基于集成学习的交通事故严重程度预测研究与应用
2024-02-29单永航张希胡川丁涛军姚远
单永航,张希,胡川,丁涛军,姚远
(上海交通大学机械与动力工程学院,上海 200240)
0 引言
近年来,随着各国政府和企业的支持,车辆不断朝着智能化方向发展。智能车辆因感知范围广、运算能力强、避免驾驶员操作错误等优势,在一定程度上提高了车辆的安全性[1],但由于违规驾驶、道路、车辆、自然条件等因素,交通事故不能完全避免。当前智能车辆更多地是关注如何去主动避免碰撞,执行一条安全且舒适的最优轨迹,而在面对无法避免的交通事故时,却没有更好的解决办法。在这种条件下,如何预测车辆在不同行驶模式下的事故严重程度并做出正确的决策,从而在一定程度上避免事故或者降低事故严重程度就显得尤为重要。
事故严重程度预测是车辆安全领域的重要研究方向之一,近年来受到了越来越多工业界以及学术界的关注。事故严重程度定义为事故造成的伤害或财产损失程度,伤害严重程度是评估安全性能的一个重要方面。事故严重程度模型构建主要分为3 类:统计模型,机器学习模型与物理模型。统计模型是事故严重程度分析常用的模型[2],可解释性好,便于分析自变量和因变量之间的关系。有序Probit模型[3-5]是研究者普遍用于事故严重程度分析的统计模型。此 外,Logit 统计学模型[6]、联合概率方法[7]、联立方程[8]、多元泊松回归[9]等方法也常应用在事故严重程度预测任务中。但使用统计模型需要预先定义一个良好的函数形式来描述碰撞发生和解释变量之间的关系,不适用于复杂问题。
与统计学习模型相比,机器学习模型更灵活,其重点关注如何设计模型或目标函数,对处理异常值、缺失和噪声数据具有更好的适应性,适用场景更广,在复杂问题上表现效果更优。例如人工神经网络(ANN)[10]、决策树(DT)[11]、支持向量机(SVM)[12]、随机森林(RF)[13]、K 均值聚类(KC)[14]均广泛应用于事故严重程度预测以及交通安全研究。然而,目前各机器学习算法性能不同,相互独立,难以优势互补,在交通事故严重程度预测任务中表现不佳。为实现更高的预测精度,一些研究者利用元学习器融合不同个体学习器预测结果,构建双层Stacking 集成学习模型,融合各学习器优势,提高预测性能[15-16]。虽然机器学习模型能够实现较好的预测精度,但是其可解释性不好,不利于调校模型参数。
相比之下,物理模型能够揭示车辆间碰撞机理,精细分析车辆碰撞全过程,但表示相对复杂。文献[17]提出两种最典型的物理模型方法,即碰撞中的速度变化方法(Delta-V)和估计车辆能量变化的等效能量速度(EES)方法。文献[18]通过进一步研究动量定理,将动量变化作为碰撞总严重程度的关键指标。
在现实场景中,人、车、路系统高度复杂,且非线性、交通事故涉及因素众多,难以采用统计学习模型与物理模型构建高精度事故严重程度预测模型。为此,本文采用泛化性能更好的Stacking 双层集成学习方法构建事故严重程度预测模型。在第1 层中综合预测表现与时间消耗确定最优基学习器组合;在第2 层中考虑到模型的复杂度与鲁棒性需求,采用逻辑回归作为元学习器,整合第1 层基学习器的分类结果,纠正各基学习器分类偏差,提高Stacking 整体模型的泛化能力和准确性。同时,为保证模型能够应用在智能车辆中,本文研究采用真实交通事故数据集NASS-CDS,提取通过摄像头、激光雷达、毫米波雷达感知处理能够获取的事故严重程度相关特征作为输入,事故后乘员最大损伤等级作为输出,完成交通事故严重程度预测模型的构建;同时通过特征重要程度分析,得到事故严重程度重要影响因素,可帮助人们更好地理解交通事故,以采取有效措施。
1 数据集预处理
1.1 NASS-CDS 介绍
本文采用美国高速公路安全局(NHTSA)公布的NASS-CDS 真实交通事故数据集[19]构建模型,解决了现有研究利用仿真数据构建事故严重程度预测模型存在车辆类型少、事故类型少等问题,有效提高预测模型在实际应用场景中的可靠性和有效性。该数据集包含1988—2015 年的代表性事故详细数据,每年研究约5 000 起撞车事故,样本充足,覆盖范围广,被广泛用于交通安全研究。数据集包含信息如表1 所示。
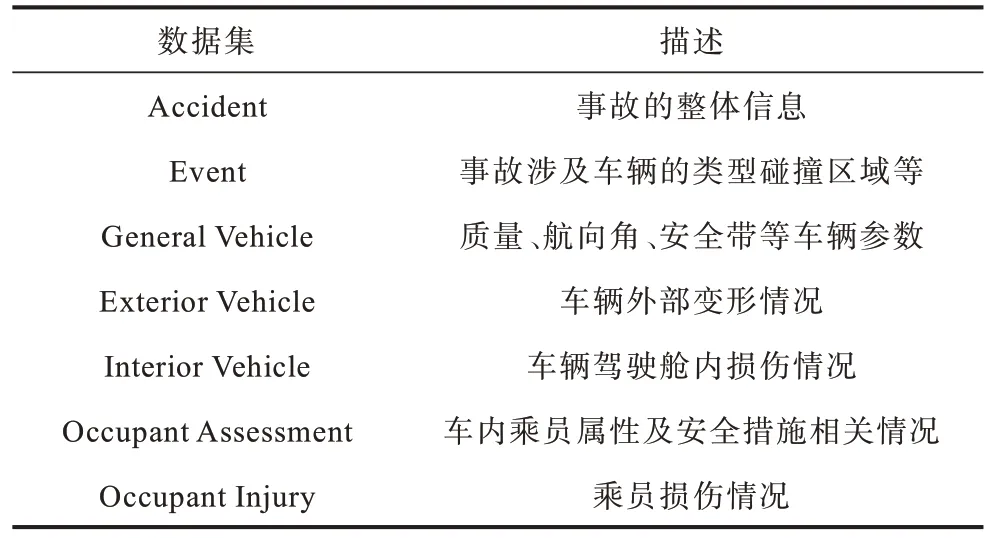
表1 NASS-CDS 数据集描述 Table 1 NASS-CDS dataset description
1.2 特征提取
为使构建的事故严重程度预测模型能够应用于智能车辆,本文提取NASS-CDS 中车辆能够通过车载传感器获取的信息作为模型特征输入。选定特征主要包括车辆特征以及道路、环境特征。初步提取的单一特征如表2 所示。

表2 初步特征 Table 2 Preliminary features
单一特征往往不能够得到最优的预测结果,在实际问题中,常需面临多种高维特征。因此,本文还提取了车辆相关组合特征,以提升模型预测准确度。车辆发生交通事故后,速度变化量越大,碰撞过程中车辆受到的冲击力越大,对车辆造成的影响也就越大。考虑到自车与目标车辆碰撞后瞬间两车可视为刚体固结,故通过动量定理可以对速度变化量进行估计,估计模型如式(1)~式(5)所示:
其 中:m1、m2表示两 车质量;v1、v2表示两 车速度;θ1、θ2表示为两车航向角;ux、uy表示事故 后两车速度;Δv1x、Δv1y表示事故后自车x、y方向上速度变化量;Δv1表示事故后自车速度变化量。
除绝对速度外,车辆间相对速度也是重要考虑的因素。本文仅考虑两车之间交通事故情况,引入相对速度特征,计算公式如式(6)所示:
其中:v1x、v2x表示两车沿x方向的速度;v1y、v2y表示两车沿y方向的速度;vr表示相对速度。
相对航向角决定了车辆的碰撞类型,不同碰撞类型对应的有效碰撞面积不同,碰撞过程中吸收能量也不同,在相同环境下造成的影响有较大差异。文献[20]通过研究沃尔沃车辆事故数据得出结论:相比于全面积正碰,1/3 面积碰撞严重程度更大。因此,本文引入相对航向角特征,并通过标签编码将相对航向角范围分为4 个部分,如表3 所示。
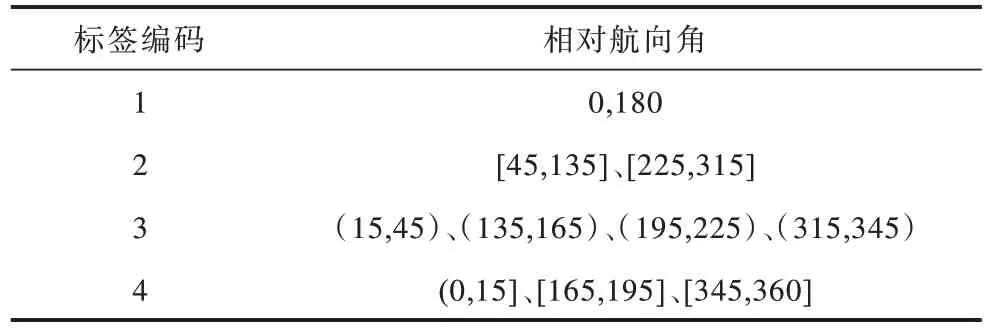
表3 相对航向角特征Table 3 Relative heading angle feature 单位:(°)
不同类型车辆在交通事故中损害不同[21]。通常来讲,小型车相较于大型车损害更为严重。依据重量以及尺寸,本文将NASS-CDS 数据集中车型分为4 类进行标签编码:(1)表示小型车,如轿车;(2)表示中小型车,如小货车;(3)表示中大型车,如轻卡;(4)表示大型车,如重型货车。定义车辆间碰撞强度因子(TYPESWET)如表4 所示,其中,(4)(1)表示4 类别的车辆与1 类别的车辆碰撞后,4 类别车辆的损伤情况(下同),特征值从1~7 代表强度递增。可提取组合特征如表5 所示。

表4 碰撞强度因子特征 Table 4 Collision intensity factor features

表5 组合特征 Table 5 Combined features
1.3 预测标签
本文选用简明损伤分级标准(AIS)评估交通事故严重程度。AIS 值从0~6 分别对应未受伤害、轻微、轻度、中度、重度、严重和致死性损伤。NASSCDS 数据集中包含事故车内各乘员AIS 受伤等级,本文提取受伤严重程度最大的乘员AIS 等级作为事故严重程度预测标签。
为简化事故严重程度预测模型,将原七分类AIS 等级归并为四分类,原0 等级对应为0 等级,原1、2 等级对应为1 等级,原3、4、5 等级对应为2 等级,原6 等级对应为3 等级。
1.4 数据不平衡问题处理
NASS-CDS 数据集中样本分布不均,重伤与死亡类别样本数量占比不到10%,导致模型在训练过程中更加偏向于未受伤以及轻伤类别。而模型对于重伤、死亡等严重程度较高类别的预测能力才是本文研究重点,只有准确预测这些类别,才能够及时采取措施减缓事故损害。为解决数据不均衡问题,本文采用合成少数过采样技术(SMOTE)算法[22]重点提升重伤及死亡样本的数量,改善样本分布均衡情况。
如图1 所示,SMOTE 算法主要分为3 步:1)计算各少数类正方形样本到其样本集中所有样本的欧氏距离,得到K 近邻;2)合理设置采样比例;3)对于样本中的每一个xi与每一个近邻,依据采样比例进行线性插值,以生成新的样本,如式(7)所示:
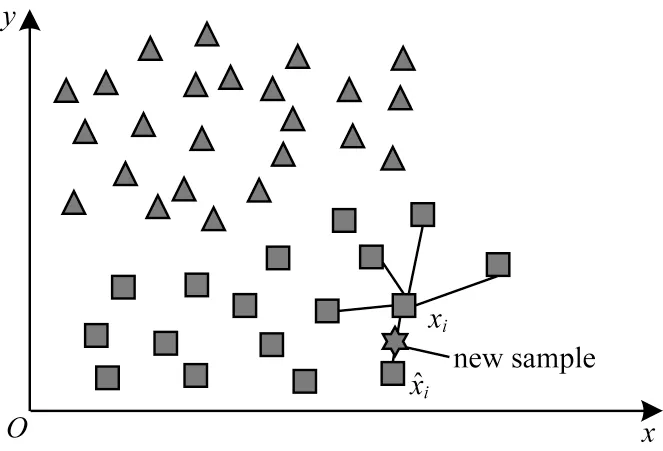
图1 SMOTE 算法图解Fig.1 SMOTE algorithm diagram
数据集处理前后,样本分布如表6 所示。
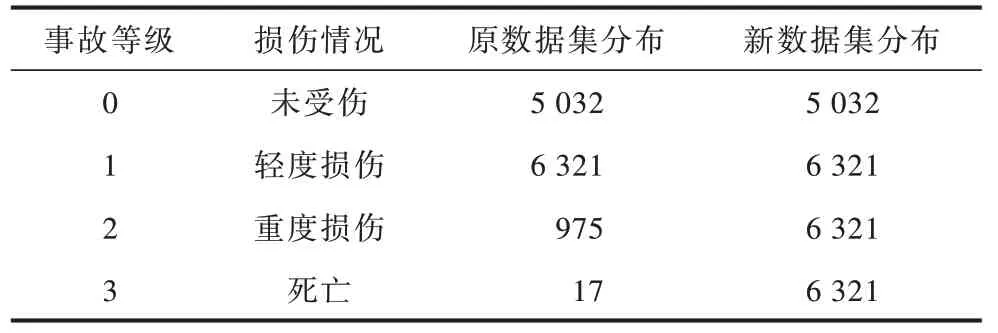
表6 数据集分布Table 6 Dataset distributions 单位:个
1.5 数据标准化
数据集中各特征量量纲不一,因此在模型训练前为避免某些特征的重要程度过大,需要对数据集进行标准化处理。本文研究采用StandardScaler 方法进行转化,如式(8)所示:
其中:μ为某特征所有样本的均值;σ为某特征所有样本的标准差。
2 Stacking 集成学习预测模型
Stacking 集成学习预测模型[23]在分类回归任务中应用广泛,第1 层由多个基学习器构成,基于原始数据集训练预测,第2 层为元学习器,基于第1 层基学习器的输出进行第2 次训练。与Voting 集成学习模型[24]仅对多个基础模型进行一次训练,采用投票策略选择投票最多的为最终的分类结果相比,具有更高的泛化精度。
2.1 基学习器
Stacking 模型对第1 层基学习器存在两个要求:模型预测性能的优异以及模型表现的多样性。优异指各基学习器的预测性能要好,分类预测性能应该在同一水平;多样性指各基学习器预测应存在较大的差异,从不同的角度学习训练,充分利用各模型优势,以实现更好的性能。在第1 层中,通过实验对不同基学习器组合进行训练,得到分类性能最优的基学习器组合策略。
本文选择多层感知机(MLP)、朴素贝叶斯(NB)、K 近邻算法(KNN)、支持向量机(SVM)、随机森林(RF)、自适应提升树(AdaBoost)、梯度提升决策树(GBDT)、极度梯度提升树(XGBoost)共8 种在分类任务中应用较多的模型作为备选基学习器。将数据集按照7∶3 的比例分为训练集和测试集,同时为避免过拟合,采用K折交叉验证训练基学习器,如图2所示,将训练集K等分,每次将其中一份用作验证集,剩下的用作训练集,以提高模型的准确性与稳定性。重复上述步骤K次,选出平均测试误差最小的模型。通常来讲,随着交叉验证次数的增大,误差减小,但计算量随之增大。综合耗时以及数据量两方面因素,最终K值取为5。

图2 交叉验证示意图Fig.2 Schematic drawing of cross validation
2.2 元学习器
第2 层元学习器的选择对Stacking 模型泛化性能影响较大[25],由于第1 层各基学习器的预测存在差异,因此需要选择合适的元学习器才能够使最终Stacking 模型预测性能达到最优。Stacking 模型对元学习器存在4 个要求:1)算法性能,对底层模型的输入进行整合,需要较好的泛化性能和集成能力;2)鲁棒性,可以避免在底层模型发生错误或过拟合的情况下产生过度拟合的情况;3)稳定性,不容易受到数据随机性的影响,以确保其稳健性;4)计算效率,可快速训练以及预测。
相比于第1 层中各基学习器从不同角度学习,综合各学习器优势,第2 层元学习器重点考虑分类预测问题中的全面优化,旨在纠正各基学习器分类偏差,提高Stacking 整体模型的泛化能力和准确性[26]。
逻辑回归(LR)方法[27]作为一种线性模型,其计算效率高,可解释性强,鲁棒性强,可适用于处理各种类型的数据,并且易集成,泛化能力强,能够很好地避免过拟合问题,是应用最广泛的元学习器。在第1 层中已经使用了复杂的非线性变换模型,这样往往更容易造成过拟合的风险。为控制模型复杂度,降低计算耗时,第2 层采用逻辑回归方法,整合第1 层基学习器的分类结果,训练输出最终预测结果,同时结合正则化方法进一步降低过拟合。

本文构建的Stacking 算法实现步骤如图3 所示。使用训练集训练出Stacking 模型,并使用测试集对模型进行预测,最终将预测结果提供给后续事故严重程度减缓决策规划模块,依据不同行驶状态下的事故严重程度先验信息,帮助智能车辆做出最优的决策,当交通事故无法避免时,能够有效减缓事故危害。其中决策规划模块将会作为后续研究内容。
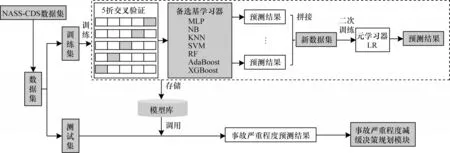
图3 Stacking 算法实现步骤Fig.3 Implementation steps of Stacking algorithm
3 模型性能分析与验证
3.1 评价指标
对于含有N个样本的数据集,准确率(A)为模型预测正确样本数所占的比例,如式(9)所示:
但是准确率往往只能表征模型的整体性能,在实际情况中,会更加关注特定类别预测性能。针对本文研究问题,真实的交通事故数据集中重伤以及死亡数据量远少于未受伤害以及轻微伤害的样本数据量,即使少量样本被分错,模型的准确率也不会有明显变化。故本文主要选择精确率(P)、召回率(R)和F1 值(F1)作为性能评价指标,计算公式如式(10)~式(12)所示:
其中:TTP表示预测为正类的正样本数量;FFP表示预测为正类的负样本数量;FFN表示预测为负类的正样本数量。
3.2 结果分析
3.2.1 个体分类器的实验结果及分析
本文首先完成了学习器MLP、NB、KNN、SVM、RF、AdaBoost、GBDT、XGBoost 的训练,并采用网格搜索法对各学习器参数进行优化。网格搜索法是一种穷举搜索的调参方法,通过事先设定好超参数的选值范围和调整步长进行穷举遍历,尝试所有的参数组合,将表现最好的参数组合作为超参数调参结果。同时,为克服数据集噪声的影响,对各学习器进行5 次训练及预测,计算各评价指标平均值如表7所示。

表7 个体学习器预测结果 Table 7 Predicted results of individual learners %
分析结果发现,集成学习器RF、AdaBoost、GBDT 与XGBoost 预测性能优于其余个体学习器,通过集成决策树可获得比单一学习器更优越的泛化性能。NB、MLP 与SVM 个体学习器预测性能最差。在本文问题中,特征数量较多且相关性较大,违背了NB 各属性间独立性假设;而MLP 表现过于依赖于数据集,本文数据集样本量偏少,不能充分利用MLP的优势;SVM 在处理二分类问题时具有良好表现,而当面临求解多分类问题时,计算能力以及求解精确率受到限制。
3.2.2 集成模型的实验结果分析
为提高集成模型的精确率与泛化能力,应选择精确率较高且存在较大差异的模型作为基学习器,个体学习器MLP、NB 和SVM 表现较差,不满足基学习器组合的优异性原则,故在本研究中不做考虑。最终从KNN、RF、AdaBoost、GBDT 和XGBoost 中挑选基分类器进行组合训练,考虑3~5 种基学习器组合形式,可以得到以下16 种基分类器组合策略,预测结果如图4 所示,耗时情况如图5 所示。

图4 各基学习器组合预测表现Fig.4 Prediction performance of each base learners combination
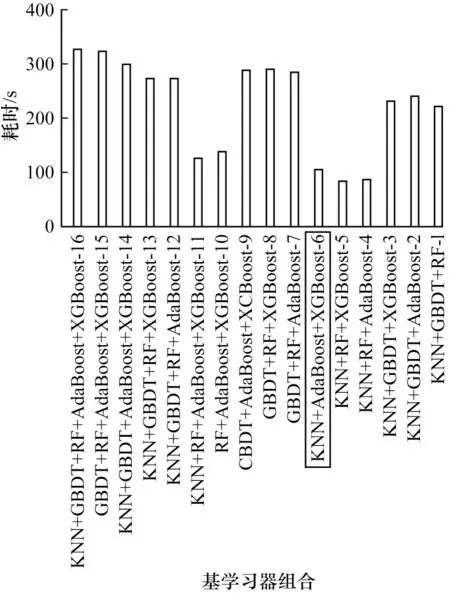
图5 各基学习器组合耗时情况Fig.5 Time consumption of each base learners combination
分析实验结果可得出如下结论:
1)各基学习器组合下的Stacking 模型预测准确率均在81%以上,高于表7 中所有学习器,说明对多种“优而不同”的异质算法进行融合可改善预测效果。以精确率、召回率、F1 值作为评价指标,6 号组合策略,即KNN+AdaBoost+XGBoost 实现了最优的预测性能,其分类准确率达到85.01%,各项指标均为最优。2 号组合次之,11、12 号组合再次之,同时6 号组合耗时仅100 s 左右,低于2、11、12 号组合。综合预测表现以及耗时,将6 号组合作为最终选用的Stacking 模型基分类器组合。
2)从6 号到11 号再到16 号组合,每次增加一个基学习器,融合模型的精确率反而有所下降。说明模型的精确率与基分类器的数量并非正比例关系,还与各基分类器的性质、关联性存在联系。
3)包含GBDT 学习器的组合均具有较高的耗时,在200 s 以上,说明GBDT 学习器复杂度较大。同时,对比组合1、2 和3 号性能表现以及耗时情况可以看出,KNN 与GBDT 为固定基分类器,将其分别与RF、AdaBoost、XGBoost 组合后,虽 然XGBoost 相对于RF 与AdaBoost 具有更优的表现,但3 号组合KNN、GBDT 与XGBoost却获得了最差的性能,说明模型的精确率与基分类器的精确率并非正比例关系。
XGBoost 是一种针对GBDT 算法的优化算法,其在优化过程中将损失函数二阶泰勒展开,引入二阶导数信息,同时在损失函数中添加正则化项来抑制模型复杂度。XGBoost 与GBDT 底层工作原理类似,它们的组合不满足基分类器多样性要求,不能够充分融合基学习器优势,提升整体性能,只有选择适合的基分类器组合才能够获得更好的表现性能。
3.2.3 最优组合策略集成模型时效性分析
在紧急场景下,当交通事故无法避免时,事故严重程度预测模型的时效性非常重要,可以提高应急响应速度,降低事故风险,在事故发生前的关键时间内帮助车辆做出正确的决策以及提高安全水平。在第3.2.2 节中,最终确定的Stacking 模型推理平均耗时为每次1.48 ms,其可满足L2辅助驾驶与L4自动驾驶的实时性需求。
对于L2辅助驾驶车辆,驾驶员主导车辆运行,驾驶员反应时间通常为300 ms 左右,该模型在危急场景下可为驾驶员实时提供事故严重程度相关信息,帮助其做出更优的决策。
对于L4自动驾驶车辆,不需要驾驶员参与,当事故无法避免时,车辆决策规划模块一般依据其最大行驶能力,生成多条离散轨迹,以最小化事故对车辆和行人的影响。
离散轨迹的数量与路径搜索时间、轨迹精确率和计算成本有关,因此需要进行权衡。一般来说,轨迹数量需要在保证足够细化的情况下尽量少,以降低计算成本和缩短路径规划时间,并提高实时性。在大多数情况下,大约10 条离散轨迹即可以满足实时性和精确率要求,并且不会带来过多计算成本。
而自动驾驶路径规划模块更新频率通常为几百毫秒。以生成10 条轨迹为例,本文所提模型推理耗时要远小于路径规划模块更新耗时,通过并行计算可以进一步缩减时间消耗,以最大程度地保证模型推理的实时性。本文研究所提出的事故严重程度预测模型满足实际工程应用中的实时性要求。
3.2.4 最优组合策略集成模型预测表现分析
该模型最优参数组合如表8 所示。

表8 学习器最优参数组合 Table 8 Optimal parameters combination of the learner
模型训练集与测试集的准确率分别为95.87%与85.01%,性能指标精确率、召回率和F1 值如表9所示。
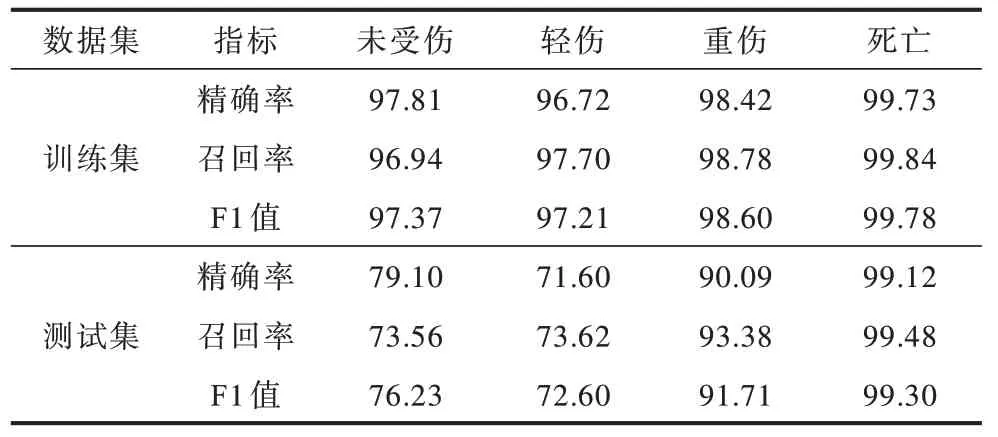
表9 精确率、召回率和F1 值结果 Table 9 Accuracy,Recall,and F1 value results %
在训练集中,未受伤类别精确率大于召回率,受伤类别召回率大于精确率。这表明本文所训练的模型更倾向于查找出所有受伤害样本,而对于未受伤样本,更倾向于准确区分。这对于开展交通事故减缓的研究至关重要,因为只有准确预测受伤类别,才能够及时采取措施降低事故严重程度,这要求在模型训练中提高对召回率的重视程度。
在测试集中,本文提出模型在各类别的表现均与训练集上的表现一致。此外,对于重伤以及死亡类别预测的精确率以及召回率远高于未受伤以及轻伤类别。受伤严重程度越大,模型预测越不容易出错,这符合现实需求。F1 值作为一种精确率与召回率的综合评价方式,重伤与死亡类别值也是远远高于未受伤与轻伤类别。
3.2.5 特征重要性分析
在事故严重程度预测模型中,不同的特征对最终的预测结果有不同的影响。为了评估不同特征在碰撞严重程度分析中的贡献,本文对所选14 个特征在3 种基分类器中的重要性进行了分析,图6~图8 分别为3 种基分类器所对应的特征重要程度分布,其中,KNN、AdaBoost 具有相似的特征分布,DVTOTAL 对事故严重程度影响最大,ALIGNMNT、SURCOND、RHEADING 与TYPESWET 对事故严重程度敏感度最小。而在XGBoost 特征分布图中,除DVTOTAL、TRAVELSP、TRAVELSPOTHER 占有较大的比重外,其余特征重要程度近似。

图6 KNN 特征重要程度分布Fig.6 Importance distribution of KNN feature
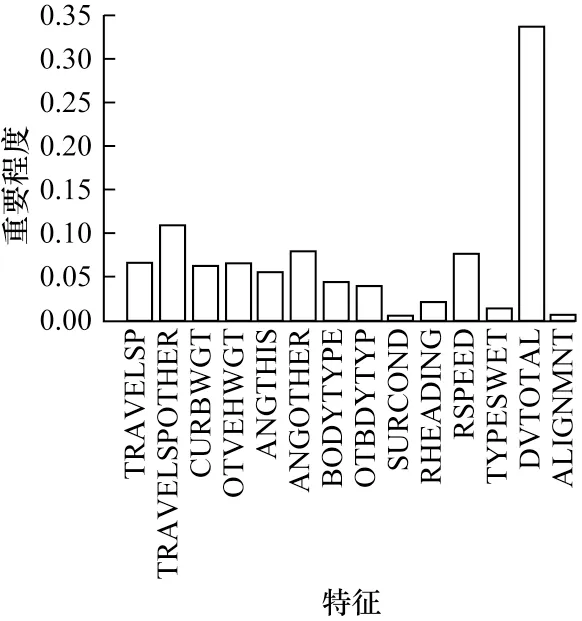
图7 AdaBoost 特征重要程度分布Fig.7 Importance distribution of AdaBoost feature
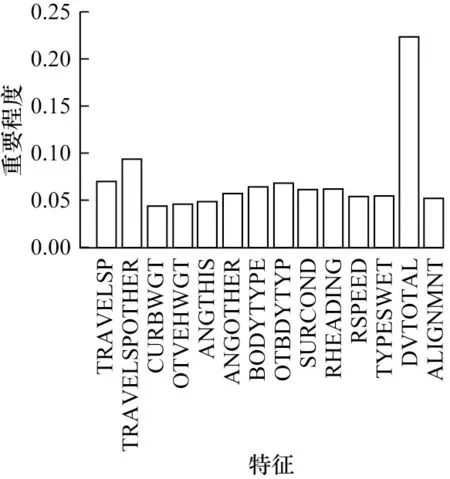
图8 XGBoost 特征重要程度分布Fig.8 Importance distribution of XGBoost feature
图9 展示了特征平均重要程度分布,速度相关特征(DVTOTAL、RSPEED、TRAVELSP、TRAVELSPOTHER)、重量相关特征(CURBWGT、OTVEHWGT)、位姿相关特征(ANGTHIS、ANGOTHER)、外形相关特征(BODYTYPE、OTBDYTYP)对最终的碰撞严重程度影响较大。这符合现实情况,从动量定理和能量守恒的角度来看,行驶速度、车辆质量和车辆姿态是事故发生后对车内乘员影响最大的几个因素。此外,不同车辆的耐撞性不同,因此车型也是重要因素之一。
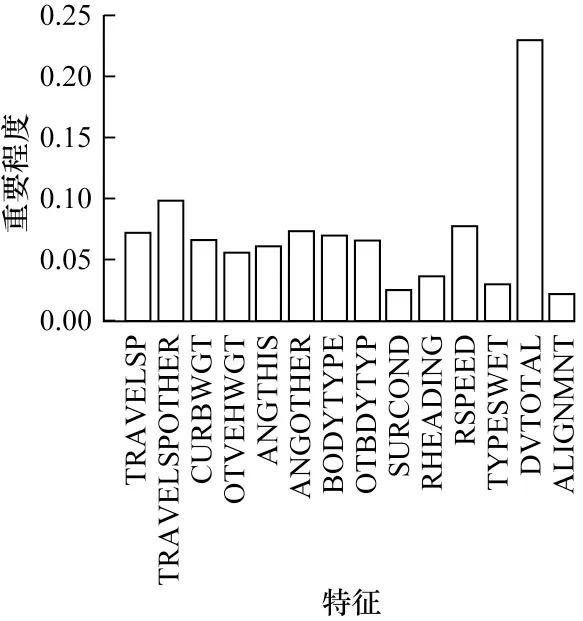
图9 特征平均重要程度分布Fig.9 Importance distribution of feature average
4 事故严重程度预测模型应用分析
在紧急情况下,事故严重程度预测模型可帮助车辆实时预测行驶风险,但在L2辅助驾驶车辆与L4自动驾驶车辆中具有不同的警示与减缓方式。在常规车辆安全模块的基础上,事故严重程度预测模型的应用进一步提升了车辆与乘员的安全性。
在L2辅助驾驶车辆中,目前主要是通过碰撞预警模块减轻紧急情况下事故损害。在车辆行驶过程中实时计算与前方车辆的距离,若小于安全距离,则首先以预警的方式提醒驾驶员即将发生碰撞风险,当检测到驾驶员在一定时间内仍未采取有效措施时,车辆自动触发紧急制动行为,最大程度保证安全。但是,在该种紧急情况下,紧急制动往往未必是最优的决策行为,而且驾驶员在慌张情况下可能会做出更危险的行为。本文所提预测模型可有效解决此类问题,通过预测与不同车辆碰撞风险损伤,在紧急情况下给驾驶员提供指导决策信息,例如左侧车道车辆风险更低,则可提醒驾驶员采取向左变道措施。
在L4自动驾驶车辆中,若车辆具有碰撞风险(可基于安全距离方式判定)或者车辆此时无有效决策时,此时进入到紧急状态下事故严重程度减缓模块,通过轨迹规划方式生成一系列碰撞减缓轨迹,调用事故严重程度预测模型,计算不同轨迹对应碰撞严重程度值,挑选最低碰撞严重程度轨迹作为最终执行轨迹。
除此之外,预测结果同样可以作为先验信息指导车辆自适应调整乘员约束系统(安全带、安全气囊),与主动碰撞减缓相结合,以更好地保证乘员安全。事故严重程度预测减缓系统如图10 所示。在现有安全场景下自动驾驶决策规划模块基础上,本文考虑了事故无法避免场景下事故严重程度如何减缓,通过双层防护最大程度地保证了车辆以及乘员的安全。

图10 事故严重程度预测减缓系统结构Fig.10 Structure of accident severity prediction mitigation system
以图11 车辆跟随场景为例,a车位于后方,速度为v1,b车辆位于前方,速度为v0,车辆间距为S0,则上述描述中两车之间的安全距离可表示为:

图11 车辆跟随示意图Fig.11 Schematic diagram of vehicle following
其中:v1、a1、amax分别为a车速度、加速度、最大加速度;v0、a0分别为b车速度、加速度;Δt为数据更新周期。若Sd>S0,则说明车辆有碰撞风险;反之,则车辆不具有碰撞风险。
以图12 所示场景为例说明事故严重程度预测模型在L4自动驾驶车辆中是如何应用的,其中,0 号车辆为自车,行驶在右侧车道,左侧车道前方2 号车速度较低,后方1 号车突然采取变道行为,插入到自车前方。在这种情况下,自车处境较为危险,当继续在本车道行驶时极易因过小的前车间距与1 号车辆发生碰撞,变道则可能与2 号车辆发生碰撞。
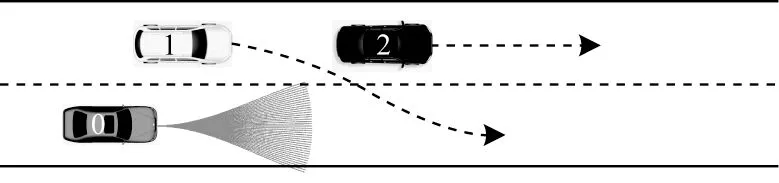
图12 交通场景Fig.12 Traffic scenario
1 号车辆变道后各车辆参数如表10 所示。经安全距离方式判定,若不具有碰撞风险,则智能车辆可继续采用常规的路径规划算法,利用搜索、采样等方法生成一系列轨迹,并依据安全性、舒适性等指标挑选一条最优的安全轨迹执行。若车辆具有碰撞风险,则此时进入到紧急状态下事故严重程度减缓模块,实时生成一系列碰撞减缓轨迹,对每条轨迹进行碰撞检测,若此时仍存在无碰撞轨迹,则仍依据安全性、舒适性等因素挑选一条最优的安全轨迹执行。相反,若所有轨迹均发生碰撞,则将事故严重程度作为唯一的轨迹质量评估标准。调用Stacking 事故严重程度预测模型,得到车辆执行不同轨迹时对应的碰撞严重程度,挑选最低碰撞严重程度轨迹作为最终执行轨迹。由于预测模型输出为四分类离散预测结果,因此此时会存在多条轨迹对应同一碰撞严重程度的情况,不利于帮助车辆做出更细致的决策。
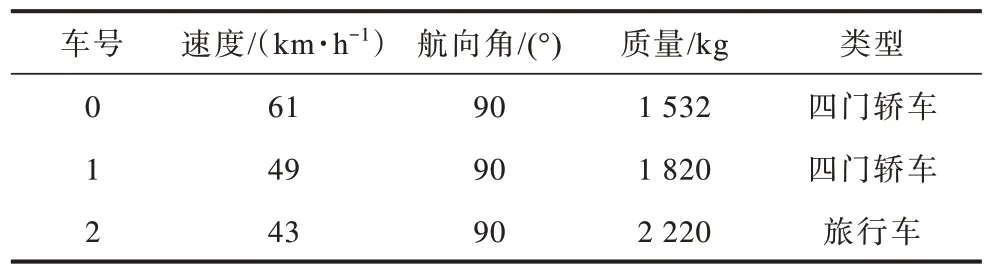
表10 1 号车变道后各车辆参数Table 10 The parameters of each vehicle after lane change of vehicle 1
为使模型应用于智能车辆中,应定义碰撞严重程度连续值,依据本文提出的预测模型输出的各受伤严重程度等级以及对应预测的最大概率加权得到受伤严重程度值(TAS),帮助做出最优的决策,以解决危急场景下不同方案风险的精确量化问题。TAS表达式如式(14)所示:
其中:k为事故严重程度类别;K为事故严重程度最高类别;pk为事故严重程度类别为k的预测概率。
当交通事故无法避免时,该模型可为智能车辆决策规划模块提供先验信息,执行相对最安全轨迹,有效提升车辆安全性。
5 结束语
本文提出一种应用于危急场景下的双层Stacking 集成模型,通过融合“优而不同”的基学习器实现高精度事故严重程度预测,在真实事故数据集上预测准确率达到85.01%,同时具有较低的预测推理耗时,精确率、召回率、F1 值3 项评估指标均高于其他个体以及集成模型,提高机器学习方法对事故严重程度的识别能力。当交通事故无法避免时,模型预测结果可作为先验信息指导决策规划模块选择最佳应急轨迹或自适应调整乘员约束系统(安全带、安全气囊),以降低事故损害。通过特征重要程度分析,得出对事故严重程度影响最大的因素,符合现实交通情况,对于后续事故预测减缓研究具有一定的指导作用。本文研究虽然能够有效应用于车辆安全领域,但目前仍然存在不足,下一步将主要解决以下问题:1)机器学习预测模型表现依赖于数据集的大小和完备性。数据的获取是交通事故分析重要前提,目前仍缺乏丰富的交通事故数据集,未来应提高事故数据的利用率,采用更完善的数据集训练模型,同时机器学习模型可解释性不好,难以分析出发生事故时车辆间碰撞内在机理情况,下一步将考虑构建车辆碰撞物理模型,与机器学习模型相融合,实现精确率更高、可解释性更好的预测系统;2)本文研究仅考虑了事故后自车乘员的损伤预测,旨在最大程度地保证自车乘员安全,但是对他车的乘员安全情况考虑欠缺,未来应该综合事故后双方损伤情况,帮助车辆做出更合理的决策。
