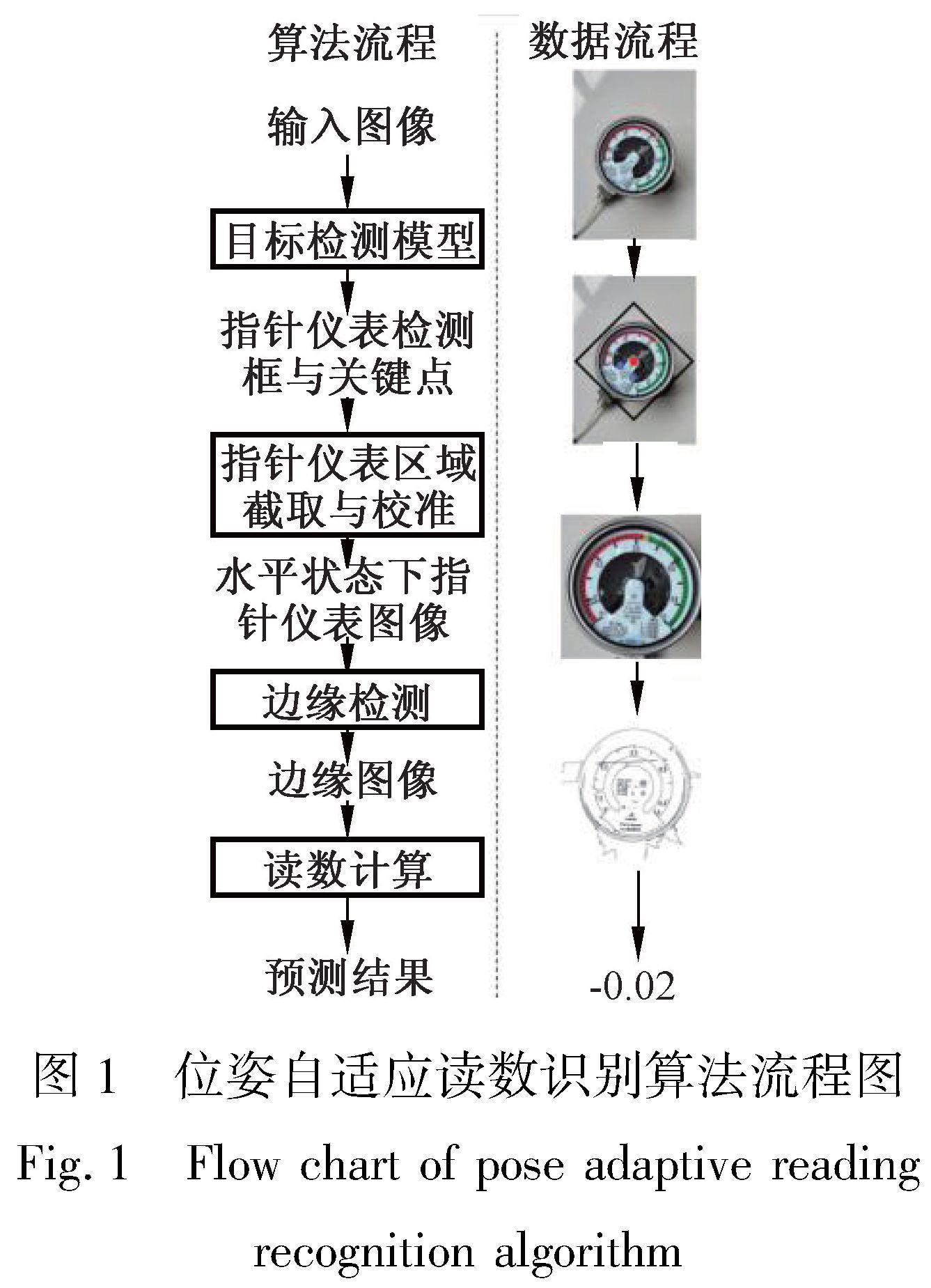
本文所提出的算法流程如图1所示。给定指针仪表在任意视角下的拍摄图像,算法首先利用位姿不变的目标检测模型预测指针仪表中心点的坐标(红点)、指针仪表的大小以及两个关键点的坐标(蓝点),基于关键点的相对位置,计算出指针仪表的位姿,进而得到其包围框(黑框)。从图像中截取包围框中的指针仪表区域并对其进行旋转校正后,可以得到水平状态下的指针仪表图像。进而通过数字图像处理技术提取指针仪表的边缘信息,并采用圆环检测与线段检测算法找到指针仪表的指针和刻度线位置,从而识别出指针仪表的读数。
2位姿自适应读数识别算法
目标检测是计算机视觉中最基础的任务之一,其目标是针对给定的输入图像,从中预测一个或多个物体的位置及其类别[13]。近年来,随着深度学习的不断发展,基于卷积神经网络的目标检测模型被广泛应用于自动驾驶、机器人、缺陷检测等多种实际场景中[14]。一般而言,目标检测可以被分为两大类:单阶段目标检测和双阶段目标检测。以YOLO为代表的单阶段目标检测模型从输入图像中直接预测目标物体的位置和类别,其运行速度较快,更适用于边缘设备[15]。以RCNN为代表的双阶段目标检测模型首先从输入图像中预测出一组候选框,再针对这些候选框进行分类,其速度相比于单阶段目标检测模型更慢,但通常情况下精度较高[16]。针对本文所研究的指针仪表读数识别任务,在一般情况下每张图像中只会出现一个物体(即指针仪表),同时目标检测模型需要被部署到边缘设备中,因此本文采用单阶段目标检测模型。然而,虽然现有目标检测算法性能优越,但是其难以在物体位姿出现变换的情况下准确识别到目标物体。针对这一问题,本文进一步提出基于对抗学习的训练方式提升指针仪表位姿出现变化时的识别精度。
2.1网络结构设计
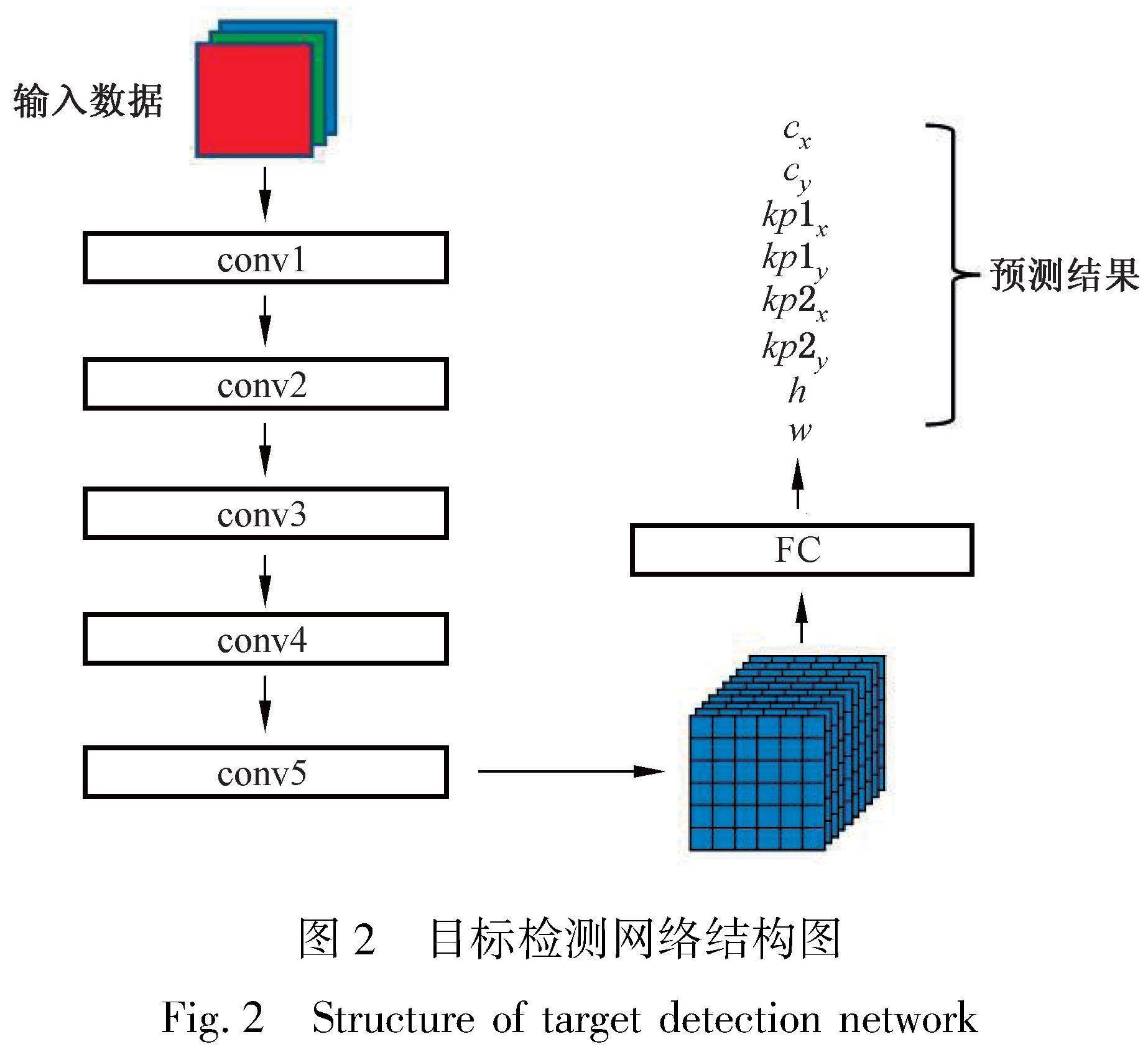
本文设计了基于经典卷积神经网络的目标检测网络结构。为了提升计算速度,网络总共包含5个卷积层和1个全连接层,如图2所示。
如图2所示,对于给定的输入图像,网络首先对图像进行卷积操作,从中提取图像特征。网络中共包含5层卷积层,在每个卷积层后使用归一化操作和激活函数对特征进行处理,自下而上地提取图像中的特征。在卷积层后,网络首先利用池化操作将特征进行压缩,得到图像的向量表示形式,通常为512维的向量,进而再通过1层全连接层将512维图像特征转换为8维预测向量[cx,cy,kp1x,kp1y,kp2x,kp2y,h,w],其中[cx,cy]代表指针仪表中心点在图像中的坐标;[kp1x,kp1y,kp2x,kp2y]为两个关键点在图像中的坐标;[h,w]为指针仪表区域在图像中的宽度和高度,表示其大小。
本文所采用的网络结构设计与一般的目标检测模型存在以下三点不同。首先,本文设计的网络结构只预测一个候选框的位置和大小,而一般的目标检测网络中会输出多个候选框的位置、大小及其对应类别。本文采用简化设计的主要原因是一般的指针仪表图像中仅会出现一个仪表,因此没有必要预测多个物体,采用此设计也可以极大地简化算法流程,提升模型效果。其次,由于仅需要预测一个物体,本文设计的网络结构没有采用锚点的方式,也使得识别过程更加灵活,不需要手动设计锚点大小。最后,与一般的目标检测模型不同,本文设计的网络结构除预测目标物体的中心点坐标和包围框大小外,还需额外预测两个关键点的坐标,这也为后续算法流程中校准指针仪表图像提供了便利。
2.2基于对抗学习的训练算法
深度学习模型通常需要大量的训练数据优化模型参数,从而取得较好的效果。然而,深度学习由于模型容量较大,同时采用数据驱动的学习方式,往往会出现泛化能力不足的问题。例如,文献[9]发现深度神经网络在图像发生旋转或平移变换的情况下准确率显著降低,这也对深度学习的实际应用带来了挑战。对于本文所研究的指针仪表读数识别任务而言,由于摄像机拍摄角度、指针仪表安装位置等因素会发生变化,图像中指针仪表的位姿也会存在差异。因此,如何提升目标检测模型在位姿不同情况下对指针仪表的检测效果是一个极大的挑战。
针对这一问题,本文提出基于对抗学习的训练方式。对抗学习通过优化模型在最差情况下的效果提升模型的稳定性。对于指针仪表读数识别任务,训练的目标是希望在指针仪表位姿发生变化时,目标检测模型均能准确检出目标物体。形式化地,给定输入图像I和位姿变换T,位姿不变目标检测模型f需要达到的目标是f(T(I))=f(I),(1)即模型的预测结果不会随着输入数据的变换发生改变。对于位姿变换T,本文考虑图像旋转rθ(·)、图像平移ta,b(·)和图像缩放sw(·)三种变换,其中θ代表旋转角度、a和b分别代表图像沿两个方向的平移距离、w代表图像缩放比例。因此,位姿变换T可以表示为T(·)=rθ(ta,b(sw(·))),即三种图像变换的组合,其中=[θ,a,b,w]代表变换的参数。
基于上述定义,对抗学习的训练方式可以描述为一个最小最大化优化问题:
其中内层最大化问题通过最大化模型的损失函数L寻找模型无法正确预测的变换T,而外层最小化问题在内层最大化的解的基础上训练目标检测模型f,提升模型在图像变换下的稳定性。与一般的图像变换方式不同,本文提出的对抗学习方法通过寻找最差情况下的图像变换训练模型,能够更加高效地提升模型对于位姿不同的图像的识别能力。通俗意义上而言,对抗学习方式通过寻找模型没有学会的变换进行训练,可以有效提升模型的泛化能力和稳定性。
为求解上述最小最大化优化问题,一般方式为:首先对内层最大化问题进行求解,再利用内层最大化的解求解外层最小化问题。对于本文所研究的目标检测模型,首先通过梯度上升优化图像变换的四个参数=[θ,a,b,w],寻找模型无法识别正确的图像变换;进而利用此变换下的图像训练目标检测网络f得到位姿不变的目标检测模型。
对于训练目标检测网络的损失函数L,其总共包含以下三项:L=Lcenter+λ·Lkeypoint+μ·Lbbox,(3)其中,Lcenter为中心点的预测误差,Lkeypoint为关键点的预测误差,Lbbox为包围框大小的预测误差,λ和μ分别为平衡三项损失的超参数。具体而言,中心点的预测误差定义为Lcenter=(cx-c*x)2+(cy-c*y)2,(4)其中,c*x和c*y為人工标注的中心点的真实坐标。关键点的预测误差定义为Lkeypoint=(kp1x-kp1*x)2+(kp1y-kp1*y)2+(kp2x-kp2*x)2+(kp2y-kp2*y)2,(5)类似地,kp1*x、kp1*y、kp2*x、kp2*y为人工标注的两个关键点的真实坐标。包围框大小的预测误差为Lbbox=(h-h*)2+(w-w*)2,(6)其中,h*和w*为包围框的真实大小。通过优化上述损失函数L,可以使得网络的预测结果和真实标签更加接近,训练后可以准确地提取图像中指针仪表的特征,预测其关键点坐标和包围框大小,得到准确的目标检测结果,进一步帮助后续指针仪表读数的识别。
2.3指针仪表校准
在目标检测模型预测出指针仪表的坐标和包围框大小后,算法流程的下一步是基于检测结果从图像中截取并校准目标物体,得到水平状态下的指针仪表图像。这个过程涉及到计算指针仪表的位姿。从图1中可以看到,所定义的两个蓝色关键点为指针仪表中指针的最小刻度和最大刻度,其应该处于水平状态。因此通过计算这两个关键点的坐标的倾斜角度,即可得到指针仪表包围框的旋转角度。具体而言,通过目标检测模型预测的两个关键点坐标[kp1x, kp1y, kp2x, kp2y],可以计算得到指针仪表的旋转角度为
通过指针仪表的中心位置[cx,cy],其大小[h, w]和旋转角度α,就可以很容易地得到其包围框的位置和旋转角度,进而从图片中直接截取包围框中的部分,就可以得到水平状态下的指针仪表图像。
2.4读数计算
通过目标检测算法得到水平视角下的指针仪表图片之后,算法的第二步是利用数字图像处理中的技术识别指针仪表的读数。从图1中可以看到,指针仪表的指针和刻度线特征较为隐蔽,采用基于深度学习的算法难以精确估计指针仪表的读数,会带来较大的误差。因此,本算法采用边缘检测算法从图像中提取边缘信息,并进一步利用圆环检测和线段检测算法识别指针和刻度线的位置,就能够更加准确地读取指针仪表的数字。
步骤1:采用自适应的边缘检测算法得到指针仪表的边缘特征。由于指针仪表的图像为彩色三通道图片,首先对图像进行二值化处理,将其转变为黑白图像。一般情况下,物体的边缘会出现像素值明显的变化,因此可以通过一个像素与其周边的像素值的差异判断出其是否是物体的边缘。
步骤2:通过目标检测算法检测到指针仪表对应的图片,并将其缩放为统一大小后,指针仪表的大小是基本固定的。因此通过找到图中的圆弧以及圆心,就可以得到刻度线外的圆弧。对于圆环检测,本文采用广泛使用的霍夫圆变换算法。首先对于边缘检测得到的结果,计算其中每个边缘点的切线,然而计算其垂直线。此后,通过判断这些垂直线是否穿过图像中的每个点找到圆心。在实际情况中,可能会出现计算不准出现偏差的情况,通过高斯滤波可以在一定程度上缓解此问题。在得到圆心后,计算圆心到边缘点的距离,即为圆环的半径。
步骤3:在此圆的内侧,有11个刻度线,分别是-0.1、0、0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9。本文采取顺时针扫描法来找到上面的11个短的刻度线。以霍夫算法找出的圆心为中心,以垂直向下为起点,顺时针扫描整个圆面,凡是指向圆心的20个像素点左右的黑色线段,即为刻度线。第1个刻度线,即为-0.1,最后一个刻度,即为0.9。在找出刻度线的过程中,也可以找出指针的位置,与刻度线相比,指针的线更长,因此判断出指针的位置。根据指针的位置,以及它处于哪两个刻度线之间,进而计算出指针指向的位置,得到指针仪表的数字。
3实验与分析
3.1硬件平台
硬件平台采用Raspberry Pi Zero2W嵌入式控制器。该控制器体积小、功耗低、性能强、价格低廉,可以搭载Linux操作系统适合在指针仪表的识别的现场应用。获取指针表盘的摄像头采用广角500万相素的树莓派专用摄像头。
3.2数据收集与标注
对变电站常见的SF6压力表,获取了不同角度、不同读数的500副指针仪表图像。在得到图像后,首先通过人工标记的方法对每幅图像中指针仪表的关键点和包围框进行标注。然后将这500张图像按照9∶1的比例分为450张训练图像数据和50张测试图像数据。使用提出的基于关键点的目标检测模型在这450张训练数据上进行模型训练。训练结束后,在50张测试数据集预测指针仪表的读数,验证算法有效性。
3.3实验结果与分析比较
本文采用绝对误差作为评估指标。对于每张指针仪表图像,首先人工标注指针的读数作为真实值,然后分别利用本文所提出的对抗算法以及结合图像预处理和霍夫圆算法[17],对数据进行预测和识别,用于评估算法的准确性。在对上述50个测试数据测试完成后发现,对抗算法预测误差在0.01以内,相较于指针仪表的读数范围[0,1],仅有1%以内的误差。而使用霍夫圆算法的预测数据,其误差要大得多。
图3展示了其中10张指针仪表照片。表1展示了这10个数据基于两种算法的预测结果。
可见基于对抗学习的指针自适应识别算法优于霍夫圆算法。另外,本文所提出的方法选取了不同位姿下的图片进行水平处理,使得处理结果更具有泛化性,更符合实际应用检测场景。
4结论
针对指针仪表自动快速读数识别的难点,本文提出了基于对抗学习的指针仪表自适应读数识别算法。针对指针仪表的安装位姿有较大随机性的特点,采用了对抗学习中的数据增强技术,通过优化搜索模型识别不准的图像旋转角度、平移距离以及缩放比例构造训练数据,提高目标检测模型在指针仪表位姿发生变化时的准确率。
实验以工矿企业中常用的SF6压力仪表为研究对象,实验结果表明读数识别的误差在1%以内,并与图像预处理和霍夫圆检测的方法作了比较,证明了所提出算法的有效性。
参考文献
[1] HAN J, LI E, TAO B, et al. Reading recognition method of analog measuring instruments based on improved hough transform [C]//International Conference on Electronic Measurement & Instruments, Chengdu, China, 2011: 337-340.
[2] YANG B, LIN G, ZHANG W. Auto-recognition method for pointer-type meter based on binocular vision[J]. Journal of Computers, 2014, 9(4): 787-793.
[3] 侯玥,王开宇,金顺福.一种基于YOLOv5的小樣本目标检测模型[J].燕山大学学报,2023,47(1):64-72.
HOU Y, WANG K Y, JIN F S. A few-shot object detection model based on YOLOv5[J]. Journal of Yanshan University,2023,47(1):64-72.
[4] 韩绍超,徐遵义,尹中川,等.指针式仪表自动读数识别技术的研究现状与发展[J]. 计算机科学,2018, 45(6):54-57.
HAN S C, XU Z Y, YIN Z C, et al. Research review and development for automatic reading recognition technology of pointer instruments[J]. Computer Science, 2018, 45(6):54-57.
[5] 张志锋,王凤琴,田二林,等.基于机器视觉的指针式仪表读数识别[J].控制工程, 2020, 27(3):581-586.
ZHANG Z F, WANG F Q, TIAN E L, et al. Machine vision based reading recognition for a pointer gauge[J]. Control Engineering of China, 2020, 27(3):581-586.
[6] LIU Y, LIU J, KE Y. A detection and recognition system of pointer meters in substations based on computer vision[J]. Measurement, 2020, 152(C): 107333.
[7] LIU J, WU H, CHEN Z. Automatic identification method of pointer meter under complex environment[C]//12th International Conference on Machine Learning and Computing, Shenzhen, China, 2020: 276-282.
[8] 王康,陆生华,陈潮,等.基于YOLOv5的指针式仪表检测与读数识别算法研究[J].三峡大学学报(自然科学版),2022,44(6):42-47.
WANG K, LU S H, CHEN C, et al. Research on detection and reading recognition algorithm of pointer instrument based on YOLOv5[J]. Journal of China Three Gorges University (Natural Sciences),2022,44(6):42-47.
[9] ENGSTROM L, TRAN B, TSIPRAS D, et al. Exploring the landscape of spatial robustness[C]//International Conference on Machine Learning, Long Beach, USA, 2019: 1802-1811.
[10] 王明,崔冬,李刚,等.融合判别区域特征与标签传播的显著性目标检测[J].燕山大学学报,2019,43(5):455-461.
WANG M, CUI D, LI G, et al. Salient object detection by integrating discriminative region feature and label propagation[J]. Journal of Yanshan University,2019,43(5):455-461.
[11] BAY H,TUYTELAARS T,GOOL L V.SURF: speeded up robust features [J].Computer Vision & Image Understanding,2006,110(3):404-417.
[12] CALONDER M,LEPETIT V,STRECHA C,et al. BRIEF:binary robust independent elementary features[C]//European Conference on Computer Vision, Grete, Greece,2010:778-792.
[13] ZOU Z, CHEN K, SHI Z, et al. Object detection in 20 years: a survey[J]. Proceedings of the IEEE, 2023, 111(3): 256-276.
[14] LECUN Y, BENGIO Y, HINTON G. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
[15] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]//IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA,2016: 779-788.
[16] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[C]// Advances in Neural Information Processing Systems, Montreal, Canada,2015: 1-12.
[17] 許立辉,杨开元,徐东东.基于计算机视觉的指针仪表盘识别算法与系统设计[J].仪器仪表用户,2023,30(2):56-60.
XU L H, YANG K Y, XU D D. Recognition algorithm and system design of pointer panel based on computer vision[J]. Instrument Users, 2023, 30(2): 56-60.
Adaptive reading recognition algorithm of pointer instrument
based on adversary learning
Abstract: To address the problems of high cost, inaccuracy, and low efficiency in manual reading of pointer instruments, a pose-invariant adaptive reading recognition algorithm of pointer instrument based on adversarial learning is proposed. This algorithm utilizes an object detection model to identify the position and attitude of the pointer instrument in the image, calibrates the pointer instrument and uses digital image processing technology for reading recognition. In order to improve the recognition effectiveness of the object detection model on pointer instrument images with different poses, a data augmentation technology based on adversarial learning is proposed, which constructs training data by optimizing rotation angles, translation distances, and scaled ratios of images that lead to inaccurate recognition, to improve the accuracy of the object detection model when the pointer instrument′s pose changes. The research focuses on the SF6 pressure instrument commonly used inindustrial and mining enterprises, and experimental results show that the error of reading recognition is within 1%, which proves the effectiveness of the proposed algorithm.
Keywords: pointer instrument; reading recognition; object detection; pose-invariant; adversarial learning
