基于改进Informer 的云计算资源负载预测
2024-02-29李浩阳贺小伟王宾吴昊尤琪
李浩阳,贺小伟,*,王宾,吴昊,尤琪
(1.西北大学网络和数据中心,陕西 西安 710127;2.西北大学信息科学与技术学院,陕西 西安 710127)
0 引言
云计算[1]是一种通过互联网提供按需服务的策略,将各种资源、软件和平台作为服务提供给客户。然而,云计算中的工作负载可能因在短时间内从用户端接收大量新的工作而频繁变化,这种变化会导致云环境中的资源利用不平衡,云平台无法高效运行。为了向用户提供高性能的云服务,对云计算资源进行高效的管理显得十分重要[2]。目前,云平台的资源管理方案可以分为自动管理和主动管理两种[3]。在自动管理模式中,当工作负载增加或减少到特定的阈值时,平台通过扩缩容技术来分配资源[4]。然而,对云平台中的资源进行扩缩容操作需要一段响应时间,该模式无法对工作负载过程中资源需求量的突变及时做出反应,存在一定的滞后性,不能给用户良好的体验感,并且可能导致违反服务级别协议(SLA)[5]。主动管理模式是管理人员通过对以往资源使用情况的分析,预估并提前为服务分配资源,有效地解决了自动管理存在的响应延迟问题,但该模式是根据历史资源的使用情况人为进行资源再分配,可能进一步造成资源浪费或分配不足等问题。
为解决上述问题并考虑负载预测对云资源高效管理的重要性,使用各种预测算法对云计算资源进行预测受到了学者们的极大关注。目前,国内外的预测方法主要分为基于统计学和基于机器学习的方法。基于统计学的方法主要包括多元线性回归[6]、指数平滑[7]和差分整合移动平均自回归模型(ARIMA)[8-9]等。但是,上述方法只能捕捉线性关系,无法获取时间序列负载数据的非线性特征,在负载预测中的效果不佳。为了对时间序列进行更准确的预测,基于机器学习的方法得到了广泛应用。递归神经网络(RNN)[10]具有捕获非平稳负载数据的能力,但存在梯度爆炸和梯度消失等问题。长短期记忆(LSTM)网络[11-12]和门控循环单元(GRU)[13-14]增加了基于RNN 筛选历史信息、选择性保存有用数据和丢弃无用数据的过程[15],解决了RNN 梯度消失和梯度爆炸的问题,使RNN 能够有效地处理长期时间序列数据[16]。然而,基于RNN 模型本身序列依赖的结构,导致其很难具备高效的并行计算,限制了其预测长度的能力。卷积神经网络(CNN)[17]因出色的负载数据趋势捕捉和并行能力而被频繁用于负载预测领域。文献[18]提出基于CNN 的时间卷积网络(TCN)预测模型,并使用多个序列建模任务证明该模型比传统的CNN 和RNN 模型有更好的效果。但是,CNN 在捕获长距离特征方面的能力较弱,已有学者通过堆叠网络深度解决了CNN 捕获长距离特征的问题。尽管如此,CNN 在这方面仍然弱于RNN 和Transformer[19]。
Transformer[20]在时序预测方面不需要考虑时间和距离问题,有助于模型对输入的每个部分均等可用,因此在处理远程信息和捕获远程依赖方面更有潜力。文献[21]提出一种基于Transformer 的多步预测模型Informer,该模型从3 个方面对Transformer在时序负载预测方面进行针对性优化,并通过多个真实数据集进行对比实验,结果表明在多步预测中该方法的预测性能优于其他主流预测方法。基于Informer的预测模型CNN-Informer[22]和Stacked-Informer[23]通过提取时序数据更多的底层特征,提升了模型预测精度。
虽然基于Informer 的改进模型通过堆叠模型本身或与其他模型进行组合提高了预测性能,但是Informer 模型在时序预测方面仍存在以下问题:1)正则卷积只能回溯线性大小的历史信息,造成模型感受野受限导致计算冗余,并且不能保证未来信息对于时序预测结果的影响;2)随着网络深度的增加可能使得网络退化及训练过程中的梯度消失或爆炸,造成模型训练收敛速度慢、预测性能下降。因此,本文提出基于改进Informer 的多步负载预测模型(Informer-DCR),通过将负载预测技术与主动管理模式相结合提高云环境中的资源利用率。本文主要贡献如下:
1)建立Informer-DCR 模型用于云计算资源负载预测。
2)改进编码器中蒸馏操作,将连接各注意力块之间的正则卷积替换为扩张因果卷积,使其提取特征中更多隐藏信息和时间关系,增加模型感受野及提升模型预测性能,并保证时序预测的因果性,防止未来信息的泄露。
3)优化模型主编码器的网络结构,通过增加残差连接使网络信息以跨层的形式直接进行深层传递,增强了特征多样性,使模型训练过程更加稳定,解决了深层网络的退化问题。
1 Informer 负载预测模型
目前,传统的Transformer 主要存在自注意力机制复杂度高、堆叠层的内存瓶颈、预测输出的速度慢等不足。Informer 对Transformer 在时序预测领域所存在的问题做了针对性的改进,具体为:提出一种稀疏概率自注意力机制代替传统自注意力机制,通过筛选出最重要的查询向量,实现了时间复杂度和内存使用量为O(LlogaL),大大减少了网络规模;提出自注意力蒸馏操作,通过正则卷积和池化操作减少维度和网络参数量;提出生成式解码器,只需一步便可生成全部预测序列,避免逐步预测造成的误差累计,缩短了预测时间。Informer整体架构如图1 所示。
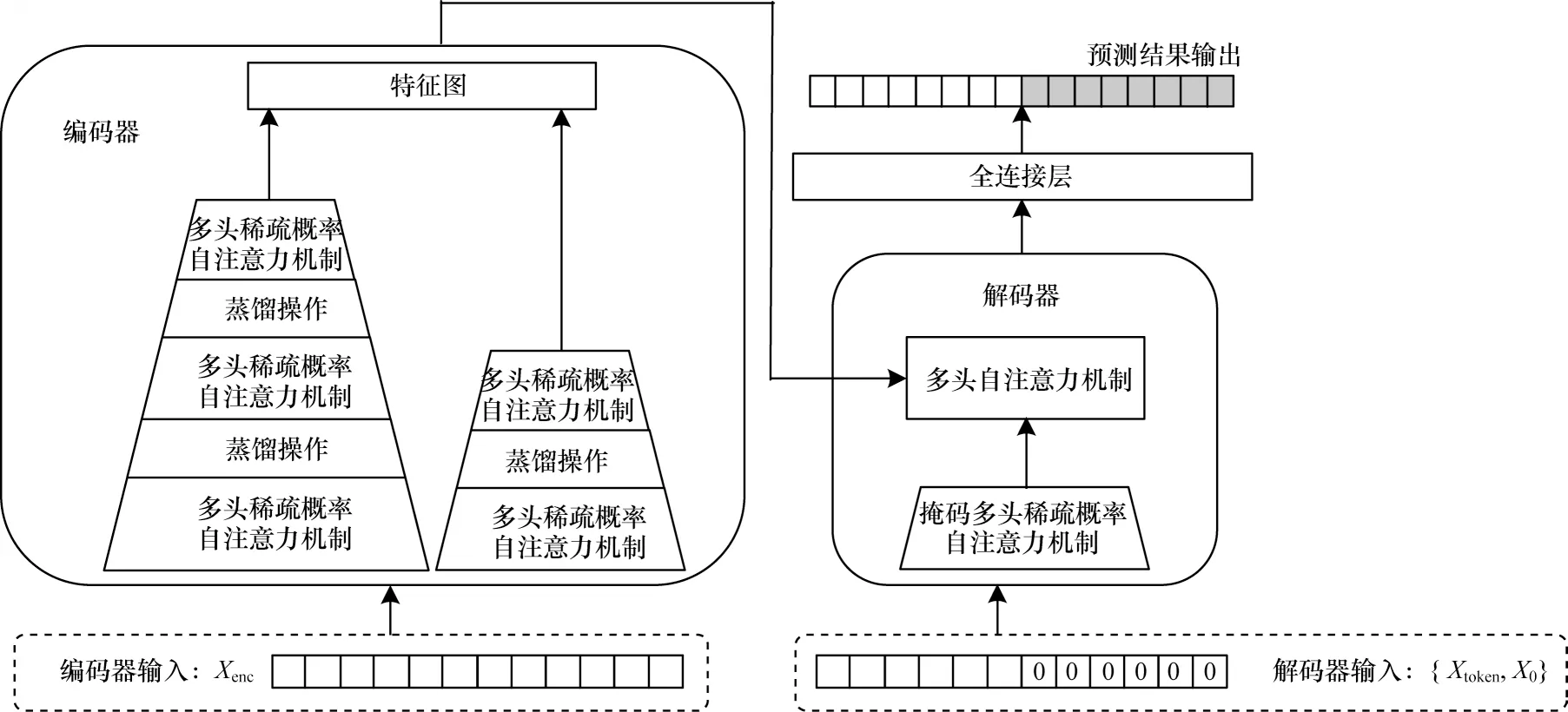
图1 Informer 架构Fig.1 Architecture of Informer
Informer 由编解码器体系结构组成,编码器和解码器均接收历史序列输入,但内容存在差异,具体如图2 所示。

图2 编解码器输入Fig.2 Input of encoder and decoder
编码器输入一段历史数据,解码器输入由编码器输入序列从后开始截取的一段与预测长度等长的0 填充序列组成。
Informer 中编码器是由多头稀疏概率自注意力机制和蒸馏操作堆叠而成的。传统的自注意力机制需要O(LQLK)的内存使用量以及二次点积计算,这是其预测能力较低的主要因素。稀疏概率自注意力机制是通过选取少数得分较高的点积对,同时将其他得分较低的点积对忽略,从而降低时间复杂度和内存使用量,具体如式(1)所示:
其中:Q、K、V分别是查询向量(query)、键向量(key)和值向量(value)组成的矩阵,是Q经过概率稀疏化后得到的;d是防止梯度消失而增加的比例因子;Softmax()是激活函数。
Informer利用蒸馏操作对具有支配特征的优势特征进行特权化,并在下一层构建一个聚焦的自注意力特征图,提取过程从第j层向第j+1层,如式(2)所示:
其中:[]AB代表注意力块;Conv1d()使用ELU()作为激活函数在时间维度上执行正则卷积操作,并在每个卷积层后增加一个最大池化层使下采样到其一半,从而将整个内存使用量减少到O((2-E)LlogaL),其中E是一个很小的数字。为了增强蒸馏操作的鲁棒性,Informer通过减半输入构建一个副本,并减少注意力块的数量使输出维度对齐。
Informer 所提出的生成式解码器使用标准解码器结构,由两个相同的多头注意力层组成,通过一个向前过程来产生预测输出。模型向解码器提供如式(3)的输入向量:
其中:是起始令牌;是目标序列的占位符。与编码器中多头稀疏概率自注意力机制不同,解码器中的自注意力机制为了防止每个位置关注未来的信息,避免自回归,将掩码多头稀疏概率自注意力机制的点积设置为-∞。
2 Informer-DCR 改进模型
本文主要针对云计算资源负载情况进行预测,考虑到云环境中负载资源存在一定的时序依赖关系,每一时刻的负载值均与该时刻之前的负载情况存在密切联系,因此对于负载预测模型而言,捕获长距离特征可以提供更多趋势信息,提升预测精度。Informer 在捕获长序列输入信息方面拥有较强的能力,预测性能也优于现有主流预测模型,然而该模型应用于时序预测时仍存在不足,主要为:在模型中蒸馏操作将自注意力块与正则卷积堆叠在一起,使感受野受限导致重复无意义的计算;没有考虑时间维度,造成未来信息对预测结果产生的影响;堆叠的深度增加引起了网络退化。因此,本文提出基于改进Informer 的多步负载预测模型,并针对其内部结构进行优化,将原编码器中注意力块之间的正则卷积替换为扩张因果卷积,并在主编码器堆叠中增加残差连接,编码器架构如图3 所示。

图3 Informer-DCR 编码器架构Fig.3 Architecture of Informer-DCR encoder
Informer-DCR 编码器是由1 个接收整个输入序列的主编码器和1 个切片减半输入的副编码器组成。假设主编码器中原始输入时序数据为L,将输入L经过1 个注意力块的输出以及经过3 个注意力块和2 个扩张因果卷积层的输出进行拼接得到1 个特征图,并将L进行减半操作得到L/2,副编码器的输入L/2 经过2 个注意力块和1 个扩张因果卷积层得到1 个特征图,最后将2 个特征图合并成1 个完整的特征图输入解码器。这种堆叠结构的目的是有效地提取输入长序列的时间特征,并提高预测序列输出的鲁棒性。
扩张因果卷积是由因果卷积和扩张卷积两部分组成的。因果卷积与传统卷积不同,因果卷积受到时间约束限制,将时间t的输出仅与前一层的时间t和更早的元素进行卷积来保证时序预测中的因果性,让网络的输出信息仅受过去输入信息的影响。为了确保经过卷积层的输出和输入具有相同的长度,仅在输入序列前侧进行零填充,防止未来信息的泄露。
虽然因果卷积能够很好地处理时序数据,但是当时序数据过长而网络需要学习更久远的历史信息时,必须增加卷积层数。这种方式只能在线性尺度上扩大对历史信息的捕捉,而且随着层数的增加,网络中参数成倍增加,使得网络训练难度变大。为了保持层数相对较小的同时增加感受野区域大小,扩张卷积算法被提出并与因果卷积配合使用。
扩张卷积也称空洞卷积,是将原始滤波器进行零膨胀得到一个具有更大滤波器的卷积,通过选择不同尺寸的滤波器或增加膨胀因子来灵活地调整模型的感受野,使顶层的输出能够接收更宽范围的输入信息,提升因果卷积对较长输入序列的建模能力。扩张因果卷积的具体实现过程如图4 所示(彩色效果见《计算机工程》官网HTML 版)。

图4 扩张因果卷积实现过程Fig.4 Implementation process of dilated causal convolution
因果卷积核仅对当前时间步t之前的输入信息做出响应,减少了对未来输入信息的冗余计算。模型选取卷积核尺寸为3,即某一时刻输出均是由前一层对应的位置和前两个位置的输入共同得到的,与未来时刻无关。扩张卷积通过增加扩张系数d,有效地扩展上层网络的感受野,形成更长的卷积记忆,随着网络层数加深,有效窗口的大小呈指数增长,模型通过较少的层数获得更大的感受野,降低网络复杂度的同时提高模型预测精度。对于时间序列X={x0,x1,…,xT-1,xT},元素xt进行扩张因果卷积:
其 中:F={f1,f2,…,fK-1,fK}表示大小为K的卷积核;xt表示t时刻的时序数据;fk表示卷积运算中的滤波器;d表示扩张系数。扩张因果卷积实现过程中最下层扩张系数d=1,表示输入时对每个时间点均进行采样,下一层d=2 表示每两个时间点作为一个输入。
然而,扩张因果卷积无法解决编码器中注意力块和卷积池化层堆叠导致的网络退化等问题,随着网络深度增加,网络获得的信息会逐层递减,影响模型训练的稳定性,并出现梯度消失或爆炸问题。针对该问题的处理方式是在主编码器中增加残差连接,核心思想为直接映射,即下一层不仅包括该层的信息,还包括该层经非线性变换后的新信息。这样可以保证即使堆叠网络深度,输出层仍可以从输入层接收更多的信息,模型训练依旧稳定,达到增加特征多样性、加快模型收敛的目的。残差连接实现过程如图5 所示,其中,残差块包括3 个注意力块、2 个扩张因果卷积+池化层。具体实现过程为:将第1 个注意力块的输出与第3 个注意力块的输出融合在一起,并使用1×1 卷积来保证2 个注意力块输出的特征图在相加时形状相同。

图5 残差连接实现过程Fig.5 Implementation process of residual connection
3 实验与结果分析
3.1 实验环境
实验环境设置如表1 所示。

表1 实验环境设置 Table 1 Experimental environment setting
3.2 数据预处理
3.2.1 实验数据集
为了验证Informer-DCR 在云计算资源负载预测方面的性能优于其他预测模型,使用Cluster Tracev2018 公开数据集进行实验对比,该数据集记录某个生产集群中4 000 台服务器8 天的资源详细情况。随机选取其中10 台机器8 天的资源使用情况,时间粒度选取为每台机器每5 min 使用的平均资源量,共20 636 条数据。数据分为训练集、测试集、验证集,三者占比分别为7∶2∶1。
3.2.2 数据处理
采用均值填充法进行缺失值处理。对于特征选择,所使用的数据集中记录每台机器7 种特征的使用情况,分别为CPU 利用率(cpu_util_percent)、内存利用率(mem_util_percent)、内存带宽使用率(mem_gps)、每千条指令缓存未命中数(mpki)、传入网络包的数量(net_in)、传出网络包的数量(net_out)、磁盘空间利用率(disk_usage_percent)。将这些特征输入模型前,通过特征选择算法来选择重要特征并重新组合,生成新的特征值。这样不仅可以减少特征数量,防止维度灾难,缩短训练时间,还可以增强模型的泛化能力,减少过拟合,增强模型对特征和特征值的理解。随机森林算法具有准确度高、训练速度快、鲁棒性好、不容易过拟合等优点[24-25],因此使用随机森林算法进行特征选择,如图6 所示。由图6 可以看出,CPU 利用率和内存利用率特征得分明显高于其他特征,分别为0.448 0和0.262 4,其他特征得分均小于0.1,因此选取CPU 利用率和内存利用率作为输入特征进行预测。

图6 各项资源的特征得分Fig.6 Characteristic scores for various resources
3.3 评价指标
在对云计算资源进行预测时,为提高预测精度,利用Informer-DCR 对云资源进行预测,同时采用3 个指标对预测模型的性能进行评价,分别是平均绝对误差(MAE)、均方误差(MSE)、均方根误差(RMSE),计算公式如式(5)、式(6)、式(7)所示:
其中:n为预测长度为实际值;yi为预测值。3 个评价指标的数值越低,代表模型预测性能越好。
3.4 对比实验
本节从预测性能、消融实验、模型对输入步长的敏感性、收敛性4 个方面进行对比实验。Informer-DCR 的超参数设置如表2 所示。
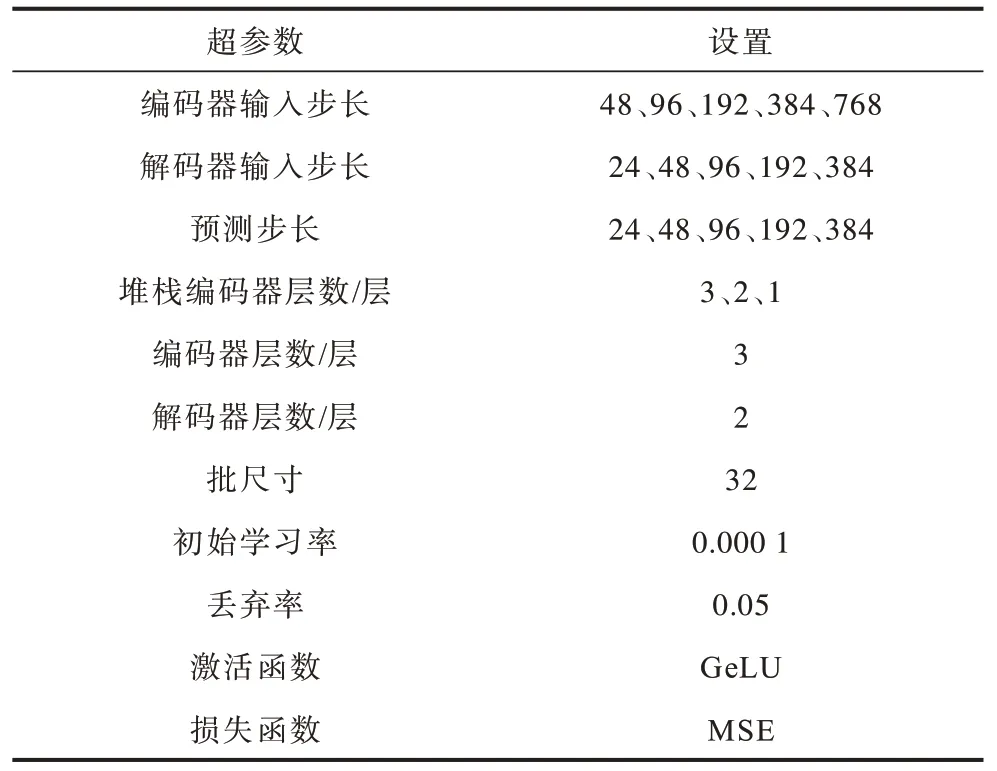
表2 超参数设置 Table 2 Hyperparameter setting
3.4.1 预测性能分析
表3 给出了Informer-DCR 与ARIMA、LSTM、GRU、TCN、Informer、CNN-Informer 等预测模型在不同预测步长下的预测性能对比,其中最优指标值用加粗字体表示,下同。由表3 可以看出,当预测步长分别为24、48、96、192、384 时,Informer-DCR 的各项预测性能指标均明显优于其他模型,说明该模型在多步预测方面具有更高的精度。具体表现为:1)与传统Informer 相比,Informer-DC 的预测精度更高,当预测步长分别为24、48、96、192、384 时,MAE分别降低了13.1%、12.1%、13.4%、13.8%、14.3%,这表明Informer-DCR 中加入扩张因果卷积和残差连接增加了感受野和特征多样性,使模型包含更多的输入信息和特征,从而在多步预测过程中取得更好的效果;2)Informer-DCR 与对比模型中效果最好的CNNInformer 相比,当预测步长分 别为24、48、96、192、384 时,RMSE 降低了8.5%、6.1%、8.2%、8.4%、10.8%,这表明尽管CNN-Informer 采用二维卷积神经网络提取到输入数据更多的特征信息,提高了预测精度,但效果并不显著,Informer-DCR 通过优化Informer内部结构,解决了Informer 在时序预测方面存在的不足,使模型预测精度得到较大幅度的提升;3)与TCN、GRU、LSTM、ARIMA 相比,当预测步长分别为24、48、96、192、384 时,Informer-DCR 的MAE 平均降低了21.9%、21.1%、25.4%、28.5%、34.6%;4)Informer-DCR 模型在不同预测步长下的MAE 比Informer、TCN 等主流预测模型降低了8.4%~40.0%。

表3 预测性能比较 Table 3 Comparison of prediction performance
3.4.2 消融实验分析
为研究Informer-DCR 模型中各个部分对预测性能的影响,以Informer-DCR 为基础进行消融实验。在实验过程中,移除扩张因果卷积模块的模型命名为Informer-R,移除残差连接模块的模型命名为Informer-DC。Informer-DCR 与Informer-DC、Informer-R和Informer 在不同条件下进行性能对比分析,实验结果如表4 所示。由表4 可以看出,Informer-DC、Informer-R 相比于Informer 预测性能均有显著提升。这表明:1)在Informer 中加入扩张因果卷积可以通过特定排列确保过滤器在有效历史数据中命中每个输入,并允许使用深度网络获得较长的有效历史,增加模型的感受野,提升预测性能;2)在Informer 中加入残差连接可以把较下层的特征图跳层连接到上层,增加特征多样性,使模型具有更好的预测结果。由此可见,将上述网络结构融合到模型中,并与其他模型在不同输入步长和预测步长下进行对比,Informer-DCR 均取得了较好的效果。

表4 消融实验结果 Table 4 Ablation experiment results
3.4.3 模型对输入步长的敏感性分析
为验证模型对编码器输入序列长度的敏感性,对比在预测步长均为24 及编码器输入步长为48、96、192、384、768 时Informer-DCR、Informer 和CNNInformer 的预测性能,模型对输入步长的敏感性实验结果如图7 所示(彩色效果见《计算机工程》官网HTML 版)。由图7 可以看出:增加输入步长可以使编码器包含更多的时序依赖信息,3 种模型的预测性能均有所提升;当预测步长均为24 及编码器输入步长为48、96、192、384、768 时Informer、CNN-Informer和Informer-DCR 的MAE 下降幅度有所区别,随着输入步长的增加,Informer-DCR 的MAE 仍有明显下降趋 势,而Informer 和CNN-Informer 的MAE 逐渐平缓。这表明CNN 在捕获长距离特征方面的能力较弱,导致CNN-Informer 的预测性能提升效果不显著,而Informer-DCR 相比于其他模型,其网络结构中扩张因果卷积具有更大的感受野,保留了较多原始信息,使得模型在预测方面的优势更加明显。

图7 模型对输入步长的敏感性实验结果Fig.7 Experimental results of model sensitivity to input step size
3.4.4 收敛性分析
本节实验内容是对比不同条件下Informer-DCR和Informer 训练过程的收敛性,主要考虑Epoch 的训练损失。图8 给出编码器输入步长为96、192、384 时Informer-DCR 和Informer 的收敛速度对比结果。由图8 可以看出:最开始由于网络需要训练,两个模型损失值较高且不稳定,随着训练次数的增加损失值逐渐趋于稳定;在不同输入步长下Informer-DCR 的收敛速度均快于Informer,并且随着输入步长的增加,两个模型的收敛性差异越来越大,Informer-DCR表现更好。这表明Informer 中蒸馏机制增加了网络深度导致难以训练,需要花费很长时间才能收敛,而残差连接使得Informer-DCR 在训练过程中信息传播更加顺畅,一定程度上解决了网络退化问题,使模型收敛更快速稳定。

图8 收敛速度对比Fig.8 Comparison of convergence speed
4 结束语
针对云计算资源负载预测问题,本文构建Informer-DCR 多步负载预测模型。通过使用扩张因果卷积增加模型感受野提升预测性能,同时保证时序预测的因果性。利用残差连接增强模型特征多样性和收敛速度,提升预测性能和训练过程的稳定性。在Cluster Trace-v2018 公开数据集上的实验结果表明,Informer-DCR 模型的性能表现优于Informer、CNN-Informer、LSTM 等主流模型,证明了其具有良好的预测性能,可以为云平台资源管理提供准确高效的技术支持。后续将进一步优化Informer-DCR 模型,使其能更好地提取时序数据的底层特征,提升预测精度,并将进一步降低模型中自注意力机制的计算复杂度和内存使用量,提高运行速度。
