文本视觉问答综述
2024-02-29朱贵德黄海
朱贵德,黄海
(浙江理工大学计算机科学与技术学院(人工智能学院),浙江 杭州 310018)
0 引言
视觉问答(VQA)[1]是计算机视觉、自然语言处理等领域中的学习任务,它是将给定的一张图像和一个自然语言问题作为输入,通过理解图像和问题来输出自然语言答案。视觉问答任务通常只关注图像中的视觉信息,并不考虑图像中可能包含的文本信息,而这些文本信息对于图像理解任务至关重要。例如,一个问题是“出现停车标志的街道名称是什么?”,图像中的“街道名称”文本即为问题所需的答案。因此,能够阅读并理解图像中的文本是正确回答该问题的关键,文本视觉问答(TextVQA)[2]任务在这一背景下被提出。
文本视觉问答任务是将给定的一张包含文本的图像和一个自然语言问题作为输入,通过理解图像和问题来输出自然语言答案。文本视觉问答任务通过将问题、图像中的视觉信息以及图像中的文本信息3 个模态进行联合以推理出答案。与视觉问答任务不同,文本视觉问答任务除了关注图像中的视觉信息外,还需要关注图像中的文本信息,它是一个比视觉问答任务更具挑战性的问题,主要表现在以下方面:
1)文本视觉问答任务需要关注图像中的文本,如何提取有效的文本特征是需要考虑的问题,而视觉问答不需要考虑文本特征。
2)文本视觉问答需要处理文本、视觉以及问题3 个模态的信息,而视觉问答任务只考虑视觉和问题2 个模态。
3)文本视觉问答的问题通常比视觉问答更加复杂,大多都涉及图像中视觉对象与文本的关系,而视觉问答一般只涉及单个视觉对象。
文本视觉问答任务的问题较为复杂,大多都涉及视觉对象与文本的关系,常见的问题有:
1)目标检测、文本识别,如“图中指示牌上写的是什么?”。
2)视觉对象与文本的空间关系,如“穿红色衣服的人左边是谁?”。
3)目标检测、文本间语义关系,如“香蕉与苹果哪个便宜?”。
4)属性分类、文本识别,如“白色的站牌写的什么?”。
除此之外,文本视觉问答任务的问题还可能涉及更复杂的空间关系以及语义理解,比如“中间一台手机的时间是多少?”。与视觉问答任务的问题相比,文本视觉问答任务更加复杂,它需要关注多个模态的信息,还需要联合更多关系进行推理。
自视觉问答任务被提出以来,在该领域涌现了众多成果。文献[3-5]提出了有效的VQA 模型。文献[6]对视觉问答数据集进行介绍并分析了数据集的优缺点,同时对模型进行分类介绍。文献[7]对比了目前的主流模型,并根据融合机制的不同对模型进行分类介绍。文献[8]分析VQA 任务中各个模型的原理以及它们的优劣,其中对模型鲁棒性进行了研究。文献[9]对VQA 任务的不同解答阶段进行分析和对比。然而,目前没有相关文献对文本视觉领域进行综述。
本文对文本视觉问答任务进行系统性的综述,主要工作如下:系统地综述文本视觉问答领域近年来所出现的相关模型,并对模型进行比较;介绍文本视觉问答任务常用数据集以及评估指标;给出文本视觉问答领域未来可能的研究方向。通过上述内容的总结和归纳,以期为文本视觉问答领域的研究人员提供参考。
1 文本视觉问答模型介绍
目前,文本视觉问答模型架构主要包括以下3 个部分:1)特征提取,包括视觉特征提取、文本特征提取、问题特征提取;2)多模态特征融合,将多个模态特征融合并进行推理;3)答案预测,主要分为多分类答案预测和解码器迭代解码答案预测。文本视觉问答模型架构如图1 所示。
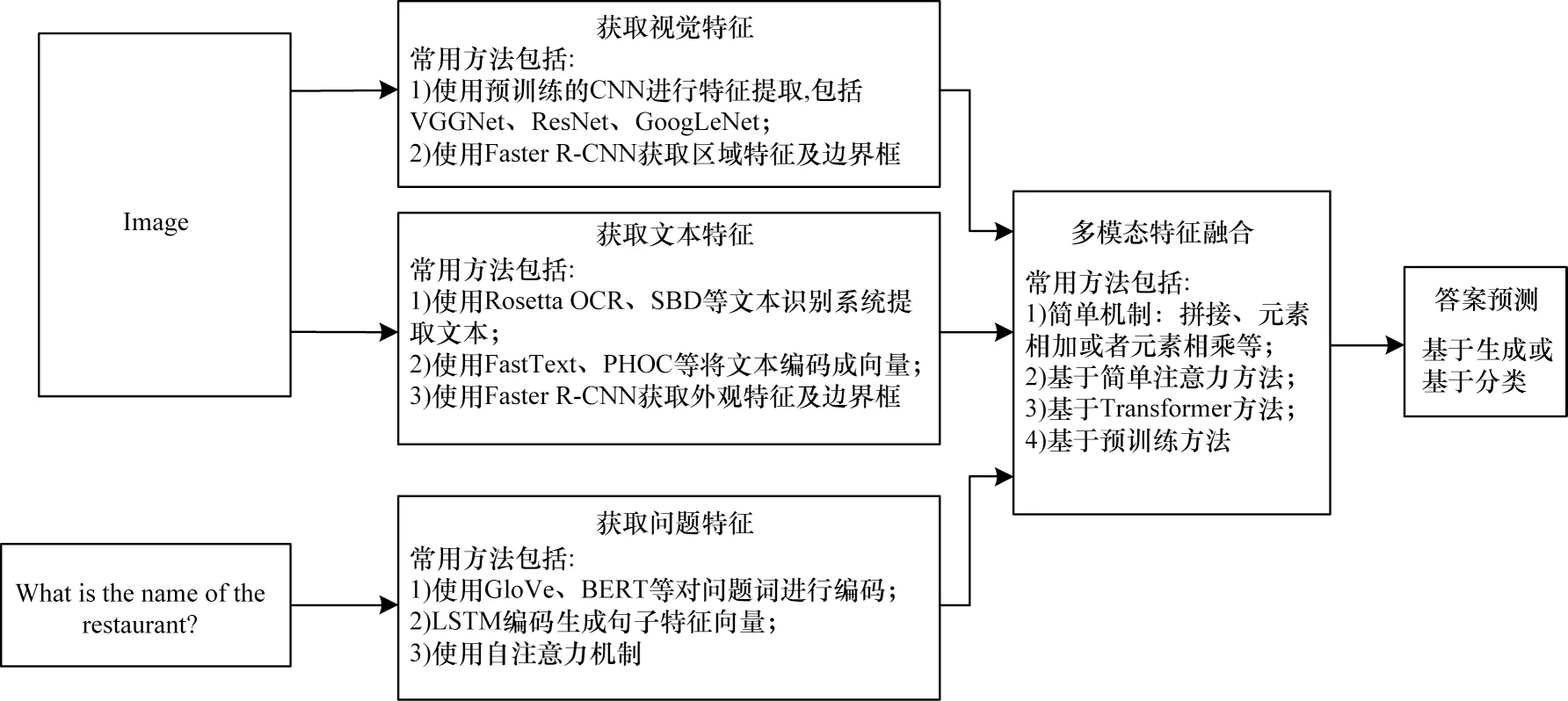
图1 文本视觉问答模型框架Fig.1 Text-based visual question answering model framework
特征提取阶段常用的方法如下:视觉特征提取主要使用目标检测器(Faster R-CNN[10]、YOLO(You Only Look Once)[11])提取基于区域的特征,使用卷积网络[12-13]提取基于网格的特征,以及使用骨干网络[14-16]提取特征;文本特征提取主要采用文本检测器[17-19]来检测文本区域,然后使用文本识别器[20-22]根据文本区域提取文本内容,通过特征编码器FastText[23]、PHOC[24]等将文本词编码 为特征向量;问题特征提取主要采用词袋、循环神经网络(RNN)、长短期记忆(LSTM)[25]、GloVe[26]、基于Transformer的双向编码(BERT)[27]等提取特征。
特征融合阶段常用的方法如下:利用元素拼接、元素相加或元素相乘等进行融合[28-29];通过简单注意力方法进行融合,如LoRRA[2]、MM-GNN(Multi-Modal Graph Neural Network)[30]等;基于Transformer[31]架构进行融合,如M4C(Multimodal Multi-Copy Mesh)[32]、SA-M4C[33]、ssBaseline(simple strong Baseline)[34]等;基于预训练方法进行融合,如TAP(Text-Aware Pretraining)[35]、TWA[36]、LaTr(Layoutaware Transformer)[37]。
根据模型所采用的融合方法进行模型分类,由于简单融合方法处理方式比较简单,因此这里主要分为简单注意力方法、基于Transformer 融合方法和基于预训练方法这3 个类别,如图2 所示。

图2 文本视觉问答任务相关模型分类Fig.2 Text-based visual question answering task-related models classification
1.1 简单注意力方法
简单注意力方法将问题作为查询条件,引导模型关注视觉和文本中与问题最相关的部分,它大幅增强了模型的推理能力。例如问题“公交车的路线是什么?”,模型应该更关注图像中与“公交车路线”相关的文本。模型通过关注图像中的关键部分,去除图像中存在的冗余及噪声,减轻计算负担。简单注意力方法框架如图3 所示。

图3 简单注意力方法框架Fig.3 Simple attention method framework
文献[2]提出LoRRA 模型,它将自上而下注意力方法[38]运用到文本视觉问答中,以问题作为查询条件,引导更新文本以及视觉特征,去除了图像中存在的冗余及噪声,最后将更新后的特征串联起来,通过多分类方法来预测答案。LoRRA 是早期联合图像文本进行推理的模型,它采用答案复制机制,动态地将识别的单词添加到答案分类器中,允许从图像中复制单个图像文本作为答案。LoRRA 模型在TextVQA 数据集的验证集和测试集上准确率分别达到26.56%、27.63%。但LoRRA 模型存在以下缺点:1)文本特征不够丰富,忽略了图像中文本的外观特征;2)忽略了空间关系的处理,无法回答包含空间关系的问题;3)无法输出由多个单词组成的长答案。
文献[30]提出了MM-GNN 模型,它使用3 层图神经网络(GNN)[39]对视觉特征和文本特征进行聚合,以重建特征间的空间关系与语义关系。MMGNN 以问题作为查询条件,引导图推理,并在图推理结束后使用自上而下注意力方法对视觉和文本特征进行更新,最后采用多层感知机和答案复制机制[40]来预测答案。MM-GNN 算法利用图像中的上下文信息来帮助理解图像文本的含义,通过不同图神经网络的引导优化视觉和文本特征,模型可以更准确地回答问题。与LoRRA 相比,MM-GNN 使用多层图对特征进行聚合,使得模型在融合阶段可以更好地利用上下文信息进行辅助推理。通过采用图像上下文的丰富信息来帮助理解图像文本含义,MM-GNN 的准确度相对于LoRRA 有了进一步的提升,其在TextVQA 数据集的验证集和测试集上准确率分别达到32.92%、32.46%。但MM-GNN 模型的缺点为:1)无法生成包含多个单词的长答案;2)文本特征不够丰富,仅包含词嵌入特征;3)模型采用多层图结构,较为复杂。
文献[41]将每个视觉对象和图像文本分别作为单个实体,针对每个实体提取特征,使用问题做引导计算出每个特征的注意力分数,求出特征的加权平均和作为注意力模块的输出,最后,模型通过LSTM[25]迭代解码来预测答案。与LoRRA 相比,该模型可以解码生成包含多个单词的答案。
文献[42]采用视觉特征和文本特征构建多模态特征网格,以问题作为推理条件,通过卷积网络以及线性变换对多模态特征网格进行推理,计算出每个网格的注意力权重,这些注意力权重即为答案在该空间网格位置的概率。模型通过特征网格的方式进行融合推理,可以为答案提供依据。但是,这种方式对文本边界框有限制,使得模型不能很好地处理较小的文本。
文献[43]在LoRRA 的基础上对视觉特征和文本特征进行融合,通过双线性函数去除文本中的噪声,并通过语义注意力和位置注意力来捕获文本与视觉对象之间的关系。在对视觉和文本特征融合时,模型以文本特征为指导,使用自上向下注意力方法更新视觉特征,视觉和文本特征融合方法如图4所示。此外,为了增强文本特征表示,使用单步词识别架构[44]提取图像中的文本词,并引入费舍尔向量(FV)[45]特征,它含有的信息更加丰富且易于计算。与LoRRA 相比,该模型没有采用复制答案的方法,而是使用指针网络[46]来预测答案,它可以直接预测来自文本的答案。

图4 视觉-文本融合方法框架Fig.4 Vision-text fusion method framework
简单注意力方法以问题作为查询条件,引导模型关注图像中与问题有关的信息,过滤特征中的冗余信息,减轻了模型的计算负担。但是简单注意力方法只针对2 个模态的融合,不能很好地处理多个模态的融合。此外,注意力方法只是使模型关注重点特征,并没有联合周围特征进行推理。如何获取图像文本和视觉对象的空间关系以及语义关系,并根据空间关系和语义关系进行推理仍需要继续研究。
1.2 基于Transformer 融合方法
基 于Transformer[31]融合方 法使用Transformer作为融合器,将多模态特征作为融合器的输入进行融合。与简单注意力方法相比,Transformer 使用自注意力机制,可以很好地处理长序列数据,输入序列之间可以相互关注。Transformer 融合方法可以同时对多个模态特征进行融合,特征间的联系更加紧密。
文献[32]提出M4C 模型,它首次使用Transformer[31]架构对多模态进行融合,将来自问题、视觉和文本3 个模态的特征映射到统一维度并进行融合。Transformer 独特的自注意力机制使得输入的每个特征向量间可以相互学习。另外,M4C 模型通过动态指针网络[46]以自回归的方式迭代解码预测答案。M4C 模型添加了丰富的文本特征,如外观特征、边界框信息等,增强了文本特征的表达能力,通过迭代解码预测答案,模型可以回答包含多个单词长答案的问题。M4C 模型在TextVQA 数据集的验证集上准确率达到39.4%,远高于之前方法,这得益于Transformer 独特的自注意力机制以及使用了丰富的文本特征。M4C 模型框架如图5 所示。

图5 M4C 模型框架Fig.5 M4C model framework
但是M4C 模型存在以下缺点:1)将全部特征作为融合器的输入,会增加融合器的计算负担;2)无差别地对所有特征计算注意力,会引入冗余特征与噪声;3)未对视觉特征和文本特征之间的空间关系进行显式处理。
以下模型在M4C 的基础上进行改进,根据不同特点主要分为联合图推理的模型、带有答案解释的模型、引入丰富特征表示的模型和引入外部知识的模型。
1.2.1 联合图推理的模型
图神经网络(GNN)[39]在结构特征学习中有较好的表现,不仅能够聚合周围邻居节点的信息,还能很好地捕获节点之间的关系。联合图推理模型在Transformer 融合之前使用图神经网络对输入特征进行处理,重建特征之间的空间关系和语义关系,增强模型推理能力。联合图推理模型框架如图6 所示。
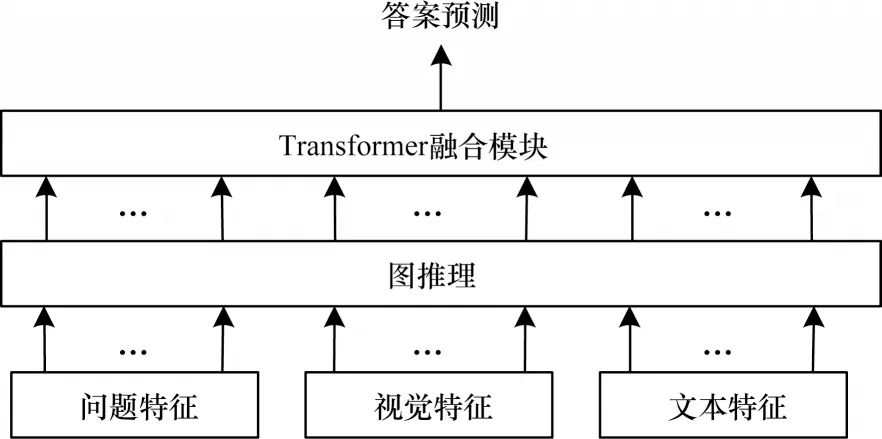
图6 联合图推理模型框架Fig.6 Framework of joint graph reasoning model
文献[33]提出SA-M4C 模型,它通过构建空间图网络来捕获相邻视觉实体(检测的视觉对象与文本)之间的空间关系[47],并通过修改Transformer 注意力层,使每个头只关注存在固定关系的2 个特征向量。此外,SA-M4C 增加二分图来构建问题特征与视觉和文本特征的隐式关系。模型采用6 层Transformer 自注意力层,其中前2 层为经典架构,后4 层被修改为空间感知层,通过在计算注意力分数时添加偏置项,使每个头关注存在不同空间关系的实体。M4C 在融合阶段隐式地学习来自特征中坐标信息的空间关系,这对于空间推理几乎没有帮助,SAM4C 很好地解决了这个问题。SA-M4C 在TextVQA数据集的验证集上准确率达到43.9%,比同等条件下M4C 的准确率略高(同等条件下M4C 的准确率为42.7%)。SA-M4C 有较好的结果得益于2 个方面:1)采用了准确率更高的文本识别系统;2)对视觉实体之间的空间关系进行了处理。但是SA-M4C 模型存在以下缺点:1)对于视觉实体之间空间关系的处理采用手工设置,方法较为粗粒度;2)将所有模态特征作为输入,模型计算负担较大。
文献[48]提出MTXNet 模型,它扩展了M4C 架构,为了更好地捕获并编码视觉对象和图像文本之间的关系,它采用图神经网络将多模态特征连接在一起,并通过图注意力网络(GAT)[49]对图中节点信息进行更新。与SA-M4C 相比,MTXNet 构建的空间关系更加细粒度,但MTXNet 在构建图的边时,只有边界框存在包含关系的2 个节点间才会构建边。
文献[50]提出SMA 模型,它使用图神经网络来捕获节点之间的关系,增强文本阅读能力和文本视觉推理能力。SMA 不使用整个问题特征来指导图的更新,而是使用经过自注意力模块后的子问题特征作为查询条件,指导图神经网络更新。SMA 计算图中每个节点的权重,然后根据权重分别求出视觉特征与文本特征的加权特征和,并将加权特征和作为全局特征送入Transformer 融合器中。SMA 并没有聚合邻居节点的信息,而是以问题为引导,计算出节点自身的权重。与SA-M4C 相比,SMA 模型以节点之间的相对距离来确定节点之间的连接,抛弃了手工设置关系,捕获到视觉实体之间更加细粒度的关系。SMA 在TextVQA 数据集的验证集和测试集上准确率分别为43.74%、44.29%,它的性能提升得益于使用了准确率更高的文本识别系统[51-52]以及对视觉实体之间的关系进行了处理。但是SMA 模型有以下2 个缺点:1)图推理中只使用问题关注节点和节点之间的关系,没有为节点加入上下文信息;2)模型需要对每个节点进行处理,计算负担较大。
文献[53]提出CRN 模型,它使用多模态推理图来构建图像文本和视觉对象之间的空间关系,解决了由于分别使用目标检测器和文本识别系统提取特征而导致的特征相互独立且比较分散的问题。与SMA 模型不同,CRN 采用以问题为指导的注意力方法聚合邻居节点信息,对每个节点进行更新。此外,为了使模型可以从冗余的图像信息中提取有用信息,CRN 中加入了渐进式注意力模块来过滤掉无用信息。CRN 还添加了策略梯度损失来减轻对文本识别系统的依赖,主要思想为训练过程中当预测值与真实值相似但不相同时,模型不会只获得负的训练反馈。CRN 在TextVQA 数据集的验证集和测试集上准确率分别为40.39%、40.96%,比同等条件下M4C 的准确率高了1%。CRN 有较好的性能提升得益于使用了图推理、渐进式自注意力方法以及策略梯度损失。但是CRN 模型存在以下缺点:1)模型在渐进式自注意力模块中不使用视觉特征,性能没有明显的变化,说明渐进式自注意力模块并未对视觉特征进行很好的推理;2)模型仅处理了视觉和文本2 个不同模态间的关系,并没有处理相同模态间的关系。
文献[54]提出MGEN 模型,它使用问题特征和全局视觉特征引导图神经网络进行更新,通过图网络来重建文本之间的空间关系,并去除文本中的噪声和冗余。CRN[53]通过使用多模态推理图来构建文本和视觉之间的关系,而MGEN 则是通过图神经网络来重建文本之间的空间关系。另外,为了进一步去除特征中的冗余信息,MGEN 对Transformer 融合器进行修改,向其注入全局特征来引导融合器关注重要信息。
图神经网络对于特征间关系的重建有着较强的能力,能够建立更加细粒度的关系,引入丰富的上下文信息。使用图神经网络,模型可以更好地理解场景文本的含义,回答包含空间关系属性的问题。
1.2.2 带有答案解释的模型
带有答案解释的模型是在图像上构建答案区域或者生成答案解释,目的是为答案提供依据。如图7所示,问“公交车的路线是什么?”,带有答案解释的模型为答案构建答案区域以指示答案的合理性,或者生成答案解释表示答案的位置、字体等信息。先前一些其他计算机视觉领域的工作研究了带有答案解释的方法,其中文献[55-57]通过计算出注意力分数在图像上构建答案区域,文献[58-59]为答案生成答案解释。然而,在文本视觉问答任务中为答案提供解释的工作较少,目前只有文献[48,60]。
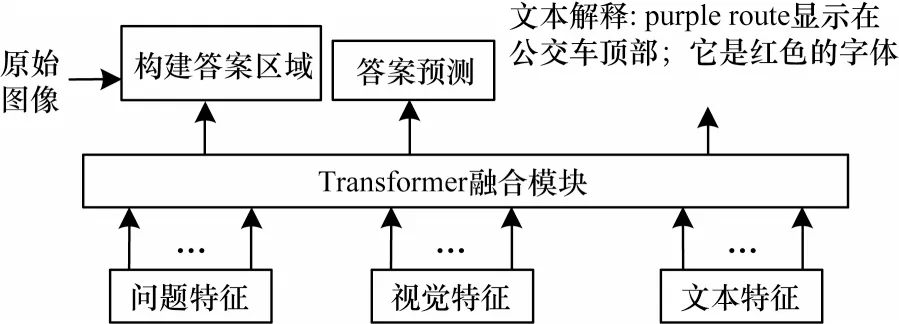
图7 在图像中构建答案区域以及生成文本解释的示例Fig.7 Examples of constructing answer regions in images and generating text explanations
文献[60]提出LaAP-Net 模型,它通过预测边界框来为答案提供依据,在答案评估阶段对预测的边界框和文本一同计算损失。另外,为了更好地利用视觉信息,模型根据图像文本和视觉对象之间的空间关系,将视觉特征加入文本特征中。在此前的一些工作中(如LoRRA[2]、M4C[32]等),文本的位置信息未被充分利用,LaAP-Net 通过预测边界框并将预测的边界框参与答案预测以及损失计算,使模型在训练过程中充分考虑到文本的位置信息。与M4C 相比,LaAP-Net 不仅为答案提供了依据,还更好地利用了文本的位置信息,提升了模型性能。LaAP-Net在TextVQA 数据集的验证集上准确率为40.68%,优于相同条件下的M4C。但是LaAP-Net 模型存在以下缺陷:1)根据空间关系将视觉特征加入文本特征中,并未使用问题进行引导,因此加入的视觉特征中包含很多冗余信息;2)在训练阶段需要提供答案依据的数据集,目前这样的数据集较少。
文献[48]提出MTXNet 模型,它使用图像语义分割在图像上构建答案区域,并且为答案提供文本解释。MTXNet 根据图像收集多种文本解释,模型每次随机选择一个参与训练,以降低文本解释存在的偏差。为了使模型具有更好的性能并较好地生成多模态解释,MTXNet 设置多个训练任务,分阶段进行训练。与LaAP-Net 不同,MTXNet 采用生成文本解释和构建答案区域的方式为答案提供依据。
带有答案解释的模型更加显式地把推理过程展现出来,为答案来源提供依据。通过将答案依据参与损失计算,进一步提升了模型性能。
1.2.3 引入丰富特征表示的模型
在文本视觉问答任务中,通常需要3 个模态的特征,分别是视觉特征、文本特征和问题特征。特征的提取对模型性能有着很大影响,通过引入丰富特征可以有效地提升模型性能。引入丰富特征的方法如下:1)增加一个模态特征,如增加全局特征;2)在原有特征中引入新的表示,如在视觉特征中加入对象标签特征;3)对原有特征进行修改,如将文本特征划分为文本视觉特征和文本语言特征。
文献[61]提出PAT-EAM 模型,为了保留原始图像信息,除了提取视觉特征和文本特征外模型还提取了全局图像特征,以提供全局上下文信息辅助模型推理。同时,PAT-EAM 采用实体对齐网格(全局特征网格)替代复杂的图神经网络,通过卷积操作更直接全面地捕捉视觉对象和图像文本之间的语义和空间关系。
文献[62]提出BOV 模型,它在原有文本特征基础上加入额外的语义特征,由与文献[63-64]类似的端到端模块直接通过图像的文本区域提取得到。该模块除了直接获取文本特征编码外,也对文本区域做了文本识别,为答案预测提供候选文本。该模块的使用降低了模型对文本识别系统的依赖,避免了文本识别系统误差带来的影响。另外,BOV 在视觉特征中引入对象标签特征,打破视觉和文本之间存在的差异,更好地对文本特征和视觉特征进行融合。对象标签特征通过扩展原始Faster R-CNN[10]模型,使其生成对象标签特征向量而得到。BOV 通过引入这些额外的特征,模型性能有了大幅提升,但是针对这些额外特征,模型需要训练额外模块才能提取,模型复杂度较高。BOV 在TextVQA 数据集的验证集和测试集上准确率分别为40.90%、41.23%,BOV能取得较好的性能提升得益于3 个方面:1)采用端到端的模块提取文本特征;2)加入对象标签特征增强融合;3)使用端到端的模块识别文本,并将其作为候选答案,减轻对文本识别系统的依赖。但是BOV模型的缺陷也很明显:1)需要预先单独训练多个模块,增加了工作量;2)模型忽略了视觉实体间存在的空间关系;3)将所有特征作为融合器的输入,融合器计算负担较大。
文献[65]提出MML&TM 模型,它采用文本合并算法,将图像中具有邻近关系的文本合并在一起,构建行级和段落级的文本,然后对合并后的文本提取文本特征,这样提取的文本特征包含文本上下文信息,更具有连续性。与M4C 不同,MML&TM 通过将文本进行合并,在答案预测阶段无须采用迭代解码便可生成多个单词的答案。
文献[34]提出ssBaseline 模型,为了更有效地利用文本特征,该模型将文本特征分成文本视觉特征和文本语言特征,这样更加符合人类推理的过程,即人类会从视觉和语义2 个方面理解场景文本。在之前的工作[32]中,将所有的特征送入融合器,模型计算负担较重。为了减轻计算负担,过滤掉冗余特征,ssBaseline 模型采用注意力模块,以问题引导模型关注特征。相较于其他模型,ssBaseline 在设计上非常简单,降低了模型的计算负担,有效提升了模型性能。ssBaseline 在TextVQA 数据集的验证集和测试集上准确率分别为43.95%、44.72%。ssBaseline 的性能提升主要得益于使用了与SMA[50]一样的文本识别系统以及将文本特征分成两部分,模型在保证性能的同时大幅减轻了计算负担。但是ssBaseline 模型存在以下缺陷:1)忽略了视觉实体间存在的关系,没有处理场景文本和视觉对象之间的关系;2)没有充分利用视觉信息,在去除视觉特征时模型性能改变不大。
文献[66]提出SC-Net 模型,它也将文本特征分为文本视觉特征和文本语言特征,并将文本视觉特征融入文本语言特征中,以突出场景文本语义在模型推理中的重要作用,减轻对文本识别系统的依赖。此外,SC-Net 通过融合器输出的全局信息指导答案预测,以减少语言偏见。
丰富特征表示可以增强特征在模型中的表达能力,使模型更好地理解多模态信息。以上研究大多旨在增强文本特征的表达能力,忽略了视觉特征的作用。然而,在模型推理过程中往往需要根据视觉特征来辅助推理,找到问题的答案。在增强文本特征表达能力时,充分利用视觉信息辅助推理也很关键。
1.2.4 引入外部知识的模型
文本视觉问答任务中一些问题仅仅通过图像是不能正确回答的,比如“这杯牛奶是什么品牌?”。如果模型拥有外部知识,它能预先理解“伊利”、“蒙牛”等文本是品牌名字,那么这些文本作为答案的概率将更大,像这种类型的问题都需要借助外部知识才能够准确地回答。在视觉问答任务中已有工作通过引入外部知识进行辅助推理,如文献[67-69]通过采用包含知识的数据集来使用知识辅助推理,文献[70-72]则通过问题词和对象标签从外部知识库中查询知识来使用知识辅助推理。但是在文本视觉问答任务中引入外部知识的工作较少,值得继续研究。
文献[73]提出EKTVQA 模型,它是文本视觉问答领域中首次引入外部知识来辅助推理的模型,通过从外部知识库检索来获取知识。EKTVQA 利用场景文本从谷歌知识库(GKB)中获取候选知识,并通过图像上下文信息(问题词、文本、对象标签)过滤掉候选知识中无效的知识,将有效的知识联合问题、文本和视觉对象进行推理,指导答案生成。在融合推理期间,模型通过在自注意力层添加偏置项来保证文本与知识的一一对应。EKTVQA 通过引入外部知识,使模型能够理解文本的含义,提升模型的理解能力。此外,EKTVQA 利用场景文本去外部查询知识,这种引入外部知识的方式不受数据集的影响。EKTVQA 模型在TextVQA 数据集的验证集和测试集上准确率分别为44.26%、44.20%。EKTVQA 模型框架如图8 所示。但是EKTVQA 模型存在以下缺陷:1)将所有模态特征送入融合器,模型计算负担较大;2)增强了模型对场景文本的理解,但是忽略了视觉实体间的空间关系。
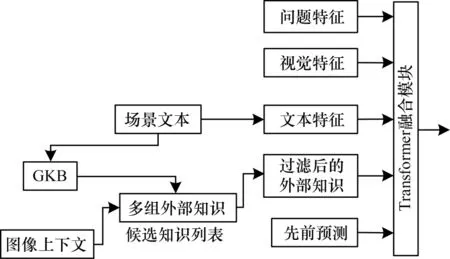
图8 EKTVQA 模型框架Fig.8 EKTVQA model framework
基于Transformer 的融合方法对于2 种及以上模态的融合具有较好的效果,它可以均匀地捕捉模态内和模态间的关系,可以很好地处理长序列数据。但是也正是由于Transformer 均匀地对各个特征进行交互,模型会学习到很多冗余的信息或者噪声,同时也会增加模型的计算负担。
1.3 基于预训练方法
基于预训练的方法通常分为2 个阶段,即预训练和微调。在预训练阶段,模型通过在大量数据集上进行无监督预训练,以学习到通用知识;在微调阶段,模型使用小规模数据集针对具体任务进行有监督训练。预训练方法可以在有标注数据集规模较小时,通过在大规模无标注数据集上训练来使得模型学习到有用知识,它很好地解决了由于数据集规模较小导致模型性能较低的问题。先前一些工作[74]对视觉语言领域的预训练工作进行了总结,其中文献[75-77]介绍了可用于视觉问答的预训练方法。然而,在文本视觉问答任务中使用预训练方法较少,目前只有文献[35-37]。
文献[35]提出TAP 模型,它除了采用屏蔽语言模型(MLM)、图像文本匹配(ITM)作为预训练任务外,还引入相对(空间)位置预测(RPP)预训练任务。TAP 通过相对(空间)位置预测预训练任务来构建图像文本和视觉对象之间的空间关系[47],增强模型的空间推理能力。相对(空间)位置预测预训练任务随机选择2 个视觉实体,预测2 个实体之间的空间关系。TAP 使用文本视觉问答数据集来对预训练好的模型进行微调。TAP 在TextVQA 数据集的验证集和测试集上准确率分别为49.91%、49.71%,远高于传统的不使用预训练方法的模型。TAP 模型框架如图9所示。但是TAP 模型存在以下缺陷:1)需要较大规模的数据集,在预训练阶段数据集规模越大,模型的理解推理能力越强;2)预训练方案对硬件设施有要求,往往需要比较高的配置;3)忽略了文本之间的空间布局信息。

图9 TAP 模型框架Fig.9 TAP model framework
文献[36]提出TWA 模型,它在TAP[35]的基础上增加图像文本-单词对比学习(TWC)预训练任务,以减轻模型对外部文本识别系统的依赖以及增强模型的鲁棒性,使得当文本识别出错时模型仍能进行正确的推理并预测出正确答案。TWC 具体任务是对识别的文本与使用CharBERT[78]修改的文本进行对比学习,然后预测两者的关系。
文献[37]提出LaTr 模型,它在IDL 文档上采用布局感知预训练来学习文本信息和布局之间的对齐。通过大量文档的训练,它可以推理任意形状的句子,有效地捕获文本上下文关系。布局感知预训练通过屏蔽文本标记(文本信息和边界框信息),让模型预测被屏蔽的文本和边界框,从而有效地学习到文本信息与布局间的对齐。与TAP 和TWA 不同,LaTr 并没有使用视觉特征预训练,只对文本信息和布局进行了学习。为了消除对外部对象检测器的依赖,LaTr 在下游微调中采用ViT[79]进行视觉特征提取。LaTr 进行预训练与微调之后,在TextVQA 数据集的验证集上准确率为52.29%,比同等条件下TAP高了2.38%。LaTr 模型框架如图10 所示。但是LaTr模型存在以下缺陷:1)模型的性能与数据集规模有关,数据集越大,模型性能越好;2)模型参数比TAP大,需要更高的配置;3)模型存在数据集偏差。

图10 LaTr 模型框架Fig.10 LaTr model framework
与其他基于Transformer 架构的模型相比,预训练模型在数据集上的表现有了明显提升。但是,由于硬件的限制,目前在文本视觉问答任务中预训练模型较少。预训练模型通过大量训练可以达到很好的效果,模型潜力巨大,值得深入研究。
1.4 模型性能对比
对前文所述主流模型进行对比,对比内容包括特征提取方法、文本特征以及在TextVQA 数据集上的准确率,结果如表1 所示。模型特点对比如表2 所示。从表1、表2 可以得出:
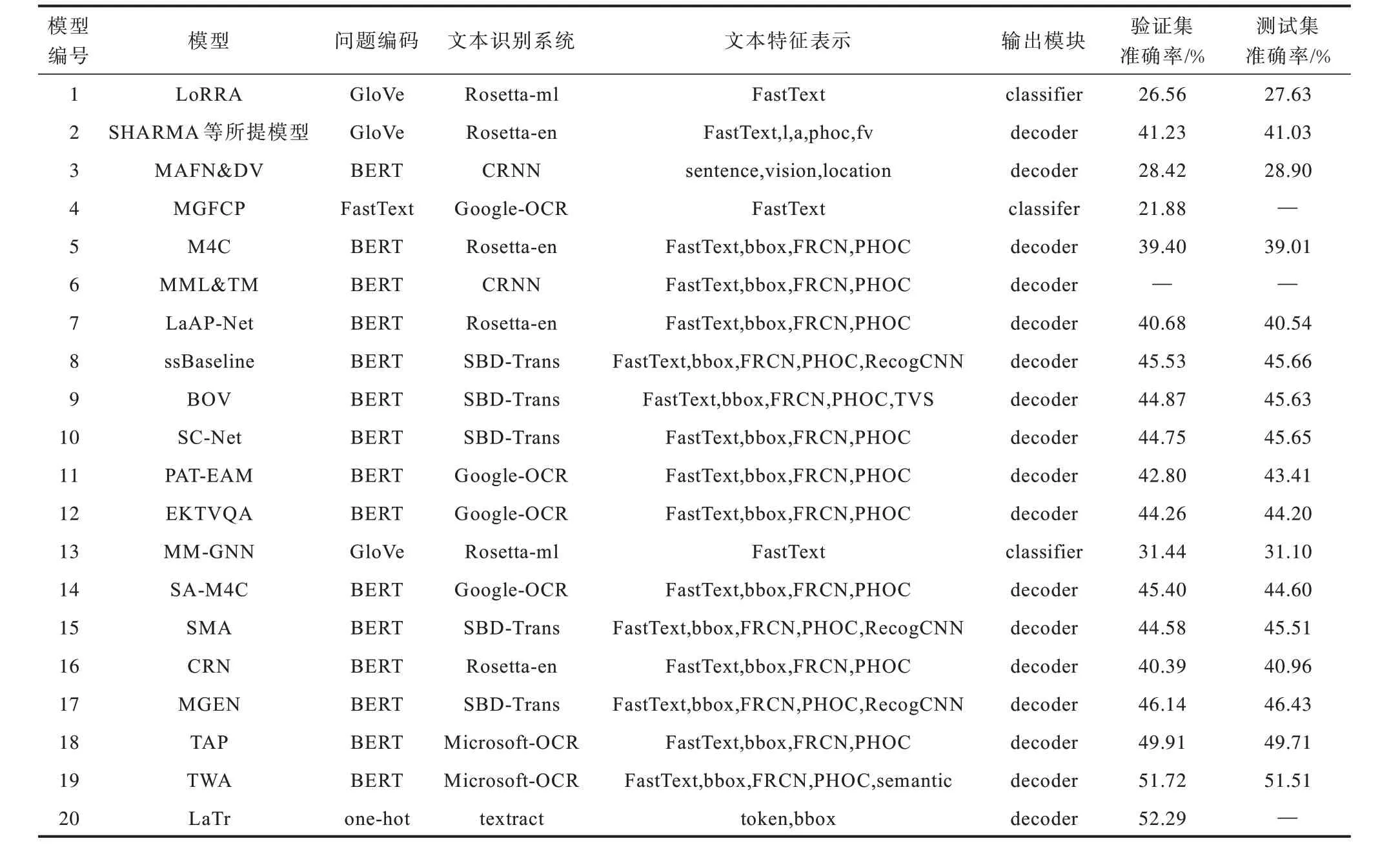
表1 模型框架及在TextVQA 数据集上的性能对比 Table 1 Models framework and performance comparison on TextVQA dataset

表2 模型特点对比 Table 2 Comparison of models characteristics
1)模型的性能在很大程度上依赖于文本识别系统的准确率,文本识别系统准确率越高,模型性能越好;
2)模型使用Transformer 进行融合比使用传统的串联效果更好;
3)使用预训练方法的模型可以更好地捕获视觉实体(视觉对象和场景文本)间的空间关系以及问题与视觉实体之间的关系;
4)普通的Transformer 方法在M4C 之后虽然有改进,但是性能提升幅度不大,与预训练方法对比可知,普通方法的关系推理能力很弱,不能很好地捕获实体间的空间关系以及多模态间的语义关系。
2 数据集以及评价指标
2.1 数据集介绍
2.1.1 TextVQA 数据集
文献[2]提出TextVQA 数据集,它使用Open Images v3[80]数据集作为图像源,过滤掉不包含文本的图像以及有噪声的数据,共得到28 408 幅图像,其中多数为生活中常见的包含文本的场景图像,如广告牌、交通标志等。TextVQA 数据集中一共包含45 336 个问题和453 360 个答案。平均每张图像对应1~2 个问题,平均问题长度为7.18 个单词,平均答案长度为1.58 个单词。训练集包含21 953 幅图像、34 602 个 问题,验证 集包含3 166 幅图像、5 000 个问题,测试集包含3 289 幅图像、4 734 个问题。该数据集中每个问题都需要阅读图像中的文本才能回答,图像中文本可以直接作为答案,也可以作为推理的依据。
TextVQA 数据集采用VQA 中广泛使用的评估指标,假设模型预测输出为ans,则单个问题样本的分数为:
其中:Nhumansthatsaidans表示人类注释与预测相同的数量。TextVQA 数据集为每个问题都提供了10 个答案,如果预测答案至少与3 个注释者提供的答案相同,则准确率为100%。一共会出现4 种分数,即0、、1。最后,对所有问题分数取平均值作为数据集准确率。这种评估方法存在一些局限性,不同注释者针对同一问题给出的答案不尽相同,从而使得无法在这种问题上获得满分。
2.1.2 ST-VQA 数据集
文献[81]提出ST-VQA 数据集,它包括23 038 幅来自公共数据集的图像,这些数据集包括场景文本理解数据集和通用计算机视觉数据集,使用多种数据源,分别为ICDAR 2013、ICDAR 2015、ImageNet、VizWiz[82]、IIIT Scene Text Retrieval、Visual Genome和COCO Text,共包含31 791 个问题和答案对,该数据集每张图片的问题数量、每个问题的平均长度以及答案的平均长度都与TextVQA 高度相似。训练集包含19 027 幅图像、26 308 个问题,测试集包含2 993 幅图像、4 163 个问题。ST-VQA 数据集旨在强调在视觉问答过程中利用图像中的高级语义信息作为文本线索的重要性。在该数据集中,问题只能基于图像中的文本进行回答,不包含答案为“是/否”的问题,也不包含可以只根据视觉信息进行回答的问题。
ST-VQA 采用平均归一化Levenshtein 相似性(ANLS)作为评估指标,ANLS 定义如下:
其中:N表示数据集的问题总数;j表示答案的索引(每个问题共有M个真值);aij表示第i个问题的第j个真实答案;oqi表示模型预测答案;定义阈值τ为0.5;NL(·)表示归一化Levenshtein 距离。ST-VQA 使用Levenshtein 相似性作为评估指标,即只要推理正确,尽管文本识别出错,也不会直接评判为错误。
2.1.3 OCR-VQA 数据集
文献[83]提出OCR-VQA 数据集,它主要是针对图像文本的问答,包含207 572 幅封面图片,1 002 146 个问题答案对,其中的问题主要是针对书本封面进行的提问。书籍封面包含作者、标题、类型等元素信息,模型通过视觉信息和文本信息进行推理,从而回答问题。数据来源于Book Cover Dataset,数据集中训练集、验证集和测试集的比例为8∶1∶1。该数据集中平均问题长度为6.46 个单词,平均答案长度为3.31 个单词,每个图像平均有4.83 个问题。但是在该数据集中存在一些特殊的挑战:1)书籍封面有各种布局,需要模型推理各种布局的文本;2)数据封面字体较为独特,需要稳健的文本识别系统;3)需要有额外的知识才能理解书籍封面的文本。
2.1.4 STE-VQA 数据集
文 献[84]提 出STE-VQA 数据集,它收集 了25 239 幅图像,这些图像来自于Total-Text、ICDAR 2013、ICDAR 2015、CTW1500、MLT 和COCO Text,中文图像来自于LSVT,这些场景文本数据集的图像都由日常场景组成。英文训练集图像有11 383 幅,测试集图像有2 267 幅,训练集问题有12 556 个,测试集问题有2 500 个。中文训练集图像有9 374 幅,测试集图像有2 215 幅,训练集问题有10 506 个,测试集问题有2 500 个。平均问题长度为6~8 个单词,平均答案长度为1~2 个单词。数据集中问题只能通过阅读图像中的文本来回答,不包含答案为“是/否”的问题以及有多个正确答案的模糊问题。
STE-VQA 数据集除了提供图像、问题和答案以外,还为每个问题提供了一个边界框作为答案的证据,指示答案基于图像的哪个区域得到。
STE-VQA 数据集提出新的性能评估指标,该评估指标更倾向于推理过程而非推理结果。评估协议包括2 个部分,一是检查答案,二是检查证据。对于答案的评估,采用归一化Levenshtein 相似性分数,与ST-VQA 中的s(·)评估协议函数一致。对于证据(边界框)的评估,采用IoU 度量来确定证据是否充分,对于单个问题样本的评估分数如下:
其中:Bgt表示答案边界框;Bdet表示预测边界框;θ设置为0.5;sl为式(2)中的s(·);gt 为真实答案;ans 为模型预测答案。最后,对所有问题分数取平均值作为数据集准确率。
2.2 数据集对比
对上述数据集进行对比,主要包括数据集来源、数据集规模等,结果如表3 所示。

表3 数据集规模以及特点 Table 3 Datasets size and characteristics
3 未来研究展望
本文对文本视觉问答领域未来的研究方向进行展望,具体如下:
1)空间关系推理
自然场景中的文本和物体都存在着空间关系,如方位关系(上、下、左、右)、包含关系(里面与外面、相交)等,输入的问题中也涉及空间关系,如“左边的瓶子里装了什么?”。空间关系对于模型理解图像有着很重要的作用,理解空间关系可以更准确地回答含有空间关系的问题。文献[30,33,61]介绍了进行空间处理的模型,但是它们都具有局限性,如空间关系不够细粒度、未使用注意力机制引导关注指定空间关系等。因此,如何有效地处理空间关系以提升模型性能,是一个值得研究的方向。
2)模型的安全性问题
在计算机视觉领域,模型的安全性问题早已是一个重要的研究课题。例如,通过篡改输入的图片,可以让模型输出错误的预测结果,这在一些安全要求较高的应用领域(如无人驾驶场景)将会造成很严重的后果。文献[85-87]介绍了针对图像的对抗性攻击和防御方法,文献[88]研究了针对场景文本识别的对抗性攻击和防御方法。目前文本视觉问答领域并没有研究对抗性攻击和防御方法,因此,模型的安全性问题值得研究。
3)端到端的文本视觉问答
目前文本视觉问答任务主要分为3 步,即特征提取、多模态特征融合、答案预测。特征提取一般都依赖于外部训练好的特征提取器,它们的性能会直接影响文本视觉问答模型的性能。此外,外部特征提取器并不是通过文本视觉问答任务而训练的,在运用到文本视觉问答任务中时,提取的特征会有偏差。如何将图像检测模块以及文本识别模块纳入模型中以进行端到端的训练,是一个值得研究的课题。
4)预训练模型
现有模型的性能与数据集紧密关联,模型需要较大的数据集才能获得较高的性能。然而,获取大数据集需要较高的成本,但是无标注的数据集资源丰富。模型预训练方法可以首先在预训练阶段利用无标注数据集学习特征之间的关联,重建特征之间的关系,然后在微调阶段使用小规模标注数据集进行训练。模型预训练方法解决了标注数据集规模小的问题,并且能达到较好的性能。目前在文本视觉问答领域有了一些预训练方法[35-37],但是模型性能还有很大的提升空间。在文本视觉问答中使用预训练方法进一步提升模型性能,也是值得研究的方向。
5)引入外部知识的方法
文本视觉问答任务中一些问题仅仅通过图像是不能正确回答的,需要借助外部知识才能够准确回答。在视觉问答任务中,已有工作通过引入外部知识进行辅助推理,但是它们的知识数据集图像大多数不含文本,因此不适用于文本视觉问答任务。目前,在文本视觉问答领域只有极少的工作对引入外部知识进行了研究,因此,在文本视觉问答任务中引入外部知识进行辅助推理,可以作为未来的一个研究课题。
4 结束语
本文首先回顾文本视觉问答领域的最新进展,根据融合方法的不同对已有模型进行分类,并总结各个模型及其优缺点,分析主要方法在公开数据集中的表现;然后归纳文本视觉问答任务中的数据集,并给出不同数据集的评估指标;最后对下一步的研究方向进行了展望。在未来,文本视觉问答领域可以从预训练方法、安全性加固、空间关系增强等方面开展研究。
