基于YOLOv7-SE 的煤矿井下场景小目标检测方法
2024-04-22曹帅董立红邓凡高峰
曹帅,董立红,邓凡,高峰
(西安科技大学 计算机科学与技术学院,陕西 西安 710054)
0 引言
据统计,近10 年来煤矿安全事故率持续下降,但仍在高危行业前列[1]。为了保障井下人员安全生产,矿工在井下作业过程中必须佩戴防护设备。由于部分矿工安全意识低,对于防护设备不是很重视,不能有效佩戴防护设备,保障自身安全。目前煤矿企业主要通过人工及视频监控摄像头查看的方法来监督矿工是否佩戴防护设备。由于井下作业环境的监控摄像头位置固定,其覆盖范围广、拍摄距离远,监控画面中防护设备目标的尺寸较小,导致小型防护设备目标易受到目标尺寸和井下环境变化的影响,检测难度大大增加。因此,对煤矿井下场景的小目标(尺寸小于32×32 的目标)进行检测研究,在小型防护设备监测中起至关重要的作用。
传统的小目标检测方法[2-4]难以有效提取井下小目标特征信息,随着深度学习的兴起,卷积神经网络(Convolutional Neural Networks,CNN)模型[5]逐步代替了传统小目标检测方法,基于CNN 的小目标检测方法主要分为两阶段目标检测和单阶段目标检测。两阶段目标检测算法通过生成区域网络(Region Proposal Network,RPN)提取到感兴趣的特征信息后进行分类,例如R-CNN 算法(Region with CNN feature)[6]、Fast R-CNN 算 法[7]及Faster R-CNN 算法[8]等,该类算法需生成大量候选区域,检测速度慢,无法满足对小目标实时检测的要求。单阶段目标检测算法将检测归纳为回归问题,实现端到端的检测技术,如单步多框目标检测(Single Shot MultiBox Detector,SSD)算法[9]、YOLO 系列算法[10-14],该类检测算法的检测速度较快,但会有一定的误差。基于CNN 的小目标检测方法较传统方法有很大提升,但仍然存在召回率低、误检率高的问题。针对上述问题,文献[15]为了准确处理和提取小目标信息特征,在YOLOv3 网络模型的特征金字塔网络中自适应融合浅层和深层特征图的局部和全局特征。文献[16]提出了一种轻量型特征提取模块,该模块采用空洞瓶颈和多尺度卷积获得更丰富的图像特征信息,增强了目标特征表达能力。文献[17]在YOLOv5s 模型Backbone 区域嵌入自校正卷积(Self-Calibrated Convolution,SCConv)作为特征提取网络,可更好地融合多尺度特征信息。文献[18]提出了一种结合通道和空间注意力引导的残差学习方法,用于捕捉目标的关键信息。文献[19]提出了高分辨率表示模块,通过使用多尺度特征来捕捉目标的细节信息,并将其融合到高分辨率表示模块,有助于提高目标的定位准确性。
上述研究虽然提高了小目标检测效果,但针对的多为常规场景,受煤矿井下恶劣环境影响,在检测过程中存在井下小目标特征信息提取困难的问题。针对该问题,本文提出一种基于YOLOv7-SE 的井下场景小目标检测方法。首先,将模拟退火(Simulated Annealing,SA)算法与k-means++聚类算法融合,优化YOLOv7 网络模型中初始锚框值。然后,在YOLOv7 网络模型骨干网络中增加新的检测层,得到井下小目标信息丰富的特征图。最后,在YOLOv7网络模型骨干网络的聚合网络模块之后引入双层注意力机制[20],强化井下小目标特征表示。
1 YOLOv7 网络模型
YOLOv7 网络模型[21]主要由输入层、骨干网络、检测头3 个模块组成,如图1 所示。
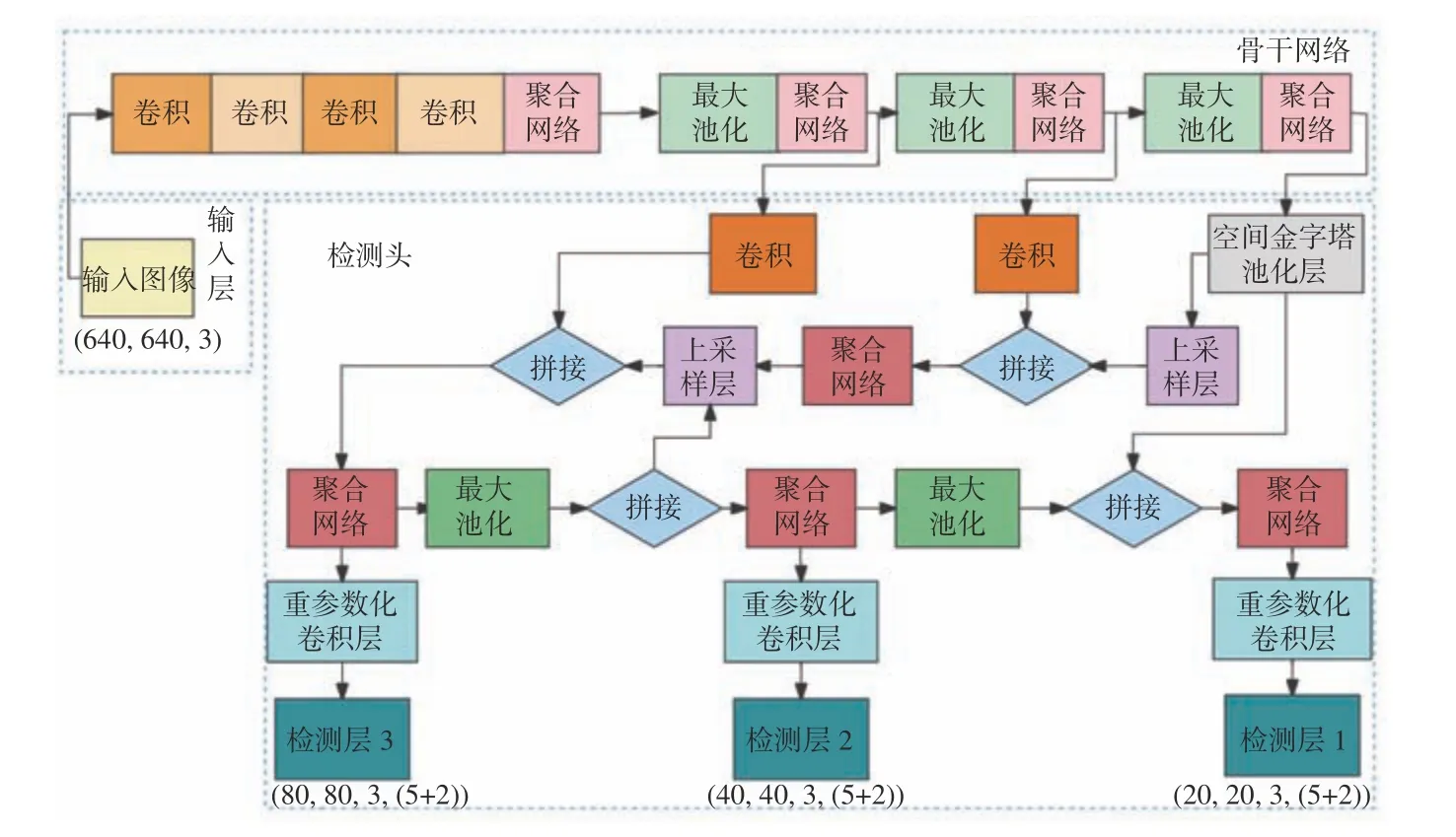
图1 YOLOv7 网络结构Fig.1 YOLOv7 network structure
输入层将图像缩放到固定尺寸640×640,以满足骨干网络对尺寸输入的要求。骨干网络由卷积模块、聚合网络模块和最大池化模块组成,对输入图像进行特征提取。卷积模块主要由1 个卷积层、1 个批量归一化层和1 个SiLU 激活函数构成。聚合网络模块包含3 个1×1 卷积层和4 个3×3 卷积层。最大池化模块由1 个最大池化层、2 个1×1 卷积层和1 个3×3 卷积层组成。检测头由路径聚合特征金字塔网络(Path Aggregation Feature Pyramid Network,PAFPN)和检测层组成,PAFPN 用于融合不同尺寸的特征图,检测层输出带有检测类别和准确度的结果。
2 YOLOv7-SE 小目标检测方法
2.1 融合SA 和k-means++聚类算法
YOLOv7 网络模型的初始锚框尺寸是针对井下常规目标设计,难以适用于井下小目标检测,因此,使用k-means++聚类算法对YOLOv7 网络模型进行聚类分析,生成新的锚框尺寸,若随机选取的初始化聚类中心点在密度小的簇内,会使其相似性较小,聚类结果较差。因此,利用SA 算法[22]来确定k-means++聚类算法中最优的首个初始聚类中心点。SA 算法是寻找数据集样本中最优值的算法,先初始化SA 算法的参数,如初始温度、终止温度和迭代次数。通过迭代的方式,不断更新聚类中心点的值,并计算目标函数的值。根据SA 策略判断是否接受当前参数的更新,若接受,则更新聚类中心点的值,否则降低温度继续迭代下一次参数值,直到达到终止温度,返回最优的聚类中心点。
将SA 算法与k-means++聚类算法进行融合,并对本文数据集进行聚类分析,得到的锚框尺寸分别为[9,31],[9,17],[15,37],[16,23],[21,29],[26,40],[29,71],[39,55],[50,79]。
2.2 新的目标检测层
YOLOv7 网络模型中深层网络提取抽象的语义特征信息,用来反映井下大目标特征信息,而浅层网络提取目标的细节特征,能够保留更多的井下小目标特征信息。YOLOv7 网络模型通常通过增加下采样结构以获取更大的目标感受野,但随着下采样结构的增加,井下小目标的特征信息逐渐丢失,对于在图像中特征信息少的井下小目标不友好,不利于井下小目标检测。
为了使YOLOv7 网络模型重点提取浅层网络中丰富的井下小目标特征信息,而抑制深层网络的特征提取,本文去掉YOLOv7 网络模型骨干网络的32 倍下采样结构,在YOLOv7 网络模型中增加1 层新的目标检测层,获取浅层网络中细节信息更明确的井下小目标特征,减少在下采样过程中丢失井下小目标特征。YOLOv7 网络模型从第1 个聚合网络模块开始提取特征信息,经过PAFPN 输出到检测层,得到新尺寸(160×160)的特征图,该特征图的井下小目标信息相对丰富。
2.3 引入双层注意力机制
针对煤矿复杂环境下小目标图像特征抽取不准确的问题,本文在YOLOv7 网络模型的聚合网络模块之后添加双层注意力机制,以强化聚合网络模块对井下小目标的特征提取能力。
双层注意力机制整体结构如图2 所示。第1 阶段使用重叠块嵌入,将原始的二维输入图像转换为一维的图像块。第2 阶段到第4 阶段使用合并块模块进行下采样操作,用于调整相应通道数,并降低输入分辨率,同时在每个阶段的操作后采用双层注意力模块(图3)对特征图做特征变换。
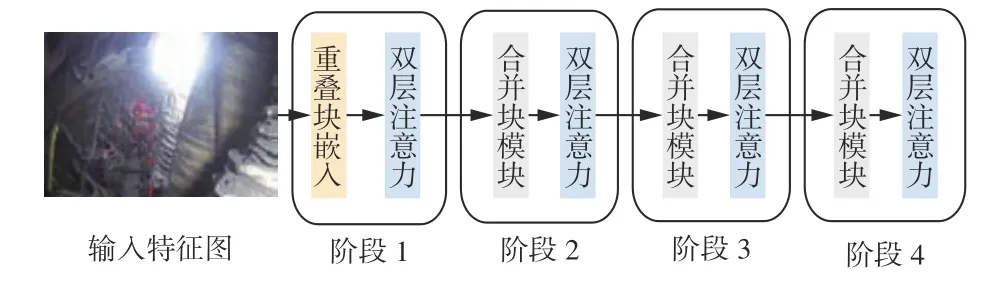
图2 双层注意力机制整体结构Fig.2 Overall structure of dual layer attention mechanism
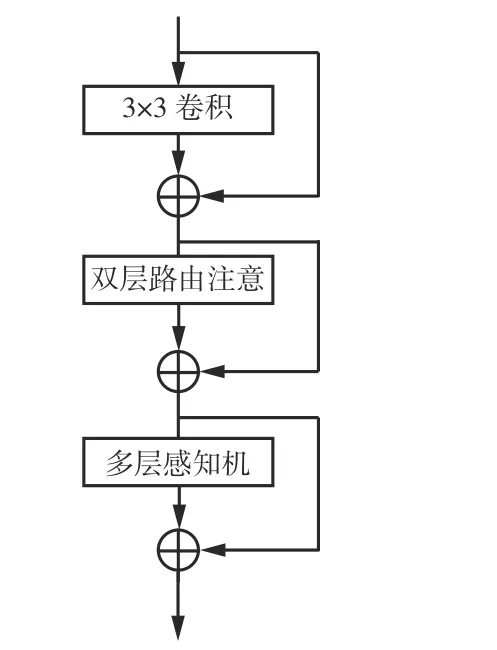
图3 双层注意力模块Fig.3 Dual layer attention module
通过收集前n个相关区域中的键值对,并利用稀疏性操作忽略最不相关区域的计算来节省模块参数量和计算量,并对收集的键值对进行注意力操作。
式中:O为输出;Attention(·)为自注意力函数;Q为查询;KT为键的张量;VT为值的张量;LCE(·)为局部上下文增强模块;V为值。
式中:K为健;S(·)为归一化函数;d为缩放因子;QKT为Q和K之间的相似程度。
对YOLOv7 进行上述改进,将改进后的网络模型命名为YOLOv7-SE。
3 实验结果与分析
3.1 数据集
本文数据集来源于煤矿井下多个场景的视频监控摄像头拍摄的图像视频,包括采煤工作面、胶带机头工作面、井下巷道、井下站台、煤壁面、井下候车点等场景,如图4 所示。

图4 不同场景样本示例Fig.4 Sample examples of different scenarios
为提升数据集的多样性,通过水平、垂直翻转及随机方向旋转等方法扩充数据。整理后共有5 622 张图像,将数据集按照8∶1∶1 的比例划分为训练集、验证集和测试集。同时,使用labelImg 工具对数据集进行标注,在满足小目标尺寸的条件下,标注类别有安全帽和自救器。
为解决井下环境中煤尘对图像的干扰,在YOLOv7 网络模型的数据预处理阶段增加图像处理模块,对数据集进行预处理,如图5 所示。
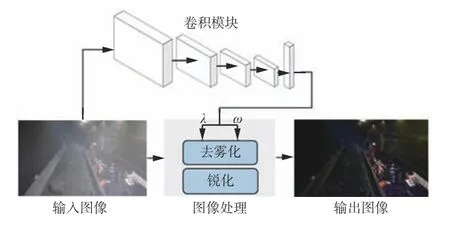
图5 图像处理模块Fig.5 Image processing module
首先,采用暗通道去雾方法[23]对原始图像进行去雾,以减少井下煤尘对图像的影响。然后,采用高斯函数对去雾后的图像进行锐化,以突出图像细节,提高井下场景目标边缘与周围像素之间的反差。最后,使用卷积模块作为调优器,利用其反向传播的特性对图像处理方法中的去雾程度和锐化强度进行优化,以达到更好的增强效果。
3.2 评价指标
常用的小目标评价指标包括准确率P、召回率R、平均精度(Average Precision,AP)、所有类别的平均精度值(mean Average Precision,mAP)及每秒传输帧数(Frames Per Second,FPS)。
式中:NTP为预测正确的正样本数量;NFP为预测错误的正样本数量;NFN为预测错误的负样本数量;M为目标的类别数。
3.3 实验配置
本文实验在ubuntu20.04 操作系统中搭建,具体配置见表1。
表1 实验环境配置Table 1 Experimental environment configuration
3.4 结果分析
3.4.1 模型训练
在模型训练前需对实验超参数进行设置,迭代次数为200,初始学习率为0.015,批量大小为32,选取640×640 的图像作为模型的输入。在模型训练过程中损失函数值随迭代次数变化曲线如图6 所示。
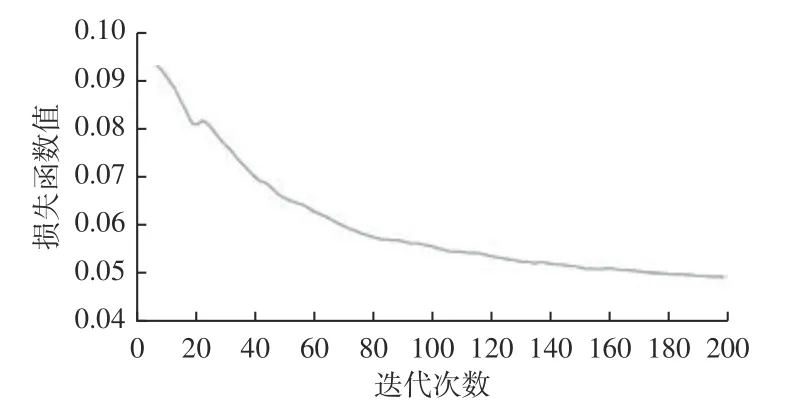
图6 模型训练过程Fig.6 Model training process
由图6 可看出在模型训练过程前80 次迭代,损失函数值下降十分明显,第80—180 次迭代时,损失函数值下降趋势趋于平缓,最后20 次迭代的损失函数值已逐渐稳定。模型训练过程中的最终损失函数值低于0.05,说明本文模型的训练参数设置合理,模型学习效果较好。
3.4.2 对比实验
为了衡量YOLOv7-SE 网络模型的检测性能,将其 与 Faster R-CNN,RetinaNet,CenterNet,FCOS(Fully Convolutional One-Stage),SSD,YOLOv5,YOLOv7 目标检测模型进行对比,结果见表2。
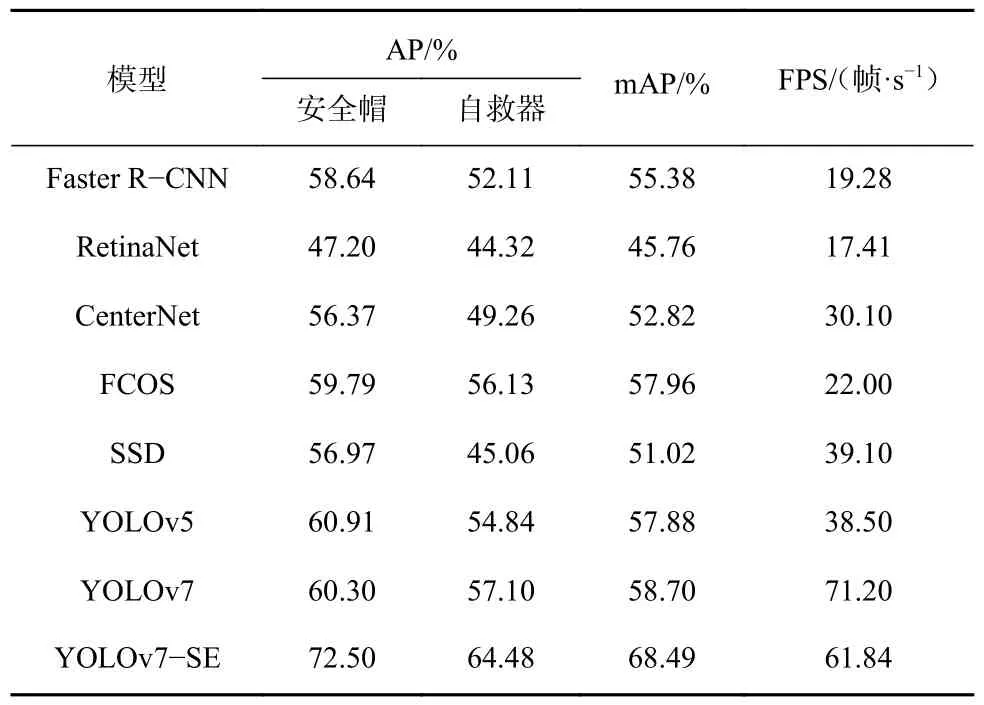
表2 各模型对比结果Table 2 Comparison results of each model
由表2 可看出,YOLOv7-SE 网络模型的安全帽检测AP 较Faster R-CNN,RetinaNet,CenterNet,FCOS,SSD,YOLOv5,YOLOv7 分别提升了13.86%,25.3%,16.13%,12.71%,15.53%,11.59%,12.20%。YOLOv7-SE 网络模型的自救器检测AP 较FasterR-CNN,RetinaNet,CenterNet,FCOS,SSD,YOLOv5,YOLOv7分别提升了12.37%,20.16%,15.22%,8.35%,19.42%,9.64%,7.38%。YOLOv7-SE 网络模型的mAP 较Faster R-CNN,RetinaNet,CenterNet,FCOS,SSD,YOLOv5,YOLOv7 分别提升了13.11%,22.73%,15.67%,10.53%,17.47%,10.61%,9.79%。YOLOv7-SE 网络模型的FPS 较Faster R-CNN,RetinaNe,CenterNet,FCOS,SSD,YOLOv5 分别提升了42.56,44.43,31.74,39.84,22.74,23.34 帧/s,较YOLOv7 下降9.36 帧/s。说明YOLOv7-SE 网络模型的检测性能更佳。
3.4.3 消融实验
为了验证不同改进方法对YOLOv7 网络模型性能的影响,设计了6 组实验,改进的骨干网络实验为添加新的目标检测层和引入双层注意力机制,实验结果见表3。
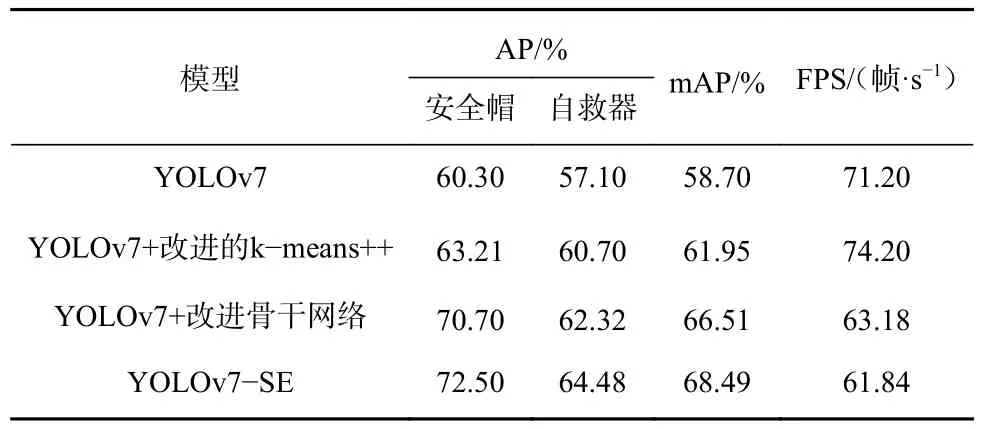
表3 消融实验结果Table 3 Results of ablation experiment
由表3 可看出,使用改进的k-means++方法重新聚类分析锚框值,安全帽检测AP、自救器检测AP、mAP、FPS 分别为63.21%,60.7%,61.95%,74.2 帧/s,较YOLOv7 分别提升了2.91%,3.6%,3.25%,3 帧/s;改进YOLOv7 网络模型骨干网络后,安全帽检测AP、自救器检测AP、mAP 分别为70.7%,62.32%,66.51%,较YOLOv7 分别提升了10.4%,5.22%,7.81%,FPS 下降8.02 帧/s,为63.18 帧/s;YOLOv7-SE 网络模型的安全帽AP、自救器AP、mAP 分别为72.5%,64.48%,68.49%,较YOLOv7 分别提升了12.2%,7.38%,9.79%,FPS 为61.84 帧/s,说明YOLOv7-SE模型在保证检测速度的同时,有效强化了YOLOv7-SE 网络模型对井下小目标的特征提取能力。
3.4.4 检测效果对比分析
为更加直观地体现YOLOv7-SE 网络模型的优越性,在井下采煤工作面、胶带机头工作面、井下巷道及井下站台等场景中与YOLOv7 网络模型对比,对比结果如图7 所示。

图7 检测效果对比Fig.7 Comparison of detection effects
由图7 可看出,在对安全帽和自救器的检测中,YOLOv7 网络模型出现漏检和误检的问题,而YOLOv7-SE 网络模型有效改善了该问题,提高了检测精度。因此,YOLOv7-SE 网络模型可满足井下小目标检测任务。
4 结论
1)针对煤矿井下场景中目标尺寸较小、环境存在大量煤尘导致小目标特征提取困难等问题,将SA 算法与k-means++聚类算法融合,在YOLOv7骨干网络中增加新的目标检测层,同时将双层注意力机制嵌入聚合网络模块之后。YOLOv7-SE 网络模型安全帽检测AP、自救器检测AP、mAP 分别为72.50%,64.48%,68.49%,较YOLOv7 网络模型分别提升了12.2%,7.38%,9.79%,FPS 为61.84 帧/s。
2)将YOLOv7-SE 网络模型与Faster R-CNN,RetinaNet,CenterNet,FCOS,SSD,YOLOv5,YOLOv7进行对比,实验结果表明,YOLOv7-SE 网络模型对安全帽和自救器的检测精度最高。
3)在对安全帽和自救器的检测中,YOLOv7-SE 网络模型有效改善了漏检和误检问题,提高了检测精度。
