基于MES-YOLOv5s 的综采工作面大块煤检测算法
2024-04-22徐慈强贾运红田原
徐慈强,贾运红,田原
(1.煤炭科学研究总院,北京 100013;2.中国煤炭科工集团太原研究院有限公司,山西 太原 030032;3.煤矿采掘机械装备国家工程实验室,山西 太原 030032)
0 引言
煤炭是我国的主体能源,煤矿智能化建设是我国煤炭工业高质量发展的方向[1-3]。综采工作面的刮板输送机在运输煤流的过程中,大块煤易造成煤流堵塞,引发堆煤现象,严重影响机械设备性能和采煤效率[4-7]。由于综采工作面低照度、运动模糊和粉尘、水雾等特殊环境条件[8],且受限于煤矿井下的低算力设备,现有的目标检测算法往往存在精度低、模型占用的内存大、硬件依赖强等问题。因此,设计精度高、轻量化、移动端易部署的大块煤目标检测算法对于综采工作面安全生产有重要意义。
综采工作面环境恶劣,存在运动模糊、尺度变化、遮挡等复杂工况。传统的目标检测算法存在效率低、准确率较低等问题[9]。随着计算机视觉技术的发展,基于深度学习的目标检测技术[10]被应用到煤矿井下目标检测中。曹现刚等[11]提出了一种跨模态注意力融合的煤炭异物检测方法,有效提高了复杂特征异物检测精度,减少了误检、漏检现象。高涵等[12]融合特征增强与Transformer 的方法,实现了煤矿输送带异物检测,有效解决了输送带异物目标检测中细长物体检测效果差、弱语义特征提取困难的问题。张立亚[13]提出了一种基于生成对抗网络的带式输送机异物检测方法,采用深度可分离卷积代替原有主干网络中的卷积操作,大幅降低了模型计算量,提高了异物检测速度。王科平等[14]以YOLOv4模型为基础,通过深度可分离卷积替换传统卷积,在主干网络中添加残差自注意力模块,减少了模型参数量和计算量,实现了检测模型的工业部署。李江涛等[15]提出了一种基于异物识别模型的轻量化策略,减小了模型大小和运行时占用的内存。
上述研究通过添加注意力机制、更换深度可分离卷积等操作,一定程度上提升了煤矿目标检测精度,但仍存在以下问题:模型占用的内存过大,导致部署困难;轻量化设计虽提升了模型的检测速度,但导致精度下降。针对上述问题,本文以YOLOv5s为基础,通过轻量化MobileNetV3 网络、高效多尺度注意力(Efficient Multi-Scale Attention,EMA)模块、SIoU 损失函数对模型进行改进,提出了一种基于MES-YOLOv5s 的综采工作面大块煤检测算法,并通过实验验证了该算法的有效性。
1 基础模型选择
YOLO 网络因其在速度和准确性方面的显著平衡而在目标检测模型中脱颖而出。YOLO 系列中常用的网络有YOLOv5,YOLOv7,YOLOv8。YOLO 系列网络性能对比如图1 所示,n,s,m,l,x 表示YOLO的不同变体,E为3 种模型在COCO 数据集上的检测精度(阈值范围为0.50~0.95),m为模型占用的内存,t为CPU 检测时间。可看出,YOLOv8 网络模型整体性能优于其他网络模型,但检测速度较慢;YOLOv7 网络模型精度较高,但检测速度慢,且模型占用的内存大,难以部署;YOLOv5 网络模型精度较低,但具有参数量少、易训练、推理速度快和部署简单等特点;YOLOv5s 性能优于YOLOv8n,且检测时间和占用的内存与YOLOv8n 差距较小。综合性能和实际工况考虑,本文选择YOLOv5s 作为基础模型。

图1 YOLO 系列网络模型性能对比Fig.1 Performance comparison of YOLO series network models
YOLOv5s 网络模型[16]主要包括输入层、主干网络、颈部网络、检测头4 个部分。输入层包含数据增强方法,对随机4 张图像进行任意缩放和拼接,以扩张数据集并提高训练效率。主干网络是由卷积(Conv)模块、C3 模块和快速空间金字塔池化(Spatial Pyramid Pooling-Fast,SPPF)模块组成。Conv 模块用于提取物体特征,C3 模块对特征信息进行残差连接,SPPF 模块融合不同尺度的特征信息。颈部网络由特征金字塔网络(Feature Pyramid Network,FPN)和路径聚合网络(Path Aggregation Network,PAN)[17]组成,用于提高多尺度检测精度。检测头输出预测结果,生成预测类别。
2 MES-YOLOv5s 网络模型
在煤矿井下,煤机装备等移动端设备搭载的硬件算力低,而目标检测任务实时性要求高。针对该问题,本文设计了MES-YOLOV5s 网络模型,其结构如图2 所示。

图2 MES-YOLOV5s 网络模型结构Fig.2 MES-YOLOV5s network model structure
2.1 主干网络改进
YOLOv5s 的主干网络由卷积模块和C3 模块堆叠组成,该结构能够较好地提取物体特征信息,但参数量大、计算量大、推理时间长,难以部署到移动端等算力较低的设备上。因此,本文使用MobileNetV3替代主干网络。
MobileNetV3 的核心模块是bneck,该模块主要包含可分离卷积、压缩和激励(Squeeze-and-Excitation,SE)通道注意力机制和shortcut 连接,如图3 所示[17-18]。特征图首先经过1×1 卷积升维,再通过3×3 深度可分离卷积,保持通道数不变。SE 通道注意力机制为每一个通道赋予权重。设输入特征图维度为C×H×W(通道数×高×宽),经过全局平均池化得到C×1×1 的张量,该张量包含每个通道的权重。将通道权重与对应通道的输入特征相乘,再通过1×1 卷积降维,得到深层信息。最后通过shortcut 将浅层特征信息传递到深层,实现特征复用。

图3 bneck 模块结构Fig.3 Structure of bneck module
2.2 EMA 模块
由于大块煤检测任务目标遮挡严重,密集分布且MobileNetV3 网络缩减了大量模型参数,导致YOLOv5s模型精度下降。因此,本文在颈部网络引入EMA 模块[19],保留各通道信息并进一步减少计算开销。
EMA 模块结构如图4 所示[19]。在空间维度上,对于输入维度为C×H×W的特征图,按通道将其分为G组,每组的维度为(C/G)×H×W。通过一维水平全局池化XAvg Pool、一维垂直全局池化YAvg Pool、3×3 卷积3 个并行分支进行处理。前2 个分支输出的特征经过Sigmoid 激活函数激活,最后通过Concat 将2 个通道注意力特征聚合。3×3 卷积操作用于提取特征图的特征。跨空间学习方法利用二维全局平均池化将全局空间信息编码并通过1×1 分支输出,建立信息短期和长期依赖关系。最后输出维度为C×H×W的特征图。

图4 EMA 模块结构Fig.4 Structure of efficient multi-scale attention(EMA)module
2.3 SIoU 损失函数
YOLOv5s 模型的损失函数为CIoU[20],该函数依赖于预测框与真实框的距离、重叠区域和纵横比,未考虑到预测框与真实框的方向匹配问题,在模型训练过程中,预测框的方向会产生振荡。因此,本文采用SIoU[21]损失函数,该函数考虑到所需回归之间的向量角度,重新定义了惩罚指标,提高了训练速度和推理准确性。
SIoU 损失函数中添加了角度损失,当预测框与真实框水平方向夹角 α≤π/4时,收敛过程首先最小化 α;当预测框与真实框垂直方向夹角 β≤π/4时,收敛过程首先最小化 β。
3 实验及结果分析
3.1 数据采集及预处理
实验使用文献[22]提供的长壁综采工作面数据集,将大块煤数据集按照8∶1∶1 的比例划分,共包含16 813 张训练图像、2 101 张验证图像、2 101 张测试图像。长壁综采工作面数据集处理流程如图5 所示,包含数据采集、数据过滤和数据标注。首先将采集到井下原始监控视频数据通过FFmpeg 软件切成帧图像,通过数据过滤操作筛出不完整、难识别、运动模糊、远距离的图像,最后使用LabelImg 软件完成数据标注。
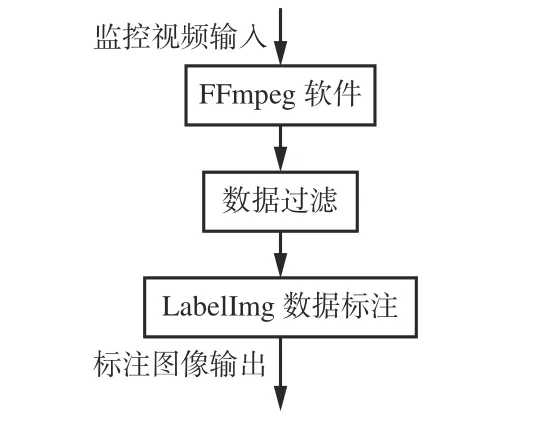
图5 长壁综采工作面数据集处理流程Fig.5 The processing process of the dataset of the longwall fully mechanized working face
3.2 实验配置及评价指标
硬件配置:操作系统为ubuntu20.04,cuda 版本为11.3,CPU 型号为Intel(R)Xeon(R)Platinum 8369B CPU @2.90 GHz,GPU 型号为NVIDIA A10。
软件及训练参数:输入图像分辨率为1 920×1 080,迭代次数为300,初始学习率为0.01,batchsize 为32,选用SGD 优化器,学习率动量为0.937;python 版本为3.9,pytorch 框架版本为1.12,OpenCV版本为4.5.1。
使用召回率、平均精度均值(mean Average Precision,mAP)作为模型的评价指标。
式中:P为精确度;TP 为预测类别与真实类别都为真的目标数目;FP 为预测类别为真、真实类别为假的目标数目;R为召回率;FN 为预测类别为假、真实类别为真的目标数目;AP 为平均精确度;n为检测框数目;L为类别数,当L=1 时,mAP 与AP 相等。
3.3 消融实验
为验证各模块的效果,以相同的实验配置进行消融实验,结果见表1。可看出采用MobileNetV3替代主干网络后,模型的mAP 降低了4.2%,内存减少了43 MiB,检测时间减少了39.7 ms;在颈部网络添加EMA 模块后,模型的mAP 增加了2.2%,内存增加了0.6 MiB,检测时间增加了7.2 ms;在检测头部使用更为高效的SIoU 损失函数后,模型的mAP 增加了0.6%,内存保持不变,检测时间减少了3.6 ms;同时添加3 项改进策略后,模型的mAP 达84.6%,占用内存为11.2 MiB,检测时间为31.8 ms。
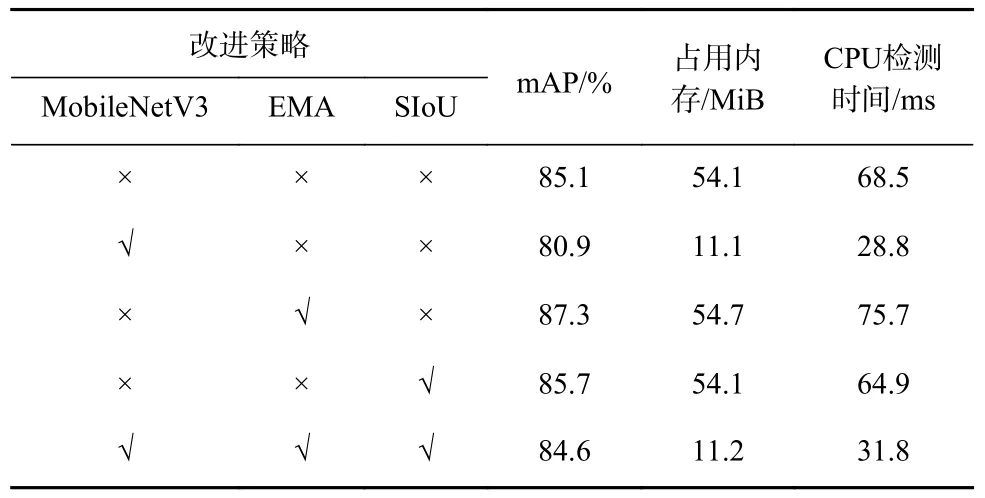
表1 消融实验结果Table 1 Ablation test results
消融实验结果表明:MobileNetV3 大幅减少了模型占用的内存和检测时间,但mAP 损失严重;EMA 模块和SIoU 损失函数可在一定程度上恢复损失的精度,同时保证模型在CPU 上具有较高的检测速度,满足煤矿井下目标实时检测需求。
3.4 对比实验
为进一步验证MES-YOLOv5s 的性能,在CPU测试环境下,将其与DETR[22],YOLOv5n,YOLOv5s,YOLOv7 进行对比。DETR 是基于Transformer 的目标检测框架,使用 Transformer 编码器-解码器架构来同时预测所有对象,比传统的目标检测器更简单、更高效。实验结果见表2。可看出MES-YOLOv5s模型的mAP 达84.6%,较DETR,YOLOv5n 分别增加了3.3%,0.7%,较YOLOv5s,YOLOv7 模型分别减少了0.5%,1.9%;模型占用的内存为11.2 MiB,较DETR,YOLOv5n,YOLOv5s,YOLOv7 模型分别减少了137.8,2.8,42.9,273.4 MiB;检测时间为31.8 ms,较DETR,YOLOv5n,YOLOv5s,YOLOv7 模型分别减少了464.4,0.1,36.7,289.0 ms。
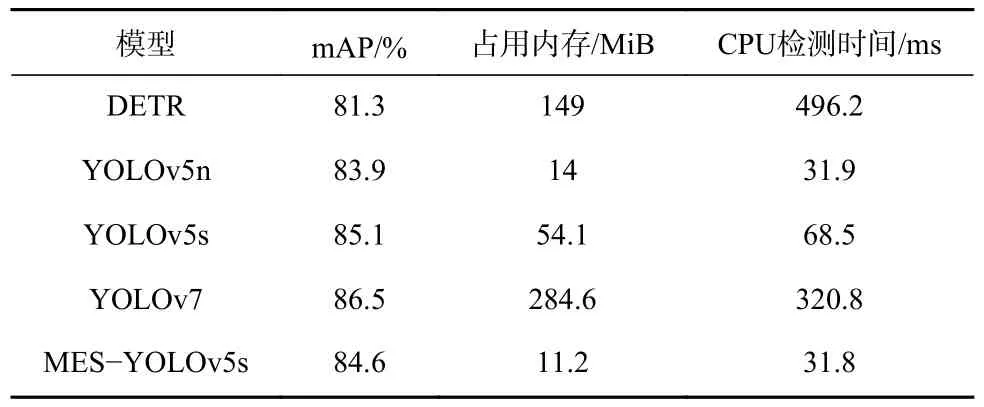
表2 对比实验结果Table 2 Comparative experimental results
对比实验结果表明,MES-YOLOv5s 模型的精度较高,内存小,CPU 检测速度快,综合性能优于其他模型,更适合部署于低算力设备。
在测试集上采用各模型进行实验,部分结果如图6 所示。第1 组实验在高速运动、多尺度的工况下进行,DETR,YOLOv5n,MES-YOLOv5s 模型对于小尺度目标的mAP 小于50%,YOLOv5s,YOLOv7模型的mAP 大于50%。第2 组实验在遮挡、多目标的工况下进行,DETR 和YOLOv5n 模型出现误检情况,YOLOv5s,YOLOv7,MES-YOLOv5s 模型的召回率为100%,且mAP 大于85%。第3 组实验在静止的工况下进行,DETR 模型的精确度为57%,其他模型的召回率为100%,mAP 大于85%。第4 组实验在高速运动、多尺度、遮挡的工况下进行,DETR 模型的精确度为85%,其他模型的召回率为100%,YOLOv7和MES-YOLOv5s 模型的mAP 大于60%。

图6 不同模型部分检测结果Fig.6 Partial detection results of different models
MES-YOLOv5s 模型综合性能表现最好,在高速运动、多尺度、遮挡和多目标的工况环境下能够保持较高的召回率和精度。
4 结论
1)采用MobileNetV3 网络替换YOLOv5s 的主干网络,以适应模型在移动端的部署,模型占用的内存减少了43 MiB,CPU 端检测时间减少了39.7 ms。在颈部网络添加EMA 模块,以保留各通道信息并进一步减少计算开销,mAP 增加了2.2%,模型占用的内存增加了0.6 MiB,检测时间增加了7.2 ms。在检测头部更换SIoU 损失函数,以提高模型的训练速度和推理的准确性,mAP 增加了0.6%,模型占用的内存保持不变,检测时间增加了3.6 ms。
2)与DETR,YOLOv5n,YOLOv5s,YOLOv7 模型进行对比,MES-YOLOv5s 模型综合性能最好,mAP为84.6%,模型占用的内存为11.2 MiB,在CPU 端的检测时间为31.8 ms,在高速运动、多尺度、遮挡和多目标的工况环境下能够保持较高的召回率和精度。
