在单片机中应用卷积神经网络实现故障诊断
2024-03-21张岷涛廖文豪卿朝进
张岷涛,廖文豪,卿朝进
(西华大学 电气与电子信息学院,成都 610039)
智能故障诊断(Intelligent fault diagnosis,IFD)是指将机器学习应用于故障诊断。近年来,随着机器学习的理论发展取得巨大成就,IFD 被更多专家学者所关注[1-4]。这对以信号处理和人工提取特征为主的传统故障诊断方法提出了挑战。
时域、频域及时频域分析是基于振动信号的传统故障诊断方法[5]。为表征局部特征,通常采用短时傅里叶变换[6]、小波变换[7]、经验模态分解[8]、局部均值分解[9]等时频处理方法提取故障特征,再通过工程师的人工经验进行故障判定,这需要大量的数据统计。智能化的故障诊断方法则利用支持向量机[10]、k-means[11]、人工神经网络[12]等机器学习方法自动分类特征,降低了对专家经验的依赖,但准确率仍取决于人工提取的特征能否准确描述故障信息,具有较大局限性。而深度学习等方式是基于数据驱动的方式,只需要精确的原始数据和合适的网络结构就可以实现端到端的自动故障诊断。
随着信息技术的飞速发展,现代检测技术已经能很容易实现对于复杂设备的多点全覆盖的数据采集,使得深度学习这种基于数据驱动的方式更能发挥其长处,取得更高精度的诊断效果。Hinton 应用深度置信网络(Deep belief network,DBN)[13],AlexNet[14]和ResNet[15]等应用卷积神经网络(Convolutional neural network,CNN),使IFD 取得了相当大的进步。
然而,这些深度学习的神经网络架构中都有神经元的设计。从某种程度上说,神经元的数量越多网络的学习能力就越强,但同时大量神经元的设计也会消耗相当多的计算资源,使得其在计算能力有限的嵌入式设备中的应用受到很大的局限。而机械设备运行状态具有体量大、真实度高、生成速度快、数据类型多和价值密度低等特点[16],要求现场进行快速且低成本的应用。很多场景需要嵌入式设备承担起更多的任务。所以TinyML(小型设备的机器学习)领域开始逐渐的发展起来。一种解决方案是在CPU 中内置神经单元,如某些手机或穿戴设备。一种是简化神经网络的架构,使其能够适应单片机的有限资源。
本文在Jupyter notebook 工具内使用Scipy、Numpy 等科学计算库对原始的数据进行预处理,使用Tensorflow、Pytorch 等深度学习框架训练网络参数,并对不同的网络结构和参数进行测试准确度、参数量、运行时间等进行方面进行比较。利用CubeAI等工具将网络结构与权重转化为单片机环境所需的C 语言结构和权重形式,然后将其部署至STM32H743VI 内。实现了基于CNN2D 神经网络的轴承故障振动信号的识别。
本文网络的训练和验证使用凯斯西储大学(CWRU)滚动数据中心的轴承故障数据集。CWRU数据集是世界公认的轴承故障诊断标准数据集。截止到 2015 年,仅机械故障诊断领域顶级期刊《Mechanical Systems and Signal Processing》就发表过 41 篇使用CWRU 轴承数据进行故障诊断的文章[17]。在基于深度学习的轴承故障诊断领域,目前被引用数最高的两篇文章[18-19]的试验数据也均来自 CWRU轴承数据库。为了评价被提出算法的优越性,最客观的方式就是使用第三方标准数据库与当下主流算法比较。因此,本文的所有试验均采用 CWRU 轴承数据。获得其中的包含10 种故障类型的数据,优化后的最优模型的故障识别准确度可以达到98.90%。每次诊断运行时间为19 ms。
1 神经网络架构
目前应用于智能诊断领域的典型的深度学习方案主要包括有堆栈自动编码器(SAE)、深度置信网络(DBN)、卷积神经网络(CNN)、深度残差收缩网络(ResNet)等。其中卷积神经网络(CNN)比较成功的两种架构分别是一维卷积神经网络(CNN1D)和二维卷积神经网络(CNN2D)。CNN1D 和CNN2D的最大区别就是CNN1D 的卷积核为一维向量,网络输入的数据也同样的为一维向量,其对于一维的时间序列数据或周期性数据都有较大的应用范围。二维神经网络的卷积核为二维向量,网络输入的数据为二维数据,CNN2D 由于其强大的特征提取能力,在近年的图像处理领域包括定位、目标识别等有广泛的应用。本文通过对数据进行预处理,将一维输入数据转换为二维,采用二维卷积神经网络的架构实现滚动轴承故障诊断。
1.1 数据集
CWRU 轴承数据集为美国凯斯西楚大学数据中心发布的一个有关于故障轴承的数据集,其目的是用来检测和验证电机性能,近年来由于故障诊断领域的兴起,其多用作故障信号诊断的基准数据。其测量数据的实验平台如图1 所示。

图1 CNN2D 主要调试与优化流程Fig.1 Main debugging and optimization process of CNN2D
其实验平台包括一个电机(左侧),一个转矩传感器(中间),一个功率计(右侧)和电子控制设备(没有显示)。实验中使用加速度采集振动信号,通过使用磁性底座将传感器安放在电机壳体上。加速度传感器分别安装在电机壳体的驱动端12 点钟的位置,在其他一些实验中,传感器也被安放在电机支承底盘上。数字信号的大部分采样频率为12 000 Hz,部分正常轴承数据也以48 000 Hz 的采样速率采集。外圈的故障是固定不变的,因此故障相对于轴承受载区域的位置对电机/轴承系统的振动响应由直接的影响,为了对这个影响进行定量研究,实验中分别对驱动和风扇端的轴承外圈布置3 点钟、6 点钟、12 点钟方向的故障。除此之外,实验对每种情况,还分别统计了在1 797、1 772、1 750 和1 730 r/min转速下数据。
实验中使用的轴承为滚动轴承,其结构如图2所示。
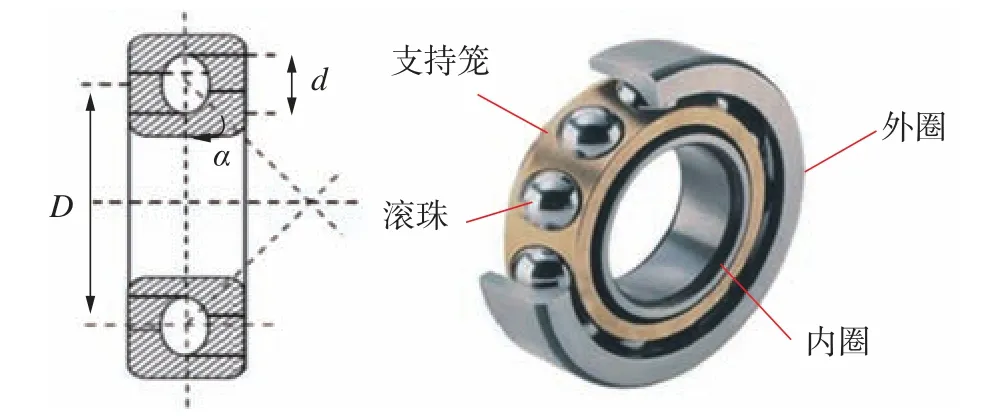
图2 CWRU 实验中使用的滚动轴承结构Fig.2 Rolling bearing structure used in CWRU experiments
被测试轴承支承电机轴,使用电火花加工技术在轴承上布置了单点故障,故障直径分别为0.177 8 mm、0.355 6 mm、0.533 4 mm、0.711 2 mm 和1.016 0 mm,其中前3 种故障直径的轴承使用的是SKF 轴承,后两种故障直径的轴承使用的是相较差距不大的NTN 轴承。而单点故障的位置则设在滚珠、外圈、内圈3 个地方。
对于数据科学来说,对于数据的分析与预处理是一个十分重要的,其可以极大的减小数据错误以及数据的偏好对于后续实验的影响,透彻的了解所得到的数据可以对后续实验出现的问题,使用更加有针对性的手段进行解决和分析。
根据Smith 等[17]对于CWRU 故障轴承数据集所做的基础性分析,以及其最后总结的数据图表可以清楚的了解到,对于整个CWRU 故障轴承数据集来说,其中12 kHz 采样率的驱动端的数据最为完整且明显的人为错误最少。而对于不同转速下的数据,1 797 r/min 的转速数据最接近于1 800 r/min,此时对于使用12 kHz 的采样率来说,400 的采样点的数据正好接近于一个转动周期,可以在信号里观察到一个完整的故障信号波形。所以后续将使用12 kHz采样率下1 797 r/min 的驱动端数据,来进行网络结构的训练以及之后的验证,至此可以得到如表1 中的10 种不同的故障分类。
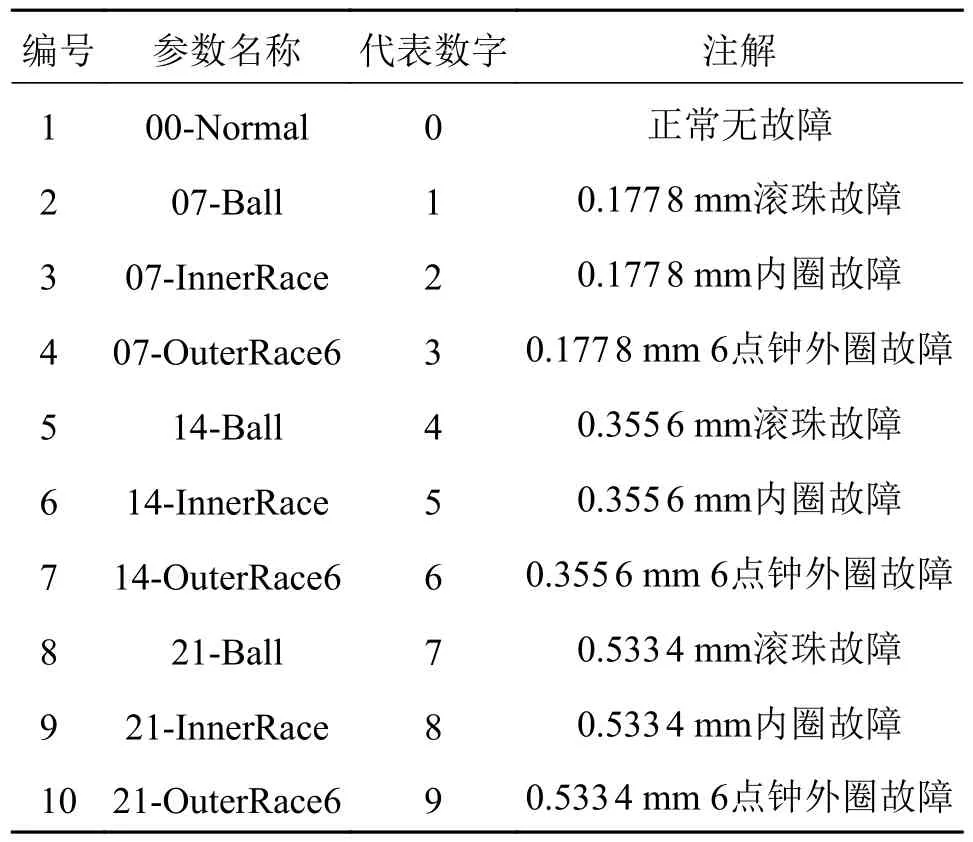
表1 CWRU 数据集中获取的10 种不同故障分类Tab.1 10 different fault classifications obtained in the CWRU data set
其中,前面的数字为故障的直径大小,后面的英文表示故障的位置,比如14-Ball 就代表轴承滚珠直径为35.56 cm(14 英寸) 大小的故障。特别说明的是OuterRace6 后面的数字6 代表的时候6 点钟方向,其余的两个3 点钟方向与12 点钟方向的故障,由于其数据量较少这里将其丢弃不考虑。
而对于整个数据集的文件结构来说,大致可以总结为单一故障情况下的数据为一个独立文件,一个独立文件为.mat 格式。文件结构主要里面包括DE 和FE 两种不同的向量数据,其对应的便是驱动端数据和风扇端数据,而部分文件内还包括正常的BA 基准数据。具体文件结构内容如表2 所示。
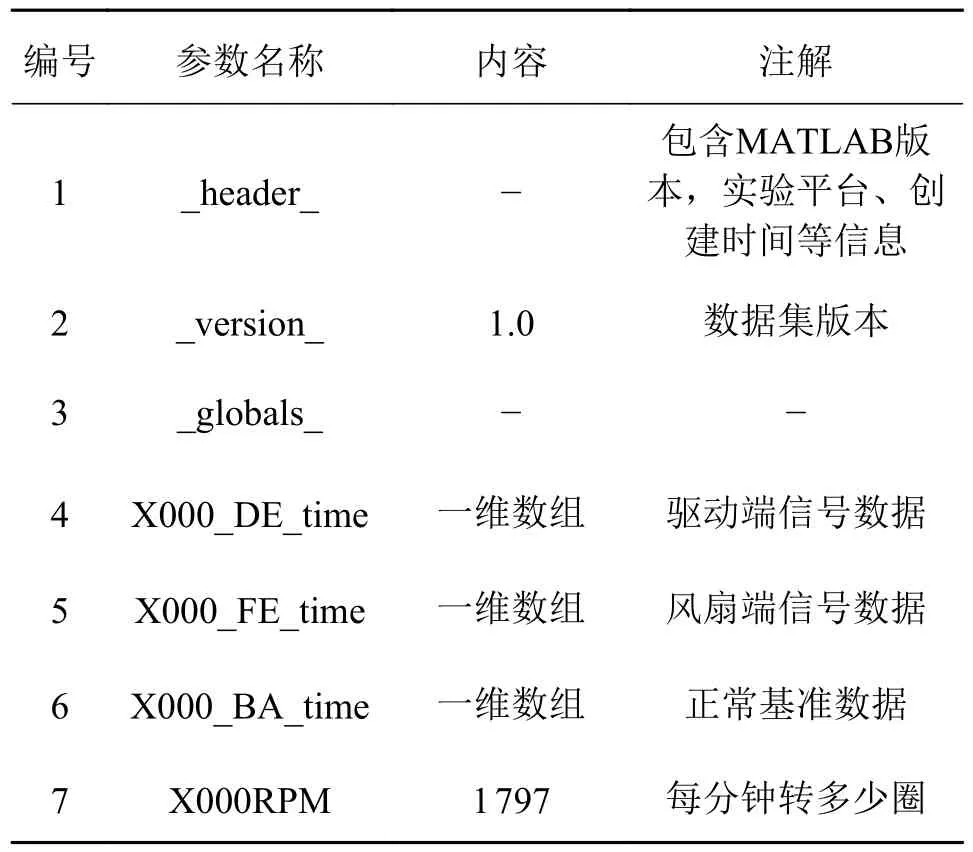
表2 CWRU 数据集单个文件内部结构Tab.2 Internal structure of a single file of a CWRU data set
利用基于Python 的Scipy 和Numpy 等科学计算和数据分析库,将所需要的信号数据提取出来并且保存到本地文件以便后续的分析与处理。将一段信号数据转化到时间序列后如图3 所示。

图3 时间序列下的部分CWRU 数据集数据Fig.3 Part of the CWRU data set under the time series
1.2 数据预处理
由于轴承故障信号为一维时间序列的数据,要使用CNN2D 网络进行训练就必须将数据转化为二维矩阵形式。而转化的方式主要有3 种:直接转化法[20];时频图转化法[21];GAF 转化法[21]。这里考虑到单片机资源限制,采用算法最为简单的,资源占用最少的直接转化法。
直接转化法十分简单,其直接将采集到的一维数据通过滑动窗口的方式截取特定长度的数据,然后将多次截取的数据进行堆叠就可以得到一个二维矩阵数据。具体的转化方法如图4 所示。

图4 直接转化法过程Fig.4 Direct conversion process
将一段长度为400 数据转化为20*20 的二维数据图像如图5 所示。

图5 直接转化法后生成的二维图像Fig.5 Two-dimensional image generated by direct transformation method
这种方法有转化简单,计算量小等优点,不过当其振动信号的峰值数据转化为一行的时候可能会造成转化后的图像较为接近,增加了网络对于不同类型数据的特征提取的难度。
在文献[17]中指出由于CWRU 数据集是人工电火花打点模拟故障,所以其噪声程度较低,而且对于某些情况下,有噪声也可以加强对于网络的训练。而对信号进行时频的基础分析,对于使用深度学习这种基于数据驱动的方式来说作用并不大。对于数据的采样方式这里使用随机采样方式,可以尽可能的避免输入网络训练的数据存在数据相关性太强的情况。
此外为了优化不同故障情况下的数据分布,提升网络模型的准确度和训练的拟合速度,所以还需要将数据特征进行无量纲处理,即对数据进行归一化处理,这里使用的归一化方法为Min-Max 法,即
1.3 卷积网络的结构设计
将一维输入数据处理为CNN2D 网络可以处理的二维数据后,便可以进行架构网络结构然后进行网络的训练了。这里的模型基于Keras 官方例子中对于MINIST 手写识别的CNN2D 的网络结构进行改进。由输入层(InputLayer)、卷积神经网络层(Conv2D)、二维最大池化层(MaxPooling2D)、平坦层(Flatten)、全连接层(Dense)、分类器(Softmax)组成。其完整的网络结构以及数据结构的变化如图6所示。

图6 CNN2D 验证模型完整结构Fig.6 The complete structure of the CNN2D verification model
卷积神经网络层(Conv2D)的作用是自适应提取轴承故障信号的特征。选择合适的卷积核对轴承信号进行卷积,卷积核即一个权重矩阵。不同的卷积核实际就代表着轴承信号中不同的故障特征,卷积神经网络往往通过增加卷积核来提高提取故障特征的能力。卷积核为
式中:Mj为输入特征矩阵的集合;l网络层数;为第j个输入特征矩阵;为权重矩阵;blj为偏置系;f(·)为激活函数。这里的激活函数为
tanh 函数图像如图7 所示。
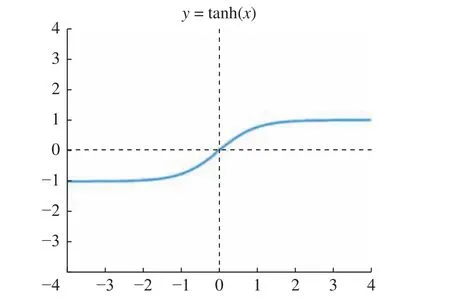
图7 Tanh 函数图像Fig.7 Tanh Function image
最大池化层(MaxPooling2D)又称为降采样层,与卷积层类似,池化层常用的有最大池化与均值池化两种,卷积核依次扫描目标数据取目标区域的最大值或平均值。其作用是提取卷积层输出的数据的主要特征,同时降低数据维度,这里采用的是最大池化函数。
式中: βlj为权重矩阵;blj为偏置矩阵; down(·)为降采样函数;fmax(·)为最大池化函数。
全连接层(Dense)将池化层提取的故障特征进行分类,则
式中:l为网络层序号;wl为权重向量;xl为一维特征向量;bl为偏置向量。
分类器(Softmax)的数学模型为
式中:wj为权重向量,表示第i个样本属于j类故障模式的概率。取最大值进行分类。
该模型的具体参数设置如表3 所示。
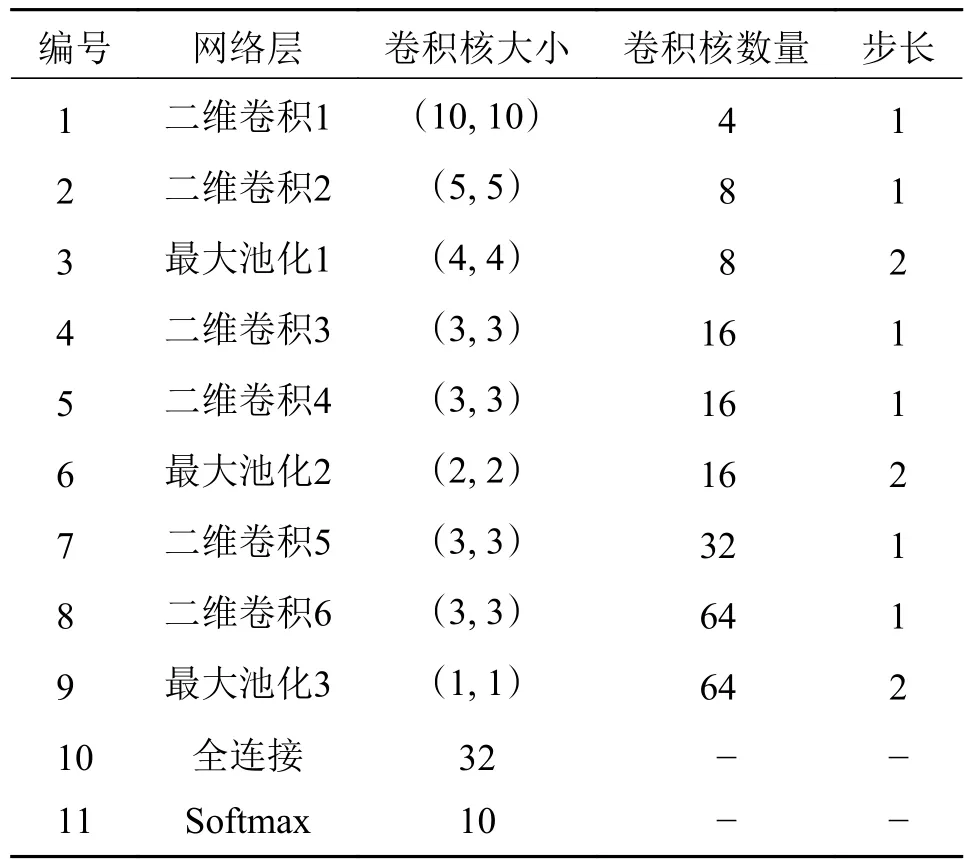
表3 CNN2D 模型参数Tab.3 CNN2D model's parameters
1.4 网络结构的验证
网络模型的训练使用专业深度学习工作站,硬件配置为64g 内存;CPU 为Inter(R) Xeon(R) E5-2620 v4 双核2.1 GHz;GPU 配置为双卡Tesla P100 250 W 16 GB。使用基于Tensorflow 深度学习框架的Keras 工具进行网络架构和网络训练。Kearas 是由Python 语言编写的开源神经网络学习库。Keras提供了强大的神经网络的API 库,采用模块化编程,代码编写量小,是深度学习中使用较多的模型之一。训练与验证的准确度如图8 所示。

图8 CNN2D 改进模型训练与验证的准确度Fig.8 The CNN2D improved model’s accuracy of training and verification
为验证该CNN2D 模型的有效性,对比了CNN1D的基准模型[22];CNN2D 基准模型,激活函数采用Relu 函数[23],CNN2D 基准模型,激活函数采用Tanh 函数[24];与改进后的该模型。对这些模型进行对比训练和验证。性能比较如表4 所示。

表4 CNN2D 改进模型与其余验证模型性能比较Tab.4 Performance comparison between CNN2D improved model and other validated models
2 神经网络架构在单片机平台上的部署
为了使IFD 在生产过程中大量使用,就必须寻找低成本小型化的解决方案。能够将智能神经网络部署到单片机中无疑是非常有吸引力的方案。这里将前面设计的CNN2D 改进模型通过CubeAI 网络结构部署工具部署到STM32H743VI 单片机上。
2.1 单片机硬件平台
单片机硬件平台选用WeAct Studio 开发的STM32H743VI 核心板。STM32H743VI 为带DSP和DP-FPU 的高性能ARM Cortex-M7 MCU,具有2 MB Flash、1 MB RAM、480 MHz CPU、ART 加速器、一级缓存、外部存储器接口和大量外设。还提供3 个ADC,两个DAC,两个超低功耗比较器,一个低功耗RTC,一个高分辨率计时器,12 个通用16 位计时器,两个用于电机控制的PWM 计时器,5 个低功耗计时器。
WeAct Studio 的STM32H743VI 核心板主要的接口有4 Pin 2.54mm SW、USB C (type C)、MicroSD TF、8Bit DCMI、User Key K1 (PC13)、NRST Key、BOOT0 Key 等。核心板上有8MB SPI Flash, 8MB QSPI Flash 作为单片机的外存。
2.2 单片机软件配置与网络部署
通过CubeMX 完成对单片机的配置。CubeMX为ST 官方推出的一款图形化的STM32 配置工具,可以非常轻松地配置STM32 微控制器和微处理器。配置STM32 的时钟树、配置外围设备(例如GPIO 或USART)和中间件堆栈(例如USB 或TCP /IP)等,其直观的GPIO 配置。CubeMX 带有功耗计算器功能,并且可以十分方便的导出为各种主流的工程文件,包括初始化代码工程,包含:EWARM、MDK-ARM、 TureSTUDIO 、 SW4STM32 等。STM32H743VI 的管脚图如图9 所示。

图9 STM32H743VI 芯片管脚图Fig.9 Pin diagram of STM32H743VI
首先,进行初级配置。设置核心板上的LED 灯和自定义按键,主要是为了方便我们的调试过程。PB14 和PB15 是USART1 串口通信接口。详细引脚的设定说明如表5 所示。

表5 芯片相关引脚设定说明Tab.5 Chip-related pin setting instructions
其次,由于在代码编写过程中对于输入数据设定的全局变量会占用占用较大的栈空间,所以还需要通过CubeMX 将最小栈分配空间设置为0X1000。
最后,使用CubeMX 工具对芯片的时钟设置完成。将高速外部时钟设置为400 MHz,低于芯片最快运行频率的480 MHz。
网络部署采用CubeMX 的AI 扩展包CubeAI。通过CubeAI 将预训练的神经网络进行转换生成优化库集成到项目中。将CWRU 轴承数据集的测试数据通过串口传入单片机。下载并安装CubeMX内提供的CubeAI 6.0 插件,然后将改进CNN2D 模型导入插件中,自动处理和量化工作完成后,便得到了一个包含参数和激活函数权重、函数结构文件在内的神经网络C 语言库,详细库文件结构见表6。
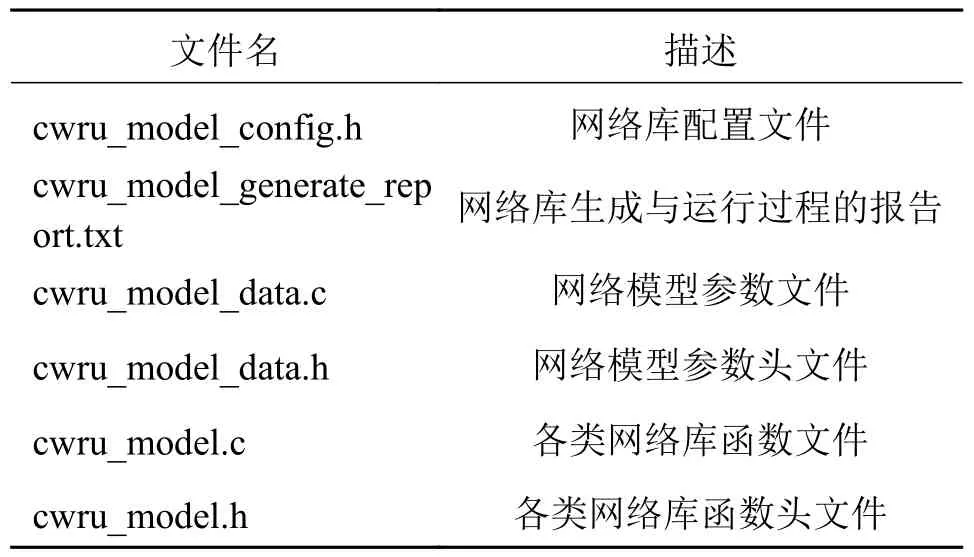
表6 库文件结构Tab.6 Structure of library file
导入后可以选择对权重和参数进行压缩和量化,但是会降低模型精度,可以根据实际情况考虑,本设计由于单片机资源足够,所以不对网络模型进行压缩和量化。
导入模型后,其网络参数复杂度为1 238 380 MACC,MACC(Multiply-accumulate operations)用以描述神经网络的模型复杂度,其代表网络计算中先乘起来再加起来的运算次数。其具体的资源消耗如表7 所示。

表7 网络模型资源消耗Tab.7 Resource consumption of network model
虽然输入变量和中间变量的初始化和定义还需要占用系统资源,但是相较于STM32H743VI 芯片的2M FLASH 和1M RAM 来说资源占用完全无太大影响。经过实测,该改进CNN2D 网络模型可以实现对于数据集中的10 种故障诊断准确率达到98.90%,且网络参数总量仅为36 390,相较于前面未优化的CNN2D 网络模型准确率提升了3.8%,而网络参数总量下降了36.66%。平均每次诊断运行时间为21Tick 换算后则为20 ms 左右,耗时在应用中满足需求。
3 结束语
本文主要验证了深度学习对于工业中的轴承故障诊断的可行性,并且可以通过调试网络结构得到较高的诊断准确度,另外验证了对于单片机这样的嵌入式设备中,部署神经网络进行深度学习的可行性,这是对于现在的TinyML 这个新兴领域的初步探索,部署过程中得到的一些数据可以作为之后相关应用的基准参考。
主要存在的问题是,由于条件限制,设计的改进CNN2D 模型对于实际工业应用中的高噪声环境下的数据训练是否还能有较高诊断准确度无法验证。根据相关领域的最新研究方向,对于第一个高噪声环境的诊断问题,现在有较多的相关研究关注这个问题。论文[25]中提出的使用深度残差收缩网络针对于高噪声环境下的高精度故障诊断,其主要是利用深度残差收缩网络的抗噪特性实现。
其次,对于整个流程过程的优化加强其鲁棒性,可以自动的处理一些串口传输过程中出现的问题。进一步优化流程和优化模型都需要以后的研究中去进一步做实验验证各种方案。
