基于Transformer 的矿井内因火灾时间序列预测方法
2024-04-22王树斌王旭闫世平王珂
王树斌,王旭,闫世平,王珂
(1.陕煤集团神木柠条塔矿业有限公司,陕西 榆林 719300;2.中国矿业大学 计算机科学与技术学院,江苏 徐州 221116)
0 引言
矿井火灾是煤炭开采过程中的一种严重的安全事故,不仅会造成人员伤亡和巨大的财产损失,还会对环境和社会造成不可逆转的影响。因此,对矿井安全状况进行有效监测,对火灾风险的发展趋势进行精准预测,是煤炭安全生产的重要课题,也是保障矿工生命安全和提高生产效率的必要措施。
矿井火灾分为外因火灾和内因火灾。内因火灾是由于煤炭或其他易燃物质自身氧化蓄热并发生燃烧而引起的火灾。当前监测矿井安全状况和预测矿井内因火灾发展趋势的主要方法[1-2]包括温度监测法[3-5]、烟雾监测法、可见光图像监测法[6-8]、红外图像监测法[9]、多参数融合监测法[10]、气体分析法。其中,温度监测法、烟雾监测法通过传感器监测矿井温度、烟雾,可见光图像监测法、红外图像监测法分别通过可见光摄像头和红外摄像头监测矿井可见光、温度,实现火灾监测,这些方法并不能有效地预测早期火灾。多参数融合监测法对矿井生产中的多种参数进行综合分析,该方法虽具有较高的预测精度,但存在算法难度大、成本高的弊端。气体分析法通过传感器监测矿井火灾产生的标志性气体的浓度变化,对矿井内因火灾进行有效预测。
煤体在燃烧的各个时期都存在气体浓度的变化,通过气体分析法可有效监测火灾的整个过程,同时气体分析法所使用的算法复杂度较小,成本较低。许多学者采用气体分析法对矿井火灾进行了广泛研究。魏超等[11]依据煤自燃过程中各阶段释的放标志性气体不同的特点,以及采空区三带静态分布理论,给出了定性和定量判断采空区煤自然发火状况的方法,设计了基于激光气体分析的矿井火灾预警装置。侯毛伟等[12]采用光纤气体传感器监测煤矿井下一氧化碳与氧气等自然发火标志气体浓度,实现了全光纤火灾预测预警及综合监测,提高了煤矿安全生产系数。陈雅等[13]将特定气体作为煤矿自燃的危机征兆,运用BP 神经网络建立了煤矿内因火灾预测模型,该模型具有通用性、扩展性和高效性等优点。刘永立等[14]利用采空区遗煤氧化过程产生的气体构建模型数据集,通过调整长短时记忆(Long Short Term Memory,LSTM)模型时间步长和迭代次数,分析模型超参数对预测遗煤温度的影响,提高了煤矿火灾的预测精度。以上方法在预测矿井内因火灾中起到了一定的作用,但煤体燃烧是一个阶段性过程,过程中产生的气体浓度会随着时间动态变化,呈现一定的趋势性和周期性,通过分析时间序列的趋势性和周期性,可对序列的未来走向进行预测。因此,将时间序列预测引入气体分析法。
时间序列预测是一种利用历史数据来预测未来数据的方法,在各行各业有着广泛应用。常见的时间序列预测算法在处理单一变量的简单数据时有着较好的预测效果,但在预测数据量大的多变量数据时往往不能有效捕捉数据之间的长期依赖关系。而Transformer 算法是一种基于自注意力的神经网络模型,它不使用循环连接来处理序列数据,可直接访问整个输入序列,直接处理非平稳数据,通过自注意力机制来计算每个时间步骤与其他时间步骤的相关性,从而捕捉到序列之间的长期依赖性和周期性。由于不使用循环连接,Transformer 还可进行并行化训练,且能更好地处理噪声和异常值。通过查阅大量参考文献,发现Transformer 算法在多领域得到了广泛应用[15-20],但在煤矿火灾预测方面的研究较少。针对上述问题,本文提出基于Transformer 的矿井内因火灾时间序列预测方法。首先,采用Hampel滤波器和拉格朗日插值法对数据进行预处理,以提高数据的质量和可用性。然后,基于Transformer 算法建立矿井内因火灾时间序列预测模型。最后,通过实验验证该模型的可靠性。
1 矿井内因火灾预测模型的建立
1.1 基于Transformer 的矿井内因火灾预测模型
基于Transformer 的矿井内因火灾预测模型包含数据预处理、Transformer 算法、数据预测3 个主要模块,如图1 所示。采用Hampel 滤波器和拉格朗日插值法对数据进行预处理,将预处理后的数据输入Transformer 算法模型进行训练,采用训练后的Transformer 算法模型对测试数据进行预测。
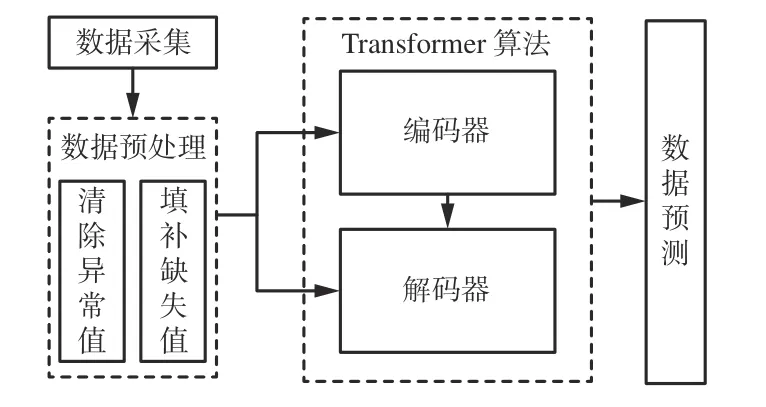
图1 基于Transformer 的矿井内因火灾预测模型Fig.1 Mine internal caused fire prediction model based on Transformer
1.2 数据预处理
实验所用数据来自于井下气体传感器。在实际生产中,传感器经常会受到各种因素(如电磁、机械振动、温度变化等)的干扰,易出现与真实值偏差较大的异常值。这些异常值会影响数据的质量和可信度,从而降低模型的准确性和稳定性。此外,当井下气体传感器出现故障时,也会导致一段时间的真实值缺失。这些缺失值会造成数据的不完整和不连续,从而增加模型的复杂度和不确定性。因此,要对实验数据进行预处理,以提高数据的质量和可用性。
式中:yi为滤波后的第i个观测值;xi为原始数据中的第i个观测值;mi为以xi为中心的窗口内数据的中位数;h为阈值参数,用于控制异常值检测的灵敏度,h=3;si为以xi为中心的窗口内数据的绝对偏差中位数;S为符号函数;c为常数,c=1.482 6;M为中位数函数;n为窗口大小。
采用拉格朗日插值法对缺失值进行填补,对于给定的k+1 个点 (x0,y0),(x1,y1),···,(xk,yk),找到一个次数不超过k的多项式L(x),使得L(xi)=yi对于所有i(i=0,1,···,k)成立。
式中:ℓj(x) 为拉格朗日基本多项式,在xj点处取值为1,而在其他点xi(i≠j)处取值为0;x为原始数据的观测值。
1.3 Transformer 时间序列预测算法
Transformer 算法不使用传统的循环神经网络或卷积神经网络,而是完全依赖于自注意力机制来计算输入和输出,自注意力机制可捕捉序列中任意2 个位置之间的依赖关系,而不受距离的限制。
将输入序列中每个位置映射为查询向量Q、键向量K和值向量V,并通过点积运算和加权求和得到一个输出向量。
式中:A为注意力;softmax 为归一化函数;dK为键向量的维度。
多头自注意力机制是在自注意力机制的基础上,将输入序列中每个位置的向量分成H个子向量,分别进行自注意力计算后拼接,得到一个完整的输出向量。多头自注意力机制可使模型在关注不同子空间的同时,增加模型的多样性和表达能力。
SourceBuf:存放未加密数据的缓冲区首地址;CodeLength:数据字节数;DestBuf:存放加密后数据的缓冲区首地址;
Transformer 算法模型由编码器和解码器组成,如图2 所示,每部分包含多个相同的层,每层又包含多头自注意力子层和前馈神经网络子层。编码器的输入为过去时刻的协变量序列x1:(t-1)={x1,x2,···,xt-1}和目标变量序列y1:(t-1)={y1,y2,···,yt-1},其中t为预测开始的时刻。解码器的输入为未来时刻的协变量序列xt:T={xt,xt+1,···,xT},其中T为预测的截止时刻。模型的输出为未来时刻的目标变量序列yt:T={yt,yt+1,···,yT}。序列数据因其时序性不能直接输入模型,需经过编码处理后才能输入,编码分为数据编码和位置编码,它可增强Transformer 模型在时间序列预测任务上的表现。
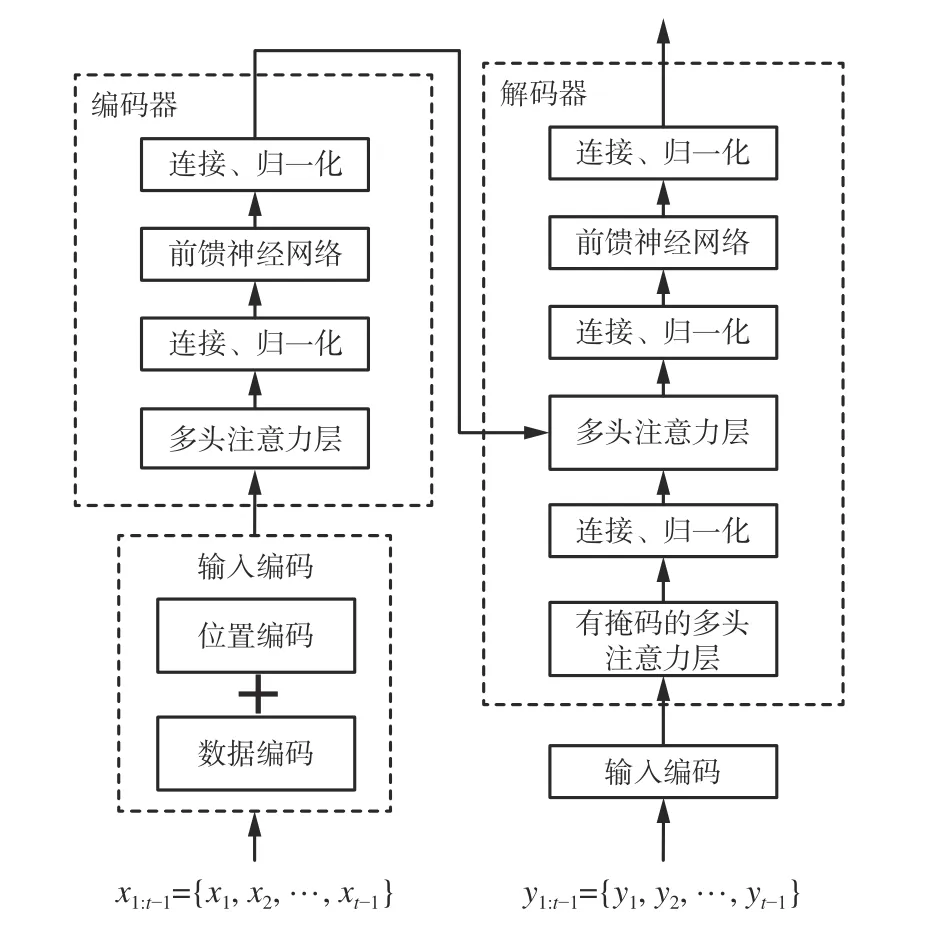
图2 Transformer 算法模型Fig.2 Transformer algorithm model
编码器的作用是将输入序列转换为一个高维的向量表示。编码器由N个相同的层堆叠而成,每层包括多头自注意力子层和前馈神经网络子层。编码器中第I层的多头注意力子层的输出为
式中:MI为多头输出;C为连接函数;headH为第H个头的输出;WO为拼接矩阵,用于将多个头的输出子向量拼接起来,得到一个完整的输出向量;headi为第i个头的输出;为多头注意力子层的可学习参数矩阵,用于将输入序列中每个位置的向量映射为Q,K,V。
前馈神经网络子层的作用是对每个位置的向量表示进行非线性变换,增加模型的表达能力。编码器中第I层的前馈神经网络子层的输出为
式中:max 为ReLU 激活函数;W1,W2为可学习的参数矩阵;b1,b2为可学习的偏置向量。
解码器的作用是根据编码器的输出和已生成的目标序列来预测下一个目标序列。解码器由N个相同的层堆叠而成,每层包括多头自注意力子层、编码器-解码器注意力子层和前馈神经网络子层。解码器的多头自注意力子层使用一个掩码来遮盖未生成的位置。带掩码的自注意力为
式 中 Mask 为掩码操作。
解码器中第I层的多头自注意力子层的输出为
式中AMask为解码器多头注意力子层第i个头的自注意力。
编码器-解码器注意力子层的作用是计算已生成的目标序列中每个位置与编码器输出中每个位置的相关性。解码器中前馈神经网络子层的作用与编码器中的相同。
2 实验及结果分析
2.1 标志性气体的选取
煤体自燃一般要经过潜伏期(即吸附氧化)、自热期(即氧化聚热)、发展期(即着火临界阶段)和发生明火4 个阶段(个别煤种不一定经过这4 个阶段),不同阶段产生的主要气体有所不同[21]。以陕煤集团柠条塔煤矿井下火灾预警系统监测的数据为例,该预警系统监测了CO,O2,N2,CO2,C2H2,C2H4,C2H67 种气体浓度。其中,C2H4主要产生于自热期,C2H2主要产生于发展期,而CO 产生于煤体燃烧的整个过程,因此选取CO 作为预测矿井内因火灾的标志性气体。
2.2 评价指标
选择平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Square Error,RMSE)作为模型预测精度的评价指标。MAE 和RMSE 可衡量预测值和真实值之间的误差大小。MAE 和RMSE的值越小,说明预测值与真实值的差距越小,模型的预测精度越高。
式中:μMAE,μRMSE分别为平均绝对误差、均方根误差;m为样本总数量;a为样本数量;ya为真实值;为预测值。
2.3 模型验证和实例分析
本文选取陕煤集团柠条塔煤矿S1206 回风隅角火灾预警的束管数据作为实验数据。将80%的数据作为训练样本,20%的数据作为测试样本,根据数据维度和数据大小,确定了矿井内因火灾预测模型中编码器和解码器的初始参数,多头注意力头数为5,隐藏层大小为128,内部层大小为64,前馈神经网络激活函数为ReLU。
时间步长为30、预测长度为10 时部分实验结果如图3 所示。MAE 为0.012 4,RMSE 为0.015 6。可看出Transformer 算法通过自注意力机制有效地捕捉了标志性气体序列的周期性和趋势性,预测误差在可接受范围内,说明该模型能够较好地建立数据之间的长期依赖性并进行较为精确的预测。
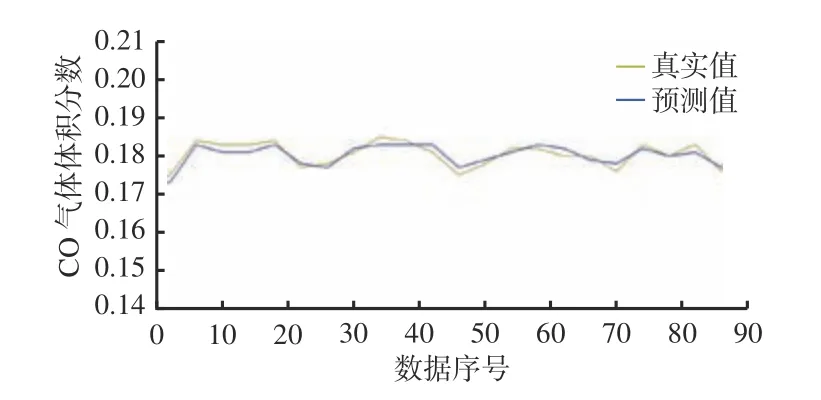
图3 测试样本中预测值与真实值的拟合曲线Fig.3 Fitting curve of predicted values and true values in test samples
煤体自燃的相关气体由同一个系统产生,相互之间存在一定关联性,若仅对CO 进行单一变量的预测,预测结果不够精确。因此选取CO 作为目标变量,O2,N2,CO2,C2H2,C2H4,C2H6作为协变量,将7 种气体的序列同时输入模型中来预测CO 的变化趋势。对CO 进行单变量预测和多变量预测,结果如图4 所示。可看出多变量预测精度较单变量预测精度高,说明多变量预测能通过捕捉序列间的相关性提高模型的预测精度。
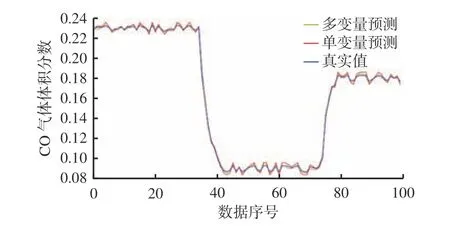
图4 对CO 进行单变量预测和多变量预测的拟合曲线Fig.4 Fitted curves for univariate and multivariate predictions for CO
在实际的生产活动中,需要的预测长度并非一成不变。而Transformer 算法的一次输入值是由多个时间步的数据组成的。具体来说,对于一个长度为z的时间序列,将其分为c个长度为p的子序列,其中p是设定的时间步长。对于每个子序列,将后q个时间步长的数据作为输出,将其前p-q个时间步长的数据作为输入,得到多组输入输出对。这个过程可看作一个滑动窗口,通过调节滑动窗口的大小和步长就可实现不同时间维度的预测。通过调整不同输入输出长度,模型可学习到更多的时间序列信息,从而提高模型的泛化能力。这种方法可更好地处理长时间序列数据,且在不牺牲模型性能的情况下减少计算成本。
基于Transformer 的矿井内因火灾预测模型在不同时间步长和预测长度下的误差见表1。可看出当时间步长固定时,预测精度随预测长度的增加而下降。当预测长度固定时,预测精度随时间步长增加而提高。该模型在不同时间步长和预测长度下均表现出良好的预测能力,说明该模型具有较强的泛化性。

表1 基于 Transformer 的矿井内因火灾预测模型在不同时间步长下的误差Table 1 Errors of mine internal caused fire prediction model based on Transformer under different time dimensions
将Transformer 算法与LSTM、循环神经网络(Recurrent Neural Network,RNN)算法进行对比,实验结果见表2。以MAE 而言,Transformer 算法的预测精度较LSTM 算法和RNN 算法分别提高了7.1%~12.6%和20.9%~24.9%。可见基于Transformer的矿井内因火灾预测模型是一种高效可靠的预测模型,可有效应用于矿井内因火灾的预测。
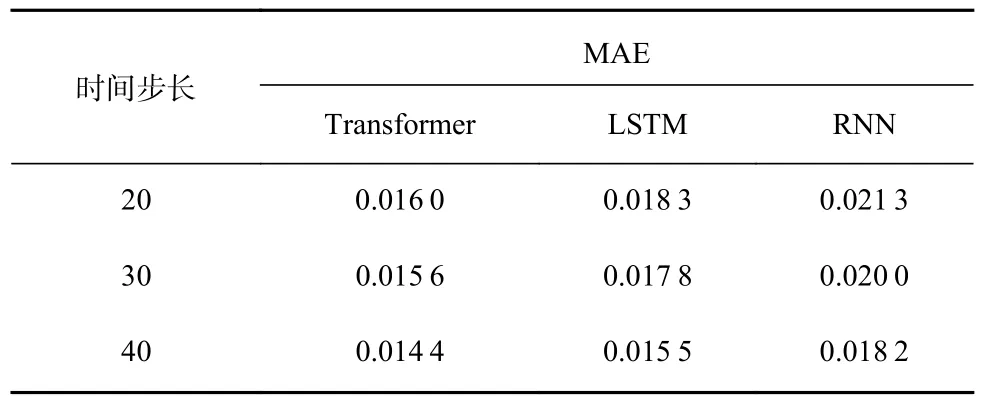
表2 不同算法预测结果比较Table 2 Comparison of the prediction results of the different algorithms
3 结论
1)提出了基于Transformer 的矿井内因火灾预测模型。基于气体分析法,选取煤体燃烧过程中产生的相关气体CO,O2,N2,CO2,C2H2,C2H4,C2H6作为模型输入,将CO 作为目标变量,其余气体作为协变量。
2)多变量预测精度较单变量预测精度高,说明多变量预测能通过捕捉序列间的相关性提高模型的预测精度。
3)对模型在不同时间步长和不同预测长度下进行了多次训练,当时间步长固定时,预测精度随预测长度的增加而下降;当预测长度固定时,预测精度随时间步长增加而提高。
4)通过实例验证,Transformer 算法的预测精度较LSTM 算法和RNN 算法分别提高了7.1%~12.6%和20.9%~24.9%。
