基于非定长编码和滑动窗口的隐私保护记录链接方法
2024-02-29叶晓东赵迎迎孙永奇赵思聪刘真
叶晓东,赵迎迎,孙永奇*,赵思聪,刘真
(1.北京交通大学计算机与信息技术学院,北京 100044;2.交通大数据与人工智能教育部重点实验室,北京 100044;3.北京航天晨信科技有限责任公司,北京 102308)
0 引言
跨不同数据库的信息融合已成为银行、医疗、国家安全等不同应用领域进行决策活动的重要手段[1]。从多个数据库中识别和链接对应于同一实体对象的类似记录被称为记录链接,其可促进应用领域的高效数据分析,从而提高领域决策的准确性。目前,越来越多的记录链接操作发生在跨组织数据库中用于识别来自不同组织数据库的相似记录,以针对同一实体对象进行信息补充[2-4]。例如,通过链接银行和保险公司持有的数据库可以帮助生成更为完整的用户画像,从而更好地为用户提供个性化服务。然而,被链接的数据库中往往存储着用户的敏感信息,且用户不希望这些敏感信息在参与链接的不同组织间共享[5-6]。
隐私保护记录链接(PPRL)[7]技术可以实现跨不同数据库的记录链接计算,并且不会在组织间共享包含任何敏感信息的数据库实体信息。在PPRL 计算中,会对数据库中各实体信息进行编码或加密来生成各实体信息对应的隐私保护记录,以用于跨数据库的记录匹配计算。另外,PPRL 要求参与匹配计算的任何组织或其他组织都不会破坏被链接数据库中代表实体信息的记录。PPRL 中普遍利用布隆过滤器(BF)[8]进行编码计算。BF 编码具有实现简单且能有效计算记录间相似性的优点,被广泛应用于许多实际PPRL 的计算过程[9-10]。然而,已有研究表明BF 编码极易受到隐私攻击[11-12]。
本文提出一种基于非定长编码和滑动窗口的隐私保护记录链接技术,简称为VSW 方法,基于VSW实现跨数据库的隐私保护记录链接计算。本文的主要工作如下:
1)提出一种非定长编码的隐私保护记录生成方法,通过对实体信息进行非定长编码来隐藏位数组的频率信息,从而避免频率攻击。
2)提出一种基于滑动窗口的记录链接方法,利用快速过滤策略仅通过简单计算即可过滤大部分不匹配的记录,从而使记录链接计算更加高效。
3)提出一种基于双向滑动窗口的精确匹配计算方法,以实现不同记录的精确匹配并进一步提高记录链接计算的效率。
4)在公开数据集上进行实验,以验证VSW 方法的准确性和安全性。
1 相关研究
PPRL 技术的提出使跨不同数据库的实体信息整合被广泛应用于诸多领域,有助于各领域为用户提供更加个性化的服务。目前,PPRL 主要包括基于典型BF 编码、基于加固BF 编码的PPRL 技术以及其他的PPRL 技术。
1.1 基于典型BF 编码的PPRL 技术
目前,典型的BF 编码技术被广泛应用于PPRL计算中,用于生成被比较数据库的隐私保护记录。BF 是一种由一个长度为mbit 的位数组与k个独立的哈希函数构成的能节省空间的数据结构。BF 位数组的初始长度为0,当插入元素时,该元素经哈希函数执行k次哈希计算产生k个哈希值,并以哈希值作为位数组中的下标将所有对应的比特值由0 置为1。在基于BF 的PPRL 中,通常从实体信息中提取qgram 再将其散列成BF 编码。由于其编码效率和属性值的近似匹配,BF 几乎已成为PPRL 的编码标准。这里q-gram 是q位相邻字符对,例如“jack”,其q=2的q-gram 列表为[‘j’,‘ja’,‘ac’,‘ck’,‘k’]。
然而,由于BF 编码是由基于实体信息的q-gram映射到比特位置而得到的,攻击方可以学习关于如何执行编码的信息,使编码值被重新识别。此外,在编码数据库中频繁出现的敏感值可能导致BF 中的频繁比特模式被识别,甚至可以使用模式挖掘技术找到单个频繁q-gram。因此,BF 编码方式容易遭受攻击,存在数据库实体信息被攻击泄露的风险。
1.2 基于加固BF 编码的PPRL 技术
为了提高安全性,近年来研究人员已提出许多加固的BF 编码技术应用于PPRL 中。如文献[13]提出一种基于向量折叠和逐位XOR 运算相结合的BF加固技术。首先将BF 编码均分成b1和b2两半,然后b1和b2对每个位应用逐位XOR 运算并组合成新的加固BF 编码。这种对应位置的逐位XOR 运算可确保2 个原始位置的输入值不可能被恢复,有效提高了安全性。加盐(Salting)是另一种加固BF 编码技术,由文献[14]提出,在每个q-gram 被散列之前为其添加一个额外的(字符串)值来避免对BF 的隐私攻击,这些字符串通常基于一些不易改变的属性值确定,如出生年、出生地等,使得大多数频繁出现的q-gram 与盐值连接在一起,会变得不那么频繁。
另外,有研究人员利用Markov 链为频繁出现的q-gram 随机添加额外的q-gram,有效避免了频率攻击[15]。该方法对于q-gram 中每个独特的q随机选择c个其他q-gram,基于它们在q之后出现的概率与q一起编码,其中,c是在加固技术中使用的链长参数。但是,当c值较大时会降低链接质量。
Rule 90[16]是一种一维细胞自动机,规则比较简单,有一个一维单元阵列(开或关),每个单元的下一个状态是该单元的2 个相邻单元的异或。基于它的不可逆性,文献[15]提出一种使用Rule 90 作为BF 编码的强化技术。
文献[17]使用滑动窗口和重采样的方法来选择原始BF 中的某些比特,并对这些选择的比特进行逐位XOR 运算生成新比特值,从而提高安全性。
1.3 其他PPRL 技术
除BF 编码外,已有许多新型编码方式被成功应用于PPRL 中。文献[18]提出一种基于最小哈希的制表方法(TMH),在小规模数据集上的实验结果表明,TMH 方法在提高匹配精确率的同时能有效保护数据隐私。但与BF 编码相比,这种制表哈希编码方法的计算复杂度较高,因此不适用于大数据规模的PPRL 计算。文献[19]提出一种新的编码方法,使用两步散列过程将敏感值编码为整数集。这种方法实现了更高质量的相似性计算,且能有效抵御频率攻击,但是无法抵御相似性图攻击。
此外,文献[20]提出了两种新的隐私保护字符串匹配方法:第一种方法通过改变q-gram 的顺序来提高编码的私密性,q-gram 的顺序移位隐藏了它们在字符串中的实际位置,这使得基于位置的频率分析更加困难;另一种字符串匹配方法(SRA)将每个q-gram 编码成固定长度的位数组,并在编码q-gram列表的位数组的开头和结尾位置分别添加随机位数组,这种操作可以隐藏实际的子字符串位置和编码字符串的长度,从而提高了对手识别已编码到位阵列中的原始字符串值的难度。然而,SRA 方法的时间开销较大,且固定长度的q-gram 编码方法会带来比特模式被识别的风险。另外,SRA 方法只能进行子字符串的匹配,不能用来计算2 个字符串的整体相似性,因此不能用于隐私保护记录的链接计算。
针对BF 编码对q-gram 位置不敏感以及容易受到频率攻击的问题,本文对SRA 方法进行改进,提出一种基于非定长编码和滑动窗口的隐私保护记录链接方法VSW。该方法通过对实体信息进行非定长编码来隐藏位数组频率信息,从而防御频率攻击。此外,在计算2 个字符串的整体相似性时,通过基于滑动窗口的精确匹配方法提高记录链接效率。
2 问题定义
不同用户持有的数据库中都存储了一定数量的实体信息,各实体信息都对应唯一对象,而位于不同数据库的两条实体信息可能是指向同一对象。各用户希望在不向其他用户或服务器泄露本地数据库中任何实体信息的前提下实现本地数据库与其他数据库中实体信息的匹配。例如,银行数据库中各实体信息记录着用户的姓名、身份证号、银行卡号、存款、交易记录等,保险公司数据库中各实体信息记录着用户的姓名、身份证号、投保类型等,银行和保险公司就可以通过匹配它们数据库中的实体信息得到用户更完整的画像。
上述应用都可以基于所提VSW 方法来安全、高效地实现记录的精确链接。令A、B 为2 个不同的用户,DA、DB为A、B 各自持有的数据库,则VSW 方法基于A、B 的协商秘密和非定长编码计算得到DA、DB对应的隐私保护记录索引WA、WB,并对其中的记录执行匹配计算,为各用户返回一个匹配的记录链接列表LA、LB。其中,相关定义如下:
定义1(隐私保护记录索引)DA或DB中每条实体信息都唯一对应着索引中的一条记录,其由记录id 和一串定长且仅包含0 和1 的字符串构成。

图1 相关定义示例Fig.1 Examples of relevant definitions
定义2(匹配记录链接列表)对于匹配记录链接列表LA、LB内同一位置的2 个元素ida、idb,它们在WA、WB内分别对应的记录ra、rb的相似度大于阈值dice∈[0,1]。
当WA、WB内2 个记录ra、rb的相似度大于dice 时,则认为它们对应的实体信息是匹配的。如图1 所示,LA、LB为DA、DB的匹配记录链接列表,则DA、DB中idi、idt标记的2 条实体信息匹配,且WA、WB内idi和idt标记的2 个记录相似度值大于阈值dice。
在隐私保护记录链接计算过程中,使用Dice 系数作为链接标准,其为一种计算不同集合相似度的度量函数,取值范围为[0,1]。Dice 系数具体计算公式如下:
其中:|X∩Y| 是集合X和Y之间的交集;|X|和|Y|分别表示X和Y中元素的个数。
3 VSW 方法
本节将详细描述利用VSW 方法执行隐私保护记录链接的计算过程及算法实现。
3.1 VSW 方法概述
基于VSW 的隐私保护记录链接方法包括2 个阶段,即基于非定长编码的隐私保护记录生成和基于滑动窗口的记录链接计算,分别简称为记录生成阶段和记录链接阶段。图2 所示为VSW 方法的整体框架。
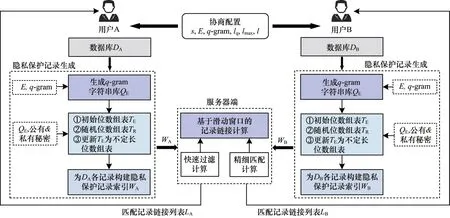
图2 VSW 方法整体框架Fig.2 Overall framework of VSW method
2 个阶段的详细计算过程如下:
一个课堂的精彩在于看到这些去回应,重新让这些断裂的点连续起来,形成一种内在的节奏和旋律。这种节奏和旋律是一种和谐的声音。如果没有这些矛盾,也就没有和谐的声音,只是一些平淡、索然无味、形式上看似和谐的东西。但只有所有的矛盾和冲突背后的张力,才能凸显出和谐的美,就像我们看到光是因为有黑暗一样。
1)记录生成阶段
用户A 和B 首先进行协商配置,包括协商公有秘密s、字符表E的内容、q-gram 生成方式、位数组的初始及最大长度lmin和lmax以及记录长度l,然后各用户执行如下步骤:
(1)基于协商的字符表E及q-gram 生成各自的q-gram 字符串库QE。
(2)基于公有秘密s为QE中各q-gram 字符串生成定长位数组表TE。
(3)基于私有秘密进行定长编码,构建随机位数组表TR。
(4)对初始的位数组表TE进行非定长编码,将其转换为非定长位数组表。
(5)基于TE、TR为DA和DB中的对象构建隐私保护记录索引WA和WB。
2)记录链接阶段
服务器得到用户A、B 发送的隐私保护记录索引WA、WB后,执行如下步骤进行记录链接计算:
(1)首先取出WA中的一条记录ra,然后与WB中各记录rb进行快速过滤计算,若rb一定不与ra匹配,则将rb快速过滤掉。
(2)若ra与rb可能匹配,则 继续针对ra与rb执行精确匹配计算,计算两者相似度并判断是否大于阈值,若大于阈值,则分别将两者id 存入匹配记录链接列表LA、LB中。
3.2 基于非定长编码的隐私保护记录生成
隐私保护记录生成的目的是将用户持有的各实体信息加密编码为一段具有固定长度的位数组。首先构建一个字符表E,E中包含实体信息中可能出现的所有字符。然后通过字符表E生成包含所有q-gram 字符串的表QE,并根据QE构建2 个位数组表TR和TE。其中:TR表内存储着随机位数组,任意用户的TR表都不与其他所有位数组表相交,防止虚假匹配;TE存储着QE内所有q-gram 字符串以及对应的编码。由于使用定长编码时存在被逆推出q-gram 列表长度的风险,因此本阶段采用非定长编码构建TE·,表内各位数组长度在[lmin,lmax]内变化。有研究表明,足够大的lmin可以有效抵御频率攻击,表1 给出了根据Stirling 公式计算的不同情况下的lmin最优值,其中|E|为字符表E中的元素个数[20]。

表1 不同情况下的lmin最优值 Table 1 The optimal values of lmin in different ituations
在记录生成过程中,各实体信息的q-gram 列表通过TE表编码成位数组(称为有效位数组),并将TR中的随机位数组填充到有效位数组的首、末端位置,使生成的隐私保护记录长度相同。这种填充方法可隐藏有效位数组的位置,从而提高记录的隐私保护程度。
在算法1 的输入中:D为一个包含所有实体信息的索引,其各元素都为一条实体信息的q-gram 列表;s为所有用户协商的公有秘密;sd为各用户持有的私有秘密。初始化3 个数组TE、TR和W后,基于字符表E和设置的q-gram 长度q,利用函数BldQgramSet()构建一个包含所有可能q-gram 信息的列表QE。在第5 行~第8 行,对于QE中的每个q-gram 字符串qE,利用函数BldBitArr()构建长度为lmin的位数组bq,并将qE及其bq存入TE。在第9 行~第14 行,当TR长度不大于TE长度时,基于用户的私有秘密sd构建长度为lmin的随机位数组bt,并判断bt是否存在于当前及其他所有用户的TE和TR表中,若不存在,则将bt存入TR表。在第15行~第18 行,对TE中各qE及其bq,利用BldExtBitArr()为qE生成额外随机位数组(长度≤lmax-lmin)并将其补充至bq末尾位 置得 到,并 用更 新TE[qE]的 值。在 第19 行~第26 行,针对索引D中存储的每条实体信息,即id→gramL,通过搜索TE表,为其生成有效位数组并存入temL 中。然后基于TR利用BldPPRBitArr()将有效位数组(长度为len(temL))补充成长度为l的隐私保护记录bf,并将其存入索引W中。最后输出生成的隐私保护记录索引W。

图3 举例说明了隐私保护记录生成的过程。首先基于用户约定的共有秘密,对QE中各字符串qE进行加密并生成长度为6 的位数组bq,构建初始定长的位数组表TE;然后对表TE进行非定长计算得到新的非定长位数组表TE,如图3 左侧所示。对于DA中的记录“jack”,首先计算其q-gram 表[_j,ja,ac,ck,k_];然后搜索非定长的TE表,将各实体信息编码为长度不同的有效位数组“100010110001001001001100101 010110100011110100101”(有效长度为48);接着将TR中的随机位数组“101101”和“101010”分别填充在有效位数组的首、末端位置,从而得到一个长度为60的隐私保护记录;最后将记录id、隐私保护记录和有效位长度存入隐私保护记录索引WA中。

图3 隐私保护记录生成示例Fig.3 Example of privacy protection record generation
3.3 基于滑动窗口的记录链接计算
链接计算的目标是根据为用户生成的隐私保护记录索引WA和WB,进行两索引内记录的链接计算,分别为用户生成一个匹配的记录链接列表LA、LB。为提高记录链接计算的效率,在2 条记录比较过程中,以其中一条为基准,设计快速过滤计算,过滤掉一定不匹配的记录,并对未被过滤的记录执行精确匹配计算,进一步判断记录是否匹配。在计算过程中同时采用基于滑动窗口的计算策略,根据基准记录设置定长窗口,并使其按特定步长进行滑动比较,进一步加速匹配计算过程。
用户A 和B 的隐私保护记录链接计算过程如算法2 所示。输入为用户的隐私保护记录索引WA和WB以及给定的相似度系数dice,输出为各用户的记录链接列表LA和LB。对WA中的每一条记录ra,遍历WB中每条记录rb并判断2 条记录是否匹配。首先,进行快速过滤计算(第5 行),快速判断rb是否与ra一定不匹配,若一定不匹配,则RecFiltComp()返回值为false,否则返回true;然后,如果返回值为true,则继续精确判断计算(第7 行),即执行函数DetailComp(),并 返回ra和rb的相似度系 数值v;最后,若v≥dice,则2 条记录链接成功并将各自的编号ida和idb分别存入列表LA和LB中。

3.3.1 快速过滤计算
快速过滤计算用于快速判断WB中某一记录rb是否一定不与WA中记录ra匹配。由于实体信息对应q-gram 列表的长度以及q-gram 对应位数组长度均存在最小值,因此可以计算出隐私保护记录中有效位数组的最短长度。当最短有效位超过50%时,记录的中间部分总会有一个子集,其中的位数组均是有效位,在这部分进行初步筛查可以有效避免随机位数组带来的干扰。对于ra和rb这2 个需要链接的记录,在ra的绝对有效位数组上进行滑动窗口查找,对与rb不匹配的部分进行计数。当ra和rb的不匹配位数大于最大不匹配位数时说明不匹配(如图4 所示),其中最大不匹配位数可以通过dice 系数计算得出。通过这种方法,大部分不匹配的记录会被快速淘汰。
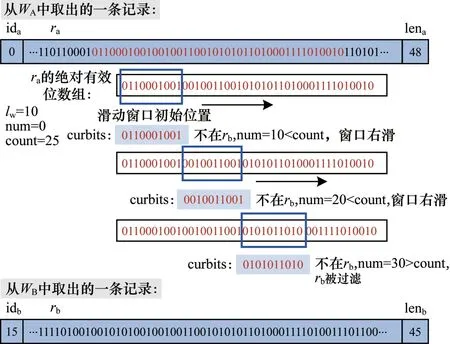
图4 快速过滤计算示例Fig.4 Example of computation of rapid filtering
算法3 给出了快速过滤函数RecFiltComp()的详细计算过程。第1 行根据2 个记录各自的有效位长度lena和lenb及指定的相似度系数dice 计算ra和rb的最大不匹配位数count;第2 行~第3 行获取ra的绝对有效位数组workbits 并初始化一个长度为lw的滑动窗口;第5 行~第14 行从字符串workbits 的第0 位开始以lw为步长滑动窗口,curbits 为位于当前窗口位置的字符串,若curbits 位于rb内,则更新rb,即将从0 位到当前curbits 的所有字符从rb中删除,否则,累加不匹配字符串数并判断其是否大于count,若大于,则2 个记录一定不匹配,返回false。当窗口滑动到workbits 的最末尾位置时num ≤ count,则返回true并结束计算。

3.3.2 精确匹配计算
对于通过了快速过滤的记录rb,继续以记录ra为基准进行精确匹配以计算2 个记录的相似度。精确匹配基于双向滑动窗口策略执行,当定位到一段同时位于ra、rb内的有效字符串时,以有效字符串位置为参考构建沿左、右方向且长度不同的滑动窗口以确定最长的匹配字符串。如图5(a)所示,首先设置长度为lw的滑动窗口,从基准记录首位开始以步长step 向右滑动,以定位窗口字符串curbita在rb的位置;然后分别以匹配字符串curbita的头、尾为起点,对ra、rb执行双向不等长窗口的滑动搜索,并动态更新匹配字符串长度直至满足结束条件,如图5(b)所示。精确匹配是从基准记录的首位开始向右滑动窗口来定位有效字符串,滑动步长step≤窗口长度lw。为了能保证精确匹配同时尽可能地提高计算效率,对于ra、rb内有效字符串的左侧字符串,分别以长度1 和步长1 向左滑动窗口搜索,对于右侧字符串,则以步长为lw的滑动窗口向右快速搜索。

图5 精确匹配计算示例Fig.5 Example of exact matching calculation
算法4 给出了针对记录ra和rb的精确匹配计算过程。首先初始化滑动窗口及滑动步长lw和step,从ra第0 位开始移动并获取位于窗口内的字符串curbita,若curbita不位于rb内,则以步长step 更新位置值i,否 则获取curbita在rb内的起始位置ps;然后第10 行分别以i和ps为参考位置进行ra和rb内的左移计算(步长为1)得到左匹配位数lecount,第11 行分别以i和ps为参考位置进行ra和rb内的右移计算(步长为lw)得到右 匹配位 数ricount,loca和locb分别为ra和rb内滑动窗口的新起始位置;最后更新rb及匹配的位数组总数sum,同时计算ra和rb的相似度值v。

4 位置敏感性与安全性分析
4.1 位置敏感性
位置敏感性是指算法对于仅存在元素顺序差异的q-gram 列表是否会产生不同的编码。BF、TMH 等方法采用哈希映射的方式进行编码,编码结果仅与q-gram 和哈希函数有关,而与q-gram 顺序无关,因此无法区分具有不同元素顺序的q-gram 列表。例如,对于字符串“330310”和“310330”,由于2 个字符串生成的q-gram 列表元素相同,BF 等方法将生成完全相同的隐私保护记录,无法区分2 个字符串。而VSW 方法是按照顺序进行编码,保留了位置信息,在上述情况下,只会识别到“310”,这种位置敏感性使其能获得更高的匹配精确度。
4.2 安全性
本文假定服务器和用户之间是诚实且好奇的(honest-but-curious)[21-22]。诚实是 指用户 不会伪 造数据,服务器也不会对参与者上传的数据进行攻击、破译或逆向工程等恶意操作。好奇是指服务器方对用户的原始数据有一定程度的好奇,并且可能会绕过一些安全措施直接访问用户的原始数据。因此,本文约定用户不能将字典和秘密提供给服务器,用户间不能直接或通过服务器访问对方的隐私保护位数组。这时服务器虽然持有所有用户的隐私保护记录索引和索引中每个位数组的有效位数,但是不知道有效部分起始位置,且没有用户协商的秘密,所以无法破解位数组信息。由于使用非定长编码,服务器即使知道记录的有效位长度也无法推测出对应q-gram 列表的长度。用户之间虽然在协商过程中拥有相同的非定长位数组表TE,但是无法获得对方基于私有秘密生成的随机位数组表TR,从而保护了用户的数据隐私。
目前对于BF 的大多数攻击是通过分析BF 集合中位模式的频率和相应q-gram 频率,从而获得qgram 与某个数值模式频率之间的相关性,BF 的非均匀Hamming 权重分布容易遭受频率攻击[23]。而本文提出的基于非定长编码的VSW 方法在隐私保护记录生成的过程中使用随机函数,确保了记录服从均匀分布,非定长也使得相较于SRA 方法更难被攻击者分析频率和有效位长度,且通过在有效位数组的前、后端添加随机位数组隐藏了有效位置,从而有效防御了频率攻击。
基于相似图的PPRL 攻击[24]是将纯文本值生成的图与编码值生成的图进行比较,目的是基于节点特征确定纯文本值和编码值之间的对应关系。相似图攻击的成功与否取决于2 个相似图的可比性,因此,常规的计算编码之间精确相似性的PPRL 方法都可能受到相似性攻击。VSW 方法也可计算相似性,但是由于在有效位数组前后添加了随机位数组,使得纯文本值和编码值之间没有了对应关系,因此也可以防御相似图攻击。
另一种攻击方式是通过对编码进行聚类提取出特定特征[25],例如常见的q-gram 组合。为了分析这种攻击的有效性,需要考虑隐私保护记录的位分布(bit distribution)。有研究表明,如果编码具有接近多维正态分布的分布,则任意聚类方法都不会产生准确且分离良好的聚类,从而使其抗攻击能力更强[26]。在第5.2 节,将通过比较隐私保护记录与正态分布的接近程度来评估VSW 方法抵御聚类攻击的安全性能。
5 实验结果与分析
本节针对VSW 方法进行实验测试和验证,并对实验结果进行详细分析。本节实验包括两部分:第一部分对VSW 方法进行详细测试,确定使得VSW性能达到最佳的参数;第二部分基于调优参数对比测试VSW 方法和其他3 种方法的性能。
5.1 实验数据及评价指标
5.1.1 实验数据集及实验环境
本节实验采用的数据集为北卡罗来纳州选民登记名单(NCVR),该数据集中的记录是真实的个人信息,可从 ftp://alt.ncsbe.gov/ data/上下载。
实验的硬件环境为:Intel Core i7-6700 处理器,主 频3.40 GHz,4 核,16 GB 内 存。软件环境为:Windows 10 操作系统(64 位),PyCharm 开发平台,所有算法均采用 Python 语言实现。
5.1.2 评价标准
实验通过召回率(RRecall)、准确率(PPrecision)和运行时间评价所有算法的运行结果。准确率为在匹配的记录中正确匹配记录数量的比例,如式(2)所示;召回率为正确匹配记录占全部应匹配记录数量的比例,如式(3)所示。
其中:TTP是正确匹配的记录数量;FFP是错误匹配的记录数量;FFN是应该匹配但未能匹配的记录数量(即正类预测为负类的数量)。
5.1.3 参数优化
对有效位数组最短长度、滑动窗口大小、滑动窗口步长分别进行测试,数据集大小为 5×103条记录。为了测试链接质量,模仿现实生活中可能出现的录入问题对数据集中的实体信息进行随机修改,具体修改包括:
1)以1/20 的概率转置2 个相邻字符。
2)以1/60 的概率删除字符。
3)以1/60 的概率将一个字符加倍。
4)以1/60 的概率用键盘上的相邻字符替换某字符。
表2 展示了有效位数组的最短长度变化时VSW方法的时间消耗及对快速过滤策略错误率的影响,其中错误率是指一条不匹配的记录未被成功过滤掉的概率。由表2 可见,当有效位数组的最短长度增大时,快速过滤计算的错误率逐渐降低。但当有效位数组的最短长度越大时,每条记录有效位长度的波动范围会越小,这会影响q-gram 列表长度的取值区间大小,进而降低记录链接的安全性。因此,在第5.2 节的对比实验中将有效位数组的最短长度设定为整个记录长度的60%。
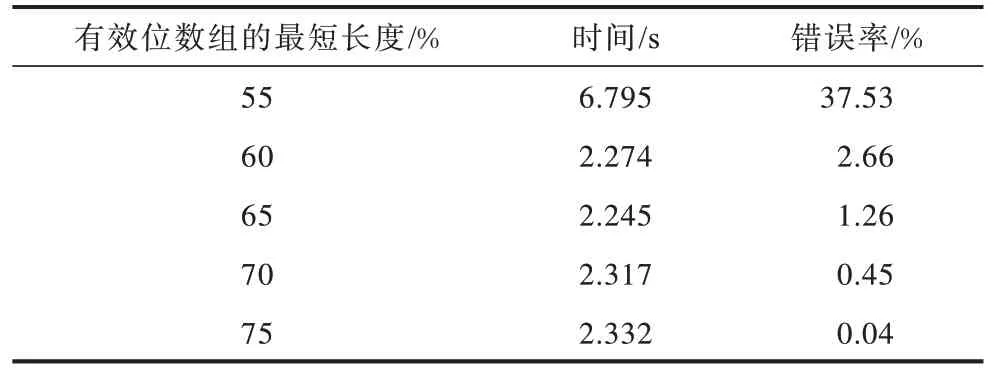
表2 有效位数组最短长度对计算效率和错误率的影响 Table 2 Effect of minimum length of effective bit array on computational efficiency and error rate
表3 中展示了精确匹配计算中,滑动窗口长度变化时对精确匹配计算的时间消耗、召回率以及准确率的影响,其中设置步长与滑动窗口长度相同。由表3 可见,当滑动窗口长度变小时,准确率不变,均为100%,召回率在逐渐增大,但时间消耗也在变大。为平衡实时性和召回率,在第5.2 节的对比实验中将滑动窗口长度设定为12 bit。
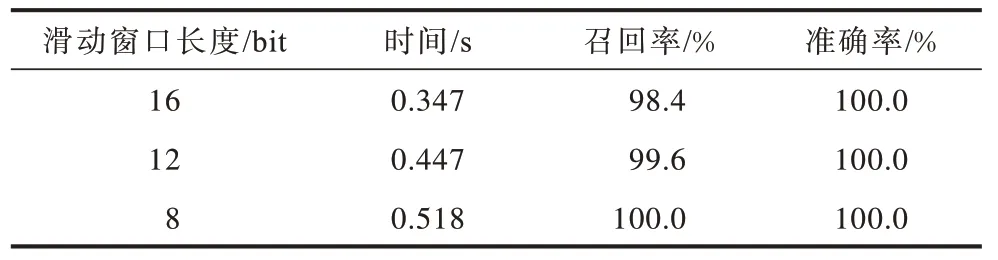
表3 精确匹配中滑动窗口长度变化对算法的影响 Table 3 Effect of sliding window length changes on algorithms in accurate matching
表4 中展示了精确匹配计算中,滑动窗口滑动步长变化时对精确匹配计算的时间消耗、召回率以及准确率的影响,其中设置滑动窗口长度为12 bit。由表4 可见,当滑动步长增大时,准确率仍保持不变,均为100%,召回率在降低,但时间消耗逐渐降低。为平衡实时性和召回率,在第5.2 节的对比实验中将滑动窗口步长设定为8 bit。
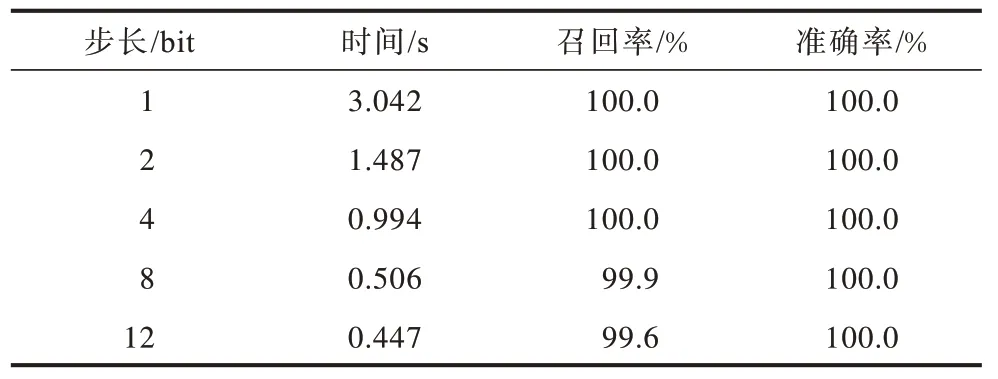
表4 精确匹配中滑动窗口步长变化对算法的影响 Table 4 Effect of sliding window step size changes on algorithms in accurate matching
5.2 VSW 方法与其他方法的对比实验
本节将从编码和匹配时间、匹配精确度以及抗攻击性等方面,对VSW 方法与其他3 种典型方法(BF、TMH、SRA)进行对比实验。在对比方法中:第1 种是典型的BF 编码方 法[8],参数设置为l=1 024 bit,k=30,q=2;第2 种方法是文献[18]提出的TMH 编码方法,实验中使用8 个制表键,每个键长度为64 bit,生成记录长度为l=1 024 bit;第3 种方法SRA 本身不具备记录链接功能,本文通过累加其计算出的匹配位数进行相似度计算。VSW 方法中记录长度l=1 024 bit,窗口长度为12 bit,滑动步长为8 bit,有效位数组长度占比最小为60%。采用非定长编码生成用户记录时,根据用户间协商的公有秘密构建非定长位数组表TE,表内各位数组长度在[16,20]内变化,如果变化范围过大,会导致隐私保护记录匹配精度降低。
1)编码和匹配时间
图6 展示了4 种方法在数据集NCVR 上编码计算的运行时间结果,图中横轴为数据集大小,分别包含103条、104条和105条记录,纵轴为编码计算的时间消耗,用对数表示。从中可以看出:VSW 方法与SRA 编码方法相近,只需要查找TR和TE表即可快速生成记录,在3 种规模数据下的编码计算运行时间相似,都达到了最佳;BF 和TMH 均需要进行多次函数映射,运行时间较长。

图6 数据集规模变化时4 种编码方法的运行时间Fig.6 The runtime of four encoding methods when the dataset size changes
图7 展示了单次匹配计算中4 种方法的时间消耗情况,图中纵轴为对数表示的平均查询时间。从中可以看出,在单次匹配计算中,BF 和TMH 由于只需要按位比较,因此时间消耗最少,SRA 计算的时间消耗最大,性能最差,而VSW 由于采用了滑动窗口的快速过滤和精确匹配算法,相较于SRA 大幅提升了匹配速度,但与BF 和TMH 相比仍然偏慢。

图7 4 种方法单次匹配的平均查询时间Fig.7 Average query time for single matching of four methods
2)匹配精确度
图8 展示了4 种方法相似度计算过程中编码相似度与q-gram 相似度平均差值的变化情况。其中,TMH 使用Jaccard 相似度,其他方法使用Dice 相似度。VSW 方法为了能够计算低相似度情况,只使用精确匹配。从图8 可以看出:VSW 方法相较于BF 和TMH 方法有更精确的相似度,一方面是因为哈希碰撞将不同的q-gram 散列到了相同的位置,而VSW 方法是按顺序编码,避免了哈希冲突;另一方面,BF 和TMH 不具备位置敏感性,对于仅存在元素顺序差异的q-gram 列表会产生相同的编码,而VSW 具有位置敏感性,可以达到更高的相似度计算精度。由于SRA 采用定长编码与顺序编码相结合的方式,其匹配精确度最高。VSW 方法的匹配精确度与SRA 相比略低,主要原因是VSW 使用了非定长编码,通过牺牲一定的匹配精度来提高隐私性。
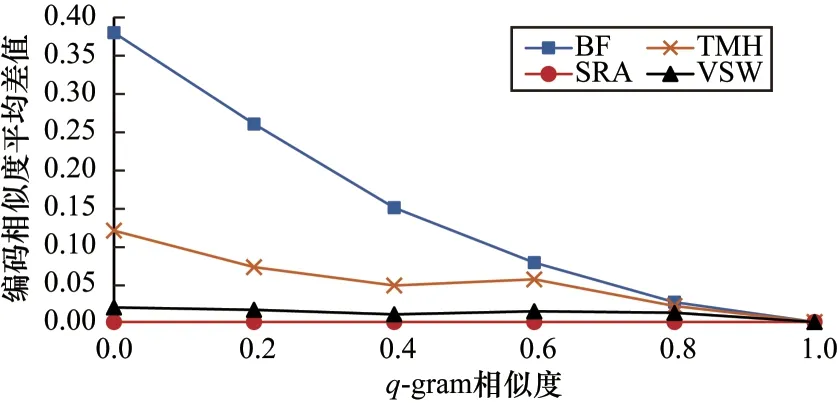
图8 4 种方法相似度计算平均差值变化情况Fig.8 The variation of average difference in similarity calculation of four methods
3)抗攻击性
为定量分析VSW 方法的抗聚类攻击能力,采用隐私保护记录与正态分布的接近程度作为评价标准[26]。将每条隐私保护记录分割成64 条16 bit 的二进制串,对其进行归一化,再通过Shapiro-Wilk 检验方法判断其与正态分布N(0,1)之间的相似性,当结果值越接近1 时,编码的分布就越类似于正态分布。表5 展示了4 种方法的抗聚类攻击能力实验结果,可以看出VSW 方法具有更高的安全性。主要原因是VSW 在非定长编码过程中使用随机函数,保证了位数组每一位0 和1 的概率相同,从而使得在本实验中的编码分布与正态分布相似,提高了防御聚类攻击的能力。

表5 4 种方法的抗聚类攻击能力对比 Table 5 Comparison of the anti cluster attack capability of four methods
6 结束语
本文提出一种基于非定长编码和滑动窗口的隐私保护记录链接方法VSW,以实现跨不同数据库实体信息的隐私保护记录链接计算。首先,利用非定长编码将实体信息加密为长度相同的位数组,为各用户构建隐私保护记录索引,该编码方式具有位置敏感性,可提高记录链接的匹配精度;然后,基于滑动窗口对生成的隐私保护记录索引进行记录链接计算,先采用快速过滤策略高效过滤掉一定不匹配的大部分记录,再对过滤得到的记录进行精确匹配计算得到记录的相似度值,其中均采用滑动窗口策略进行加速。在公开数据集上的实验结果表明,VSW方法编码效率较高且扩展性较好。在安全性方面,由于VSW 方法采用了非定长编码方式,可以有效抵御频率攻击、图攻击和聚类攻击。在隐私保护性能方面,VSW 方法也达到了较优的效果。但是,相较于BF 方法,VSW 的计算效率较差,下一步将针对该问题对VSW 的计算性能进行改进。
