多特征加权集成模型在用户购买预测中的研究
2024-04-27胡静静
胡静静,樊 军
(新疆大学机械工程学院,新疆 乌鲁木齐 830047)
1 引言
随着互联网技术与电子商务快速发展,线上消费越发普遍,消费者规模不断扩大,线上消费平台存留了海量用户、商品及用户-商品交互行为等数据[1]。通过这些数据分析和预测用户的购买行为,可为用户个性化推荐商品,更快速准确地满足用户对商品的需求,为企业识别和定位潜在客户、制定营销策略、调节商品货量等提供重要参考信息,有效提高企业效益[2-3]。
用户购买行为预测为二元分类任务[4],即从用户、商品、用户-商品交互等数据中挖掘出影响购买行为的因素,运用统计学、机器学习等方法提取特征并进行特征工程处理,再训练分类模型,调节模型参数,用训练好的模型预测用户购买行为。作为人工智能领域的典型问题,逻辑回归(Logistic Regression,LR)[5]、随机森林(Random Forest,RF)[6]、递归神经网络(Recurrent Neural Network,RNN)[7]等模型已广泛用于用户购买预测。文献[8]在提取用户特征、品牌特征的基础上添加行为时变特征,采用LR模型预测用户购买行为。文献[9]量化商品和用户行为数据提取静态特征,结合长短期记忆网络(Long Short-Term Memory,LSTM)提取行为动态特征,采用RF模型预测用户购买行为。文献[10]在原有特征群的基础上提出二次组合特征的构建方法,用不同特征组合建立对照检验模型,优化了基础特征群。文献[11]从用户、商品、商品品类、用户-商品交互和行为时间五方面提取特征,使用贝叶斯(Naive Bayes,NB)模型预测用户购买行为。文献[12]从商品、商品类别和用户行为三方面进行特征提取,利用梯度提升决策树(Gradient Boosting Decision Tree,GDBT)模型预测用户购买行为,得到较高的F1值。由此可见,特征和预测模型不同效果也不同。Stacking 集成模型能结合不同算法优势提升预测性能,根据用户-商品交互等数据构造3个特征群,建立了针对此种业务场景的特征工程,并提出一种基于Stacking的加权异质集成模型,在真实数据集中可得到较高F1值。
首先,对原数据集进行数据清洗、统计分析等预处理;其次,采用函数拟合、计数、加和、均值、比值、二次组合衍生等方法提取静态和动态特征,通过特征工程产生有效子特征集。
再选取5种分类算法分别对子特征集进行训练并优化算法参数,将其作为基分类器,获取这5种基分类器的性能排序信息。
最后,将性能排序信息转化为一组约束,加入Stacking集成模型的第二层LPBoost算法[13]中,求解LPBoost算法目标规划问题得到基分类器更佳组合权重,构建基于Stacking的加权集成分类预测模型。选用阿里云天池官方发布的用户行为数据集进行实验验证,以精确度、召回率、F1值为评估指标,实验结果表明所提方法优于对比方案。
2 特征工程
用户购买预测的特征工程包括数据预处理、构造提取特征、特征缩放、特征编码及特征选择部分,每部分都有多种方法。
2.1 数据预处理
将原数据集整理成以属性字段为主键的数据集。根据样本中相关属性的关系推理出缺失值,如商品类别属性缺失而商品属性存在的样本可根据其他样本推理得到商品类别,如表1所示。删除缺失数据过多的属性;删除缺失一半及以上属性的样本;其他无法推理得到的属性缺失时参考其余样本进行人工随机插补,如表1所示。过滤用户-商品间存在大量点击行为却无或者存在少量收藏、加购物车、购买等行为的非正常数据,如表2所示。最后,统计分析数据集,利用图表可视化数据,探索数据样本分布情况及随时间发生的变化。

表1 缺失属性推理实例Tab.1 Examples of Reasoning for Missing Attributes

表2 过滤方法说明Tab.2 Description of Filtration Method
式(1)、式(2)如下:
式中:Click—点击次数;Buy—购买次数;w、δ根据具体数据集取。
2.2 特征构造
一般原数据集的特征维度过低,不能全面、详细地描述用户行为。为得到好的预测效果,在原始特征的基础上,利用函数拟合、计数、加和、均值、比值、设置非数值类别型特征、二次组合衍生等方法进一步构造出3个特征群,分别为基础特征群、交互特征群和衍生特征群。在一个周期内特征的构造方法及所属,如表3所示。

表3 特征构造Tab.3 Feature Construction
2.3 特征缩放
对于连续型特征,单位和值的范围可能存在差异,导致特征无法在模型中充分表达,需要对其进行无量纲化缩放。为使缩放更为鲁棒且利于模型收敛,采用标准化缩放方法,如式(3)所示:
定义1:x为数据集表示样本i的特征j:
式中:z—缩放后的特征集;mean—均值;std—标准差。
2.4 特征编码
算法要求数据类型是数值型。对需要离散化的年龄等数值型特征,采用有监督离散中最小描述长度原则(Minimum Description on Length Principle,MDLP)进行离散。对无序非数值型离散特征采用独热编码,有序非数值型离散特征采用标签编码。
2.5 特征选择
构造出的特征维度过高时须进行特征选择,去除不相关或冗余特征,从特征集中挑出最优特征子集,减少特征数量,提高模型准确度并降低模型运行时间。为使特征选择准确度高、鲁棒性佳且易于进行,采用嵌入法(Embedded)中基于树模型的方法,选择RF模型进行特征选取。
特征工程的整体流程,如图1所示。

图1 特征工程Fig.1 Feature Engineering
3 建立加权异质集成模型
基于文献[14],提出一种为Stacking集成模型中基分类器分配更优权重的方法,建立加权异质集成模型,此模型可有效提高预测效果。
3.1 LPBoost算法赋权
LPBoost算法是推断基分类器权重向量的典型方法,通过最大化训练样本的最小间隔来提高算法的推广性能。给定一组训练好的基分类器和一个训练(或验证)集,求解其目标规划问题即可得到基分类器权重向量。LPBoost算法的线性规划形式,如式(4)所示:
式中:ρ—训练样本的最小间隔,如式(5)所示:
式中:Lm(m=1,…,M)—基分类器;M—分类器个数;β(m)—基分类器权重,则βT=[β(1),β(2),…,β(M)]T。xn—训练样本,yn—样本类标,Hnm=Lm(xn),Hn:—所有基分类器对样本的分类结果。
3.2 模型建立
为进一步赋予Stacking集成模型中基分类器更佳的组合权重,提取数据集上真实可靠的基分类器性能排序信息,性能越佳权重越大,将此信息转化为一组约束,加入Stacking集成模型的第二层元学习器LPBoost算法中,求解目标规划问题得到更优的基分类器组合权重。构建模型的具体流程如下:
(1)采用支持向量机(SVM)、朴素贝叶斯(NB)、C4.5决策树、逻辑回归(LR)和随机森林(RF)算法分别在数据集上训练,调节算法参数,将其作为基分类器,获取这5种基分类器在数据集上的性能排序信息;
(2)将数据集划分为训练集、验证集和测试集,令(1)中5种基分类器初始化后依次在训练集上训练并调节参数,然后在验证集上运行训练好的基分类器,每个验证实例上所有基分类器的分类结果组成一个新特征向量,由此获得求解分类器权重所需的新训练集;
(3)基于(2)中新训练集和训练好的5种基分类器,将(1)中得到的性能排序信息转化为一组约束,加入LPBoost算法中,求解目标规划问题即可得到5种基分类器更优的权重组合。优化式(6)如下:
式中:β(m)—基分类器更优权重,可知L1性能最优,L5性能最差。
(4)根据优化式(6)的加权方法建立基于Stacking的加权异质集成模型,对此模型进行实验验证并与其他集成方法对比。
模型伪代码如下:
ξ1,ξ2,…,ξM为(1)中提出的支持向量机(SVM)、朴素贝叶斯(NB)、C4.5决策树、逻辑回归(LR)和随机森林(RF)算法,ξ为LPBoost算法,x为特征集。
4 实验验证
4.1 数据描述
选用阿里云天池官方发布的用户行为数据集,此数据集为2014年11月18日至2014年12月18日的用户-商品行为日志,包括用户在商品全集上的行为数据集和商品子集两部分,如表4、表5所示。抽取8000名用户在商品全集上的行为数据及商品子集进行实验验证,其中用户行为数据集共9825248条日志,商品子集共418231条数据。
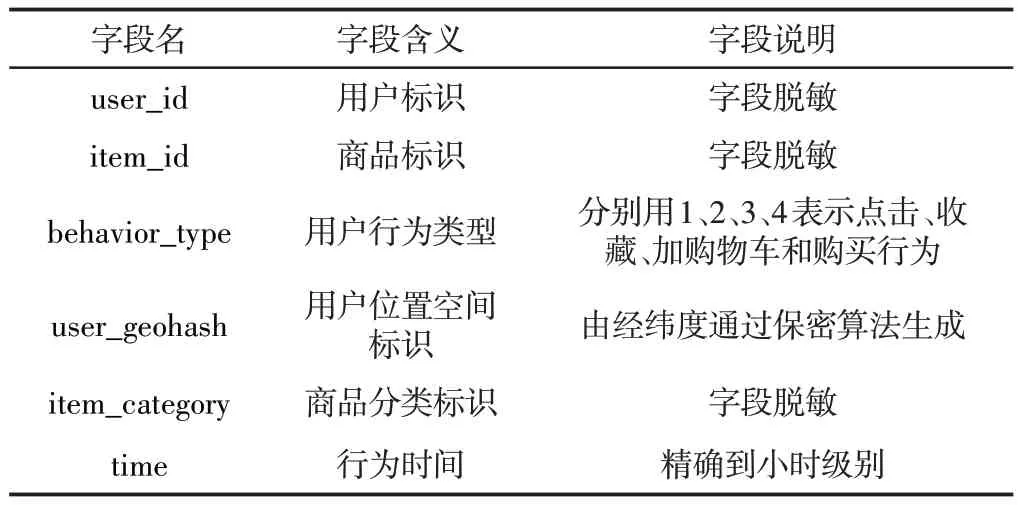
表4 用户行为数据集Tab.4 User Behavior Data Set

表5 商品子集Tab.5 Product Subset
定义2:U为用户集合,C为商品类别集合,I为商品全集,P为商品子集且P属于I,D为用户对商品全集的行为数据集合。
实验目标:利用D预测2014年12月18日U中用户对P中商品的购买行为。
4.2 评价指标
针对二分类问题,采用精确度(Precision)、召回率(Recall)及F1值为评价指标,F1值为精确度和召回率的加权调和均值,将其作为主要指标。
4.3 实验结果
4.3.1 预处理阶段
整理原始数据集。用户地理位置数据缺失较多,直接删除此属性,根据表1填补缺失值,删除缺失一半及以上属性的数据。根据表2进行过滤操作,δ设置为130,ω设置为180。最后统计分析数据集,点击、收藏、加购物车及购买4种行为分布,如图2所示。
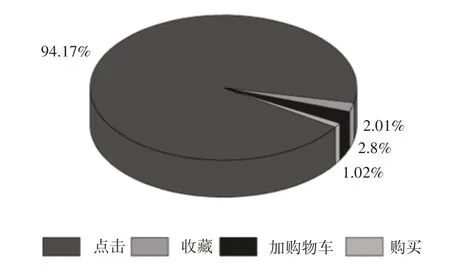
图2 行为分布Fig.2 Behavioral Distribution
图2表明购买正样本远少于未购买负样本,数据集存在类不平衡问题。且发现用户对商品点击、收藏、加购物车后(7~10)日内不购买,后期基本也不会购买。用户对商品子集点击、收藏、加购物车行为发生后各时长下购买量,表明用户购买意愿的强烈程度随时间衰减,如图3所示。
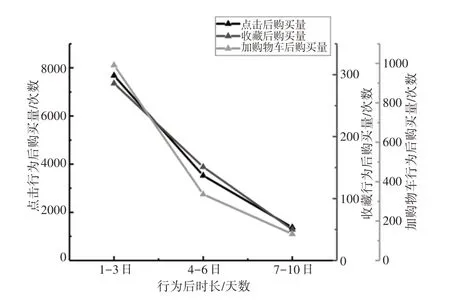
图3 用户行为衰减Fig.3 User Behavior Attenuation
则以10日为一个周期,第(1~9)日数据用于提取特征,第10日数据作为标签。一个周期内正样本约314个,负样本数约为正样本的300倍,对正样本进行SMOTE(Synthetic Minority Oversampling Technique)过采样,对负样本进行随机欠采样,使正负样本比例为1:5,采样结果正样本2200个,负样本11000个。采用时间序列滑动窗口采样方法提取更多样本以提高预测效果,鉴于数据集规模及模型要求,在31日的时间序列下,按15:6:1的比例将数据集划分为训练集、验证集和测试集,如图4所示。
图4 时间序列滑窗采样Fig.4 Sliding Window Sampling of Time Series
4.3.2 特征构造阶段
据图3知,一个周期内用户在预测日的购买意愿强烈程度随时间向前衰减,则构造特征设定预测日前12h、前1天、前2天、前3天、前6天、前9天这6种时间粒度。一个周期内基础特征群构造情况,如表6所示。共构造出442个特征。其中U属性内的动态特征使用S型(Slogistic1)函数拟合用户随天数累计的行为量,描述用户活跃程度,行为量逐渐减少时表明用户活跃度越来越低,4个用户实例,如图5所示。

图5 用户行为拟合图Fig.5 User Behavior Fitting Graph

表6 基础特征群特征构造Tab.6 Feature Construction of Basic Feature Group
交互特征群共构造出276个特征,如表7所示。衍生特征群共构造出208个特征,如表8所示。

表7 交互特征群特征构造Tab.7 Feature Construction of Interactive Feature Group
3个特征群共构造出926个特征,利用随机森林(RF)进行特征选择后的前12个特征,如表9所示。

表9 前12个特征列表Tab.9 List of the Top 12 Features
4.3.3 模型测试阶段
Stacking集成模型中基分类器参数设置,如表10所示。

表10 模型参数设置Tab.10 Model Parameter Setting
不同特征群下,所提加权方法、多数投票法和LPBoost方法实验结果即精确度、召回率、F1值,如图6~图8所示。
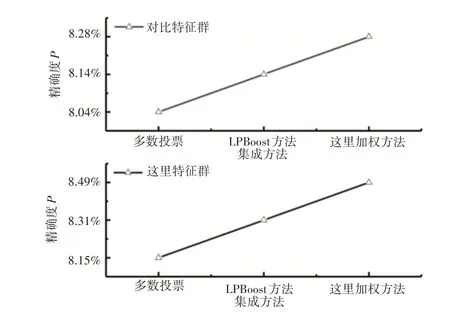
图6 不同特征群下模型精确度Fig.6 Model Precision Under Different Feature Groups
5 结论
用户线上购买行为预测有助于实现精准营销,具有极大的现实意义和经济价值。根据用户-商品交互等数据构造了3个特征群,制定了针对此种业务的特征工程,并提出一种基于Stacking的加权集成模型,显著提高了预测效果。由图6、图7、图8可知,这里所构造的特征群优于对比特征群,这里所提模型的F1值为8.51%,优于对比模型。由于预测只针对存在交互的用户-商品对,但预测日仍存在大量前期无交互而当天购买的样本,导致F1值大大降低,但F1值达到8.51%对于现实场景已是不错的结果,充分说明了这里所提方法的有效性。
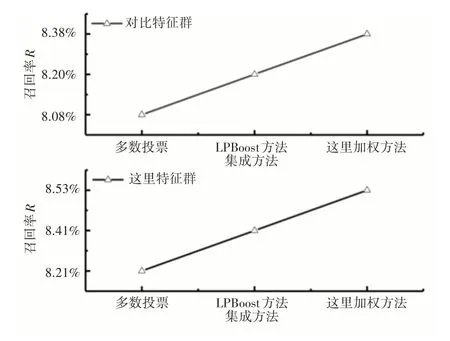
图7 不同特征群下模型召回率Fig.7 Model Recall Rate Under Different Feature Groups

图8 不同特征群下模型F1值Fig.8 Model F1 Value Under Different Feature Groups
