面向FT-M6678 的对称矩阵特征值求解算法实现与优化
2024-02-29于立韩林罗有才商建东
于立,韩林,罗有才,商建东
(1.郑州大学计算机与人工智能学院,河南 郑州 450001;2.国家超级计算郑州中心,河南 郑州 450001)
0 引言
随着计算机技术的不断发展,其在工程领域方面的应用越来越多,其中离不开数字信号处理器(DSP)的支持[1]。DSP 由于其超低功耗,传统意义上一直是许多嵌入式系统的基石[2-4]。在国产DSP 芯片中,由国防科技大学研制的飞腾系列DSP 芯片采用了更为先进的制造工艺,进一步提高了芯片主频,其通用性能较强,并且在专用性能方面采用流处理器方式,在提高专用计算性能的同时,也能显著降低功耗[5]。其中,FT-M6678 不但具有强大的浮点运算性能支持,而且具有易扩展、软件兼容度高的特点,因此,FT-M6678 适合作为研究算法和优化的平台,同时,构建国产芯片的生态体系,对提升国防安全、民生经济、国家综合科技实力都有重大意义。
对称矩阵特征值求解(SYEV)是线性代数数学库中的一个重要组成部分,其主要负责求解给定对称矩阵的特征值和特征向量[6-7],解决该问题在许多科研工程中都有至关重要的作用,如量子力学、航空动力学、计算流体力学等应用领域[8-9]。纵观近些年来,国内学者对线性代数运算库愈加重视,尝试在不同国产平台适配并改进其所需的线性代数相关应用的算法:文献[10]基于飞腾2000+平台,使用OpenMP并行技术对BLAS 库3 级函数进行优化;文献[11]在神威众核平台SW26010 上实现了数学库xMath2.0,并对其进行针对性优化,该库包含LAPACK 等多种数学库,完善了神威平台的数学库运算需求;文献[12]面向鲲鹏处理器平台,通过向量化与多核并行实现了LAPACK 库中对称矩阵方程求解例程的性能优化,完善了鲲鹏平台线性代数运算基础;文献[13]基于龙芯3A 平台对LAPACK 线性方程组求解函数并行化,并且在龙芯平台上使得该算法在原LAPACK 基础架构上加速2 倍。目前未见有基于FT-M6678 平台实现与优化对称矩阵特征值求解的相关研究,且FT-M6678 现有的数学库并不能很好地满足线性代数相关的问题需求,因此,将本文研究内容在FT-M6678 上实现对满足飞腾平台线性代数计算需求具有重大意义。
本文研究内容主要包含如下方面:首先介绍FT-M6678 的体系结构,分析SYEV 的算法原理,在FT-M6678 平台上实现该算法;然后对整个算法程序的运行热点进行测试分析,针对热点情况对SYEV进行优化,采用基于FT-M6678 的编译优化、访存优化以及向量并行化方法,重点优化耗时高的部分;最后验证正确性并分析优化性能,正确性验证使用线性代数库LAPACK 官方提供的验证集,性能分析使用不同规模的输入矩阵,矩阵由LAPACK 官方提供的生成矩阵函数生成,分析各规模数据下的优化性能,对比优化前后的性能差异,并与TMS320C6678平台上的性能进行对比。
1 FT-M6678 体系结构与算法原理
1.1 FT-M6678 体系结构
FT-M6678 是由国防科技大学自主研发的数字信号处理器,单核理论计算峰值为16GFlops,具有高性能、易扩展的特点,可用于机载信号处理[14]、图像处理[15]、电子对抗等多个领域,满足嵌入式高性能计算需求,且兼容德州仪器(TI)的DSP 芯片TMS320C 6678 处理器 的软件 开发环 境[16-17]。FT-M6678 采 用新型Key Stone 多核架构和增强型内核M66x,为8 核DSP,每个核的处理频率为1 GHz。FT-M6678 的架构如图1 所示,其从功能上主要分为CorePac 内核、核外存储系统、互连网络、高速接口、低速接口、集成外设、全局控制寄存器、自举复位[18-19]等8 个部分。每个核具有1 级和2 级缓存,核外存储有共享内存通信(SMC)存储以及内存DDR3 存储,每个SMC 共享存储空间为4 MB,每个DDR3 最高可用2 GB。
由于FT-M6678 的硬件特性,其强大的浮点运算能力适用于线性代数中各问题求解的矩阵运算,这能很好地发挥飞腾平台的优势。
1.2 SYEV 算法原理
SYEV 算法求解特征值与特征向量使用QL、LQ或QR 分解算法。QR 算法的具体形式如式(1)所示,其中,A为对称矩阵,Q为正交矩阵,R为上三角矩阵。QL 或LQ 算法与此原理相同,不同之处为L代表使用的是下三角矩阵,且LQ 算法为右乘操作。
QR 分解算法是一个不断迭代的过程[20],迭代过程如式(2)所示,其中,上标T 表示该矩阵的转置(下文相同),变量k为迭代次数。
使用正交矩阵Q不断左乘A,将A的某些元素消零,其中正交矩阵Q的生成方法是通过HouseHolder反射变换。HouseHolder 反射变换是通过初等反射矩阵的连乘将非奇异矩阵转化为上三角矩阵[21],其只需求解n-1 个反射矩阵及其乘积,复杂度低于Givens 分解[22-23]。HouseHolder 反射变换原理如下:
假设非0 向量α∈Rn,I为单位矩阵,则满足:
如 式(3)所 示,形式如n阶矩阵P即 是HouseHolder 矩阵,该矩阵满足对称且正交的性质。将式(3)修改为式(4)所示的形式,H即为算法每一次反射的反射因子,其中,I为单位矩阵,v为单位正交矩阵,t为变换输入的标量参数。
因此,迭代过程可转化为式(5)到式(6)所列出的公式,其中,H(x)为第x代的HouseHolder 反射因子,R为上三角矩阵,每一次迭代将一列的对角线以下元素清零,使得矩阵无限趋近于一个上三角矩阵。
经过上述不断迭代,最终可收敛简化成式(7)所示的形式:
其中:Λ为对角矩阵,其对角线元素即为所求对称矩阵的特征值,而XT中包含与之所对应的特征向量。
2 面向FT-M6678 的SYEV 实现与优化
2.1 面向FT-M6678 的SYEV 算法实现
SYEV 算法实现过程如图2 所示。算法先将对称矩阵转换为三对角形式,转换方式为正交相似变换,这一步是为了简化数据量,减少后续计算的运算开销。

图2 SYEV 算法实现过程Fig.2 Implementation process of SYEV algorithm
程序在只求解特征值时,直接使用QL 或QR 算法计算一个对称矩阵的所有特征值;在既求解特征值又求解特征向量时,SYEV 会先生成正交矩阵,生成的方式是通过采用HouseHolder 反射变换,与将对称矩阵转换为三对角步骤中使用的正交矩阵生成方式相同,然后计算所有特征值和对应的特征向量,使用的算法是隐式QL 或QR 算法。
本文选用单精度浮点型数据类型进行算法实现,算法部分计算需要借助底层一些基本矩阵操作(如对称矩阵与向量乘等操作)来完成,该操作部分使用BLAS 二级函数[24-25]辅助完成。
2.2 热点分析
分别生成100×100、500×500、1 000×1 000 规模的对称矩阵,测试SYEV 的性能并且分析函数热点,单个函数运行耗时占比如图3 所示。

图3 运行热点分析图Fig.3 Analysis diagram of operational hotspots
图3 仅显示出耗时排在前9 位的操作运算,再后面的操作运算耗时几乎可以忽略不计。由该图可知,SYEV 的运行热点分布比较规律,注意到子程序矩阵平面旋转操作是耗时最多的,单个函数耗时占比超过总程序运行时间的50%,并且随着计算规模的增大,其占比也会变大,而剩余耗时的部分是一些BLAS 二级函数,如计算矩阵向量乘以及秩更新等,但都与矩阵平面旋转操作无法相比,因此,本文重点优化该操作部分。矩阵平面旋转功能上负责实现将一个矩阵从左侧或右侧进行平面旋转,在计算HouseHolder 反射因子部分会大量运行该操作。
2.3 编译优化
对于编译阶段的优化主要是根据不同的编译选项指导编译器来进行不同程度的编译优化[26]。FT-M6678 编译器提供了部分直接影响或控制程序优化的编译选项,通过合理地配置这些优化选项,可以达到提升程序运行效率的目的。编译优化是对程序最基础的优化,后续的优化均建立在编译优化之上,其选项的合理配置需要针对程序特点以及实验尝试进行验证。本文基于SYEV 算法的运行特点,经过测试,选择表1 列举的编译优化选项,以取得较好的加速效果,其中,-o3 会指导编译器根据程序语句、关键字等有效信息来源了解到循环执行次数和数据存放方式等信息,在编译阶段自动进行循环展开以及指令流水线等操作,但是效果上因程序而异,在本文研究内容中,经测试,须配合手动展开才能取得更好的优化效果。

表1 编译优化选项 Table 1 Compilation optimization options
2.4 访存优化
2.4.1 缓存优化
DSP 的运行耗时主要分布在两部分:一是计算所需的时间开销;二是数据存取的时间开销[27]。缓存优化是通过对Cache 加速,提高运算数据的存取效率。
FT-M6678 每个核内存储都采用了两级Cache 结构,其中L2 为512 KB,L1 分为一级程序缓存(L1P)和一级数据缓存(L1D),容量均为32 KB。此外,还有4 MB 的共享内存SMC 以及2 GB 的外部空间DDR3。FT-M6678 的存储结构与各级存储器的工作频率如图4 所示。
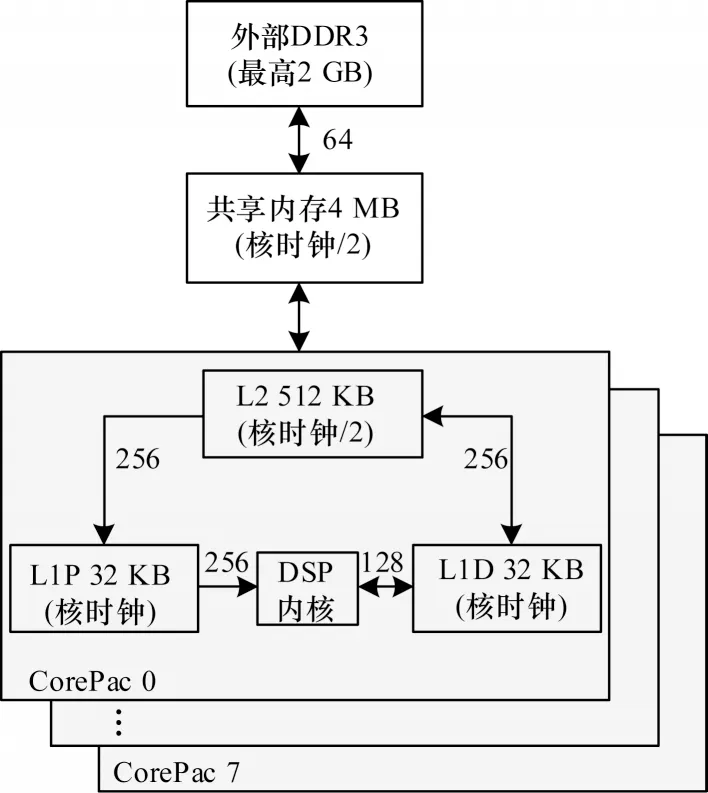
图4 FT-M6678 多级内核存储结构Fig.4 FT-M6678 multilevel kernel storage structure
FT-M6678 内核从L1P 中读取程序指令,从L1D中加载数据,L1D 和L1P 与L2 可直接通信,L2 可 直接与共享内存通信,而共享内存直接与外部DDR3通信。整体的核内通信分级分层划分明确,且离DSP 内核越远,存储器工作时钟越低,即内存访问的速度越慢。
本文在优化SYEV 算法中开启了L1、L2 缓存,设置寄存器与Cache 之间的通信,并将外部存储器设置为可缓存属性,在数据运算过程中将矩阵数据提前加载到缓存中,可在缓存层面优化数据读取,减少时间开销。
2.4.2 访存优化的资源分配
根据FT-M6678 的硬件特点,对硬件资源(.MEMORY)和段(.SECTIONS)进行分配,可根据程序段与数据段的大小将其分配到合适的位置,提高程序运行时的访存效率。
首先在硬件资源分配上分别把L1P 和L1D 的部分或全部设置为Cache,容量取最大为32 KB;L2 存储控制器是L1 存储器和更高级存储器的接口,把L2设为Cache,容量也取最大为512 KB;对于共享内存SMC 取最大为4 MB;对于外部存储DDR3,考虑到矩阵大小,取1 GB 空间。
其次是段分配。在text 段中存放程序代码,将该段放入DDR3 中;对于存放全局变量和常量的段,如cinit 段或const 段等,考虑到此类段数据量很小,故放入共享内存SMC 中;将sysmem 段用于程序中的函数动态分配存储空间,如malloc 空间等,该段也是堆空间存放的段。可根据输入的对称矩阵的大小将数据放入不同的段中:当矩阵规模不大时,可将sysmem 段放入共享内存SMC 中,数据无须从外部存储器再读入;当矩阵规模较大时,共享内存空间不足以支撑矩阵容量,将sysmem 段放入DDR3 内。
2.5 向量并行化优化
向量并行化优化主要针对耗时占比最高的矩阵平面旋转进行优化。首先分析该部分的代码特点,考虑循环展开,探究最佳循环展开次数,并使用单指令多数据流(SIMD)并行操作指令对计算部分以及读取部分进行向量化操作。
2.5.1 循环展开
矩阵平面旋转核心操作部分会大量使用双重for 循环,每一次循环实现2 个数组元素的互换,并且伴随乘法、加减计算。分别对该核心运算部分进行4、8、12 次循环展开,选取合适的展开因子,在保证性能的同时也要防止代码体过大。循环展开将迭代间并行转为了迭代内并行,可以在展开后的循环体内发掘数据级并行,生成向量访存和运算指令以提高性能。对比这3 次不同的展开运行效率发现,在1 000 阶矩阵的输入测试下,展开4 次与8 次效果相近,8 次稍优,展开12 次性能稍有下降,但整体上相差不大。展开4 次的伪代码示例如下:

2.5.2 向量化
FT-M6678 系 列支持32 位数 据的SIMD 指令,并且允许其在128 位向量上进行操作,如图5 所示,通过向量化操作将4 个32 位数据组成一个128 位的向量,运算时通过SIMD 指令实现128 位的向量乘,从而达到4 对32 位数据并行乘操作的效果,这样做的好处是可以充分利用FT-M6678 的寄存器增大处理器指令调度的空间,从而提高运算效率。

图5 FT-M6678 128 位并行乘示意图Fig.5 Schematic diagram of FT-M6678 128 bit parallel multiplication
FT-M6678 编译器提供同时支持128 位的并行操作数据类型_x128_t,指令示例为FT_fto128;支持的4 个float 并行乘的SIMD 指令示例为FT_qmpysp。FT_fto128 指令将取4 个float 类型的数据并定义为一个_x128_t 的向量数据放入寄存器中,FT_qmpysp指令则是实现2 个_x128_t 数据类型的相乘,即4 对float 数据的并行乘运算操作,运算的结果依然返回一个_x128_t。在本文算法的矩阵平面旋转核心操作上运用该向量化,将耗时的乘法操作并行执行。以4 次循环展开为例,4 次展开的代码中有16 次指令乘法操作,而向量化将这16 次指令乘法转为4 次指令执行,从而提升了运算的效率,以下为4 次展开的向量化伪代码:

3 实验结果与分析
本节从正确性验证、优化性能分析2 个方面来分析实验结果。正确性验证采用权威线性代数运算库LAPACK 官方提供的正确性验证集,将该验证程序移植到FT-M6678 平台上编译并验证结果;优化性能分析则生成不同规模的对称矩阵作为输入,测试运行时间,矩阵的生成选用LAPACK 官方提供的生成矩阵的方式,对比方式分为纵向对比和横向对比,即FT-M6678 优化前后的运行速度对比、FT-M6678优化后与TMS320C6678 平台对比,选用的对比平台TMS320C6678 是DSP 主流的芯片之一,与该平台对比能凸显FT-M6678 的可替代性与国产自主性。
3.1 实验环境
实验环境分别采用目标平台FT-M6678 与对比平台TMS320C6678,且设置C6678 的主频为1.25 GHz,2 个平台开发环境保持一致以便于控制对比变量,实验在单核运行环境下进行,具体参数如表2 所示。
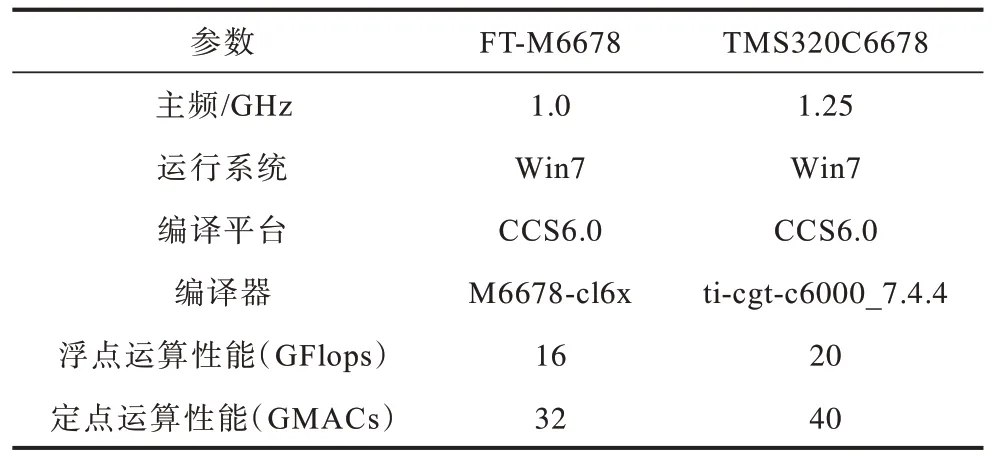
表2 实验环境参数 Table 2 Experimental environment parameters
3.2 正确性验证
验证集位于LAPACK 文件TESTING 下的EIG文件部分,验证过程是由MATGEN 功能部分生成测试矩阵,EIG 调用测试程序进行运算,判断运算结果是否正确。由于EIG 部分测试范围广泛,测试的是所有有关矩阵特征问题的例程,而对称矩阵特征求解算法部分的验证由EIG 下的子程序SEP 测试程序负责,因此只需要执行该部分子程序即可。
在FT-M6678 上运行移植后的测试程序,输入SEP 默认测试参数,验证实现且优化后的算法,结果如图6 所示,在默认给定的不同测试规模下,正确性测试用例对算法部分进行4 662 次测试,对驱动例程部分进行14 256 次测试,FT-M6678 平台均通过测试,验证了算法的正确性。

图6 FT-M6678 正确性测试结果Fig.6 FT-M6678 correctness test results
3.3 优化性能分析
分别生 成1 000×1 000、2 000×2 000、3 000×3 000、4 000×4 000、5 000×5 000 规模的对称矩阵作为输入,测试矩阵生成使用LAPACK 官方提供的MATGEN 功能部分,选用生成矩阵函数LATMS,该函数可根据用户指定的特征值与特征向量生成对应的对称矩阵,并且该函数提供种子参数,输入LAPACK 提供的不同种子生成的测试矩阵数值也不同。分别在FT-M6678 以及TMS320C6678 平台上运行测试矩阵,相同阶数运行3 次以上取结果平均值,数据精确到小数点后3 位。
本文算法在FT-M6678 上基于不同对称矩阵规模的优化性能对比结果如表3 所示。由表3 可知,矩阵规模在3 000×3 000 后加速比趋于稳定,故选取该阶数下的测试数据分析单步优化性能。

表3 FT-M6678 优化前后性能对比 Table 3 Performance comparison of FT-M6678 before and after optimization
表4 列出了单步优化分析数据,其中数据为多次运行取的平均值,误差范围保持在毫秒级。表4中的优化是一个叠加的过程,即先进行编译优化,在编译优化的基础上依次进行访存优化和向量并行化。在实验中尝试去除单个优化后均不能达到最佳效果。以编译优化为例,若单独去除编译优化,除了编译优化这部分的性能加速会受到影响外,向量并行化优化的加速效果也会下降,原因在于编译优化会对算法次热点的部分进行总体性优化,提升了主热点子程序的耗时占比,若去除编译优化,主热点子程序的耗时占比会下降,对该部分的向量化优化性能也会随之下降。
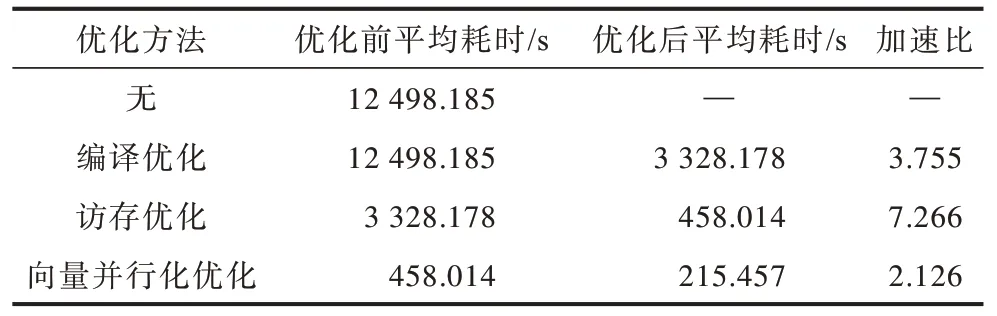
表4 单步优化数据 Table 4 Single step optimization data
在FT-M6678 平台上对1 000×1 000 以上规模对称矩阵运行测试后,编译优化加速比约为3.697~3.794,访存优化加速比可达到7.104~7.351,其中主要的性能优化来源于Cache 的数据预取,开启缓存优化可以很大程度上降低矩阵数据的访存开销,而向量并行化优化可再将速度提升约1.930~2.149 倍。
表5 为算法在FT-M6678 与TMS32C6678 上的对比结果。结合表3 分析可知,在优化前FT-M6678平台与TMS320C6678 运行性能差距较大,但在优化后FT-M6678 运行性能比TMS320C6678 性能更好。
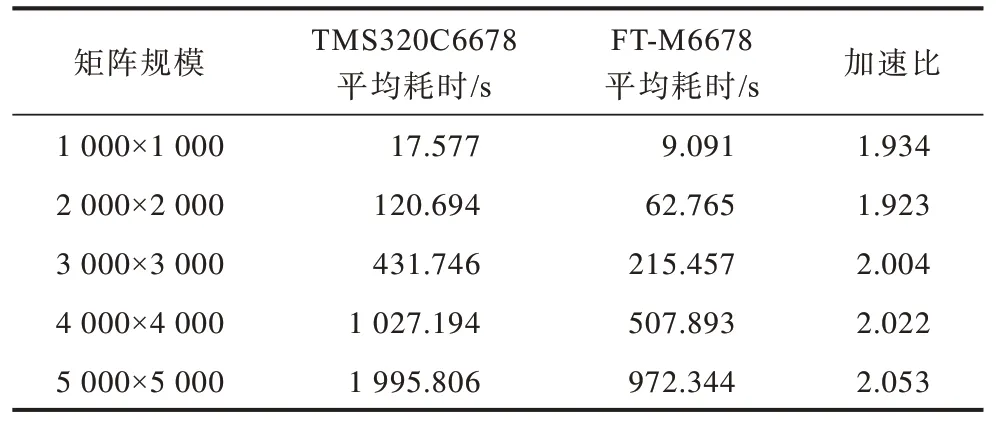
表5 FT-M6678 与TMS32C6678 性能对比 Table 5 Performance comparison between FT-M6678 and TMS32C6678
图7为纵向与横向加速比对比,由该图可知,本文算法在FT-M6678 上的整体加速效果较好,优化前后的加速比可达51.399~58.346,优化后较TMS32C6678平台运行加速比可达1.923~2.053。
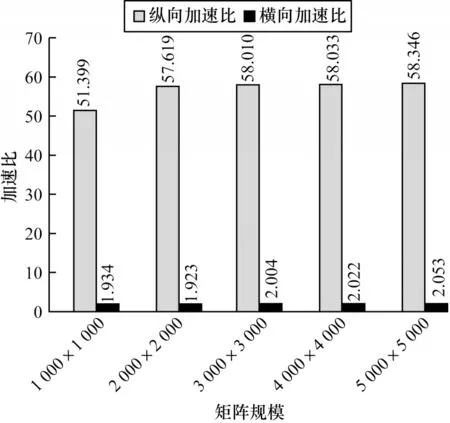
图7 纵向与横向加速比对比Fig.7 Comparison of longitudinal and lateral acceleration ratios
4 结束语
本文面向FT-M6678 平台实现对称矩阵特征值求解算法并对其进行优化。通过分析FT-M6678 的体系结构以及求解算法的原理与过程,在FT-M6678平台实现该算法,并对算法进行针对性优化,充分发挥FT-M6678 平台的运算优势,分别使用基于FT-M6678 平台的编译优化、缓存层面优化、基于FT-M6678 和程序运行的硬件资源和段分配优化、针对算法的循环展开以及向量并行化优化。对实现且优化后的算法进行正确性验证与优化性能分析,经测试,正确性验证全部通过,性能提升明显,FT-M6678 最终优化效果较优化前速度提升51.399~58.346 倍,对 比TMS32C6678 平台速 度提升1.923~2.053 倍,实验结果证明FT-M6678 具有可行性,其在性能上可以替代TMS32C6678 平台,且具有国产自主可控性。后续可考虑使用OpenMP 多核并行以及对算法底层所调用的BLAS 函数进行优化,进一步提升优化性能。
