融合特征权重与改进粒子群优化的特征选择算法
2024-02-28刘振超苑迎春王克俭
刘振超,苑迎春,2,王克俭,2,何 晨
(1.河北农业大学信息科学与技术学院,河北 保定 071000;2.河北农业大学河北省农业大数据重点实验室,河北 保定 071000)
1 引言
大数据时代,高等教育信息建设迅速发展,使得高校的教育教学数据逐年剧增,有效挖掘并合理利用高校教学数据对学校管理、教师教学及学生自我认知的提升都具有重要价值[1]。决策树因其分类准确率高、运算效率高,被广泛应用于教育教学数据挖掘中。但是,由于教育教学等数据具有维度高、冗余多等特点,若将高维原始数据直接应用于决策树分类,决策树分类的准确率并不理想。特征选择[2]是数据预处理的关键步骤,是从原始特征集合中筛选出对分类模型性能贡献度最高的特征子集。特征选择不但能有效降低数据集特征维度,提升分类模型的学习效率,还可以从原始数据集中选择对分类器分类性能贡献最高的特征子集,从而提高分类器的分类准确率[3]。常见的特征选择算法根据其是否包含相关学习算法可以分为过滤式(Filter)和封装式(Wrapper)2种。
Filter特征选择算法[4]通过数据非标签特征与标签特征之间的潜在规律以及数据本身内在性质判断数据特征的优劣,进而筛选特征子集。常用方法有互信息法[5]、信息增益法[6]和特征权重法[7]等。该类算法具有简单易行、效率较高和评价标准独立于分类算法等特点。
Wrapper特征选择算法由分类器和搜索算法组成,以分类器的分类准确率作为性能评估标准,通过对原始数据特征集进行搜索得到特征子集。该类算法能有效筛除冗余特征,提高分类准确率。已有研究人员利用粒子群优化PSO(Particle Swarm Optimization)算法[8]、灰狼算法GWO(Grey Wolf Optimizer)[9]等元启发式算法作为搜索策略,有效提高了所选特征质量和数据分类准确率。例如,吴晓燕等[10]利用樽海鞘群算法和粒子群优化PSO算法进行特征选择,在不同UCI(University of California, Irvine)数据集上均可选出最佳特征子集,并在多项评估指标上获得了较好效果;Zhang等[11]提出利用粒子群搜索特征子集的封装式算法,使用C4.5算法作为评估算法,实验结果表明该算法提取的特征子集有较高的辨识度。Wrapper算法尽管提升了分类准确率,但当数据维度较高时,仍存在计算代价高、效率低等问题。
Filter和Wrapper特征选择算法在特征选择方面各有优势和不足,因此有研究人员[12]提出了将2类算法融合使用的特征选择策略。该策略的一般流程为:首先,使用Filter算法剔除部分冗余特征,以减小启发式算法的特征搜索规模;然后,将Filter算法筛选出的特征子集传递给Wrapper算法,再进一步搜索最优特征子集。王金杰等[13]将粒子群优化算法和互信息融合成混合式多目标特征选择方法,在15个UCI数据集上的实验结果表明,该算法能够有效减少特征个数,降低分类错误率。肖艳等[14]针对面向对象土地分类中数据特征维数过高的问题,提出了将RELIEF-F和粒子群优化算法混合的特征选择算法,有效降低了土地数据维度,提高了面向对象土地分类的效率。虽然上述文献均使用了包含粒子群的融合式特征选择算法,在特征选择方面进行了有效改进,但相关研究表明[15,16]:粒子群优化算法可能因迭代初期种群个体多样性的快速降低使得算法收敛过早,出现“早熟”现象,进而影响特征选择算法的性能。
综上分析,本文提出一种融合特征权重与改进粒子群优化算法的混合式特征选择算法RF- ATPSO(RELIEF-F AdaptiveT-distribution Particle Swarm Optimization)。该算法利用特征权重过滤法剔除部分冗余特征,有效降低后续改进粒子群优化算法的搜索规模;通过自适应权重和T-分布扰动2种改进策略,平衡粒子群优化算法的全局探索和局部开发能力,提高粒子群的多样性,进而保证在Wrapper算法特征选择时不易陷入局部最优,从而提高算法的特征选择性能。
2 改进粒子群优化算法
搜索算法是Wrapper特征选择算法中的关键组成部分;而粒子群优化PSO算法因其优越的全局搜索和寻优能力在各个领域被广泛应用。因此,本文利用粒子群优化算法在Wrapper算法中搜索最优特征子集。但其迭代初期种群个体多样性的快速降低会使得算法收敛过早,容易陷入局部最优,进而影响选出的特征子集的质量。因此,本节通过自适应惯性权重和T-分布扰动2种策略改进粒子群优化算法,提高其寻优能力,从而提高Wrapper特征选择算法的性能。
2.1 粒子群优化算法基本原理
粒子群优化算法是Kennedy等[17]根据鸟群捕食行为中寻找最佳觅食区域的过程所提出的一种智能算法,具有原理简单、参数少等优点。在粒子群优化算法中,鸟群中的每个个体都是一个粒子,每个粒子均记录自己所找到的最佳觅食位置(局部最优解),粒子群中所有粒子的最佳觅食位置可以看作全局最优解,每个粒子的觅食位置拥有食物的可能性通过适应度刻画。
假设个体数为N的粒子群在D维空间中寻找最优解,其中第i个粒子在N维空间中可用位置Xi=(xi,1,xi,2,…,xi,D)表示,第i个粒子的飞行速度设为Vi=(vi,1,vi,2,…,vi,D),第i个粒子的历史最优位置称为个体最优值Pi=(pi,1,pi,2,…,pi,D),整个粒子群的最优位置称为全局最优值Gbest=(gbest,1,gbest,2,…,gbest,D)。根据第i个粒子、第i个粒子最优值Pi和全局最优值Gbest对粒子的速度和位置进行更新,更新公式如式(1)和式(2)所示:
v′i,d=ω×vi,d+c1r1(pi,d-xi,d)+
c2r2(gbest,d-xi,d)
(1)
x′i,d=xi,d+vi,d
(2)
其中,ω表示粒子的惯性权重,该值将会影响算法的收敛性;c1和c2表示学习因子,即加速常数;r1、r2表示0~1之间的随机数;1≤d≤D。
根据上述公式可以看出,粒子群优化算法寻优基于本身(局部最优)及周围个体的经验(全局最优)进行决策。在迭代初期,粒子群的个体多样性迅速降低,导致算法提前收敛,从而丢失一些重要的位置信息。针对以上不足,本文从2个方面对粒子群优化算法进行改进,平衡算法的全局探索和局部开发能力,提升粒子群优化算法的搜索精度。
2.2 自适应惯性权重策略
ω为粒子的惯性权重,其取值将影响算法收敛性。在粒子群迭代过程中,算法迭代前期需要增加粒子变化步长,从而较早定位全局最优解所在的区域;算法迭代后期则需要减小粒子变化步长,使粒子在该区域内精细化搜索,以找到全局最优解。基于上述思想,本文提出自适应惯性权重策略来平衡算法的全局探索和局部开发能力。ω的计算可用式(3)表示:
ω=0.8×e-3(t/tmax)2
(3)
其中,t表示迭代次数,tmax表示最大迭代次数。ω在迭代初期尽可能取最大值,使算法步长迅速变化,方便进行全局搜索;随着迭代的进行,权重不断减小,侧重进行局部搜索。该策略有效平衡了算法的全局探索和局部开发能力。
2.3 T-分布扰动策略
在迭代初期粒子种群个体多样性迅速下降,导致迭代后期种群多样性较低。粒子群的群体最优值远离全局最优值时,粒子易向错误方向进化和学习,此情况下极易陷入局部最优。本文提出了一种基于T-分布的扰动策略,以实现在算法迭代过程中增加粒子种群的多样性并及时跳出局部最优。即如果经过连续几次迭代,当前粒子的最优适应度值基本没有或不再发生变化,则认为算法陷入局部最优,在这时加入扰动让粒子震荡,使其跳出局部最优,这样也增加了种群多样性。该策略如式(4)所示:
(4)
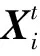
3 融合特征权重和ATPSO的特征选择(RF-ATPSO)算法
在过滤式算法中,特征权重算法RELIEF-F具有运行效率高、特征选择结果辨识度好的优势。本文提出双策略改进粒子群优化算法平衡了全局探索和局部开发能力,增加了粒子的多样性,提高了粒子群优化算法的搜索能力。基于此,提出一种将特征权重算法RELIEF-F与改进粒子群优化算法融合的混合特征选择算法。该算法主要包括2部分:首先使用特征权重算法对原始特征集合进行初步特征筛选;然后从筛选后的特征集合中利用改进粒子群优化算法搜索最优特征子集,提高所选特征子集的精度及后来的分类准确率。其中又包括2个关键步骤,分别是粒子群二进制转化和适应度函数设计。
3.1 特征权重算法RELIEF-F
RELIEF-F算法是Kononenko等[18]在1994年基于RELIEF算法改进的一种适用于多分类的特征选择方法。
特征权重计算流程如下:
重复执行步骤(1)~步骤(3)共m次:
(1)从数据集中随机抽取样本R,选择R的猜中近邻和猜错近邻各k个,分别记作集合H={h1,h2,…,hk},M={m1,m2,…,mk}。
(2)根据以下规则进行特征权重更新:若R和H中所有样本在某个特征上的距离小于R和M中所有样本的距离,说明该特征对区分同类和异类样本最近邻有益,则增加该特征权重,反之降低该特征权重。
(3)根据式(5)和式(6)更新特征A的特征权重,直到最大迭代次数结束。
(5)
(m×k)
(6)
其中,A表示样本的一种特征,max(A)和min(A)分别表示特征A上的最大取值和最小取值,R[A]表示样本R的特征A上的值,hj[A]表示猜中近邻中第j个样本hj在特征A上的值;diff(A,R,hj)表示样本R与样本hj在特征A上的差;P(C)表示C类的比例;P(class(R))表示随机抽取样本R所属类别的比例;mj表示C类样本中的第j个最近邻样本。
3.2 粒子群二进制转化方式
基于ATPSO(AdaptiveT-distribution Particle Swarm Optimization)法对数据集进行特征选择,可以看作将解空间限定在{0,1}范围内的二进制优化问题。需要注意的一点是,进行特征选择时,需要将连续型优化问题转换为离散型优化问题。
首先要对粒子群中的粒子进行编码。一个完整的特征选择解对应改进粒子群优化算法中的一个粒子,粒子的维度与原始数据集中样本的特征属性数量相同,且粒子群个体的某个维度值xi,j∈{0,1}。若要将离散粒子群与特征选择问题正确对应,需定义粒子群编码规则。编码规则为:若xi,j=1,表明第i个粒子的第j个特征被选择,若xi,j=0,则表明第i个粒子的第j个特征未被选择。
除粒子编码问题外,连续型优化问题如何转换为离散型优化问题也同样重要。本文利用Sigmoid函数将连续型变量转换为二进制形式。Sigmoid函数如式(7)所示:
(7)
具体到特征选择上,需要将连续型粒子的各个维度映射到{0,1},需将xi,j带入Sigmoid函数,结果如式(8)所示:
(8)
其中,映射函数T(·)表示粒子中的元素xi,j取值为1的概率。综上所述,粒子群的位置更新策略可以用式(9)进行描述:
(9)
其中,rand为[0,1]的随机数。若随机数大于或等于元素xi,j取值为1的概率,则rand取值为1,否则取值为0。
以粒子群的某一种特征选择解为例。假设原始数据集拥有7个特征,在ATPSO算法迭代中某个粒子位置的结果如图1所示。由图1可知,xi,2=xi,3=xi,5=xi,6=1,xi,1=xi,4=0,表明第i个粒子将原始数据特征2,3,5和6选中作为特征选择的最优特征子集,将原始数据特征1和4筛除。最终利用分类器可以基于选出来的最优特征子集进行模型训练与数据分类。

Figure 1 Feature selection solution图1 特征选择解
3.3 适应度函数设计
数据集的特征选择可以转化成多目标优化问题。优化目标为:在满足特征选择数量最小化的同时,也最大化分类器的分类准确率。基于上述2个优化目标,本文将适应度函数定义为式(10):
(10)
其中,error_rate表示指定分类算法(本文采用决策树算法)的误分率,D表示数据集中样本的特征总数量,RF表示特征选择算法最终所选择的特征子集大小,α、β分别对应分类算法误分率和特征子集大小在适应度中的重要性。α、β∈[0,1],且α+β=1。
3.4 RF-ATPSO算法流程
RF-ATPSO特征选择算法首先使用特征权重算法对原始特征集合进行初步特征筛选,然后从筛选后的特征集合中利用改进粒子群优化算法搜索最优特征子集,最终得到最优特征子集。算法详细步骤如下所示:

算法1 RF-ATPSO特征选择算法输入:基准数据集。输出:最优特征子集以及分类算法的准确率。步骤1 输入基准数据集,将其按照7∶3的比例划分为训练集和测试集,设置C4.5为评估算法。步骤2 使用RELIEF-F算法计算各个特征权重并按照权重对特征排序。步骤3 根据设定阈值对有序的特征集进行筛选。步骤4 初始化粒子群优化算法参数,初始化粒子初始位置并利用式(9)实现粒子位置和特征集的映射。步骤5 利用式(10)计算粒子适应度值。步骤6 比较每个粒子的适应度值,更新全局和局部最优解。步骤7 利用自适应惯性权重策略(式(1)和式(2)所示),更新粒子位置。步骤8 执行T-分布策略。步骤9 若未达到最大迭代次数则跳转至步骤5。步骤10 输出最优特征子集和分类准确率。
4 实验与结果分析
4.1 数据集介绍与实验设置
4.1.1 数据集介绍
为充分验证本文提出的RF-ATPSO算法的有效性,本文基于加州大学UCI机器学习库中的6个标准数据集进行实验。这些数据集分别来自不同领域,如Spambase主要用于冗余邮件的识别分类,Arrhythmia心率失常数据集和Cancer癌症数据集为医学数据集。
表1简要介绍了上述6个UCI数据集和学生画像指标数据集的样本数量、特征数量和类别数量。

Table 1 Datasets introduction
为进一步验证本文算法的鲁棒性,实验选用本研究团队构建的某高校学生学业成绩画像指标数据集。该数据集从学分体系模块、成绩体系模块和课程指标体系模块3个方面构建学业指标体系,全方位刻画学期、学年和课程类别等方面的学生学业成绩情况。
构建的学生学业成绩画像指标具体如表2所示。在表2中,学分指标体系拥有1个一级指标,二级指标按照课程类别、课程属性进行划分;成绩指标体系拥有3个一级指标,当前总绩点排名二级指标按照课程类别进行划分,成绩波动程度二级指标按照学期学年时间线进行划分,总挂科率二级指标按照课程类别进行划分;课程指标体系拥有5个一级指标,共将学生课程分为3段,总优秀课程学分率是对总课程优秀率的补充,其次是低于课程均分率,最后为及格率,二级指标均按照课程种类或时间线进行划分。
本文使用分类算法的分类准确率来评估特征选择算法所选特征子集的优劣。因此,本文实验中对原始数据集与经过特征选择后的数据集使用C4.5决策树算法的分类准确率和最终选择特征的数量进行评估。本文实验包括基于UCI公共数据集实验和应用实验,之后再在学生画像指标数据集上进一步评估算法的应用能力。
4.1.2 实验设置
本文实验的机器配置参数如下:基于Intel®CoreTMi56300HQ、2.6 GHz主频、16 GB内存以及Windows 10操作系统,实验仿真软件采用PyCharm, 2020.2版本。
参数设置会影响算法的全局收敛性能。控制参数实验被广泛用于调度优化、组合优化和函数优化等问题,具有易于理解、便于实现等优点[19,20]。因此,本文将控制参数实验用于算法参数的设定。通过实验设计,对粒子群优化算法的2个学习因子(c1和c2)进行设定。本文给出了参数选择表,如表3所示,共选取9组参数组合,并将式(10)作为适应度函数。由于算法的随机性等特点,本文将每组参数运行10次的结果取平均值作为最终适应度值。通过9组实验结果可以发现,学习因子c1和c2值为2时,算法的适应度值最低,算法的性能最好。为保证实验的公平性,最大迭代次数和种群规模均与对比算法的一致。

Table 3 Parameter selection table
因此,所用粒子群优化算法的参数设置如下:学习因子c1和c2值为2,粒子个数N值为30,最大迭代次数tmax值为100。
4.2 UCI公共数据集实验
4.2.1 UCI公共数据集实验数据集介绍
为了检验提出的RF-ATPSO算法的性能及稳定性,本文基于UCI公共数据集,将RF- ATPSO算法与传统特征选择算法(包括RELIEF-F、PSO、GWO、RFGWO和RFPSO算法)进行对比实验。
实验分别在6个UCI公共数据集上进行,通过计算各算法选出的特征子集的准确率来评估算法的性能。在每个数据集上取20次实验的实验结果,分别选取最优准确率(Best)和平均准确率(Avg)2个指标来度量不同算法的性能。表4展示了RF-ATPSO算法与传统特征选择算法在6个数据集上取得的分类准确率。
由表4可知,C4.5算法在其原始特征集合上的准确率均比经过特征选择后的准确率低,出现这种现象主要因为原始数据高维特征空间和特征高度冗余对C4.5的分类结果产生了较大影响,但是也存在经过特征选择后的特征子集辨识度变差的情况。
表5给出了RF-ATPSO算法与传统特征选择算法从6个数据集中提取的平均特征子集规模。由表5可知,基于RF-ATPSO算法对数据集进行特征选择后,特征空间维度明显减小。观察表4和表5可知,RF-ATPSO算法在Meu、Scadi、Can- cer、Arrhythmia和HillValley 5个数据集上所选的特征子集规模最小且准确率最高,即能以最低的特征空间维度取得最高的准确率。总之,本文提出的RF-ATPSO算法在保证准确率的情况下,可以有效提高C4.5算法的运行效率。
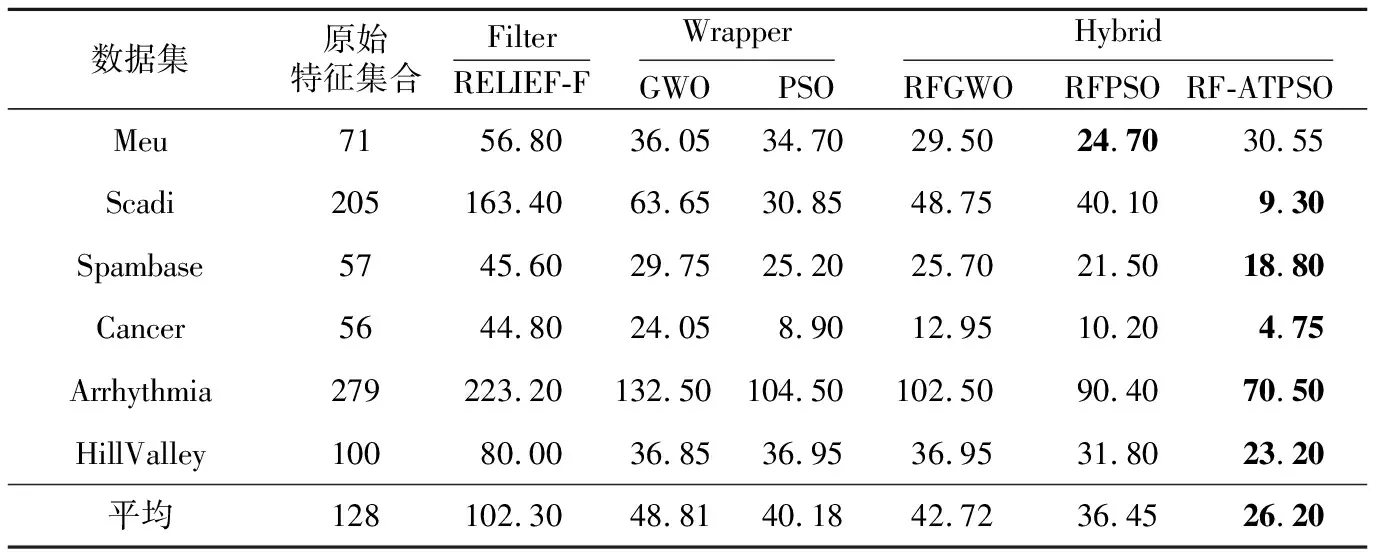
Table 5 Average sizes of feature subsets extracted by RF-ATPSO algorithm and traditional feature selection algorithms from 6 datasets
进一步分析表4中的实验结果,可以发现:对比3种传统的Filter和Wrapper算法RELIEF-F、GWO、PSO可知,经过特征选择后,C4.5算法分类准确率均有不同程度的提高。2种Wrapper算法在不同数据集上的性能表现不同,在Meu、Scadi、Spambase和HillValley数据集上,PSO算法的结果最优,在Cancer和Arrhythmia数据集上,GWO算法的结果最优。整体而言,PSO算法要优于RELIEF-F和GWO算法,平均分类准确率较2种算法分别提高了7.68%和0.70%。在所选特征子集规模上,PSO算法在6个数据集上均优于GWO算法,平均特征子集规模比GWO算法的低8.63。总体而言,PSO的特征选择结果较GWO具有一定优势。
对比3种混合式算法可知,算法针对不同的数据集,性能可能也会有所区别。由表4可知,在Scadi、Cancer、Arrhythmia和HillValley数据集上,RF-ATPSO平均分类准确率最高,较RFGWO和RFPSO算法的均有小幅度提升,分别为1.51%,1.29%;在Meu数据集上,平均准确率最高,但其最高分类准确率表现并非最优;在所选特征子集规模上,RT-ATPSO算法在除Meu外的5个数据集上,特征子集规模最小;对比本文提出的RF- ATPSO和其他特征选择算法可知,RF-ATPSO算法在Spambase数据集上分类准确率未达到最优,但整体而言RF-ATPSO的平均分类准确率达到81.54%,在所有数据集上均表现最优。
4.2.2 UCI公共数据集收敛性对比
本节实验将GWO、PSO、RFGWO、RFPSO和RF-ATPSO算法进行对比分析,图2为3种封装式特征选择算法在6个数据集上的错误率收敛曲线。

Figure 2 Error rate convergence curves图2 错误率收敛曲线
从图2可以看出,在Cancer、Arrhythmia和HillValley数据集上,RF-ATPSO算法的收敛曲线均在GWO、PSO、RFGWO和RFPSO算法的之下;在Cancer和HillValley数据集上,RF-ATPSO算法拥有较低的初始适应度值,并且能快速收敛至全局最优解,在所有算法中收敛速度最快;在Arrhythmia数据集上,RF-ATPSO算法在迭代前期收敛速度低于RFPSO和RFGWO算法的,但在第30次迭代时,可迅速跳出局部最优解,向全局最优解收敛;在Scadi数据集上,没有经初步特征选择的PSO算法收敛速度较慢,但其优于GWO和RFGWO算法,RF-ATPSO算法初始和最终收敛值最低,具有较快的收敛速度;在Meu和Spambase数据集上,尽管RF-ATPSO算法没有取得最优的收敛效果,但RF-ATPSO算法的收敛曲线在RFPSO的之下,因此本文提出的改进策略有效,并且利用PSO算法进行特征选择后均优于使用GWO算法的。经过RELIEF-F算法初步筛选特征后的RFPSO和RF-ATPSO算法收敛速度和收敛适应度值均不如PSO算法的,说明在上述2个数据集上RELIEF-F算法筛选过的特征子集本身辨识度差,在原特征空间中搜寻效果更佳。
4.3 学生学业成绩画像指标数据集实验
4.3.1 分类准确率和收敛性分析
为进一步验证RF-ATPSO算法的有效性,在表2所示的某高校学生学业成绩画像指标数据集上进行对比实验。选取计算机专业四年学业成绩数据,按照本文设计的特征指标体系,构建出的学生学业成绩画像拥有227维特征。实验中RELIEF-F、GWO、PSO、RFGWO、RFPSO和RF-ATPSO算法分别运行20次,分类准确率均值计算结果如表6所示。
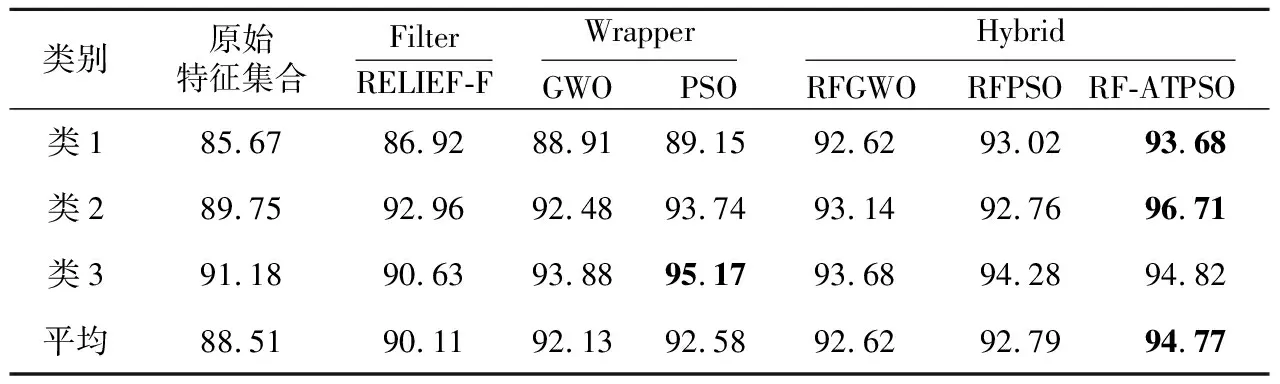
Table 6 Classification accuracies of feature selection for the portrait index dataset
由表6可以看出,C4.5算法在原始数据集上的分类准确率较差,平均准确率仅为88.51%,比用RF-ATPSO算法进行特征选择后的平均准确率低6.26%。RF-ATPSO算法在学生类别1、2及所有类别平均值上的准确率最高,尤其在类别2上准确率达到94.82%,比原始数据集的准确率高6.96%。
RF-ATPSO算法相较于其他5种特征选择算法不仅总体准确率分别提高了4.66%,2.64%,2.19%,2.15%和1.98%,而且在3个类别上也均有不同程度的提高。在类别1和类别2上,RF-ATPSO算法所求得的特征子集准确率最高,分别达到了93.68%和96.71%。
学生学业成绩画像指标数据收敛曲线如图3所示。从图3可知,RF-ATPSO算法在收敛速度和收敛值方面,均优于其余4种特征选择算法;

Figure 3 Convergence curves of student profile indicator data图3 学生画像指标数据收敛曲线
RF-ATPSO算法在第15次已寻找到全局最优解,证明其收敛速度较快,可及时跳出局部最优解;GWO、PSO分别在第50次和第19次寻找到全局最优值;RFGWO、RFPSO分别在第18次和第17次寻找到全局最优值。因此,RF-ATPSO不仅迭代次数少且最优解适应度值更低,拥有较高的寻优效率。
4.3.2 RF-ATPSO特征选择结果分析
如前所述,本文构建的学生学业成绩画像经过RF-ATPSO算法特征选择后降到了82维,包括44个成绩指标(含8个课程排名指标、14个成绩波动指标、3个平均排名指标、18个绩点排名指标和1个挂科总学分指标);37个课程指标(含22个优秀课程指标、5个优秀课程学分率指标、6个低于均分课程率指标和4个优秀课程率指标)。
在实际数据中,学生出现挂科(不及格)的情况较少,因此,学分指标体系下各学生的各项指标值,大多接近于1,因此学分率的区分度不高,在特征选择结果中也基本没有学分率指标体系中的指标,可见该特征选择结果符合实际情况。在选择出的37个课程指标中,所有及格率相关指标的值均接近1,因此区分度不高,实际特征选择结果中,也没有及格率相关指标,可见该特征选择结果也符合实际情况。
5 结束语
针对高校教务领域数据固有的高维特征空间和高度冗余问题,本文提出了一种融合特征权重和改进粒子群优化算法的混合式特征选择算法(RF-ATPSO)。该算法主要分为2个步骤,首先使用RELIEF-F算法计算各个特征的权重,筛除冗余特征;然后从筛选出的特征集合中利用改进粒子群优化算法搜索最优特征子集。
实验方面,首先在6个UCI公共数据集上进行实验。结果表明,C4.5算法在经过RF-ATPSO算法特征筛选后的数据集上不仅准确率优于其他特征选择算法的,而且算法所选特征子集规模最小,在保证准确率的同时提高了C4.5算法的运行效率。在学生学业成绩画像指标数据集上的结果表明,C4.5算法在经过RF-ATPSO算法特征筛选后的数据集上准确率达到94.77%,优于其他传统特征选择算法。尽管本文提出的RF-ATPSO特征选择算法在大部分数据集上取得了较好效果,但还存在经RELIEF-F特征选择后特征子集辨识度变差的问题,未来将重点研究提高特征子集辨识度的最优方法。
