面向装备平台的敏捷交换芯片设计与实现
2024-02-28刘汝霖吕高锋孙志刚
刘汝霖,杨 惠,李 韬,吕高锋,孙志刚
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
随着车载、航空航天等装备平台信息化、智能化程度的不断演进,各类接入设备的数目显著增加,承载功能组件间互联任务的网络设备的重要性愈发凸显。为了应对网络流量的增长,装备平台网络逐步由传统总线网络向以太网为核心的混合网络转变[1]。在这一过程中,有针对性地瞄准装备平台网络在物理特征、性能需求等方面的特点来开发以太网交换芯片具有十分重要的意义。
具体而言,装备平台开发时面临众多的约束条件,如便携装备要求整体体积尽量小,应尽量缩小器件体积,减少部署所需器件数量,同时也对低功耗提出了极端苛求。
其次,装备平台的业务流量相对数据中心场景仍较小。以车载平台网络为例,自动驾驶、车载影音系统的功能所需的高清摄像头、各种雷达等产生的网络流量仅在100 Gbps量级[2]。
第三,由于装备平台的功能碎片化程度高,但同时装机量较少,无法吸引大型厂商根据需求进行交换芯片的业务定制。采用FPGA或CPU的解决方案在处理速度和功耗方面很难满足需求。博通、美满等商用解决方案主要针对数据中心、云计算等场景进行设计,且出于市场等原因,往往更强调大规模极高带宽网络的交换和对已有网络协议的广泛支持,能效比较差。
另外,传统的网络交换芯片在设计时针对特定的网络环境,其报文解析器的流程和行为是固定的,在面对新的网络协议时无法提供正确的解析。为了提高芯片的灵活性,提出了协议无关的可编程解析器设计,如XILINX Packet Parser[3]、可重构匹配表RMT(Reconfigurable Match Table)[4]等。不同方案均采用了可编程的解析器,用户通过设置解析偏移量,来选择将报文的哪些字段进行提取并提交给后续的查表、动作处理等流程。可编程解析器提升了网络交换芯片的灵活性,满足现有网络协议及新协议的需求。然而,可编程解析器需要消耗大量的硬件资源和时序周期,当前商用的可编程交换芯片普遍功耗较高且编程行为复杂,导致上层的配置软件相对繁琐,不便于用户使用。
综上所述,为了满足装备平台对高能效、高灵活性、易用性及后期更新升级的便捷性需求,本文设计并流片生产了可编程、低功耗的敏捷交换芯片YHHX-DS160。本文主要内容总结如下:
(1)提出了一种协议无关的交换芯片实现架构,采用可编程的协议无关多级匹配-动作MMA(Multiple Match &Action)流水线实现对现有网络协议和用户自定义协议的支持。与其它芯片采用可编程解析器的设计不同,该流水线架构通过掩码方式将解析和匹配过程相融合,降低了硬件逻辑和使用配置的复杂度,并大幅提高了能效比。
(2)提出了一种轻量级的多链配置结构,基于二层报文的管理协议能够有效简化配置逻辑的复杂度,支持远程配置、无CPU的轻量级配置等模式。
(3)面向装备平台定制了160 Gbps交换带宽的可编程、低功耗的交换芯片并完成了流片验证,实测全接口线速最大功耗为6.6 W,能效比达到了24 Gbps/W。芯片支持带内远程配置和无配置CPU的轻量化配置模式,可面向各类装备平台提供低功耗、高性能、高灵活度的端到端网络交换解决方案。
2 敏捷交换芯片架构
针对装备平台的芯片架构如图 1所示,包括接口处理逻辑、可编程多级匹配-动作流水线逻辑、轻量级管理配置逻辑、敏捷交换协议处理逻辑等。
2.1 接口处理
芯片接口包括接口物理层硬件和接口数字处理逻辑。其中,接口物理层硬件实现以太网协议(如GMII、10GBASER/KR)、总线协议(如SPI、IIC)等模拟信号与芯片内部数字数据总线之间的转换。接口数字处理逻辑则实现报文的初步过滤、分类、分撒等功能。其中,输入接口逻辑主要实现对报文进行CRC校验、规则过滤、端口报文汇聚等操作。输出接口逻辑根据输出端口号将报文分撒到对应接口。
2.2 可编程多级匹配-动作流水线
本文架构中,报文在流水线中会携带一个长度为32 B的数据结构(元数据),用于记录报文状态、历史匹配情况、待执行的动作等信息。如图 2所示,元数据包含用户自定义字段、报文类型字段、查表控制使能、动作处理使能、报文长度字段、输入端口号、输出端口号等内容。
图1中可编程协议无关匹配-动作流水线可分为查表匹配阶段和动作处理阶段。与其它可编程芯片不同,本文的芯片架构并没有包含独立的可编程解析器模块,而是尝试将解析过程和查表过程相融合。通过带掩码的超长内容匹配,在1个时钟周期内即可得到匹配结果并完成对元数据的更新。同时,解析与匹配相融合的机制将多级表项间的查表匹配过程解耦,匹配动作与各字段在报文中的顺序无关。通过这种设计,既可以满足装备平台对可编程的需求,又消除了可编程解析器对硬件资源和时序周期的大量消耗,提高了能效比,并减轻了用户使用时的配置复杂度。

Figure 1 Architecture of chip图1 芯片架构
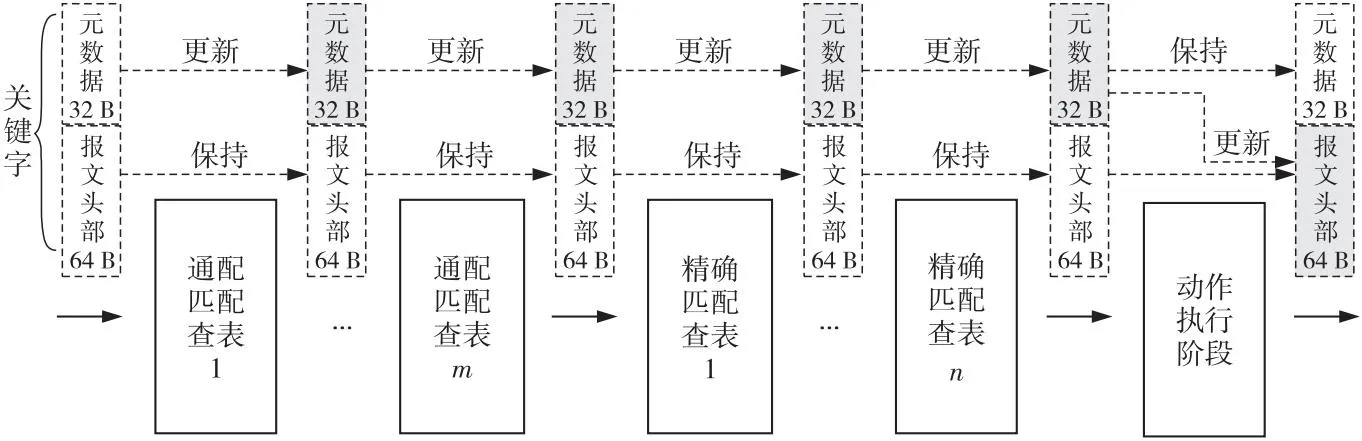
Figure 3 Match-Action pipeline图3 匹配-动作流水线

Figure 4 Format of management packet图4 管理报文格式

Figure 5 Structure of multi-chain management configuration图5 多链管理配置结构

Figure 6 Agile switch chip YHHX-DS160图6 敏捷交换芯片YHHX-DS160

Figure 7 Test environment of switch chip图7 交换芯片测试环境
具体而言,查表关键字为64 B报文头和32 B元数据,可以覆盖绝大部分现有协议的头部信息。查表前未经过任何解析逻辑,能够大幅减少报文解析所需的时间周期,同时保障对于任何单一或多字段的匹配均消耗固定时长,以保障报文处理过程的确定性。
报文分组在流水线中经历多级查表匹配、一次动作处理MMA。在查表匹配阶段,每一级表将表项与报文头部字段和元数据进行匹配,根据结果对元数据进行更新。匹配方式可分为通配匹配和精确匹配,表的级数根据实际需要可进行串联扩展。在完成多级查表之后,动作处理阶段则根据元数据中的各使能开关完成对报文的处理。匹配-动作流水线的工作行为如图 3所示。
芯片所定义的匹配过程(Match)包括:
(1)将报文前64 B和32 B查表结果作为关键字进行通配匹配查表;
(2)将报文前64 B和32 B查表结果作为关键字进行精确匹配查表。
芯片所定义的动作过程(Action)包括:负载均衡,根据流ID或优先级对数据流进行限速,以及报文修改等。
具体而言,通配匹配流程伪代码如算法1所示。每级通配匹配表包含M条表项,每一条表项都具有独立的匹配掩码。掩码的作用等价于报文解析,将所关心的字段掩码有效,其它字段掩码无效。通过配置掩码即可实现可编程的协议无关匹配。在通配匹配过程中,表项和匹配掩码的一一对应,每一条表项都可独立形成一级查表,通过字段的正交组合极大扩展了表项的实际覆盖范围。

Algorithm 1 Ternary Match AlgorithmInput:pkt_header(64 B),metadata(32 B),match_field[M](96 B),key_mask[M](96 B),result[M](32 B),result_mask(32 B),default_result(32 B)。Output:metadata(32 B)。Process: for i=0 to M do key_in={pkt_header,metadata}; key_m=AND(key_in,key_mask); match_field_m=AND(match_field[i],key_ mask); if (key_m == match_field_m) metadata=(result[i] & result_mask) | (metadata&~result_mask); else metadata=metadata; if (metadata.finish) break; end for metadata=(default_result & result_mask) | (metadata&~result_mask);end process
精确匹配采用哈希匹配的方式,每级共用一个匹配掩码,可为同一字段的匹配提供大量表项。精确匹配查表流程伪代码如算法2所示。

Algorithm 2 Exact Match AlgorithmInput:pkt_header(64 B),metadata(32 B),key_mask(96 B),result_mask(32 B)。Output:metadata(32 B)。Process: key_in={pkt_header,metadata}; key_m=AND(key_in,key_mask); address=hash(key_m); //read RAM with address to get match_field and result if (key_m == match_field) metadata=(result & result_mask) | (metadata&~result_mask); else metadata=metadata;end process
精确匹配对查表关键字进行哈希计算,将结果作为地址对存储有表项内容和结果的RAM进行访问。如果查表关键字与RAM中存储的表项内容完全一致,则认为匹配成功,将结果做掩码后更新元数据。
相对通配匹配而言,精确匹配查表的HASH计算值为N-bit地址,即单次可对2N条表项进行索引,极大加快了查表速度。
在查表匹配阶段,仅64 B的报文头部和32 B的元数据组成的查表关键字在流水线中流转,完整的原始报文则存储在缓存FIFO(First Input First Output)中,这种集中缓存的结构可降低因报文分组迁移所产生的延时和功耗。
查表匹配阶段完成后为动作处理阶段,动作处理引擎从集中缓存中取出报文,并根据32 B元数据中动作使能字段、报文长度字段等对报文进行相应处理。芯片的动作处理引擎可独立实现流限速、DMAC(Destination Media Access Control)/SMAC(Source Media Access Control)替换、VLAN(Virtual Local Area Network)标签的添加/删除/替换、敏捷协议封装、管理配置协议封装、负载均衡、PTP相关功能等功能。
2.3 轻量级管理配置
敏捷交换架构中,芯片与外部控制部件之间采用基于二层以太网报文的轻量级管理控制协议,管理控制报文可通过以太网接口、IIC(Inter- Integrated Circuit)接口、SPI(Serial Peripheral Interface)接口等对芯片进行访问。基于二层的配置报文协议能够有效降低管理控制器的复杂度,可通过可编程器件等实现无配置CPU的轻量级管理。
配置报文格式包括了二层头、报文序列号、读写类型、连续读写标识、配置链MID(Module ID)、寄存器地址和寄存器值等。其中,报文二层头中的目的MAC地址、MID、寄存器地址用于定位待访问的寄存器;读写类型标识当前报文是读请求、读响应、写请求、写响应等类型;连续读写标识则根据寄存器地址作为首地址,进行连续读写;寄存器值则与读写类型的具体情况有关。
对某个寄存器的访问经历以下3次寻址:
(1)芯片的接口逻辑根据目的MAC地址判断是否对本文芯片进行配置,如果是则送至芯片内部管理配置模块;否则按规则进行查表转发。
(2)芯片的配置译码逻辑根据MID决定送往哪一条配置链的哪个硬件模块。
(3)根据寄存器地址、读写类型、配置对硬件模块内部寄存器进行访问。
如果接口判断当前配置报文需要对本文芯片进行配置,会将该报文送入配置管理模块。芯片内部配置网络采用多链结构,如图 5所示。配置请求报文在经过配置译码逻辑后,被送入不同的配置链。配置链的划分主要根据功能的耦合关系,如接口模块采用一条配置链,查表逻辑采用一条配置链。在每条配置链内部,由于芯片设计中常采用不同来源的IP,配置接口存在差异,于是将硬件模块配置接口通过适配模块接入配置链。由此,如果将配置网络中的译码逻辑看作树根,配置链可作为树枝,而硬件模块内各寄存器则为配置叶节点。这种树状多链结构可有效缩短管理控制逻辑链条的长度,提高配置效率,避免了总线型结构的多扇出问题和环形结构的长延时问题,也便于后端实现布局布线。
由于芯片可以对配置报文进行转发,该机制可以支持远程访问,通过一台控制终端实现对整个二层网络域内所有交换芯片的配置。
2.4 敏捷交换协议处理
在OpenFlow架构中,元数据是对外部不可见的,仅用于内部表项间的信息交互。本文为了进一步增强芯片的灵活性,设计了敏捷交换协议,可将内部查表过程产生的元数据信息随报文携带出芯片。外部通过提取元数据信息可以获取该报文的查表结果、动作处理历史等信息。另外,利用元数据中的用户自定义字段,将预置信息在查表匹配成功后更新到元数据中,以实现丰富的自定义功能。如,预先填入流标签信息可以实现流映射功能;针对芯片组件的多节点网络,预先填入节点编号,可以获取报文路由信息。根据元数据中携带的信息不同,敏捷交换协议可实现数据状态的随流检测、流映射、查表协处理等功能。本文4.2节介绍了基于敏捷交换协议的随流检测的例子。
基于敏捷交换协议,芯片不仅可作为独立的交换芯片使用,也可作为查表协处理器、动作执行器等与外部FPGA、CPU等设备进行协作。更进一步,基于先进的多芯片封装技术,芯片可作为芯粒化(Chiplet)的基本单元支持构建功能更加复杂的芯片。
图 1架构图中的敏捷交换协议解封装和敏捷交换协议封装2个模块提供了对自定义的敏捷交换协议报文的支持。其中,敏捷交换封装模块位于输出接口逻辑之前,将元数据封装在原始报文的报文头部形成敏捷交换报文;解封装模块则位于输入接口逻辑之后,负责从封装报文中获取元数据信息。对于不包含元数据的标准以太网报文,解封装模块可通过实际的输入端口号、报文长度构造一个新的元数据用于后续流水线操作。
3 芯片实现与实验验证
基于上述架构,本文流片生产了面向装备平台的可编程、低功耗的银河衡芯敏捷交换芯片YHHX-DS160,如图 6所示。芯片采用676引脚BGA封装,尺寸为27 mm*27 mm,全接口线速交换最大功耗仅6.6 W,交换能效比达到了24 Gbps/W。DS160芯片属于银河衡芯芯片谱系。该谱系已发布了敏捷交换芯片DS40[5]、时间敏感网络芯片DS09[6]等。
根据装备平台对高速以太网接口和轻量化配置的需求,芯片物理层接口提供16路10 GE高速以太网数据接口、1组千兆媒体无关接口GMII(Gigabit Media Independent Interface)数据接口、1组SPI配置接口、1组IIC配置接口。其中,10 GE高速以太网接口采用内置串并转换器SerDes (Serializer-Deserializer)的集成化设计,免除了对外置物理层设置PHY(port PHYsical layer)的需求。另外,16路接口可分为4组,每组4路10 GE接口可聚合形成一组40 GE接口。芯片全部40 GE/10 GE接口和GMII接口均支持带内配置方式,可同时收发配置报文和数据报文。SPI和IIC等慢速接口则仅用于管理配置。板级实现时,可将配置信息写入外置可编程逻辑器件EPLD (Erasable Programmable Logic Device),以实现上电自配置功能,实现无需专用配置CPU的轻量化管理模式。另外,配置报文可通过网络交换节点进行传输,以实现远程配置。
为满足各类装备平台对表项的需求,芯片包含了8级通配匹配和4级精确匹配。每级通配匹配具有16条表项,8级通配表共计128条表项。每级精确匹配具有2 000条表项,4级通配表共计8 000条表项。所有表项均支持可编程的协议无关配置,极具灵活性。
芯片在使用时,需要对匹配表项和表项的掩码寄存器进行配置。为便于用户开发使用,芯片提供了将底层细节屏蔽的配套软件,包括通用的表项配置接口API、通用表项字段的结构体和常见IP报文匹配字段结构体。用户首先对结构体成员进行赋值,再将结构体传递给表项配置API,由API函数完成寄存器读写报文的构造和解析。
芯片测试环境如图 7所示,其中芯片测试板对外提供1路千兆以太网RJ-45接口、8个10 GE SFP接口、2组4通道SFP QSFP(Quad Small Form-factor Pluggable)接口。千兆RJ-45接口通过网线与配置PC相连;10 GE/40 GE接口通过光纤与网络测试仪相连。
测试内容包括带宽测试、延时特征测试、功耗测试、基本查表功能、动作执行、敏捷交换协议报文封装测试等。下文将对其中部分测试项进行详细说明。
3.1 带宽测试
根据RFC 2544对芯片各接口线速进行测试,测试选取64 B, 128 B, 256 B, 512 B, 1 024 B, 1 280 B, 1 518 B以及随机长度的报文,通过测试仪以接口的标称线速(千兆接口为1 Gbps, 10 GE接口标称线速为10 Gbps, 40 GE接口标称线速为40 Gbps)进行测试,测试结果无丢包情况。不同报文长度的测试案例均可达到160 Gbps的全端口线速。
3.2 延时特征测试
测试过程中选定1组40 GE/10 GE接口,网络测试仪收发固定长度的报文,并统计延时。
图8所示为无背景流影响时的芯片交换延时。可以看出,40 GE接口和10 GE接口的转发延时均与报文长度呈现正相关性,增长斜率上10 GE接口的比40 GE接口的大,且10 GE接口对64 B和128 B长度的小报文收发延时低于40 GE接口的,但在收发256 B及更长报文时的延时高于40 GE接口的。该趋势是端口存储报文延时和链路速率差异共同作用的结果:一方面,由于接口采用了存储转发方式,40 GE接口的链路速率更高,其收集完整报文所需的时间较10 GE接口的要短;另一方面,40 GE接口的报文处理逻辑较10 GE接口的长,报文延时更高。
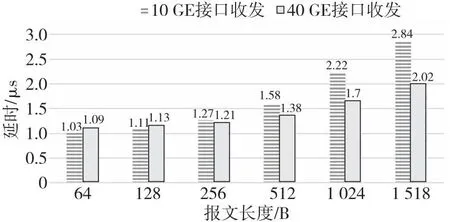
Figure 8 Transmission delay of 40 GE/10 GE图8 40 GE/10 GE接口延时
另外,由于芯片流水线中的动作处理阶段及接口汇聚分撒流水线阶段均采用了存储转发方式,长报文经过多次存储也会导致延时升高,图8中延时随报文长度变化的趋势也反映了这一点。
3.3 功耗测试
对于装备平台设备,尤其是嵌入式设备而言,功耗是比较重要的指标。本节对DS160芯片的功耗进行分析。芯片具有3类电源域:IO电源域、10 GE/40 GE高速以太网接口电源域、芯片内部逻辑电源域。芯片上电后的典型待机功耗(Standby Power)为5.8 W,3类电源域的待机功耗分别为1.95 W, 2.2 W和1.65 W。
为了分析动态功耗,本文将全端口线速工况下的功耗与无报文收发情况下的待机功耗进行了对比,如图 9所示。可以看出,全端口线速下的动态功耗为6.6 W,相对待机功耗增加了0.8 W,一个合理的解释是芯片采用了门控时钟机制,在无报文收发的情况下部分逻辑未产生功耗。
进一步的测试中,减小了芯片的核心工作频率。实验结果表明,芯片动态功耗和待机功耗都有不同程度的降低,但降幅不明显。如图 9所示,芯片的核心频率从500 MHz(核心处理带宽160 Gbps)降至125 MHz(核心处理带宽40 Gbps),核心处理带宽下降了75%,待机功耗和动态功耗仅降低了0.26 W和0.65 W。
需要特别指出的是,图9的数据中I/O电源域和10 GE/40 GE高速以太网电源域的功耗值几乎不变,即所有功耗的变化几乎都来自于芯片内部报文处理逻辑。这是因为对于高速以太网接口而言,即使其模拟链路上没有有效数据传输,仍会以10.312 5 Gbps的速率发送链路空闲信息,导致功耗几乎不变。
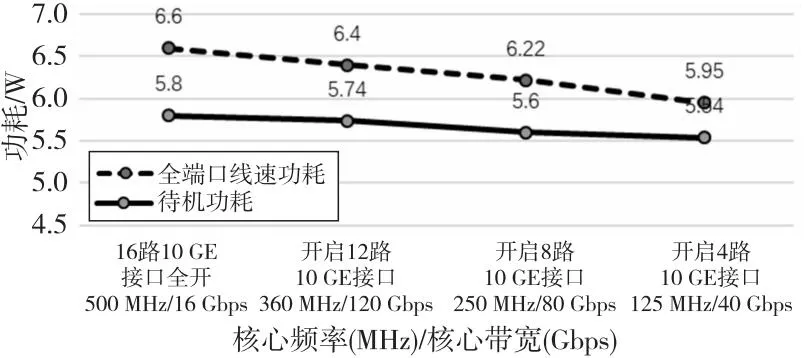
Figure 9 Relationship between core frequency and chip power consumption图9 核心频率与芯片功耗的关系
在实际使用场景中,并非总是会用尽芯片的接口资源,因此可采用关闭部分接口的方式进一步降低功耗。测试结果表明,每关闭1路10 GE收发通路可降低功耗约0.14 W。且由于端口总带宽减小,可相应调整核心频率,在保证剩余端口满足线速的情况下,尽可能减小功耗。如图 10所示为根据开启接口数目调整核心处理频率后的功耗变化趋势。图10中,数据点选择开启16路,12路,8路和4路10 GE接口,将核心频率调整为500 MHz, 360 MHz, 250 MHz和125 MHz,核心处理能力达到了160 Gbps, 120 Gbps, 80 Gbps和40 Gbps。
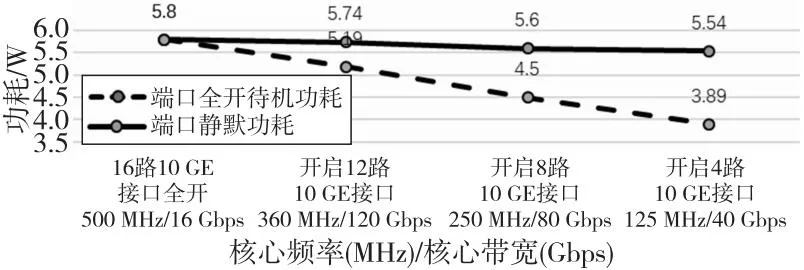
Figure 10 Relationship between chip port state and power consumption图10 芯片接口状态与功耗的关系
根据功耗测试结果可知,DS160芯片相对于100 Gbps级别的其它交换芯片具有较高的能效比。另外,由于该芯片为试制芯片,I/O中包含大量的调测试引脚,导致了较高的功耗,后续芯片设计将采用寄存器代替I/O硬连线方式,能效比还会得到进一步提高。
4 芯片部署与应用
为了说明本文芯片特点,如协议无关匹配动作流水线进行报文转发、敏捷交换协议的优势等,本节对典型的业务应用进行举例说明。
4.1 L2转发
由于DS160芯片流水线没有报文解析器的参与,对于报文转发而言,表项掩码一次性标识所有参与匹配字段。对于L2/L3层的转发而言,即通过掩码将目的MAC DMAC、源MAC SMAC(Source Media Access Control)、报文类型(TYPE字段)、五元组信息等字段置为有效即可。
如图 11所示为基于DMAC地址进行匹配的示意图。由于DMAC位于L2层以太网报文的前48 bit,因此设置查表掩码与DMAC对应的48 bit位值为1,其它位置均为0。由报文前64 B和32 B元数据组成的查表关键字在掩码作用下,仅就DMAC字段进行匹配,图11中假设表项2匹配成功。下一步,根据结果掩码的设置,以表项2结果中的输出端口号字段更新元数据,并结束本级查表。

Figure 11 Example of L2 packet forwarding图11 L2层报文转发示例
4.2 随流故障检测
敏捷交换芯片DS160芯片具有丰富的表项资源和报文处理动作支持,可用于构建网络设备的交换核心,同时基于敏捷交换协议可以将查表结果、用户自定义信息在数据路径的前后级模块间传递,加强了前后级处理单元的协作能力,可支持包括带内检测等在内的一系列新功能的实现。
带内检测主要针对传统网络遥测过程中业务故障被动检测、定位效率低下等问题,通过在报文内部添加标记信息等方式实现随流检测。基于DS160的带内检测解决方案如图 12所示。带内检测流程可分为故障上报、链路检测配置、检测结果收集和检测结果输出4个阶段。在第1阶段中,任意节点均可发出故障上报请求,图11中假设接入设备处发现报文丢失,将故障发送到管理服务器。
在第2阶段中,由管理服务器执行链路检测相关配置,具体是针对待检测的报文开启敏捷交换协议封装,查表匹配逻辑则针对敏捷交换协议封装报文进行统计计数。根据报文数守恒原则,在一条链路上,端到端之间收发报文数相等,如果某个节点出现拥塞或其它原因导致的丢包,那么该节点及后续节点报文的计数值会变小。由此,通过对各个节点接收到的敏捷交换协议封装报文进行计数,可以推断链路故障发生的节点位置。另外,针对有多条流需要检测的情况,可通过元数据中的用户自定义字段进行流区分。
启动报文带内检测后,经过一段时间的数据收集进入检测第3阶段。第3阶段中,管理服务器关闭敏捷交换报文封装功能,并对各节点接收到的封装报文进行汇总分析,通过报文数守恒原则确定故障发生的节点,并将结果以可视化的方式呈现给系统管理员(即图12中的④),然后进行下一步处理。
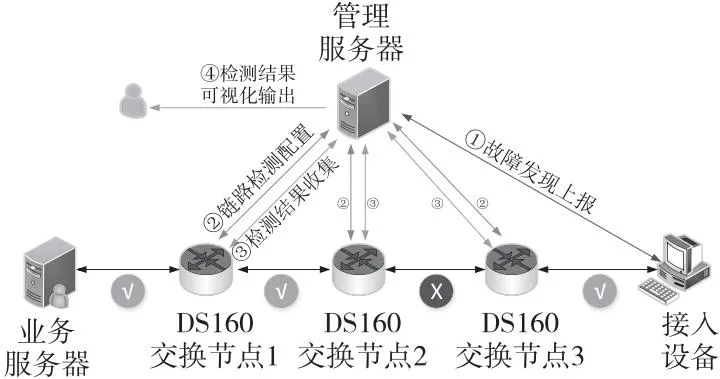
Figure 12 Schematic diagram of in-band detection图12 带内检测流程示意图
5 相关工作
商用的可编程交换芯片往往采用软件或硬件的方式实现灵活的可定制处理方法,如Intel Tofino系列芯片、BroadCom BCM5340X系列芯片、Intel NFP-6xxx系列芯片等。相对于软件处理方式,硬件可编程的交换能够实现更好的处理性能、更低的线速功耗;相对地,软件方式可以实现更复杂的报文处理。
Tofino交换芯片面向数据中心等场景提供Tbps量级的交换容量。采用硬件RMT架构,支持无语义的协议无关匹配-动作(Match-Action)模型。报文进入RMT流水线后通过可编程解析器提取并匹配报文关键字段,随后送入超长指令执行单元构成的动作处理器对报文进行处理。通过多级解析器和动作处理器的级联实现复杂报文处理功能。
BCM5340X系列交换芯片提供160 Gbps的交换容量,采用将常见的固定数据报文字段匹配和基于通用处理器的软件自定义处理方式相结合的架构,在兼顾硬件交换性能的基础上,提供部分可编程支持。
Intel NFP-6xxx系列芯片则通过集成多核处理器,将任务分割到多个完全可编程的、分工具体的处理内核中。这种方式能够处理极其复杂的报文处理流程,但由于采用多核处理器,其功耗较高,以240 Gbps的6324型号芯片为例,其典型功耗高达102 W。
与上述芯片相比,本文提出的DS160芯片采用纯硬件的方式实现协议无关超长字节匹配处理。与Tofino芯片不同,DS160面向装备平台设计,不追求超大交换容量和过于复杂的可编程性,采用相对简化的多级查表匹配、一次动作处理的模型,在提供灵活可编程功能的同时有效降低芯片功耗,能效比显著优于当前主流的商用芯片的。同时,DS160支持远程配置、无CPU的轻量级配置等模式,可有效简化配置逻辑的复杂度。另外,敏捷交换协议封装可在支持标准以太网报文交换的同时提供更多的扩展功能。
6 结束语
针对装备平台面临的功耗受限、体积受限、功能碎片化、硬件升级困难等制约因素,本文提出了可编程、低功耗的敏捷交换芯片架构,并流片生产了具有160 Gbps全线速交换带宽的DS160芯片,能效比达到24 Gbps/W。该芯片可提供数目充足的可编程的协议无关匹配表项,支持各类现有协议和自定义协议,支持远程配置和无CPU的轻量级配置模式,为上层应用提供精细化流映射,可面向各类装备平台提供低功耗、高性能、高灵活的端到端网络交换解决方案。
